
Как изменить параметры PHP | REG.RU
Как установить PHP на хостинг
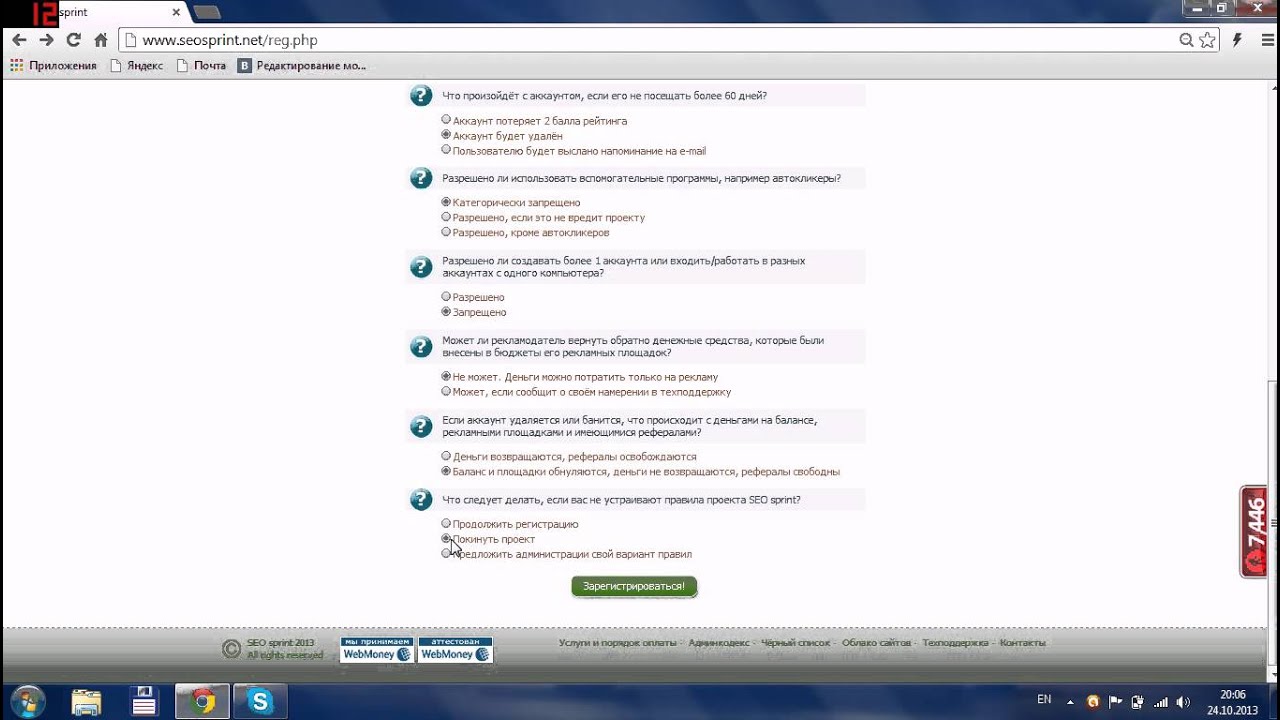
Поддержка PHP присутствует на всех тарифных планах Hosting Linux и Hosting Windows, кроме тарифов Host-Lite и Win-Lite. Если у вас один из этих тарифов, повысьте тарифный план, чтобы включить поддержку PHP.
Как изменить параметры PHP
Для каждой версии PHP можно установить свои параметры. Инструкция для изменения параметров PHP подходит, только если у вас есть услуга хостинга Linux. Можно ли сменить те или иные параметры PHP на хостинге Windows, вы можете уточнить в службе техподдержки. Вы можете попробовать бесплатный хостинг для сайтов HTML с поддержкой PHP и MySQL в течение 14 дней тестового периода.
Чтобы изменить настройки PHP, нужно установить на файл php.ini права 600 (rw——-) или 644 (rw-r—r—) и затем внести в него изменения.
Чтобы установить права и внести изменения, следуйте инструкции для вашей хостинг-панели:
-
2.Выполнение этого шага зависит от пути, по которому хранятся настройки PHP. Подробнее в статье Где находятся настройки версий PHP в ISPmanager.
- Если вы храните настройки PHP отдельно для каждого домена по пути /var/www/php-bin/имя-домена/php.ini, в разделе «Главное» нажмите Менеджер файлов. Перейдите в каталог /var/www/php-bin/имя-домена/. Выберите файл php.ini и нажмите Атрибуты. Измените права файла на 600 или 644:
- Если вы используете общую версию PHP и храните настройки для всех доменов по пути /var/www/php-bin-php(номер-версии-PHP)/php.
 ini, в разделе «Главное» нажмите Менеджер файлов. Перейдите в каталог /var/www/php-bin-php(номер-версии-PHP)/. Выберите файл php.ini и нажмите Атрибуты. Измените права файла на 600 или 644:
ini, в разделе «Главное» нажмите Менеджер файлов. Перейдите в каталог /var/www/php-bin-php(номер-версии-PHP)/. Выберите файл php.ini и нажмите Атрибуты. Измените права файла на 600 или 644:
-
3.Откройте файл php.ini и внесите необходимые изменения. Примеры изменений приведены в раскрывающихся блоках ниже.
-
4.Сохраните изменения и закройте файл.
 org/HowToStep»>
org/HowToStep»>
1.
Войдите в панель управления хостингом.
Обратите внимание! Если внешний вид вашей панели управления отличается от представленного в инструкции, кликните в левом нижнем углу «Старый интерфейс».
 ini, в разделе «Главное» нажмите Менеджер файлов. Перейдите в каталог /var/www/php-bin-php(номер-версии-PHP)/. Выберите файл php.ini и нажмите Атрибуты. Измените права файла на 600 или 644:
ini, в разделе «Главное» нажмите Менеджер файлов. Перейдите в каталог /var/www/php-bin-php(номер-версии-PHP)/. Выберите файл php.ini и нажмите Атрибуты. Измените права файла на 600 или 644:
-
1.
Войдите в панель управления хостингом. -
2.В разделе «Файлы» нажмите Диспетчер файлов.
Перейдите в каталог php-bin/имя-домена. Измените права файла php.ini на 0600 или 0644. Нажмите Save:
-
3.Откройте файл php.ini и внесите необходимые изменения. Примеры изменений приведены в раскрывающихся блоках ниже.
-
4.Сохраните изменения и закройте файл.
 Перейдите в каталог php-bin/имя-домена. Измените права файла php.ini на 0600 или 0644. Нажмите Save:
Перейдите в каталог php-bin/имя-домена. Измените права файла php.ini на 0600 или 0644. Нажмите Save:
-
1.Войдите в панель управления хостингом.
Обратите внимание! Если внешний вид вашей панели управления отличается от представленного в инструкции, перейдите в раздел «Сайты и домены» и в правом верхнем углу измените вид на «Активный».
-
3.Откройте файл php.ini и внесите необходимые изменения. Примеры изменений приведены в раскрывающихся блоках ниже.
-
4.Сохраните изменения и закройте файл.
 org/HowToStep»>
org/HowToStep»>
2.
В разделе «Файлы» перейдите в каталог etc/имя-домена. Измените права файла php.ini: в строке «Владелец» поставьте чекбоксы Чтение и Запись, в строках «Группа» и «Остальные» поставьте чекбокс Чтение. Нажмите Применить:
Готово, изменения вступят в силу в течение минуты.
Примеры изменений настроек PHP
Основные директивы для настройки файла php.ini описаны в статье Настройка файла php.ini.
Как увеличить memory_limit (лимит памяти)
Чтобы предотвратить ситуацию, когда скрипт с плохим синтаксисом занимает всю доступную память сервера, нужно настроить директиву memory_limit. Она задаёт максимально допустимый объём памяти в байтах, который разрешается использовать скрипту. Некоторые CMS и плагины требуют установки определённого значения memory_limit.
Она задаёт максимально допустимый объём памяти в байтах, который разрешается использовать скрипту. Некоторые CMS и плагины требуют установки определённого значения memory_limit.
Пример:
Обратите внимание: на виртуальном хостинге есть технические ограничения на максимальный размер оперативной памяти на один процесс. Ограничения для каждого тарифа приведены на странице Технические характеристики хостинга.
Если данного порога вам не хватает, вы можете:
Как увеличить max_execution_time
Чтобы предотвратить торможение сервера из-за скриптов с плохим синтаксисом, нужно настроить директиву max_execution_time. Она задаёт максимальное время в секундах, в течение которого скрипт должен полностью загрузиться. Если скрипт не загружается, анализатор синтаксиса завершает работу скрипта.
Пример:
Как увеличить upload_max_filesize (максимальный размер закачиваемого файла)
С помощью директивы upload_max_filesize вы можете увеличить максимальный размер закачиваемого файла. На виртуальном хостинге можно загружать файлы размером до 128 МБ.
На виртуальном хостинге можно загружать файлы размером до 128 МБ.
Пример:
upload_max_filesize = 128MЕсли вам требуется загрузить файл размером более 128 МБ:
Как изменить max_input_vars
Директива max_input_vars задаёт количество входных переменных, которое может быть принято в одном запросе. Использование этой директивы снижает вероятность сбоев в случае атак.
Пример:
Подробнее читайте в статье Как исправить ошибку PHP Max Input Vars Limit в WordPress.
Как удалить настройку mbstring.func_overload
При обновлении Bitrix можно столкнуться с проблемой: «Для обновления продукта необходимо удалить настройку PHP mbstring.func_overload. Пожалуйста, внесите необходимые изменения или обратитесь в службу технической поддержки вашего хостинга».
Решить эту проблему можно удалением параметра mbstring.func_overload. Как это сделать читайте в статье Как удалить настройку PHP mbstring. func_overload.
func_overload.
Как исправить ошибку PHP mbstring.internal_encoding
В версиях Bitrix версии 20.100.0 и ниже может возникнуть ошибка, которая связана с неправильными настройками параметров mbstring.func_overload и mbstring.internal_encoding.
Как решить эту проблему читайте в статье Ошибка PHP mbstring.internal_encoding.
Как включить обработку PHP в HTML
На хостинге Linux
В некоторых случаях вид строк может отличаться от указанных в примере. Чтобы корректно добавить строки, мы рекомендуем обратиться в техническую поддержку.
-
1.Перейдите в корневую папку сайта.
Обратите внимание! Если внешний вид вашей панели управления отличается от представленного в инструкции, кликните в левом нижнем углу «Старый интерфейс».
- Если вы храните настройки PHP отдельно для каждого домена по пути /var/www/php-bin/имя-домена/php.ini, добавьте в файл следующие строки:
- Если вы используете общую версию PHP и храните настройки для всех доменов по пути /var/www/php-bin-php(номер-версии-PHP)/, добавьте в файл следующие строки:
 org/HowToStep»>
org/HowToStep»>
2.
Создайте файл с названием .htaccess или откройте его, если файл уже существует.
AddHandler fcgid-script .php .phtml .html .htm
FCGIWrapper /var/www/php-bin/u1234567/domain.ru/php .php
FCGIWrapper /var/www/php-bin/u1234567/domain.ru/php .phtml
FCGIWrapper /var/www/php-bin/u1234567/domain.ru/php .html
FCGIWrapper /var/www/php-bin/u1234567/domain.ru/php .htmГде:
domain.ru — доменное имя вашего сайта;
u1234567 — логин вашего хостинга. Узнать его можно по инструкции.
AddHandler fcgid-script .php .phtml .html . htm
FCGIWrapper /var/www/php-bin-php73/u1234567/php .php
FCGIWrapper /var/www/php-bin-php73/u1234567/php .phtml
FCGIWrapper /var/www/php-bin-php73/u1234567/php .html
FCGIWrapper /var/www/php-bin-php73/u1234567/php .htm htm
FCGIWrapper /var/www/php-bin-php73/u1234567/php .php
FCGIWrapper /var/www/php-bin-php73/u1234567/php .phtml
FCGIWrapper /var/www/php-bin-php73/u1234567/php .html
FCGIWrapper /var/www/php-bin-php73/u1234567/php .htm
htm
FCGIWrapper /var/www/php-bin-php73/u1234567/php .php
FCGIWrapper /var/www/php-bin-php73/u1234567/php .phtml
FCGIWrapper /var/www/php-bin-php73/u1234567/php .html
FCGIWrapper /var/www/php-bin-php73/u1234567/php .htmГде:
php73 — ваша версия PHP. Узнать её можно по инструкции;
u1234567 — логин вашего хостинга. Узнать его можно по инструкции.
-
1.
Перейдите в корневую папку сайта. -
2.Создайте файл с названием .htaccess или откройте его, если файл уже существует. Добавьте в файл следующие строки:
AddHandler fcgid-script .php .phtml .html .htm FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .php FCGIWrapper /var/www/u1234567/php-bin/domain. ru/php .phtml
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .html
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .htmГде:
domain.ru — доменное имя вашего сайта;
u1234567 — логин вашего хостинга. Узнать его можно по инструкции.
 ru/php .phtml
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .html
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .htm
ru/php .phtml
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .html
FCGIWrapper /var/www/u1234567/php-bin/domain.ru/php .htm
-
1.Перейдите в корневую папку сайта.
Обратите внимание! Если внешний вид вашей панели управления отличается от представленного в инструкции, перейдите в раздел «Сайты и домены» и в правом верхнем углу измените вид на «Активный».
-
2.Создайте файл с названием .htaccess или откройте его, если файл уже существует. Добавьте в файл следующие строки:
AddHandler fcgid-script .php .phtml . html .htm
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .php
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .phtml
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .html
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .htmЕсли данное решение не работает, добавьте другие строки:
AddType application/x-httpd-php .php AddHandler php-script .html
 html .htm
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .php
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .phtml
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .html
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .htm
html .htm
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .php
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .phtml
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .html
FCGIWrapper /var/www/cgi-bin/cgi_wrapper/cgi_wrapper .htm
Готово, вы включили обработку PHP в HTML.
На хостинге Windows
Перейдите в корневую папку сайта. Создайте файл с названием web.config или откройте его, если файл уже существует. Добавьте в файл следующие строки:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<system.web>
<identity impersonate="false" />
</system.web>
<system.webServer>
<handlers>
<add name="PHP_via_FastCG1" path="*. htm" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
<add name="PHP_via_FastCG2" path="*.html" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
</handlers>
</system.webServer>
</configuration> htm" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
<add name="PHP_via_FastCG2" path="*.html" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
</handlers>
</system.webServer>
</configuration>
htm" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
<add name="PHP_via_FastCG2" path="*.html" verb="*" modules="FastCgiModule" scriptProcessor="C:\Program Files (x86)\Parallels\Plesk\Additional\PleskPHP53\php-cgi.exe" resourceType="Either" />
</handlers>
</system.webServer>
</configuration>Готово, вы включили обработку PHP в HTML.
Помогла ли вам статья?
176
раз уже помогла
азы для новичков / Блог компании OTUS / Хабр
В преддверии старта нового потока по курсу «Backend-разработчик на PHP», а также смежного с ним курса «Framework Laravel», хотим поделиться статьей, которую подготовил наш внештатный автор.
Внимание! данная статья не имеет отношения к программе курса и будет полезна только для новичков. Для получения более углубленных знаний приглашаем вас посетить бесплатный двухдневный онлайн интенсив по теме: «Создание Telegram-бота для заказа кофе в заведении и оплаты онлайн». Второй день интенсива будет проходить тут.
Для получения более углубленных знаний приглашаем вас посетить бесплатный двухдневный онлайн интенсив по теме: «Создание Telegram-бота для заказа кофе в заведении и оплаты онлайн». Второй день интенсива будет проходить тут.
Всем привет! Всех с наступившим [20]{2,}0 годом. Сегодня я хочу затронуть тему, которая иногда является темой для шуток от «Да зачем тебе все это учить, если есть уже есть готовые решения» до «может тебе еще и весь Perl выучить?». Однако время идет, множество программистов начинают осваивать регулярные выражения, а на Хабре нет ни одной свежей (хоть регулярные выражения не слишком изменились за последнее время) статьи на этой тематику. Пришло время написать ещё одну!
Регулярные выражения в отрыве от их конкретной реализации
Регулярные выражения (обозначаемые в английском как RegEx или как regex) являются инструментальным средством, которое применяется для различных вариантов изучения и обработки текста: поиска, проверки, поиска и замены того или иного элемента, состоящего из букв или цифр (или любых других символов, в том числе специальных символов и символов пунктуации). Изначально регулярные выражения пришли в мир программирования из среды научных исследований, которые проводились в 50-е годы в области математики.
Изначально регулярные выражения пришли в мир программирования из среды научных исследований, которые проводились в 50-е годы в области математики.
Спустя десятилетия принципы и идеи были перенесены в среду операционной системы UNIX (в частности вошли в утилиту grep) и были реализованы в языке программирования Perl, который на заре интернета широко использовался на бэкенде (и по сей день используется, но уже меньше) для такой задачи, как, например, валидация форм.
Если они вроде простые, тогда почему такие страшные на первый взгляд?
На самом деле любое выражение может быть «регулярным» и применяться для проверки или поиска каких-либо символов. Например, слова Pavel или [email protected] тоже могут использоваться как регулярки, только, понятное дело, в довольно узком ключе. Для проверки работы регулярных выражений в среде PHP без запуска своего сервера или хостинга вы можете воспользоваться следующим онлайн сервисом (вот только на нем у меня не работала обработка русских символов). Для начала в качестве регулярного выражения мы используем просто Pavel.
Для начала в качестве регулярного выражения мы используем просто Pavel.
Положим у нас есть следующий текст:
Pavel knows too much. Pavel using nginx and he’s not rambler.
Сейчас регулярные выражения нашли оба вхождения слова Pavel. Здорово, но звучит не очень полезно (разве что только вы зачем-то пытаетесь проанализировать что-то вроде количества упоминания слова сударь в Войне и Мире через Vim и Python, но тогда у меня к вам вопросов нет).
Вариативность выражения
Если ваше регулярное выражение вариативно (например, вам известна только некоторая его часть и нужно найти количество вхождений годов, начиная от 2000 и заканчивая 2099), то мы можем использовать следующее регулярное выражение: 20..
Текст: Молодые писатели пишут много чего. Например писатель 2002 года рождения очень отличается от 2008 и 2012
Здесь у нас с помощью регулярного выражения найдутся все годы, но пока в этом нет никакого смысла. Скорее всего нам не нужны годы дальше 2012 (хотя молодые писатели младше 8 лет могут обидеться, но не об этом сейчас). Стоит изучить наборы символов, но об этом попозже, потому как сейчас поговорим про другую важную часть регулярных выражений: экранирование метасимволов.
Скорее всего нам не нужны годы дальше 2012 (хотя молодые писатели младше 8 лет могут обидеться, но не об этом сейчас). Стоит изучить наборы символов, но об этом попозже, потому как сейчас поговорим про другую важную часть регулярных выражений: экранирование метасимволов.
Представим, что нам нужно найти количество вхождений файлов с расширением .doc (допустим, мы экспортируем только определенные файлы загруженные в нашу базу данных). Но ведь точка обозначает просто любой символ? Так как же быть?
Тут к нам на помощь приходит экранирование метасимволов обратным слешем \. Теперь выражение \.doc будет достаточно успешно искать любой текстовое упоминание с расширением .doc:
Регулярное выражение: \.doc
Текст: kursach.doc , nepodozritelneyfail.exe, work.doc, shaprgalka.rtf doc
Как видите, мы успешно можем найти количество файлов с расширением .doc в списке. 0-9]\.jpg
0-9]\.jpg
Текст: 1.jpg, 2.jpg, 3.jpg, photo.jpg , anime.jpg , 8.jpg, jkl.jpg
Но без множественного выбора это конечно неполноценные выражения.
Полезные таблицы
Приведем таблицу метасимволов:
Таблица пробельных метасимволов
Множественный выбор: делаем простую валидацию
Вооружившись полученными знаниями, попробуем сделать регулярное выражение, которое находит, например, слова короче 3 букв (стандартная задача для антиспама). Если мы попробуем использовать следующее регулярное выражение — \w{1,3} (в котором метасимвол \w указывает на любой символ, а фигурные скобки обозначают количество символов от сколько до скольки, то у нас выделятся все символы подряд — нужно как-то обозначить начало и конец слов в тексте. Для этого нам потребуется метасимвол \b.
Регулярное выражение: \b\w{1,3}\b:
Текст: good word
not
egg
Неплохо! Теперь слова короче трех букв не смогут попадать в нашу базу данных. Посмотрим на валидацию почтового адреса:
Посмотрим на валидацию почтового адреса:
Регулярное выражение: \w+@\w+\.\w+
Требования: в электронной почте в начале должен быть любой символ (цифры или буквы, ведь электронная почта, которая состоит только из цифр в начале, встречается довольно часто). Потом идет символ @, затем — сколько угодно символов, после чего экранированная точка (т.е. просто точка) и домен первого уровня.
Подробнее рассмотрим повторение символов
Теперь давайте поподробнее разберем, как можно в регулярных выражениях задать повторение символов. К примеру вы хотите найти любые комбинации цифр от 2-6 в тексте:
Регулярное выражение: [2-6]+
Текст: Here are come’s 89 different 234 digits 24 .
Давайте я приведу таблицу всех квантификаторов метасимволов:
В применении квантификаторов нет ничего сложного. Кроме одного нюанса: жадные и ленивые квантификаторы. Приведем таблицу:
Ленивые квантификаторы отличаются от жадных тем, что они выхватывают минимальное, а не максимальное количество символов. Представим, что есть у нас задача найти все теги заголовков h2-h6 и их контент, а весь остальной текст не должен быть затронут (я умышленно ввел несуществующий тэг h7, чтобы не мучаться с экранированием хабровских тэгов):
Представим, что есть у нас задача найти все теги заголовков h2-h6 и их контент, а весь остальной текст не должен быть затронут (я умышленно ввел несуществующий тэг h7, чтобы не мучаться с экранированием хабровских тэгов):
Регулярное выражение: <h[1-7]>.*?<\/h[1-7]>
Текст: <h7> hello </h7> lorem ipsum avada kedavra <h7> buy</h7>
Все сработало успешно, однако только благодаря ленивому квантификатору. В случае применения жадного квантификатора у нас выделился бы весь текст между тегами (полагаю, в иллюстрации это не нуждается).
Границы символьных строк
Границы символьных строк мы уже использовали выше. Приведем здесь более подробную таблицу:
Работа с подвыражениями
Подвыражения в регулярных выражениях делаются с помощью метасимвола группировки ().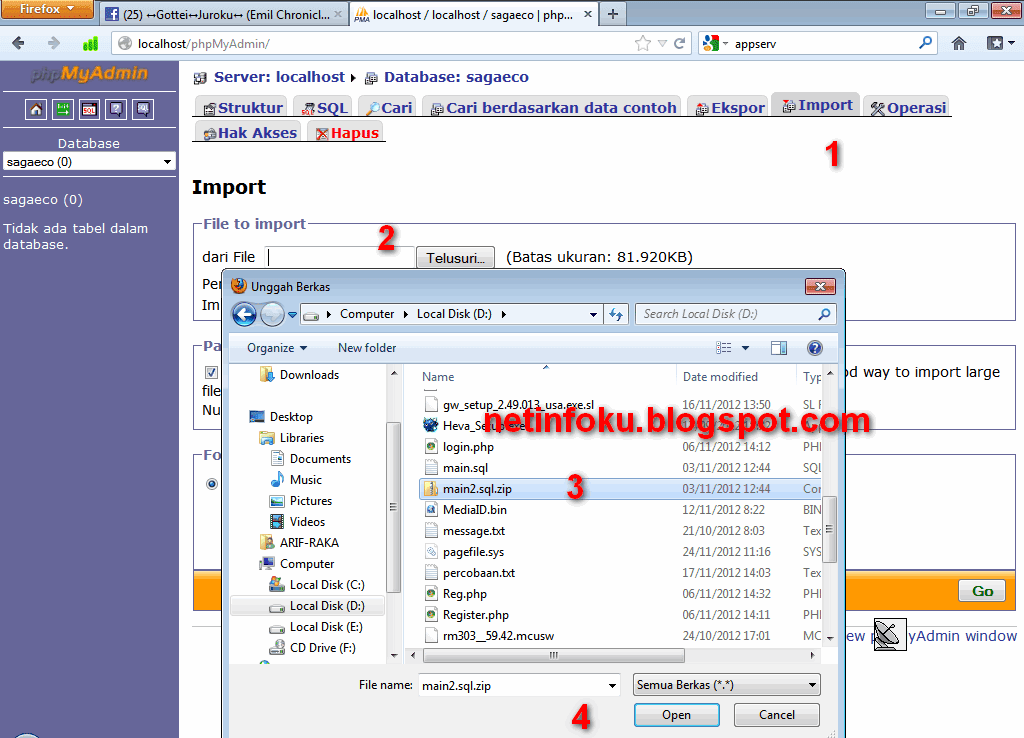
Приведем пример регулярного выражения, которое универсально может находить различные вариации IP — адресов.
Регулярное выражение: (((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2}))\.){3}(((25[0-5]|(2[0-4]\d)|(1\d{2})|(\d{1,2}))))
Текст: 255.255.255.255 просто адрес
191.198.174.192 wikipedia
87.240.190.67 vk
31.13.72.36 facebook
Здесь используется логический оператор | (или), который позволяет нам составить регулярное выражение, которое соответствует правилу, по которому составляются IP- адреса. В IP адресе должно быть от 1 и до 3 цифр, в котором число из трех чисел может начинаться с 1, с 2 (или тогда вторая цифра должна быть в пределах от 0 и до 4), или начинаться с 25, и тогда 3 цифра оказывается в пределах от 0 и до 5. Также между каждой комбинацией цифр должна стоять точка. Используя приведенные выше таблицы, постарайтесь сами расшифровать регулярное выражение сверху. Регулярные выражения в начале пугают своей длинной, но длинные не значит сложные. (?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
Текст: Qwerty123
Im789098
weakpassword
Особенности работы регулярных выражений именно в PHP
Для изучения работы регулярных выражений в PHP, изучите функции в официальной документации PCRE (Perl Compatible Regular Expressions) которая доступна на официальном сайте. Выражение должно быть заключено в разделители, например, в прямые слеши.
Разделителем могут выступать произвольные символы, кроме буквенно-цифровых, обратного слеша ‘\’ и нулевого байта. Если символ разделителя встречается в шаблоне, его необходимо экранировать \. В качестве разделителей доступны комбинации, пришедшие из Perl: (), {}, [].
Какие функции используются в php? В пакете PCRE предоставляются следующие функции для поддержки регулярных выражений:
- preg_grep() — выполняет поиск и возвращает массив совпадений.
- preg_match() — выполняет поиск первого совпадения с помощью регулярных выражений
- preg_match_all() — выполняет глобальный поиск с помощью регулярных выражений
- preg_quote() — принимает шаблон и возвращает его экранированную версию
- preg_replace() — выполняет операцию поиска и замены
- preg_replace_callback() — тоже выполняет операцию поиска и замены, но используют callback – функцию для любой конкретной замены
- preg_split() — разбивает символьную строку на подстроки
Для организации совпадения без учета регистра букв служит модификатор i.
С помощью модификатора m можно активировать режим обработки многострочного текста.
Замещающие строки допускается вычислять в виде кода PHP. Для активизации данного режима служит модификатор e.
Во всех функциях preg_replace(), preg_replace_callback() и preg_split() поддерживается дополнительный аргумент, который вводит ограничения на максимальное количество замен или разбиений.
Обратные ссылки могут обозначаться с помощью знака $ (например $1), а в более ранних версиях вместо знака $ применяются знаки \\.
Метасимволы \E, \l, \L, \u и \U не используются (поэтому они и не были упомянуты в этой статье).
Наша статья была бы неполной без классов символов POSIX, которые также работают в PHP (и в общем вполне могут повысить читабельность ваших регулярок, но не все их спешат учить, потому как часто ломают логику выражения).
Под конец приведу пример конкретной реализации регулярных выражений в PHP, используя упомянутые выше реализации. (?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
if (preg_match($pattern_name, $name) &&
preg_match($pattern_mail, $mail) &&
preg_match($pattern_password, $_POST[‘password’])) {
# тут происходит, к примеру, регистрация нового пользователя, отправка ему письма, и внесение в базу данных
}
Всем спасибо за внимание! Конечно, сегодня мы затронули только часть регулярных выражений и о них можно написать ещё несколько статей. К примеру, мы не поговорили о реализации поиска повторений одинаковых слов в тексте. Но я надеюсь, что полученных знаний хватит, чтобы осмысленно написать свою первую валидацию формы и уже потом перейти к более зубодробительным вещам.
По традиции, несколько полезных ссылок:
Шпаргалка от MIT по регулярным выражениям
Официальная часть документации php по регулярным выражениям.
На этом все. До встречи на интенсиве!
Второй день интенсива пройдет тут
Регулярные выражения — PHP с нуля
Регулярные выражения — это специальные шаблоны для поиска
подстроки в тексте. С их помощью можно решить одной строчкой
С их помощью можно решить одной строчкой
такие задачи: «проверить, содержит ли строка цифры»,
«найти в тексте все адреса email»,
«заменить несколько идущих подряд знаков вопроса на один».
Начнем с одной народной программистской мудрости:
Некоторые люди, сталкиваясь с проблемой, думают:
«Ага, я умный, я решу её с помощью регулярных выражений». Теперь у них две проблемы.
Это довольно-таки объемный и сложный урок. Но, если ты дошел до сюда, то ты способен
осилить и это. Просто почти теорию, не надо запоминать, а когда дойдешь до задачек, вернись
и проясни непонятные моменты. Ну или открой мануал — там эта тема подробно разъясняется. Ссылка:
http://www.php.net/manual/ru/reference.pcre.pattern.syntax.php
Примеры шаблонов
Начнем с пары простых примеров. Первое выражение на картинке ниже ищет
последовательность из 3 букв, где первая буква это «к», вторая — любая русская буква и
третья — это «т» без учета регистра (например, «кот» или «КОТ» подходит
под этот шаблон). Второе выражение ищет в тексте время в формате
Второе выражение ищет в тексте время в формате 12:34.
Любое выражение начинается с символа-ограничителя (delimiter по англ.). В качестве
него обычно используют символ /, но можно использовать и другие
символы, не имеющие специального назначения в регулярках, например, ~,
# или @. Альтернативные разделители используют, если в
выражении может встречаться символ /. Затем идет сам шаблон строки,
которую мы ищем, за
ним второй ограничитель и в конце может идти одна или несколько букв-флагов. Они
задают дополнительные опции при поиске текста. Вот примеры флагов:
i— говорит, что поиск должен вестись без учета
регистра букв (по умолчанию регистр учитывается)u— говорит, что выражение и текст, по которому идет поиск,
исплоьзуют кодировку utf-8, а не только латинские буквы. Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
 Без него поиск
Без него поиск
Сам шаблон состоит из обычных символов и специальных конструкций. Ну
например, буква «к» в регулярках обозначает саму себя, а вот символы [0-5]
значат «в этом месте может быть любая цифра от 0 до 5». Вот полный список
специальных символов (в мануале php их называют метасимволы),
а все остальные символы в регулярке — обычные:
Ниже мы разберем значение каждого из этих символов (а также объясним почему буква
«ё» вынесена отдельно в первом выражении), а пока попробуем
применить наши регулярки к тексту и посмотреть, что выйдет. В php есть
специальная функция preg_match($regexp, $text, $match),
которая принимает на вход регулярку, текст и пустой массив. Она проверяет,
есть ли в тексте подстрока, соответствующая данному шаблону и возвращает
0, если нет,
или 1, если она есть. А в переданный массив в элемент с индексом
А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
| Код | Результат |
|---|---|
| Строка: рыжий кот + Найдено слово 'кот' Строка: рыжий крот - Ничего не найдено Строка: кит и кот + Найдено слово 'кит' |
Познакомившись с примером, изучим регулярные выражения более подробно. a-c] значит «один любой символ,
a-c] значит «один любой символ,
кроме a, b или c».
выражении
abc+ знак «плюс» относится только
к букве c и это выражение ищет слова вроде abc, abcc, abccc. А если
поставить скобки
a(bc)+ то квантифиактор плюс относится
уже к последовательности
bc и выражение ищет слова
abc, abcbc, abcbcbc
Примечание: в квадратных скобках можно указывать диапазоны
символов, но помни, что русская буква ё идет отдельно от
алфавита и чтобы написать «любая русская буква»,
надо писать [а-яё].
Бекслеши
Если ты смотрел другие учебники по регулярным выражениям, то наверно заметил,
что бекслеш везде пишут по-разному. Где-то пишут один бекслеш:
\d, а здесь в примерах он повторен 2 раза: \\d.
Почему?
Язык регулярных выражений требует писать бекслеш один раз. Однако в
строках в одиночных и двойных кавычках в PHP бекслеш тоже имеет особое
значение: мануал про строки.
Ну например, если написать $x = "\$"; то PHP воспримет это как
специальную комбинацию и вставит в строку только символ $
(и движок регулярных выражений не узнает о бекслеше перед ним). Чтобы
вставить в строку последовательность \$, мы должны удвоить бекслеш
и записать код в виде $x = "\\$";.
По этой причине в некоторых случаях (там, где последовательность символов
имеет специальный смысл в PHP) мы обязаны удваивать бекслеш:
- Чтобы написать в регулярке
\$, мы пишем в коде"\\$" - Чтобы написать в регулярке
\\, мы удваиваем каждый
бекслеш и пишем"\\\\" - Чтобы написать в регулярке бекслеш и цифру (
\1),
бекслеш надо удвоить:"\\1"
В остальных случаях один или два бекслеша дадут один и тот же
результат: "\\d" и "\d" вставят в строку пару
символов \d — в первом случае 2 бекслеша это последовательность
для вставки бекслеша, во втором случае специальной последовательности
нет и символы вставятся как есть. Проверить, какие символы вставятся в строку,
Проверить, какие символы вставятся в строку,
и что увидит движок регулярных выражений, можно с помощью
echo: echo "\$";. Да, сложно, а что поделать?
Специальные конструкции в регулярках
\dищет одну любую цифру,\D— один
любой символ, кроме цифры\wсоответствует одной любой букве (любого алфавита), цифре
или знаку подчеркивания_.\Wсоответствует
любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: \b.
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (\w), а с
другой стороны — не являющийся. Ну, например, мы хотим найти в тексте слово
«кот». Если мы напишем регулярку /кот/ui, то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: /\bкот\b/ui, то теперь
искаться будет только отдельно стоящее слово «кот».
Мануал
Также, есть полезный сайт
Regex101, где
можно протестировать свою регулярку и проверить, что она найдет в тексте. Помни,
что на том сайте бекслеши надо писать ровно один раз, и
ставить флаг u не требуется.
Задачка
Напиши программу, получающую на вход автомобильный номер, и проверяющую,
правильно ли он введен. Автомобильный номер имеет вид «а123вг»,
то есть начинается с буквы, за которой идет 3 цифры, и еще 2 буквы. Никаких
посторонних символов быть в нем не должно.
Эту программу надо решить с помощью preg_match() и регулярного
выражения. Протестировать его ты можешь например на сайте Regex101.
Задачка на проверку телефонов
Дан текст, который по идее должен быть номером телефона в виде 8-(911)-506 56 56
(т.е. человек может ввести не только цифры, но и скобки, минусы, может что-то еще).
Но в реальности, пользователь может вместо номера написать что угодно. Напиши скрипт для
проверки правильности введенного номера («8(911)-506 56 56» — правильный
номер, «8-911-50-656-56» — правильный, «89115065656» — правильный, «02» — неправильный,
«89115065656 позвать Люду» — неправильный).
Задачу надо проверить на большом числе телефонов,
чтобы убедиться что твой код правильный. Для этого давай добавим в программу
тесты, чтобы сразу было видно, верно все работает или нет.
Сделай 2 списка номеров (правильные и нет), добавь их в программу и напиши цикл,
который их по очереди прогоняет через регулярку и проверяет,
что они определяются как надо (если нет — надо вывести, какой именно номер
не распознается правильно).
Вот список номеров:
// Правильные: $correctNumbers = [ '84951234567', '+74951234567', '8-495-1-234-567', ' 8 (8122) 56-56-56', '8-911-1234567', '8 (911) 12 345 67', '8-911 12 345 67', '8 (911) - 123 - 45 - 67', '+ 7 999 123 4567', '8 ( 999 ) 1234567', '8 999 123 4567' ]; // Неправильные: $incorrectNumbers = [ '02', '84951234567 позвать люсю', '849512345', '849512345678', '8 (409) 123-123-123', '7900123467', '5005005001', '8888-8888-88', '84951a234567', '8495123456a', '+1 234 5678901', /* неверный код страны */ '+8 234 5678901', /* либо 8 либо +7 */ '7 234 5678901' /* нет + */ ];
Также, на regex101
https://regex101.com/r/qF7vT8/3 уже введены номера и можно простестировать
свою регулярку. Помни что на этом сайте надо писать бекслеш один раз,
например \s, а не \\s. Флаг m там стоит чтобы
^ и $ в регулярке обозначали «начало и конец
любой строки», а не «начало и конец всего текста». Флаг g (его нет в PHP,
Флаг g (его нет в PHP,
он только на этом сайте) значит что надо искать все совпадения с
регуляркой, а не только первое.
Подсказка: не надо строить сложных выражений и предусматривать все
возможные комбинации символов. Достаточно написать:
сначала идет +7 или 8, за ними ровно 10 цифр, между которыми может быть
любое число скобок, минусов, пробелов
Повторим
- preg_match находит первое совпадение с
регулярными выражением и проверяет, соответствует ли текст или часть выражению - preg_match_all находит все фрагменты текста,
соответствующие регулярке - preg_split разбивает текст на массив частей
по регулярному выражению - preg_replace заменяет в тексте части, соответствующие
регулярке, на данную строку
Задачки (пока без картинок)
- На вход скрипта дан введенный пользователем номер телефона в
виде 8-911-404-44-11 или +7(812)6786767 (в начале 8 или +7, потом идут 10 цифр и, возможно, какие-то символы).
То есть, как и в прошлой задаче, человек вводит номер как хочет.
Надо проверить номер на правильность и привести любой номер к единому формату 89114044411
(то есть, заменить +7 на 8 и выкинуть весь мусор вроде пробелов, скобок и минусов, кроме цифр) - Автозамена. Напиши скрипт, заменяющий определенное слово на другое (например, слово
«дурак» на «хороший человек» в фразе «ты дурак»). Скрипт должен не пропускать слово,
если оно написано буквами в разном регистре (ДуРАк), с заменой русских букв
на похожие английские (а -> a), или через пробелы («ты — д у р а к») - Дан текст, содержащий в себе email’ы (адреса почты вроде [email protected] ). Напиши
скрипт, выводящий все email, встречающиеся в этом тексте - «Grammar Nazi». Напиши скрипт, проверяющий текст на наличие злостных ошибок:
- нет пробела после запятой, точки с запятой, восклицательного знака,
вопросительного знака, двоеточия - «жи» или «ши» написано с буквой ы
- в тексте есть слово «координально» или «сдесь», «зделал», «зделаю», «зделан»
- в тексте есть слова «а» или «но» без запятой перед ними.
- (можешь добавить еще несколько правил, если хорошо знаешь русский язык)
В случае обнаружения ошибки скрипт должен писать сообщение об этом и выводить
кусок текста с ошибкой (чтобы было понятно, что не так). - нет пробела после запятой, точки с запятой, восклицательного знака,
- Если ты сделал задачу про Grammar Nazi, сделай скрипт, которы вместо сообщения об ошибках будет
молча их исправлять.


Опечаточники
Как тебе наверно известно, многие люди, занимающие государственные посты, тратят свои силы
отнюдь не на улучшение ситуации в своем городе или регионе, а на придумывание разнообразных
схем по перемещению вверенных им бюджетных средств в свои карманы.
Например, государственные органы, которые хотят провести закупки, обязаны организовать публичные торги и
разместить объявление о них на сайте госзакупок. Чтобы помешать всем желающим участвовать в тендере
(и чтобы отдать заказ «своим людям» и получить потом от них в свой карман часть денег), они заменяют в
описании заказа некоторые русские буквы на похожие на них латинские. Таким образом, не предупрежденные
Таким образом, не предупрежденные
заранее организации не смогут найти объявление через поиск и принять участие в конкурсе.
Давай попробуем применить наши знания языка PHP для того, чтобы вывести жуликов на чистую воду.
Задача: дан текст, содержащий слова на русском и английском языках. В некоторых словах часть русских букв
заменена на похожие на них латинские, и наоборот. Напиши программу, которая находит все такие слова,
выводит их и выделяет квадратными скобками первую замененную букву.
Для проверки работоспособности, попробуй применить программу к тексту из поля «Наименование заказа» на
странице (осторожно, спойлер!)
http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5193640
или http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5138013
ололо кто бы поверил!
Дополнительная задача: добавь в программу автоматическое исправление найденных «опечаток».
Подсказки для глупеньких: слова с опечатками найти легко: это слово, которое
начинается с одной или нескольких русских букв, за которыми идет латинская. Ну или начинается с латинской,
за которой идет русская. Достаточно минимальных знаний регулярных выражений, чтобы написать решение.
P.S. На сайте программистских комиксов xkcd есть комикс про регулярные выражения:
перевод, оригинал (англ.).
дальше:
Повторим? →
——
Куда вводить код? Что надо скачать? Читай первый урок.
Есть вопросы? Задай гуглу или автору.
Нравится урок? Лайкай, репости, приглашай друзей, пости котов и Канако,
шли добра, решай задачи, помогай новичкам! Кнопок для лайка нет, кто хочет зарепостить, всегда может сделать это ручками.
Как связаться с автором? Я хочу переодеть его в платье
школьницы и жениться на нем. Ящик codedokode (кот) gmail.com ждет ваших писем. А
Ящик codedokode (кот) gmail.com ждет ваших писем. А
вконтактик и
фейсбучек ждут ваших лайков.
Но ответ на банальные вопросы лучше искать в Гугле или на stackoverflow.
Я решил задачку!!! Молодец, делай следующий урок
Ideone не работает!11 Ну так открой Гугл и найди сайты
вроде https://repl.it/languages/php , http://phptester.net/ ,
http://sandbox.onlinephpfunctions.com/ ,
http://codepad.org/ или http://www.runphponline.com/ . Не ленись.
Почему так много рекламы? Всю рекламу
на сайте ставит юкоз (бесплатный хостинг же), а не я.
На сайте установлена система Google Analytics (и еще несколько аналогичных систем от юкоза). Данные о твоем IP-адресе, посещаемых страницах,
времени посещения отправляются в Google Corporation, США. Хочу знать, кто и зачем сюда заходит. Поверь,
Поверь,
другие сайты делают точно так же. Все сайты пишут логи.
Логирование ошибок PHP на хостинге reg.ru
Недавно начал переносить свои проекты с sweb.ru, хостинга, которым пользовался много лет, но который начал портиться в последнее время. Большинство проектов переношу на reg.ru, который мне больше нравится, как по ограничениям в нагрузке, так и по техническим ограничениям, накладываемым на сервер и php.
Перенеся несколько проектов решил проверить, как отрабатывает php и каким образом регистрируются его ошибки (стараюсь следить за логами ошибок, иногда в них что-нибудь да вылезает). Однако на reg.ru привычный для меня error_log отсутствовал, что побудило разобраться с этим неудобством.
В ходе изучения панели (я предпочитаю cPanel) было найден только Журнал ошибок, куда логировались ошибки сервера, но никак не php. Использование справки хостинга так же не дало результатов. В итоге было найдено следующее решение, которое потом было подтверждено поддержкой хостинга.
Итак, решение логирования ошибок php на reg.ru делается через внесение изменений в php.ini, который находится в папке php-bin и доступен для редактирования. В данный файл надо добавить следующие инструкции:
display_startup_errors off
display_errors off
html_errors off
log_errors = on
error_log = "/путь к файлу/php_error.log"Тут необходимо учитывать несколько моментов. Во-первых, использование инструкций display_startup_errors off, display_errors off, html_errors off не гарантируют вам полный запрет вывода ошибок, так как данные инструкции могут быть переопределены непосредственно в php скрипте. Во-вторых, данное решение не предполагает ротирование логов, поэтому если в них сыпется много ошибок, то надо следить за их размерами. В-третьих, если вы держите файл с ошибками в доступном для доступа извне месте (например, корне сайта), то желательно запретить обращение к данному файлу в .htaccess.
<Files php_errors.log>
Order allow,deny
Deny from all
Satisfy All
</Files>В ближайшее время поищу более элегантное решение, но пока и этого достаточно 🙂
Просмотров: 4556
Комментариев:
« Использование шрифтов для иконокНастройка TinyMCE »
Php ini reg ru — Знай свой компьютер
Данная инструкция подходит только для Hosting Linux. Возможность смены тех или иных параметров PHP на хостинге Windows вы можете уточнить в службе техподдержки.
Как установить PHP на хостинг?
Поддержка PHP предоставляется на всех тарифных планах услуг хостинга Linux, кроме Host-Lite. Вы можете попробовать 14 дней тестового периода бесплатного хостинга для сайтов HTML с поддержкой PHP и MySQL. Мы регулярно обновляет и добавляем новые версии PHP. Выбрать нужную версию и изменить параметры вы можете по инструкции ниже.
Как изменить параметры PHP?
Для каждой версии PHP можно установить свои параметры. Чтобы внести изменения в хостинг-панели:
Перейдите в «Менеджер файлов», затем в каталог php-bin-php(версия_php)/ и измените права для файла php.ini на 600 или 644 (rw-r–r–):
Откройте «Диспетчер файлов» и перейдите в каталог php-bin/ваш-домен. Измените права файла php.ini на 600 или 644 (rw-r–r–):
Перейдите в раздел «Файлы», затем в каталог etc/ваш_домен и измените права для файла php.ini на 600 или 644 (rw-r–r–):
Откройте файл php.ini и внесите необходимые изменения:
Готово. Изменения вступят в силу в течение минуты.
Директива max_execution_time задаёт максимальное время в секундах, в течение которого скрипт должен полностью загрузиться. Если этого не происходит, анализатор завершает его работу.
На виртуальном хостинге
- чаще всего лог phpmail включают для определения источника рассылки спама;
- данная инструкция применима только к hosting linux;
- mail.log работает только на версии PHP 5.3 и выше.
Для активации лога необходимо в файл php.ini вставить следующие строки:
Путь до каталога хостинга имеет вид:
- ISPmanager: /var/www/u1234567/data/
- ParallelsPlesk: /var/www/vhosts/u1234567.plsk.regruhosting.ru/
- cPanel: /var/www/u1234567/
Где u1234567 — ваш логин хостинга.
Готово! Вы включили логирование сообщений.
На VPS
в папке сайта создайте файл info.php и запишите в него следующие строки:
перейдите по адресу ваш_сайт/info.php
вы можете добавить логирование почты только для конкретного сайта или для всех сайтов на сервере.
- чтобы добавить настройки для одного сайта, необходимо внести записи в файл, путь к которому указан в «Loaded Configuration File», в нашем примере это /var/www/php-bin/user_name/php.ini
- чтобы добавить настройки для всех сайтов на сервере, необходимо внести записи в файл php.ini, путь к которому указан в строке «Configuration File (php.ini) Path». В нашем примере путь до общего файла php.ini выглядит так: /opt/php/5.3/etc/php.ini
для логирования сообщений добавьте ниже следующий код в конец файла php.ini.
/var/tmp/php.mail.log — это файл, в который будет записываться лог отправки сообщений посредством php mail. Права на данный файл должны разрешать запись в него. Вы можете дать права на запись через панель ISPmanager, или через SSH, при помощи команды:
перезапустите сервер Apache, для этого выполните команду:
- CentOS: service httpd restart ;
- Debian, Ubuntu: service apache2 restart .
Поддержка PHP присутствует на всех тарифных планах Hosting Linux и Hosting Windows, кроме тарифов «Host-Lite» и «Win-Lite». Если у вас заказан «Host-Lite» или «Win-Lite», пункт PHP в панели управления будет отсутствовать. Чтобы включить поддержку PHP, повысьте тарифный план.
Как сменить версию PHP?
Ознакомиться со списком доступных модулей для каждой версии PHP можно по ссылке. Если у вас заказан сервер VPS, смена версии PHP происходит по инструкции: Как сменить версию PHP на VPS?
Сборка PHP для Bitrix: в хостинг-панели ISPmanager и CPanel доступны оптимизированные сборки PHP. Для работы CMS Bitrix мы рекомендуем использовать именно их: 5.3-bx-optimized– 7.2-bx-optimized.
Чтобы сменить версию PHP:
Откройте панель управления и следуйте дальнейшей инструкции:
В разделе WWW выберите пункт «WWW-домены». На открывшейся странице из списка выберите домен, для которого хотите сменить версию PHP, и нажмите Изменить. В разделе Дополнительные возможности выберите нужную версию PHP и подтвердите изменения:
В панели ISPmanager можно выбрать индивидуальную версию PHP для домена и индивидуальный файл php.ini для каждой версии сборки PHP.
- Версия PHP автоподдомена зависит от версии PHP родительского домена.
- Версия PHP поддомена, добавленного как самостоятельный домен, НЕ зависит от версии PHP родительского домена.
В разделе Программное обеспечение выберите пункт Выбор версии PHP. На открывшейся странице из списка выберите домен, для которого хотите сменить версию PHP, и нажмите Изменить. Затем выберите нужную версию PHP и подтвердите изменения:
В cPanel можно выбрать индивидуальную версию PHP для домена и индивидуальный файл php.ini для каждой версии сборки PHP.
Версия PHP субдоменов НЕ зависит от версии PHP родительского домена.
Во вкладке Сайты и домены выберите пункт Настройки PHP. На открывшейся странице в выпадающем списке выберите нужную версию PHP и нажмите Применить:
В Plesk можно выбрать индивидуальную версию PHP для домена и индивидуальный файл php.ini для каждой версии сборки PHP.
Версия PHP субдоменов НЕ зависит от версии PHP родительского домена.
Как выбрать версию PHP при работе в командной строке (SSH)
При работе в консоли используйте следующие пути до обработчиков PHP для запуска скриптов под различными версиями:
Как узнать параметры PHP на хостинге?
Перед заказом услуги хостинга вы можете ознакомиться c параметрами PHP и подключенными модулями на странице.
На хостинге REG.RU PHP работает в режиме Fast CGI (mod_fcgi).
Если у вас уже есть услуга хостинга
Чтобы узнать подробные настройки PHP, выполните следующие действия:
Откройте корневую директорию вашего сайта и создайте файл info.php со следующим содержимым:
Проверка параметров php в командной строке
Обратите внимание: проверка версии php в командной строке при помощи команды php -v не корректна. Данная команда отображает системную сборку php, а не пользовательскую.
Подробнее о том, как работать с php в консоли, читайте в статье: Работа с PHP-скриптами в командной строке.
Как включить поддержку PHP?
Поддержка PHP присутствует на всех тарифных планах хостинга REG.RU, кроме тарифов «Host-Lite» и «Win-Lite». Если у вас заказан «Host-Lite» или «Win-Lite», пункт PHP в панели управления будет отсутствовать. Чтобы включить поддержку PHP, повысьте тарифный план.
Если на вашей услуге хостинга установлена панель управления ISPmanager, убедитесь, что поддержка PHP включена в настройках WWW-домена. Для этого перейдите в раздел WWW-домены, два раза кликните по имени вашего домена. Найдите на открывшейся странице категорию Дополнительные возможности и в пункте Режим работы PHP выберите FastCGI (Apache). Затем сохраните изменения, нажав кнопку Ok.
Установка ionCube PHP Loader на хостинг
Внимание! Модуль ionCube PHP Loader установлен только на виртуальном хостинге Linux.
Модуль ionCube PHP Loader установить на хостинг можно не во всех случаях. По умолчанию он присутствует на всех версиях PHP виртуального хостинга Linux, кроме сборок для 1C-Битрикс. Это такие сборки PHP:
То есть на всех сборках, в названии который присутствует «-bx-», модуля ionCube Loader нет и он не может быть там установлен. Причина в том, что данный модуль существенно снижает производительность работы 1C-Битрикс.
Что делать, если на одном хостинге 1C-Битрикс и другая CMS, требующая ionCube Loader. Как установить на хостинг?
Вы можете установить разные версии PHP для каждого домена (обычную для CMS и «-bx-» для Битрикс). Изменить версию PHP вы можете по инструкции.
У меня VPS, и на нём нет поддержки ionCube Loader
Попробуйте переключить версию PHP на другую и проверить наличие модуля: Как сменить версию PHP на VPS?
Если смена версии не помогла, рекомендуем установить ionCube Loader по следующей инструкции: Установка ionCube на VPS.
Не обрабатываются PHP-скрипты
Ваш тариф хостинга — Host-Lite
На тарифе хостинга «Host-Lite» не предусмотрена поддержка PHP. Узнать тариф хостинга можно на странице со списком ваших услуг. Для решения проблемы мы рекомендуем повысить тарифный план до «Host-0» или выше: Как повысить тарифный план хостинга.
Не обрабатывается PHP в html
Не обрабатывается PHP в файлах с расширением .html. В этом случае выполните рекомендации справки: Как включить обработку PHP в HTML.
Отключена поддержка PHP в ISPmanager
Если вы пользуетесь панелью управления ISPmanager проверьте, что в настройках «WWW домена» включена поддержка PHP. Для этого откройте панель управления, перейдите в раздел WWW домены и два раза кликните по имени необходимого домена.
- ISPmanager 5 в выпадающей строке «Режим работы PHP» должен быть выбран пункт FastCGI (Apache):
Установка CRON задания на хостинге REG.RU [Документация AMX MONITORING]
1. Покупаем хостинг на сайте reg.ru
Я выбирал тариф Host-1 ( дешевые не пробывал типа Host-Lite, но не уверен что он там будет работать)
Добавляем домен и т.д… Думаю разберетесь
2. Узнаем правильную команду для CRON
Пишем в техническую поддержку reg.ru (думаю найдете где писать)
Примерно следующее содержание:
Здравствуйте. Можете дать правильную CRON команду для планировщика заданий URL сайта: ваш_сайт.ru Файл для CRON: ваш_сайт.ru/cron/game_cron.php Логин в системе: Login Ип сервера: ip_servera
В ответ Вам пришлют примерно следующий ответ
/opt/php/5.3/bin/php-cgi -f /var/www/vhosts/u000001.plsk.regruhosting.ru/httpdocs/site.ru.ru/cron/game_cron.php
3. Заходим в панель управления
4. Заходим в планировщик
5. Создаем CRON Задание
Заполняем примерно так же, поле «Команда» вставить команду которую Вам дал хостер
Нажимаем ок и сохраняем
6. Завершение
Вам должно было выдать вот такое
После этого добавляем еще одно задание для файла other.php, просто в команде замените game_cron.php на other.php, выставляем время 1 час И нажмите OK
Обязательно нужно защитить эти 2 файла, читаем инструкцию дальше
Открываем файл .htaccess, он находится в корне мониторинга.
И видим там строки
##<Files cron/other.php> ## deny from all ##</Files> ##<Files cron/game_cron.php> ## deny from all ##</Files>
И раскоментируем их, т.е делаем вот так
<Files cron/other.php> deny from all </Files> <Files cron/game_cron.php> deny from all </Files>
Поздравляю CRON настроен
manual/cron/reg_ru.txt · Последние изменения: 19:18 21/01/2018 (внешнее изменение)
Регулярные выражения в Python: теория и практика
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
- Для чего нужны регулярные выражения?
- Регулярные выражения в Python
- Задачи
Для чего нужны регулярные выражения?
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
Регулярные выражения в Python
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
import reА вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
<_sre.SRE_Match object at 0x0000000009BE4370>
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AVТеперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV')
print result
Результат:
NoneТакже есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.start()
print result.end()
Результат:
0
2Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AnalyticsМетод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
result = re.findall(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
['AV', 'AV']re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics')
print result
Результат:
['Anal', 'tics']В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры:
result = re.split(r'i', 'Analytics Vidhya')
print result
Результат:
['Analyt', 'cs V', 'dhya'] # все возможные участки.result = re.split(r'i', 'Analytics Vidhya',maxsplit=1)
print result
Результат:
['Analyt', 'cs Vidhya']Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India')
print result
Результат:
'AV is largest Analytics community of the World're.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV']До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки \n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра [0-9] (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
| [. и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Ну хватит теории. Рассмотрим примеры использования Python RegEx.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
result = re.findall(r'.', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a']Для того, чтобы в конечный результат не попал пробел, используем вместо . \w.
result = re.findall(r'\w', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a']Теперь попробуем достать каждое слово (используя * или +)
result = re.findall(r'\w*', 'AV is largest Analytics community of India')
print result
Результат:
['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', '']И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
result = re.findall(r'\w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']Теперь вытащим первое слово, используя ^:
result = re., то мы получим последнее слово, а не первое:result = re.findall(r'\w+$', 'AV is largest Analytics community of India') print result Результат: [‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя
\w, вытащить два последовательных символа, кроме пробельных, из каждого слова:result = re.findall(r'\w\w', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (
\b):result = re.findall(r'\b\w.', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
result = re.findall(r'@\w+', '[email protected], [email protected], [email protected], [email protected]') print result Результат: ['@gmail', '@test', '@analyticsvidhya', '@rest']Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@\w+.\w+', '[email protected], [email protected], [email protected], [email protected]') print result Результат: ['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку —
( ):result = re.findall(r'@\w+.(\w+)', '[email protected], [email protected], [email protected], [email protected]') print result Результат: ['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем
\dдля извлечения цифр.result = re.findall(r'\d{2}-\d{2}-\d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009') print result Результат: ['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.findall(r'\d{2}-\d{2}-(\d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009') print result Результат: ['2007', '2011', '2009']Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']А теперь — только те, которые начинаются на определенные буквы (используя
[]):result = re.findall(r'[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем
\bдля обозначения границы слова:result = re.findall(r'\b[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать
^внутри квадратных скобок для инвертирования группы:result = re.aeiouAEIOU ]\w+', 'AV is largest Analytics community of India') print result Результат: ['largest', 'community']Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999'] for val in li: if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10: print 'yes' else: print 'no' Результат: yes no noРазбить строку по нескольким разделителям
Возможное решение:
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," "). result = re.split(r'[;,\s]', line) print result Результат: ['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод
re.sub()для замены всех разделителей пробелами:line = 'asdf fjdk;afed,fjek,asdf,foo' result = re.sub(r'[;,\s]',' ', line) print result Результат: asdf fjdk afed fjek asdf fooИзвлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между
<td>и</td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную
test_str):result = re.findall(r'\d([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str) print result Результат: [('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»
Начало строки $Конец строки \ AНачало строки \ zКонец строки
.Любой одиночный символ \ сЛюбой пробельный символ \ SЛюбой непробельный символ \ dЛюбая цифра \ DЛюбое нецифровое \ wЛюбой символ слова (буква, цифра, подчеркивание) \ ВтЛюбой символ, не являющийся словом \ bЛюбая граница слова
(...)Захватить все замкнутое (а | б)а или б а?Ноль или один из а *Ноль или более а +Один или несколько из а {3}Ровно 3 из а {3,}3 или более из а {3,6}Между 3 и 6 из
PHP имеет два набора функций регулярных выражений: функции ereg и preg.Функции preg поддерживают современный полнофункциональный синтаксис регулярных выражений на основе библиотеки PCRE и рекомендуются для нового кода. Начиная с PHP 7.3.0 они основаны на PCRE2. Функции ereg реализуют регулярные выражения POSIX с ограниченным синтаксисом. Функции ereg устарели, но RegexBuddy по-прежнему полностью поддерживает их, поэтому вы можете поддерживать существующий код или преобразовывать свои регулярные выражения из версии PHP ereg в версию preg. Посмотрите, насколько простым может быть кодирование с помощью регулярных выраженийВо-первых, используйте RegexBuddy, чтобы определить регулярное выражение или получить регулярное выражение, сохраненное в библиотеке RegexBuddy.Положитесь на четкий анализ регулярных выражений RegexBuddy, который постоянно обновляется по мере создания шаблона, вместо того, чтобы самостоятельно разбираться с загадочным синтаксисом регулярных выражений. Подробная справка по этому синтаксису всегда находится на расстоянии одного клика. Если вы скопировали регулярное выражение, написанное для другого языка программирования, просто вставьте его в RegexBuddy, выберите исходный язык, а затем преобразуйте регулярное выражение в конкретную версию PHP и набор функций, которые вы используете. Вы также можете конвертировать из одной версии PHP в другую и из старого синтаксиса ereg в современный синтаксис preg.Если вы пишете библиотеку кода, которая должна работать с несколькими версиями PHP, сравните свое регулярное выражение между этими версиями PHP, чтобы убедиться, что оно будет работать одинаково со всеми из них. RegexBuddy знает все функции и все ошибки во всех версиях PCRE, начиная с PHP 4.3.3 2003 года и заканчивая последней версией PHP 8.0.6. Если вы создали новое регулярное выражение, проверьте и отладьте его в RegexBuddy, прежде чем использовать его в исходном коде PHP. Проверяйте каждое регулярное выражение в безопасной песочнице RegexBuddy, не рискуя ценными данными.Быстро примените регулярное выражение к широкому спектру входных и выборочных данных, не создавая эти входные данные с помощью сценария. Наконец, позвольте RegexBuddy сгенерировать фрагмент исходного кода, который вы можете скопировать и вставить непосредственно в любой редактор кода IDE или PHP, который вы используете. Просто выберите, для чего вы хотите использовать регулярное выражение, и полнофункциональный фрагмент кода готов. Вы можете изменить имена переменных и параметров в соответствии с вашим стилем именования или текущей ситуацией, которую RegexBuddy автоматически запоминает. Не пытайтесь вспомнить, какие методы вызывать или какие параметры передавать. И не беспокойтесь о том, как правильно экранировать обратную косую черту и кавычки. Просто скажите RegexBuddy, что вы хотите сделать, и вы сразу получите правильный PHP-код. Можно сделать все, что угодно: проверить строку на соответствие, извлечь совпадения поиска, проверить ввод, выполнить поиск и заменить, разделить строку и т. Д. Let RegexBuddy Make Regex Easy for You | «Я купил лицензию на RegexBuddy около месяца назад, и он мне очень нравится! Я разработчик PHP, и создавать даже сложные регулярные выражения в RegexBuddy очень просто... «Программа действительно стоит каждого пенни - продолжайте в том же духе!» «Снимаю перед вами шляпу, ребята! Ваш RegexBuddy - БОЛЬШОЙ ОТПРАВИТЕЛЬ! «Я использую эту программу примерно 10 раз в день при разработке приложений на PHP. Это замечательно, потому что он не только описывает и обрисовывает регулярные выражения, но и учит вас в процессе. Просто хотел сказать вам пару слов от этого очень довольного покупателя! » |
Использование регулярных выражений с PHP
PHP - это язык с открытым исходным кодом для создания динамических веб-страниц.В PHP есть три набора функций, которые позволяют работать с регулярными выражениями.
Самый важный набор функций регулярных выражений начинается с preg. Эти функции представляют собой оболочку PHP вокруг библиотеки PCRE (Perl-совместимые регулярные выражения). Все, что говорится о разновидности регулярных выражений PCRE в руководстве по регулярным выражениям на этом веб-сайте, относится к функциям preg PHP. Когда в руководстве конкретно говорится о PHP, предполагается, что вы используете функции preg. Вы должны использовать функции preg для всего нового кода PHP, который использует регулярные выражения.PHP включает PCRE по умолчанию, начиная с PHP 4.2.0 (апрель 2002 г.).
Самый старый набор функций регулярных выражений - это те, которые начинаются с ereg. Они реализуют расширенные регулярные выражения POSIX, такие как традиционная команда egrep UNIX. Эти функции в основном предназначены для обратной совместимости с PHP 3. Они официально объявлены устаревшими, начиная с PHP 5.3.0. Многие из более современных функций регулярных выражений, такие как ленивые квантификаторы, поиск и Unicode, не поддерживаются функциями ereg. Не позволяйте «расширенному» прозвищу ввести вас в заблуждение.Стандарт POSIX был определен в 1986 году, и с тех пор регулярные выражения прошли долгий путь.
Последний набор представляет собой вариант набора ereg с префиксом mb_ для «многобайтовости» в именах функций. В то время как ereg обрабатывает регулярное выражение и строку темы как серию 8-битных символов, mb_ereg может работать с многобайтовыми символами из различных кодовых страниц. Если вы хотите, чтобы ваше регулярное выражение рассматривало символы Дальнего Востока как отдельные символы, вам нужно будет использовать либо функции mb_ereg, либо функции preg с модификатором / u.mb_ereg доступен в PHP 4.2.0 и новее. Он использует тот же аромат POSIX ERE.
Набор функций preg
Все функции preg требуют, чтобы вы указали регулярное выражение в виде строки с использованием синтаксиса Perl. В Perl / regex / определяет регулярное выражение. В PHP это становится preg_match ('/ regex /', $ subject). Когда косая черта используется в качестве разделителя регулярных выражений, любые косые черты в регулярном выражении должны быть экранированы обратной косой чертой. Итак, http: // www \ .jgsoft \.com / становится '/http:\/\/www\.jgsoft\.com\//'. Как и Perl, функции preg допускают использование любых не буквенно-цифровых символов в качестве разделителей регулярных выражений. Регулярное выражение URL-адреса будет более читаемым как "% http: // www \ .jgsoft \ .com /%" с использованием знаков процента в качестве разделителей регулярных выражений, поскольку в этом случае вам не нужно экранировать косую черту. Вам нужно будет избежать процентных знаков, если регулярное выражение их содержит.
В отличие от языков программирования, таких как C # или Java, PHP не требует экранирования всех обратных косых черт в строках.Если вы хотите включить обратную косую черту в качестве буквального символа в строку PHP, вам нужно только экранировать ее, если за ней следует другой символ, который необходимо экранировать. В строках с одинарными кавычками нужно экранировать только одинарные кавычки и обратную косую черту. Вот почему в приведенном выше регулярном выражении мне не нужно было удваивать обратную косую черту перед буквальными точками. Регулярное выражение \\ для соответствия одиночной обратной косой черте станет '/ \\\\ /' как строка preg PHP. Если вы не хотите использовать интерполяцию переменных в своем регулярном выражении, вы всегда должны использовать строки в одинарных кавычках для регулярных выражений в PHP, чтобы избежать беспорядочного дублирования обратной косой черты.
Чтобы указать параметры сопоставления регулярных выражений, такие как нечувствительность к регистру, задаются так же, как в Perl. '/ regex / i' применяет регистр регулярных выражений без учета регистра. '/ regex / s' заставляет точку соответствовать всем символам. '/ regex / m' заставляет привязки начала и конца строки совпадать во встроенных символах новой строки в строке темы. '/ regex / x' включает режим свободного интервала. Вы можете указать несколько букв, чтобы включить несколько опций. '/ regex / misx' включает все четыре параметра.
Специальная опция - это / u, которая включает режим сопоставления Unicode вместо 8-битного режима сопоставления по умолчанию.Вы должны указать / u для регулярных выражений, которые используют \ x {FFFF}, \ X или \ p {L} для соответствия символам Unicode, графемам, свойствам или скриптам. PHP интерпретирует '/ regex / u' как строку UTF-8, а не как строку ASCII.
Как и функция ereg, bool preg_match (шаблон строки, тема строки [, группы массивов]) возвращает значение ИСТИНА, если шаблон регулярного выражения соответствует строке темы или части строки темы. Если вы укажете третий параметр, preg сохранит подстроку, соответствующую первой группе захвата, в $ groups [1].$ groups [2] будет содержать вторую пару и так далее. Если в шаблоне регулярного выражения используется именованный захват, вы можете получить доступ к группам по имени с помощью $ groups ['name']. $ groups [0] проведут общий матч.
int preg_match_all (шаблон строки, тема строки, совпадения массива, флаги int) заполняет массив «совпадений» всеми совпадениями шаблона регулярного выражения в строке темы. Если вы укажете PREG_SET_ORDER в качестве флага, тогда $ match [0] будет массивом, содержащим совпадение и обратные ссылки первого совпадения, точно так же, как массив $ groups, заполненный preg_match.$ match [1] содержит результаты для второго совпадения и так далее. Если вы укажете PREG_PATTERN_ORDER, тогда $ match [0] будет массивом с полными последовательными совпадениями регулярных выражений, $ match [1] массивом с первой обратной ссылкой из всех совпадений, $ match [2] массивом со второй обратной ссылкой каждого совпадения, пр.
array preg_grep (шаблон строки, объекты массива) возвращает массив, который содержит все строки в массиве «субъектов», которые могут быть сопоставлены шаблоном регулярного выражения.
смешанный preg_replace (смешанный шаблон, смешанная замена, смешанный предмет [, int limit]) возвращает строку со всеми совпадениями с шаблоном регулярного выражения в строке темы, замененной строкой замены. Производятся не более лимитные замены. Одно из ключевых отличий заключается в том, что все параметры, кроме limit, могут быть массивами, а не строками. В этом случае preg_replace выполняет свою работу несколько раз, одновременно выполняя итерацию по элементам в массивах. Вы также можете использовать строки для одних параметров и массивы для других.Затем функция будет перебирать массивы и использовать одни и те же строки для каждой итерации. Использование массива шаблона и замены позволяет выполнять последовательность операций поиска и замены в одной строке темы. Использование массива для строки темы позволяет выполнять одну и ту же операцию поиска и замены для многих строк темы.
preg_replace_callback (смешанный шаблон, замена обратного вызова, смешанный предмет [, ограничение int]) работает так же, как preg_replace, за исключением того, что второй параметр принимает обратный вызов вместо строки или массива строк.Функция обратного вызова будет вызываться для каждого совпадения. Обратный вызов должен принимать один параметр. Этот параметр будет массивом строк, в котором элемент 0 содержит общее совпадение регулярного выражения, а другие элементы - текст, сопоставленный захваченными группами. Это тот же массив, что и в preg_match. Функция обратного вызова должна возвращать текст, которым должно быть заменено совпадение. Верните пустую строку, чтобы удалить совпадение. Верните $ groups [0], чтобы пропустить это совпадение.
Обратные вызовы
позволяют выполнять мощные операции поиска и замены, которые нельзя выполнить с помощью одних только регулярных выражений.Например. если вы ищете регулярное выражение (\ d +) \ + (\ d +), вы можете заменить 2 + 3 на 5, используя обратный вызов:
function regexadd ($ groups) {
вернуть $ groups [1] + $ groups [2];
} array preg_split (string pattern, string subject [, int limit]) работает так же, как split, за исключением того, что он использует синтаксис Perl для шаблона регулярного выражения.
См. Руководство по PHP для получения дополнительной информации о наборе функций preg
Набор функций ereg
Функции ereg требуют, чтобы вы указали регулярное выражение в виде строки, как и следовало ожидать.ereg ('regex', «subject») проверяет соответствие регулярного выражения subject. При передаче регулярного выражения в виде буквальной строки следует использовать одинарные кавычки. Некоторые специальные символы, такие как доллар и обратная косая черта, также являются специальными символами в строках PHP с двойными кавычками, но не в строках с одинарными кавычками.
int ereg (шаблон строки, тема строки [, группы массивов]) возвращает длину совпадения, если шаблон регулярного выражения соответствует строке темы или части строки объекта, или ноль в противном случае.Поскольку ноль оценивается как False, а ненулевое значение - как True, вы можете использовать ereg в операторе if для проверки совпадения. Если вы укажете третий параметр, ereg сохранит подстроку, совпадающую с частью регулярного выражения между первой парой круглых скобок в $ groups [1]. $ groups [2] будет содержать вторую пару и так далее. Обратите внимание, что круглые скобки только для группировки не поддерживаются ereg. ereg чувствителен к регистру. eregi - нечувствительный к регистру эквивалент.
строка ereg_replace (шаблон строки, замена строки, тема строки) заменяет все совпадения шаблона регулярного выражения в строке темы на заменяющую строку.Вы можете использовать обратные ссылки в строке замены. \\ 0 - это полное совпадение регулярного выражения, \\ 1 - первая обратная ссылка, \\ 2 - вторая и т. Д. Максимально возможная обратная ссылка - \\ 9. ereg_replace чувствителен к регистру. eregi_replace - эквивалент без учета регистра.
array split (string pattern, string subject [, int limit]) разбивает предметную строку на массив строк с использованием шаблона регулярного выражения. Массив будет содержать подстроки между совпадениями регулярных выражений.Фактически совпавший текст отбрасывается. Если вы укажете ограничение, результирующий массив будет содержать не более указанного количества подстрок. Строка темы будет разделена не более чем limit-1 раз, а последний элемент в массиве будет содержать неразделенный остаток строки темы. split чувствителен к регистру. spliti - нечувствительный к регистру эквивалент.
См. Руководство по PHP для получения дополнительной информации о наборе функций ereg
Набор функций mb_ereg
Функции mb_ereg работают точно так же, как функции ereg, с одним ключевым отличием: в то время как ereg обрабатывает регулярное выражение и строку темы как серию 8-битных символов, mb_ereg может работать с многобайтовыми символами из различных кодовых страниц.Например. закодировано с помощью кодовой страницы Windows 936 (упрощенный китайский), слово 中国 («Китай») состоит из четырех байтов: D6D0B9FA. Использование функции ereg с регулярным выражением. в этой строке в результате будет получен первый байт D6. Точка соответствует ровно одному байту, поскольку функции ereg ориентированы на байты. Использование функции mb_ereg после вызова mb_regex_encoding ("CP936") даст в результате байты D6D0 или первый символ 中.
Чтобы убедиться, что ваше регулярное выражение использует правильную кодовую страницу, вызовите mb_regex_encoding (), чтобы установить кодовую страницу.Если вы этого не сделаете, вместо этого будет использоваться кодовая страница, возвращаемая или установленная mb_internal_encoding ().
Если ваш сценарий PHP использует UTF-8, вы можете использовать функции preg с модификатором / u для сопоставления многобайтовых символов UTF-8 вместо отдельных байтов. Функции preg не поддерживают другие кодовые страницы.
См. Руководство по PHP для получения дополнительной информации о наборе функций mb_ereg
Дополнительная литература
Книга «Освоение регулярных выражений» не только объясняет все, что вы хотите знать и не хотите знать о регулярных выражениях.В нем также есть отличная глава, посвященная набору функций PHP preg, с подробностями о базовом механизме регулярных выражений PCRE и множеством примеров кода PHP, демонстрирующих более продвинутые методы. В книге не рассматриваются наборы функций ereg и mb_ereg.
Моя рецензия на книгу Освоение регулярных выражений
Сделайте пожертвование
Этот веб-сайт только что сэкономил вам поездку в книжный магазин? Сделайте пожертвование в поддержку этого сайта, и вы получите неограниченный доступ к этому сайту без рекламы!
Регулярные выражения обычно известны как regex .) для создания сложных выражений. По умолчанию регулярные выражения чувствительны к регистру . Преимущества и использование регулярного выраженияРегулярное выражение используется почти везде в современном прикладном программировании. Ниже приведены некоторые преимущества и способы использования регулярных выражений:
| |
| – | Находит диапазон между элементами, например. , [a-z] означает от a до z. |
| | | Это логический оператор ИЛИ, который используется между элементами. Например. , a | b, что означает либо ИЛИ b. |
| ? | Указывает ноль или один из предыдущего символа или диапазона элементов. |
| * | Указывает ноль или более предшествующих символов или диапазона элементов. |
| + | Указывает ноль или более предшествующих символов или диапазона элементов. |
| {n} | Обозначает не менее n раз предыдущего диапазона символов. Например - n {3} |
| {n,} | Обозначает не менее n, но не должно быть больше m раз, например, n {2,5} означает от 2 до 5 из n. |
| {n, m} | Указывает не менее n, но не более m раз.Например, n {3,6} означает от 3 до 6 из n. |
| \ | Обозначает escape-символ. |
Класс специальных символов в регулярном выражении
| Специальный символ | Описание |
|---|---|
| \ п | Указывает на новую строку. |
| \ r | Указывает на возврат каретки. |
| \ т | Представляет собой вкладку. |
| \ v | Представляет собой вертикальную табуляцию. |
| \ f | Представляет собой подачу страницы. |
| \ xxx | Представляет восьмеричный символ. |
| \ xxh | Обозначает шестнадцатеричный символ hh. |
PHP предлагает два набора функций регулярных выражений:
- Регулярное выражение POSIX
- Регулярное выражение стиля PERL
Регулярное выражение POSIX
Структура регулярного выражения POSIX аналогична типичному арифметическому выражению: несколько операторов / элементов объединяются вместе для образования более сложных выражений.
Самое простое регулярное выражение - это выражение, которое соответствует одному символу внутри строки. Например - «g» внутри тумблера или строки клетки. Давайте познакомимся с некоторыми концепциями, используемыми в регулярном выражении POSIX:
Кронштейны
Скобки [] имеют особое значение, когда они используются в регулярных выражениях. Они используются, чтобы найти диапазон символов внутри него.
| Выражение | Описание |
|---|---|
| [0-9] | Соответствует любой десятичной цифре от 0 до 9. |
| [а-я] | Соответствует любому символу нижнего регистра от a до z. |
| [А-Я] | Соответствует любому символу в верхнем регистре от A до Z. |
| [а-я] | Соответствует любому символу от нижнего a до верхнего Z. |
Обычно используются указанные выше диапазоны. Вы можете использовать значения диапазона в соответствии с вашими потребностями, например [0-6], чтобы соответствовать любой десятичной цифре от 0 до 6.
Квантификаторы
Специальный символ может обозначать позицию заключенных в квадратные скобки последовательностей символов и отдельных символов. Каждый специальный символ имеет определенное значение. Все указанные флаги символов +, *,?, $ И {int range} следуют за последовательностью символов.
| Выражение | Описание | |
|---|---|---|
| п + | Соответствует любой строке, содержащей хотя бы один p. | |
| п * | Соответствует любой строке, содержащей один или несколько p. | |
| п? | Соответствует любой строке, содержащей ноль или один p. | |
| п {N} | Соответствует любой строке, имеющей последовательность из N p. | |
| п {2,3} | Соответствует любой строке, состоящей из двух или трех p. | |
| п {2,} | Соответствует любой строке, содержащей не менее двух p.п | Соответствует любой строке с буквой p в начале. |
Функция PHP Regexp POSIX
PHP предоставляет семь функций для поиска строк с использованием регулярного выражения в стиле POSIX -
| Функция | Описание |
|---|---|
| ereg () | Он ищет шаблон строки внутри другой строки и возвращает истину, если шаблон соответствует, в противном случае возвращает ложь. |
| ereg_replace () | Он ищет образец строки внутри другой строки и заменяет соответствующий текст строкой замены. |
| eregi () | Он ищет шаблон внутри другой строки и возвращает длину совпавшей строки, если она найдена, в противном случае возвращает false. Это функция без учета регистра . |
| eregi_replace () | Эта функция работает так же, как функция ereg_replace () .Единственное отличие состоит в том, что поиск шаблона этой функции нечувствителен к регистру. |
| раздельный () | Функция split () делит строку на массив. |
| spliti () | Она похожа на функцию split (), поскольку она также делит строку на массив с помощью регулярного выражения. |
| Sql_regcase () | Он создает регулярное выражение для совпадения без учета регистра и возвращает допустимое регулярное выражение, которое будет соответствовать строке. |
Примечание: обратите внимание, что указанные выше функции устарели в PHP 5.3.0 и удалены в PHP 7.0.0.
Регулярное выражение стиля PERL
Регулярные выражения в стиле Perl очень похожи на POSIX. Синтаксис POSIX может взаимозаменяемо использоваться с функцией регулярного выражения в стиле Perl. Квантификаторы, представленные в разделе POSIX, также могут использоваться в регулярных выражениях стиля PERL.
Метасимволы
Метасимвол - это алфавитный символ, за которым следует обратная косая черта, придающая комбинации особое значение.
Например, - метасимвол '\ d' может использоваться для поиска крупных денежных сумм: / ([\ d] +) 000 /. Здесь / d будет искать строку числовых символов.
Ниже приведен список метасимволов, которые можно использовать в регулярных выражениях стиля PERL -
| Персонаж | Описание | |
|---|---|---|
| . | Соответствует одиночному символу | |
| \ с | Соответствует пробелу, например пробелу, новой строке, табуляции. | |
| \ S | Непробельный символ | |
| \ d | Соответствует любой цифре от 0 до 9. | |
| \ D | Соответствует нецифровому символу. | |
| \ w | Соответствует символу слова, например - a-z, A-Z, 0-9, _ | |
| \ Вт | Соответствует символу, не являющемуся словом.aeiou] | Соответствует любому одиночному символу, кроме указанного набора. |
| (foo | baz | bar) | Соответствует любой из указанных альтернатив. |
Модификаторы
Доступно несколько модификаторов, которые значительно упрощают работу с регулярным выражением. Например, - чувствительность к регистру или поиск по нескольким строкам и т. Д.
Ниже приведен список модификаторов, используемых в регулярных выражениях стиля PERL -
| Персонаж | Описание |
|---|---|
| и | Выполняет поиск без учета регистра |
| м | Он указывает, что если строка содержит символы возврата каретки или новой строки, оператор $ и ^ будет соответствовать границе новой строки, а не границе строки. |
| или | Оценивает выражение только один раз |
| с | Позволяет использовать. (Точка) для соответствия символу новой строки |
| х | Этот модификатор позволяет нам использовать пробелы в выражении для ясности. |
| г | Он ищет все совпадения во всем мире. |
| кг | Позволяет продолжить поиск даже после сбоя глобального совпадения. |
Функция PHP Regexp POSIX
В настоящее время PHP предоставляет семь функций для поиска строк с использованием регулярного выражения в стиле POSIX -
| Функция | Описание | |
|---|---|---|
| preg_match () | Эта функция ищет шаблон внутри строки и возвращает true , если шаблон существует, в противном случае возвращает false . | |
| preg_match_all () | Эта функция сопоставляет все вхождения шаблона в строку. | |
| preg_replace () | Функция preg_replace () аналогична функции ereg_replace (), за исключением того, что при поиске и замене можно использовать регулярные выражения. | |
| прег_сплит () | Эта функция работает точно так же, как функция split (), за исключением того, что она принимает регулярное выражение в качестве входного параметра для шаблона. В основном он делит строку на регулярное выражение. | |
| preg_grep () | Функция preg_grep () находит все элементы input_array и возвращает элементы массива, соответствующие шаблону regexp (реляционное выражение). | |
| preg_quote () | Цитируйте символы регулярного выражения. |
| Классы символов | |
|---|---|
| .abc $ | начало / конец строки |
| \ б | граница слова |
| Экранированные символы | |
| \. \ * \\ | экранированные специальные символы |
| \ t \ n \ r | табуляция, перевод строки, возврат каретки |
| \ u00A9 | код юникода экранирован © |
| Группы и поиск | |
| (abc) | группа захвата |
| \ 1 | обратная ссылка на группу № 1 |
| (?: Abc) | группа без захвата |
| (? = Abc) | положительный прогноз |
| (?! Abc) | отрицательный прогноз |
| Квантификаторы и чередование | |
| а * а + а? | 0 или более, 1 или более, 0 или 1 |
| а {5} а {2,} | ровно пять, два или больше |
| а {1,3} | между одним и тремя |
| а +? а {2,}? | совпадений как можно меньше |
| ab | cd | соответствует ab или cd |
Делаем RegEx понятным с помощью практических примеров
Регулярное выражение - это последовательность символов, используемая для синтаксического анализа и управления строками.Они часто используются для выполнения поиска, замены подстрок и проверки строковых данных. В этой статье представлены советы, приемы, ресурсы и шаги по работе со сложными регулярными выражениями.
Если у вас нет базовых навыков, вы можете выучить регулярное выражение с помощью нашего руководства для начинающих. Какими бы загадочными ни были регулярные выражения, вам не понадобится много времени, чтобы изучить их концепции.
Существует множество книг, статей, веб-сайтов и официальной документации PHP, объясняющих регулярные выражения, поэтому вместо того, чтобы писать еще одно объяснение, я предпочел бы сразу перейти к более практическим примерам.Вы можете найти полезную шпаргалку по этой ссылке.
Наряду с множеством полезных ресурсов, внизу этого поста есть также видео конференции Леа Веру - оно немного длинное, но отлично разбирает RegEx.
Как создать хорошее регулярное выражение
Регулярные выражения часто используются в повседневной работе разработчика - при анализе журналов, проверке отправки форм, поиске и замене и т. Д. Вот почему каждый хороший разработчик должен знать, как их использовать, но как лучше всего создать хорошее регулярное выражение?
1.Определите сценарий
Использование естественного языка для определения проблемы даст вам лучшее представление о подходе к использованию. Слова может и должен , используемые в определении, полезны для описания обязательных ограничений или утверждений.
Пример ниже:
- Строка должна начинаться с «h» и заканчиваться «o» (например, привет, нимб).
- Строку можно заключить в круглые скобки.
2. Разработайте план
После хорошего определения проблемы мы можем понять, какие элементы используются в нашем регулярном выражении:
- Какие типы символов разрешены (слово, цифра, новая строка, диапазон,…)?
- Сколько раз должен появиться персонаж (один или несколько, один раз,…)?
- Есть ли какие-то ограничения, которым нужно следовать (необязательные варианты, прогнозирование вперед / назад, если-то-еще,…)?
3.Реализовать / Тестировать / Рефакторинг
Очень важно иметь среду тестирования в реальном времени для тестирования и улучшения вашего регулярного выражения. Существуют такие веб-сайты, как regex101.com, regexr.com и debuggex.com, которые предоставляют одни из лучших сред.
Чтобы повысить эффективность регулярного выражения, вы можете попытаться ответить на некоторые из этих дополнительных вопросов:
- Правильно ли определены классы символов для конкретного домена?
- Следует ли мне написать больше тестовых строк, чтобы охватить больше вариантов использования?
- Можно ли найти и изолировать некоторые проблемы и протестировать их по отдельности?
- Должен ли я реорганизовать свое выражение с помощью подшаблонов, групп, условий и т. Д., чтобы сделать его меньше, понятнее и гибче?
Практические примеры
Цель следующих примеров - не написать выражение, которое только решит проблему, а написать наиболее эффективное выражение для конкретных случаев использования, используя такие важные элементы, как диапазоны символов, утверждения, условия, группы и т. (? =.* [a-z]) (? =. * [A-Z]) (? =. * \ d). {6,12} $
Это выражение основано на множественном положительном просмотре вперед (? = (Regex)) . Предварительный просмотр соответствует чему-то, за которым следует объявленное (регулярное выражение) . Порядок выполнения условий не влияет на результат. Выражения поиска очень полезны, когда есть несколько условий.
Мы также можем использовать отрицательный просмотр вперед (?! (Regex)) , чтобы исключить некоторые диапазоны символов. Например, я мог бы исключить % с (?!. утверждает позицию в начале строки
(? =. * [A-z]) положительный просмотр вперед, утверждает, что регулярное выражение . * [A-z] может быть сопоставлено:-
. *соответствует любому символу (кроме новой строки) от нуля до неограниченного числа раз -
[a-z]соответствует одному символу в диапазоне от a до z (с учетом регистра)
(? =. * [A-Z]) положительный просмотр вперед, утверждает, что регулярное выражение . * [A-Z] может быть сопоставлено:-
.*соответствует любому символу (кроме новой строки) от нуля до неограниченного числа раз -
[A – Z]соответствует одному символу от A до Z (с учетом регистра)
* \ d может быть сопоставлено:-
. *соответствует любому символу (кроме новой строки) от нуля до неограниченного числа раз -
\ dсоответствует цифре [0-9]
. {6,12} соответствует любому символу (кроме новой строки) от 6 до 12 раз $ утверждает позицию в конце строкиСоответствующий URL
Сценарий:
- Должен начинаться с
httpилиhttpsилиftp, за которым следует: // - Должно соответствовать действительному доменному имени
- Может содержать спецификацию порта (
http: // www.(http | https | ftp): [\ /] {2}.
Чтобы соответствовать доменному имени, мы должны помнить, что для того, чтобы оно было действительным, оно может содержать только буквы, цифры, дефис и точки. В моем примере я ограничил количество символов после знаков препинания от 2 до 4, но может быть расширен для новых доменов, таких как.rocksили.codes. Доменное имя соответствует([a-zA-Z0-9 \ - \.] + \. [A-zA-Z] {2,4}).Необязательная спецификация порта соответствует простому
(: [0-9] +)?.URL-адрес может содержать несколько косых черт и несколько символов, повторяющихся много раз (см. RFC3986), для этого используется диапазон символов в группе
([a-zA-Z0-9 \ - \ ._ \? \, \ '\ / \\\ + & amp;% \ $ # \ = ~] *).
Очень полезно сопоставить каждый важный элемент групповым захватом(), потому что он вернет только те совпадения, которые нам нужны. Помните, что некоторые символы нужно экранировать с помощью\. утверждает позицию в начале строки - группа захвата
(http | https | ftp), захватываетhttpилиhttpsилиftp -
:экранированный символ, буквально соответствует символу: -
[\ /] {2}точно в 2 раза соответствует экранированному символу/ - группа захвата
([a-zA-Z0-9 \ - \.] + \. [a-zA-Z] {2,4}):-
[a-zA-Z0-9 \ - \.] +соответствует одноразовому и неограниченному числу символов в диапазоне от a до z, A и Z, 0 и 9, символу–буквально и символу.буквально -
\.соответствует символу.буквально -
[a-zA-Z] {2,4}соответствует одному символу от 2 до 4 раз между a и z или A и Z (с учетом регистра)
-
- группа захвата
(: [0-9] +)?:- квантификатор
?соответствует группе от нуля или более раз -
:соответствует символу:буквально -
[0-9] +соответствует одному символу от 0 до 9 один или несколько раз
- квантификатор
-
\ /?соответствует символу/буквально ноль или один раз - группа захвата
([a-zA-Z0-9 \ - \._ \? \, \ '\ / \\\ + & amp;% \ $ # \ = ~] *):-
[a-zA-Z0-9 \ - \ ._ \? \, \ '\ / \\\ + & amp;% \ $ # \ = ~] *соответствует от нуля до неограниченного количества раз для одного символа в диапазон az, AZ, 0-9, символы:-._?, '/ \ + & amp;% $ # = ~.
-
- Начальный тег должен начинаться с
<, за которым следует один или несколько символов и заканчиваться на> - Конечный тег должен начинаться с
, за которым следует один или несколько символов и заканчиваться на> - Мы должны сопоставить содержимое внутри элемента TAG
- Начать с
< - Захватить имя тега
- После одного или нескольких символов
- Захватить содержимое тега
- Закрывающий тег должен быть
-
<соответствует символу<буквально - группа захвата
([\ w] +)соответствует любому символу словаa-zA-Z0-9_один или несколько раз -
. *соответствует любому символу (кроме новой строки) от нуля или более раз -
>буквально соответствует символу> - группа захвата
(.*?), соответствует любому символу (кроме новой строки), ноль и более раз -
<буквально соответствует символам< -
/соответствует символу/буквально -
\ 1соответствует тому же тексту, который соответствует первой группе захвата:([\ w] +) -
>буквально соответствует символам> - Слова разделены пробелами
- Мы должны сопоставить все дубликаты, в том числе непоследовательные
- Соответствует каждому символу слова, за которым следует символ, не являющийся словом (в нашем случае пробел)
- Проверить, присутствует ли уже совпадающее слово
-
\ bграница слова - группа захвата
([\ w] +)соответствует любому символу словаa-zA-Z0-9_ -
\ bграница слова -
(? =.* \ 1)положительный просмотр вперед утверждает, что можно сопоставить следующее:-
. *соответствует любому символу (кроме новой строки) -
\ 1соответствует тому же тексту, что и первая группа захвата
-
Соответствующий тег HTML
Сценарий:
Узор:
<([\ w] +).*> (. *?) <\ / \ 1>
Сопоставление начального тега и содержимого внутри довольно просто с <([\ w] +). *> и (. *?) , но в приведенном выше шаблоне я добавил полезную вещь: ссылку на группа захвата.
На каждую группу захвата, определенную круглыми скобками () , можно ссылаться, используя ее номер позиции, (первая) (вторая) (третья) , что позволит выполнять дальнейшие операции.
Выражение выше можно объяснить как:
Включение в выражение только двух групп захвата, имени тега и содержимого, вернет очень четкое совпадение, список имен тегов со связанным содержимым.
Давайте копнем немного глубже и объясним подшаблоны:
Соответствующие повторяющиеся слова
Сценарий:
Узор:
\ b (\ w +) \ b (? =.* \ 1)
Это регулярное выражение кажется сложным, но в нем используется часть ранее показанной концепции.
Шаблон вводит понятие границ слова.
Граница слова \ b в основном проверяет позиции. Соответствует, когда за символом слова (например: abcDE ) следует символ, не являющийся словом (например: - ~ ,! ).
Ниже вы можете найти несколько примеров использования границы слова, чтобы сделать его более понятным:
- Учитывая фразу Регулярные выражения прекрасны
- Шаблон \ bare \ b соответствует - это
- Шаблон \ w {3 } \ b может соответствовать последним трем буквам слов: lar, ion, are, ome
Выражение выше можно объяснить как:
Ниже вы найдете объяснение для каждого подшаблона:
Выражение станет более понятным, если мы вернем все совпадения, а не только первое. См. Функцию PHP preg_match_all для получения дополнительной информации.
Заключительные мысли
Регулярные выражения - это палки о двух концах.Чем сложнее добавляется, тем сложнее решить проблему. Вот почему иногда бывает трудно найти регулярное выражение, которое соответствовало бы всем регистрам, и вместо этого лучше использовать несколько меньших регулярных выражений.
Хороший сценарий проблемы может быть очень полезным и позволит вам начать думать о диапазоне символов, ограничениях, утверждениях, повторах, необязательных значениях и т. Д. Уделяя больше внимания групповым захватам, совпадения будут полезны для дальнейшей обработки. .Не стесняйтесь улучшать выражения в примерах и дайте нам знать, как вы это делаете!
Полезные ресурсы
Ниже вы можете найти дополнительную информацию и ресурсы, которые помогут вам развить свои навыки работы с регулярными выражениями.
Не стесняйтесь добавлять комментарий к статье, если найдете что-то полезное, чего нет в списке.
Lea Verou - / Reg (exp) {2} lained /: прояснение регулярных выражений
Библиотеки PHP
| Имя | Описание |
|---|---|
| RegExpBuilder | Создает регулярное выражение с использованием понятных человеку цепочек методов |
| NooNooFluentRegex | Строит выражения Regex с использованием свободно устанавливаемых программ и терминов на английском языке, как указано выше |
| Hoa \ Regex | Предоставляет инструменты для анализа регулярных выражений и создания строк. |
| Regex обратное | При заданном регулярном выражении будет сгенерирована строка |
Сайты
Книги
| Название | Описание | Автор | Редактор |
|---|---|---|---|
| Освоение регулярных выражений | Необходимая книга регулярных выражений | Джеффри Фридл | O’Reilly |
| Справочник по карману регулярных выражений | Регулярные выражения для Perl, Ruby, PHP, Python, C, Java и.NET | Тони Стаблбайн | O’Reilly |
PHP: регулярное выражение электронной почты.
Не следует проверять электронные письма с помощью регулярных выражений. Проще говоря: подавляющее большинство фрагментов регулярных выражений в Интернете неверны. Большинство из них слишком просты и плохо оснащены, чтобы адекватно справляться с такой сложной задачей, как адрес электронной почты. При поиске в Google таких терминов, как «Пример регулярного выражения электронной почты для проверки PHP», я заметил, что около 60-70% перечисленных результатов были абсолютной кашей.Большинство этих веб-сайтов с фрагментами PHP содержали дрянные примеры регулярных выражений, которые фактически отклоняли действительные адреса электронной почты.
Если вы хотите проверить адреса электронной почты в PHP, вы можете использовать функцию filter_var. Функция filter_var использует само регулярное выражение. Однако регулярное выражение, которое использует filter_var, намного сложнее (и информативнее), чем подавляющее большинство примеров, которые вы найдете в Интернете. Пример кода:
if (filter_var ($ emailAddress, FILTER_VALIDATE_EMAIL)) {
// Адрес электронной почты действителен.} еще{
// Адрес электронной почты недействителен.
} Сравните приведенный выше код с этим примером, который я нашел в другой статье, и вы обнаружите, что FILTER_VALIDATE_EMAIL намного точнее, когда речь идет о спецификациях электронной почты, установленных в RFC 822:
.
if (! Preg_match ("/ [- 0-9a-zA-Z. + _] [Электронная почта защищена] [- 0-9a-zA-Z. + _] +. [A-zA-Z] {2, 4} / ", $ emailAddress)) {
//Адрес электронной почты недействителен.
} Я могу сказать, что приведенный выше код неадекватен, просто взглянув на него.Если вы посмотрите на любой из примеров регулярных выражений, которые пытаются соответствовать RFC 822, вы увидите, что они примерно в 1000 раз длиннее, чем регулярное выражение, используемое в приведенном выше коде.
Не проверять адреса электронной почты.
Другой популярный подход - вообще не проверять адреса электронной почты. Поскольку даже регулярное выражение, стоящее за filter_var, имеет свои ограничения, многие люди считают, что вы должны проверять его с помощью ссылки, отправляемой на электронную почту пользователя. Пример:
- Пользователь регистрируется.
- Создайте токен для этого пользователя и затем отправьте его на указанный им адрес электронной почты.
- Если они нажмут на ссылку, содержащую токен, отметьте их адрес электронной почты как проверенный.
- Предположим, что адрес электронной почты недействителен, пока не будет нажата ссылка.
Конечно, не всем нравится эта мысль просто потому, что многие хостинговые решения довольно скудны, когда дело доходит до того, сколько электронных писем вы можете отправлять в час / день. Это особенно актуально для решений виртуального хостинга; многие из них ограничивают количество писем, которые вы можете отправлять, чтобы сэкономить ресурсы и сократить количество спама.Есть также люди, которым просто наплевать на людей, у которых есть «необычные» адреса электронной почты, независимо от того, действительны они или нет.
Добавить комментарий