
машина времени в любое место
Доброго дня, уважаемые посетители моего блога. Сегодня я не буду рассказывать о создании сайтов, заработке и других полезных штуках. Я решил немного поразвлечься. Конечно же, это мы будем делать с пользой.
Мы отправимся в прошлое интернета и посмотрим на то, как выглядел дизайн много лет назад. Я научу вас делать это в любое удобное для вас время. С этого момента машина времени будет для вас доступна по первому требованию.

Итак, как посмотреть сайт в прошлом? Сегодня я покажу, а заодно поведаю вам о некоторых интересных фактах из жизни популярных сайтов. Ну что ж, не будем тянуть.
Как смотреть в прошлое
В сожалению, вы не сможете увидеть как выглядел конкретно ваш сайт, но множество популярных ресурсов находится в базе archive.org/web/web.php. По словам самого сервиса, у них сохранилось 500 биллионов страниц.

Просто зайдите на этот портал, введите в поисковую строчку адрес сайта, который хотите увидеть, например Яндекс, и выбирайте Browse History.

Синим цветом на календаре отмечены дни, в которые добавлены скриншоты. Полоса сверху показывает годы. Черные полоски – количество изображений. Чем они выше, тем больше вы можете увидеть. Как вы видите, ближе к нашему времени скриншоты стали добавлять чаще.

Выбираете год, затем дату. Наводите на нее стрелкой, а затем кликаете на время добавления. В данном случае 03:42 или 03:44. Рекомендую последнее действие (с временем) производить через правую кнопку мыши, а в открывшемся меню выбирать «Открыть в новой вкладке». На мой взгляд так удобнее.

И вот перед вами скриншот того, как выглядел Яндекс 12 декабря 1998 года. Эта информация высвечивается в верхнем баре, который можно закрыть при желании. Или, через него же выбирать другую дату. Путешествие во времени осуществляется очень просто. Даже несмотря на то, что «машина» на английском.

Это Яндекс постарше, образец 2000 года.

Так он выглядел в 2005, 11 лет назад.

Ну а так эта поисковая система отображалась в прошлом году. Изменения есть!

Ну вот в принципе и все, но не спешите покидать мой блог. Мне бы хотелось показать вам еще несколько популярных проектов и рассказать интересные факты об этих сайтах.
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.

Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.

Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.

Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.

YouTube
Компания YouTube открылась 14 февраля, в день всех влюбленных. В России же его начали использовать лишь в 2007 году, а первым выложенным роликом стала песня Петра Налича «Гитар». С той поры прошло 10 лет.

Если бы ютуб был не видеохостингом, а кинокомпанией, то каждую неделю они смогли бы выпускать по 60 тысяч фильмов. Материала для этого предостаточно.
Кстати, сейчас у ютуба столько же посетителей, сколько было пользователей в интернете в целом в 2000 году. Ежедневно ролики набирают около 2 миллиарда просмотров.
YouTube не только стал одной из самых популярных компаний, но еще и делает знаменитыми простых людей. Многим россиянам известны такие люди как Макс Голопогосов (+100500), Рома Желудь, BadComedian, mrFreeman. А вот певица Адель и Джастин Бибер получили всемирную славу благодаря этой социальной сети. Я уже молчу о том, сколько людей благодаря ним смогли разбогатеть.
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.

Кстати, само название социальной сети стало производным от фразы, которую Павел Дуров, создатель, постоянно слышал по радио «Эхо Москвы». Она звучала как «В полном контакте с информацией».
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.

Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.

Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?

Интересный момент, но благодаря социальным сетям люди не только общаются между собой и зарабатывают, но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Мне очень понравилось, как они потом подшутили над этим фактом. После «воскрешения» в одной из серий они не показали ни единого кадра с псом, а в конце написали какую-то забавную фразу из серии: «Кто-нибудь вообще заметил, что в этой серии не было Брайана? Нам ждать возмущений по этому поводу в социальных сетях?».
Ну и на последок мне бы хотелось порекомендовать вам курс «Из зомби в интернет-предпринимателя». Становитесь популярными и вы, достигайте своих целей.

Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Подписывайтесь на рассылку и я помогу вам справиться со сложностями. До новых встреч.
Как узнать вид сайта в прошлом через WebArchive
У 9 из 10 наших читателей есть свой сайт или интернет-магазин на 1C-UMI. Кто-то создал его недавно, а кому-то уже можно праздновать юбилей. За годы развития веб-ресурсы претерпевают множество изменений во внешнем виде и функционале. Иногда хочется вспомнить, каким же был ваш проект раньше, когда всё только начиналось. Или поднять какую-то утерянную информацию, которая была на сайте ранее. Сделать это легко при помощи чудо-сервиса Wayback Machine.
Как пользоваться веб-архивом
Откройте сервис, вбейте в строку поиска домен или полный адрес своего сайта. Сервис автоматически начнет поиск и через пару секунд покажет вам результаты в виде временной шкалы и календаря с датами, когда были сделаны снимки ресурса.
Чтобы перейти к конкретному году, кликните по соответствующему блоку на шкале. Затем в календаре ниже нажмите на одну из дат, выделенных голубым цветом. Если в тот день было сделано несколько снимков, при нажатии на дату вы увидите окно для выбора нужного вам времени. Если снимок был один, вы сразу попадете на сохраненную версию.
Вот так выглядел наш сайт 1C-UMI летом 2012 года:
А вот так его видели наши пользователи осенью 2016 года:
Чем дольше ресурс работает, тем больше его снимков будет в WebArhive. Для путешествия в прошлое используйте временную шкалу и блок переключения месяцев и чисел справа от нее.
Самое классное — что данный сервис не делает скриншоты сайтов, а сохраняет их целиком. Таким образом, вы увидите версию 10-летней давности и, все разделы, формы, почитаете тексты, полистаете изображения и многое другое.
Какие сайты попадают в веб-архив
Оказаться в Wayback Machine может любой сайт. Особенно это касается тех веб-ресурсов, которые находятся в каталоге DMOZ. Но так как сейчас туда свое «детище» уже не добавить, будет достаточно того, что на вашу площадку ссылаются сайты, снимки которых уже присутствуют в веб-архиве. А даже если таких ссылок нет, ваш ресурс все равно может попасть в базу сервиса. Главное, чтобы в его файле Robots.txt не было запрета.
Как проверить? Для сайтов на 1С-UMI откройте раздел «Реклама/SEO → Управление robots.txt» в панели управления сайтом и проверьте, нет ли в нем следующей записи:
User-agent: ia_archiver
Disallow: /
Если такой записи (как выше) нет, все хорошо, ваш сайт имеет шанс на попадание в веб-архив. В противном случае, при поиске своего ресурса в сервисе вы увидите надпись, как на скриншоте ниже.
Если вы не хотите ждать, когда сервис соблаговолит сделать снимок вашего сайта, добавьте его в базу WebArchive вручную. Для этого найдите функцию «Save Page Now», которая находится в центральной части страницы справа.
Укажите ссылку на свой ресурс и нажмите на кнопку «SAVE PAGE». Сохранение начнется через несколько секунд и, спустя минуту или около того, будет закончено. За ходом выполнения вы можете наблюдать в небольшом окошке по центру экрана.
После сохранения снимка страницы начнет загружаться только что архивированная версия сайта.
По окончании процесса окно загрузки закроется, и вы сможете просмотреть сохраненный снимок, побродить по всем разделам сайта и т. д.
Чем будет полезен веб-архив для вас
Данный сервис годится не только для того, чтобы смотреть, в каком состоянии была ваша страничка или любой другой ресурс некоторое время назад. С его помощью вы можете восстановить свой сайт, его страницу, какой-то текст или элемент, если вдруг по какой-то причине данные были стерты. Чтобы этого не произошло, не забывайте почаще выполнять резервное копирование вашего сайта, ну, а на экстренный случай имейте в виду WebArchive. Но имейте в виду также, что WebArchive делает снимки по своему усмотрению с непредсказуемой частотой, поэтому нужной вам версии сайта в нем может и не оказаться.
Вручную восстанавливать ресурс из веб-архива очень долго и для этого нужно неплохо разбираться в сайтостроении и верстке. Однако при желании восстановление можно автоматизировать при помощи онлайн-инструмента ARCHIVARIX.
До 200 файлов сервис восстанавливает бесплатно, а при большем количестве взимает небольшую плату.
Веб-архив может быть вам полезен и тем, что он содержит колоссальное количество уникальных текстов, которые опубликованы на канувших в небытие ресурсах. Как это можно использовать с выгодой для своего бизнеса? Допустим, вы запускаете сайт. Сами писать тексты не можете из-за отсутствия времени, а на оплату услуг копирайтера денег нет. Чтобы не откладывать запуск проекта, попробуйте найти уникальный контент в Wayback Machine.
Найдите любой сайт, близкий вашему по тематике, откройте его содержимое, скопируйте тексты и прогоните их через софт или сервис проверки на плагиат. Статьи, которые окажутся уникальными (от 90% и выше), вы можете без зазрения совести опубликовать на своем сайте. Это не будет считаться хищением, так как тексты после удаления ресурсов стали ничейными.
Для поиска таких сайтов можно использовать базы хостинговых компаний. Обычно они публикуют список тех доменов, срок действия которых истек или вот-вот истечет. Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Несколько фактов о веб-архиве
Первый запуск сервиса WebArchive состоялся в 1996 году. С тех пор этот инструмент сумел накопить в своей базе более 338 миллиардов сайтов. Представьте, сколько это! А дисковое пространство, которое занято информацией в архиве, составляет 1015 Терабайт. Если перевести на математический язык, то это квадриллион.
На следующий год после основания сервиса WebArchive добавил в свою базу сам себя. Хотите посмотреть, как он выглядел на тот момент? Тогда взгляните на изображение ниже.
Это самый первый его снимок от 26 января 1997 года.
На данный момент веб-архив считается наилучшим способом из бесплатных для создания снимков интернет-ресурсов. Возьмите его на вооружение.
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.

Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Перейдя по ссылке, мы узнаем его поближе: http://archive.org/web/web.php
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:

История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:

Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:

Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Читайте также:
Как посмотреть старую версию сайта одним классным способом?
Автор Дмитрий Костин На чтение 4 мин. Опубликовано
Всем привет! Скажите, хотел бы вы ненадолго вернуться в прошлое, чтобы увидеть себя молодого или маленького со стороны, пообщаться, глянуть, каким вы были? К сожалению, такое совершить пока невозможно. Но зато такое можно проделать с любым веб-ресурсом. Я имею в виду, что можно вернуться на год или два назад, чтобы увидеть как выглядел cайт раньше, какой у него был дизайн, даже какая стояла реклама.
Да. Оказывается есть специальный сервис, который несколько десятков раз в году (10-20-100) делает архивные копии сaйтов, и любой желающий может абсолютно бесплатно посмотреть прошлые версии своих или чужих ресурсов. На самом деле это очень крутая вещь, поэтому я настоятельно рекомендую вам окунуться в прошлое. Поэтому сегодня я вам покажу, как посмотреть старую версию сайта одним очень классным и проверенным способом.
Archive.org
Заходите на сайт Archive.org и впишите в специальное поле адрес вашего сайта.
После этого вы увидите годовую ленту и календарь с отмеченными датами. Перемещаясь по ленте, вы выбираете год, в который вы хотите вернуться, и уже для каждого года активируется свой календарь с отмеченными датами. Именно в эти числа была создана архивная копия, а значит вы можете посмотреть состояние на тот момент. Нажмите на любое число, отмеченное кружком. Я наведу на 15 марта 2016 года и тут же появится вставка со временем. Жмите на нее.
Конечно мой сайт не сильно изменился за последний год, но на 15 марта 2016 года из нет. То есть я не наблюдаю баннеров в правом сайдбаре, не наблюдаю некоторые рубрики, например «Эксперименты» или Заработок и финансы». Также слегка изменено меню, топ комментаторов стал таким, каким был на тот момент, т.е. еще до того, как я исключил себя из этого топа. Правда некоторые моменты отображаются неправильно, например некоторые комментаторы или виджет вконтакте.
Но в целом вещь очень крутая. Можно не просто посмотреть, но и походить по местам былой славы. Действительно, как будто попали в прошлое, а не смотрите фильм про прошлое.
Но у меня дизайн не менялся, поэтому давайте усложним задачу. Возьмем какой-нибудь блог, который существует давно и 100% менял свой дизайн. Я помню, что не так давно моя знакомая по школе блоггеров Настя Скореева поменяла внешний вид своего сайта nyaskory.ru. Сейчас он выглядит так.
Теперь я иду на наш сервис чтобы проверить старую версию ее блога. Для этого я снова вбиваю имя сайта, выбираю дату, когда еще шаблон был старый, например март 2015 года и вуаля! Смотрим результат. Да. Видно, что блог Насти претерпел большие изменения.
Вконтакте
Ради прикола я еще решил проверить социальную сеть вконтакте и посмотреть предыдущие версии этого сайта. Все мы помним, что сеть начала свою деятельность еще в 2006 году и тогда сайт располагался по адресу vkontakte.ru, а не vk.com. Вот его я и решил ввести и посмотреть его в 2006 году. Вы помните такой дизайн? Вот таким он был.
Я зарегистрировался в 2007 году (помню, как даже смотрел дату регистрации в вк) и вот так выглядел тогда этот сайт.
В 2011 году ВК ограничил свободные регистрации в связи с наплывом фейковых страниц. Зарегистрироваться там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.
А с 2012 года сайт переходит на новый домен vk.com, и со старого происходит автоматическая переадресация. Поэтому с этого момента у вас не получится посмотреть, как выглядел vkontakte.ru например в 2013 году, так как надо вводить уже современный адрес и смотреть там.
В общем как-то так. Здорово, да? Я вот прошелся по старым дизайна вконтакте, и аж ностальгия взяла. Когда я регистрировался, там находилось всего чуть более миллиона человек. А теперь там сотни миллионов.
Ну в общем рекомендую вам тоже пройтись по задворкам прошлого и взглянуть, как всё выглядело раньше. А на сегодня я уже буду закругляться. Надеюсь, что статья была для вас интересной, поэтому не забудьте подписаться на обновления моего блога. С нетерпением буду вас снова ждать у себя в гостях. Удачи вам. Пока-пока!
С уважением, Дмитрий Костин.
Восстановление сайтов из Веб Архива. Копирование сайтов онлайн. Бесплатная CMS.
Восстановить с субдоменами
Оптимизировать HTML-код
Оптимизировать картинки
Сжать JS
Сжать CSS
Вычистить счетчики и аналитику
Вычистить рекламу
Удалить внешние ссылки, сохранив анкоры
Удалить внешние ссылки вместе с анкорами
Удалить кликабельные контакты
Удалить внешние iframes альфа
Сделать внутренние ссылки относительными рекомендуем
Сделать сайт без www. (обновляются все внутренние ссылки) рекомендуем
Сделать сайт с www. (обновляются все внутренние ссылки)
Сохранить перенаправления
История домена, история сайта
У Вас в браузере заблокирован JavaScript. Разрешите JavaScript для работы сайта!
В моей экспертно-судебной практике стали встречаться запросы, связанные с историей использования домена.
Данный материал поможет пользователям и другим экспертам в получении информации об истории сайта.
Основные источники информации:
- Анализ сайта — сводная информация о сайте и готовые прямые ссылки на другие сервисы с передачей домена.
- web.archive.org — История сайта, если сайту более 6 месяцев
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»
Чтобы увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/yoursite.com/*, например, http://web.archive.org/*/htmlweb.ru/
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE». - archive.md, он же archive.ph и archive.today
Получить все снимки указанного URL: http://archive.is/http://htmlweb.ru/
Все сохранённые страницы домена: http://archive.is/htmlweb.ru
Все сохранённые страницы всех субдоменов: http://archive.is/*.htmlweb.ru - web-arhive.ru
- whoishistory.ru — история изменения Whois только для зон ru, рф, su
Пример прямого запроса:whoishistory.ru/simplesearch?sbmt=start&domainsimple=htmlweb.ru - Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:cache:https://htmlweb.ru/ - История Whois на reg.ru — регистратор reg.ru платно предоставляет информацию об изменениях whois домена
- История Whois на domaintools.com
- Поиск по Whois в зонах RU и SU
- Поиск соседних доменов (расположенных по тому же IP адресу что и Ваш домен)
Пример прямого запроса:http://1stat.ru/neighbours?show=neighbours&search_name=htmlweb.ru - Косвенно по ссылкам на домен: linkpad
Пример прямого запроса:https://www.linkpad.ru/?search=htmlweb.ru - История Alexa Rank за 90 дней
Пример прямого запроса:https://www.alexa.com/siteinfo/htmlweb.ru
как пользоваться вебархивом, как восстановить сайт и узнать, как он выглядел раньше
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Веб-архив (Webarchive) – это бесплатная платформа, где собраны все сайты, созданные когда-либо, и на которые не наложен запрет для их сохранения.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
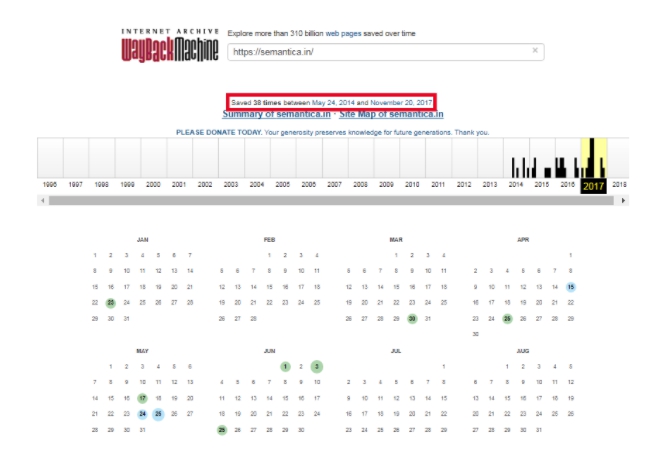 Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
 Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
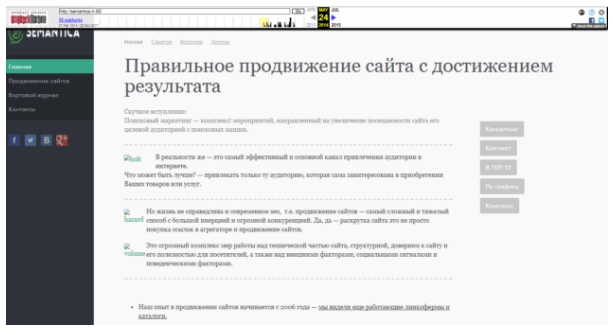 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
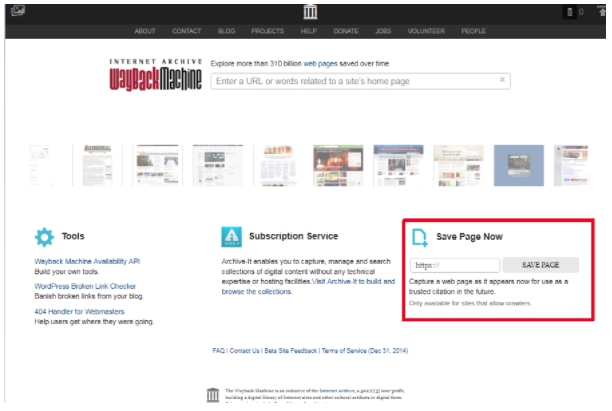 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
СТРАНИЦ — Прошедшие глобальные изменения
Проект PAGES (Прошлые глобальные изменения) — это международная попытка координировать и продвигать прошлые исследования глобальных изменений. Основная цель состоит в том, чтобы улучшить наше понимание прошлых изменений в системе Земля, чтобы улучшить прогнозы будущего климата и окружающей среды и дать информацию для стратегий обеспечения устойчивости. … еще
PAGES, зарегистрированная ассоциация научных исследований и сетей, открыта для всех ученых, заинтересованных в глобальных изменениях прошлого.Наука в рамках PAGES проводится рабочими группами, которые открыты для всех палеологов, работающих над темой. Примите участие, связавшись с руководителями рабочих групп, подписавшись на списки рассылки и посетив телеконференции и / или семинары.
PAGES финансируется Швейцарской академией наук и Китайской академией наук и поддерживается натурой Бернским университетом, Швейцария. В административных целях он является частью Центра исследований изменения климата Ошгера (OCCR).PAGES — это глобальный исследовательский проект Future Earth, научный партнер WCRP и партнер WDS-Paleo.
Следуйте за нами в Facebook, Twitter и YouTube.
- Детали
- Опубликовано: 25.09.2020 19:43
Из-за пандемии COVID-19 и последующей большой неопределенности в отношении здоровья, ограничений на поездки и экономического кризиса PAGES и местные организаторы OSM / YSM, к сожалению, должны принять решение отложить OSM / YSM до мая 2022 года.Более того, до принятия окончательного решения ситуация будет пересмотрена в середине 2021 года.
Подробнее …
- Детали
- Опубликовано: 17.09.2020 14:31
Две новые одобренные группы открыты сегодня на веб-сайте PAGES.
Международная сеть Paleofire (IPN) была создана для продолжения работы Глобальной рабочей группы 2 Paleofire (GPWG2) PAGES, которая прекратила свое существование в декабре 2019 года.Программа IPN, которая продлится до 2030 года, посвящена продвижению науки о палеопламени и управлению базами данных с открытым доступом и их развитию.
> Узнать больше о IPN
Другая одобренная группа — это инновационная обучающая сеть h3020 по прокси-серверам глубокого ледяного покрова для анализа динамики антарктического климата в прошлом (DEEPICE). Он продлится с 2021 по 2025 год, период захватывающих времен и проблем для европейского сообщества ледяных кернов, как часть старейшего проекта ледяного ядра Beyond EPICA.
Участники DEEPICE также будут работать над будущим выпуском журнала Past Global Changes Magazine .
> Узнать больше о DEEPICE
Получите доступ ко всем одобренным и аффилированным группам PAGES здесь.
- Детали
- Опубликовано: 14.09.2020 16:08
Скажите свое слово!
PAGES подготовил опрос (документ Google) для сбора предложений от палеонаучного сообщества относительно деятельности PAGES в ближайшие годы.
Ответы на опрос будут представлены и использованы в качестве основы для обсуждения на нашем 6-м Открытом научном собрании в Агадире, Марокко, в мае 2021 года.
Есть три раздела — о вас, о приоритетах СТРАНИЦ и о том, что СТРАНИЦЫ могут для вас сделать.
Крайний срок для опроса, на заполнение которого уходит около 10 минут, — воскресенье, 14 февраля 2021 года.
PAGES заранее благодарит вас за ваш отзыв.
- Детали
- Опубликовано: 09.09.2020 15:31
Читайте о последних новостях, встречах и возможностях PAGES со всего мира в электронных новостях этого месяца.
Основные моменты включают продление крайних сроков для YSM и OSM в 2021 году; призыв к воспоминаниям о 30-летии СТРАНИЦ; обширные новости рабочих групп, продукты и обновления встреч; Номинации на премию «Ранняя карьера» PAGES поданы 30 сентября; ECN, Земля будущего и информация ВПИК; и многие другие актуальные возможности.
Были продлены несколько сроков проведения 6-го открытого научного собрания (OSM) и 4-го собрания молодых ученых (YSM) PAGES, которые состоятся в Агадире, Марокко, с 16 по 22 мая 2021 года.
YSM
Новый крайний срок подачи заявок на участие в YSM — 11 октября (было 13 сентября). Будет выбрано около 80 начинающих исследователей. Дата уведомления о решении для выбора участников YSM и тех, кто получает гранты, теперь 15 ноября.
> Все подробности
YSM будет проходить в 30 км к северу от Агадира с 16 по 18 мая 2021 года.
OSM
Крайний срок подачи тезисов и запросов на финансовую поддержку OSM был продлен до 15 октября (было 1 октября).
> Все подробности
OSM пройдет в Агадире 18-22 мая 2021 года.
PAGES внимательно следит за ситуацией с коронавирусом и будет следовать указаниям соответствующих национальных органов общественного здравоохранения и глобальных организаций здравоохранения. Мы по-прежнему надеемся, что YSM и OSM состоятся в соответствии с графиком лично. PAGES и Местный организационный комитет будут продолжать выпускать обновления по мере поступления информации.
- Детали
- Опубликовано: 27.08.2020 16:17
Новая статья «Уроки из мира с высоким содержанием CO 2 : вид на океан примерно 3 миллиона лет назад» от бывшей рабочей группы PAGES «Изменчивость климата плиоцена в ледниково-межледниковых временах» (PlioVAR) была опубликована в Climate прошлого сегодня.
Авторы во главе с Эрин МакКлимонт исследуют один межледниковый период в течение позднего плиоцена (KM5c, примерно 3,205 ± 0,01 млн лет), когда содержание CO 2 в атмосфере превышало доиндустриальные концентрации, но были аналогичны сегодняшним и сценариям самых низких выбросов для этот век.
Поскольку орбитальное воздействие и континентальные конфигурации были почти идентичны сегодняшним, они могут сосредоточиться на реакции равновесной климатической системы на современный и ближайший выброс CO 2 . Используя косвенные данные с 32 участков, они демонстрируют, что глобальные средние температуры поверхности моря были на ∼2 выше, чем доиндустриальные значения.3 ° C для объединенных прокси-данных (фораминиферы Mg ∕ Ca и алкеноны) или на ~ 3,2–3,4 ° C (только алкеноны).
Их результаты показывают, что даже при сценариях с низким уровнем выбросов CO 2 можно ожидать, что потепление поверхности океана превысит прогнозы модели и будет усиливаться в более высоких широтах.
Доступ к бумаге здесь.
Подробнее о работе PlioVAR можно узнать здесь.
.
Что такое режим макета страницы и как его использовать?
- Дом
- Начало работы
- Бизнес
- Продам
- ВА Профили
- Образ жизни
- Офисные навыки
- Бухгалтерский учет
- Создание контента
- Excel
- Инфузионсофт
- Mac
- Outlook
- PowerPoint
- SEO
- Социальные сети
- Издатель
- Слово
- Программное обеспечение
- Технологии
- Ресурсы
Поиск
Понедельник, 5 октября 2020 г.
 VA Pro Magazine
VA Pro Magazine
- Дом
- Начало работы
- Бизнес
- Продам
- ВА Профили
- Образ жизни
- Офисные навыки
- Бухгалтерский учет
- Создание контента
- Excel
- Инфузионсофт
- Mac
- Outlook
- PowerPoint
- SEO
- Социальные сети
- Издатель
- Слово
- Программное обеспечение
- Технологии
- Ресурсы
На главную Навыки офиса Excel Что такое режим макета страницы и как его использовать?
- Офисные навыки
- Excel
Автор:
Стеф Миддлтон-Фостер 1
16477
Поделиться
Твиттер
Google+
.
Как обойти платный доступ на популярных новостных сайтах
Вот как быстро обойти платный доступ на популярных новостных сайтах и сайтах журналов.
Если вы пытались прочитать статью на таких сайтах, как Washington Post, Medium, Bloomberg, Los Angeles Times, Wired, Vanity Fair или Wall Street Journal, вы, вероятно, столкнулись с платным доступом. Платный доступ ограничивает доступ к контенту, требуя платной подписки, но есть несколько способов обойти это.
Информация становится все более фрагментированной, и многие из нас используют множество сайтов для доступа к информации.В наши дни для большинства людей экономически нецелесообразно платить за несколько подписок для просмотра сайтов, которые вы иногда посещаете. Если вы регулярно посещаете новостной или другой сайт на работе или в личных целях, имеет смысл заплатить за подписку. Постоянным читателям целесообразно иметь подписку. Некоторые новостные сайты потеряли читателей печатных изданий и нуждаются в доходах, чтобы оставаться на плаву.
Если вам нужен доступ к сайту на короткий период времени, рекомендуется воспользоваться множеством предлагаемых пробных подписок.Обычно они рассчитаны на 14 или 30 дней и могут быть отменены в любое время до истечения пробного периода.
Некоторые советы по обходу платного доступа могут измениться в любой момент, а то, что сработало на прошлой неделе, может не сработать сегодня.
Используйте надстройки и расширения
Если вы используете веб-браузер, это надстройка может обходить платный доступ на многих сайтах. Надстройка bypass-paywalls от iamadamdev доступна как для браузеров на базе Firefox, так и для Chrome. Щелкните ссылку браузера, который хотите использовать, и следуйте инструкциям.Версия Firefox — это простая загрузка и установка, версия Chrome должна быть установлена вручную. Направления ясны, и это не сложно. Процесс такой же для других браузеров на базе Chrome. Разработчик говорит, что лучше всего работает в паре с uBlock Origin.
Очистить историю сайта и файлы cookie.
Работает на сайтах, которые просят вас заплатить после прочтения определенного количества статей в течение определенного периода времени. Если вы израсходуете выделенные на сайте статьи, вероятно, стоит подписаться.Я использую надстройку Firefox для очистки файлов cookie и хранилища для каждой вкладки, чтобы я мог оставаться на сайтах, которые я часто использую. Надстройка доступна на странице надстройки Firefox — она называется Кнопка удаления файлов cookie. Он удаляет локальное хранилище, файлы cookie сеанса и хранилище сеанса с текущей вкладки одним нажатием кнопки в адресной строке. Очистку сайта также можно выполнить через адресную строку большинства браузеров, щелкнув значок замка рядом с URL-адресом и используйте параметры там.
Просмотр кэшированных или заархивированных веб-страниц
Если то, что вы хотите прочитать на сайте, устарело, вы можете использовать Wayback Machine из Интернет-архива для просмотра предыдущих страниц или использовать Google Search для просмотра кешированных страниц хотя сайты теперь отключают кеш, поэтому этот метод будет все менее и менее надежным.
Отключить Java Script в вашем браузере
Вы можете отключить Javascript с помощью инструментов разработчика в браузерах, используя контекстное меню элемента проверки для просмотра и изменения кода на странице, или вы можете использовать надстройку или расширение и сделать это одним нажатием кнопки. Использование инструмента разработчика браузера для проверки элементов контекста требует небольшого знания HTML.
Chrome: быстрое переключение JavaScript
Firefox: отключить JavaScript
Воспользуйтесь сайтом для чтения и аннотации в Интернете
Outline.com извлекает текст статьи и отображает ее для чтения и аннотирования. Введите URL статьи, которую хотите прочитать. Это эффективно для большинства платных систем, но не для всех.
Вы можете найти больше Tech Treats здесь.
.
Будущее в прошлом | АНГЛИЙСКИЙ СТРАНИЦА
Как и простое будущее, future in the past имеет в английском две разные формы: would и was going to. Хотя эти две формы иногда могут использоваться как взаимозаменяемые, они часто выражают два разных значения.
ФОРМА Будет
[будет + ГЛАГОЛ]
Примеры:
- Я знал, что вы поможете ему .
- Я знал, что не поможет ему .
ФОРМА
была / собиралась на
[был / собирался + собираться + ГЛАГОЛ]
Примеры:
- Я знал, что вы собираетесь пойти на вечеринку.
- Я знал, что вы, , не пойдете на вечеринку.
USE 1 Будущее в прошлом
«Будущее в прошлом» используется для выражения идеи о том, что в прошлом вы думали, что что-то произойдет в будущем. Неважно, правы вы или нет.Будущее в прошлом подчиняется тем же основным правилам, что и простое будущее. «Был бы» используется для волонтерства или обещания, а «собирался» — для планирования. Более того, обе формы можно использовать для прогнозирования будущего.
Примеры:
- Я сказал вам, что он собирался прийти на вечеринку.
- Я знал, что Джули приготовит ужин .
- Джейн сказала, что Сэм собирался привести с собой свою сестру , но он пришел один.
- У меня было ощущение, что отпуск обернется для катастрофой.
- Он обещал, что пришлет открытку из Египта.
ПОМНИТЕ Оговорки об отсутствии будущего во времени
Как и все формы future, future in the past не может использоваться в предложениях, начинающихся с выражений времени, таких как: when, while, before, after, by the time, asfore as, if, except и т. Д. Вместо использования future в выражении прошлое, вы должны использовать простое прошлое.
Примеры:
- Я уже сказал Марку, что когда он приедет , мы пойдем ужинать. Не верно
- Я уже сказал Марку, что когда он приедет , мы пойдем обедать. Правильно
АКТИВНЫЙ / ПАССИВНЫЙ
Примеры:
- Я знал, что Джон закончит работу к 17:00.
- Я знал, что работа будет закончена к 17:00.
- Я думал, Салли собирается приготовить прекрасный ужин.
- Я думал, что Салли приготовит прекрасный ужин .
Подробнее об активных / пассивных формах
.
Добавить комментарий