
Регулярные выражения для новичков
Что такое регулярные выражения?
Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы «d», можно написать rm d*.
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. xyz] соответствует любой символ, кроме, собственно, «x», «y» или «z».
xyz] соответствует любой символ, кроме, собственно, «x», «y» или «z».
Итак, применяя данный инструмент к нашему случаю, если мы напишем [Хх][аоие]х[аоие], то каждая из строк «Хаха», «хехе», «хихи» и даже «Хохо» будут соответствовать шаблону.
Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется \s, для цифр — \d, для символов латиницы, цифр и подчёркивания «_» — \w.
Если необходимо описать вообще любой символ, для этого используется точка — .. Если указанные классы написать с заглавной буквы (\S, \D, \W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно. — начало текста, а
— начало текста, а $ — конец. Так, по паттерну \bJava\b в строке «Java and JavaScript» найдутся первые 4 символа, а по паттерну \bJava\B — символы c 10-го по 13-й (в составе слова «JavaScript»).
Комикс про регулярные выражения с xkcd.ru
Диапазоны
У вас может возникнуть необходимость обозначить набор, в который входят буквы, например, от «б» до «ф». Вместо того, чтобы писать [бвгдежзиклмнопрстуф] можно воспользоваться механизмом диапазонов и написать [б-ф]. Так, паттерну x[0-8A-F][0-8A-F] соответствует строка «xA6», но не соответствует «xb9» (во-первых, из-за того, что в диапазоне указаны только заглавные буквы, во-вторых, из-за того, что 9 не входит в промежуток 0-8).
Механизм диапазонов особенно актуален для русского языка, ведь для него нет конструкции, аналогичной \w. Чтобы обозначить все буквы русского алфавита, можно использовать паттерн [а-яА-ЯёЁ]. Обратите внимание, что буква «ё» не включается в общий диапазон букв, и её нужно указывать отдельно.
Обратите внимание, что буква «ё» не включается в общий диапазон букв, и её нужно указывать отдельно.
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке регулярных выражений специальные обозначения:
Спецобозначения квантификаторов в регулярных выражениях.
Таким образом, с помощью квантификаторов мы можем улучшить наш шаблон для междометий до [Хх][аоеи]+х[аоеи]*, и он сможет распознавать строки «Хааха», «хееееех» и «Хихии».
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Очевидное решение <., которое запретит считать содержимым тега правую угловую скобку. Второй — объявить квантификатор не жадным, а ленивым. Делается это с помощью добавления справа к квантификатору символа  >]*>
>]*>?. Т.е. для поиска всех тегов выражение обратится в <.*?>.
Ревнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части регулярного выражения. Это называется ревнивой квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа +. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттерну ab*+a в строке «ababa» будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ «a», который стоит на третьей позиции, уже был использован для первого результата.
Скобочные группы
Для нашего шаблона «смеющегося» междометия осталась самая малость — учесть, что буква «х» может встречаться более одного раза, например, «Хахахахааахахооо», а может и вовсе заканчиваться на букве «х». Вероятно, здесь нужно применить квантификатор для группы [аиое]+х, но если мы просто напишем [аиое]х+, то квантификатор + будет относиться только к символу «х», а не ко всему выражению. Чтобы это исправить, выражение нужно взять в круглые скобки: ([аиое]х)+.
Таким образом, наше выражение превращается в [Хх]([аиое]х?)+ — сначала идёт заглавная или строчная «х», а потом произвольное ненулевое количество гласных, которые (возможно, но не обязательно) перемежаются одиночными строчными «х». Однако это выражение решает проблему лишь частично — под это выражение попадут и такие строки, как, например, «хихахех» — кто-то может быть так и смеётся, но допущение весьма сомнительное. Очевидно, мы можем использовать набор из всех гласных лишь единожды, а потом должны как-то опираться на результат первого поиска.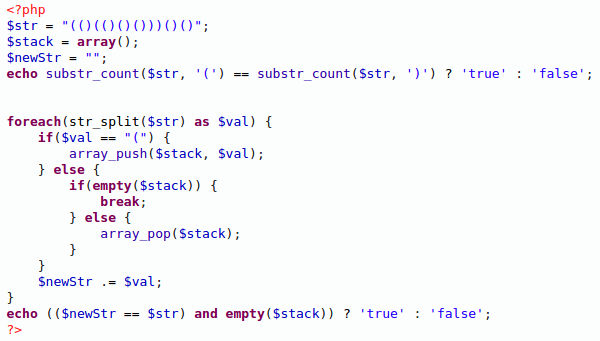 Но как?…
Но как?…
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регулярного выражения. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение <(.*?)>.
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Результат поиска по всему регулярному выражению: «<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».
На результат поиска по группе можно ссылаться с помощью выражения \n, где n — цифра от 1 до 9. Например выражению (\w)(\w)\1\2 соответствуют строки «aaaa», «abab», но не соответствует «aabb».
Если выражение берётся в скобки только для применения к ней квантификатора (не планируется запоминать результат поиска по этой группе), то сразу после первой скобки стоит добавить ?:, например (?:[abcd]+\w).
С использованием этого механизма мы можем переписать наше выражение к виду [Хх]([аоие])х?(?:\1х?)*.
Перечисление
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом булевого оператора OR, который записывается с помощью символа |. Так, под шаблон Анна|Одиночество попадают строки «Анна» и «Одиночество» соответственно. Особенно удобно использовать перечисления внутри скобочных групп. Так, например (?:a|b|c|d) полностью эквивалентно [abcd] (в данном случае второй вариант предпочтительнее в силу производительности и читаемости).
С помощью этого оператора мы сможем добавить к нашему регулярному выражению для поиска междометий возможность распознавать смех вида «Ахахаах» — единственной усмешке, которая начинается с гласной: [Хх]([аоие])х?(?:\1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы
Потренироваться и / или проверить своё регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101.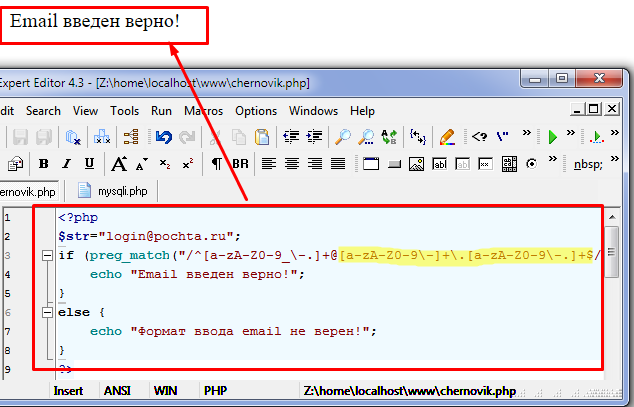 script] вполне подходит символ «S».
script] вполне подходит символ «S».
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
Итак, нужно написать выражение для описания цвета, который начинается с «#», за которым следуют 6 шестнадцатеричных символов. Шестнадцатеричный символ можно описать с помощью [0-9a-fA-F]. Для его шестикратного повторения мы будем использовать квантификатор {6}.
#[0-9a-fA-F]{6}Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: «+», «-», «*» и «/».
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярное выражение, которое найдёт как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного: -?\d+(\..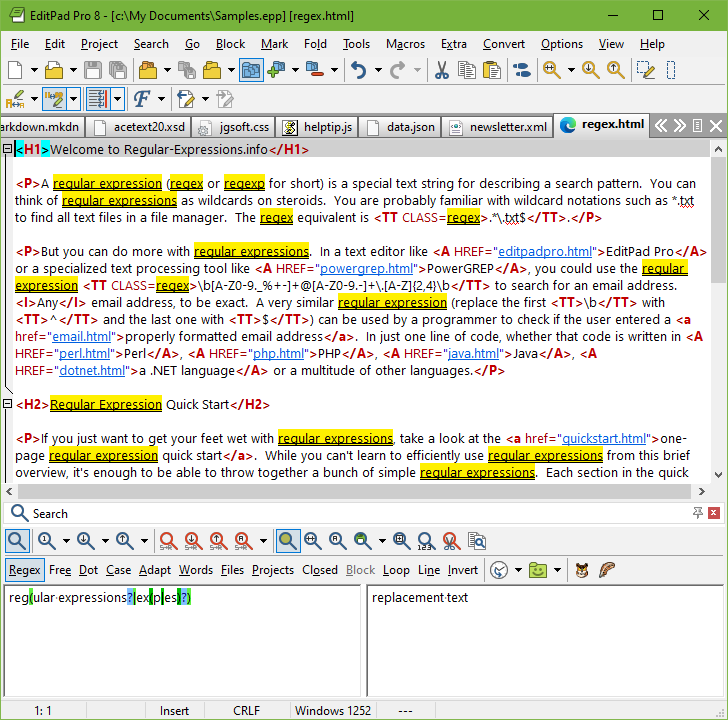 \d+)?
\d+)?
Оператор – это [+*/\-]. Заметим, что дефис мы экранируем. Нам нужно число, затем оператор, затем число, и необязательные пробелы между ними. Чтобы получить результат в требуемом формате, добавим ?: к группам, поиск по которым нам не интересен (отдельно дробные части), а операнды наоборот заключим в скобки. В итоге:
(-?\d+(?:\.\d+)?)\s*([-+*\/])\s*(-?\d+(?:\.\d+)?)Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
Удачи и помните — не всегда задачу стоит решать именно с помощью регулярных выражений («У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы»). Иногда лучше, например, написать развёрнутый автомат конечных состояний.
Задачи и их разборы с javascript.ru; в статье использованы комиксы xkcd.
regex — Регулярное выражение для соответствия строке, которая не содержит слова?
Поскольку никто другой не дал прямого ответа на вопрос который был задан, я сделаю это. a-zA-Z0-9_]
a-zA-Z0-9_]
\ b соответствует специальной границе символа, такой как пробел, &, # и т. д.
Обратите внимание, что поскольку интерпретатор python поставляется с частью обычной грамматики, а также распознает escape-символ \, если вы хотите передать escape-символ в логику обработки re, вы должны сначала позволить интерпретатору python не обрабатывать this \, что является Добавьте \. Например, следующий пример:
import re
ret=re.findall('c\l','abc\le')
print(ret)
ret=re.findall('c\\l','abc\le')
print(ret)
ret=re.findall('c\\\\l','abc\le')
print(ret)
ret=re.findall(r'c\\l','abc\le')
print(ret)
() и |
m = re.findall(r'(ad)+', 'add')
print(m)
ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group())
print(ret.group('id'))
ret=re.search('(ab)|\d','rabhdg8sd')
print(ret.group())
метод
import re
re.findall('a','alvin yuan')
re.search('a','alvin yuan').group()
re. match('a','abc').group()
ret=re.split('[ab]','abcd')
print(ret)
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())
ret=re.finditer('\d','ds3sy4784a')
print(ret)
match('a','abc').group()
ret=re.split('[ab]','abcd')
print(ret)
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())
ret=re.finditer('\d','ds3sy4784a')
print(ret)
 match('a','abc').group()
ret=re.split('[ab]','abcd')
print(ret)
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())
ret=re.finditer('\d','ds3sy4784a')
print(ret)
match('a','abc').group()
ret=re.split('[ab]','abcd')
print(ret)
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())
ret=re.finditer('\d','ds3sy4784a')
print(ret)
Regex: соответствует всему, кроме определенного шаблона
Регулярное выражение: соответствует всему , но :
- строка , начинающаяся с определенный шаблон (например, любой — тоже пустой — строка не начинается с
foo):- Решение на основе Lookahead для NFA:
- Решение на основе классов отрицательных символов для механизмов регулярных выражений, не поддерживающих поисковые запросы :
- строка , оканчивающаяся на конкретный образец (скажем, нет
world.в конце):- Решение на основе ретроспективного обзора:
- Lookahead решение:
- POSIX:
Обходной путь
- строка , содержащая конкретный текст (скажем, не соответствует строке, имеющей
foo):- Решение на основе поиска:
- POSIX:
Обходной путь
- строка , содержащая определенный символ (скажем, избегайте сопоставления строки, имеющей символ
|): - строка равна некоторая строка (скажем, не равна
foo): - последовательность символов :
- — определенный одиночный символ или набор символов :
Демо-заметка : новая строка \ n используется внутри инвертированных классов символов в демонстрациях, чтобы избежать переполнения совпадений с соседними строками. В них нет необходимости при тестировании отдельных строк.
В них нет необходимости при тестировании отдельных строк.
Якорное примечание : на многих языках используйте \ A для определения однозначного начала строки и \ z (в Python это \ Z , в JavaScript $ в порядке) для определения самый конец струны.
Точечное примечание : Во многих вариантах (кроме POSIX, TRE, TCL), . соответствует любому символу , кроме символа новой строки . Убедитесь, что вы используете соответствующий модификатор DOTALL ( / s, в PCRE / Boost /.NET / Python / Java и / m на Ruby) для . соответствует любому символу, включая новую строку.
Примечание с обратной косой чертой: в языках, где вы должны объявлять шаблоны со строками C, разрешающими escape-последовательности (например, \ n для новой строки), вам необходимо удвоить обратную косую черту для экранирования специальных символов, чтобы движок мог обрабатывать их как буквальные символы (например, в Java world \. будет объявлен как 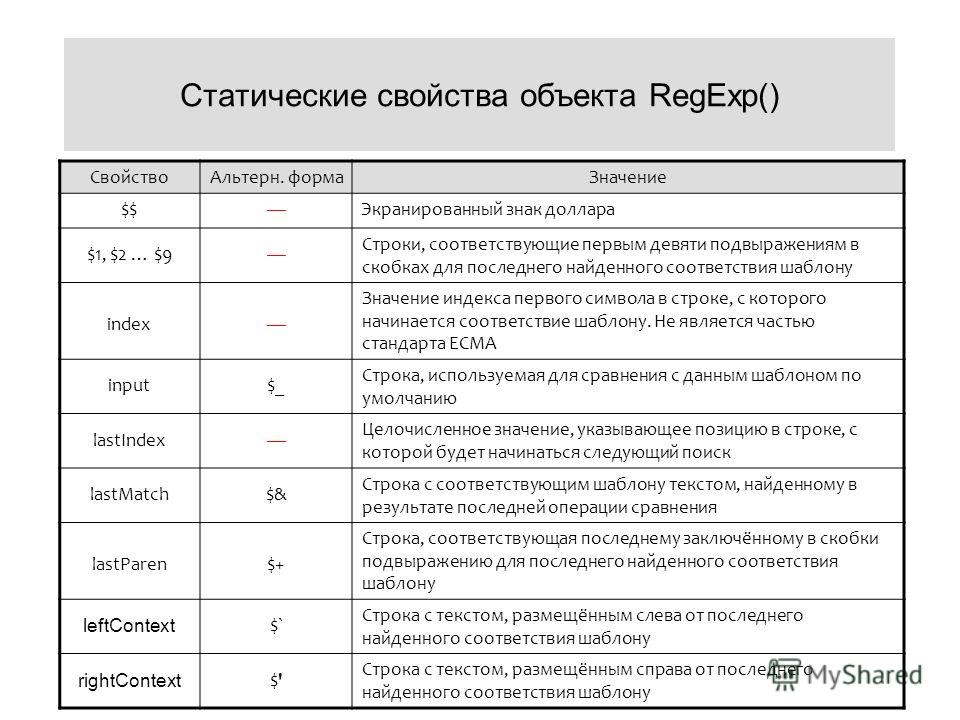
"world \\." или использовать класс символов: "world [.] "). Используйте необработанные строковые литералы (Python r '\ bworld \ b' ), дословные строковые литералы C # @" world \. " или буквальные обозначения строк / регулярных выражений с косой чертой, такие как /world\./
Учебное пособие и шпаргалка по
Regexp · YourBasic Go
yourbasic.org/golang
Регулярное выражение — это последовательность символов, определяющая шаблон поиска.
Основы
Регулярное выражение a.b соответствует любой строке,
начинается с a , заканчивается b ,
и состоит из одного символа между ними (точка соответствует любому символу).a.b $ `,» aaxbb «)
fmt.Println (соответствует)
Точно так же мы можем проверить, начинается ли строка с или заканчивается шаблоном, используя только начальную или конечную привязку.
Компиляция
Для более сложных запросов следует скомпилировать регулярное выражение для создания
объект Regexp .
Есть два варианта:
re1, ошибка: = regexp.Compile (`regexp`)
re2: = regexp.MustCompile (`regexp`) Сырые струны
Удобно использовать `raw strings` при написании регулярных выражений,
поскольку как обычные строковые литералы, так и регулярные выражения используют обратную косую черту для специальных символов.
Необработанная строка, разделенная обратными кавычками, интерпретируется буквально, а обратная косая черта не имеет особого значения.
Шпаргалка
Выбор и группировка
| Регулярное выражение | Значение |
|---|---|
xy | x , за которым следует y |
x | y | x или y , предпочтительнее x |
xy | z | то же, что и (xy) | z |
xy * | то же, что и x (y *) |
Повторение (жадное и нежадное)
| Регулярное выражение | Значение |
|---|---|
x * | ноль или больше x, предпочитаю больше |
х *? | предпочитают меньше (не жадные) |
х + | один или несколько x, предпочитаю больше |
х +? | предпочитают меньше (не жадные) |
х? | ноль или один x, предпочитаю один |
х ?? | предпочитаю ноль |
x {n} | ровно n x |
Классы символов
| Выражение | Значение | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
. буквально, экранируйте его обратной косой чертой. Например, \ { соответствует символу открывающей скобки.Другие escape-последовательности:
Якоря границы текста
Многострочные совпадения без учета регистра Чтобы изменить поведение сопоставления по умолчанию, вы можете добавить набор флагов | ||||||||||||||||||||||||||||||
с | лет . соответствует \ n (однострочный режим) |
 $.|? * + - [] {} ()
$.|? * + - [] {} ()  и
и Примеры кода
Первый матч
Используйте метод FindString
чтобы найти текст первого совпадения .
Если совпадений нет, возвращаемое значение — пустая строка.
re: = regexp.MustCompile (`foo.?`)
fmt.Printf ("% q \ n", re.FindString ("дурак морепродуктов"))
fmt.Printf ("% q \ n", re.FindString ("мясо")) Расположение
Используйте метод FindStringIndex
чтобы найти loc , местоположение первого совпадения , в строке s .
Совпадение происходит через с [loc [0]: loc [1]] . Возвращаемое значение nil указывает на отсутствие совпадения.
re: = regexp.MustCompile (`ab?`)
fmt.Println (re.FindStringIndex ("tablett"))
fmt.Println (re.FindStringIndex ("foo") == nil) Все совпадения
Используйте метод FindAllString
чтобы найти текст всех совпадений .
Возвращаемое значение nil указывает на отсутствие совпадения.
Метод принимает целочисленный аргумент n ;
если n> = 0 , функция возвращает не более n совпадений.
re: = regexp.MustCompile (`a.`)
fmt.Printf ("% q \ n", re.FindAllString ("паранормальное явление", -1))
fmt.Printf ("% q \ n", re.FindAllString («паранормальное явление»; 2))
fmt.Printf ("% q \ n", re.FindAllString ("graal", -1))
fmt.Printf ("% q \ n", re.FindAllString ("none", -1)) Заменить
Используйте метод ReplaceAllString
на заменить текст всех совпадений .
Он возвращает копию, заменяя все совпадения регулярного выражения строкой замены.
re: = regexp.MustCompile (`ab *`)
fmt.Printf ("% q \ n", re.ReplaceAllString ("- a-abb-", "T")) Сплит
Используйте метод Split
to разрезать строку на подстроки , разделенные регулярным выражением.Он возвращает фрагмент подстрок между этими совпадениями выражений.
Возвращаемое значение nil указывает на отсутствие совпадения.
Метод принимает целочисленный аргумент n ;
если n> = 0 , функция возвращает не более n совпадений.
a: = regexp.MustCompile (`a`)
fmt.Printf ("% q \ n", a.Split ("банан", -1))
fmt.Printf ("% q \ n", a.Split ("банан", 0))
fmt.Printf ("% q \ n", a.Split ("банан", 1))
fmt.Printf ("% q \ n", a.Split ("банан", 2))
zp: = регулярное выражение.MustCompile (`z +`)
fmt.Printf ("% q \ n", zp.Split ("пицца", -1))
fmt.Printf ("% q \ n", zp.Split ("пицца", 0))
fmt.Printf ("% q \ n", zp.Split ("пицца", 1))
fmt.Printf ("% q \ n", zp. Split ("пицца", 2))  Split ("пицца", 2))
Split ("пицца", 2)) Дополнительные функции
Имеется 16 функций в соответствии с шаблоном именования
Найти (все)? (Строка)? (Подсоответствие)? (Индекс)?
Например: Find , FindAllString , FindStringIndex ,…
- Если присутствует
Все, функция сопоставляет последовательные неперекрывающиеся совпадения. -
Строкауказывает, что аргумент является строкой; в противном случае это байтовый фрагмент. - Если присутствует
Submatch, возвращаемое значение является срезом последовательных подчиненных совпадений.
Подсоответствия — это совпадения заключенных в скобки подвыражений в регулярном выражении.
См. ПримерFindSubmatch. - Если присутствует
Index, совпадения и частичные совпадения идентифицируются парами байтовых индексов.
Реализация
- Пакет
regexpреализует регулярные выражения с синтаксисом RE2. - Он поддерживает строки в кодировке UTF-8 и классы символов Unicode.
- Реализация очень эффективна: время выполнения линейно зависит от размера ввода.
- Обратные ссылки не поддерживаются, поскольку они не могут быть эффективно реализованы.

Дополнительная литература
Сопоставление регулярных выражений может быть простым и быстрым (но медленным в Java, Perl, PHP, Python, Ruby,…).
Поделиться:
Написание правил YARA — yara 3.Документация 4.0
Правила YARA просты в написании и понимании, а их синтаксис
напоминает язык C. Вот простейшее правило, для которого можно писать
YARA, который абсолютно ничего не делает:
Каждое правило в YARA начинается с ключевого слова rule, за которым следует идентификатор правила.
Идентификаторы должны соответствовать тем же лексическим соглашениям, что и программирование на C.
языка, они могут содержать любые буквенно-цифровые символы и подчеркивание
символ, но первый символ не может быть цифрой. Идентификаторы правил
Идентификаторы правил
с учетом регистра и не может превышать 128 символов. Следующие ключевые слова:
зарезервировано и не может использоваться в качестве идентификатора:
Правила обычно состоят из двух разделов: определение строк и условие.
Раздел определения строк можно опустить, если правило не опирается ни на какие
строка, но всегда требуется раздел условия. Определение строк
Раздел — это место, где определяются строки, которые будут частью правила. Каждый
строка имеет идентификатор, состоящий из символа $, за которым следует последовательность
буквенно-цифровые символы и символы подчеркивания, эти идентификаторы можно использовать в
раздел condition для ссылки на соответствующую строку.Строки можно определить
в текстовой или шестнадцатеричной форме, как показано в следующем примере:
Текстовые строки заключаются в двойные кавычки, как в языке C. Шестигранник
строки заключаются в фигурные скобки и состоят из последовательности
шестнадцатеричные числа, которые могут быть смежными или разделенными пробелами. Десятичная дробь
Десятичная дробь
числа не допускаются в шестнадцатеричных строках.
Раздел условий — это то место, где находится логика правила. Этот раздел должен
содержать логическое выражение, указывающее, при каких обстоятельствах файл или процесс
удовлетворяет правилу или нет.Как правило, условие относится к ранее
определенные строки, используя их идентификаторы. В этом контексте строка
идентификатор действует как логическая переменная, которая оценивает значение true для строки, которая была
найдено в памяти файла или процесса, или false в противном случае.
Струны
В YARA есть три типа строк: шестнадцатеричные строки, текстовые строки и
обычные выражения. Шестнадцатеричные строки используются для определения необработанных последовательностей
байтов, в то время как текстовые строки и регулярные выражения полезны для определения
части разборчивого текста.Однако текстовые строки и регулярные выражения могут быть
также используется для представления необработанных байтов с помощью управляющих последовательностей, как будет
показано ниже.
Шестнадцатеричные строки
Шестнадцатеричные строки допускают три особые конструкции, которые делают их более
гибкость: подстановочные знаки, прыжки и альтернативы. Подстановочные знаки — это просто заполнители
что вы можете поместить в строку, указав, что некоторые байты неизвестны, и они
должно соответствовать чему угодно. Знак-заполнитель — это вопросительный знак (?). Здесь
у вас есть пример шестнадцатеричной строки с подстановочными знаками:
правило подстановочного знака Пример
{
струны:
$ hex_string = {E2 34 ?? C8 A? FB}
условие:
$ hex_string
}
Как показано в примере, подстановочные знаки являются полубайтами, что означает, что вы можете
определите только один полубайт байта и оставьте другой неизвестным.
Подстановочные знаки полезны при определении строк, содержимое которых может варьироваться, но вы знаете
длина переменных блоков, однако, это не всегда так. В некоторых
обстоятельства, вам может потребоваться определить строки с фрагментами переменного содержимого и
длина. В таких ситуациях вы можете использовать прыжки вместо подстановочных знаков:
правило JumpExample
{
струны:
$ hex_string = {F4 23 [4-6] 62 B4}
условие:
$ hex_string
}
В приведенном выше примере у нас есть пара чисел в квадратных скобках и
разделенные дефисом, это прыжок.Этот скачок указывает на то, что любой произвольный
Последовательность от 4 до 6 байтов может занимать позицию перехода. Любой из
следующие строки будут соответствовать шаблону:
F4 23 01 02 03 04 62 B4 F4 23 00 00 00 00 00 62 B4 F4 23 15 82 A3 04 45 22 62 B4
Любой прыжок [X-Y] должен соответствовать условию 0 <= X <= Y. В предыдущих версиях YARA и X, и Y должны быть меньше 256, но начиная с YARA 2.0 нет предел для X и Y.
Это допустимые прыжки:
FE 39 45 [0-8] 89 00 FE 39 45 [23-45] 89 00 FE 39 45 [1000-2000] 89 00
Это недействительно:
Если нижняя и верхняя границы равны, вы можете написать одно число, заключенное в скобки.
в скобках, например:
Вышеупомянутая строка эквивалентна обоим из них:
FE 39 45 [6-6] 89 00 FE 39 45 ?? ?? ?? ?? ?? ?? 89 00
Начиная с YARA 2.0 вы также можете использовать неограниченные прыжки:
FE 39 45 [10-] 89 00 FE 39 45 [-] 89 00
Первый означает [10-бесконечный] , второй означает [0-бесконечный] .
Есть также ситуации, в которых вы можете захотеть предоставить разные
альтернативы для данного фрагмента вашей шестнадцатеричной строки. В таких ситуациях вы
может использовать синтаксис, напоминающий регулярное выражение:
правила Альтернативы Пример1
{
струны:
$ hex_string = {F4 23 (62 B4 | 56) 45}
условие:
$ hex_string
}
Это правило будет соответствовать любому файлу, содержащему F42362B445 или F4235645 .
Но можно выразить и более двух альтернатив. На самом деле нет
ограничивает количество альтернативных последовательностей, которые вы можете предоставить, и ни
их длина.
правила Альтернативы Пример 2
{
струны:
$ hex_string = {F4 23 (62 B4 | 56 | 45 ?? 67) 45}
условие:
$ hex_string
}
Как видно из приведенного выше примера, строки, содержащие подстановочные знаки, являются
допускается как часть альтернативных последовательностей.
Текстовые строки
Как показано в предыдущих разделах, текстовые строки обычно определяются следующим образом:
правило TextExample
{
струны:
$ text_string = "foobar"
условие:
$ text_string
}
Это простейший случай: строка в кодировке ASCII с учетом регистра.Однако,
текстовые строки могут сопровождаться некоторыми полезными модификаторами, которые изменяют способ
что строка будет интерпретироваться. Эти модификаторы добавляются в конец
определение строки, разделенное пробелами, как будет описано ниже.
Текстовые строки также могут содержать следующее подмножество управляющих последовательностей
доступно на языке C:
\ " | Двойная кавычка |
\ | Обратная косая черта |
\ т | Горизонтальная вкладка |
\ n | Новая линия |
\ xdd | Любой байт в шестнадцатеричной системе счисления |
Строки без учета регистра
Текстовые строки в YARA по умолчанию чувствительны к регистру, однако вы можете
строка в режим без учета регистра, добавив модификатор nocase в конце
определения строки в той же строке:
правило CaseInsensitveTextExample
{
струны:
$ text_string = "foobar" нет
условие:
$ text_string
}
С модификатором nocase строка foobar будет соответствовать Foobar , FOOBAR ,
и фоБар .Этот модификатор можно использовать вместе с любым другим модификатором.
Строки расширенных символов
Модификатор wide может использоваться для поиска строк, закодированных двумя байтами.
на символ, что типично для многих исполняемых двоичных файлов.
На приведенном выше рисунке строка «Borland» отображается в кодировке как два байта на
символ, поэтому будет соответствовать следующее правило:
правило WideCharTextExample
{
струны:
$ wide_string = ширина "Borland"
условие:
$ wide_string
}
Однако имейте в виду, что этот модификатор просто чередует коды ASCII
символы в строке с нулями, он не поддерживает по-настоящему UTF-16
строки, содержащие неанглийские символы.Если вы хотите искать строки
как в ASCII, так и в широкой форме, вы можете использовать модификатор ascii вместе
с шириной , независимо от того, в каком порядке они появляются.
правило WideCharTextExample
{
струны:
$ wide_and_ascii_string = "Borland" широкий ascii
условие:
$ wide_and_ascii_string
}
Модификатор ascii может появляться вместе, без сопровождающего шириной
модификатор, но писать его необязательно, так как при отсутствии шириной
По умолчанию предполагается, что строка имеет формат ASCII.
Поиск полных слов
Другой модификатор, который можно применить к текстовым строкам, — это fullword . Этот
модификатор гарантирует, что строка будет совпадать, только если она появится в файле
разделены не буквенно-цифровыми символами. Например строка домен , если
определяется как fullword , не соответствует www.mydomain.com , но соответствует
www.my-domain.com и www.domain.com .
Регулярные выражения
Регулярные выражения — одна из самых мощных функций YARA.Они есть
определены так же, как текстовые строки, но вместо этого заключены в обратную косую черту
двойных кавычек, как в языке программирования Perl.
правило RegExpExample1
{
струны:
$ re1 = / md5: [0-9a-zA-Z] {32} /
$ re2 = / состояние: (вкл | выкл) /
условие:
$ re1 и $ re2
}
За регулярными выражениями также может следовать nocase , ascii , wide ,
и модификаторы fullword , как и в текстовых строках.
$ | () [] Также распознаются следующие количественные показатели:
* | Совпадение 0 или более раз |
+ | Совпадение 1 или более раз |
? | Совпадение 0 или 1 раз |
{n} | Совпадение ровно n раз |
{n,} | Совпадение не менее n раз |
{, m} | Совпадение от 0 до m раз |
{n, m} | Сопоставьте n и m раз |
У всех этих квантификаторов есть нежадный вариант, за которым следует вопрос
марка (?):
*? | Соответствует 0 или более раз, нежадный |
+? | Совпадение 1 или более раз, нежадный |
?? | Совпадение 0 или 1 раз, нежадное |
{n}? | Совпадение ровно n раз, нежадный |
{n,}? | Совпадение не менее n раз, нежадное |
{, м}? | Совпадение от 0 до m раз, нежадный |
{n, m}? | Сопоставьте n с m раз, нежадный |
Распознаются следующие escape-последовательности:
\ т | Вкладка (HT, TAB) |
\ n | Новая линия (LF, NL) |
\ r | Возврат (CR) |
\ n | Новая линия (LF, NL) |
\ f | Подача формы (FF) |
\ a | Колокольчик |
\ xNN | Символ, порядковый номер которого является заданным шестнадцатеричным числом |
Это признанные классы символов:
\ w | Соответствует слову символу (буквенно-цифровое плюс «_») |
\ Вт | Соответствует символу, отличному от слова |
\ с | Соответствует пробельному символу |
\ S | Соответствует непробельному символу |
\ d | Соответствует символу десятичной цифры |
\ D | Соответствует нецифровому символу |
Начиная с версии 3.3.0 также признаются эти утверждения с нулевым коэффициентом:
\ b | Соответствует границе слова |
\ B | Совпадение без границы слова |
Условия
Условия — это не что иное, как логические выражения, такие как те, которые можно найти
на всех языках программирования, например, в операторе if . Они могут содержать
типичные логические операторы and, or and not и операторы отношения
> =, <=, <,>, == и! =.) можно использовать на числовых
выражения.
Строковые идентификаторы также могут использоваться в условии, действуя как логическое значение.
переменные, значение которых зависит от наличия или отсутствия связанной строки
в файле.
Пример правила
{
струны:
$ a = "text1"
$ b = "текст2"
$ c = "text3"
$ d = "text4"
условие:
($ a или $ b) и ($ c или $ d)
}
Счетные строки
Иногда нам нужно знать не только, присутствует ли определенная строка,
но сколько раз строка появляется в памяти файла или процесса.Номер
вхождений каждой строки представлена переменной, имя которой
строковый идентификатор, но с символом # вместо символа $.
Например:
правило CountExample
{
струны:
$ a = "dummy1"
$ b = "dummy2"
условие:
#a == 6 и #b> 10
}
Эти правила соответствуют любому файлу или процессу, содержащему строку $ a, ровно шесть раз,
и более десяти вхождений строки $ b.
Смещения строки или виртуальные адреса
В большинстве случаев, когда в условии используется строковый идентификатор, мы
хотят знать, находится ли связанная строка где-нибудь в файле или
память процесса, но иногда нам нужно знать, находится ли строка в каком-то конкретном
смещение в файле или по некоторому виртуальному адресу в адресном пространстве процесса.В таких ситуациях нам нужен оператор по адресу . Этот оператор используется как
показано в следующем примере:
правило AtExample
{
струны:
$ a = "dummy1"
$ b = "dummy2"
условие:
$ a по цене 100 и $ b по цене 200
}
Выражение $ a по адресу 100 в приведенном выше примере истинно, только если строка $ a
найдено по смещению 100 в файле (или по виртуальному адресу 100, если применяется к
запущенный процесс). Строка $ b должна появиться по смещению 200.Пожалуйста, обрати внимание
что оба смещения являются десятичными, однако шестнадцатеричные числа могут быть записаны
добавление префикса 0x перед числом, как в языке C, что очень
удобно при написании виртуальных адресов. Также обратите внимание на более высокий приоритет
оператор на вместо и .
В то время как оператор at позволяет искать строку с некоторым фиксированным смещением в
файл или виртуальный адрес в пространстве памяти процесса, оператор в
позволяет искать строку в диапазоне смещений или адресов.
правило InExample
{
струны:
$ a = "dummy1"
$ b = "dummy2"
условие:
$ a в (0..100) и $ b в (100..filesize)
}
В приведенном выше примере строка $ a должна быть найдена со смещением от 0 до
100, а строка $ b должна иметь смещение от 100 до конца файла.
Опять же, числа по умолчанию являются десятичными.
Вы также можете получить смещение или виртуальный адрес i-го вхождения строки
$ a с помощью @a [i]. Индексы отсчитываются от единицы, поэтому первое вхождение будет
@a [1] второй @a [2] и так далее.Если вы укажете индекс больше, чем
количество вхождений строки, результатом будет NaN (не число)
стоимость.
Размер файла
Строковые идентификаторы — не единственные переменные, которые могут появляться в условии.
(на самом деле правила могут быть определены без какого-либо строкового определения, как будет показано ниже).
ниже), можно использовать и другие специальные переменные. Один из
эти особые переменные — px , которые, как видно из названия,
размер сканируемого файла.20. Оба постфикса можно использовать только с десятичными константами.
Использование px имеет смысл только тогда, когда правило применяется к файлу, если
правило, применяемое к запущенному процессу, никогда не будет совпадать, потому что px
не имеет смысла в этом контексте.
Исполняемая точка входа
Другая специальная переменная, которую можно использовать в правиле, — это точка входа . Если файл
это Portable Executable (PE) или Executable and Linkable Format (ELF), это
переменная содержит исходное смещение точки входа исполняемого файла на случай, если мы
сканирование файла.Если мы сканируем запущенный процесс, точка входа будет удерживать
виртуальный адрес точки входа основного исполняемого файла. Типичное использование
эта переменная предназначена для поиска некоторого шаблона в точке входа для обнаружения пакеров
или простые файловые инфекторы.
правило EntryPointExample1
{
струны:
$ a = {E8 00 00 00 00}
условие:
$ a в точке входа
}
правило EntryPointExample2
{
струны:
$ a = {9C 50 66 A1 ?? ?? ?? 00 66 A9 ?? ?? 58 0F 85}
условие:
$ a в (точка входа..entrypoint + 10)
}
Наличие в правиле переменной entrypoint означает, что только PE или
Файлы ELF могут удовлетворять этому правилу. Если файл не является PE или ELF, любое правило, использующее
эта переменная принимает значение false.
Предупреждение
Переменная точки входа устарела, следует использовать
эквивалент pe.entry_point из модуля PE. Запуск
с YARA 3.0 вы получите предупреждение, если используете точку входа , и это будет
полностью удален в будущих версиях.
Доступ к данным в заданной позиции
Есть много ситуаций, в которых вы можете захотеть написать условия, которые
зависит от данных, хранящихся в определенном файловом смещении или виртуальном адресе памяти,
в зависимости от того, сканируем ли мы файл или работающий процесс. В тех ситуациях
вы можете использовать одну из следующих функций для чтения данных из файла по заданному смещению:
int8 (<смещение или виртуальный адрес>) int16 (<смещение или виртуальный адрес>) int32 (<смещение или виртуальный адрес>) uint8 (<смещение или виртуальный адрес>) uint16 (<смещение или виртуальный адрес>) uint32 (<смещение или виртуальный адрес>) int8be (<смещение или виртуальный адрес>) int16be (<смещение или виртуальный адрес>) int32be (<смещение или виртуальный адрес>) uint8be (<смещение или виртуальный адрес>) uint16be (<смещение или виртуальный адрес>) uint32be (<смещение или виртуальный адрес>)
Функции intXX читают 8-, 16- и 32-битные целые числа со знаком из
<смещение или виртуальный адрес>, а функции uintXX читают беззнаковые целые числа.И 16-, и 32-битные целые числа считаются прямым порядком байтов. если ты
хотите прочитать целое число с прямым порядком байтов, используйте соответствующую функцию, заканчивающуюся
в быть . Параметр <смещение или виртуальный адрес> может быть любым выражением, возвращающим целое число без знака, включая возвращаемое значение одной из функций uintXX . В качестве примера рассмотрим правило различения файлов PE:
правило IsPE
{
условие:
// Подпись MZ со смещением 0 и ...
uint16 (0) == 0x5A4D и
//... Подпись PE по смещению, хранящемуся в заголовке MZ в 0x3C
uint32 (uint32 (0x3C)) == 0x00004550
}
Наборы струн
Существуют обстоятельства, при которых необходимо указать, что файл должен
содержат определенные числовые строки из заданного набора. Ни одна из струн в
set должны присутствовать, но по крайней мере некоторые из них должны быть. В этих
ситуации, когда на помощь приходит оператор.
правило OfExample1
{
струны:
$ a = "dummy1"
$ b = "dummy2"
$ c = "dummy3"
условие:
2 из ($ a, $ b, $ c)
}
Это правило гласит, что по крайней мере две строки в наборе ($ a, $ b, $ c)
должен присутствовать в файле, независимо от того, какой.Конечно, при использовании этого
оператор, число перед ключевого слова должно быть равно или меньше чем
количество струн в наборе.
Элементы набора могут быть явно пронумерованы, как в предыдущем
пример, или можно указать с помощью подстановочных знаков. Например:
правило OfExample2
{
струны:
$ foo1 = "foo1"
$ foo2 = "foo2"
$ foo3 = "foo3"
условие:
2 из ($ foo *) / * эквивалентно 2 из ($ foo1, $ foo2, $ foo3) * /
}
правило OfExample3
{
струны:
$ foo1 = "foo1"
$ foo2 = "foo2"
$ bar1 = "bar1"
$ bar2 = "bar2"
условие:
3 из ($ foo *, $ bar1, $ bar2)
}
Вы даже можете использовать ($ *) для ссылки на все строки в вашем правиле или написать
эквивалентное ключевое слово им для большей разборчивости.
правило OfExample4
{
струны:
$ a = "dummy1"
$ b = "dummy2"
$ c = "dummy3"
условие:
1 из них / * эквивалент 1 из ($ *) * /
}
Во всех приведенных выше примерах количество строк было указано
числовая константа, но можно использовать любое выражение, возвращающее числовое значение.
Также можно использовать ключевые слова any и all.
все из них / * все строки в правиле * / любой из них / * любая строка в правиле * / all of ($ a *) / * все строки, идентификатор которых начинается с $ a * / любой из ($ a, $ b, $ c) / * любой из $ a, $ b или $ c * / 1 из ($ *) / * то же, что «любой из них» * /
Применение одного и того же условия ко многим строкам
Есть еще один оператор, очень похожий на из , но еще более мощный,
для..оператора . Синтаксис:
для выражения набора_строк: (логическое_выражение)
И его значение: из тех строк в string_set по крайней мере выражение
из них должно удовлетворять boolean_expression .
Другими словами: boolean_expression оценивается для каждой строки в
string_set и должно быть не менее выражений из них, возвращающих True.
Конечно, boolean_expression может быть любым логическим выражением, допустимым в
раздел условия правила, за исключением одной важной детали: здесь вы
может (и должен) использовать знак доллара ($) в качестве заполнителя для строки, являющейся
оценен.Взгляните на следующее выражение:
для любого из ($ a, $ b, $ c): ($ в точке входа)
Символ $ в логическом выражении не привязан к какой-либо конкретной строке,
это будет $ a, а затем $ b, а затем $ c в трех последовательных вычислениях
выражения.
Возможно, вы уже поняли, что оператор из — это частный случай
для..из . Следующие выражения совпадают:
любой из ($ a, $ b, $ c) для любого из ($ a, $ b, $ c): ($)
Вы также можете использовать символы # и @ для обозначения количества
вхождений и первое смещение каждой строки соответственно.
для всех: (#> 3) для всех ($ a *): (@> @b)
Использование анонимных строк с
из и для .. из
При использовании из и для .. из операторов, за которыми следуют
идентификатор, присвоенный каждой строке правила, обычно лишний. В виде
мы не ссылаемся ни на одну строку по отдельности, которую нам не нужно предоставлять
уникальный идентификатор для каждого из них. В таких ситуациях вы можете объявить
анонимные строки с идентификаторами, состоящими только из символа $, как в
следующий пример:
правило AnonymousStrings
{
струны:
$ = "dummy1"
$ = "dummy2"
условие:
1 из них
}
Итерация по вхождению строки
Как видно из строковых смещений или виртуальных адресов, смещения или виртуальные адреса, в которых заданы
строка появляется в файле, или к адресному пространству процесса можно получить доступ
используя синтаксис: @a [i], где i — индекс, указывающий, какое вхождение
строки $ a, о которой вы говорите.(@a [1], @a [2], …).
Иногда вам нужно перебрать некоторые из этих смещений и гарантировать
они удовлетворяют заданному условию. Например:
правило возникновения
{
струны:
$ a = "dummy1"
$ b = "dummy2"
условие:
для всех i в (1,2,3): (@a [i] + 10 == @b [i])
}
Предыдущее правило гласит, что первые три вхождения $ b должны быть 10
байтов от первых трех вхождений $ a.
То же условие можно записать также как:
для всех i в (1..3): (@a [i] + 10 == @b [i])
Обратите внимание, что мы используем диапазон (1–3) вместо перечисления индекса.
значения (1,2,3). Конечно, мы не обязаны использовать константы для указания диапазона
границ, мы также можем использовать выражения, как в следующем примере:
для всех i в (1 .. # a): (@a [i] <100)
В этом случае мы перебираем каждое вхождение $ a (помните, что #a
представляет количество вхождений $ a). Это правило говорит о том, что каждый
вхождение $ a должно быть в пределах первых 100 байтов файла.
В случае, если вы хотите выразить, что только некоторые вхождения строки
должен удовлетворять вашему условию, та же логика, что и в операторе for..of
применяется здесь:
для любого i в (1 .. # a): (@a [i] <100) для 2 i в (1 .. # a): (@a [i] <100)
В резюме синтаксис этого оператора:
для идентификатора выражения в индексах: (логическое_выражение)
Ссылка на другие правила
При написании условия для правила вы также можете ссылаться на
ранее определенное правило способом, который напоминает вызов функции
традиционные языки программирования.Таким образом вы можете создавать правила, которые
зависит от других. Давайте посмотрим на пример:
правило Правило1
{
струны:
$ a = "dummy1"
условие:
$ а
}
Правило Правило2
{
струны:
$ a = "dummy2"
условие:
$ a и Правило1
}
Как видно из примера, файл удовлетворяет Правилу 2, только если он содержит
строка «dummy2» и удовлетворяет Правилу 1. Обратите внимание, что строго необходимо
определить вызываемое правило перед тем, которое будет вызывать.
Подробнее о правилах
Некоторые аспекты правил YARA еще не рассмотрены, но все же
очень важны. Это: глобальные правила, частные правила, теги и метаданные.
Глобальные правила
Глобальные правила дают вам возможность вводить ограничения во всех ваших
правила сразу. Например, предположим, что вы хотите, чтобы все ваши правила игнорировались.
те файлы, которые превышают определенный предел размера, вы можете следовать правилу за правилом, выполняя
необходимые изменения в их условиях, или просто напишите глобальное правило
как этот:
глобальное правило SizeLimit
{
условие:
размер файла <2 МБ
}
Вы можете определить столько глобальных правил, сколько хотите, они будут оцениваться
перед остальными правилами, которые, в свою очередь, будут оцениваться только из всех
глобальные правила выполнены.
Частные правила
Частные правила - очень простая концепция. Это просто правила, которых нет
сообщает YARA, когда они совпадают в данном файле. Правила, о которых не сообщается
на первый взгляд может показаться бесплодным, но в сочетании с возможностью
предложенный YARA ссылки одного правила из другого (см.
Ссылаясь на другие правила) они становятся полезными. Частные правила могут служить
строительные блоки для других правил, и в то же время предотвращают загромождение
Вывод YARA с нерелевантной информацией.Для объявления правила частным
просто добавьте ключевое слово private перед объявлением правила.
частное правило PrivateRuleExample
{
...
}
К правилу можно применить модификаторы private и global , в результате
глобальное правило, о котором не сообщает YARA, но которое должно выполняться.
Использование модулей
Модули
- это расширения основных функций YARA. Некоторые модули, такие как
модуль PE и модуль Cuckoo
официально распространяются вместе с YARA, и некоторые из них могут быть созданы
третьими сторонами или даже вами, как описано в разделе Написание собственных модулей.
Первым шагом к использованию модуля является его импорт с помощью оператора import .
Эти утверждения должны быть помещены вне любого определения правила и сопровождаться
имя модуля заключено в двойные кавычки. Как это:
импортный "пэ" импорт "кукушка"
После импорта модуля вы можете использовать его функции, всегда используя
<имя модуля>. в качестве префикса к любой переменной или функции, экспортируемой
модуль. Например:
pe.entry_point == 0x1000 кукушка.http_request (/ someregexp /)
Модули
часто оставляют переменные в неопределенном состоянии, например, когда переменная
не имеет смысла в текущем контексте (подумайте о pe.entry_point , а
сканирование файла, отличного от PE). YARA обрабатывает неопределенные значения таким образом, чтобы
правило, чтобы сохранить его осмысленность. Взгляните на это правило:
импортный "пэ"
проверка правил
{
струны:
$ a = "какая-то строка"
условие:
$ a и pe.entry_point == 0x1000
}
Если отсканированный файл не является PE, вы не ожидаете, что это правило будет соответствовать файлу,
даже если он содержит строку, потому что оба условия (наличие
строка и правильное значение для точки входа) должны быть выполнены.Однако если
состояние изменено на:
$ a или pe.entry_point == 0x1000
В этом случае можно ожидать совпадения правил, если файл содержит строку,
даже если это не PE-файл. Именно так ведет себя YARA. Логика проста:
любая арифметическая операция, сравнение или логическая операция приведет к неопределенному значению
если один из его операндов не определен, за исключением операций OR , где неопределенный
операнд интерпретируется как ложь.
Внешние переменные
Внешние переменные позволяют определять правила, которые зависят от предоставленных значений.
снаружи.Например, вы можете написать следующее правило:
правило ExternalVariableExample1
{
условие:
ext_var == 10
}
В этом случае ext_var - внешняя переменная, значение которой присваивается
время выполнения (см. параметр -d инструмента командной строки и параметр externals программы
компилирует и соответствует методам в yara-python). Внешние переменные могут быть
типов: целое, строковое или логическое; их тип зависит от присвоенного значения
им.Целочисленная переменная может заменять любую целочисленную константу в
Условные и логические переменные могут занимать место логических выражений.
Например:
правило ExternalVariableExample2
{
условие:
bool_ext_var или размер файла Внешние переменные типа string могут использоваться с операторами contains и
Спички. содержит оператор возвращает истину, если строка содержит
указанная подстрока. Оператор соответствует возвращает истину, если строка
соответствует заданному регулярному выражению.
правило ExternalVariableExample3
{
условие:
string_ext_var содержит «текст»
}
правило ExternalVariableExample4
{
условие:
string_ext_var соответствует / [a-z] + /
}
Вы можете использовать модификаторы регулярного выражения вместе с оператором соответствует ,
например, если вы хотите, чтобы регулярное выражение из предыдущего примера
чтобы регистр не учитывался, можно использовать / [a-z] + / i . Обратите внимание на i после
регулярное выражение в стиле Perl.Вы также можете использовать модификатор s
для однострочного режима точка соответствует всем символам, включая
разрывы строк. Конечно, оба модификатора можно использовать одновременно, как в
следующий пример:
правило ExternalVariableExample5
{
условие:
/ * однострочный режим без учета регистра * /
string_ext_var соответствует / [a-z] + / равно
}
Имейте в виду, что каждая внешняя переменная, используемая в ваших правилах, должна быть определена.
во время выполнения, либо с помощью параметра -d инструмента командной строки, либо с помощью
предоставление параметра externals соответствующему методу в
яра-питон .
Конфигурация
- документация Sphinx
# тестовая документация файл конфигурации сборки, созданный
# sphinx-quickstart, вс, 26 июня, 00:00:43, 2016.
#
# Это файл execfile () d с текущим каталогом, установленным на его
# содержащий dir.
#
# Обратите внимание, что не все возможные значения конфигурации представлены в этом
# автоматически сгенерированный файл.
#
# Все значения конфигурации имеют значение по умолчанию; закомментированные значения
# служить для отображения значения по умолчанию.
# Если расширения (или модули для документирования с помощью autodoc) находятся в другом каталоге,
# добавить эти каталоги в sys.путь сюда. Если каталог относительно
# документация root, используйте os.path.abspath, чтобы сделать его абсолютным, как показано здесь.
#
# import os
# import sys
# sys.path.insert (0, os.path.abspath ('.'))
# - Общая конфигурация --------------------------------------------- ---
# Если вашей документации требуется минимальная версия Sphinx, укажите ее здесь.
#
# needs_sphinx = '1.0'
# Добавьте сюда любые имена модулей расширения Sphinx в виде строк. Они могут быть
# расширения, поставляемые со Sphinx (названные 'sphinx.ext. *') или ваши собственные
# ед.extension = []
# Добавьте сюда любые пути, содержащие шаблоны, относительно этого каталога.
templates_path = ['_templates']
# Суффикс (а) имен исходных файлов.
# Вы можете указать несколько суффиксов в виде списка строк:
#
# source_suffix = ['.rst', '.md']
source_suffix = '.rst'
# Кодировка исходных файлов.
#
# source_encoding = 'utf-8-sig'
# Главный документ с деревом дерева.
root_doc = 'индекс'
# Общая информация о проекте.
проект = u'test '
copyright = u'2016, test '
автор = u'test '
# Информация о версии документируемого проекта действует как замена
# | версия | и | release |, также используются в различных других местах по всему миру.
# построенных документов.#
# Краткая версия X.Y.
версия = u'test '
# Полная версия, включая теги alpha / beta / rc.
release = u'test '
# Язык контента, автоматически созданного Sphinx. Обратитесь к документации
# для списка поддерживаемых языков.
#
# Это также используется, если вы выполняете перевод контента через каталоги gettext.
# Обычно для этих случаев вы устанавливаете "язык" из командной строки.
language = None
# Есть два варианта замены | today |: либо, вы установили сегодня на некоторые
# не ложное значение, тогда оно используется:
#
# сегодня = ''
#
# Иначе, today_fmt используется как формат для вызова strftime.#
# today_fmt = '% B% d,% Y'
# Список шаблонов относительно исходного каталога, которые соответствуют файлам и
# каталоги, которые следует игнорировать при поиске исходных файлов.
# Эти шаблоны также влияют на html_static_path и html_extra_path
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
# Роль reST по умолчанию (используется для этой разметки: `text`), чтобы использовать для всех
# документов.
#
# default_role = Нет
# Если true, к тексту перекрестной ссылки: func: etc. будет добавлен '()'.
#
# add_function_parentheses = Истина
# Если true, то имя текущего модуля будет добавлено ко всему описанию
# заголовки модулей (например,.. функция: :).
#
# add_module_names = True
# Если true, директивы sectionauthor и moduleauthor будут показаны в
# выход. По умолчанию они игнорируются.
#
# show_authors = Ложь
# Имя используемого стиля Pygments (подсветка синтаксиса).
pygments_style = 'сфинкс'
# Список игнорируемых префиксов для сортировки индекса модуля.
# modindex_common_prefix = []
# Если true, в созданных документах сохранять предупреждения в виде абзацев "системного сообщения".
# keep_warnings = Ложь
# Если true, `todo` и` todoList` производят вывод, иначе они ничего не производят.todo_include_todos = Ложь
# - Параметры вывода HTML ------------------------------------------- ---
# Тема для использования на страницах справки HTML и HTML. Документацию для
# список встроенных тем.
#
html_theme = 'алебастр'
# Параметры темы зависят от темы и настраивают внешний вид темы
# дальше. Список параметров, доступных для каждой темы, см.
# документация.
#
# html_theme_options = {}
# Добавьте сюда любые пути, содержащие пользовательские темы, относительно этого каталога.# html_theme_path = []
# Имя для этого набора документов Sphinx.
# "<проект> v <выпуск> документация" по умолчанию.
#
# html_title = u'test vtest '
# Более короткий заголовок для панели навигации. По умолчанию то же, что и html_title.
#
# html_short_title = Нет
# Имя файла изображения (относительно этого каталога) для размещения вверху
# боковой панели.
#
# html_logo = Нет
# Имя файла изображения (относительно этого каталога) для использования в качестве значка
# документы. Этот файл должен быть файлом значка Windows (.ico) размером 16x16 или 32x32
# пикселя больше.
#
# html_favicon = Нет
# Добавьте сюда любые пути, которые содержат пользовательские статические файлы (например, таблицы стилей),
# относительно этого каталога. Они копируются после встроенных статических файлов,
# поэтому файл с именем "default.css" перезапишет встроенный "default.css".
html_static_path = ['_static']
# Добавьте любые дополнительные пути, содержащие пользовательские файлы (например, robots.txt или
# .htaccess) здесь относительно этого каталога. Эти файлы скопированы
# прямо в корень документации.#
# html_extra_path = []
# Если не None, отметка времени "Последнее обновление:" вставляется на каждой странице
# снизу, используя заданный формат strftime.
# Пустая строка эквивалентна "% b% d,% Y".
#
# html_last_updated_fmt = Нет
# Пользовательские шаблоны боковой панели, сопоставляют имена документов с именами шаблонов.
#
# html_sidebars = {}
# Дополнительные шаблоны, которые должны отображаться на страницах, сопоставляют имена страниц с
# имена шаблонов.
#
# html_additional_pages = {}
# Если false, индекс модуля не создается.
#
# html_domain_indices = True
# Если false, индекс не создается.#
# html_use_index = True
# Если true, индекс разбивается на отдельные страницы для каждой буквы.
#
# html_split_index = False
# Если true, на страницы добавляются ссылки на источники reST.
#
# html_show_sourcelink = True
# Если true, в нижнем колонтитуле HTML отображается «Создано с использованием Sphinx». По умолчанию True.
#
# html_show_sphinx = True
# Если true, в нижнем колонтитуле HTML отображается "(C) Copyright ...". По умолчанию True.
#
# html_show_copyright = True
# Если true, будет выведен файл описания OpenSearch, и все страницы будут
# содержат относящийся к нему тег .Значение этой опции должно быть
# базовый URL-адрес, с которого передается готовый HTML.
#
# html_use_opensearch = ''
# Это суффикс имени файла для файлов HTML (например, ".xhtml").
# html_file_suffix = Нет
# Язык, который будет использоваться для создания индекса полнотекстового поиска HTML.
# Sphinx поддерживает следующие языки:
# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'.
# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr', 'zh'.
#
# html_search_language = 'ru'
# Словарь с опциями для поддержки языка поиска, по умолчанию пустой.# 'ja' использует это значение конфигурации.
# Пользователь 'zh' может изменить путь словаря 'jieba`.
#
# html_search_options = {'type': 'default'}
# Имя файла javascript (относительно каталога конфигурации), который
# реализует систему оценки результатов поиска. Если пусто, будет использоваться значение по умолчанию.
#
# html_search_scorer = 'scorer.js'
# Базовое имя выходного файла для построителя HTML-справки.
htmlhelp_basename = 'testdoc'
# - Опции вывода LaTeX ------------------------------------------- -
latex_elements = {
# Размер бумаги («бумага для писем» или «бумага формата a4»).#
# 'paperize': 'letterpaper',
# Размер шрифта ('10pt', '11pt' или '12pt').
#
# 'pointsize': '10pt',
# Дополнительный материал для преамбулы LaTeX.
#
# 'преамбула': '',
# Выравнивание фигур в латексе (поплавок)
#
# 'figure_align': 'htbp',
}
# Группирование дерева документов в файлы LaTeX. Список кортежей
# (исходный стартовый файл, имя цели, заголовок,
# автор, класс документа [руководство, руководство или собственный класс]).
latex_documents = [
(root_doc, 'test.tex', u'test Documentation ',
u'test ',' manual '),
]
# Имя файла изображения (относительно этого каталога) для размещения в верхней части
# титульная страница.#
# latex_logo = Нет
# Если true, показывать ссылки на страницы после внутренних ссылок.
#
# latex_show_pagerefs = Ложь
# Если true, показывать URL-адреса после внешних ссылок.
#
# latex_show_urls = Ложь
# Документы для добавления в качестве приложения ко всем руководствам.
#
# latex_appendices = []
# Если false, индекс модуля не создается.
#
# latex_domain_indices = True
# - Опции для вывода страниц руководства ---------------------------------------
# Одна запись на страницу руководства. Список кортежей
# (исходный стартовый файл, название, описание, авторы, раздел руководства).man_pages = [
(root_doc, 'test', u'test Documentation ',
[автор], 1)
]
# Если true, показывать URL-адреса после внешних ссылок.
#
# man_show_urls = Ложь
# - Опции вывода Texinfo -------------------------------------------
# Группирование дерева документов в файлы Texinfo. Список кортежей
# (исходный стартовый файл, имя цели, заголовок, автор,
# dir пункт меню, описание, категория)
texinfo_documents = [
(root_doc, 'test', u'test Documentation ',
автор, 'тест', 'Однострочное описание проекта.',
'Разнообразный'),
]
# Документы для добавления в качестве приложения ко всем руководствам.
#
# texinfo_appendices = []
# Если false, индекс модуля не создается.
#
# texinfo_domain_indices = True
# Как отображать URL-адреса: 'сноска', 'нет' или 'встроенный'.
#
# texinfo_show_urls = 'footnote'
# Если true, не генерировать @detailmenu в меню узла "Top".
#
# texinfo_no_detailmenu = Ложь
# - Случайный пример -------------------------------------------- ---------
import sys, os
sys.path.insert (0, os.path.abspath ('.'))
exclude_patterns = ['zzz']
numfig = Истина
#language = 'ja'
extension.append ('sphinx.ext.todo')
extension.append ('sphinx.ext.autodoc')
# extension.append ('sphinx.ext.autosummary')
extension.append ('sphinx.ext.intersphinx')
extension.append ('sphinx.ext.mathjax')
extension.append ('sphinx.ext.viewcode')
extension.append ('sphinx.ext.graphviz')
autosummary_generate = Истина
html_theme = 'по умолчанию'
#source_suffix = ['.rst', '.txt']
Вакансий | GitLab
Конфигурация конвейера начинается с заданий.Работа - это самый важный элемент файла .gitlab-ci.yml .
Вакансий:
- Определяется с ограничениями, указывающими, при каких условиях они должны выполняться.
- Элементы верхнего уровня с произвольным именем и должны содержать как минимум условие
сценария . - Не ограничено, сколько может быть определено.
Например:
job1:
скрипт: «выполнить-скрипт-для-задания1»
job2:
скрипт: «выполнить-скрипт-для-задания2»
Приведенный выше пример представляет собой простейшую возможную конфигурацию CI / CD с двумя отдельными
задания, где каждое задание выполняет отдельную команду.Конечно, команда может выполнять код напрямую ( ./configure;make;make install )
или запустить скрипт ( test.sh ) в репозитории.
Задания подбираются бегунами и выполняются в
среда бегуна. Важно то, чтобы каждое задание выполнялось
независимо друг от друга.
Просмотр вакансий в конвейере
Когда вы обращаетесь к конвейеру, вы можете видеть связанные задания для этого конвейера.
При нажатии на отдельное задание отображается журнал заданий, который позволяет:
- Отмените задание.
- Повторите задание.
- Удалите журнал заданий.
Узнайте, почему не удалось выполнить задание
Когда конвейер выходит из строя или может выйти из строя, есть несколько мест, где вы
можно найти причину:
- На графике конвейера, в подробном представлении конвейера.
- В виджетах конвейера, на страницах мерж-реквестов и фиксации.
- В представлениях задания, в глобальных и подробных представлениях задания.
В каждом месте, если вы наводите курсор на неудачное задание, вы можете увидеть причину его сбоя.
В GitLab 10.8 и новее,
Вы также можете увидеть причину сбоя на странице сведений о задании.
Порядок выполнения работ в трубопроводе
Порядок заданий в конвейере зависит от типа конвейерного графа.
Степень серьезности:
- не удалось
- предупреждение
- на рассмотрении
- работает
- инструкция
- по расписанию
- аннулировано
- успех
- пропущено
- создано
Например:
Групповые задания в конвейере
Если у вас много похожих работ, ваш конвейерный график станет длинным и сложным.
читать.
Вы можете автоматически группировать похожие задания вместе. Если имена заданий отформатированы определенным образом,
они сворачиваются в одну группу в обычных конвейерных графах (а не на мини-графах).
Вы можете распознать, когда конвейер имеет сгруппированные задания, если вы не видите повтор или
кнопка отмены внутри них. При наведении курсора на них отображается количество сгруппированных
рабочие места. Щелкните, чтобы развернуть их.
Чтобы создать группу заданий, в файле конфигурации конвейера CI / CD,
разделите каждое название работы номером и одним из следующих значений:
- Косая черта (
/), например, тест 1/3 , тест 2/3 , тест 3/3 . - Двоеточие (
: ), например, тест 1: 3 , тест 2: 3 , тест 3: 3 . - Пробел, например
тест 0 3 , тест 1 3 , тест 2 3 .
Эти символы можно использовать как взаимозаменяемые.
В приведенном ниже примере эти три задания находятся в группе с именем build ruby :
build ruby 1/3:
этап: сборка
сценарий:
- эхо «рубин1»
построить рубин 2/3:
этап: сборка
сценарий:
- эхо «рубин2»
построить рубин 3/3:
этап: сборка
сценарий:
- эхо «рубин3»
В конвейере результатом является группа с именем build ruby с тремя заданиями:
Задания упорядочиваются путем сравнения чисел слева направо.Ты
обычно требуется, чтобы первое число было индексом, а второе число - общим числом.
Это регулярное выражение
оценивает имена вакансий: ([\ b \ s:] + ((\ [. * \]) | (\ d + [\ s: \ / \\] + \ d +))) + \ s * \ z .
Одна или несколько последовательностей : [...] , X Y , X / Y или X \ Y удаляются с конца
только названий должностей. Соответствующие подстроки, найденные в начале или в середине
имена вакансий не удаляются.
В GitLab 13.8 и более ранних версиях
регулярное выражение - \ d + [\ s: \ / \\] + \ d + \ s * .Флаг функции
удалено в GitLab 13.11.
Указание переменных при выполнении заданий вручную
При выполнении заданий вручную вы можете указать дополнительные переменные, относящиеся к заданию.
Это можно сделать на странице задания, выполняемого вручную.
дополнительные переменные. Чтобы получить доступ к этой странице, щелкните имя ручного задания в
вид конвейера, , а не кнопка воспроизведения ().
Это полезно, если вы хотите изменить выполнение задания, которое использует
пользовательские переменные CI / CD.Добавьте сюда имя переменной (ключ) и значение, чтобы переопределить значение, определенное в
пользовательский интерфейс или .gitlab-ci.yml ,
для однократного выполнения ручной работы.
Отложить задание
Если вы не хотите запускать задание немедленно, вы можете использовать ключевое слово when: delayed для
отложить выполнение задания на определенный период.
Это особенно полезно для инкрементного развертывания по времени, когда новый код развертывается постепенно.
Например, если вы начинаете развертывание нового кода и:
- Пользователи не испытывают проблем, GitLab может автоматически завершить развертывание от 0% до 100%.
- У пользователей возникают проблемы с новым кодом, вы можете остановить инкрементное развертывание по времени, отменив конвейер
и откат к последней стабильной версии.
Развертывание и свертывание разделов журнала заданий
Журналы заданий разделены на разделы, которые можно свернуть или развернуть. В каждом разделе отображается
продолжительность.
В следующем примере:
- Три раздела свернуты и могут быть развернуты.
- Три раздела развернуты и могут быть свернуты.
Пользовательские складные секции
В журналах заданий можно создавать складные разделы.
путем ручного вывода специальных кодов
который GitLab использует, чтобы определить, какие разделы свернуть:
- Маркер начала раздела:
\ e [0Ksection_start: UNIX_TIMESTAMP: SECTION_NAME \ r \ e [0K + TEXT_OF_SECTION_HEADER - Маркер конца раздела:
\ e [0Ksection_end: UNIX_TIMESTAMP: SECTION_NAME \ r \ e [0K
Эти коды необходимо добавить в раздел сценариев конфигурации CI.Например,
используя echo :
job1:
сценарий:
- echo -e "\ e [0Ksection_start:` date +% s`: my_first_section \ r \ e [0KHeader 1-го сворачиваемого раздела "
- echo 'эта строка должна быть скрыта при свертывании'
- echo -e "\ e [0Ksection_end:` date +% s`: my_first_section \ r \ e [0K "
В зависимости от оболочки, которую использует ваш бегун, например, если он использует ZSH, вам может потребоваться
экранируйте специальные символы, например: \ e и \ r .
В приведенном выше примере:
- Дата
+% s : метка времени Unix (например, 1560896352 ). -
my_first_section : Имя, присвоенное разделу. -
\ r \ e [0K : Предотвращает отображение маркеров раздела в обработанном (цветном)
журнал заданий, но они отображаются в необработанном журнале заданий. Чтобы увидеть их, в правом верхнем углу
в журнале задания щелкните ( Показать полное необработанное ).-
\ r : возврат каретки. -
\ e [0K : escape-код ANSI для очистки строки.
Пример необработанного журнала задания:
\ e [0Ksection_start: 1560896352: my_first_section \ r \ e [0KЗаголовок 1-го сворачиваемого раздела
эта строка должна быть скрыта при свертывании
\ e [0Ksection_end: 1560896353: my_first_section \ r \ e [0K
Предварительно обрушенные секции
Вы можете сделать так, чтобы в журнале задания автоматически сворачивались сворачиваемые разделы, добавив параметр свернутый в начало раздела.Добавьте [collapsed = true] после имени раздела и перед \ r . Маркер конца раздела
остается неизменной:
- Маркер начала раздела с
[collapsed = true] : \ e [0Ksection_start: UNIX_TIMESTAMP: SECTION_NAME [collapsed = true] \ r \ e [0K + TEXT_OF_SECTION_HEADER - Маркер конца раздела:
section_end: UNIX_TIMESTAMP: SECTION_NAME \ r \ e [0K
Добавьте обновленный текст начала раздела в конфигурацию CI.Например,
используя echo :
job1:
сценарий:
- echo -e "\ e [0Ksection_start:` date +% s`: my_first_section [collapsed = true] \ r \ e [0KЗаголовок 1-го сворачиваемого раздела "
- echo 'эта строка должна быть скрыта автоматически после загрузки журнала задания'
- echo -e "\ e [0Ksection_end:` date +% s`: my_first_section \ r \ e [0K "
Вакансий по развертыванию
Задания по развертыванию - это особый вид задания CI, в котором код развертывается в
среды. Работа по развертыванию - это любая работа, которая
использует ключевое слово environment и действие среды start environment .Задания по развертыванию не обязательно должны находиться на этапе развертывания и . Следующий разверните меня
job - это пример работы по развертыванию. Действие : начало - поведение по умолчанию и
определено для примера, но вы можете его опустить:
разверните меня:
сценарий:
- deploy-to-cats.sh
окружающая обстановка:
имя: производство
url: https://cats.example.com
действие: начало
Поведение заданий развертывания можно контролировать с помощью
настройки безопасности развертывания, такие как
пропуск устаревших заданий по развертыванию
и обеспечение одновременного выполнения только одного задания развертывания.
(PDF) Шаблоны сопоставления с переменными
h (x1) = bacb, h (x2) = band gwith g (x1) = g (x2) = ab, соответственно. Кроме того, β также соответствует
слову w = acbbcbcb стирающей заменой h с h (x1) = ε, h (x2) = cb;
легко проверить, что не существует нестираемой замены, которая отображает β в w.
Задача сопоставления, обозначенная как Match, состоит в том, чтобы решить для данного шаблона α и слова w,
, существует ли подстановка h с h (α) = w.Вариант, в котором нас интересуют только
с заменами без стирания, называется случаем без стирания задачи сопоставления; мы также используем термин «регистр стирания», чтобы подчеркнуть, что допускается замена пустым словом.
Другой особый вариант - это случай задачи согласования без терминала, когда входные
шаблонов являются бесконтактными, т.е. е., они не содержат каких-либо вхождений терминального символа. Мы
кратко обсудим некоторые особенности этих различных частных случаев задачи согласования
в разделе 3.Обратите внимание, что в разделах, посвященных эффективным алгоритмам, а именно в разделах 5.1, 5.2 и 6,
, мы рассматриваем только случай без стирания (с терминальными символами) задачи сопоставления. Представленные результаты
можно легко обобщить на общие настройки, но мы предпочитаем соответствующую структуру
для простоты представления.
Для любого P⊆Pat проблема соответствия для P (или Match for P, для краткости) - это проблема соответствия
, где входные шаблоны взяты из P.В разделах этой статьи мы представим
и обсудим несколько интересных семейств паттернов.
Поскольку мы обсуждаем эффективные алгоритмы, важно описать вычислительную модель, которую мы используем в этой работе
. Это стандартная ОЗУ с удельной стоимостью с логарифмическим размером слова. Кроме того, все логарифмы
, появляющиеся в наших оценках временной сложности, находятся в базе 2. Для общности мы предполагаем, что
, что всякий раз, когда нам дается в качестве входных данных слово w∈Σ ∗ длины n, символы слова на самом деле
целых чисел из {1,2 ,..., n} (т.е. Σ = alph (w) ⊆ {1,2, ..., n}), а w рассматривается как последовательность из
целых чисел. Это обычное предположение в области алгоритмики слов (см., Например, обсуждение
в [52]). Ясно, что наши алгоритмические результаты канонически верны для постоянных алфавитов, так как
хорошо.
3 Трудность задачи сопоставления
Во-первых, напомним, что существует несколько различных вариантов задачи сопоставления: наиболее общий случай
(возможна замена пустым словом и вхождения терминалов в шаблоны),
случай без стирания (с терминальными символами), случай без терминала (стирание) и, наконец, случай без стирания
без терминала.Как мы увидим, эти различия не имеют большого значения, если нас интересует только проблема соответствия шаблонов. Однако в других контекстах паттернов
с переменными (например, другие проблемы принятия решений, теория обучения) эти различия являются наиболее важными
, и поэтому мы кратко дадим некоторую предысторию.
Для класса так называемых языков шаблонов, т.е. е., наборы всех слов, которые соответствуют шаблону,
, разница между стиранием и не стиранием важна, поскольку эти классы из
формальных языков довольно существенно различаются в отношении основных задач принятия решений.Например,
в случае без стирания, два шаблона описывают один и тот же язык тогда и только тогда, когда шаблоны идентичны
(вплоть до переименования переменных), в то время как остается открытым вопрос о том, является ли проблема эквивалентности
даже разрешимой. в случае стирания (см., например, раздел 6 в [68] или [74]). Более того, проблема включения
, которая неразрешима как для случая стирания, так и для случая без стирания (см. [50, 34]), может быть решена для шаблонов
без терминала в случае стирания, в то время как для случая без терминала. без стирания
шаблонов статус разрешимости открыт (интуитивно говоря, это связано с тем фактом, что
вопросов избегания формы «обязательно ли шаблон β встречается в достаточно длинных словах более
ак-буквенного алфавита?» могут быть выражается как включение для двух языков, заданных шаблонами без терминала
без стирания).Наконец, также то, можно ли вывести шаблоны (или описательные шаблоны)
из положительных данных, сильно зависит от того, рассматривается ли случай стирания или отсутствия стирания, или
, разрешены ли терминальные символы в шаблонах (см. [73, 75, 36, 35]).
Для проблемы сопоставления (обратите внимание, что это соответствует проблеме принадлежности для языков pat-
tern), рассматриваем ли мы стирающую или не стирающую замену, или запрещаем ли мы
терминальные символы в шаблонах, имеет мало влияние на его вычислительную трудность.В
факт, что проблема сопоставления для шаблонов с переменными является NP-полной, был независимо обнаружен в разных сообществах и для немного разных вариантов проблемы (см., Например,
введения [28, 29] для несколько замечаний по истории исследования задачи сопоставления
).
3
grep и регулярные выражения используют
grep - это инструменты фильтрации текста (режим: шаблон), которые в основном используются следующим образом:
grep [опция] ФАЙЛ ШАБЛОНА
grep [ОПЦИИ] [-e ШАБЛОН | -f ФАЙЛ] [ФАЙЛ.]
Количество совпадений: используется для указания количества символов позади него, количество символов, которые появляются спереди, для ограничения
*: Любой символ, предшествующий этому совпадению; 0,1, повторно
*: Соответствует любому символу любой длины
\?: Соответствует предыдущему символу 0 или 1, i.е. передний необязательный символ
\ +: Соответствует предыдущему символу один или несколько раз, а именно перед символом появляется хотя бы один раз.
\ {M \}: m раз, чтобы сопоставить символ
\ {M, n \} соответствует как минимум m раз предыдущему символу, максимум n
\ {0, n}: n раз до
\ {M, \}: не менее m
Положение якоря
^: Начало закрепленной строки: крайний левый режим
$: Привязка конца строки; крайний правый шаблон для
^ ШАБЛОН $: для соответствия всей строке ШАБЛОНА
^ $: Пустые строки
^ [[: Пробел:]] * $: пустые строки содержат пустые лицензионные символы
Слова: непрерывная строка специальных символов называется словом
\ <Или \ b: привязка левой части первого слова в слово режим
\> Или \ b: конец привязки, правильный режим для слова
\ <ШАБЛОН \>: соответствие целым словам
Группировка и ссылки
\ (\): Один или несколько символов, связанных вместе, как единый процесс.
Например: \ (xy \) * ab
Пакетные скобки, совпадающие с шаблоном содержимого обработчика регулярных выражений, будут автоматически записаны во внутренние переменные, эти переменные
\ 1: режим с левой стороны, и первая левая скобка, правая скобка перед сопоставлением с образцом для соответствия символу
\ 2: режим с левой стороны, и второй режим перед левой круглой скобкой, соответствующей правой круглой скобке, сопоставлен с символом
\ 3:
После ссылки на ввод: Применение вышеуказанного пакета в круглых скобках сопоставления с шаблоном символа.
Расширенные регулярные выражения
Соответствие символов
.: Начало линии привязано
$: Конечный якорь
\ <Или \ b: привязка левой части первого слова в слово режим
\> Или \ b: конец привязки, правильный режим для слова
\ <ШАБЛОН \>: соответствие целым словам
Группировка и ссылки:
(): Шаблон группировки в скобках соответствует символам, записанным во внутренних переменных обработчика регулярных выражений.
После цитаты: \ 1 \ 2
Или: a | б: а или б
1 взят ip-адрес команды ifconfig
[[электронная почта защищена] ~] # ifconfig | egrep -o "([1-9] | [1-9] [0-9] | 1 [0-9] {2} | 2 [0-9] [0-4] | 25 [0-5] ) \.(([0-9] | [1-9] [0-9] | 1 [0-9] {2} | 2 [0-9] [0-5] | 25 [0-5]) \. ) {2} ([0-9] | [1-9] [0-9] | 1 [0-9] {2} | 2 [0-9] [0-5] | 25 [0-5] ) "
10.127.69.19
255.255.255.0
10.127.69.255
127.0.0.1
255.0.0.0
192.168.122.1
255.255.255.0
192.168.122.255
[Root @ Linuxprobe ~] # ifconfig | .. Egrep -o "[0-9] {1,3} \ [0-9] {1,3} \ [0-9] {1,3} \ [. 0-9] {1,3} "слегка напишите простую формулировку
10.127.69.19
255.255.255.0
10.127.69.255
127.0.0.1
255.0.0.0
192.168.122.1
255.255.255.0
192.168.122.255
[Корень @ Linuxprobe ~] # ifconfig | egrep -o "(. ([0-9] {1,3}) \) {3} [0-9] {1,3}" снова оптимизировать
10.(s | S). * "/ proc / meminfo
SwapCached: 87400 КБ
SwapTotal: 2097148 kB
SwapFree: 1929496 Кбайт
Shmem: 8336 Кбайт
Slab: 189808 кБ
Заявленный: 118840 КБ
SUnreclaim: 70968 kB
6 Удалите / etc / paswwd нефайловую оболочку по умолчанию / sbin / nogloin
[[защищенные по электронной почте] резервные копии] # grep -v "nologin \> $" / etc / passwd
корень: x: 0: 0: корень: / корень: / bin / bash
синхронизация: x: 5: 0: синхронизация: / sbin: / bin / sync
выключение: x: 6: 0: выключение: / sbin: / sbin / выключение
остановка: x: 7: 0: остановка: / sbin: / sbin / halt
harrycai: x: 1000: 1000: harry.cai: / home / harrycai: / bin / bash
.............................................
7 взят / etc / paswwd оболочка по умолчанию для пользователей file / bin / bash.
[[защищенные по электронной почте] резервные копии] # grep "bash \> $" / etc / passwd
корень: x: 0: 0: корень: / корень: / bin / bash
harrycai: x: 1000: 1000: harry.cai: / home / harrycai: / bin / bash
студент: x: 1001: 1001 :: / home / student: / bin / bash
bash: x: 1002: 1002 :: / дома / bash: / bin / bash
user1: x: 1004: 1004 :: / home / user1: / bin / bash
.............................................
8, чтобы найти файл / etc / passwd, состоящий из одной или двух цифр
[[защищенные по электронной почте] резервные копии] # grep -E "\ <[0-9] {1,2} \>" / etc / passwd
корень: x: 0: 0: корень: / корень: / bin / bash
bin: x: 1: 1: bin: / bin: / sbin / nologin
демон: x: 2: 2: демон: / sbin: / sbin / nologin
adm: x: 3: 4: adm: / var / adm: / sbin / nologin
.[: пробел:]] + "/etc/rc.d/init.d/network
# network Включение / отключение сети
# chkconfig: 2345 10 90
# description: Активирует / деактивирует все сетевые интерфейсы, настроенные на \
.......................
11 play netstat -tan результаты выполнения команды "LISTEN", за которым следует пробел в строке
[[защищенные по электронной почте] резервные копии] # netstat -tan | grep -E "СЛУШАТЬ \> [[: пробел:]] +"
tcp0 0 0.0.0.0:111 0.0.0.0:* СЛУШАТЬ
tcp0 0 192.168.122.1:530.0.0.0:* СЛУШАТЬ
............................................
12 Соответствует всем почтовым адресам
[[email protected] ~] # cat mailtest | grep -E "\ <[[: alnum:]] * @ [[: alnum:]] * [[: punct:]] * [[: alnum:]]] * \. [a-z] + \>"
[электронная почта защищена]
[электронная почта защищена]
[электронная почта защищена]
[электронная почта защищена]
jzssysjzzyxg [адрес электронной почты защищен]
[электронная почта защищена]
[электронная почта защищена]
.............
.
Добавить комментарий