
Распознавание текста с картинки онлайн бесплатно
Мы уже рассматривали с Вами программу для распознавания текста с картинки. Но распознавать текст можно не только с помощью программы. Это можно делать с помощью онлайн сервисов, не имея никаких программ на своем компьютере.
И действительно, зачем устанавливать какие-то программы, если Вам нужно распознать текст один раз, и в дальнейшем Вы не собираетесь эту программу использовать? Или Вам нужно делать это раз в месяц? В этом случае лишняя программа на компьютере не нужна.
Давайте рассмотрим несколько сервисов, при помощи которых можно распознавать текст с картинки бесплатно, легко и быстро.
Free Online OCR
Очень хорошим сервисом для распознавания текста с картинки онлайн является сервис Free Online OCR. Он не требует регистрации, распознает текст с картинки практически любого формата. работает с 58 языками. Распознаваемость текста у него отличная.
Пользоваться этим сервисом просто. Когда Вы на него зайдете, перед Вами будет всего два варианта: загрузить файл с компьютера, или вставить URL-адрес картинки, если она находится в Интернете.
Если Ваше изображение находится на компьютере, нажимаете на кнопку Выберите файл, затем выбираете свой файл, и нажимаете на кнопку Upload. Вы увидите свой графический файл ниже, а над ним кнопку OCR. Жмете эту кнопку, и получаете текст, который Вы можете найти в нижней части страницы.
Online OCR Net
Также довольно неплохой сервис, который позволяет распознавать тексты с картинок онлайн бесплатно, и без регистрации. Поддерживает он 48 языков, включая русский, китайский, корейский и японский. Чтобы начать с ним работать, заходите на Online OCR, нажимаете кнопку Select file, и выбираете файл на своем компьютере. Существуют ограничения по размеру — файл не должен весить больше 5 Мбайт.
В соседних полях выбираете язык и расширение текстового документа, в котором будет полученный из картинки текст. После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
После этого вводите капчу внизу, и нажимаете на кнопку Convert справа.
Внизу появится текст, который Вы можете скопировать, а выше текста — ссылка на загрузку файла с этим текстом.
ABBYY FineReader Online
Очень хороший сервис в плане своей многофункциональности. На ABBYY FineReader Online можно не только распознавать текст с картинки, но также и переводит документы из формата PDF в формат Word, переводить таблицы из картинок в Excel, и создавать документы PDF из сканов.
На этом сервисе есть регистрация, но можно обойтись и входом с помощью социальной сети Facebook, сервисов Google+, или Microsoft Account.
Преимущество такого подхода в том, что созданные документы будут храниться в Вашем аккаунте в течении 14 дней, и даже если Вы их удалите из компьютера, можно будет вернуться на сервис, и опять их скачать.
Online OCR Ru
Сервис, похожий на предыдущий, с информацией на русском языке. Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Принцип работы сервиса Online OCR такой же, как и всех остальных — нажимаете на кнопку Выберите файл, загружаете картинку, выбираете язык и выходной формат текстового документа, и нажимаете на кнопку Распознать текст.
Кроме распознавания текста из картинок, сервис предоставляет возможность перевода изображений в форматы PDF, Excel, HTML и другие, причем структура и разметка документа будет соответствовать той, которая была на картинке.
На этом сервисе также есть регистрация, и файлы, созданные Вами с его помощью, будут храниться в Вашем личном кабинете.
Данные сервисы распознавания текста с картинок, на мой взгляд, самые лучшие. Надеюсь, они и Вам принесут пользу. Также, возможно, я не все хорошие сервисы осветил. Жду Ваших комментариев, насколько эти сервисы Вам понравились, какими сервисами пользуетесь Вы, и какие из них являются, на Ваш взгляд, самыми удобными.
Более подробные сведения Вы можете получить в разделах «Все курсы» и «Полезности», в которые можно перейти через верхнее меню сайта.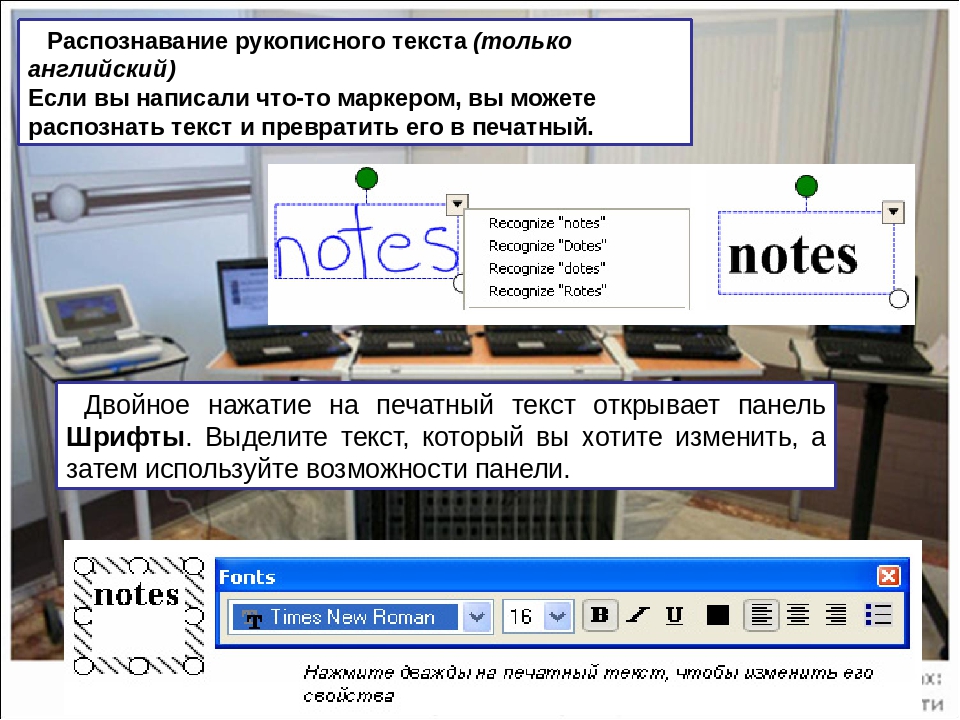 В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях.
Это не займет много времени. Просто нажмите на ссылку ниже:
Подписаться на блог: Дорога к Бизнесу за Компьютером
Проголосуйте и поделитесь с друзьями анонсом статьи на Facebook:
App Store: FineReader: Сканер документов
Отличный инструмент для оцифровки документов и книг!
Сканируйте и конвертируйте документы в PDF, Word, Excel, PPT, TXT, FB2, EPUB, и делитесь ими как угодно.
ABBYY FineReader PDF – ваш умный карманный сканер для документов и книг от ведущего мирового разработчика решений в области интеллектуальной обработки информации.
FineReader PDF использует искусственный интеллект, создавая электронные копии документов и книг в форматах PDF и JPEG, и распознает текст на сканах (OCR) с сохранением форматирования.
*****Победитель конкурса Mobile Star Award в категории «Сканирование документов» с наградой SUPERSTAR*****
***** № 1 в категории Бизнес в 98 странах *****
Сканируйте с помощью вашего iPhone или iPad документы, книги, чеки, рецепты, заметки, статьи, изображения, диаграммы, таблицы, слайды, объявления и даже рекламные щиты на улице и получайте прекрасные электронные копии. FineReader PDF — идеальный инструмент оцифровки для бизнесменов, студентов, научных сотрудников, простых обывателей, который всегда с собой.
КЛЮЧЕВЫЕ ВОЗМОЖНОСТИ
• PDF И JPEG. Сканируйте любые печатные или рукописные бумаги и сохраняйте их в JPEG или PDF.
• OFFLINE OCR. Распознавайте текст в формате TXT быстро и без интернета.
• ONLINE OCR. Распознавайте печатные тексты на сканах документов на 193 языках (включая латиницу, кириллицу и азиатские языки) с выгрузкой результатов в Word, Excel, PDF, TXT с сохранением форматирования документа (списки, таблицы, заголовки). Доступно для 100 страниц в документе.
• ЭКСПОРТ. Делитесь результатами по e-mail, отправляйте в FineReader PDF для Windows, сохраняйте в облако — iCloud Drive, Box, Яндекс.Диск, Evernote, Dropbox, Facebook или Google.Drive, OneDrive для Бизнеса, переносите сканы напрямую на Маc или Windows с помощью iTunes sharing.
• Нейросети ABBYY. Умная галерея автоматически распределит документы на 7 типов: A4, книги, визитки, удостоверения, рукописный текст, чеки, прочее.
• ИЩИТЕ ТЕКСТ НА ФОТО. Введите искомый текст в строку поиска на странице галереи. FineReader PDF найдёт и покажет фото, содержащие этот текст.
• AR ЛИНЕЙКА. Определяйте размер документа с помощью дополненной реальности (AR). Это пригодится для документов нестандартного размера и позволит сохранить правильные пропорции при печати документов.
• BOOKSCAN. Переключите камеру в режим Книга и обрабатывайте разворот книги одним кадром! BookScan разрежет разворот на две отдельные страницы, удалит геометрические искажения, дефекты света, выпрямит изгибы строк и страниц. Как если бы вы прижимали книгу крышкой обычного настольного сканера.
Как если бы вы прижимали книгу крышкой обычного настольного сканера.
• ГОЛОСОВЫЕ КОМАНДЫ SIRI. Открывайте сканы голосом и настраивайте цепочки действий для документов с помощью приложения «Команды»
• АННОТАЦИЯ СКАНОВ. Редактируйте PDF с помощью инструментов аннотации: добавляйте подписи или пишите текст ручкой, выделяйте маркером, скрывайте конфиденциальные данные или вставляйте печатный текст.
• 3D TOUCH И SPOTLIGHT SEARCH.
• ПАРОЛЬ НА PDF. Добавляет пароль на image-only PDF при экспорте и пересылке по email.
• МНОГОСТРАНИЧНЫЕ ДОКУМЕНТЫ. Создавайте электронные копии как небольших (1-2 страницы), так и объемных многостраничных документов без дополнительных переключений (не более 100 страниц в документе).
• АВТО-ЗАХВАТ И ФИЛЬТРЫ. Идеальный результат за счет автоматического определения границ листа, а также фильтров, которые позволяют сохранить изображение в черно-белом, сером или цветном режиме.
• УДОБНОЕ ХРАНИЛИЩЕ с тегами и поиском.
• AIRPRINT.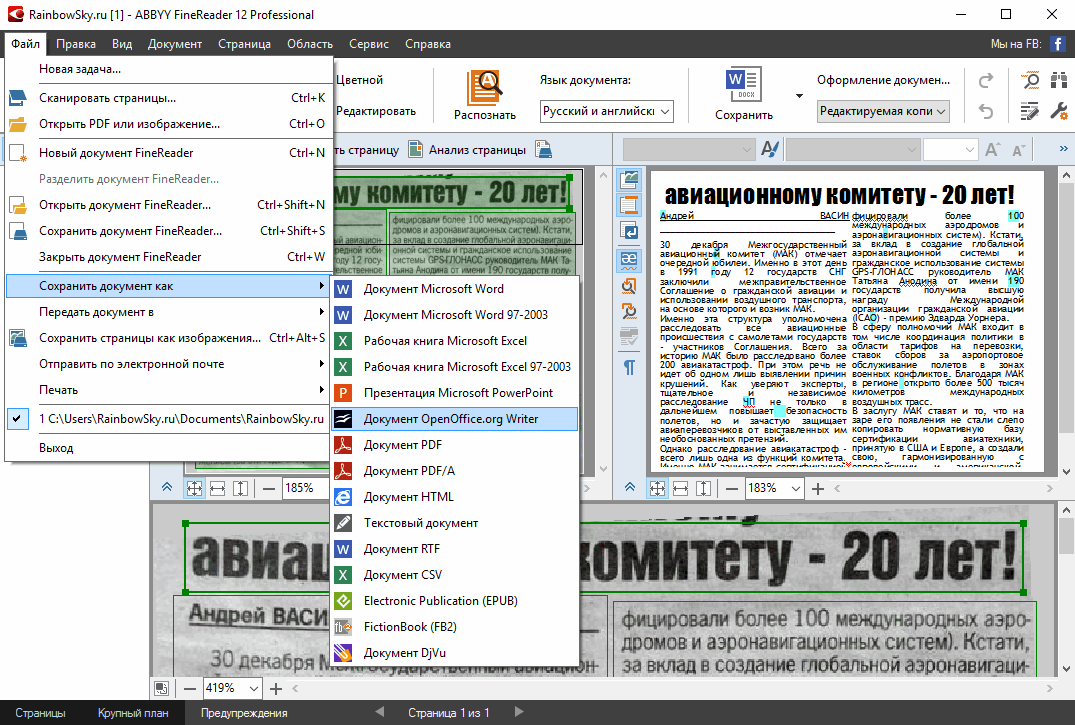 Печатайте сканы прямо с iPhone или iPad.
Печатайте сканы прямо с iPhone или iPad.
КОРПОРАТИВНОЕ ЛИЦЕНЗИРОВАНИЕ
Если вы хотите приобрести большое количество лицензий (от 100 лицензий) для вашей компании или хотите внести кастомизацию в приложение, пожалуйста, напишите [email protected].
Читайте нас:
Mobileblog.abbyy.com
@ABBYY_Mobile в Твиттере
Facebook.com/Abbyy.Lingvo
vk.com/abbyylingvo
Youtube.com/ABBYYMobile
Пожалуйста, оставьте отзыв, если вам понравилось приложение FineScanner. Спасибо!
Как онлайн распознать текст с картинки и сохранить его
Что делать, если надо распознать текст с картинки или сканированный текст, а подходящей программы на компьютере нет? Устанавливать специальный софт? Но это долго, и большинство их них платны.
i2OCR (Optical Character Recognition) – 100% бесплатный онлайн сервис, который быстро распознает текст с любого изображения и позволит скачать его в виде файла. В качестве источника можно использовать страницы книг, факсы, рецепты, фотографии, скриншоты и пр.
Основные возможности i2OCR
- Для распознавания можно загружать как сами документы с компьютера, так и указывать ссылки на них в интернет
- Форматы исходников: JPG, PNG, BMP, TIF, PBM, PGM, PPM
- Поддержка более 60 языков, среди которых есть английский, русский, украинский, японский, китайский и пр.
- Распознанный текст можно сохранить и скачать в форматах: Text (txt), Microsoft Word (doc), Adobe PDF (pdf), HTML
- Поддержка многоколоночной верстки
- Редактирование распознанного текста в Google Docs или его онлайн перевод при помощи переводчиков Google или Bing
Как видим, возможности для бесплатного сервиса более чем впечатляющие и вполне достаточны для обычных нужд. Теперь рассмотрим как именно распознать текст с картинки при помощи i2OCR.
Как работать с сервисом
Всё делается очень быстро в три простых этапа:
- Загрузка файла или указание ссылки на него в интернет
- Указание языка текста на картинке
- Нажатие кнопки «Extract Text»
Для проверки качества работы сервиса я выбрал следующие изображение со сканированным текстом (качество шрифта не самое лучшее):
Вот такой результат я получил в итоге:
Всё распознано идеально, без ошибок кроме символа «№».
После того как текст будет распознан, появятся кнопки дополнительных опций:
- «Download» — скачать документ в одном из форматов
- «Translate» — перевести на другой язык
- «Edit Google Docs» — внести правки в онлайн редакторе
Ограничения сервиса
Все ограничения сервиса носят лишь системный характер и состоят в следующем:
- размер загружаемого изображения не должен превышать 10 MB
- сервис не распознает рукописный текст
i2OCR не имеет ограничений на количество загружаемых файлов и на число скачиваний! Все возможности сервиса абсолютно бесплатны и доступны без регистрации!
Итог
При помощи сервиса i2OCR можно бесплатно распознать онлайн текст с картинки (скана, фото и пр.), сделать его перевод на другой язык, отредактировать, сохранить и скачать в одном из форматов (txt, doc, pdf, html). Всё делается быстро, четко и без установки на ПК дополнительных программ. Сервис однозначно должен быть в закладках у каждого!
P. S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст.
S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст.
Автор статьи: Сергей Сандаков, 40 лет.
Программист, веб-мастер, опытный пользователь ПК и Интернет.
Как распознать и перевести текст с фото на Айфоне без установки приложений
Среди всех новинок iOS 15 (инструкция по установке) функция Live Text кажется наиболее востребованной. Работает она также и в iPadOS 15, и в macOS Monterey. Суть этой функции заключается в том, что она извлекает (распознает) слова из изображений, а потом вставляет их в заметки, электронные письма и т.д. Пользователи уже оценили возможности Live Text как на iPhone, так и на iPad, найдя опыт действительно удивительным.
♥ ПО ТЕМЕ: Как снизить фоновый шум в видеозвонках на iPhone (выделить голос).
Для чего нужна функция Live Text?
У многих людей сформировалась привычка – не запоминать, а просто фотографировать ту информацию, которая понадобится позже. Но Live Text делает эту процедуру еще более полезной. Вместо того, чтобы сохранять изображение целиком, можно превратить текст в нем в заметку или напоминание.
Но Live Text делает эту процедуру еще более полезной. Вместо того, чтобы сохранять изображение целиком, можно превратить текст в нем в заметку или напоминание.
Например, прогуливаясь, вы можете сразу же считать название интересующего вас ресторана на вывеске. А затем можно осуществить поиск этого заведения в Интернете. Или же, предположим, администрация заведения написала пароль от Wi-Fi на доске. Можно не вводить его побуквенно, а использовать камеру iPhone для захвата текста, через пару секунд его можно будет вставить в настройки своего устройства для подключения к общественной сети.
Студенты же могут копировать написанное на доске (функция распознает даже рукописный текст), чтобы потом вставлять в свои заметки. Эта функция должна пригодиться людям, которым на собраниях или лекциях что-то пишут на досках.
♥ ПО ТЕМЕ: На домашнем экране iOS 15 можно размещать одно и то же приложение несколько раз.
На каких iPhone, iPad и Mac работает LiveText?
Для работы функции LiveText вам понадобится относительно новое «железо». Функция потребует как минимум процессор A12 Bionic (выпущен в 2018 году) в вашем iPhone или iPad. К тому же Live Text работает только на компьютерах Mac с процессором серии M, но не на компьютерах предыдущих поколений с процессорами Intel.
Функция потребует как минимум процессор A12 Bionic (выпущен в 2018 году) в вашем iPhone или iPad. К тому же Live Text работает только на компьютерах Mac с процессором серии M, но не на компьютерах предыдущих поколений с процессорами Intel.
♥ ПО ТЕМЕ: Нужно ли вынимать зарядку с розетки, когда ничего не заряжается.
Как распознавать текст на фото при помощи функции Live Text в iOS 15?
Функцией Live Text пользоваться очень просто. По сути, никакого обучения и не потребуется.
Рассмотрим пример. Допустим, вы нашли в каком-то журнале понравившийся рецепт. Достаньте свой iPhone или iPad, откройте встроенное приложение «Камера» и действуйте так, как будто собираетесь сфотографировать текст. Подождите секунду или две, и в правом нижнем углу появится небольшой значок. Нажмите на него, и появится всплывающее окно с текстом в нем.
Тут вы можете выбрать слова, предложения и прочее, что вам требуется скопировать.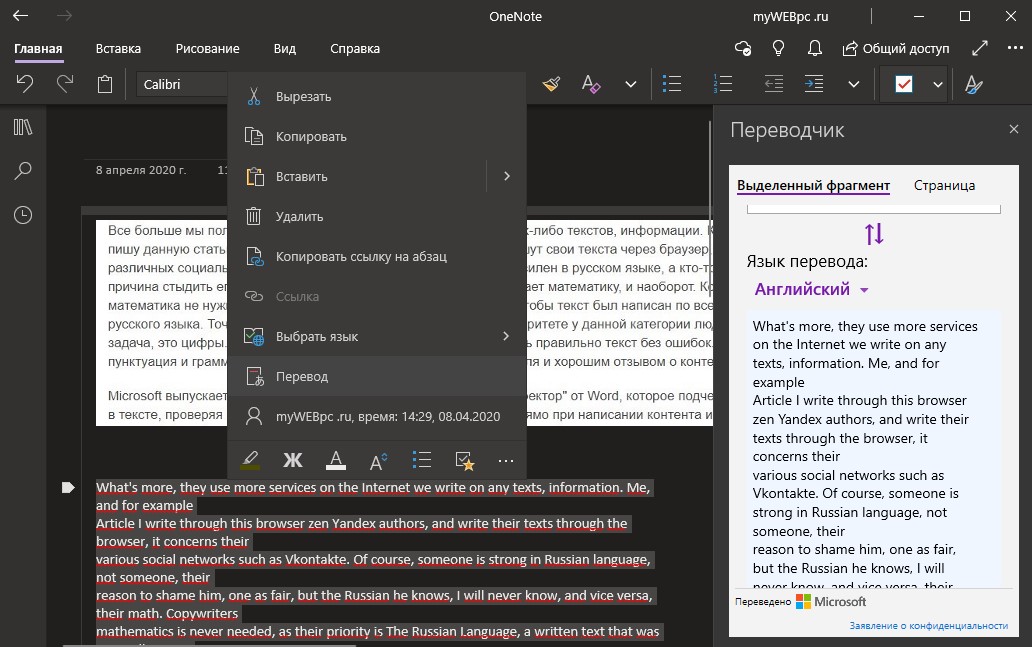 Нажмите поделиться во всплывающем меню.
Нажмите поделиться во всплывающем меню.
Выберите приложение, в которое вы бы хотели экспортировать выделенный текст.
Аналогичный процесс работает с изображениями в приложении «Фото». В этом случае весь текст будет сразу показан на картинке. Затем вы можете выбрать нужные его части. Иногда специальный значок не отображается. В этом случае нажмите и удерживайте текст, который хотите выделить. Он будет выбран, если символы не окажутся слишком искаженными.
Также Live Text зачастую может вытягивать слова из изображений на веб-страницах. В ходе тестирований этот вариант пока показал себя не слишком надежным, но надо понимать, что работа велась с первыми бета-версиями iOS 15 и iPadOS 15. У Apple есть достаточно времени, чтобы улучшить Live Text к выходу финальных версий своих операционных систем.
Но даже на этой ранней стадии Live Text работает почти потрясающе. При копировании чего-либо напечатанного точность часто составляет 100%! И даже в плохих условиях обычно удается захватить почти весь текст.
Функция работает и с почерком, в том числе написанными курсивом словами. Точность распознавания зависит от того, насколько ясен текст, но он не обязательно должен быть идеальным.
Конечно, если слова написаны знаменитым «почерком врачей», то могут возникнуть проблемы. Функцию опробовали на нескольких заметках, результаты оказались правильными на 95%.
♥ ПО ТЕМЕ: Как размыть фон во время видеозвонков на iPhone (WhatsApp, FaceTime, Instagram, Telegram и т.д.).
С какими языками работает Live Text?
К огромному сожалению, функция Live Text пока поддерживает только семь языков: английский, китайский (как упрощенный, так и традиционный), французский, итальянский, немецкий, испанский и португальский. Мы очень надеемся, что поддержка русского языка появится в ближайших обновлениях операционных систем Apple.
Но даже сейчас русскоязычные пользователи могут воспользоваться этой функцией, например, в путешествиях – Live Text умеет переводить текст на русский и другие языки.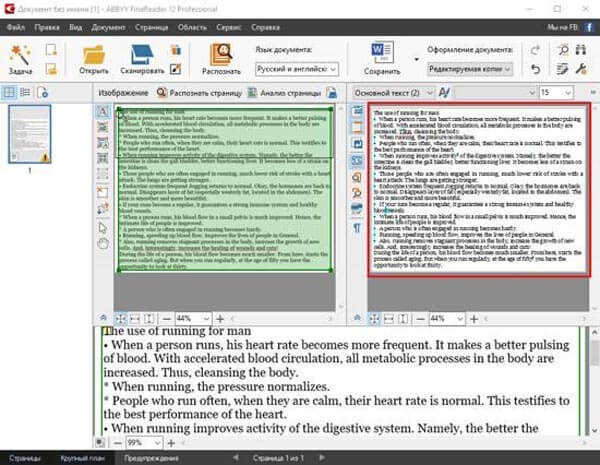
♥ ПО ТЕМЕ: 20 функций iPhone, которые можно отключить большинству пользователей.
Как переводить текст при помощи функции Live Text
Live Text, вероятно, пригодится путешественникам, потому что функция тесно связана со службой переводов Apple. Есть простой вариант использования – сделать снимок меню, затем открыть его, нажать и удерживать фразу, чтобы выбрать ее. Во всплывающем окне следует выбрать пункт Перевод, который и позволит перевести текст на необходимый язык (в том числе русский).
Первый опыт взаимодействия с такой связкой оказывается интересным и достаточно полезным. Да, перевод, неидеален. Но, находясь в чужой стране без знания местного языка, поможет и такой инструмент для формирования заказа.
♥ ПО ТЕМЕ: Как изменить метаданные местонахождения, даты и т.д. на фото в iPhone.
LiveText – это система распознавания текста для всех и везде
Live Text – это, конечно, всего лишь приложение для оптического распознавания символов. Технология эта существует уже несколько десятилетий (обзор лучших приложений для распознавания текста для iOS и Android). Но iOS 15, macOS Monterey и iPadOS 15 неплохо интегрировали в себя эту функцию. Live Text оказалась удобной и работает очень быстро.
Технология эта существует уже несколько десятилетий (обзор лучших приложений для распознавания текста для iOS и Android). Но iOS 15, macOS Monterey и iPadOS 15 неплохо интегрировали в себя эту функцию. Live Text оказалась удобной и работает очень быстро.
И поскольку разработчиком функции является Apple, процесс осуществляется с учетом конфиденциальности. Функция распознавания слов работает непосредственно на вашем устройстве. Изображение не загружается на некий удаленный сервер. Это не только хорошо с точки зрения конфиденциальности, но также означает, что вам не нужно быстрое подключение к Интернету или вообще какое-либо сетевое соединение.
Смотрите также:
Распознать арабский текст с картинки
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.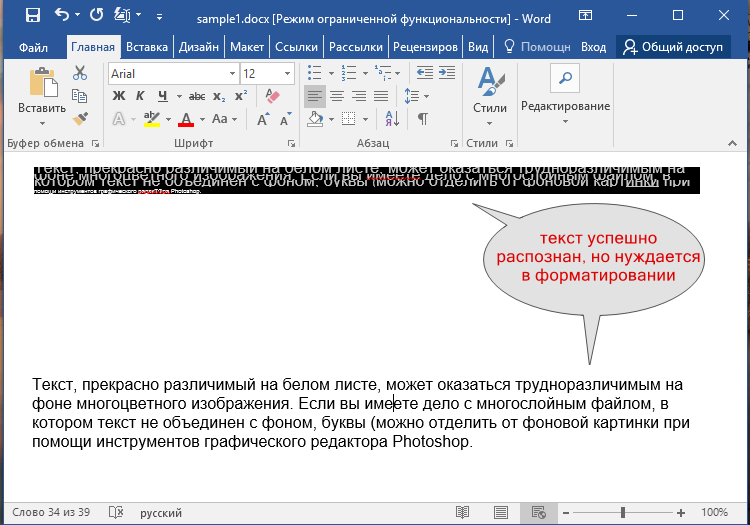
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания
Загрузите файл
Выберите язык содержимого текста в файле
После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных.
 Данные между серверами передаются по SSL + автоматически будут удалены
Данные между серверами передаются по SSL + автоматически будут удалены - Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 5.7M+ запросов
 Данные между серверами передаются по SSL + автоматически будут удалены
Данные между серверами передаются по SSL + автоматически будут удаленыОсновные возможности
Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian — Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian — Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek — Cyrillic, Vietnamese
© 2014-2019 img2txt Сервис распознавания изображений / v. 0.6.5.0
0.6.5.0
Описание
Допустимые форматы: pdf (в т.ч. многостраничные), jpg, gif, jp2, jpeg, png, tiff (в т.ч. многостраничные), webp
Сервис позволяет бесплатно распознать текст онлайн с картинок и pdf файлов. После распознавания можно проверить текст на уникальность и орфографические ошибки. Результаты распознавания доступны по секретной ссылке, которой можно поделиться. Ссылка на результаты OCR хранится 7 дней.
Рекомендации
Для лучшего распознавания используйте картинки с разрешением не менее 300 dpi.
Старайтесь, чтобы строки текста располагались горизонтально, поправьте предварительно картинки в графическом редакторе, если строки слишком завалены.
Желательно обрезать ненужные края, особенно если там есть элементы, похожие на текст.
Оптимальным для распознавания являются картинки, сканированные планшетным сканером.
Как распознать текст с картинки онлайн
Распознать текст бесплатно с картинки онлайн можно с помощью Документов Google. Для этого нужно завести аккаунт или почту в Гугл. Делать все это мы будет через сервис Google Диск. После создания аккаунта вам будет доступно пространство в размере 15 ГБ — его мы и будем использовать.
Для этого нужно завести аккаунт или почту в Гугл. Делать все это мы будет через сервис Google Диск. После создания аккаунта вам будет доступно пространство в размере 15 ГБ — его мы и будем использовать.
- Заходим в Google Диск по ссылке
https://www.google.com/intl/ru_ru/drive/
- Загружаем фото/картинку или PDF документ нажав на кнопку «Создать» и выбрав «Загрузить файлы». Выбираем файл и загружаем.
- Жмем правой кнопкой мышки по загруженному файлу и выбираем «Открыть с помощью > Документы Google».
- Ждем пока наша картинка откроется в документе Гугл. Под картинкой будет распознанный текст. Его можно скопировать и вставить в WORD или в любой другой документ.
Ограничения
- Максимальный размер файла — 2 МБ.
- Поддерживаемые форматы — JPG, GIF, PNG и PDF.
- В файлах PDF распознаются только первые 10 страниц. (Как разделить файл PDF на части или страницы).
- Текст на картинке должен быть расположен ровно. Если он под углом, необходимо в любом графическом редакторе повернуть изображение на требуемый угол.
 Если он под углом, необходимо в любом графическом редакторе повернуть изображение на требуемый угол.
Если он под углом, необходимо в любом графическом редакторе повернуть изображение на требуемый угол.Если вы хотите качественного распознавания нужно сделать четкую фотографию или картинку с равномерным освещением и без размытостей.
Официально заявлена поддержка китайского языка.
Подробно про оптическое распознавание символов на Google Диске можно прочитать здесь.
Еще интересное:
Распознавайте текст с картинок бесплатно с удовольствием еще и онлайн).
Как распознать текст с картинки в Word
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.
Как распознать текст с картинки в Word
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть.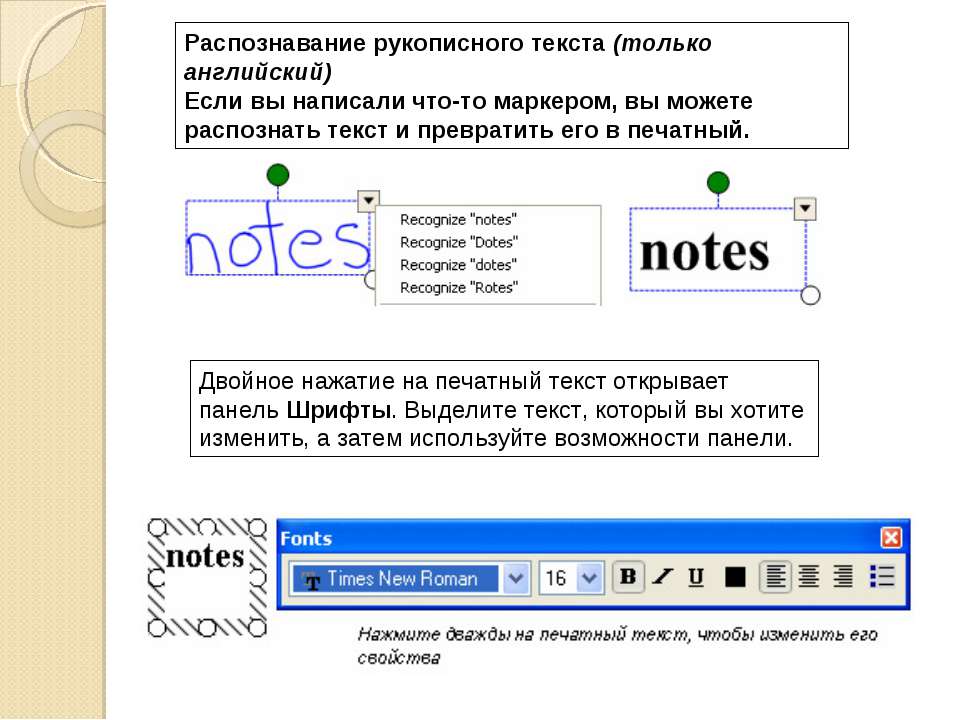 Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.
Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.
Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.
Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей.
 Он не распознает русский текст.
Он не распознает русский текст.Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»
Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.

Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
 Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Извлекаем текст
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Понравилась статья?
Сохраните, чтобы не потерять!
5 БЕСПЛАТНЫХ ОНЛАЙН-ИЗОБРАЖЕНИЙ ДЛЯ ТЕКСТА ИНСТРУМЕНТЫ ДЛЯ ИЗВЛЕЧЕНИЯ ТЕКСТА ИЗ БИЗНЕС-ДОКУМЕНТОВ
В наш век цифровых технологий нередко приходится извлекать текст из изображения, чтобы сделать его доступным для редактирования. Это особенно верно с учетом того, что мы полагаемся на бумажные документы, которые можно преобразовать в форматы, редактируемые в цифровом виде, только с помощью программного обеспечения OCR.
Оптическое распознавание символов (OCR) — это метод распознавания образов на основе искусственного интеллекта, используемый для распознавания текста в изображении и преобразования его в редактируемый цифровой документ.
В этой статье будет представлен список многих программ оптического распознавания символов (OCR), которые могут помочь вам в извлечении текста из изображений на различных устройствах. В зависимости от ваших требований один из этих инструментов должен соответствовать потребностям вашего бизнеса.
В зависимости от ваших требований один из этих инструментов должен соответствовать потребностям вашего бизнеса.
Что такое оптическое распознавание символов (OCR)?
Когда изображения преобразуются в письменный текст с помощью оптического распознавания символов (OCR), этот процесс называется оптическим распознаванием символов.Доступны различные виды программного обеспечения для оптического распознавания текста, которое может помочь вам извлекать текст из изображений и превращать их в файлы с возможностью поиска. Эти программы принимают широкий спектр форматов изображений и преобразуют их в широко используемые форматы файлов, такие как word, excel и простой текст. Эти решения могут принести пользу как частным лицам, так и компаниям, что делает управление документами и облачное хранилище быстрым и простым.
Какую роль он играет в деловом мире?
Копирование текста с изображений требует времени, но с онлайн-конвертером изображений в текст работа часов может быть завершена за минуты.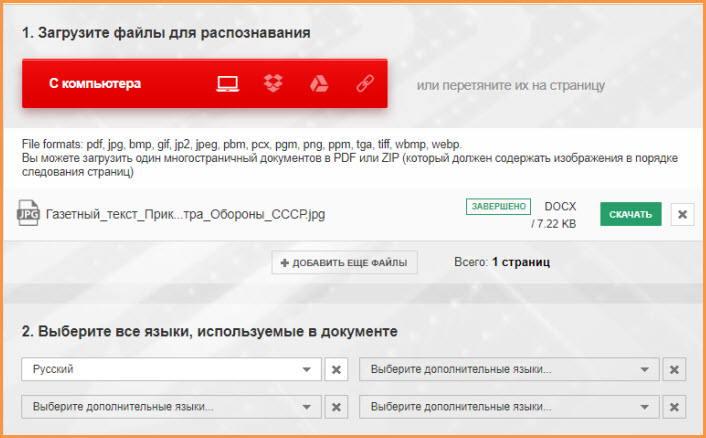 Этот инструмент повышает продуктивность вашей компании, поскольку позволяет сэкономить значительное количество времени другими способами. Этот метод также может помочь вам снизить дополнительные расходы, которые вы можете понести, заплатив сотрудникам за то, чтобы они вручную интерпретировали текст с изображений и записывали его на компьютере.
Этот инструмент повышает продуктивность вашей компании, поскольку позволяет сэкономить значительное количество времени другими способами. Этот метод также может помочь вам снизить дополнительные расходы, которые вы можете понести, заплатив сотрудникам за то, чтобы они вручную интерпретировали текст с изображений и записывали его на компьютере.
Топ-5 лучших инструментов преобразования изображения в текст для бизнеса
- Prepostseo
Конвертер фотографий Prepostseo в изображения — это совершенно бесплатное приложение.В дополнение к этому инструменту Prepostseo предоставляет различные другие инструменты, помогающие в решении связанных технических проблем. Технологии Prepostseo помогают преобразовывать изображения в текст без дополнительных регистрационных сборов. Это позволяет вам загружать несколько файлов одновременно, если вы этого хотите. Принимаются соответствующие меры для защиты конфиденциальности информации клиента.
Эффективно понимает и доставляет текст с использованием оптического распознавания символов изображения, который может быть написан любым стилем и шрифтом и на любом языке.Он также способен распознавать математические уравнения, что является фантастикой. Кроме того, он способен определять более 100 различных языков. Помимо английского, он поддерживает несколько других западных языков.
- imagetotext.info
Это простая бесплатная программа оптического распознавания текста, которая предоставляет все основные функции, которые могут вам понадобиться от этого типа программного обеспечения. Это программа OCR только для Windows, которая, как утверждается, обеспечивает максимально возможный уровень точности.Он работает со всеми основными форматами изображений, а также с документами Photoshop.
С обычным текстом он отлично справляется с работой, сохраняя преобразованный текст в формате DOC или TXT после завершения преобразования.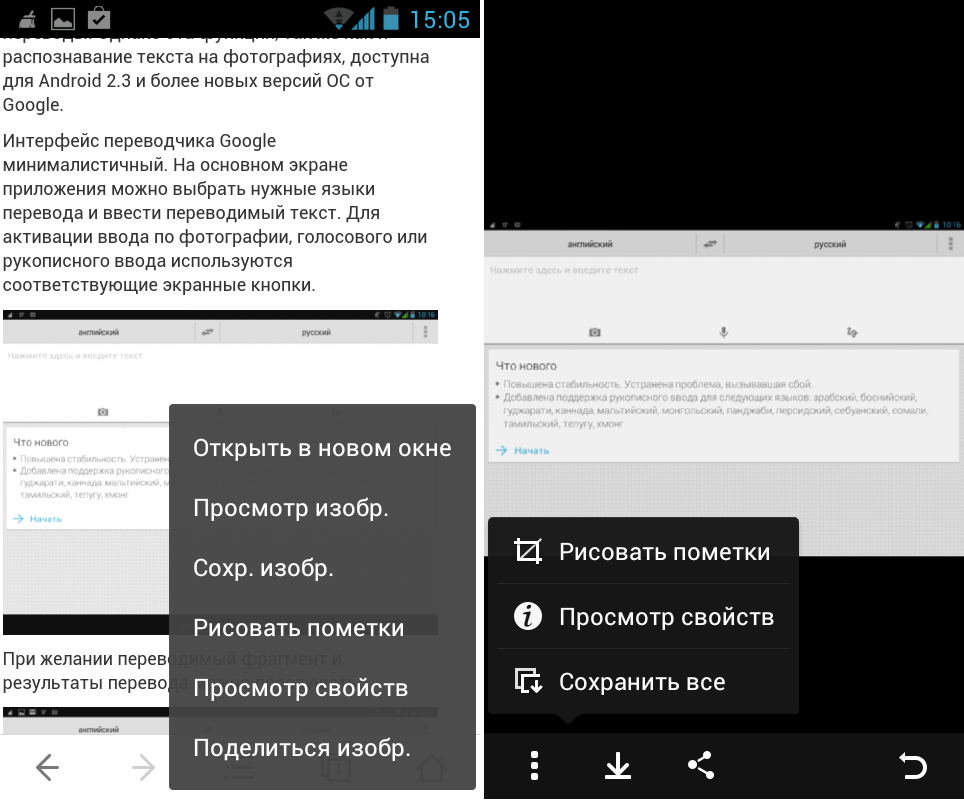 Вместо использования шаблонной структуры программа сканирует бумагу в поисках важной информации с помощью искусственного интеллекта.
Вместо использования шаблонной структуры программа сканирует бумагу в поисках важной информации с помощью искусственного интеллекта.
В качестве бонуса это одно из самых быстрых и удобных приложений для распознавания текста. Как и все лучшие приложения, оно объединяет множество надежных функций в простом и удобном для навигации дизайне.
- Myfreeocr
Это надежная и масштабируемая программа для визуализации документов и извлечения данных, которая автоматически преобразует документы любого формата, языка или содержания в ценные и доступные бизнес-данные. Он разработан для использования в различных средах. Кроме того, программное обеспечение OCR позволяет отправлять преобразованные файлы PDF в предварительно запрограммированные процессы без необходимости делать что-либо вручную.
Кроме того, встроенная программа проверки орфографии поможет вам исправить любые ошибки, которые могли произойти в процессе преобразования. В нем это необычная функция. Он позволяет пользователям хранить извлеченный текст у различных поставщиков облачных хранилищ, что делает его ценным инструментом.
В нем это необычная функция. Он позволяет пользователям хранить извлеченный текст у различных поставщиков облачных хранилищ, что делает его ценным инструментом.
- Pdfsimpli
Pdfsimpli — это наиболее совершенное программное обеспечение для оптического распознавания символов (OCR), доступное сегодня на рынке, и это идеальное решение для всех, кому требуется быстрое и точное распознавание текста. Это OCR хорошо работает при работе с большими объемами материала и включает в себя сложные возможности коррекции для более сложных работ.
Встроенная проверка орфографии доступна для выявления любых несоответствий в преобразованном тексте. Хотя некоторые люди обеспокоены тем, что это OCR не работает должным образом, при извлечении текста из рукописных заметок, в действительности оно работает исключительно хорошо при использовании печатной версии.
- Text-image.com
Другой лучший инструмент оптического распознавания текста для деловых документов — text-image. com. Это веб-программа для обработки текста, включая инструменты редактирования и стили, которые помогут вам форматировать текст и абзацы.Кроме того, в нем есть функция распознавания текста, которая позволяет бесплатно преобразовывать файлы PDF в редактируемый текст.
com. Это веб-программа для обработки текста, включая инструменты редактирования и стили, которые помогут вам форматировать текст и абзацы.Кроме того, в нем есть функция распознавания текста, которая позволяет бесплатно преобразовывать файлы PDF в редактируемый текст.
Макет и важные компоненты документа также определяются программой автоматически. Он также позволяет извлекать информацию из различных документов и отображать ее в табличном формате. Кроме того, вы можете поделиться своими документами с кем угодно, и они будут просматривать эти документы в режиме реального времени.
Этот инструмент позволяет вам модифицировать инструмент распознавания текста в соответствии с вашими требованиями.Автоматическое сканирование, а также ручное сканирование позволяют полностью контролировать передачу текста. Кроме того, у вас есть возможность заархивировать свой документ и добавить ограничения, чтобы ограничить возможность изменять и дублировать его.
Заключение
Компании все больше полагаются на технологии для ускорения роста, и программное обеспечение оптического распознавания символов (OCR) стало решающим решением в этом контексте. Как вы можете понять из приведенного выше списка, на рынке доступно большое количество бесплатных онлайн-инструментов, в которых используется Optical Character.Программные пакеты распознавания для преобразования изображений в текст на ваш выбор. В результате я надеюсь, что этот пост помог вам определить инструмент, который наилучшим образом соответствует вашим желаниям и сэкономит ваше драгоценное время.
Как вы можете понять из приведенного выше списка, на рынке доступно большое количество бесплатных онлайн-инструментов, в которых используется Optical Character.Программные пакеты распознавания для преобразования изображений в текст на ваш выбор. В результате я надеюсь, что этот пост помог вам определить инструмент, который наилучшим образом соответствует вашим желаниям и сэкономит ваше драгоценное время.
Следите за нами и ставьте лайки:
Обнаружение текста — Amazon Rekognition
Amazon Rekognition может обнаруживать текст в изображениях и видео. Затем он может преобразовать обнаруженные
текст в
машиночитаемый текст.Вы можете использовать обнаружение машиночитаемого текста на изображениях, чтобы реализовать
такие решения как:
Визуальный поиск.
Например, получение и отображение изображений, содержащих одинаковые
текст.Анализ содержания. Например, предоставление информации о темах, встречающихся в тексте.
это распознается в извлеченных видеокадрах.Ваше приложение может искать признанные
текст для релевантного содержания, такого как новости, спортивные результаты, номера спортсменов и
подписи.Навигация.
Например, разработка мобильного приложения с поддержкой речи для визуального
инвалиды, которые узнают названия ресторанов, магазинов или уличные знаки.Общественная безопасность и транспортная поддержка.Например, обнаружение номерного знака автомобиля
числа из изображений с камеры дорожного движения.Фильтрация. Например, фильтрация информации, позволяющей установить личность (PII) из
изображений.
 Например, получение и отображение изображений, содержащих одинаковые
Например, получение и отображение изображений, содержащих одинаковые Например, разработка мобильного приложения с поддержкой речи для визуального
Например, разработка мобильного приложения с поддержкой речи для визуального
Для обнаружения текста в видео вы можете реализовать такие решения, как:
Поиск в видео клипов с определенными текстовыми ключевыми словами, такими как имя гостя на
изображение в новостном шоу.Модерирование контента на соответствие стандартам организации путем обнаружения
случайный текст, ненормативная лексика или спам.Поиск всех текстовых наложений на временной шкале видео для дальнейшей обработки, например
замена текста текстом на другом языке для контента
интернационализация.Поиск местоположений текста, чтобы можно было соответствующим образом выровнять другую графику.
Для обнаружения текста в изображениях в формате JPEG или PNG используйте операцию DetectText. Чтобы асинхронно обнаруживать текст в видео, используйте
Чтобы асинхронно обнаруживать текст в видео, используйте
StartTextDetection и GetTextDetection
операции. Операции по обнаружению текста и изображений, и видео поддерживают большинство шрифтов, в том числе
сильно стилизованные. После обнаружения текста Amazon Rekognition создает представление
обнаруженных
слова и строки текста, показывает взаимосвязь между ними и сообщает вам, где
текст
находится на изображении или видеокадре.
Операции DetectText и GetTextDetection обнаруживают слова и
линий. Слово — это один или несколько символов латинского алфавита стандарта ISO из
стандартный английский алфавит и символы ASCII, не разделенные пробелами.
DetectText может обнаруживать до 100 слов в изображении. GetTextDetection может обнаруживать до 50 слов в кадре видео. В
В следующей таблице перечислены символы, которые может обнаруживать Amazon Rekognition.
Категория | Поддерживаемые символы |
|---|---|
| Прописные буквы | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
Строчные буквы | abcdefghijklmnopqrstuvwxyz |
Номера | 0123456789 |
| Символы | ! «# $% & \ ‘() * +, -. _ `{| } _ `{| }~ |
Amazon Rekognition предназначен для обнаружения слов на английском языке. Он также может обнаруживать слова
в других
языки, использующие эти символы, но не распознающие диакритические знаки и другие символы.Например, он может обнаруживать «un» во французском языке, но не может обнаруживать «garçon» или может
нет
определить его правильно.
Строка — это строка слов с равным интервалом. Линия не обязательно
полное предложение (точка не указывает конец строки). Например, Amazon
Например, Amazon
Rekognition
определяет номер водительского удостоверения в виде строки.Линия заканчивается, когда нет выровненной
текст после
это или когда есть большой разрыв между словами относительно длины слов.
В зависимости от
о разрыве слов, Amazon Rekognition
мог бы
обнаруживать несколько строк в тексте, выровненных в одном направлении. Если
предложение занимает несколько строк, операция возвращает несколько строк.
Рассмотрим следующее изображение.
Синие поля представляют информацию об обнаруженном тексте и местонахождении
текст
который возвращается операцией DetectText . В этом примере Amazon Rekognition обнаруживает
В этом примере Amazon Rekognition обнаруживает
«ЭТО», «ПОНЕДЕЛЬНИК», «но», «держать» и «Улыбаться» как слова.Amazon Rekognition обнаруживает
«ЭТО ПОНЕДЕЛЬНИК»,
«но держись» и «улыбайся» в виде линий. Чтобы быть обнаруженным, текст должен быть
в
+/- 90 градусов ориентации горизонтальной оси.
Для
пример см. в разделе «Обнаружение текста на изображении».
TextGrabber сканирование и перевод в App Store
Захватите любой текст в реальном времени!
Используйте его как хотите: копируйте, делитесь, переводите, отправляйте по электронной почте, создавайте события, ищите на картах и т. Д.
Д.
ABBYY TextGrabber легко и быстро оцифровывает фрагменты печатного текста, считывает QR-коды и превращает распознанный результат в действия: звоните, пишите, переводите на 100+ языков онлайн и на 10 языков офлайн, ищите в Интернете или на картах, создавайте события в календаре редактируйте, озвучивайте и делитесь любым удобным способом.
Когда вы наводите камеру на печатный текст, TextGrabber мгновенно захватывает и распознает информацию без подключения к Интернету. Уникальный режим распознавания в реальном времени извлекает информацию на более чем 60 языках не только из документов, но и с любых поверхностей.
Победитель премии SUPERSTAR в категориях «Мобильное приложение для повышения производительности», «Мобильное приложение для захвата изображений» и «Ввод текста» в конкурсе Mobile Star Awards
——————- ——
«TextGrabber, вероятно, лучшее приложение, которое добавляет еще одну функцию к вашему iPhone: сканер» — The Irish Times
«Результаты выдаются относительно быстро, и это здорово. Обязательно для студентов »- appadvice.com
Обязательно для студентов »- appadvice.com
« Лучшее приложение для преобразования изображений в текст для iPhone »- lifehacker.com
——————— —
КЛЮЧЕВЫЕ ФУНКЦИИ:
• Перевод в реальном времени прямо на экране камеры без фотографирования на 100+ языков онлайн (полнотекстовый перевод) и 10 языков офлайн (пословный перевод).
• Инновационный режим распознавания в реальном времени, основанный на технологии ABBYY RTR SDK, позволяет оцифровывать печатный текст прямо на экране камеры без фотографирования.
• Распознавание текста на 60+ языках, включая русский, английский, немецкий, испанский, греческий, турецкий, китайский и корейский, без подключения к Интернету.
• Все ссылки, номера телефонов, адреса электронной почты, почтовые адреса и даты после оцифровки становятся интерактивными: вы можете щелкнуть ссылку, позвонить, написать электронное письмо, найти адрес на картах или добавить событие в календарь.
• Ярлыки Siri. Чтобы распознать последнюю фотографию с помощью Siri, создайте ярлык Siri в настройках iPhone.
• Считыватель QR-кода.
• Мощная функция преобразования текста в речь с помощью функции системы VoiceOver.
• Регулируемые размеры шрифта и звуковые подсказки для людей с ослабленным зрением: вы можете увеличить размер шрифта и использовать звуковые подсказки для элементов интерфейса.
• Отправьте результаты в любое приложение, установленное на устройстве, через системное меню.
• Для всего извлеченного текста автоматически создается резервная копия, и его можно легко найти в папке «История».
————————
Бесплатная версия с рекламой и обеспечивает распознавание и перевод 3 текстов.
С помощью ABBYY TextGrabber вы можете сохранить и перевести любой печатный текст, который вам нужен, одним касанием экрана:
• Тексты с экрана телевизора или смартфона
• Квитанции
• Этикетки и счетчики
• Путевые документы
• Журнальные статьи и фрагменты книг
• Руководства и инструкции
• Ингредиенты рецептов и т. Д.
————————
СОВЕТ OCR: выберите соответствующий язык (до трех в раз) до распознавания
————————
Twitter @abbyy_mobile_ww
FB.com / AbbyyMobile
VK.com/abbyylingvo
YouTube.com/AbbyyMobile
———————— Автоматически продлеваемая подписка на Премиум-аккаунт
позволяет использовать все функции этого приложения. Срок действия подписки: 1 месяц и 1 год. Подписка автоматически продлевается в конце периода, если вы не решите отменить подписку по крайней мере за 24 часа до окончания текущего периода. Оплата будет снята с вашей учетной записи iTunes при подтверждении покупки. Вы можете управлять своей подпиской и отключить автоматическое продление в настройках своей учетной записи после покупки.Любая неиспользованная часть бесплатного пробного периода, если таковая предлагается, будет аннулирована, если вы приобретете подписку на эту публикацию.
Конфиденциальность: https://www.abbyy.com/privacy/
Условия использования: http://www.textgrabber.pro/en/eula/
————— ———
ABBYY TEXTGRABBER — САМЫЙ БЫСТРЫЙ СПОСОБ Оцифровки, ПЕРЕВОДА И ДЕЙСТВИЯ ЛЮБОЙ ПЕЧАТНОЙ ИНФОРМАЦИИ!
Пожалуйста, оставьте отзыв, если вам нравится ABBYY TextGrabber. Спасибо!
7 лучших бесплатных программ для оптического распознавания текста для преобразования изображений в текст
Хотите бесплатное программное обеспечение для распознавания текста? В этой статье собраны семь лучших программ, которые ничего не стоят.
Что такое OCR?
Программа оптического распознавания символов (OCR) преобразует изображения или даже рукописный текст в текст. Программное обеспечение OCR анализирует документ и сравнивает его со шрифтами, хранящимися в их базе данных, и / или отмечая особенности, характерные для символов. Некоторые программы OCR также используют программу проверки орфографии, чтобы «угадать» нераспознанные слова. Трудно достичь 100% точности, но большая часть программного обеспечения стремится к точному приближению.
Программное обеспечение OCR может помочь студентам, исследователям и офисным работникам повысить производительность труда. Итак, давайте поиграем еще с несколькими и найдем лучшее программное обеспечение для оптического распознавания текста, соответствующее вашим потребностям.
1. OCR с использованием Microsoft OneNote
Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками.
- Перетащите отсканированное изображение или сохраненное изображение в OneNote.Вы также можете использовать OneNote, чтобы закрепить часть экрана или изображение в OneNote.
- Щелкните правой кнопкой мыши вставленное изображение и выберите Копировать текст с изображения . Скопированный оптически распознанный текст попадает в буфер обмена, и теперь вы можете вставить его обратно в OneNote или в любую программу, например Word или Блокнот.
OneNote также может извлекать текст из многостраничной распечатки одним щелчком мыши.Вставьте распечатку нескольких страниц в OneNote, а затем щелкните правой кнопкой мыши текущую выбранную страницу.
- Щелкните Копировать текст с этой страницы распечатки , чтобы получить текст только с этой выбранной страницы.
- Щелкните Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех страниц одним снимком, как вы можете видеть ниже.
Обратите внимание, что точность OCR также зависит от качества фотографии.Вот почему оптическое распознавание почерка все еще немного нечеткое для OneNote и другого программного обеспечения для распознавания текста на рынке. Тем не менее, это одна из ключевых функций OneNote, которую вы должны использовать при каждой возможности.
Хотите узнать, как OneNote сравнивается с платным программным обеспечением для распознавания текста? Прочтите наше сравнение OneNote и OmniPage.
2. SimpleOCR
Трудность, с которой я столкнулся с распознаванием рукописного ввода с помощью инструментов MS, могла найти решение в SimpleOCR.Но программа предлагает распознавание рукописного ввода только в виде 14-дневной бесплатной пробной версии. Распознавание машинной печати, хотя не имеет ограничений .
Программное обеспечение выглядит устаревшим, поскольку оно не обновлялось с версии 3.1, но вы все равно можете попробовать его из-за его простоты.
- Настройте его для чтения прямо со сканера или путем добавления страницы (форматы JPG, TIFF, BMP).
- SimpleOCR предлагает некоторый контроль над преобразованием с помощью функций выделения текста, выбора изображения и игнорирования текста.
- Преобразование в текст переводит процесс в на этап проверки; пользователь может исправить неточности в преобразованном тексте с помощью встроенной проверки орфографии.
- Конвертированный файл можно сохранить в формате DOC или TXT.
SimpleOCR отлично справлялся с обычным текстом, но его обработка многоколоночных макетов разочаровывала.На мой взгляд, точность преобразования инструментов Microsoft была значительно лучше, чем SimpleOCR.
Загрузка: SimpleOCR для Windows (бесплатно, платно)
3. Сканирование фотографий
Photo Scan — это бесплатное приложение для распознавания текста для Windows 10, которое можно загрузить из Microsoft Store. Приложение, созданное Define Studios, поддерживается рекламой, но это не мешает работе. Приложение представляет собой сканер OCR и считыватель QR-кода в одном флаконе.
Наведите приложение на изображение или распечатку файла. Вы также можете использовать веб-камеру вашего ПК, чтобы дать ему изображение. Распознанный текст отображается в соседнем окне.
Функция преобразования текста в речь выделяется. Щелкните значок динамика, и приложение прочитает вслух то, что только что отсканировало.
С рукописным текстом не очень хорошо, но распознания печатного текста было достаточно. Когда все будет сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, Rich Text, XML, формат журнала и т. Д.
Загрузить: Photo Scan (Бесплатная покупка в приложении)
4. (a9t9) Бесплатное приложение OCR для Windows
(a9t9) Бесплатное программное обеспечение OCR — это приложение для универсальной платформы Windows. Таким образом, вы можете использовать его с любым устройством Windows, которое у вас есть. Существует также онлайн-эквивалент OCR, работающий на том же API.
(a9t9) поддерживает 21 язык для преобразования изображений и PDF в текст.Приложение также можно использовать бесплатно, а поддержку рекламы можно удалить с помощью покупки в приложении. Как и большинство бесплатных программ OCR, это идея для печатных документов, а не для рукописного текста.
Загрузить: a9t9 Free OCR (бесплатно, покупка в приложении)
5. Capture2Text
Capture2Text — это бесплатное программное обеспечение для распознавания текста для Windows 10, которое дает вам сочетания клавиш для быстрого распознавания текста на экране.Также не требует установки.
Используйте комбинацию клавиш по умолчанию WinKey + Q , чтобы активировать процесс распознавания текста. Затем вы можете использовать мышь, чтобы выбрать часть, которую хотите захватить. Нажмите Enter, и выделение будет оптически распознано. Захваченный и преобразованный текст появится во всплывающем окне и также будет скопирован в буфер обмена.
Capture2Text использует движок Google OCR и поддерживает более 100 языков.Он использует Google Translate для преобразования захваченного текста на другие языки. Загляните внутрь Settings , чтобы настроить различные параметры, предоставляемые программным обеспечением.
Загрузка: Capture2Text (бесплатно)
6. Easy Screen OCR
Easy Screen OCR не является бесплатным. Но я упоминаю об этом здесь, потому что это быстро и удобно. Вы также можете бесплатно использовать его от до 20 раз по без какой-либо подписки.Программа работает из панели задач или панели задач. Щелкните правой кнопкой мыши значок Easy Screen OCR и выберите в меню Capture . Сделайте снимок экрана любого изображения, веб-сайта, видео, документа или чего-либо еще на экране, перетащив курсор мыши.
Затем Easy Screen OCR отображает диалоговое окно с тремя вкладками. Вкладка снимков экрана дает вам предварительный просмотр захваченного текста. Нажмите кнопку OCR, чтобы прочитать текст с изображения. Оптически преобразованный текст теперь можно скопировать из вкладки «Текст» диалогового окна.
Вы можете установить языки распознавания для OCR в настройках программного обеспечения. Поддерживается более 100 языков , поскольку программное обеспечение использует механизм распознавания текста Google.
Загрузить: Easy Screen OCR (9 долларов в месяц)
Также: OCR с Google Docs
Если вы находитесь далеко от своего компьютера, попробуйте функции распознавания текста на Google Диске. В Google Docs есть встроенная программа OCR, которая может распознавать текст в файлах JPEG, PNG, GIF и PDF.Но все файлы должны быть не более 2 МБ, а текст — 10 пикселей или больше. Google Диск также может автоматически определять язык в отсканированных файлах, хотя точность с нелатинскими символами может быть невысокой.
- Войдите в свою учетную запись на Google Диске.
- Щелкните New> File Upload . Кроме того, вы также можете щелкнуть Мой диск> Загрузить файлы .
- Найдите на своем компьютере файл, который вы хотите преобразовать из PDF-файла или изображения в текст. Нажмите кнопку Открыть , чтобы загрузить файл.
- Документ теперь находится на вашем Google Диске. Щелкните документ правой кнопкой мыши и выберите Открыть с помощью> Google Docs .
- Google конвертирует ваш PDF-файл или файл изображения в текст с помощью OCR и открывает его в новом документе Google.Текст доступен для редактирования, и вы можете исправить те части, в которых OCR не смог его правильно прочитать.
- Вы можете загружать оптимизированные документы в различных форматах, поддерживаемых Google Диском. Выберите из меню File> Download as .
Бесплатное программное обеспечение OCR, которое вы можете выбрать
Хотя бесплатные инструменты подходили для печатного текста, они не справлялись с обычным курсивом рукописного текста.Я лично предпочитаю использовать оптическое распознавание текста в Microsoft OneNote, потому что вы можете сделать его частью рабочего процесса создания заметок. Photo Scan — универсальное приложение для Магазина Windows, поддерживающее разрывы строк в различных форматах документов, в которые вы можете сохранять.
Но не позволяйте вашему поиску бесплатных конвертеров OCR на этом заканчиваться. Есть много других альтернативных способов распознавания текста и изображений. И раньше мы протестировали несколько онлайн-инструментов OCR. Держите их тоже рядом.
Кредит изображения: nikolay100 / Depositphotos
Почему планшеты с Android не годятся (и что покупать вместо них)
Думаете о покупке планшета Android? Вот причины, по которым стоит рассмотреть альтернативные планшеты, а также несколько рекомендаций по использованию таблеток.
Читать далее
Об авторе
Сайкат Басу
(Опубликовано 1542 статей)
Сайкат Басу — заместитель редактора по Интернету, Windows и производительности.Избавившись от грязи MBA и проработав десять лет в маркетинге, он теперь увлечен тем, что помогает другим улучшить свои навыки рассказывания историй. Он следит за пропавшей оксфордской запятой и ненавидит плохие скриншоты. Но идеи фотографии, фотошопа и производительности успокаивают его душу.
Более
От Сайката Басу
Подпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Нажмите здесь, чтобы подписаться
OCR на основе глубокого обучения для текста в дикой природе
Мы живем во времена, когда любая организация или компания, стремящаяся к масштабированию и сохранению актуальности, должна изменить свой взгляд на технологии и быстро адаптироваться к меняющимся условиям.Мы уже знаем, как Google оцифровал книги. Или как Google Earth использует NLP (или NER) для идентификации адресов. Или как можно читать текст в цифровых документах, таких как счета-фактуры, юридические документы и т. Д.
Но как именно это работает?
Этот пост посвящен оптическому распознаванию символов (OCR) для распознавания текста в естественных изображениях сцены. Мы узнаем о том, почему это сложная проблема, о подходах к ее решению и о соответствующем коде.
Имеете в виду проблему распознавания текста? Хотите извлечь данные из документов? Зайдите в Nanonets и создавайте модели OCR бесплатно!
Но почему на самом деле?
В нашу эпоху оцифровки хранить, редактировать, индексировать и находить информацию в цифровом документе намного проще, чем тратить часы на просмотр распечатанных / рукописных / печатных документов.
Более того, поиск чего-либо в большом нецифровом документе занимает не только много времени, но и может упустить информацию при прокрутке документа вручную. К счастью для нас, компьютеры с каждым днем становятся все лучше и лучше, выполняя те задачи, которые люди думали только о них, и часто работают лучше, чем мы.
Извлечение текста из изображений нашло множество применений.
Некоторые из приложений: распознавание паспортов, автоматическое распознавание номерных знаков, преобразование рукописных текстов в цифровой, преобразование печатного текста в цифровой и т. Д.
Проблемы
Источник изображения: https://pixabay.com
Прежде чем мы расскажем, как нам нужно понять проблемы, с которыми мы сталкиваемся при распознавании текста.
Многие реализации OCR были доступны еще до бума глубокого обучения в 2012 году. Хотя обычно считалось, что OCR — это решенная проблема, OCR по-прежнему остается сложной проблемой, особенно когда текстовые изображения снимаются в неограниченной среде.
Я говорю о сложном фоне, шуме, молниях, различном шрифте и геометрических искажениях изображения.
Именно в таких ситуациях блестят инструменты машинного обучения OCR (или машинного обучения обработки изображений).
Проблемы с распознаванием текста возникают в основном из-за свойств выполняемых задач распознавания текста. Обычно мы можем разделить эти задачи на две категории:
Структурированный текст — Текст в печатном документе. Стандартный фон, правильный ряд, стандартный шрифт и в основном плотный.
Структурированный текст: плотные, удобочитаемые стандартные шрифты; Источник изображения: https: // pixabay.com
Неструктурированный текст- Текст в произвольных местах на естественной сцене. Редкий текст, отсутствие правильной структуры строк, сложный фон, случайное место на изображении и отсутствие стандартного шрифта.
Неструктурированные тексты: рукописные, несколько шрифтов и разреженные; Источник изображения: https://pixabay.com
Многие более ранние методы решали проблему распознавания текста для структурированного текста.
Но эти методы не работали должным образом для естественной сцены, которая является разреженной и имеет другие атрибуты, чем структурированные данные.
В этом блоге мы сосредоточимся больше на неструктурированном тексте, который представляет собой более сложную проблему для решения .
Как мы знаем в мире глубокого обучения, не существует единого решения, подходящего для всех. Мы увидим несколько подходов к решению поставленной задачи и проработаем один из них.
Nanonets OCR API имеет много интересных вариантов использования. Чтобы узнать больше, поговорите со специалистом по ИИ Nanonets.
Запланировать звонок
Наборы данных для неструктурированных задач OCR
Существует множество наборов данных на английском языке, но найти наборы данных для других языков сложнее.Различные наборы данных представляют разные задачи, которые необходимо решить. Вот несколько примеров наборов данных, обычно используемых для задач распознавания текста машинным обучением.
Набор данных SVHN
Набор данных Street View House Numbers содержит 73257 цифр для обучения, 26032 цифры для тестирования и 531131 дополнительных в качестве дополнительных обучающих данных. Набор данных включает 10 меток, которые представляют собой цифры от 0 до 9. Набор данных отличается от MNIST, поскольку SVHN имеет изображения номеров домов с номерами домов на разном фоне.В наборе данных есть ограничивающие прямоугольники вокруг каждой цифры вместо нескольких изображений цифр, как в MNIST.
Набор данных текста сцены
Этот набор данных состоит из 3000 изображений в различных настройках (в помещении и на улице) и условиях освещения (тень, свет и ночь) с текстом на корейском и английском языках. Некоторые изображения также содержат цифры.
Набор данных Devanagri Character
Этот набор данных предоставляет нам 1800 образцов из 36 классов символов, полученных 25 различными авторами в сценарии devanagri.
И есть много других, таких как этот для китайских иероглифов, этот для CAPTCHA или этот для рукописных слов.
Любой Типичный конвейер OCR с машинным обучением включает следующие шаги:
Поток OCR
Предварительная обработка
- Удаление шума из изображения
- Удаление сложного фона из изображения
- Обработка различных условий освещения в изображении
Удаление шума из изображения . Source
Это стандартные способы предварительной обработки изображения в задаче компьютерного зрения.В этом блоге мы не будем заострять внимание на этапе предварительной обработки.
Обнаружение текста
источник
Методы обнаружения текста, необходимые для обнаружения текста в изображении и создания ограничивающей рамки вокруг части изображения, содержащей текст. Здесь также будут работать стандартные методы обнаружения возражений.
Техника скользящего окна
Ограничивающая рамка может быть создана вокруг текста с помощью техники скользящего окна. Однако это вычислительно дорогостоящая задача.В этом методе скользящее окно проходит через изображение для обнаружения текста в этом окне, как сверточная нейронная сеть. Мы стараемся с другим размером окна, чтобы не пропустить текстовую часть другого размера. Существует сверточная реализация скользящего окна, которая может сократить время вычислений.
Детекторы одиночного снимка и детектора области
Существуют методы однократного обнаружения, такие как YOLO (вы смотрите только один раз) и методы обнаружения текста на основе области для обнаружения текста на изображении.
Архитектура YOLO: исходный код
YOLO — это однократная техника, когда вы передаете изображение только один раз, чтобы обнаружить текст в этой области, в отличие от скользящего окна.
Региональный подход работает в два этапа.
Сначала сеть предлагает область, в которой, возможно, будет проходить тест, а затем классифицирует область, есть ли в ней текст или нет. Вы можете обратиться к одной из моих предыдущих статей, чтобы понять методы обнаружения объектов, в нашем случае обнаружения текста.
EAST (Эффективный точный детектор текста сцены)
Это очень надежный метод глубокого обучения для обнаружения текста, основанный на этой статье.Стоит упомянуть, что это всего лишь метод обнаружения текста. Он может находить горизонтальные и повернутые ограничивающие рамки. Его можно использовать в сочетании с любым методом распознавания текста.
Конвейер обнаружения текста в этой статье исключил избыточные и промежуточные этапы и состоит только из двух этапов.
One использует полностью сверточную сеть для непосредственного прогнозирования на уровне слов или текстовых строк. Полученные прогнозы, которые могут быть повернутыми прямоугольниками или четырехугольниками, дополнительно обрабатываются на этапе подавления без максимального значения, чтобы получить окончательный результат.
Изображение взято с https://arxiv.org/pdf/1704.03155v2.pdf
EAST может обнаруживать текст как на изображениях, так и на видео. Как упоминалось в документе, он работает почти в реальном времени со скоростью 13 кадров в секунду на изображениях 720p с высокой точностью обнаружения текста. Еще одним преимуществом этого метода является то, что его реализация доступна в OpenCV 3.4.2 и OpenCV 4. Мы увидим эту модель EAST в действии вместе с распознаванием текста.
Распознавание текста
После того, как мы обнаружили ограничивающие прямоугольники с текстом, следующим шагом будет распознавание текста.Есть несколько техник распознавания текста. В следующем разделе мы обсудим некоторые из лучших техник.
CRNN
Сверточная рекуррентная нейронная сеть (CRNN) представляет собой комбинацию потерь CNN, RNN и CTC (Connectionist Temporal Classification) для задач распознавания последовательности на основе изображений, таких как распознавание текста сцены и OCR. Сетевая архитектура была взята из этой статьи, опубликованной в 2015 году.
Изображение взято с https: // arxiv.org / pdf / 1507.05717.pdf
Эта архитектура нейронной сети объединяет извлечение признаков, моделирование последовательностей и транскрипцию в единую структуру. Эта модель не требует сегментации символов. Сверточная нейронная сеть извлекает признаки из входного изображения (область обнаружения текста). Глубокая двунаправленная рекуррентная нейронная сеть предсказывает последовательность меток с некоторой связью между символами. Слой транскрипции преобразует кадр, созданный RNN, в последовательность меток.Существует два режима транскрипции, а именно транскрипция без лексикона и транскрипция на основе лексики. В подходе, основанном на лексике, будет предсказана наиболее вероятная последовательность меток.
Машинное обучение OCR с Tesseract
Tesseract был первоначально разработан в Hewlett-Packard Laboratories в период с 1985 по 1994 год. В 2005 году он был открыт в HP. Согласно википедии:
В 2006 году Tesseract считался одним из наиболее точных на тот момент движков OCR с открытым исходным кодом.
Возможности Tesseract в основном ограничивались структурированными текстовыми данными. Он будет плохо работать с неструктурированным текстом со значительным шумом. Дальнейшая разработка tesseract спонсируется Google с 2006 года.
Метод, основанный на глубоком обучении, лучше работает с неструктурированными данными. В Tesseract 4 добавлены возможности на основе глубокого обучения с механизмом OCR на основе сети LSTM (своего рода рекуррентной нейронной сети), который ориентирован на распознавание строк, но также поддерживает устаревший механизм Tesseract OCR Tesseract 3, который работает путем распознавания шаблонов символов.Последняя стабильная версия 4.1.0 выпущена 7 июля 2019 года. Эта версия также значительно более точна в отношении неструктурированного текста.
Мы будем использовать некоторые изображения, чтобы показать как обнаружение текста с помощью метода EAST, так и распознавание текста с помощью Tesseract 4. Давайте посмотрим на обнаружение и распознавание текста в действии в следующем коде. Данная статья оказалась полезным ресурсом при написании кода для этого проекта.
## Загрузка необходимых пакетов
импортировать numpy как np
импорт cv2
от imutils.object_detection импорт non_max_suppression
импорт pytesseract
from matplotlib import pyplot as plt Загрузка пакетов
# Создание словаря аргументов для аргументов по умолчанию, необходимых в коде.
args = {"image": "../ input / text-detection / example-images / Example-images / ex24.jpg", "east": "../ input / text-detection / east_text_detection.pb", " min_confidence ": 0,5," ширина ": 320," высота ": 320}
Создание словаря аргументов с некоторыми значениями по умолчанию
Здесь я работаю с основными пакетами.Пакет OpenCV использует модель EAST для обнаружения текста. Пакет tesseract предназначен для распознавания текста в ограничивающей рамке, обнаруженной для текста. Убедитесь, что у вас версия tesseract> = 4. В Интернете доступно несколько источников для руководства по установке tesseract.
Создал словарь для аргументов по умолчанию, необходимых в коде. Посмотрим, что означают эти аргументы.
- изображение: расположение входного изображения для обнаружения и распознавания текста.
- восток: расположение файла с предварительно обученной моделью детектора EAST.
- минимальная достоверность: минимальная оценка вероятности достоверности геометрической формы, спрогнозированной для данного местоположения.
- ширина: для правильной работы модели EAST ширина изображения должна быть кратна 32.
- высота: для правильной работы модели EAST высота изображения должна быть кратна 32.
# Укажите местоположение изображения для чтения.
# Здесь загружается изображение "Example-images / ex24.jpg".
args ['image'] = "../ input / text-detection / example-images / Example-images / ex24.jpg "
image = cv2.imread (args ['изображение'])
# Сохранение исходного изображения и формы
orig = image.copy ()
(origH, origW) = image.shape [: 2]
# установить новую высоту и ширину по умолчанию 320 с помощью args #dictionary.
(newW, newH) = (args ["ширина"], args ["высота"])
# Рассчитайте соотношение между исходным и новым изображением как для роста, так и для веса.
# Это соотношение будет использоваться для перевода положения ограничивающей рамки на исходном изображении.
rW = origW / float (newW)
rH = origH / float (newH)
# изменить размер исходного изображения до новых размеров
изображение = cv2.resize (изображение; (newW, newH))
(H, W) = image.shape [: 2]
# создаем blob из изображения, чтобы передать его модели EAST
blob = cv2.dnn.blobFromImage (изображение, 1.0, (Ш, В),
(123.68, 116.78, 103.94), swapRB = True, crop = False) Обработка изображений
# загрузка предварительно обученной модели EAST для обнаружения текста
net = cv2.dnn.readNet (args ["восток"])
# Мы хотели бы получить два вывода от модели EAST.
№1. Оценки вероятности для региона, содержит он текст или нет.
№2. Геометрия текста - Координаты ограничивающей рамки, определяющей текст
# Следующие два слоя необходимо извлечь из модели EAST для этого.layerNames = [
"feature_fusion / Conv_7 / Sigmoid",
"feature_fusion / concat_3"] Загрузка предварительно обученной модели EAST и определение выходных слоев
# Вперед передать blob из изображения, чтобы получить желаемые выходные слои
net.setInput (большой двоичный объект)
(scores, geometry) = net.forward (layerNames) Прямое прохождение изображения через модель EAST
## Возвращает ограничивающую рамку и оценку вероятности, если она превышает минимальную достоверность
прогнозы def (prob_score, geo):
(numR, numC) = prob_score.форма [2: 4]
коробки = []
доверие_val = []
# перебирать ряды
для y в диапазоне (0, numR):
scoresData = prob_score [0, 0, y]
x0 = geo [0, 0, y]
x1 = geo [0, 1, y]
x2 = geo [0, 2, y]
x3 = geo [0, 3, y]
anglesData = geo [0, 4, y]
# перебрать количество столбцов
для i в диапазоне (0, numC):
если scoresData [i] Функция декодирования ограничивающего прямоугольника из прогноза модели EAST
В этом упражнении мы декодируем только горизонтальные ограничивающие прямоугольники.Расшифровка вращающихся ограничивающих рамок из партитур и геометрии более сложна.
# Найдите прогнозы и примените подавление не максимальных значений
(коробки, доверительное_значение) = прогнозы (баллы, геометрия)
boxs = non_max_suppression (np.array (box), probs = trust_val) Получение окончательных ограничивающих рамок после подавления без максимума
Теперь, когда мы вывели ограничивающие прямоугольники после применения подавления без максимума. Мы хотели бы видеть ограничивающие рамки на изображении и то, как мы можем извлечь текст из обнаруженных ограничивающих рамок.Мы делаем это с помощью тессеракта.
## Обнаружение и распознавание текста
# инициализировать список результатов
результаты = []
# перебираем ограничивающие прямоугольники, чтобы найти координаты ограничивающих прямоугольников
для (startX, startY, endX, endY) в полях:
# масштабируйте координаты на основе соответствующих соотношений, чтобы отразить ограничивающую рамку на исходном изображении
startX = int (startX * rW)
startY = int (startY * rH)
конецX = число (конецX * rW)
конецY = целое (конецY * rH)
# извлечь интересующую область
r = orig [начало: конецY, началоX: конецX]
#configuration параметр для преобразования изображения в строку.конфигурация = ("-l eng --oem 1 --psm 8")
## Это распознает текст на изображении ограничивающей рамки
text = pytesseract.image_to_string (r, config = конфигурация)
# добавить координату bbox и связанный текст в список результатов
results.append (((startX, startY, endX, endY), text)) Создание списка с координатами ограничивающего прямоугольника и распознанным текстом в полях
В приведенной выше части кода сохранены координаты ограничивающего прямоугольника и связанный текст в списке. Посмотрим, как это будет выглядеть на изображении.
В нашем случае мы использовали определенную конфигурацию тессеракта. Для настройки тессеракта доступно несколько опций.
l: язык , выбран английский в приведенном выше коде.
OEM (режимы OCR Engine):
0 Только старый двигатель.
1 Только движок LSTM нейронных сетей.
2 двигателя Legacy + LSTM.
3 По умолчанию, в зависимости от того, что доступно.
psm (режимы сегментации страниц):
0 Только ориентация и обнаружение скриптов (OSD).
1 Автоматическая сегментация страниц с помощью экранного меню.
2 Автоматическая сегментация страниц, но без OSD или OCR. (не реализовано)
3 Полностью автоматическая сегментация страниц, без экранного меню. (По умолчанию)
4 Предположим, что один столбец текста переменного размера.
5 Предположим, что это один однородный блок вертикально выровненного текста.
6 Предположим, что это один однородный блок текста.
7 Считайте изображение одной текстовой строкой.
8 Обращайтесь с изображением как с одним словом.
9 Рассматривайте изображение как отдельное слово в круге.
10 Считайте изображение одним символом.
11 Редкий текст. Найдите как можно больше текста в произвольном порядке.
12 Разреженный текст в экранном меню.
13 Необработанная линия. Относитесь к изображению как к одной текстовой строке, минуя хаки, специфичные для Tesseract.
Мы можем выбрать конкретную конфигурацию Tesseract на основе наших данных изображения.
# Показать изображение с ограничивающей рамкой и распознанным текстом
orig_image = orig.copy ()
# Перемещение результатов и отображение на изображении
for ((start_X, start_Y, end_X, end_Y), text) в результатах:
# отображаем текст, обнаруженный Tesseract
print ("{} \ n".формат (текст))
# Отображение текста
text = "" .join ([x if ord (x) <128 else "" для x в тексте]). strip ()
cv2.rectangle (orig_image, (start_X, start_Y), (end_X, end_Y),
(0, 0, 255), 2)
cv2.putText (orig_image, текст, (start_X, start_Y - 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0, 255), 2)
plt.imshow (orig_image)
plt.title ('Вывод')
plt.show () Показать изображение с ограничивающей рамкой и распознанным текстом
Результаты
В приведенном выше коде используется модель OpenCV EAST для обнаружения текста и tesseract для распознавания текста.PSM для Tesseract настроен в соответствии с изображением. Важно отметить, что для нормальной работы Tesseract обычно требуется четкое изображение.
В нашей текущей реализации мы не рассматривали вращающиеся ограничивающие прямоугольники из-за сложности реализации. Но в реальном сценарии, когда текст повернут, приведенный выше код не будет работать. Кроме того, если изображение не очень четкое, tesseract будет трудно правильно распознать текст.
Вот некоторые из выходных данных, сгенерированных приведенным выше кодом:
Источник необработанного изображения: https: // madison.citymomsblog.com Источник сырого изображения: http://lrv.fri.uni-lj.si/andreji/CVLOCRDB/ Источник сырого изображения: https://www.tripadvisor.in/
Код может обеспечить отличные результаты для всех трех вышеперечисленных изображений. Текст на этих изображениях четкий, а фон за текстом также одинаков.
Источник необработанного изображения: https://www.magic.co.nz
Модель показала здесь неплохие результаты. Но некоторые алфавиты распознаются неправильно. Вы можете видеть, что ограничивающие рамки в основном правильные, какими они должны быть.Возможно, поможет небольшое вращение. Но наша текущая реализация не предоставляет вращающихся ограничивающих рамок. Похоже, из-за четкости изображения tesseract не смог его точно распознать.
Источник необработанного изображения: https://www.ktoo.org
Модель здесь показала неплохие результаты. Но некоторые тексты в ограничивающих рамках распознаются неправильно. Цифра 1 вообще не может быть обнаружена. Здесь неоднородный фон, возможно, создание однородного фона помогло бы в этом случае. Кроме того, 24 неправильно ограничены в рамке.В таком случае может помочь заполнение ограничивающей рамки.
Источник необработанного изображения: https://www.mirror.co.uk/
Похоже, что стилизованный шрифт с тенью на заднем фоне повлиял на результат в приведенном выше случае.
Нельзя ожидать, что модель OCR будет точной на 100%. Тем не менее, мы добились хороших результатов с моделью EAST и Tesseract. Добавление дополнительных фильтров для обработки изображения поможет улучшить производительность модели.
Вы также можете найти этот код для этого проекта в ядре Kaggle, чтобы попробовать его самостоятельно.
Nanonets OCR API имеет много интересных вариантов использования. Чтобы узнать больше, поговорите со специалистом по ИИ Nanonets.
Запланировать звонок
OCR с Nanonets
API Nanonets OCR позволяет с легкостью создавать модели OCR. Вы можете загрузить свои данные, аннотировать их, настроить модель для обучения и ждать получения прогнозов через пользовательский интерфейс на основе браузера.
1. Использование графического интерфейса: https://app.nanonets.com/
Вы также можете использовать Nanonets-OCR- API, выполнив следующие действия:
2.Использование NanoNets API: https://github.com/NanoNets/nanonets-ocr-sample-python
Ниже мы дадим вам пошаговое руководство по обучению вашей собственной модели с помощью Nanonets API за 9 простых шагов. .
Шаг 1. Клонируйте репо
git clone https://github.com/NanoNets/nanonets-ocr-sample-python
CD наносети-ОКР-образец-Питон
запросы на установку sudo pip
sudo pip install tqdm Шаг 2. Получите бесплатный ключ API
Получите бесплатный ключ API с https: // app.nanonets.com/#/keys
Шаг 3. Установите ключ API как переменную среды
экспорт NANONETS_API_KEY = YOUR_API_KEY_GOES_HERE
Шаг 4. Создание новой модели
python ./code/create-model.py
Примечание. При этом создается MODEL_ID, необходимый для следующего шага.
Шаг 5: Добавить идентификатор модели в качестве переменной среды
экспорт NANONETS_MODEL_ID = YOUR_MODEL_ID
Шаг 6: Загрузите обучающие данные
Соберите изображения объекта, который вы хотите обнаружить.Когда у вас есть готовый набор данных в папке images (файлы изображений), начните загрузку набора данных.
питон ./code/upload-training.py
Шаг 7: Обучите модель
После загрузки изображений начните обучение модели
python ./code/train-model.py
Шаг 8: Получение состояния модели
Обучение модели занимает около 30 минут. Вы получите электронное письмо после обучения модели. А пока вы проверяете состояние модели
watch -n 100 python./code/model-state.py
Шаг 9: Сделайте прогноз
После обучения модели. Вы можете делать прогнозы, используя модель
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
Зайдите в Nanonets и создавайте модели компьютерного зрения бесплатно!
Дополнительная литература
Обновление # 1 :
https://nanonets.com/ocr-api уже доступно, где вы можете использовать графический интерфейс Nanonets для обучения пользовательской модели OCR, включая рабочий процесс автоматической обработки счетов .
Обновление # 2 :
Добавлены дополнительные материалы для чтения о различных подходах с использованием распознавания текста на основе глубокого обучения для извлечения текста.
Google Фото просто позволяет мне копировать текст с фотографии в мой веб-браузер
Веб-сайт Google Фото для настольных ПК, похоже, получает возможность сканировать текст в изображении и превращать его в текст, который можно скопировать и вставить, благодаря технологии Google Lens (через 9to5Google ).Некоторое время Lens был доступен во многих местах на Android, но его функция оптического распознавания символов (OCR), появившаяся на рабочем столе, может сделать Google Фото простым и бесплатным способом переноса реального текста на ваш компьютер.
Согласно 9to5Google , эта функция, похоже, широко внедряется, но автор статьи на XDA-Developers не предложил ее им. Однако я смог его использовать. Чтобы использовать его (или проверить, есть ли он у вас), загрузите сайт Google Фото и перейдите к фотографии, на которой вы записали какой-то текст (например, страницу книги, вывеску, квитанцию и т. Д.).Если Google обнаруживает слова, должна появиться кнопка «Копировать текст из изображения», и щелчок по ней откроет панель, позволяющую прочитать текст, найденный Google.
Кнопка «Копировать текст из изображения» будет отображаться на изображениях, в которых Google находит текст.
Одним из практических приложений использования Lens на настольном компьютере может быть сканирование письменных текстовых документов и вставка их во что-то, что вы пишете на настольном компьютере. Чтобы проверить это, я сделал этот снимок открытой книги, и результаты были почти безупречными:
Вы можете выделить текст прямо на фотографии или использовать боковую панель.
Объектив
даже смог правильно интерпретировать букву «».
Google Lens имеет гораздо больше возможностей на Android (и в приложении Google Photos для iOS), но похоже, что копирование текста - единственное, что до сих пор реализовано на настольных компьютерах. Браузерная версия Google Фото не предлагала перевод изображения с испанским текстом (хотя позволяла мне копировать текст), и не похоже, что она может идентифицировать такие вещи, как животные или растения.
Тем не менее, приятно видеть, что одна из самых полезных функций Lens появляется в настольной версии Google Фото, и, надеюсь, это указывает на то, что в ближайшее время появятся новые возможности.
10 лучших инструментов для преобразования изображений в текст для использования в 2021 году
Вы один из тех, кто хотел бы превращать картинки в слова? Что ж, тогда вы попали в нужное место. Добро пожаловать в эту статью. Разве это не удивительный факт, что даже в этом цифровом мире планшетов, iPad и Kindles; бумага никуда не делась из картинки? Хотя мне это интересно, это может беспокоить других.
Может возникнуть вопрос: как рукописные и бумажные документы будут соответствовать нынешнему веку, когда безбумажная культура быстро внедряется всеми? К счастью, благодаря развитию технологий теперь у нас есть ответ на этот вопрос.И ответ - технология оптического распознавания символов (OCR).
Что такое технология оптического распознавания символов (OCR)?
OCR или оптическое распознавание символов - это сложная программная технология, которая позволяет компьютеру преобразовывать бумажные документы, рукописные или статические изображения в тексты и редактируемые PDF-файлы. Вначале программное обеспечение оптического распознавания текста было довольно неточным и, как следствие, ненадежным.
Но теперь, с развитием технологий, программное обеспечение оптического распознавания текста используется в качестве сокращения производительности для многих студентов, исследователей, учителей, врачей, юристов и офисных работников.Несмотря на то, что 100-процентная точность все еще не достигнута, точное приближение - это то, что в основном подходит для всех.
Как работает технология оптического распознавания символов (Ocr)?
Как правило, OCR работает путем сканирования и анализа документа с помощью сканера и сохранения его в формате JPEG или PDF. Отсканированный и сохраненный файл затем обрабатывается программой оптического распознавания текста, где числа и буквы распознаются, а затем преобразуются в текст, редактируемый текстовый файл или доступный для поиска PDF-файл.
По мере необходимости, программное обеспечение OCR также выполняет проверку орфографии, чтобы «угадать» любые и все нераспознанные слова. Сегодня это считается одним из самых быстрых способов преобразовать текст изображения во что-то, что можно редактировать с помощью текстового процессора.
Зачем нам нужна технология оптического распознавания символов (Ocr)
Как уже говорилось в начале, технология OCR позволяет нам идти в ногу с безбумажной культурой и с большей готовностью принять ее. Но разве это единственная причина, по которой нам нужно OCR? Ответ - нет.Переписывание документа ради оцифровки может занять много времени.
Следовательно, вместо того, чтобы тратить на это невероятно много времени, лучше позволить OCR делать свою работу. Это избавляет нас от утомительных хлопот по копированию написанного текста. Это также сокращает время поиска определенного документа, пространство для хранения бумажных документов и, в то же время, повышает эффективность рабочего процесса.
Кроме того, в дополнение к преимуществам окружающей среды, программное обеспечение OCR также способствует сокращению использования бумаги.Это означает меньше рубки деревьев и больше кислорода для всех!
Теперь, когда вы знаете все об оптическом распознавании текста и его использовании, взгляните на 10 лучших онлайн-инструментов для преобразования изображения в текст:
1. FreeOCR (Windows 10)
FreeOCR - это базовое бесплатное программное обеспечение для распознавания текста, которое предлагает все основные функции, которые могут вам понадобиться от этого типа программного обеспечения. Это приложение OCR только для Windows, которое обещает точность 99,8%. Он поддерживает все основные форматы изображений, а также файлы Photoshop.
FreeOCR использует движок с открытым исходным кодом, который первоначально был разработан Hewlett Packard и в конечном итоге выпущен Google, чтобы каждый мог его использовать. Он сохраняет исходное форматирование файла и передает распознанный текст в редактируемый файл MS Word. Это означает, что вам больше не нужно тратить время на утомительное рисование прямоугольников вокруг отдельных блоков текста.
2. Microsoft OneNote
Microsoft OneNote - это преимущественно программа для хранения заметок, которая также может выступать в качестве OCR.Фактически, он имеет расширенную функцию распознавания текста, которая работает как с изображениями, так и с рукописными заметками. Он предлагает простой и легкий метод оптического распознавания символов с небольшим ограничением, заключающимся в том, что он не поддерживает таблицы и столбцы.
Добавить комментарий