
Парсер на основе PHP и библиотеки «Simple HTML Dom»
Автор статьи: admin
В этой статье мы разберём создание парсеры на основе PHP, при этом максимально просто, также будим использовать библиотеку «Simple HTML DOM».
Если вы плохо работаете с PHP, то посмотрите наш PHP учебник.
Установка библиотеки:
Перед тем, как перейти к самой разработке нужно скачать саму библиотек, для этого заходим по ссылке и нажимаем кнопку «Download».
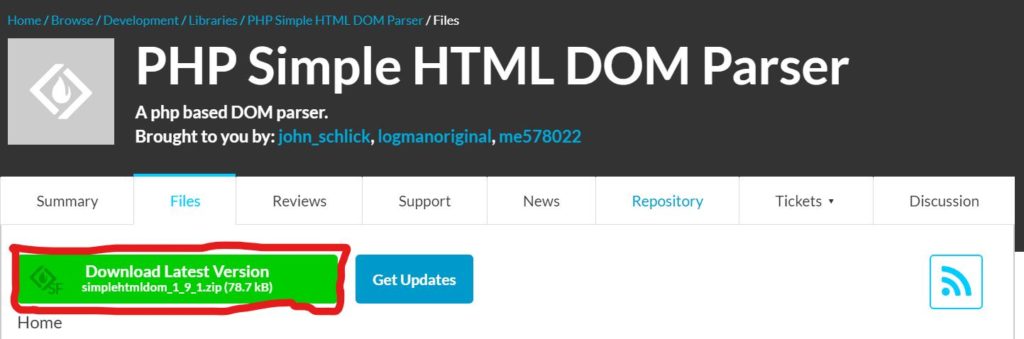
У вас скачивается архив, из него, перемешаем файл под названием «simple_html_dom.php» в папку с вашем проектом, после подключаем его в файл парсера, через require_once.
require_once «./simple_html_dom.php»; |
Теперь библиотека установлена.
Пишем парсер контента на PHP:
Теперь пришло время написать парсер на PHP самому и это будет пошаговая инструкция, умаю вам будет понятно.
Но сначала расскажу, от куда будем брать данные, будем их брать с сайта StopGame.ru, мне кажется он наиболее будет понятный для примере, возьмём мы с него новости, точнее название.
Для начала объявим переменную в которой у нас будет хранится URL страницы, от куда будем брать данные.
$url = «https://stopgame.ru/news»; |
Дальше будем использовать стандартную библиотеку PHP CURL, благодаря которой мы возьмём страницу сайта.
$ch = curl_init(); // Создаём запрос curl_setopt($ch, CURLOPT_URL, $url); // Настраиваем URL запроса curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); // Задаём в качестве возвращаемого значение от ответа строку $res = curl_exec($ch); // Отправляем запрос |
Давайте не много разберём этот код, мы создаём запрос с помощью функции curl_init(), дальше идёт его настройка, через функцию curl_setopt(), ну и отправляем его через curl_exec() и сохраняем ответ в переменную $res.
Самая интересное в этом коде функция curl_setopt(), потому что она имеет очень много настроек для запросов, поэтому, если кому не достаточно информации о ней, то переходите по ссылке, также посмотрите документацию библиотеки CURL.
Настало время самого интересного, это самого парсенга и работе с библиотекой «Simple HTML DOM».
$dom = new simple_html_dom(); // Создаём объект класса simple_html_dom $html = str_get_html($res); // Берём из строки HTML |
Тут не чего сложного нет, даже нечего объяснять, всё в комментариях написано.
Теперь пришло время получить какие данные нам нужны и вывести их на экран, мне же нужно получить только заголовки.
// Находим элемент по селектору $list = $html -> find(‘.lent-left div.title.lent-title’);
// Выводим всё элементы foreach ($list as $key => $value) { echo «<h4>» . $value->plaintext . «</h4>»; } |
Тут тоже не чего сложного нет, благодаря $html -> find(), мы находим нужные элементы по селекторы и получаем список их.
После этого проходимся по списку с помощью цикла foreach, выводим на экран каждый элемент, вот результат.

Как можете заметить, он вывел заголовки из новостей, что значит всё работает.
То есть суть работы парсера в том, что вы просто берёте страницу и ищите по селектору нужный вам элемент, при чём так работает почти всё парсеры на любом языке.
Вывод:
В это статье вы прочитали о том как делаются парсеры на основе PHP, думаю я ту рассказал всё что нужно знать.
Также если вас заинтересовала это библиотека, то посмотрите её документацию.
Подписываетесь на соц-сети:
Оценка:
(Пока оценок нет)
 Загрузка…
Загрузка…
Как писать php парсеры. Основы
Что такое парсер? Парсер — это скрипт, который автоматически, по шаблону, собирает информацию с выбранного ресурса, и сохраняет, в удобном для нас виде. Например, нам нужно скачать 1000 статей с сайта кулинарных рецептов. И задача парсера заключается в том, чтобы автоматически собрать ссылки на все эти 1000 статей, перейти по каждой из них, и получить полезные для нас данные.
В общем случае, парсер получает html-разметку, из которой он извлекает полезную информацию, путём доступных ему средств (DOM-парсинг, регулярные выражения, и т.п.). И, вот, эту полезную информацию, мы, на выходе, и получаем, в чистом виде. Как обрабатывать её, тоже решать нам.
И так, можно выделить 3 основных этапа парсинга:
- HTTP-запрос на сайт, для получения разметки сайта
- Извлечение полезной информации из загруженной зразметки
- Формирование отчёта по найденным данным, и дальнейшая обработка
Для того, чтобы получить разметку сайта, нужно сделать http-запрос. Вот для этого, в PHP и существует такая программа, как CURL. Это программа, которая делает запрос к указанному серверу, с указанными нами параметрами (тело запроса, заголовки, cookies, метод запроса, и т.д.). На самом деле, эта программа используется и для отправки API-запросов, однако, большее распространение она получила именно в написании ботов, и парсеров. Для запросов к API, обычно используют функцию file_get_contents, вместе с надстройкой для отправки кастомных запросов.
Curl — это не какая-то часть PHP, которая есть только в нём. CURL — это отдельная, независимая программа, являющаяся браузером, управляемым из консоли. А PHP лишь имеет модуль, который упрощает работу с этой программой, и позволяет делать запросы на собственном синтаксисе.
На практике, парсеры бывают очень полезными. Так, с помощью них можно скачать все картинки с сайта, все видео, или все статьи.
Часто новые интернет-магазины, для автоматического наполнения товарами, как раз и пользуются парсерами, которые автоматизируют работу копирования товаров, или автоматическое обновление цен, в зависимости от цен конкурентов.
При этом, парсеры могут содержать дополнительную логику по преобразованию (удаление фрагментов текста, редактирование картинок, увеличение цены на определённый процент).
Новостные сайты, агрегирующие новости одновременно с нескольких сайтов, аналогично, не могут обходиться без средств автоматизации.
Второй вариант использования CURL — это боты, которые автоматизируют рутинные действия: авторизуются под вашим аккаунтом, забирают бонусы, автоматически добавляют посты, комментарии, переходят по ссылке из писем, и т.д. На самом деле, применение этих «зверушек» очень широкое, потому, знать это стоит, хотя бы основы. Уверен, что в личном опыте, эти знания сыграют вам хорошую службу.
Говоря о практическом применении, последним моим парсером был скрипт, копирующий видеоуроки с сайта, сохраняя каждый видеоурок в отдельную папку.
Ещё в начале пути я интересовался, как создать парсер на php. И, на удивление, это оказалось достаточно просто. Для того, чтобы понять, как парсеры работают внутри, прочитайте две вводных статьи:
Эта статья является исключительно теорией. Она только объясняет основные термины, которые нужны для понимания того, как работают парсеры. Потому, чтобы научиться писать хорошие парсеры, нужно писать много парсеров, и читать последующие статьи по теме =)
Автоматизация парсинга на PHP | Трепачёв Дмитрий
Сейчас мы с вами научимся
автоматически запускать парсер по расписанию,
например каждый день или каждый час.
Однако, перед этим я дам вам пару советов,
без которых вполне можно прожить,
но с ними создание и отладка парсера станет намного проще.
Итак, приступим.
Логи при парсинге
Совет: ведите логи при парсинге.
Создайте отдельную таблицу в базу данных,
в которую парсер будет записывать все свои действия:
«Зашел на такую-то страницу», «Начал парсить такую-то категорию»
и так далее — любые действия парсера.
Это, конечно же, замедлит работу парсера, но не сильно существенно.
Пишите также время добавления записи в таблицу,
а также тип записи: действие, ошибка, важное действие и тп —
так будет проще отделить важное от не очень важного.
Зачем нужны эти логи: так вы сможете легко контролировать,
что происходит в данный момент, а также увидите, какие ошибки
случаются при парсинге — и легко сможете их исправить.
Создание более-менее сложного парсера без логов
достаточно проблематично — вы постоянно будете путаться,
не будете понимать, что у вас там происходит и
почему все не работает.
Еще совет: парсер лучше сразу начинать делать
с логами, а не тогда, когда куча проблем заявит о себе —
ведь тогда интегрировать логи будет гораздо сложнее
и затратнее по времени.
Еще совет: автоматически очищайте таблицу с логами
перед новым парсингом (sql команда TRUNCATE).
Кеш при парсинге
Когда вы будете разрабатывать парсер,
с первого раза у вас ничего не получится и придется постоянно
дергать сайт, который вы парсите.
Чем это плохо: во-первых, так вас могут забанить на этом сайте,
во-вторых — это достаточно медленно, в-третьих — не следует
без толку дергать чужой сайт, проявите уважение.
Итак, совет: кешируйте страницы при парсинге.
Что имеется ввиду: сделайте таблицу в базе данных,
в которую целиком будете сохранять страницы чужого сайта при парсинге.
Принцип такой: при запросе определенного URL проверяется — есть такой URL и такая страница
в вашей базе или нет. Если есть — тянем ее из базы,
а если нет — тянем ее из интернета, сохраняем в кеш —
и в при следующем обращении эта страница возьмется уже из базы.
Сохранение при обрыве
Если сайт, который вы парсите — достаточно большой
и парсится достаточно много времени — может
случится обрыв.
Причины: банальные проблемы с интернетом, или компьютер отключится,
или вам срочно нужно отойти, а сайт еще не спарсился, или вас забанил
сайт, который вы парсите.
В последнем случае можно вообще не спарсить сайт —
он вас отбанит через некоторое время, но если начать парсинг сначала —
вы опять дойдете примерно до этого место — и вас опять забанят.
Поэтому хотелось бы иметь возможность сохранения и возобновления
парсинга с места обрыва.
В общем то, можно обойтись и без этого, если сделать кеш —
в этом случае после обрыва парсер вначале будет идти по кешу,
что на порядок быстрее и не банится, так как вы не дергаете чужой сайт,
бегая по своему кешу.
Однако, все равно некоторое время будет тратится на парсер кеша
и лучше обойтись без этого и начать с места обрыва.
Как реализовать возобновление:
самое простое, что можно сделать, это сохранять спаршенные категории
сайта. К примеру, парсер спарсил первую категорию — в специальную
таблицу делаем пометку об этом (можно изначально хранить в ней все категории
и просто помечать, которая уже была спаршена).
Если был обрыв и парсер начинается сначала — он автоматически
должен проверить таблицу с сохранками и начать парсить с первой
неспаршенной категории. В этом случае неспаршенная
категория уже возможно была частично спаршена и будет перепаршена
заново, однако, это лучше, чем парсить весь сайт заново.
Можно делать и более сложные сохранки — вплоть до хранения
страницы, на которой остановился парсер.
Нужно только искать среднее между сложностью разработки
сохранения и выгодой от него. Иногда проще перепарсить часть сайта
и сделать простое сохранение категорий, чем мучаться
и делать скрупулезное сохранение вплоть до страницы.
Автоматический запуск парсера в браузере
TODO: ссылки на плагин для хрома.
Размещение парсера в интернете
Итак, мы уже выяснили, что парсер можно
размещать на локальном компьютере или на хостинге в интернете.
Давайте рассмотрим преимущества и недостатки.
Локальный компьютер. Преимущества: бесплатно, весь процессор
и оперативная память может быть отдана под парсер, легко можно
менять ваш ip в случае бана (просто перезагрузив роутер).
Недостатки: не особо подходит для периодического парсинга.
Хостинг. Преимущества: удобно запускать периодический парсинг,
можно купить несколько ip для обхода защиты от парсинга (может быть дороговато).
Недостатки: платно, статичный ip легко могут забанить при парсинге.
Если ваш парсер будет размещаться в интернете — то обычный хостинг
вам не подойдет, так как на нем стоит ограничение по времени выполнения PHP
скрипта. Вам нужен выделенный сервер
или виртуальный выделенный сервер VDS. Во первом случае
вы получите целый компьютер-сервер с свое пользование (дорого),
во втором случае — часть компьютера (дешевле).
Самостоятельное задание:
погуглите VDS хостинги, попробуйте разместить там ваш скрипт.
Работа с cron
Cron представляет собой специальный сервис на хостингах,
который позволяет запускать скрипты по расписанию.
Очень удобно для периодических парсеров.
Если вы заведете себе VDS — в настройках вы обязательно
увидите вкладку Cron, перейдя на которую вы сможете
запускать скрипты по расписанию. Это несложно — залезьте в настройки —
вы все увидите.
Предупреждение: не следует запускать кроном урлы
своего сайта — вы легко можете подвесить свой сервер.
Запускайте файлы своего скрипта.
Настройки PHP
Есть некоторые настройки PHP, необходимые при парсинге.
Их следует вызывать в начале скрипта с парсером.
Команда ini_set(‘max_execution_time’, ‘10000’) устанавливает
время выполнения скрипта PHP в секундах (по умолчанию оно очень мало —
около минуты). Ставьте побольше.
Функция set_time_limit(0) отменяет ограничение
на время выполнения скрипта. Используйте вместе с предыдущей командой.
Команда ini_set(‘memory_limit’, ‘2048M’) устанавливает
лимит оперативной памяти, выделяемой на скрипт. Ставьте побольше.
Функция ignore_user_abort(true) делает так, чтобы даже
если в браузере оборвут скрипт — он продолжался дальше.
Значение false отменяет это это поведение.
Что вам делать дальше:
Приступайте к решению задач по следующей ссылке: задачи к уроку.
Когда все решите — переходите к изучению новой темы.
Как сделать парсер контента на PHP
Вы здесь:
Главная — PHP — PHP Основы — Как сделать парсер контента на PHP
У многих из Вас возникают вопросы по поводу создания парсера на PHP. Например, есть какой-то сайт, и Вам необходимо получить с него контент. Я долго не хотел писать эту статью, поскольку конкретного смысла в ней нет. Чтобы сделать парсер на PHP, нужно знать этот язык. А те, кто его знает, такой вопрос просто не зададут. Но в этой статье я расскажу, как вообще создаются парсеры, а также, что конкретно нужно изучать.
Итак, вот список пунктов, которые необходимо пройти, чтобы создать парсер контента на PHP:
- Получить содержимое страницы и записать его в строковую переменную. Наиболее простой вариант — это функция file_get_contents(). Если контент доступен только авторизованным пользователям, то тут всё несколько сложнее. Здесь уже надо посмотреть, каков механизм авторизации. Далее, используя cURL, отправить правильный запрос на форму авторизации, получить ответ и затем отправить правильные заголовки (например, полученный идентификатор сессии), а также в этом же запросе обратиться к той странице, которая нужна. Тогда уже в этом ответе Вы получите конечную страницу.
- Изучить структуру страницы. Вам нужно найти контент, который Вам необходим и посмотреть, в каком блоке он находится. Если блок, в котором он находится не уникален, то найти другие общие признаки, по которым Вы однозначно сможете сказать, что если строка удовлетворяет им, то это то, что Вам и нужно.
- Используя строковые функции, достать из исходной строки нужный Вам контент по признакам, найденным во 2-ом пункте.
Отмечу так же, что всё это поймёт и сможет применить на практике только тот, кто знает PHP. Поэтому те, кто его только начинает изучать, Вам потребуются следующие знания:
- Строковые функции.
- Библиотека cURL, либо её аналог.
- Отличное знание HTML.
Те же, кто ещё вообще не знает PHP, то до парсеров в этом случае ещё далеко, и нужно изучать всю базу. В этом Вам поможет мой курс, либо какие-нибудь книги по PHP.
Безусловно, Америки я в этой статье не открыл, но слишком много вопросов по теме парсеров, поэтому этой статьёй я постарался лишь дать развёрнутый ответ.
-
Создано 13.01.2014 13:21:08 -
Михаил Русаков
Предыдущая статья Следующая статья
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:

-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]

10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
PHP Simple HTML DOM Parser скачать
Полное имя
Телефонный номер
Должность
Промышленность
Компания
Размер компании
Размер компании: 1 — 2526 — 99100 — 499500 — 9991,000 — 4,9995,000 — 9,99910,000 — 19,99920,000 или более
Получайте уведомления об обновлениях для этого проекта.Получите информационный бюллетень SourceForge.
Получайте информационные бюллетени и уведомления с новостями сайта, специальными предложениями и эксклюзивными скидками на ИТ-продукты и услуги.
Да, также присылайте мне специальные предложения о продуктах и услугах, касающихся:
Программное обеспечение для бизнеса
Программное обеспечение с открытым исходным кодом
Информационные технологии
Программирование
Оборудование
Вы можете связаться со мной через:
Электронная почта (обязательно)
Телефон
смс
Я согласен получать эти сообщения от SourceForge.сеть. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Я согласен получать эти сообщения от SourceForge.net указанными выше способами. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Для этой формы требуется JavaScript.
Подписывайся
Кажется, у вас отключен CSS.Пожалуйста, не заполняйте это поле.
Кажется, у вас отключен CSS.
Пожалуйста, не заполняйте это поле.
.
PHP Простой парсер HTML DOM
Полное имя
Телефонный номер
Должность
Промышленность
Компания
Размер компании
Размер компании: 1 — 2526 — 99100 — 499500 — 9991,000 — 4,9995,000 — 9,99910,000 — 19,99920,000 или более
Получайте уведомления об обновлениях для этого проекта.Получите информационный бюллетень SourceForge.
Получайте информационные бюллетени и уведомления с новостями сайта, специальными предложениями и эксклюзивными скидками на ИТ-продукты и услуги.
Да, также присылайте мне специальные предложения о продуктах и услугах, касающихся:
Программное обеспечение для бизнеса
Программное обеспечение с открытым исходным кодом
Информационные технологии
Программирование
Оборудование
Вы можете связаться со мной через:
Электронная почта (обязательно)
Телефон
смс
Я согласен получать эти сообщения от SourceForge.сеть. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Я согласен получать эти сообщения от SourceForge.net указанными выше способами. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Для этой формы требуется JavaScript.
Подписывайся
Кажется, у вас отключен CSS.Пожалуйста, не заполняйте это поле.
Кажется, у вас отключен CSS.
Пожалуйста, не заполняйте это поле.
.
Скачать PHP Simple HTML DOM Parser с SourceForge.net
Полное имя
Телефонный номер
Должность
Промышленность
Компания
Размер компании
Размер компании: 1 — 2526 — 99100 — 499500 — 9991,000 — 4,9995,000 — 9,99910,000 — 19,99920,000 или более
Получайте уведомления об обновлениях для этого проекта.Получите информационный бюллетень SourceForge.
Получайте информационные бюллетени и уведомления с новостями сайта, специальными предложениями и эксклюзивными скидками на ИТ-продукты и услуги.
Да, также присылайте мне специальные предложения о продуктах и услугах, касающихся:
Программное обеспечение для бизнеса
Программное обеспечение с открытым исходным кодом
Информационные технологии
Программирование
Оборудование
Вы можете связаться со мной через:
Электронная почта (обязательно)
Телефон
смс
Я согласен получать эти сообщения от SourceForge.сеть. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Я согласен получать эти сообщения от SourceForge.net указанными выше способами. Я понимаю, что могу отозвать свое согласие в любое время. Пожалуйста, обратитесь к нашим Условиям использования и Политике конфиденциальности или свяжитесь с нами для получения более подробной информации.
Для этой формы требуется JavaScript.
Подписывайся
Кажется, у вас отключен CSS.Пожалуйста, не заполняйте это поле.
Кажется, у вас отключен CSS.
Пожалуйста, не заполняйте это поле.
.
Добавить комментарий