
Регулярные выражения в PHP. Пробел
От автора: приветствую вас, друзья. В этой статье мы поговорим о символе пробела в PHP. Мы узнаем, какими способами можно описать пробел в шаблоне регулярного выражения, а в качестве практики составим регулярное выражение, которое будет искать лишние пробелы и удалять их. Начнем?
Итак, как же указать пробел в шаблоне регулярного выражения? Все просто. В регулярном выражении пробел обозначает сам себя. То есть мы можем нажать ту самую продолговатую клавишу SPACE на клавиатуре и шаблон регулярного выражения отыщет все пробелы в строке.
В сложных шаблонах не всегда удобно использовать пробельный символ, поскольку он трудно различим и на практике часто вместо пробела используют метасимвол \s. Однако здесь стоит помнить, что этот метасимвол совпадает не только с пробелом, но и с другими непечатными символами (символы табуляции, перевода строки, новой строки).
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Как видим, в примере выше, кроме пробелов, есть еще и символ табуляции, который был также найден. Теперь, коль мы можем найти пробел, то можем и заменить его. Например, перед нами классическая задача в PHP — заменить в URL пробелы символами тире.
Теперь, коль мы можем найти пробел, то можем и заменить его. Например, перед нами классическая задача в PHP — заменить в URL пробелы символами тире.
В используемом нами для тестирования сервисе regexr.com есть инструмент Replace, который позволяет заменить найденные символы. Как видим, все получилось.
Другой возможной задачей на практике может быть удаление лишних пробелов. Например, в текст случайно вкрались два и более пробелов, идущих подряд. Соответственно, лишние пробелы необходимо удалить. Эту задачу решить также достаточно просто. Вот один из вариантов:
Как видно, шаблон ищет один и более пробельных символов и заменяет их одним пробелом. Не забывайте, что метасимвол \s совпадает не только с пробелом. Именно поэтому для решения текущей задачи я использовал именно символ пробела, чтобы не заменить пробелом, скажем, табуляцию.
На этом мы будем завершать сегодняшнюю статью. Больше о регулярных выражениях вы можете узнать из нашего курса по регулярным выражениям. Удачи!
Удачи!
Хотите изучить регулярные выражения на PHP?
Посмотрите 12-ти часовой видео курс по регулярным выражениям на PHP!
Смотреть
Регулярные выражения кириллица PHP – вполне совместимы!
От автора: иногда среди серости будней встречаются оригинальные личности, заряжающие тебя позитивом на целую неделю. Вот на днях встретил одного разработчика, который трактует себя «русофилом». Этот от него я узнал, что регулярные выражения кириллица PHP – вполне совместимые вещи.
Зачем русский язык?
Когда-то я уже говорил, что регулярные выражения чаще всего применяются в различных типах веб-форм. В данной ситуации мы обратим свой «взор» на регистрационные формы и реализацию поддержки ими значений на русском.
Кстати, упомянутый выше «персонаж» во всех своих проектах реализует поддержку ввода кириллицы (в том числе и в формах). По его мнению, российские пользователи должны писать только на русском. Конечно, звучит немного радикально, но прок от этого тоже есть.
В PHP регулярных выражениях поддержка русских букв желательна. Таким образом вы немного улучшаете UX сайта и повышаете уровень безопасности.
Дело в том, что пароли на кириллице (по мнению многих экспертов) обладают большей степенью защищенности. И все благодаря тому, что зарубежным злоумышленникам очень трудно понять смысловую взаимосвязь русских символов, используемых в них. Это я опять привожу высказывание своего знакомого «русофила-программиста» .
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Частая проблема русификации форм
Теперь рассмотрим частую проблему, встречающуюся в PHP c русскими буквами. Регулярные выражения, в которых используются не классы символов, будут исправно работать с кириллическими значениями. Например:
<?php
$b=»В этой строке присутствует слово есть»;
if(preg_match(«/есть/»,$b))
{
echo «Подстрока найдена»;
}
else
{
echo «Подстрока не найдена»;
}
?>
<?php $b=»В этой строке присутствует слово есть»; if(preg_match(«/есть/»,$b)) { echo «Подстрока найдена»; } else { echo «Подстрока не найдена»; } ?> |
Да какие тут проблемы! Все и так работает нормально! К сожалению, не все так гладко с часто употребляемой функцией для операций с «регулярками» preg_match (). В качестве доказательства применим шаблон, созданный с помощью символьных классов:
В качестве доказательства применим шаблон, созданный с помощью символьных классов:
<?php
$b=»В этой строке присутствует слово есть»;
if(preg_match(«/[а-яА-Я]/»,$b))
{
echo «Подстрока найдена»;
}
else
{
echo «Подстрока не найдена»;
}
?>
<?php
$b=»В этой строке присутствует слово есть»; if(preg_match(«/[а-яА-Я]/»,$b)) { echo «Подстрока найдена»; } else { echo «Подстрока не найдена»; }
?> |
В Денвере этот пример будет работать нормально, но на других «нелокальных» серваках – не факт. Поэтому на специализированных форумах часто можно встретить вопросы разработчиков, столкнувшихся с этой проблемой. Тут может быть несколько вариантов ее решения:
Прописка локали с помощью функции setlocale(), в параметрах которой также указывается кодировка русских букв в PHP:
Указания модификатора для шаблона u. Но это работает не всегда, поскольку его использование несовместимо с синтаксисом Perl. В результате скрипт отработает неправильно, так как обе строки «воспринимаются» функцией preg_match() в формате UTF-8. Поэтому еще и warning вдогонку .
Но это работает не всегда, поскольку его использование несовместимо с синтаксисом Perl. В результате скрипт отработает неправильно, так как обе строки «воспринимаются» функцией preg_match() в формате UTF-8. Поэтому еще и warning вдогонку .
Если дальше капнуть, то многие советуют указывать вместо u модификатор U. Но это разные модификаторы. Например, последний призван бороться с «жадностью» регулярок. Больше об этом написано в документации языка. Это также стоит учитывать при поиске с помощью PHP русских букв в URL.
Думаю, сегодня мой знакомый порадуется. За продвижение русского языка он обещал мне три литра пива выставить. Но так как знает, что я его не пью, также пообещал выпить их за меня. Исконно русская черта характера .
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Хотите изучить регулярные выражения на PHP?
Посмотрите 12-ти часовой видео курс по регулярным выражениям на PHP!
Смотреть
Регулярные выражения — PHP с нуля
Регулярные выражения — это специальные шаблоны для поиска
подстроки в тексте. С их помощью можно решить одной строчкой
С их помощью можно решить одной строчкой
такие задачи: «проверить, содержит ли строка цифры»,
«найти в тексте все адреса email»,
«заменить несколько идущих подряд знаков вопроса на один».
Начнем с одной народной программистской мудрости:
Некоторые люди, сталкиваясь с проблемой, думают:
«Ага, я умный, я решу её с помощью регулярных выражений». Теперь у них две проблемы.
Это довольно-таки объемный и сложный урок. Но, если ты дошел до сюда, то ты способен
осилить и это. Просто почти теорию, не надо запоминать, а когда дойдешь до задачек, вернись
и проясни непонятные моменты. Ну или открой мануал — там эта тема подробно разъясняется. Ссылка:
http://www.php.net/manual/ru/reference.pcre.pattern.syntax.php
Примеры шаблонов
Начнем с пары простых примеров. Первое выражение на картинке ниже ищет
последовательность из 3 букв, где первая буква это «к», вторая — любая русская буква и
третья — это «т» без учета регистра (например, «кот» или «КОТ» подходит
под этот шаблон). Второе выражение ищет в тексте время в формате
Второе выражение ищет в тексте время в формате 12:34.
Любое выражение начинается с символа-ограничителя (delimiter по англ.). В качестве
него обычно используют символ /, но можно использовать и другие
символы, не имеющие специального назначения в регулярках, например, ~,
# или @. Альтернативные разделители используют, если в
выражении может встречаться символ /. Затем идет сам шаблон строки,
которую мы ищем, за
ним второй ограничитель и в конце может идти одна или несколько букв-флагов. Они
задают дополнительные опции при поиске текста. Вот примеры флагов:
i— говорит, что поиск должен вестись без учета
регистра букв (по умолчанию регистр учитывается)u— говорит, что выражение и текст, по которому идет поиск,
исплоьзуют кодировку utf-8, а не только латинские буквы. Без него поиск
Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
 Без него поиск
Без него поиск
Сам шаблон состоит из обычных символов и специальных конструкций. Ну
например, буква «к» в регулярках обозначает саму себя, а вот символы [0-5]
значат «в этом месте может быть любая цифра от 0 до 5». Вот полный список
специальных символов (в мануале php их называют метасимволы),
а все остальные символы в регулярке — обычные:
Ниже мы разберем значение каждого из этих символов (а также объясним почему буква
«ё» вынесена отдельно в первом выражении), а пока попробуем
применить наши регулярки к тексту и посмотреть, что выйдет. В php есть
специальная функция preg_match($regexp, $text, $match),
которая принимает на вход регулярку, текст и пустой массив. Она проверяет,
есть ли в тексте подстрока, соответствующая данному шаблону и возвращает
0, если нет,
или 1, если она есть. А в переданный массив в элемент с индексом
А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
| Код | Результат |
|---|---|
| Строка: рыжий кот + Найдено слово 'кот' Строка: рыжий крот - Ничего не найдено Строка: кит и кот + Найдено слово 'кит' |
Познакомившись с примером, изучим регулярные выражения более подробно. a-c] значит «один любой символ,
a-c] значит «один любой символ,
кроме a, b или c».
выражении
abc+ знак «плюс» относится только
к букве c и это выражение ищет слова вроде abc, abcc, abccc. А если
поставить скобки
a(bc)+ то квантифиактор плюс относится
уже к последовательности
bc и выражение ищет слова
abc, abcbc, abcbcbc
Примечание: в квадратных скобках можно указывать диапазоны
символов, но помни, что русская буква ё идет отдельно от
алфавита и чтобы написать «любая русская буква»,
надо писать [а-яё].
Бекслеши
Если ты смотрел другие учебники по регулярным выражениям, то наверно заметил,
что бекслеш везде пишут по-разному. Где-то пишут один бекслеш:
\d, а здесь в примерах он повторен 2 раза: \\d.
Почему?
Язык регулярных выражений требует писать бекслеш один раз. Однако в
строках в одиночных и двойных кавычках в PHP бекслеш тоже имеет особое
значение: мануал про строки.
Ну например, если написать $x = "\$"; то PHP воспримет это как
специальную комбинацию и вставит в строку только символ $
(и движок регулярных выражений не узнает о бекслеше перед ним). Чтобы
вставить в строку последовательность \$, мы должны удвоить бекслеш
и записать код в виде $x = "\\$";.
По этой причине в некоторых случаях (там, где последовательность символов
имеет специальный смысл в PHP) мы обязаны удваивать бекслеш:
- Чтобы написать в регулярке
\$, мы пишем в коде"\\$" - Чтобы написать в регулярке
\\, мы удваиваем каждый
бекслеш и пишем"\\\\" - Чтобы написать в регулярке бекслеш и цифру (
\1),
бекслеш надо удвоить:"\\1"
В остальных случаях один или два бекслеша дадут один и тот же
результат: "\\d" и "\d" вставят в строку пару
символов \d — в первом случае 2 бекслеша это последовательность
для вставки бекслеша, во втором случае специальной последовательности
нет и символы вставятся как есть. Проверить, какие символы вставятся в строку,
Проверить, какие символы вставятся в строку,
и что увидит движок регулярных выражений, можно с помощью
echo: echo "\$";. Да, сложно, а что поделать?
Специальные конструкции в регулярках
\dищет одну любую цифру,\D— один
любой символ, кроме цифры\wсоответствует одной любой букве (любого алфавита), цифре
или знаку подчеркивания_.\Wсоответствует
любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: \b.
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (\w), а с
другой стороны — не являющийся. Ну, например, мы хотим найти в тексте слово
«кот». Если мы напишем регулярку /кот/ui, то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: /\bкот\b/ui, то теперь
искаться будет только отдельно стоящее слово «кот».
Мануал
Также, есть полезный сайт
Regex101, где
можно протестировать свою регулярку и проверить, что она найдет в тексте. Помни,
что на том сайте бекслеши надо писать ровно один раз, и
ставить флаг u не требуется.
Задачка
Напиши программу, получающую на вход автомобильный номер, и проверяющую,
правильно ли он введен. Автомобильный номер имеет вид «а123вг»,
то есть начинается с буквы, за которой идет 3 цифры, и еще 2 буквы. Никаких
посторонних символов быть в нем не должно.
Эту программу надо решить с помощью preg_match() и регулярного
выражения. Протестировать его ты можешь например на сайте Regex101.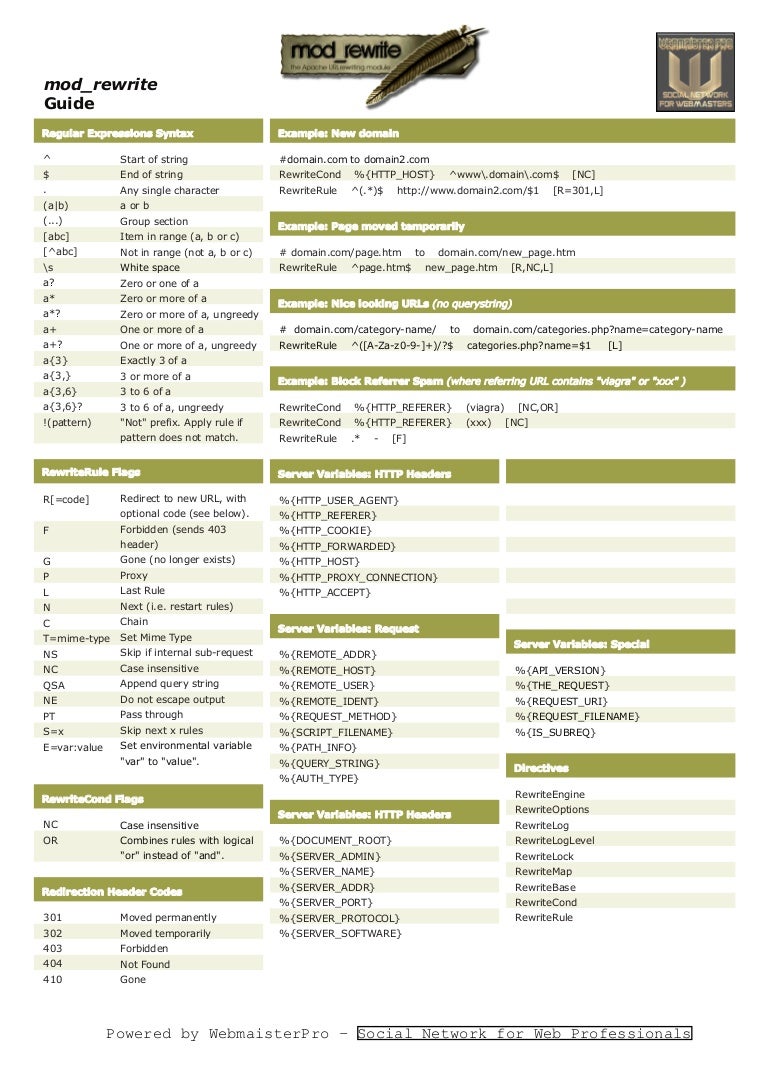
Задачка на проверку телефонов
Дан текст, который по идее должен быть номером телефона в виде 8-(911)-506 56 56
(т.е. человек может ввести не только цифры, но и скобки, минусы, может что-то еще).
Но в реальности, пользователь может вместо номера написать что угодно. Напиши скрипт для
проверки правильности введенного номера («8(911)-506 56 56» — правильный
номер, «8-911-50-656-56» — правильный, «89115065656» — правильный, «02» — неправильный,
«89115065656 позвать Люду» — неправильный).
Задачу надо проверить на большом числе телефонов,
чтобы убедиться что твой код правильный. Для этого давай добавим в программу
тесты, чтобы сразу было видно, верно все работает или нет.
Сделай 2 списка номеров (правильные и нет), добавь их в программу и напиши цикл,
который их по очереди прогоняет через регулярку и проверяет,
что они определяются как надо (если нет — надо вывести, какой именно номер
не распознается правильно).
Вот список номеров:
// Правильные: $correctNumbers = [ '84951234567', '+74951234567', '8-495-1-234-567', ' 8 (8122) 56-56-56', '8-911-1234567', '8 (911) 12 345 67', '8-911 12 345 67', '8 (911) - 123 - 45 - 67', '+ 7 999 123 4567', '8 ( 999 ) 1234567', '8 999 123 4567' ]; // Неправильные: $incorrectNumbers = [ '02', '84951234567 позвать люсю', '849512345', '849512345678', '8 (409) 123-123-123', '7900123467', '5005005001', '8888-8888-88', '84951a234567', '8495123456a', '+1 234 5678901', /* неверный код страны */ '+8 234 5678901', /* либо 8 либо +7 */ '7 234 5678901' /* нет + */ ];
Также, на regex101
https://regex101.com/r/qF7vT8/3 уже введены номера и можно простестировать
свою регулярку. Помни что на этом сайте надо писать бекслеш один раз,
например \s, а не \\s. Флаг m там стоит чтобы
^ и $ в регулярке обозначали «начало и конец
любой строки», а не «начало и конец всего текста». Флаг g (его нет в PHP,
Флаг g (его нет в PHP,
он только на этом сайте) значит что надо искать все совпадения с
регуляркой, а не только первое.
Подсказка: не надо строить сложных выражений и предусматривать все
возможные комбинации символов. Достаточно написать:
сначала идет +7 или 8, за ними ровно 10 цифр, между которыми может быть
любое число скобок, минусов, пробелов
Повторим
- preg_match находит первое совпадение с
регулярными выражением и проверяет, соответствует ли текст или часть выражению - preg_match_all находит все фрагменты текста,
соответствующие регулярке - preg_split разбивает текст на массив частей
по регулярному выражению - preg_replace заменяет в тексте части, соответствующие
регулярке, на данную строку
Задачки (пока без картинок)
- На вход скрипта дан введенный пользователем номер телефона в
виде 8-911-404-44-11 или +7(812)6786767 (в начале 8 или +7, потом идут 10 цифр и, возможно, какие-то символы).
То есть, как и в прошлой задаче, человек вводит номер как хочет.
Надо проверить номер на правильность и привести любой номер к единому формату 89114044411
(то есть, заменить +7 на 8 и выкинуть весь мусор вроде пробелов, скобок и минусов, кроме цифр) - Автозамена. Напиши скрипт, заменяющий определенное слово на другое (например, слово
«дурак» на «хороший человек» в фразе «ты дурак»). Скрипт должен не пропускать слово,
если оно написано буквами в разном регистре (ДуРАк), с заменой русских букв
на похожие английские (а -> a), или через пробелы («ты — д у р а к») - Дан текст, содержащий в себе email’ы (адреса почты вроде [email protected] ). Напиши
скрипт, выводящий все email, встречающиеся в этом тексте - «Grammar Nazi». Напиши скрипт, проверяющий текст на наличие злостных ошибок:
- нет пробела после запятой, точки с запятой, восклицательного знака,
вопросительного знака, двоеточия - «жи» или «ши» написано с буквой ы
- в тексте есть слово «координально» или «сдесь», «зделал», «зделаю», «зделан»
- в тексте есть слова «а» или «но» без запятой перед ними.
- (можешь добавить еще несколько правил, если хорошо знаешь русский язык)
В случае обнаружения ошибки скрипт должен писать сообщение об этом и выводить
кусок текста с ошибкой (чтобы было понятно, что не так). - нет пробела после запятой, точки с запятой, восклицательного знака,
- Если ты сделал задачу про Grammar Nazi, сделай скрипт, которы вместо сообщения об ошибках будет
молча их исправлять.


Опечаточники
Как тебе наверно известно, многие люди, занимающие государственные посты, тратят свои силы
отнюдь не на улучшение ситуации в своем городе или регионе, а на придумывание разнообразных
схем по перемещению вверенных им бюджетных средств в свои карманы.
Например, государственные органы, которые хотят провести закупки, обязаны организовать публичные торги и
разместить объявление о них на сайте госзакупок. Чтобы помешать всем желающим участвовать в тендере
(и чтобы отдать заказ «своим людям» и получить потом от них в свой карман часть денег), они заменяют в
описании заказа некоторые русские буквы на похожие на них латинские. Таким образом, не предупрежденные
Таким образом, не предупрежденные
заранее организации не смогут найти объявление через поиск и принять участие в конкурсе.
Давай попробуем применить наши знания языка PHP для того, чтобы вывести жуликов на чистую воду.
Задача: дан текст, содержащий слова на русском и английском языках. В некоторых словах часть русских букв
заменена на похожие на них латинские, и наоборот. Напиши программу, которая находит все такие слова,
выводит их и выделяет квадратными скобками первую замененную букву.
Для проверки работоспособности, попробуй применить программу к тексту из поля «Наименование заказа» на
странице (осторожно, спойлер!)
http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5193640
или http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5138013
ололо кто бы поверил!
Дополнительная задача: добавь в программу автоматическое исправление найденных «опечаток».
Подсказки для глупеньких: слова с опечатками найти легко: это слово, которое
начинается с одной или нескольких русских букв, за которыми идет латинская. Ну или начинается с латинской,
за которой идет русская. Достаточно минимальных знаний регулярных выражений, чтобы написать решение.
P.S. На сайте программистских комиксов xkcd есть комикс про регулярные выражения:
перевод, оригинал (англ.).
дальше:
Повторим? →
——
Куда вводить код? Что надо скачать? Читай первый урок.
Есть вопросы? Задай гуглу или автору.
Нравится урок? Лайкай, репости, приглашай друзей, пости котов и Канако,
шли добра, решай задачи, помогай новичкам! Кнопок для лайка нет, кто хочет зарепостить, всегда может сделать это ручками.
Как связаться с автором? Я хочу переодеть его в платье
школьницы и жениться на нем. Ящик codedokode (кот) gmail.com ждет ваших писем. А
Ящик codedokode (кот) gmail.com ждет ваших писем. А
вконтактик и
фейсбучек ждут ваших лайков.
Но ответ на банальные вопросы лучше искать в Гугле или на stackoverflow.
Я решил задачку!!! Молодец, делай следующий урок
Ideone не работает!11 Ну так открой Гугл и найди сайты
вроде https://repl.it/languages/php , http://phptester.net/ ,
http://sandbox.onlinephpfunctions.com/ ,
http://codepad.org/ или http://www.runphponline.com/ . Не ленись.
Почему так много рекламы? Всю рекламу
на сайте ставит юкоз (бесплатный хостинг же), а не я.
На сайте установлена система Google Analytics (и еще несколько аналогичных систем от юкоза). Данные о твоем IP-адресе, посещаемых страницах,
времени посещения отправляются в Google Corporation, США. Хочу знать, кто и зачем сюда заходит. ) для создания сложных выражений.
) для создания сложных выражений.
Для чего используются регулярные выражения:
- Регулярные выражения упрощают идентификацию строковых данных путем вызова одной функции. Это экономит время при составлении кода;
- При проверке введенных пользователем данных, таких как адрес электронной почты, домен сайта, номер телефона, IP-адрес ;
- Выделение ключевых слов в результатах поиска;
- Регулярные выражения могут использоваться для идентификации тегов и их замены.
Регулярные выражения в PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP .
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true , если совпадение найдено, и false , если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.

Ниже приведен синтаксис функций регулярных выражений, таких как preg_match , preg_split или PHP regexp replace :
«имя_функции» — это либо preg_match , либо preg_split , либо preg_replace .
«/…/» — косые черты обозначают начало и конец регулярного выражения.
«‘/шаблон/’» — шаблон, который нам нужно сопоставить.
«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg_match
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе .
В приведенном ниже коде показан вариант реализации данного примера:
Рассмотрим ту часть кода, которая отвечает за вывод «preg_match (‘/ guru /’, $ my_url)» .
«preg_match(…)» — функция PHP match regexp .
«‘/Guru/’» — шаблон регулярного выражения.
«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон. PH/ — любая строка, которая начинается с PH.
PH/ — любая строка, которая начинается с PH.
Теперь рассмотрим сложный PHP regexp пример, в котором проверяется валидность адреса электронной почты:
Результат: адрес электронной почты name@company. [a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.
[a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.
«+@[a-zA-Z0-9-]» соответствует символу @ , за которым следуют буквы в нижнем или верхнем регистре, цифры от 0 до 9 или дефисы.
«+.[a-zA-Z.]<2,5>$/» указывает точку, используя обратную косую черту, затем должны следовать любые буквы в нижнем или верхнем регистре, количество символов в конце строки должно быть от 2 до 5.
Метасимволы являются полезными, когда речь идет о сопоставлении на соответствие шаблонам.
Заключение
- PHP regexp — это алгоритм поиска по шаблону;
- Регулярные выражения полезны при выполнении проверок валидности, создании HTML-шаблонов , которые распознают теги и т. д.;
- PHP имеет встроенные функции для работы с регулярными выражениями: preg_match , preg_split и preg_replace ;
- Метасимволы позволяют создавать сложные шаблоны.
Данная публикация представляет собой перевод статьи « PHP Regular Expressions » , подготовленной дружной командой проекта Интернет-технологии. ру
ру
Регулярные выражения позволяют найти в строке последовательности, соответствующие шаблону. Например шаблон «Вася(.*)Пупкин» позволит найти последовательность когда между словами Вася и Пупкин будет любое количество любых символов. Если надо найти шесть цифр, то пишем «[0-9]<6>» (если, например, от шести до восьми цифр, тогда «[0-9]<6,8>»). Здесь разделены такие вещи как указатель набора символов и указатель необходимого количества:
Вместо набора символов может быть использовано обозначение любого символа — точка, может быть указан конкретный набор символов (поддерживаются последовательности — упоминавшиеся «0-9»). Может быть указано «кроме данного набора символов».
Указатель количества символов в официальной документации по php называется «квантификатор». Термин удобный и не несет в себе кривотолков. Итак, квантификатор может иметь как конкретное значение — либо одно фиксированное («<6>»), либо как числовой промежуток («<6,8>»), так и абстрактное «любое число, в т. ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).
ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).
Для более гибкого поиска сочетаний эти связки «набор символов — квантификатор» можно объединять в метаструктуры.
Как всякий гибкий инструмент, регулярные выражения гибки, но не абсолютно: зона их применения ограничена. Например, если вам надо заменить в тексте одну фиксированную строку на другую, фиксированную опять же, пользуйтесь str_replace. Разработчики php слезно умоляют не пользоваться ради этого сложными функциями ereg_replace или preg_replace, ведь при их вызове происходит процесс интерпретации строки, а это серьезно потребляет ресурсы системы. К сожалению, это любимые грабли начинающих php-программистов.
Пользуйтесь функциями регулярных выражений только если вы не знаете точно, какая «там» строка. Из примеров: поисковый код , в котором из строки поиска вырезаются служебные символы и короткие слова а так же вырезаются лишние пробелы (вернее, все пробелы сжимаются: » +» заменяется на один пробел).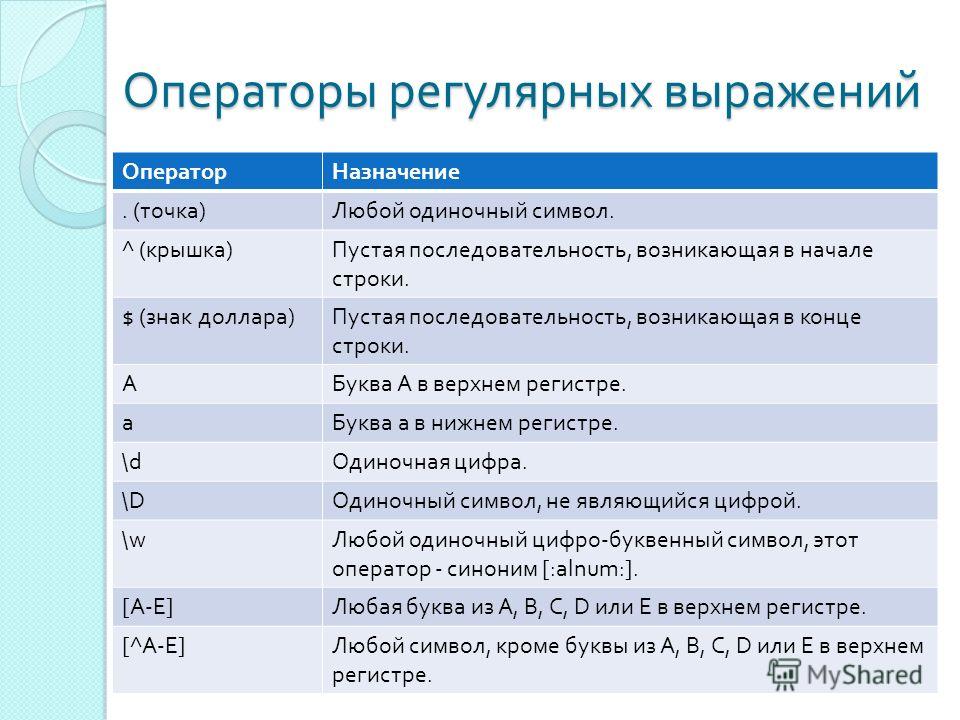 При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.
При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.
Набор символов
| . | точка | любой символ | |
| [ ] | квадратные скобки | класс символов («любое из»). ] ] | Кроме пробельных символов |
| | | (одно|другое) | На этом месте может быть один из перечисленных вариантов, например: (Вася|Петя|Маша). Если Вы не хотите, чтобы это попало в выборку используйте (?: . ) |
Не пользуйтесь классом символов для обозначения всего лишь одного (вместо «[ ]+» вполне сойдет » +»). Не пишите в классе символов точку это ведь любой символ, тогда другие символы в классе будут просто лишними (а в негативном классе получится отрицание всех символов).
Квантификатор
Квантификатором можно указать как конкретное значение, так и пределы. Если число заданных подпадает под пределы квантификатора, фрагмент выражения считается совпавшим с разбираемой строкой. Синтаксис:
Если нужно указать только необходимый минимум, а максимума нет, просто ставим запятую и не пишем второе число: «<5,>» («минимум 5»). Для наиболее часто употребляемых квантификаторов есть специальные обозначения:
| * | «звёздочка» или знак умножения |
| + | плюс |
| ? | вопросительный знак |
На практике такие символы используются чаще, чем фигурные скобки.» и «$» совпадают с началом и концом отдельных строк.
Функции для работы с регулярными выражениями
- preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
- preg_match — Выполняет проверку на соответствие регулярному выражению. Данная функция ищет только первое совпадение!
- preg_match_all — Выполняет глобальный поиск шаблона в строке
- preg_quote — Экранирует символы в регулярных выражениях. Т.е. вставляет слэши перед всеми служебными символами (например, скобками, квадратными скобками и т.п.), чтобы те воспринимались буквально. Если у вас есть какой-либо ввод информации пользователем, и вы проверяете его с помощью регулярных выражений, то лучше перед этим заэкранировать служебные символы в пришедшей переменной
- preg_replace — Выполняет поиск и замену по регулярному выражению
- preg_replace_callback — Выполняет поиск по регулярному выражению и замену
- preg_split — Разбивает строку по регулярному выражению
preg_grep
Функция preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
array preg_grep (string pattern, array input [, int flags])
preg_grep() возвращает массив, состоящий из элементов входящего массива input, которые соответствуют заданному шаблону pattern.
Параметр flags может принимать следующие значения:
PREG_GREP_INVERT
В случае, если этот флаг установлен, функция preg_grep(), возвращает те элементы массива, которые не соответствуют заданному шаблону pattern.
Результат, возвращаемый функцией preg_grep() использует те же индексы, что и массив исходных данных. Если такое поведение вам не подходит, примените array_values() к массиву, возвращаемому preg_grep() для реиндексации.
Пример кода:
preg_match
Функция preg_match — Выполняет проверку на соответствие регулярному выражению
int preg_match ( string pattern, string subject [, array matches [, int flags [, int offset]]]) Ищет в заданном тексте subject совпадения с шаблоном pattern
В случае, если дополнительный параметр matches указан, он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске, и так далее.
flags может принимать следующие значения:
PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Функция preg_match() возвращает количество найденных соответствий. Это может быть 0 (совпадения не найдены) и 1, поскольку preg_match() прекращает свою работу после первого найденного совпадения. Если необходимо найти либо сосчитать все совпадения, следует воспользоваться функцией preg_match_all(). Функция preg_match() возвращает FALSE в случае, если во время выполнения возникли какие-либо ошибки.
Рекомендация: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Используйте для этого strpos() либо strstr(), поскольку они выполнят эту задачу гораздо быстрее.
Пример кода
Пример кода
Пример кода
preg_match_all
Функция preg_match_all — Выполняет глобальный поиск шаблона в строке
int preg_match_all (string pattern, string subject, array matches [, int flags [, int offset]])
Ищет в строке subject все совпадения с шаблоном pattern и помещает результат в массив matches в порядке, определяемом комбинацией флагов flags.
После нахождения первого соответствия последующие поиски будут осуществляться не с начала строки, а от конца последнего найденного вхождения.
Дополнительный параметр flags может комбинировать следующие значения (необходимо понимать, что использование PREG_PATTERN_ORDER одновременно с PREG_SET_ORDER бессмысленно):
PREG_PATTERN_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит массив полных вхождений шаблона, элемент $matches[1] содержит массив вхождений первой подмаски, и так далее.
Пример кода
Как мы видим, $out[0] содержит массив полных вхождений шаблона, а элемент $out[1] содержит массив подстрок, содержащихся в тегах.
PREG_SET_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее.
Пример кода
В таком случае массив $matches[0] содержит первый набор вхождений, а именно: элемент $matches[0][0] содержит первое вхождение всего шаблона, элемент $matches[0][1] содержит первое вхождение первой подмаски, и так далее. Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора.
PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
В случае, если никакой флаг не используется, по умолчанию используется PREG_PATTERN_ORDER.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Возвращает количество найденных вхождений шаблона (может быть нулем) либо FALSE, если во время выполнения возникли какие-либо ошибки.
Пример кода
Пример кода
preg_quote
Функция preg_quote — Экранирует символы в регулярных выражениях
string preg_quote (string str [, string delimiter])
Функция preg_quote() принимает строку str и добавляет обратный слеш перед каждым служебным символом. ] $ ( ) < >= ! | :
Пример кода
Пример кода
preg_replace
Функция preg_replace — Выполняет поиск и замену по регулярному выражению
mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit])
Выполняет поиск в строке subject совпадений с шаблоном pattern и заменяет их на replacement. В случае, если параметр limit указан, будет произведена замена limit вхождений шаблона; в случае, если limit опущен либо равняется -1, будут заменены все вхождения шаблона.
Replacement может содержать ссылки вида \n либо (начиная с PHP 4.0.4) $n, причем последний вариант предпочтительней. Каждая такая ссылка, будет заменена на подстроку, соответствующую n’нной заключенной в круглые скобки подмаске. n может принимать значения от 0 до 99, причем ссылка \0 (либо $0) соответствует вхождению всего шаблона. Подмаски нумеруются слева направо, начиная с единицы.
При использовании замены по шаблону с использованием ссылок на подмаски может возникнуть ситуация, когда непосредственно за маской следует цифра. В таком случае нотация вида \n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией $<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1.
Результатом работы этого примера будет:
Если во время выполнения функции были обнаружены совпадения с шаблоном, будет возвращено измененное значение subject, в противном случае будет возвращен исходный текст subject.
Первые три параметра функции preg_replace() могут быть одномерными массивами. В случае, если массив использует ключи, при обработке массива они будут взяты в том порядке, в котором они расположены в массиве. Указание ключей в массиве для pattern и replacement не является обязательным. Если вы все же решили использовать индексы, для сопоставления шаблонов и строк, участвующих в замене, используйте функцию ksort() для каждого из массивов.
В случае, если параметр subject является массивом, поиск и замена по шаблону производятся для каждого из его элементов. Возвращаемый результат также будет массивом.
В случае, если параметры pattern и replacement являются массивами, preg_replace() поочередно извлекает из обоих массивов по паре элементов и использует их для операции поиска и замены. Если массив replacement содержит больше элементов, чем pattern, вместо недостающих элементов для замены будут взяты пустые строки. В случае, если pattern является массивом, а replacement — строкой, по каждому элементу массива pattern будет осущесвтлен поиск и замена на pattern (шаблоном будут поочередно все элементы массива, в то время как строка замены остается фиксированной). Вариант, когда pattern является строкой, а replacement — массивом, не имеет смысла.
Модификатор /e меняет поведение функции preg_replace() таким образом, что параметр replacement после выполнения необходимых подстановок интерпретируется как PHP-код и только после этого используется для замены. Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса.
Пример кода: Замена по нескольким шаблонам
Этот пример выведет:
Пример кода: Использование модификатора /e
Пример кода: Преобразует все HTML-теги к верхнему регистру
preg_replace_callback
Функция preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием функции обратного вызова
mixed preg_replace_callback (mixed pattern, callback callback, mixed subject [, int limit])
Поведение этой функции во многом напоминает preg_replace(), за исключением того, что вместо параметра replacement необходимо указывать callback функцию, которой в качестве входящего параметра передается массив найденных вхождений. Ожидаемый результат — строка, которой будет произведена замена.
Пример кода
preg_split
Функция preg_split — Разбивает строку по регулярному выражению
array preg_split (string pattern, string subject [, int limit [, int flags]])
Возвращает массив, состоящий из подстрок заданной строки subject, которая разбита по границам, соответствующим шаблону pattern.
В случае, если параметр limit указан, функция возвращает не более, чем limit подстрок. Специальное значение limit, равное -1, подразумевает отсутствие ограничения, это весьма полезно для указания еще одного опционального параметра flags.
flags может быть произвольной комбинацией следующих флагов (соединение происходит при помощи оператора ‘|’):
PREG_SPLIT_NO_EMPTY
В случае, если этот флаг указан, функция preg_split() вернет только непустые подстроки.
PREG_SPLIT_DELIM_CAPTURE
В случае, если этот флаг указан, выражение, заключенное в круглые скобки в разделяющем шаблоне, также извлекается из заданной строки и возвращается функцией. Этот флаг был добавлен в PHP 4.0.5.
PREG_SPLIT_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки, будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
Примеры кода
В случае, если после открывающей круглой скобки следует «?:«, захват строки не происходит, и текущая подмаска не нумеруется. Например, если строка «the white queen» сопоставляется с шаблоном the ((?:red|white) (king|queen)), будут захвачены подстроки «white queen» и «queen», и они будут пронумерованы 1 и 2 соответственно:
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.
Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
- preg_match (http://php.net/manual/en/function.preg-match.php)
- preg_match_all (http://php.net/manual/en/function.preg-match-all.php)
- preg_replace (http://php.net/manual/en/function.preg-replace.php)
Для работы с ними нужен текст, в котором мы будем искать или заменять подстроки, а также само регулярное выражение, описывающее правило поиска.
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.
В JS чаще всего мне приходится использовать:
Пример использования функций
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “
”.0-9]$#
Если необходимо использовать разделитель внутри шаблона, его нужно проэкранировать с помощью обратной косой черты. Если разделитель часто используется в шаблоне, в целях удобочитаемости, лучше выбрать другой разделитель для этого шаблона.
В JavaScript регулярные выражения реализованы отдельным объектом RegExp и интегрированы в методы строк.
Создать регулярное выражение можно так:
Или более короткий вариант:
Пример самого простого регулярного выражения для поиска:
В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
Пробуем то же самое для второй функции:
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска.’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.
Об остальных модификаторах, используемых в PHP, можно почитать тут.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
Метасимволы в регулярных выражениях
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
Первый пример, нам надо получить все числа из текста:
Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “[0-9]”. Для всех цифр существует метасимвол “d”. Он работает идентично.
Но если мы укажем регулярное выражение “/d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “”.
Сейчас будет пара примеров, чтобы это уложилось в голове:
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
- [a-z]
- [a-zA-Z]
- [а-яА-Я]
C кириллицей указанный диапазон работает по-разному для разных кодировок.s.]+”
Оказалось не так сложно. Теперь у нас есть email, собранный по частям. Рассмотрим на примере результата работы preg_match в PHP:
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
Тогда массив матча станет ассоциативным:
Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:
Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.
Вариантов можно перечислять сколько угодно:
Далее у нас знак двоеточия и один пробел:
Далее знак тега b:
А дальше нас интересует все, что не символ “ Теги:
- regexp
- javascript
- junior developer
- php
Добавить метки
Рекомендуем к прочтению
30 примеров полезных регулярных выражений
Процесс разработки веб-приложений значительно отличается от разработки программного обеспечения, однако основные моменты при программировании одинаковы в обоих случаях, поэтому выгода от использования регулярных выражений будет видна всем.
Изучение регулярных выражений (regex) довольно сложный процесс, особенно для начинающих, но при правильном подходе, вы освоите чрезвычайно мощный и полезный инструмент.
Самым сложным этапом при обучении с нуля является понимание синтаксиса регулярных выражений.(?=.*[A-Z].*[A-Z])(?=.*[!@#$&*])(?=.*[0-9].*[0-9])(?=.*[a-z].*[a-z].*[a-z]).{8}$
Надежность пароля — довольно субъективное понятие, поэтому не существует универсального решения для проверки. Однако, приведенный выше пример регулярного выражения может стать хорошей отправной точкой, если вы не желаете придумывать выражение для проверки пароля с нуля.
Код цвета в шестнадцатеричном формате
Шестнадцатеричные коды цветов используются при веб-разработке очень часто. Это регулярное выражение может быть поможет сравнить: совпадает ли какая-либо строка с шаблоном шестнадцатеричного кода.
Проверка адреса электронной почты
/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igmОдной из самых распространенных задач при разработке является проверка соответствия введенной пользователем строки формату адреса электронной почты. Существует множество различных вариантов выражений для решения этой задачи, автор этой статьи предлагает свой оригинальный вариант.
IP-адрес (v4)
/\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b/Как e-mail может использоваться для идентификации посетителя, так IP-адрес является идентификатором конкретного компьютера в сети. Приведенное регулярное выражение проверяет соответствие строки формату IP-адреса v4.
IP-адрес (v6)
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.\s]*$ //соответствует фразе из 5 и более ключевых словЭто действительно полезные выражения для пользователей Google Analytics и инструмента для веб-мастеров. Ведь с помощью них можно отсортировать ключевые фразы, используемые посетителями при поиске по количеству слов, входящих в них.
Выражения могут проверять фразы, содержащие определенное количество слов (например, 5), а также фразы количество слов в которых более двух, трех и т.д. Одно из самых мощных выражений, используемое для сортировки данных аналитики.
Поиск валидной строки Base64 в PHP
\?php[ \t]eval\(base64_decode\(\'(([A-Za-z0-9+/]{4})*([A-Za-z0-9+/]{3}=|[A-Za-z0-9+/]{2}==)?){1}\'\)\)\;Если вы являетесь PHP-разработчиком, то иногда вам может понадобиться найти объект, закодированный в формате Base64. Указанное выше выражение может использоваться для поиска закодированных строк в любом PHP-коде.
Проверка телефонного номера
^\+?\d{1,3}?[- .(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9])|(?:1[0-2]))\4(?:(?:1[6-9]|[2-9]\d)?\d{2})$Проверять даты сложно, потому что они могут быть представлены в различных форматах, в том числе содержащих и числа, и текст.
В PHP имеется отличная функция date(), но она не всегда подходит, ведь в нее может быть передана необработанная строка. Поэтому для проверки указанного формата даты нужно использовать приведенное выше регулярное выражение.
Совпадение строки с адресом видеоролика на YouTube
/http:\/\/(?:youtu\.be\/|(?:[a-z]{2,3}\.)?youtube\.com\/watch(?:\?|#\!)v=)([\w-]{11}).*/giНа протяжении нескольких лет на Youtube не меняется структура URL-адресов. Youtube является самым популярным видео хостингом в Интернет, благодаря этому, видео с Youtube набирают наибольший трафик.
Если вам необходимо получить ID какого-либо видеоролика с Youtube, воспользуйтесь приведенным выше регулярным выражением. Это наилучшее выражение, подходящее для всех вариантов URL-адресов на этом видео-хостинге.
Проверка ISBN
/\b(?:ISBN(?:: ?| ))?((?:97[89])?\d{9}[\dx])\b/iИнформация обо всех печатные изданиях, хранится в системе, известной как ISBN, которая состоит из 2 систем: ISBN-10 и ISBN-13. Неспециалисту очень сложно увидеть различия между этими системами. Однако, представленное выше регулярное выражение позволяет проверять соответствие кода ISBN сразу обоим системам: будь то ISBN-10 или ISBN-13. Код написан на PHP, поэтому это решение подходит исключительно для веб-разработчиков.
Проверка почтового индекса (Zip Code)
Автор этого регулярного выражения не только придумал его, но и еще нашел время его описать. Это выражение будет полезно вам, если вы проверяете совпадение строки со стандартным пятизначным индексом или его удлиненным вариантом, содержащим 9 знаков. Обращаем ваше внимание, что это выражение подходит только для проверки американских почтовых индексов. Для индексов других стран необходима настройка.
Комментарий mattweb.\s*[a-zA-Z\-]+\s*[:]{1}\s[a-zA-Z0-9\s.#]+[;]{1}Ситуация, когда придется воспользоваться указанным регулярным выражением, может сложиться очень редко, но не факт что не сложится никогда
Этот код можно использовать когда будет необходимо «вытянуть» какое-либо CSS-правило из списка правил для какого-нибудь селектора.
Удаление комментариев в HTML
Если вам необходимо удалить все комментарии из блока HTML-кода, воспользуйтесь этим регулярным выражением. Чтобы получить желаемый результат, вы можете воспользоваться PHP-функцией preg_replace().
Проверка на соответствие ссылке на Facebook-аккаунт
/(?:http:\/\/)?(?:www\.)?facebook\.com\/(?:(?:\w)*#!\/)?(?:pages\/)?(?:[\w\-]*\/)*([\w\-]*)/Если вам необходимо узнать у посетителя вашего сайта адрес его странички в Facebook, попробуйте это регулярное выражение. Оно поможет вам проверить правильность указанного пользователем URL. Этот код отлично подходит для проверки ссылок в этой соцсети..*MSIE [5-8](?:\.[0-9]+)?(?!.*Trident\/[5-9]\.0).*$
Несмотря на то, что Microsoft выпустил новый браузер Edge, многие пользователи до сих пор пользуются Internet Explorer. Веб-разработчикам часто приходится проверять версию этого браузера, чтобы учитывать особенности разных версий при работе над своими проектами.
Вы можете использовать это регулярное выражения в JavaScript-коде чтобы узнать какая версия IE (5-11) используется.
«Вытягиваем» цену из строки
/(\$[0-9,]+(\.[0-9]{2})?)/Цена какого-либо товара может быть указана в различных форматах: в ней могут встречаться запятые, знаки после запятой и символы валюты.
Указанное выше регулярное выражение учитывает различные форматы отображения цены, с его помощью вы сможете «вытянуть» цену из любой символьной строки.
Разбираем заголовки в e-mail
/\b[A-Z0-9._%+-]+@(?:[A-Z0-9-]+\.)+[A-Z]{2,6}\b/iС помощью этого небольшого выражения вы сможете разобрать заголовок e-mail сообщения, чтобы извлечь оттуда список адресатов. ]*))/g
Вы можете составить свои собственные регулярные выражения для манипулирования результатами поиска по вашим запросам в поисковой системе Google. Например, знак плюс (+) добавляет дополнительные ключевые слова, а минус (-) означает, что слова должны быть проигнорированы и удалены из результатов.
Это довольно сложное выражение, но если разобраться как использовать его должным образом, приведенный код может стать основой для построения собственного алгоритма поиска.
Заключение
Путь к пониманию регулярных выражений довольно труден, однако, если вы будете его придерживаться, результат вас не разочарует. Попробуйте использовать приведенные в статье регулярные выражения при создании своего веб-приложения. Таким образом вы сможете понять как работают выражения из примеров, приведенных в статье, в реальности.
Если у вас есть свои примеры полезных регулярных выражений, вы можете добавить их в качестве комментария к этой статье.
Почитать оригинал статьи
Writer.Поиск и замена: Часто задаваемые вопросы
Все вопросы по поиску и замене символов через диалог Правка — Найти и заменить, а также вопросы автоматической замены и автодополнения слов.
Contents
- 1 Как удалить мягкие переносы?
- 2 Как заменить начертание шрифта в выделенном фрагменте, чтобы все символы одного шрифта стали другого цвета?
- 3 Как пробелы в числах заменить на неразрывные пробелы?
- 4 Как найти символы абзаца, разрыва строки, табуляции?
- 5 Как заменить символы разрыва строки на символы абзаца?
- 6 Как составлять регулярные выражения?
- 7 Как преобразовать тексты, набранные в старых текстовых (DOS), где в конце каждой строки стоят Enter’ы
- 8 Как узнать количество символов в документе без пробелов?
- 9 Как найти/заменить двойной пустой абзац? Я уже знаю про регулярные выражения, но всё равно не получается
- 10 Пишу диалог, с новой строки после табуляции ставлю «—«(длинное тире), дописываю абзац, жму ентер — выскакивает меню маркированного списка. Как отключить?
- 11 Автозамена подставляет длинное тире вместо среднего.
- 12 Если в MS Word на выделенном слове зайти в контекстное меню, то там есть пункт «Синонимы». Есть ли что-нибудь подобное в ОО?
- 13 Как менять варианты, предлагаемые функцией автодополнения?
- 14 Существует ли альтернативный способ поиска и замены для Writer?
- 15 Как можно просмотреть список слов в тексте, которые не прошли проверку правописания?
Как удалить мягкие переносы?
Чтобы удалить все мягкие переносы, выделите какой-нибудь один мягкий перенос, нажмите Ctrl F, и нажмите «заменить всё» (поле для замены оставьте пустым).
3.1
Как заменить начертание шрифта в выделенном фрагменте, чтобы все символы одного шрифта стали другого цвета?
Диалог «Найти и заменить», использовать кнопку «Формат» и регулярное выражение.
2.4
Как пробелы в числах заменить на неразрывные пробелы?
В тексте разряды в числах разделяются пробелами. Для замены всех пробелов в числах на неразрывный пробел нужно воспользоваться заменой с регулярными выражениями.
- Для этого в диалоге «Найти и заменить» нужно нажать кнопку «Больше параметров» и установить флажок «регулярные выражения». Затем
- — в строке поиска ввести ([:digit:]) ([:digit:]{3})
- — в строке замены ввести $1 $2
Примечание: В данном диалоге нельзя непосредственно ввести символ «неразрывный пробел». Но его можно предварительно ввести в документ, вырезать в документе и вставить в нужном месте в строке поиска или замены. Таким образом в строке $1 $2 на самом деле не пробел, а именно «неразрывный пробел».
3.0
Как найти символы абзаца, разрыва строки, табуляции?
Для поиска таких символов необходимо использовать регулярные выражения. В диалоге поиска и замены регулярные выражения включаются через «Дополнительные настройки».
Используйте для поиска следующие регулярные выражения:
- символ разрыва строки — «\n«, однако при использовании в поле замены это выражение будет обозначать символ абзаца;
- символ абзаца — «$«;
- символ табуляции — «\t«.
Подробнее см.: система помощи, закладка «Индекс», искомое выражение — «регулярные выражения;список».
2.4
Как заменить символы разрыва строки на символы абзаца?
Последовательность действий при поиске и замене символов разрыва строк
Как сказано выше для поиска таких символов используются регулярные выражения (взведите флаг «Регулярное выражение» ).
Часто возникает задача заменить в тексте, например взятом из окна браузера, символы «\n» на символы абзаца для более корректного форматирования текста.
Попытка поставить в качестве замены символ «$» (конец абзаца) ни к чему хорошему, кроме вставки собственно символа «$«, не приводит !
Как оказалось диалог поиска находит эти символы «\n«, но и в качестве замены, в нашем случае, тоже надо указывать «\n» !!
3.2
Как составлять регулярные выражения?
Общие принципы написания регулярных выражений описаны в этой статье: http://ru.$ В строке Заменить вводим QWERTYTREWQ
Если же переносы строк в абзацах отформатированы «мягким переводом строки» (Shift-Enter), то второй шаг немного меняется. В этом случае регулярное выражение в строке Найти будет \n В строке Заменить так же просто нажимаем ПРОБЕЛ.
2.4
Как узнать количество символов в документе без пробелов?
Последовательность действий для подсчета непробельных символов
Для подсчёта слов и символов в документе используется команда Сервис — Количество слов (выводятся данные по выделенному фрагменту (фрагментам) и по всему документу).$ на «ABZ», а потом искать/обрабатывать «ABZABZ».
| Внимание! Весь документ окажется в одном параграфе, а у OpenOffice.org существует ограничение на величину параграфа, не применяйте такой метод к объемным документам. |
- можно воспользоваться макросом из книги «Useful Macro Information For OpenOffice By Andrew Pitonyak»
2.3
Пишу диалог, с новой строки после табуляции ставлю «—«(длинное тире), дописываю абзац, жму ентер — выскакивает меню маркированного списка. Как отключить?
Сервис — Автозамена — Параметры
или использовать CTRL+Z
2.3
Автозамена подставляет длинное тире вместо среднего.
Если в свойствах абзаца стоит русский или украинский языки, то минус заменится на длинное тире (em dash), по правилам типографики. В остальных языках используется среднее тире (en dash)
Отменить автозамену можно, используя CTRL+Z
2.3
Если в MS Word на выделенном слове зайти в контекстное меню, то там есть пункт «Синонимы». Есть ли что-нибудь подобное в ОО?
Выберите команду Сервис — Язык — Тезаурус
2.3
Как менять варианты, предлагаемые функцией автодополнения?
Если в списке слов для автодополнения есть более одного варианта, нажмите клавиши CTRL+TAB для прокрутки доступных слов. Для прокрутки в обратном направлении используйте клавиши CTRL+SHIFT+TAB.
Посмотреть список вариантов можно через Сервис — Автозамена — Дополнение слов.
| Пользователям Linux (KDE) необходимо учитывать, что данные сочетания клавиш зарезервированы KDE для переключения между рабочими столами |
2.3
Существует ли альтернативный способ поиска и замены для Writer?
Да.
Расширение от Tomas Bilek Alternative dialog Find & Replace for Writer
Доступна русская версия расширения
По сравнению с оригинальным диалогом поиска и замены добавлены:
- Быстрый выбор шаблонов регулярных выражений
- Возможность пакетной работы
- Возможность менять стили в изменяемом тексте
- Быстрый подсчёт числа повторений строки поиска в обрабатываемом тексте
- …
2.3
Как можно просмотреть список слов в тексте, которые не прошли проверку правописания?
Это можно сделать с помощью расширения Linguist, написанном на Python.
Расширение позволяет:
- Составить список слов, не прошедших проверку орфографии
- Составить список слов, присутствующих в тексте
- Подсчитать количество слов и прочую статистическую информацию о тексте
2.3
| Классы символов | |
|---|---|
| . | любой символ, кроме новой строки |
| \ ш \ д \ с | слово, цифра, пробел |
| \ W \ D \ S | не слово, цифра, пробел |
| [abc] | любой из a, b или c |
| [^ abc] | не a, b или c |
| [а-г] | символ между a и g |
| Анкеры | |
| ^ abc $ | начало / конец строки |
| \ б | граница слова |
| Экранированные символы | |
| \.\ * \\ | экранированных специальных символов |
| \ t \ n \ r | табуляция, перевод строки, возврат каретки |
| \ u00A9 | Unicode сброшен © |
| Группы и поиск | |
| (abc) | группа захвата |
| \ 1 | обратная ссылка на группу № 1 |
| (?: Abc) | группа без захвата |
| (? = Abc) | положительный прогноз |
| (?! Abc) | негативный прогноз |
| Квантификаторы и чередование | |
| а * а + а? | 0 или более, 1 или более, 0 или 1 |
| а {5} а {2,} | ровно пять, два или больше |
| а {1,3} | между одним и тремя |
| а +? а {2,}? | совпадений как можно меньше |
| ab | cd | соответствует ab или cd |
Библиотека регулярных выражений — cppreference.com
Библиотека регулярных выражений
Библиотека регулярных выражений предоставляет класс, представляющий регулярные выражения, которые представляют собой своего рода мини-язык, используемый для сопоставления с образцом в строках. Почти все операции с регулярными выражениями можно охарактеризовать, оперируя несколькими из следующих объектов:
- Целевая последовательность . Последовательность символов, в которой выполняется поиск шаблона. Это может быть диапазон, указанный двумя итераторами, символьной строкой с завершающим нулем или std :: string.
- Образец . Это само регулярное выражение. Он определяет, что составляет матч. Это объект типа std :: basic_regex, созданный из строки со специальным синтаксисом. См. Описание поддерживаемых вариантов синтаксиса в syntax_option_type.
- Согласованный массив . Информация о совпадениях может быть получена как объект типа std :: match_results.
- Запасная струна .Это строка, которая определяет, как заменить совпадения, см. Match_flag_type для описания поддерживаемых вариантов синтаксиса.
[править] Основные классы
Эти классы инкапсулируют регулярное выражение и результаты сопоставления регулярного выражения в целевой последовательности символов.
| объект регулярного выражения (шаблон класса) [править] | |
| определяет последовательность символов, совпадающих с подвыражением (шаблон класса) [править] | |
| определяет одно совпадение регулярного выражения, включая все совпадения подвыражений (шаблон класса) [править] |
[править] Алгоритмы
Эти функции используются для применения регулярного выражения, инкапсулированного в регулярном выражении, к целевой последовательности символов.
| пытается сопоставить регулярное выражение со всей последовательностью символов (шаблон функции) [править] | |
| пытается сопоставить регулярное выражение с любой частью последовательности символов (шаблон функции) [править] | |
| заменяет вхождения регулярного выражения форматированным текстом замены (шаблон функции) [править] |
[править] Итераторы
Итераторы регулярных выражений используются для просмотра всего набора совпадений регулярных выражений, найденных в последовательности.
| выполняет итерацию по всем совпадениям регулярных выражений в последовательности символов (шаблон класса) [править] | |
| выполняет итерацию по указанным подвыражениям внутри всех совпадений регулярных выражений в данной строке или по несопоставленным подстрокам (шаблон класса) [править] |
[править] Исключения
Этот класс определяет тип объектов, создаваемых как исключения для сообщения об ошибках из библиотеки регулярных выражений.
| сообщает об ошибках, сгенерированных библиотекой регулярных выражений (класс) [править] |
[править] Черты
Класс свойств регулярного выражения используется для инкапсуляции локализуемых аспектов регулярного выражения.
| предоставляет метаинформацию о типе символа, требуемую библиотекой регулярных выражений (шаблон класса) [править] |
[править] Константы
[править] Пример
#include#include #include <строка> #include int main () { std :: string s = "Некоторые люди, сталкиваясь с проблемой, думают" "\" Я знаю, я буду использовать регулярные выражения.\ "" «Теперь у них две проблемы.»; std :: regex self_regex ("ОБЫЧНЫЕ ВЫРАЖЕНИЯ", std :: regex_constants :: ECMAScript | std :: regex_constants :: icase); if (std :: regex_search (s, self_regex)) { std :: cout << "Текст содержит фразу 'регулярные выражения' \ n"; } std :: regex word_regex ("(\\ w +)"); auto words_begin = std :: sregex_iterator (s.begin (), s.end (), word_regex); auto words_end = std :: sregex_iterator (); std :: cout << "Найдено" << std :: distance (words_begin, words_end) << "слова \ п"; const int N = 6; std :: cout << "Слова длиннее, чем" << N << "символов: \ n"; for (std :: sregex_iterator i = words_begin; i! = words_end; ++ i) { std :: smatch match = * i; std :: string match_str = совпадение.str (); if (match_str.size ()> N) { std :: cout << "" << match_str << '\ n'; } } std :: regex long_word_regex ("(\\ w {7,})"); std :: string new_s = std :: regex_replace (s, long_word_regex, "[$ &]"); std :: cout << new_s << '\ n'; }
Выход:
Текст содержит фразу "регулярные выражения"
Найдено 20 слов
Слова длиной более 6 символов:
столкнулся
проблема
регулярный
выражения
проблемы
Некоторые люди, [сталкиваясь] с [проблемой], думают
"Я знаю, я буду использовать [регулярные] [выражения]. › и
‹ $ ›, сопоставить позицию
внутри строки темы и не использовать никаких символов.(? = [\ S \ s] {1,10} $) [\ S \ s] * | Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
Важно, чтобы привязка ‹ $ › отображалась внутри опережающего просмотра, потому что
тест максимальной длины работает только в том случае, если мы гарантируем, что больше нет
символов после того, как мы достигли предела. Потому что взгляд вперед на
начало регулярного выражения обеспечивает диапазон длины, следующий
шаблон может затем применить любые дополнительные правила проверки.В этом случае,
узор ‹. * › (или
‹ [\ S \ s] * › в версии
который добавляет встроенную поддержку JavaScript) используется для простого соответствия
весь предметный текст без дополнительных ограничений.
Первое регулярное выражение использует параметр «точка соответствует разрывам строки», поэтому
что он будет работать правильно, если ваша тема содержит строку
перерывы. См. Рецепт 3.4.
как применить этот модификатор с вашим языком программирования. Стандарт
JavaScript без XRegExp не имеет «точка соответствует разрывам строки».
вариант, поэтому второе регулярное выражение использует класс символов, соответствующий любому
персонаж.\ s * (?: \ S \ s *) {10,100} $
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
По умолчанию ‹ \ s › в
.NET, JavaScript, Perl и Python 3.x соответствуют всем пробелам Unicode,
и ‹ \ S › соответствует
все остальное. В Java, PCRE, Python 2.x и Ruby ‹ \ s › соответствует пробелам ASCII.
только, и ‹ \ S › соответствует
все остальное.В Python 2.x вы можете заставить ‹ \ s › соответствовать всем пробелам Unicode, передавая
UNICODE
или флаг U
при создании регулярного выражения. В Java 7 вы можете заставить ‹ \ s › соответствовать всем пробелам Unicode.
передавая флаг UNICODE_CHARACTER_CLASS . Разработчики, использующие
Java 4-6, PCRE и Ruby 1.9, которые хотят избежать использования Unicode
количество пробелов против их лимита символов может переключиться на
следующая версия регулярного выражения, использующая Unicode
категории (описаны в рецепте 2.\ p {Z} \ s] [\ p {Z} \ s] *) {10,100} $
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, XRegExp, PCRE, Perl, Ruby 1.9 |
PCRE должен быть скомпилирован с поддержкой UTF-8, чтобы
Работа. В PHP включите поддержку UTF-8 с помощью модификатора шаблона / u .
Последнее регулярное выражение объединяет Unicode ‹ \ p {Z} ›
Свойство-разделитель с сокращением ‹ \ s › для пробелов.Это потому, что
символы соответствуют ‹ \ p {Z} ›
и ‹ \ s › не
полностью перекрываются. ‹ \ s ›
включает символы в позициях от 0x09 до 0x0D (табуляция, строка
подачи, вертикальной табуляции, подачи формы и возврата каретки), которые не
присвоено свойство Separator стандартом Unicode. Объединив
‹ \ p {Z} ›
и ‹ \ s › в персонаже
class, вы убедитесь, что все пробельные символы совпадают.
В обоих регулярных выражениях квантификатор интервала ‹ {10,100} › применяется к
предшествующая ему группа без захвата, а не отдельный токен. В
group соответствует любому одиночному символу без пробела, за которым следует ноль или
больше пробелов. Квантификатор интервалов может надежно отслеживать
сколько непробельных символов найдено, потому что ровно один
непробельный символ сопоставляется на каждой итерации.
Ограничьте количество слов
Следующее регулярное выражение очень похоже на предыдущее.
пример ограничения количества непробельных символов, кроме
что каждое повторение соответствует целому слову, а не одному
непробельный символ.\ W * (?: \ W + \ b \ W *) {10,100} $
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
В Java 4–6, JavaScript, PCRE, Python 2.x и Ruby слово
знак символа ‹ \ w › в
это регулярное выражение будет соответствовать только символам ASCII A – Z, a – z, 0–9 и _,
и поэтому это не может правильно подсчитывать слова, содержащие не-ASCII
буквы и цифры.В .NET и Perl ‹ \ w › основан на таблице Unicode (как и ее
обратный, ‹ \ W ›, и
граница слова ‹ \ b ›) и
будет соответствовать буквам и цифрам из всех скриптов Unicode. В Python 2.x
вы можете сделать эти токены на основе Unicode, передав
UNICODE
или U флаг при создании
регулярное выражение. В Python 3.x они по умолчанию основаны на Unicode. В Java
7, вы можете сделать сокращение для слова и без слова
символов на основе Unicode путем передачи флага UNICODE_CHARACTER_CLASS .\ p {L} \ p {M} \ p {Nd} \ p {Pc}] + | $)) {10,100} $
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, XRegExp, PCRE, Perl, Ruby 1.9 |
PCRE должен быть скомпилирован с поддержкой UTF-8, чтобы это работало. В
PHP, включите поддержку UTF-8 с помощью модификатора шаблона / u .
Как уже отмечалось, причина этих разных (но равнозначных)
регулярные выражения — это различная обработка символа слова и слова
граничные маркеры, более подробно объясненные в Символах слов.
Последние два регулярных выражения используют классы символов, которые включают
отдельные категории Unicode для букв, знаков (необходимо для сопоставления
слова многих языков), десятичные числа и знаки препинания соединителя
(подчеркивание и подобные символы), что делает их эквивалентными
на более раннее регулярное выражение, которое использовало ‹ \ w › и ‹ \ W ›.
Каждое повторение группы без захвата в первых двух
эти три регулярных выражения соответствуют целому слову, за которым следует ноль или более
несловесные символы.\ p {L} \ p {M} \ p {Nd} \ p {Pc}] ›), чтобы каждый
повторение группы действительно соответствует целому слову. Без
границы слова, единственное повторение будет разрешено для соответствия любой части
слова, с последующими повторениями, соответствующими дополнительным
шт.
Третья версия регулярного выражения (которая добавляет поддержку XRegExp,
PCRE и Ruby 1.9) работает немного иначе. Он использует плюс (один или
more) вместо квантификатора звездочки (ноль или больше) и явно
позволяет сопоставление нулевых символов, только если в процессе сопоставления
дошел до конца строки.Это позволяет нам избежать слова
граничный маркер, который необходим для обеспечения точности, поскольку ‹ \ b › не поддерживает Unicode в
XRegExp, PCRE или Ruby. ‹ \ b › — поддерживает Unicode в
Java, даже если в Java ‹ \ w › нет (если вы не используете флаг UNICODE_CHARACTER_CLASS в Java 7).
К сожалению, ни одна из этих опций не поддерживает стандартный JavaScript.
или Ruby 1.8 для правильной обработки слов, в которых используются символы, отличные от ASCII.\ s * (?: \ S + (?: \ s + | $)) {10,100} $
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, Perl, PCRE, Python, Ruby |
Во многих случаях это будет работать так же, как и предыдущее.
решения, хотя это не совсем эквивалент. Например, один
разница в том, что соединения, соединенные дефисом, например
«Далеко идущие» теперь будут учитываться как одно слово вместо двух.В
то же самое относится к словам с апострофами, например, «не надо».
30 Полезные инструменты и ресурсы для регулярных выражений
Регулярное выражение, или часто называемое регулярным выражением, — это шаблон, который состоит из правил, используемых для сопоставления определенного набора строк. Они чрезвычайно мощные, и они понадобятся вам на большинстве языков программирования, с которыми вы сталкиваетесь, особенно когда необходимо сканировать и сопоставлять контекст для дальнейших действий.
Вот простой пример регулярного выражения — чтобы соответствовать всей строке, состоящей из « регулярное выражение », « регулярное выражение », « регулярное выражение » и « регулярное выражение » в содержимом, это ваше регулярное выражение. шаблон — reg (улярное выражение? | ex (p | es)?)
Поначалу они могут показаться немного запутанными или трудными для понимания, но как только вы поймете синтаксис, вы заметите, что он довольно простой и определенно очень полезен для будущих проектов по программированию.Изучение и использование регулярных выражений не должно быть мучительным процессом.
Вот список полезных инструментов и ресурсов для регулярных выражений, которые сделают вашу жизнь проще.
Руководство для начинающих по регулярным выражениям (Regex)
Руководство по регулярным выражениям (Regex) для начинающих
Регулярное выражение — это набор символов, образующих шаблон, который можно искать в строке …. Читать далее
Инструменты для регулярных выражений рабочего стола
regexИнструменты
Простое и понятное приложение RegEx для macOS для записи и проверки совпадений RegEx.
- Платформа: macOS
- Цена: Бесплатно
Узоры
Довольно обширное приложение для macOS для написания и тестирования RegEx. Он имеет подсветку синтаксиса в реальном времени для шаблона RegEx и совпадений. Он также поддерживает множество разновидностей RegEx, включая Perl (PCRE), Ruby, bash, grep и sed. Отличное приложение как для новичков, так и для опытных пользователей.
- Платформа: macOS
- Цена: 2 доллара.99
Маркер RegEx
Это приложение позволяет автоматизировать редактирование кода в XCode с помощью RegEx. С его помощью вы можете написать выражение, добавляете ли вы новую строку, заменяете или удаляете ее. Он совместим с XCode 10 и 9 в macOS Mojave или High Sierra.
- Платформа: macOS
- Цена: $ 4.99
Expresso
Expresso — отмеченный наградами редактор регулярных выражений, подходящий для начинающих регулярных выражений; он также имеет полнофункциональную среду разработки для программистов и веб-дизайнеров.
- Платформа: Windows
- Цена: Бесплатно
Регги
Приложение с открытым исходным кодом должно быть простым функциональным приложением с красивым пользовательским интерфейсом для macOS. Он поддерживает несколько разновидностей RegEx, включая Perl, Ruby и Java.
- Платформа: macOS
- Цена: Бесплатно
тренер Regex
Графическое приложение для Windows, которое можно использовать для интерактивных экспериментов с (совместимыми с Perl) регулярными выражениями.
- Платформа: Windows
- Цена: Бесплатно
Виджет Regex
Интерактивный виджет для тестирования регулярных выражений для JavaScript и других языков (таких как Sed, Ruby или Perl).
- Платформа: macOS
- Цена: Бесплатно
Регулярное выражение магии
Создает полные регулярные выражения в соответствии с вашими требованиями без необходимости иметь дело с синтаксисом регулярных выражений.
- Платформа: Windows
- Цена: 39.95 $
RegexPixie
Довольно многофункциональный инструмент для работы с RegEx в Windows. Он предлагает подсветку синтаксиса в реальном времени, поиск с заменой совпадений RegEx и поддержку «именованной группы» в RegEx.
- Платформа: Windows
- Цена: Бесплатно
Средство регулярных выражений Regex
Еще один удобный инструмент для Windows для написания и тестирования шаблона RegEx.Это работает довольно просто. Он имеет 3 входа, где вы можете добавить источник текста для тестирования, еще один вход для записи шаблона RegEx, а другой вход будет показывать совпадения RegEx в режиме реального времени.
- Платформа: Windows
- Цена: Бесплатно
Выражения
Приложение для macOS для игры с RegEx. Он имеет красивый минималистичный интерфейс, а также поддерживает темный режим macOS.
- Платформа: macOS
- Цена: долларов США7.99
Рекс-Т
Позволяет легко разрабатывать и тестировать сложные шаблоны RegEx и сохранять их для дальнейшего использования. Он также может сгенерировать образец кода на основе шаблона для использования в коде Swift или Objective-C.
- Платформа: macOS
- Цена: USD1.99
Интернет-инструменты для регулярных выражений
RegExr
Созданный gskinner, это один из лучших онлайн-инструментов для работы с регулярными выражениями, которые мы когда-либо видели. Это разработано сообществом с полезными примерами синтаксиса регулярных выражений.Поддерживает соответствие и замену.
Регулярное выражение 101
Один из самых популярных и полнофункциональных онлайн-инструментов RegEx. Помимо ввода для тестирования.
Рубика
Редактор регулярных выражений на основе Ruby. Удобный и простой способ проверить свои регулярные выражения в Интернете.
RegexTester
Этот сервис использует функции регулярных выражений PHP в качестве основы для своих операций. Это также может быть полезно для программистов других языков.
Рекс В
Средство оценки регулярных выражений на основе Ajax для трех различных систем регулярных выражений PHP PCRE, PHP Posix и Javascript.
Средство тестирования регулярных выражений Python
Один из веб-инструментов регулярных выражений Python для быстрого тестирования регулярных выражений. Включает поддержку специальных функций регулярных выражений Python, таких как dotall и unicode.
Ненавижу RegEx
Набор часто используемых выражений RegEx, подобных тем, которые соответствуют имени пользователя , электронной почты , телефонному номеру с объяснением того, для чего соответствует каждое выражение. Экономия времени и отличный источник для изучения RegEx.
PHPLiveRegEx
Удобный инструмент для написания шаблона RegEx и тестирования с помощью функции PHP, такой как preg_match , preg_match_all и preg_replace прямо из браузера.
Сборка RegEx
Удобно составлять выражение RegEx с помощью пользовательского интерфейса. Вы можете просто щелкнуть, выбрать условие и перетащить, чтобы изменить положение синтаксиса.
Regulex
Инструмент, позволяющий визуализировать шаблон RegEx для JavaScript.Удобный инструмент, если вы собираетесь написать учебное пособие, книгу или презентацию.
Надстройки кода Visual Studio
VScode Регулярное выражение
Надстройка, которая позволяет вам написать выражение RegEx и показать текущие совпадения в параллельном документе.
RegexWorkbench
Надстройка, которая запускает инструмент на собственном экране в Visual Studio Code для разработки и тестирования шаблона RegEx.
Добавить комментарий