
Что такое стоп-слова? Допустимый процент вхождения стоп-слов в текстах
SEO-тексты отличаются от простых текстов тем, что с помощью ключевых слов/ фраз оптимизируются под определенные поисковые запросы, облегчая пользователям поиск нужной информации. Проводить SEO-оптимизацию нужно грамотно, учитывая не только релевантность ключевиков содержанию страницы, но и множество других, влияющих на результат факторов. Поскольку, для того чтобы индексировать, а затем выдать пользователю максимально соответствующие его запросу веб-страницы, поисковые роботы подвергают содержание каждой из них тщательному анализу по многим параметрам. Наиболее важными среди них являются правильная концентрация в представленном контенте ключевых фраз, оптимальная тошнота текста и пропорция значимых и шумовых слов. Последние принимают активное участие в формировании каждого из этих параметров, поэтому познакомимся с ними поближе.
Что такое стоп-слова?
Стоп-слова (иначе называемые шумовыми) – это слова, знаки, символы, которые самостоятельно не несут никакой смысловой нагрузки и просто игнорируются поисковыми системами при осуществлении ранжирования или индексации сайтов. Но которые, тем не менее, совершенно необходимы для нормального восприятия текста, его целостности, читабельности. Без использования стоп-слов невозможно создать полноценный контент, хорошо воспринимаемый не только поисковиками, но и людьми. При написании SEO-текста они позволяют максимально органично вписать в него ключевые фразы, соединив несогласованные между собой ключевые слова с помощью предлогов или разделив их знаками препинания.
Но которые, тем не менее, совершенно необходимы для нормального восприятия текста, его целостности, читабельности. Без использования стоп-слов невозможно создать полноценный контент, хорошо воспринимаемый не только поисковиками, но и людьми. При написании SEO-текста они позволяют максимально органично вписать в него ключевые фразы, соединив несогласованные между собой ключевые слова с помощью предлогов или разделив их знаками препинания.
* — Примеры стоп-слов выделены в предыдущем абзаце.
Перечни стоп-слов (индивидуальные для каждой из поисковых систем, таких как Яндекс или Гугл) регулярно обновляются, поэтому представить их здесь полностью практически невозможно. Чаще всего стоп-слова подразделяют на 2 группы: общие, зависимые.
- К общим относят предлоги, частицы, междометия, союзы, наречия, местоимения, вводные слова, числа от 0 до 9 (однозначные), другие часто употребляемые служебные, самостоятельные части речи, символы, знаки препинания.
 Относительно недавно этот список пополнили такие часто используемые в сети Интернет последовательности символов, как www, com, http и др.
Относительно недавно этот список пополнили такие часто используемые в сети Интернет последовательности символов, как www, com, http и др. - Во вторую группу попадают слова, которые в ключевом запросе определяются, как второстепенные. Пример: в запросе «Лев Николаевич Толстой» поисковые системы выделяют основной компонент запроса – «Толстой» и второстепенные, то есть зависимые стоп-слова, имеющие значение только рядом с главным ключевым словом, – «Лев», «Николаевич». Поэтому среди выпавших в поисковой выдаче страниц будут только те, которые содержат значимый компонент запроса – «Толстой». Зависимые стоп-слова будут учитываться только при его наличии рядом с ними.
 Относительно недавно этот список пополнили такие часто используемые в сети Интернет последовательности символов, как www, com, http и др.
Относительно недавно этот список пополнили такие часто используемые в сети Интернет последовательности символов, как www, com, http и др.Стоп-слова и поисковые роботы
Все вышеперечисленные шумовые слова удаляются поисковыми роботами из текстов при их индексации, из ключевых фраз при определении соответствия документа конкретному запросу, заменяясь специальными символами – маркерами (*). Это делается с целью уменьшения размеров индекса, снижения нагрузок на сервер, рационального использования пространства баз данных.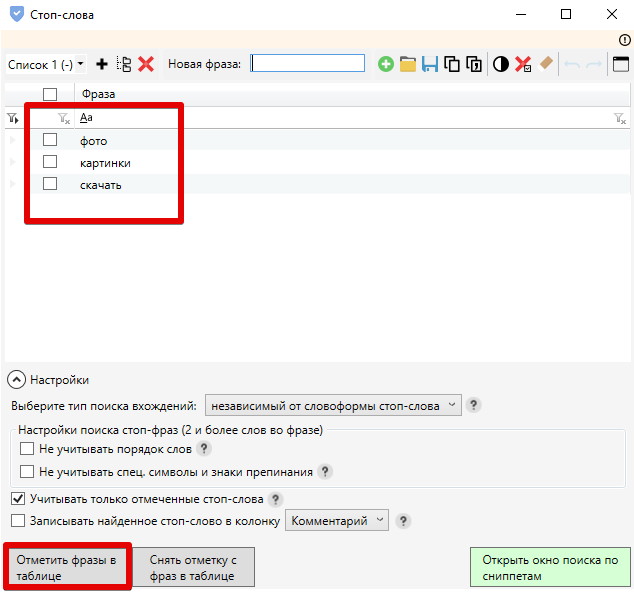 Кроме того, вычеркивание стоп-слов из запросов позволяет сократить количество операций по поиску каждого элемента ключевой фразы, а значит, повысить скорость, эффективность поиска нужной информации, сохранив релевантность запроса. Если вы хотите, чтобы система учла ваш ключевой запрос целиком (включая общие или зависимые стоп-слова), вам нужно для этого просто добавить к фразе знак «+».
Кроме того, вычеркивание стоп-слов из запросов позволяет сократить количество операций по поиску каждого элемента ключевой фразы, а значит, повысить скорость, эффективность поиска нужной информации, сохранив релевантность запроса. Если вы хотите, чтобы система учла ваш ключевой запрос целиком (включая общие или зависимые стоп-слова), вам нужно для этого просто добавить к фразе знак «+».
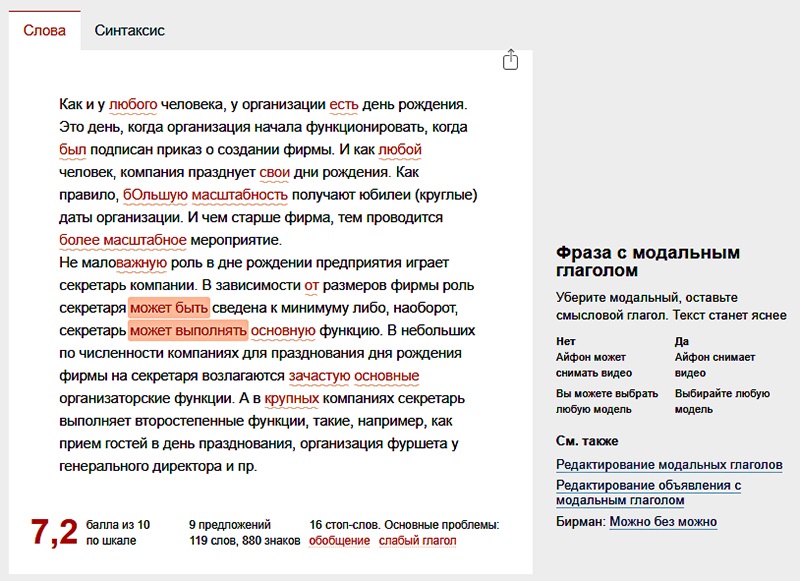
И снова повторимся. Несмотря на полное игнорирование шумовых слов со стороны поисковых систем, при создании связных, интересных для интернет-пользователей текстов без них не обойтись. Поэтому важно найти оптимальный баланс между их откровенным недостатком и явным переизбытком, удерживая правильное их соотношение с общей массой слов и ключевыми фразами. При недостатке шумовых слов вы получите сухой, нечитаемый текст, понятный только поисковым роботам, но совершенно неинтересный для посетителей сайта. А при переизбытке – текст с повышенной водностью, утяжеляющей его восприятие читателями и размывающей суть изложенной информации.
Оптимальная концентрация стоп-слов по отношению к общему количеству слов в тексте составляет около 30%, уровень тошноты текста (на которую также влияет количество стоп-слов) старайтесь удерживать в пределах значения указанных в таблице.
Символов | Слов | Допустимая тошнота* |
До 1000 | ~167 | До 3 |
До 2000 | ~334 | До 3.5 |
До 3000 | ~500 | До 4 |
До 4000 | ~667 | До 4. |
До 5000 | ~834 | До 5 |
До 6000 | ~1000 | До 5.5 |
До 7000 | ~1167 | До 6 |
 5
5* Данные значения являются усредненными и не значительно отличаться для разных тематик.
В качестве вывода:
обязательно учитывайте факт пропуска стоп-слов поисковиками при формировании поисковых запросов, ключевых фраз для SEO-текстов и определении их правильной плотности, которая неминуемо повысится после замены всех стоп-слов маркерами. Но при этом не забывайте, что текст должен оставаться читабельным. Для определения оптимального количества шумовых слов в статье в помощь авторам и оптимизаторам существует множество специализированных сервисов и программ для SEO-анализа текстов. Мы привыкли пользоваться Textus Pro и Advego.
Мы привыкли пользоваться Textus Pro и Advego.
Если же для вас это сложно, то звоните нам или заказывайте услугу продвижения сайта по словам.
Хочешь стать экспертом в SEO?
Пройди курсы от SEO Интеллект
Подробнее
Понравилось? Репост!
Ильяхов: 11 заметок с тегом стоп-слова
Ильяхов: 11 заметок с тегом стоп-слова
Rose debug info ---------------
Тег: стоп-слова
Было Данный микрофон обеспечивает оптимальный звуковой охват за счёт передовых технологий, а также надежное высококачественное поглощение вибраций за счет инновационной системе подвесов
Вот несколько примеров: .error{ color: #dA570f; font-style: normal;…
В информационном стиле есть понятие мусора. Это слова и выражения, которые не несут смысла для читателя
Это слова и выражения, которые не несут смысла для читателя
Есть такой корпоративный штамп «товары и услуги». Юридически он верный: фирма продает товары и оказывает услуги
Все неопределенное — кандидаты в стоп-слова. Читаю какие-то статьи, отвечаю на какие-то звонки → Читаю статьи, отвечаю на звонки
Сослагательное наклонение и частица «бы» — кандидаты в стоп-лист
В продолжение разговора о словах «просто» и «но». У Карнеги наконец-то нашёл почти универсальную пилюлю от «но»
Слова вроде: действительно, реально, на самом деле…
Такой комментарий подойдёт любой книге: Книга очень понравилась, никого не оставит равнодушным. Отличается интересным стилем, читается легко, доступна любому виду читателей
«Просто» — опасное слово-паразит. Оно всплывает, когда человек оправдывается
This text was created with a very old version of Aegea that used a formatter called Calliope. It is no longer included with Aegea 2
It is no longer included with Aegea 2
Стоп-слова – что это такое и как правильно применять.
Стоп-слова – seo-термин, обозначающий слова, не обладающие смысловой нагрузкой («шумовые слова»).
Что считать стоп-словами?
Стоп-слова – название слов-связок, без которых невозможно построение полноценного текст, обладающего должным смыслом. Включают в себя:
-
Вводные слова; -
Знаки препинания; -
Междометия; -
Местоимения; -
Предлоги; -
Союзы и союзные слова; -
Указательные слова; -
Цифры; -
Частицы.
Это могут быть определённые существительные, глаголы, наречия (всегда, давать, например, однако и т.п.).
Поскольку алгоритмы поисковых системнеустанно развиваются и совершенствуются, происходит периодическое обновление и изменение списков стоп-слов. Собственная база стоп-слов имеется у всех поисковиков. При написании текстов обязательное внимание стоит обращать на вхождение стоп-слов из вышеуказанных категорий и соотношение их с общей словесной массой, включая ключевые слова.
Собственная база стоп-слов имеется у всех поисковиков. При написании текстов обязательное внимание стоит обращать на вхождение стоп-слов из вышеуказанных категорий и соотношение их с общей словесной массой, включая ключевые слова.
Значение для поисковых роботов и пользователей
Стоп-слова не оказывают никакого влияния на поисковые системы, автоматически пропускаясь при индексации для того, чтобы сэкономить пространство баз данных. Данный факт обязательно следует учитывать при продвижении сайта в момент составления поисковых запросовс определением плотности ключевых слов, что касается контентного наполнения страниц.
Увеличение количества стоп-слов в тексте приводит к затруднённому восприятию читателями и создаёт впечатление «водянистости». Если стоп-слов в тексте недостаточно (оптимизатор ориентировался преимущественно на поисковые роботы, а не на читателя), такой контентпостепенно становится неинтересным пользователю.
Услуги, связанные с термином:
друзья или враги — ppc.
 world
world
Многие, уверен, знают, что такое стоп-слова и чем они отличаются от минус-слов.
«Стоп-слова — служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа». Справка Директа
Главное отличие стоп-слов заключается в том, что они детерминированы, а минус-словом может быть любое слово. Основное в определении стоп-слов — то, что это слова, не несущие смысла. Однако это понятие относительное. Есть «неоднозначные» стоп-слова, например, «то» (техобслуживание), «тех» (тех характеристики = технические характеристики), «тем» (много интересных тем). И зачастую стоп-слова кардинально меняют смысл фраз. Именно это и есть главная мысль этого материала.
Точный список стоп-слов Директа неизвестен и постоянно меняется. По моим наблюдениям, недавно из него удалили все украинские стоп-слова.
Как определить стоп-слова?
Я знаю четыре способа:
- Через заведение группы в интерфейсе: слова без стоп-слова и со стоп-словом «схлопываются», остается только слово без стоп-слова.
- Через кросс-минусовку и удаление дублей в Коммандере.
- Через Прогноз бюджета в интерфейсе: если при запросе частотности система ругается «Ключевая фраза не может состоять только из стоп-слов: союзов, предлогов, частиц». Причем, в отличие от Вордстата, не дает это сделать даже с применением операторов.
- Через Wordstat Яндекса: если отдает 0 показов по слову:
Удивительное в том, что эти варианты отдают разные данные, есть небольшой рассинхрон. Я взял за истину Прогноз бюджета в интерфейсе, так как считаю, что это самый приоритетный продукт. На текущий момент мной найдены 295 имеющих смысл слов:
a about all an and any are as at be but by can do for from have i if in is it my no not of on one or so that the there they this to was we what which will with would you а будем будет будете будешь буду будут будь будьте бы был была были было быть в вам вами вас весь во вот все всё всего всей всем всём всеми всему всех всею всю вся вы да для до его ёго ее её ёё ей ёй ему ёму если ест есть еще ещё ею же за и из или им ими их к как кем ко когда кого ком кому которая которого которое которой котором которому которою которую которые который которым которыми которых кто меня мне мной мог моги могите могла могли могло могу могут мое моё моего моей моем моём моему моею можем может можете можешь мои моим моими моих мой мочь мою моя мы на нам нами нас наш наша наше нашего нашей нашем нашему нашею наши нашим нашими наших нашою нашу не нё него нее неё ней нем нём нему нет нею ним ними них но о об один одна одни одним одними одних одно одного одной одном одному одну он она они оно от по при с сам сама самим самими самих само саму свое своё своего своей своем своём своему своею свои своим своими своих свой свою своя себе себя собой собою та так такая такие таким такими таких такого такое такой таком такому такою такую те тё тебе тебя тем тём теми тех то тобой тобою того той только том тому тот тою ту ты у уже чего чем чему что чтобы эта эти этим этими этих это этого этой этом этому этот эту я
Для Google Ads список стоп-слов может быть шире: каких-то ограничений на это в Ads нет необходимости устанавливать. Фактически Ads может посчитать стоп-словом любое слово, перед которым вы не поставите модификатор широкого соответствия — выбор стоп-слов за вами.
Фактически Ads может посчитать стоп-словом любое слово, перед которым вы не поставите модификатор широкого соответствия — выбор стоп-слов за вами.
Работа с операторами
Работа со стоп-словами подразумевает проставление либо удаление модификаторов перед ними.
Удалять модификаторы может быть нужно в нескольких случаях:
- Запрос в Директе состоит из семи слов без стоп-слов, с модификаторами — система не пропустит.
- Есть риск потерять охват из-за того, что пользователи могут не употреблять стоп-слова в запросе, а эквивалентных фраз без стоп-слов нет.
- Стоп-слова добавлены умышленно, для приукрашивания шаблонных заголовков.
Проставлять модификаторы нужно во всех обратных случаях.
Поскольку подход к стоп-словам в Директе и Ads различный, я сделал в своей надстройке два списка стоп-слов: общий и только для Директа. Каждый из списков можно использовать в макросах: удалить стоп слова, удалить операторы перед ними, проставить операторы «!» или «+». Выбор операторов обусловлен тем, что некоторые стоп-слова склоняются, например, весь, все, всех, всем и т. д.
Выбор операторов обусловлен тем, что некоторые стоп-слова склоняются, например, весь, все, всех, всем и т. д.
Стоп-слова как маркер интента
Стоп-слова можно классифицировать по интенту. Этот лайфхак я обнаружил довольно давно и пользовался им при проработке минус-слов. Он заключается в том, что стоп-слова в сочетании с продвигаемой сущностью (услуга или товар) могут характеризовать запрос пользователя как релевантный или нерелевантный. На пути пользователя (customer journey map) основополагающий параметр, влияющий на взаимодействие с продуктом/услугой — временной промежуток. Утрируя, это до и после. Также пользователь может сомневаться и искать альтернативы — это происходит во время основного поиска.
Исходя из этого, я промаркировал стоп-слова по интенту, чтобы на их основе вычислять нерелевантные запросы.
До
Сюда входит много запросов, связанных с людскими страхами, сомнениями и стремлением их развеять путем обращения к поиску. Это — «теплая» аудитория, как правило, она не отличается высокой конверсией, но при умелой работе может приносить прибыль, так как зачастую с ней предпочитают не возиться и оставляют на потом ваши конкуренты.
Это — «теплая» аудитория, как правило, она не отличается высокой конверсией, но при умелой работе может приносить прибыль, так как зачастую с ней предпочитают не возиться и оставляют на потом ваши конкуренты.
Слова-маркеры:
- перед
- какой/какая/какие… + сущность
- вред
- последствия
- если
- о/об + услуга/товар
- при + услуга в сфере услуг
- ли (больно ли, вредно ли, стоит ли, нужно ли, можно ли, возможно ли, хорошо ли, правда ли…)
- и, разумеется, до + услуга — в сфере услуг
После
Сюда относятся поисковые запросы, обозначающие возникающие у пользователя проблемы уже после покупки товара или услуги. Это могут быть какие-либо дефекты товара или последствия некачественно оказанной услуги, необходимость замены, возврата, ремонта товара или поиск консультационного материала (что делать и как действовать в новых реалиях).
Основные маркеры:
- для + сущность
- под/подо + сущность
- на + сущность (кроме маркеров покупки: цена на товар, скидки на товар)
- в/во + сущность
- к/ко + сущность
- от + сущность
- сущность + не
- сущность + глагол (кроме глаголов-маркеров покупки)
- как (в товарной семантике, кроме фраз с маркерами покупки)
- после + сущность — в сфере услуг
Вместо
Здесь все просто: пользователь или вовсе не наш потенциальный клиент, или вероятность этого около 100%. Он ищет альтернативу нашему продукту, причем необязательно платную. Видов подобных интересов и деятельности много, портреты пользователя могут быть совершенно разные:
Он ищет альтернативу нашему продукту, причем необязательно платную. Видов подобных интересов и деятельности много, портреты пользователя могут быть совершенно разные:
- Студент или специалист. Ищет статьи, рефераты, курсовые, курсы, образовательные заведения и т. д.
- DIY-энтузиаст. Ищет руководства и инструкции, пытается все сделать своими руками.
- Любитель порно.
- Искатель смысла. Интересуется сонниками, гороскопами, приметами, молитвами, гаданиями, приворотами и т. д.
- Геймер.
- Заядлый онлайнер. Его поведение перекликается с некоторыми вышеупомянутыми. Ищет анекдоты, приколы, видяхи, дровишки, софт, обои для рабочего стола и прочие похожие сущности. Эти слова не относятся к стоп-словам, но без их использования проработка нецелевой семантики была бы менее эффективной.
Из стоп-слов, характерных для подобного портрета:
- без + сущность
- вместо + сущность
- зачем + сущность или сущность + зачем
- почему + сущность или сущность + почему
- или + сущность или сущность + ли
- ли + сущность или сущность + ли
И этот список далеко не полный и будет существенно пополняться.
Минус-слова через стоп-слова — подробный алгоритм подбора
Зная интент, который дают фразам стоп-слова, и понимая релевантность самого интента, мы можем автоматизировать сбор нерелевантной семантики. Получится такая в своем роде кластеризация фраз по интенту через стоп-слова.
Как делается:
-
Выбираем нерелевантный интент.
-
Выбираем стоп-слова, характеризующие его.
-
Анализируем порядок следования стоп-слов и продвигаемой сущности.
-
Выбираем из семантического ядра все фразы с зафиксированными последовательностями. На этом этапе есть два варианта:
-
более точный, когда мы берем строго одно слово перед/после стоп-слов;
-
менее точный, но на выходе больше слов: составляем частотный словарь полученной семантики.
-
-
Удаляем очевидно полезные слова: маркеры покупки, эпитеты, геомаркеры, стоп-слова.
-
Profit! На самом деле все равно нужно пройтись по списку глазками.

Неочевидные сложности и их решение
- Непросто определить часть речи (глагол).
- Иногда между стоп-словом и продвигаемой сущностью может быть другое слово (например, эпитет). Если его предварительно не удалить, фраза не будет отфильтрована.
- Услуга может использоваться в запросе в любом склонении, поэтому нужна либо морфология, либо использование услуги во всех склонениях. Немного пожертвовав юзабилити и упростив разработку, я выбрал второй вариант.
Есть алгоритм — есть скрипт! Подбор слов от интента возможен в один клик в SEMTools. Публикация надстройки с реализованным в ней скриптом, делающим все это в один клик, совпадает с моим выступлением на SEMConf 14 сентября 2018 года.
Есть ли где-то полный и окончательный список стоп-слов?
Окончательного списка быть не может, потому что язык меняется. Составленный сегодня словарь стоп‑слов устареет за полгода.
Составленный сегодня словарь стоп‑слов устареет за полгода.
Вместо того, чтобы учить стоп‑слова, советую обратить внимание на категории стоп‑слов, которые не меняются уже два года.
Междометия: ах, ух, ну, уж, ой;
Местоимения: я, мы, мой, вы, ваш;
Вводные конструкции: скажем, допустим, например, в общем, на самом деле;
Обобщения и неточные определения: всего, примерно, около, где‑то, порядка;
Усилители: очень, максимально, абсолютно, предельно, сильно, наиболее, самый;
Оценочные определения и наречия: красивый, дорогой, уютный, роскошный, активный;
Газетные штампы: пески времени, в лучших традициях, царила атмосфера, ударными темпами;
Бытовые штампы: шаг за шагом, мало‑помалу, так или иначе, сплошь и рядом, направо и налево;
Корпоративные и рекламные штампы: завоевать доверие клиентов, решать задачи бизнеса, расширить географию продаж;
Паразиты времени: в настоящее время, в наши дни, в современной России;
Фразы с отглагольными существительными: осуществлять деятельность, производить ремонт, оказывать услуги по ремонту;
Модальность: можете авторизоваться, должны завершить заказ, нужно пройти процедуру.
Лишнее сослагательное наклонение: мне бы хотелось поговорить, было бы здорово созвониться;
Глаголы в страдательном залоге и сказуемые в безличных предложениях: школа построена по заказу мэрии, леса вырубают;
Очевидные сущности: данный сайт, этот документ, меню ниже, на этой странице, форма внизу страницы, нажмите на кнопку, кликните здесь;
Неопределённое: что‑то, какой‑то, где‑то, как‑то, зачем‑то.

Когда я редактирую текст, я не держу в голове сами стоп‑слова, но помню о категориях. Это помогает мне опознавать те стоп‑слова, которые я раньше не встречал.
1 декабря я запустил сервис «Главред», который помогает находить стоп‑слова в тексте и подбирает советы для каждого случая. Алгоритмы и интерфейс «Главреда» несовершенны, но он уже помогает находить все известные мне стоп‑слова и некоторые синтаксические ошибки. На момент публикации этого совета в памяти «Главреда» 1000 стоп‑слов и 5000 ссылок на полезные материалы. Буду рад, если он поможет уважаемым советчикам.
Буду рад, если он поможет уважаемым советчикам.
Список стоп-слов Яндекс.Директа
Стоп-слова в Яндекс.Директе — это служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа. Например, при запросе пользователя “Как и когда купить слона” для показа будут отобраны объявления, у которых в ключевых словах присутствует фраза “Купить слона”. “Как”, “и”, “когда” будут в этом случае являться стоп-словами. Для их принудительного включения во фразу перед ними нужно поставить знак плюс, например «+как +и +когда купить слона».
Не путайте стоп-слова и минус-слова. Минус-слова — это слова, по запросам с которыми рекламное объявление показываться не будет. Минус-слова можно указать на уровне кампании, группы объявлений или ключевой фразы. Например, если мы укажем минус-слово «скачать» на уровне кампании, то ни одно из объявлений кампании не будет показываться по любым поисковым запросам пользователя, содержащим «скачать».
Мне понадобилось определить какие слова Яндекс.Директ считает стоп-словами. Сначала я задумал использовать для этой задачи список всех предлогов, союзов, междометий и местоимений. Но оказалось, что не все слова этих частей речи используются Директом в качестве стоп-слов. Например, союз «со» и предлог «между» к стоп-словам не относятся. Проверить это просто: если в сервис прогноза бюджета добавить предлог «в» и нажать «Посчитать», то сервис сообщит об ошибке:
А попытка рассчитать бюджет для предлога «между» закончится успехом:
Другой способ определить стоп-слова — с помощью Вордстата. Количество показов по фразам «небо земля» и «небо и земля» одинаковое. Это означает, что союз «и» не учитывается при показе объявлений в Директе:
Фраза «между небом и землей» обладает другим количеством показом, значит наличие предлога «между» во фразе уменьшает количество показов:
Вордстат при расчете количества показов для фразы, состоящей только из стоп-слова, возвращает 0. В этом он отличается от сервиса прогноза бюджета (который, напомню, выдает ошибку).
В этом он отличается от сервиса прогноза бюджета (который, напомню, выдает ошибку).
Но Вордстат возвратит тот же ноль и при запросе любого слова, у которого вообще нет показов:
Так что использовать Вордстат для определения стоп-слов не совсем надежно, поэтому я решил использовать сервис прогноза бюджета, он позволяет массово загружать несколько фраз и уведомляет о том какие именно слова не позволяют рассчитать бюджет:
Итак, я взял свой список предлогов, союзов, междометий и местоимений и начал опрашивать все слова в сервисе прогноза бюджета, но внезапно оказалось, что глагол «есть» — это тоже стоп-слово:
Значит список стоп-слов Яндекса не ограничивается одними лишь служебными словами и местоимениями. После этого открытия мне ничего не оставалось кроме как взять список кириллических униграмм (однословников) с OpenCorpora и прогнать их все в сервисе прогноза бюджета.
Следующим открытием было то, что ограничиваться одними лишь кириллическими словами было ошибкой:
Поэтому в список слов для проверки были добавлены англоязычные униграммы. Найти англоязычный корпус оказалось не так легко, но всё же удалось получить 5000 наиболее популярных англоязычных лемм.
Найти англоязычный корпус оказалось не так легко, но всё же удалось получить 5000 наиболее популярных англоязычных лемм.
Итоговый список получился таким:
| a |
| about |
| all |
| am |
| an |
| and |
| any |
| are |
| as |
| at |
| be |
| been |
| but |
| by |
| can |
| could |
| do |
| for |
| from |
| has |
| have |
| i |
| if |
| in |
| is |
| it |
| me |
| my |
| no |
| not |
| of |
| on |
| one |
| or |
| so |
| that |
| the |
| them |
| there |
| they |
| this |
| to |
| was |
| we |
| what |
| which |
| will |
| with |
| would |
| you |
| а |
| будем |
| будет |
| будете |
| будешь |
| буду |
| будут |
| будучи |
| будь |
| будьте |
| бы |
| был |
| была |
| были |
| было |
| быть |
| в |
| вам |
| вами |
| вас |
| весь |
| во |
| вот |
| все |
| всё |
| всего |
| всей |
| всем |
| всём |
| всеми |
| всему |
| всех |
| всею |
| всея |
| всю |
| вся |
| вы |
| да |
| для |
| до |
| его |
| едим |
| едят |
| ее |
| её |
| ей |
| ел |
| ела |
| ем |
| ему |
| емъ |
| если |
| ест |
| есть |
| ешь |
| еще |
| ещё |
| ею |
| же |
| за |
| и |
| из |
| или |
| им |
| ими |
| имъ |
| их |
| к |
| как |
| кем |
| ко |
| когда |
| кого |
| ком |
| кому |
| комья |
| которая |
| которого |
| которое |
| которой |
| котором |
| которому |
| которою |
| которую |
| которые |
| который |
| которым |
| которыми |
| которых |
| кто |
| меня |
| мне |
| мной |
| мною |
| мог |
| моги |
| могите |
| могла |
| могли |
| могло |
| могу |
| могут |
| мое |
| моё |
| моего |
| моей |
| моем |
| моём |
| моему |
| моею |
| можем |
| может |
| можете |
| можешь |
| мои |
| мой |
| моим |
| моими |
| моих |
| мочь |
| мою |
| моя |
| мы |
| на |
| нам |
| нами |
| нас |
| наса |
| наш |
| наша |
| наше |
| нашего |
| нашей |
| нашем |
| нашему |
| нашею |
| наши |
| нашим |
| нашими |
| наших |
| нашу |
| не |
| него |
| нее |
| неё |
| ней |
| нем |
| нём |
| нему |
| нет |
| нею |
| ним |
| ними |
| них |
| но |
| о |
| об |
| один |
| одна |
| одни |
| одним |
| одними |
| одних |
| одно |
| одного |
| одной |
| одном |
| одному |
| одною |
| одну |
| он |
| она |
| оне |
| они |
| оно |
| от |
| по |
| при |
| с |
| сам |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| свое |
| своё |
| своего |
| своей |
| своем |
| своём |
| своему |
| своею |
| свои |
| свой |
| своим |
| своими |
| своих |
| свою |
| своя |
| себе |
| себя |
| собой |
| собою |
| та |
| так |
| такая |
| такие |
| таким |
| такими |
| таких |
| такого |
| такое |
| такой |
| таком |
| такому |
| такою |
| такую |
| те |
| тебе |
| тебя |
| тем |
| теми |
| тех |
| то |
| тобой |
| тобою |
| того |
| той |
| только |
| том |
| томах |
| тому |
| тот |
| тою |
| ту |
| ты |
| у |
| уже |
| чего |
| чем |
| чём |
| чему |
| что |
| чтобы |
| эта |
| эти |
| этим |
| этими |
| этих |
| это |
| этого |
| этой |
| этом |
| этому |
| этот |
| этою |
| эту |
| я |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Список не претендует на полную точность и вполне вероятно, что существуют еще какие-то стоп-слова. Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Немного интересных и необъяснимых аномалий:
- В список стоп-слов Яндекс.Директа входит слово «наса» (предполагаю, что это что-то вроде склонения слова «нас»).
Но Вордстат не считает его стоп-словом:
Количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» будет разным:
Но сервис прогноза бюджета не пропускает обе эти фразы и оставляет первую из них:
А рассчитать бюджет по фразе «что такое наса» сервис вообще не даст, так как она полностью состоит из стоп-слов (чтобы посчитать нужно добавлять плюсы перед словами):
Судя по тому, что количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» всё-таки разное, «наса» не является стоп-словом в том плане, что оно учитывается при показе объявлений, а уведомление об ошибке в сервисе прогноза бюджета — это баг Яндекса.
- Есть странные стоп-слова: «оне», «емъ», «комья», «томах», «имъ».
Но судя по разнице в количестве показов это всё стоп-слова только для валидатора сервиса прогноза бюджета:

Скорее всего, это тоже баг Яндекса.
- Есть некоторые слова, которые в Вордстате имеют количество показов больше 0, но прогноз бюджета Яндекс.Директа говорит о том, что слово является стоп-словом. Например, слово «будете» — это стоп-слово для сервиса прогноза бюджета:
Но не стоп-слово для Вордстата:
Если взять фразы «будете пить колу» и «пить колу», то количество показов у них различается, а значит «будете» всё же учитывается при показе объявлений:
Таких «псевдо-стоп-слов» (которые стоп-словами не являются, но на них ругается валидатор сервиса прогноза бюджета) я обнаружил довольно-таки много:
| будете |
| будучи |
| едим |
| едят |
| ел |
| ела |
| ем |
| емъ |
| ест |
| ешь |
| имъ |
| комья |
| наса |
| оне |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| томах |
| тою |
| этою |
| am |
| could |
| me |
| them |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Фактически, эти слова учитываются при показе объявлений и стоп-словами не являются. Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
UPD: Благодаря Татьяне Михальченко и Олегу Саламаха список пополнился украинскими стоп-словами.
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Что такое стоп слово в тексте и какие они бывают
Стоп-слова в копирайтинге можно сравнить с красным знаком светофора. Что такое стоп-слово? Это фразы, слова, словоформы, не несущие никакой смысловой нагрузки. Их легко можно заменить или выбросить из статьи. Стоп-слова в копирайтинге делают текст малоинформативным и пресным. Поисковые системы подобный материал игнорируют, как итог — шанс оказаться в топ-выдаче невысок. Не менее печальной выглядит картина, когда заказчики просят написать SEO-текст, да еще с использованием большого количества «ключей» на пару тысяч знаков.
Не менее печальной выглядит картина, когда заказчики просят написать SEO-текст, да еще с использованием большого количества «ключей» на пару тысяч знаков.
Как же выглядит список ненужных стоп-слов? К ним относятся:
- наречия и определения;
- штампы;
- паразиты времени;
- модальные фразы;
- очевидные формулировки;
- отглагольные существительные.
Сюда же можно причислить местоимения, междометия и фразы-клише. Интересно, но даже предлоги и цифры некоторые проверочные сервисы относят в эту категорию. В качестве стоп-слов можно привести такие примеры:
- все знают, что;
- ни для кого не секрет;
- кроме того, необходимо подумать;
- следует упомянуть, что;
- давно известно;
- в первую очередь необходимо учитывать;
- в общем-то;
- на мой взгляд и т. д.
Главная проблема стоп-слова в тексте — отсутствие этой самой проблемы. Но многие оптимизаторы и заказчики впадают в крайности. Написать текст без одного или двух этих слов — задача непростая по одной причине: текст с указанными словами становится «живее» и «человечнее». Учитывать правила поисковых роботов нужно, но не стоит забывать — ваш клиент не робот, а человек!
Написать текст без одного или двух этих слов — задача непростая по одной причине: текст с указанными словами становится «живее» и «человечнее». Учитывать правила поисковых роботов нужно, но не стоит забывать — ваш клиент не робот, а человек!
Употреблять ли стоп-слова в тексте?
Поисковые системы вполне благосклонно относятся к наличию тех или иных стоп-слов в тексте. Вопрос в их количестве. Любой нормальный копирайтер, будь он новичок или профи, не сможет обойтись в копирайтинге без стоп-слова. Если они есть в русском или украинском языке, значит для чего-то были придуманы. Наличие стоп-слов в тексте — нормальная практика, ведь без них материал будет выглядеть слабым, пустым и безэмоциональным. Другое дело, если речь идет о технических документах, инструкциях, законодательных статьях и актах. В остальном наличие стоп-слов ничем не навредит статье.
Ведь что такое стоп-слово? Это некий баланс между словами, которые можно оставить, а какие-то следует удалить без нарушения логики и связующей мысли. Распространенная ошибка — желание полностью убрать местоимения в тексте. В итоге мы получаем сухой безжизненный текст, написанный как для телеграммы.
Распространенная ошибка — желание полностью убрать местоимения в тексте. В итоге мы получаем сухой безжизненный текст, написанный как для телеграммы.
Золотая середина — где она?
Когда заказчик или оптимизатор составляет техническое задание копирайтеру для написания СЕО-текста, никто не обращает внимание на количество ключевых слов, необходимых для употребления. Т. е. внести с десяток «ключей» в материал из 2000 символов — нормально, а вот прописать парочку стоп-слов — смерти подобно. Во всем должна быть норма, и в стоп-словах тоже.
SEO-специалисты считают, что в тексте может присутствовать не больше 30% стоп-слов от их общего количества. А чтобы понять это, поможет специальная проверка на стоп-слова. Но после нее не нужно сразу удалять все лишние фразы, иначе велик риск получить не просто сжатый текст, а совершенную бессмыслицу.
Без прилагательных текст становится скучным и неинтересным, а без местоимений появляются нестыковки в предложениях. Стоп-слова и полезны, и вредны одновременно. Но задача копирайтера в том и состоит, чтобы найти баланс между ними. Не нужно доходить до фанатизма и удалять все неугодные слова, фразы, предлоги, местоимения и наречия. Если видите, что из текста можно убрать шумовое слово — удаляйте без сожаления. А если понимаете, что оно приукрашает, добавляет эмоций, то пусть остается.
Но задача копирайтера в том и состоит, чтобы найти баланс между ними. Не нужно доходить до фанатизма и удалять все неугодные слова, фразы, предлоги, местоимения и наречия. Если видите, что из текста можно убрать шумовое слово — удаляйте без сожаления. А если понимаете, что оно приукрашает, добавляет эмоций, то пусть остается.
Надеемся, что статья была полезной и интересной, и мы смогли ответить на вопрос, что такое стоп-слово и как с ним бороться.
Что такое стоп-слова. Как удалить стоп-слова.
Все о стоп-словах при обработке естественного языка вместе с практическими примерами.
Фото Хосе Арагонеса на Unsplash
В этой статье мы узнаем все о стоп-словах для обработки естественного языка.
В вычислениях стоп-слова — это слова, которые отфильтровываются до или после обработки данных естественного языка (текста). Хотя «стоп-слова» обычно относятся к наиболее употребительным словам в языке, инструменты обработки естественного языка не используют единый универсальный список стоп-слов.
«стоп-слова» обычно относятся к наиболее распространенным словам в языке. Не существует универсального списка «стоп-слов», который используется всеми инструментами НЛП совместно.
В этой статье мы рассмотрим следующие темы:
- Что такое стоп-слова
- Когда удалять стоп-слова
- Плюсы и минусы
- Как удалить стоп-слова в Python с помощью:
* Библиотека NLTK
* SpaCy Библиотека
* Библиотека Gensim
* Пользовательские стоп-слова
Что такое стоп-слова?
Стоп-слова — это слова на любом языке, которые не добавляют особого смысла предложению.Их можно спокойно игнорировать, не жертвуя смыслом предложения. Для некоторых поисковых систем это одни из самых распространенных коротких служебных слов, например, is, at, which и on. В этом случае стоп-слова могут вызвать проблемы при поиске фраз, которые их включают, особенно в таких именах, как «Кто» или «Возьми это».
Когда удалять стоп-слова?
Если у нас есть задача классификации текста или анализа тональности, то мы должны удалить стоп-слова, поскольку они не предоставляют никакой информации для нашей модели, т.е.e не допускает попадания нежелательных слов в наш корпус, , но если у нас есть задача языкового перевода, то полезны стоп-слова, так как их нужно переводить вместе с другими словами.
Не существует жесткого правила, когда следует удалять стоп-слова. Но я бы предложил удалить стоп-слова, если наша задача — это классификация языков, фильтрация спама, создание титров, автоматическое создание тегов, анализ тональности или что-то, что связано с классификацией текста.
С другой стороны, если наша задача — машинный перевод, вопросы с ответами на вопросы, обобщение текста, языковое моделирование, лучше не удалять стоп-слова, поскольку они являются важной частью этих приложений.
Плюсы и минусы:
Первое, что мы задаем себе, это каковы плюсы и минусы любой выполняемой нами задачи. Давайте посмотрим на некоторые плюсы и минусы удаления стоп-слов в НЛП.
Давайте посмотрим на некоторые плюсы и минусы удаления стоп-слов в НЛП.
pro:
* Стоп-слова часто удаляются из текста перед обучением моделей глубокого обучения и машинного обучения, поскольку стоп-слова встречаются в изобилии, поэтому практически не предоставляются уникальные данные, которые можно использовать для классификации или кластеризации.
* При удалении игнорируемых слов размер набора данных уменьшается, и время обучения модели также уменьшается без значительного влияния на точность модели.
* Удаление стоп-слов потенциально может помочь в повышении производительности, так как осталось меньше и только значимых токенов. Таким образом, точность классификации может быть улучшена.
cons:
Неправильный выбор и удаление стоп-слов может изменить смысл нашего текста. Поэтому мы должны быть осторожны при выборе стоп-слов.
Пример: «Этот фильм нехороший».
Если мы удаляем (не) на этапе предварительной обработки, предложение (этот фильм хороший) указывает, что оно положительное, что неправильно интерпретируется.
Как удалить стоп-слова в Python с помощью:
Удалить стоп-слова с помощью библиотек Python довольно просто и можно сделать разными способами. Пройдем по порядку.
Использование библиотеки NLTK:
Набор инструментов для естественного языка, или более широко NLTK, представляет собой набор библиотек и программ для символьной и статистической обработки естественного языка для английского языка, написанных на языке программирования Python. Он содержит библиотеки обработки текста для токенизации, синтаксического анализа, классификации, выделения корней, тегов и семантического анализа.
Давайте посмотрим, как мы можем удалить стоп-слова с помощью библиотеки Python NLTK.
с использованием NLTK для удаления вектора с маркерами стоп-слов со стоп-словами и без них
Мы можем заметить, что такие слова, как ‘this’, ‘is’, ‘will’, ‘do’, ‘more’, ‘such’, удаляются из токенизированного вектора как они являются частью набора стоп-слов НЛТК. Мы можем просмотреть все такие стоп-слова для английского языка, напечатав стоп-слова.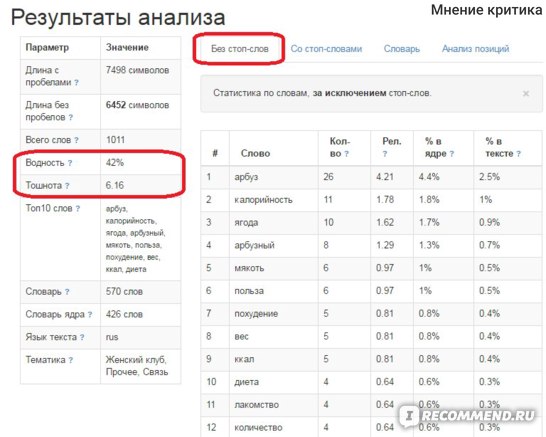
Список из 179 стоп-слов NLTK
Использование библиотеки SpaCy:
spaCy — это программная библиотека с открытым исходным кодом для расширенной обработки естественного языка.spaCy разработан специально для production и помогает создавать приложения, обрабатывающие и «понимающие» большие объемы текста. Его можно использовать для построения систем извлечения информации или понимания естественного языка или для предварительной обработки текста для глубокого обучения.
Перед тем, как продолжить, убедитесь, что вы установили spaCy и его английскую языковую модель. Для этого вы можете использовать следующие команды.
$ pip install -U spacy
$ python -m spacy загрузить en_core_web_sm
Давайте посмотрим, как мы можем удалить стоп-слова с помощью этой библиотеки.
с использованием spaCy для удаления вектора с токенизированными стоп-словами со стоп-словами и без них.
Выходные данные размеченных векторов NLTK и spaCy без стоп-слов одинаковы.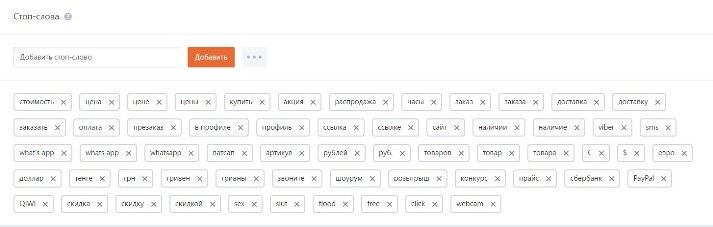 Но у spaCy был больший набор стоп-слов (326), чем у NLTK (179).
Но у spaCy был больший набор стоп-слов (326), чем у NLTK (179).
Список из 326 стоп-слов spaCy
Использование библиотеки Gensim:
Gensim — это библиотека с открытым исходным кодом для неконтролируемого моделирования тем и обработки естественного языка с использованием современного статистического машинного обучения. Gensim разработан для обработки больших текстовых коллекций с использованием потоковых данных и инкрементных онлайн-алгоритмов, что отличает его от большинства других программных пакетов машинного обучения, ориентированных только на обработку в памяти.Для получения дополнительной информации ознакомьтесь с документацией Gensim.
Используя Gensim, мы можем напрямую вызвать remove_stopwords () , который является методом gensim.parsing.preprocessing. Затем нам нужно передать наше предложение, из которого вы хотите удалить стоп-слова, методу remove_stopwords (), который возвращает текстовую строку без стоп-слов. Затем мы можем токенизировать возвращенные предложения.
Затем мы можем токенизировать возвращенные предложения.
Давайте посмотрим, как мы можем удалить стоп-слова с помощью библиотеки Gensim.
с использованием gensim для удаления вектора, отмеченного стоп-словами, со стоп-словами и без них
Мы можем заметить, что выходные данные NLTK, spaCy и gensim одинаковы, даже если каждый из них имеет другой набор стоп-слов по умолчанию.Давайте посмотрим на 337 стоп-слов Gensim.
Список из 337 стоп-слов gensim
Пользовательские стоп-слова:
Если вы чувствуете, что стоп-слова по умолчанию в любом языковом средстве Python NLP слишком много и вызывают потерю информации, или слишком мало, чтобы удалить все ненужные corpus, то мы можем выбрать собственный список стоп-слов.
Для этого вы можете просто получить стоп-слова по умолчанию в список и добавить или удалить требуемые слова из списка в соответствии с требованиями.
настраиваемый список стоп-слов
Если нам нужно очень мало стоп-слов, мы можем определить наш собственный список стоп-слов и использовать его для удаления соответствующих слов из нашего корпуса.
Пример:
my_stopword_list = ['the,' is ',' as ',' a ',' are ',' in ',' this ',' that ']
Заключение:
В этой статье мы узнали, что такое стоп-слова, плюсы и минусы удаления стоп-слов. В этой статье мы также видели различные библиотеки, которые можно использовать для удаления стоп-слов из строки Python.Вы также узнали, как добавлять или удалять стоп-слова из списков стоп-слов по умолчанию, которые предоставлены различными библиотеками для создания пользовательских списков стоп-слов.
Полный код записной книжки Jupyter доступен в моем GitHub .
Удачного обучения!
Удаление стоп-слов с помощью NLTK в Python
Процесс преобразования данных во что-то, что может понять компьютер, называется предварительной обработкой . Одна из основных форм предварительной обработки — отфильтровывать бесполезные данные. При обработке естественного языка бесполезные слова (данные) называются стоп-словами.
Что такое стоп-слова?
Стоп-слова: Стоп-слово — это часто используемое слово (например, «the», «a», «an», «in»), которое поисковая машина запрограммирована игнорировать, как при индексировании записей для поиска, так и при получении их в результате поискового запроса.
Мы бы не хотели, чтобы эти слова занимали место в нашей базе данных или драгоценное время обработки.Для этого мы можем легко удалить их, сохранив список слов, которые вы считаете стоп-словами. NLTK (Natural Language Toolkit) в python имеет список стоп-слов, хранящихся на 16 различных языках. Вы можете найти их в каталоге nltk_data. home / pratima / nltk_data / corpora / stopwords — это адрес каталога. (Не забудьте изменить имя домашнего каталога)
Чтобы проверить список игнорируемых слов, вы можете ввести следующие команды в оболочке python.
импорт НЛТК из нлтк.корпус импорта стоп-слов print (stopwords.
 words ('английский'))
words ('английский')) {‘мы’, ‘ее’, ‘между’, ‘ты’, ‘но’, ‘снова’, ‘там’, ‘примерно’, ‘однажды’, ‘во время’, ‘вне’, ‘очень’, ‘имеющий’, ‘с’, ‘они’, ‘владеть’, ‘ан’, ‘быть’, ‘некоторые’, ‘для’, ‘делать’, ‘свой’, ‘твой’, ‘такой’, ‘в ‘,’ из ‘,’ большинство ‘,’ сам ‘,’ другой ‘,’ выкл ‘,’ есть ‘,’ s ‘,’ am ‘,’ or ‘,’ who ‘,’ as ‘,’ from ‘, ‘он’, ‘каждый’, ‘тот’, ‘себя’, ‘до’, ‘ниже’, ‘есть’, ‘мы’, ‘эти’, ‘ваш’, ‘его’, ‘через’, ‘не ‘,’ ни ‘,’ я ‘,’ были ‘,’ она ‘,’ больше ‘,’ сам ‘,’ это ‘,’ вниз ‘,’ должен ‘,’ наш ‘,’ их ‘,’ пока ‘, ‘выше’, ‘оба’, ‘вверх’, ‘к’, ‘наш’, ‘имел’, ‘она’, ‘все’, ‘нет’, ‘когда’, ‘в’, ‘любой’, ‘до ‘,’ они ‘,’ такой же ‘,’ и ‘,’ был ‘,’ иметь ‘,’ в ‘,’ будет ‘,’ на ‘,’ делает ‘,’ сами ‘,’ то ‘,’ тот ‘, ‘потому что’, ‘что’, ‘сверх’, ‘почему’, ‘так’, ‘могу’, ‘сделал’, ‘не’, ‘сейчас’, ‘под’, ‘он’, ‘ты’, ‘сама ‘,’ имеет ‘,’ просто ‘,’ где ‘,’ тоже ‘,’ только ‘,’ я ‘,’ который ‘,’ те ‘,’ я ‘,’ после ‘,’ несколько ‘,’ кого ‘, ‘т’, ‘быть’, ‘если’, ‘их’, ‘мой’, ‘против’, ‘а’, ‘по’, ‘делаю’, ‘это’, ‘как’, ‘дальше’, ‘было ‘, ‘здесь’ , ‘Than’}
Примечание: Вы даже можете изменить список, добавив слова на ваш выбор на английском языке. текст. файл в каталоге игнорируемых слов.
текст. файл в каталоге игнорируемых слов.
Удаление стоп-слов с помощью НЛТК
Следующая программа удаляет стоп-слова из фрагмента текста:
|
 добавить (w)
добавить (w) Выход:
['Это', 'есть', 'a', 'образец', 'предложение', ',', 'показ', 'off', 'the', 'stop', 'слова', 'фильтрация', '.'] ['Это', 'образец', 'предложение', ',', 'показ', 'стоп', "слова", "фильтрация", "."]
Выполнение операций со стоп-словами в файле
В приведенном ниже коде текст.txt — это исходный входной файл, в котором должны быть удалены стоп-слова. filtertext.txt — выходной файл. Это можно сделать с помощью следующего кода:
|
 слова (
слова ( Таким образом мы делаем наш обработанный контент более эффективным, удаляя слова, которые не влияют на какие-либо будущие операции.
Автор статьи: Pratima Upadhyay .Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на [email protected]. Смотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогайте другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
Что такое стоп-слова? | Кавита Ганесан, доктор философии
При работе с приложениями интеллектуального анализа текста мы часто слышим термин «стоп-слова», «список стоп-слов» или даже «стоп-список».Стоп-слова — это в основном набор часто используемых слов на любом языке, а не только на английском.
Причина, по которой стоп-слова важны для многих приложений, заключается в том, что, если мы удалим слова, которые очень часто используются в данном языке, мы можем вместо этого сосредоточиться на важных словах. Например, в контексте поисковой системы, если ваш поисковый запрос — «как разрабатывать приложения для поиска информации», , если поисковая система пытается найти веб-страницы, содержащие термины «как», «чтобы» «разрабатывать» , «Информация», «поиск», «приложения» поисковая система найдет гораздо больше страниц, содержащих термины «как», «к», чем страниц, содержащих информацию о разработке приложений для поиска информации, потому что термины «как» и «to» так часто используются в английском языке.Если мы не будем принимать во внимание эти два термина, поисковая машина может фактически сосредоточиться на поиске страниц, содержащих ключевые слова: «разработка», «информация», «поиск», «приложения», которые будут отображать страницы, которые действительно представляют интерес. Это всего лишь базовая интуиция для использования стоп-слов.
Например, в контексте поисковой системы, если ваш поисковый запрос — «как разрабатывать приложения для поиска информации», , если поисковая система пытается найти веб-страницы, содержащие термины «как», «чтобы» «разрабатывать» , «Информация», «поиск», «приложения» поисковая система найдет гораздо больше страниц, содержащих термины «как», «к», чем страниц, содержащих информацию о разработке приложений для поиска информации, потому что термины «как» и «to» так часто используются в английском языке.Если мы не будем принимать во внимание эти два термина, поисковая машина может фактически сосредоточиться на поиске страниц, содержащих ключевые слова: «разработка», «информация», «поиск», «приложения», которые будут отображать страницы, которые действительно представляют интерес. Это всего лишь базовая интуиция для использования стоп-слов.
Стоп-слова могут использоваться в целом ряде задач, и вот некоторые из них:
- Машинное обучение с учителем — удаление стоп-слов из пространства функций
- Кластеризация — удаление стоп-слов перед созданием кластеров
- Получение информации — предотвращение стоп-слова от индексации
- Обобщение текста — исключение стоп-слов из вклада в оценку суммирования и удаление стоп-слов при вычислении оценок ROUGE
Типы стоп-слов
Обычно считается, что стоп-слова представляют собой «единый набор слов». Это действительно может означать разные вещи для разных приложений. Например, в некоторых приложениях удаление всех стоп-слов прямо от определителей (например, a, an) до предлогов (например, выше, поперек, перед) и некоторых прилагательных (например, хороший, красивый) может быть подходящим списком стоп-слов. Однако для некоторых приложений это может быть вредным. Например, при анализе настроений удаление таких прилагательных, как «хороший» и «хороший», а также отрицаний, таких как «не», может сбить алгоритмы с их рельсов. В таких случаях можно выбрать использование минимального стоп-списка, состоящего только из определителей или определителей с предлогами или просто координирующих союзов, в зависимости от потребностей приложения.Примеры минимальных списков стоп-слов, которые вы можете использовать:
Это действительно может означать разные вещи для разных приложений. Например, в некоторых приложениях удаление всех стоп-слов прямо от определителей (например, a, an) до предлогов (например, выше, поперек, перед) и некоторых прилагательных (например, хороший, красивый) может быть подходящим списком стоп-слов. Однако для некоторых приложений это может быть вредным. Например, при анализе настроений удаление таких прилагательных, как «хороший» и «хороший», а также отрицаний, таких как «не», может сбить алгоритмы с их рельсов. В таких случаях можно выбрать использование минимального стоп-списка, состоящего только из определителей или определителей с предлогами или просто координирующих союзов, в зависимости от потребностей приложения.Примеры минимальных списков стоп-слов, которые вы можете использовать:
- Определители — Определители обычно отмечают существительные, где за определителем обычно следует существительное
Примеры: the, a, an, another - Координационные союзы — Координирующие союзы соединяют слова, фразы и предложения
примеры: for, an, nor, but, or, still, so - Предлоги — Предлоги выражают временные или пространственные отношения
примеров: in, under, to, before
В некоторых случаях, специфичных для предметной области, например в клинических текстах, нам может потребоваться совершенно другой набор стоп-слов. Например, такие термины, как «mcg», «dr» и «пациент», могут иметь меньшую силу при создании интеллектуальных приложений по сравнению с такими терминами, как «сердце», «отказ» и «диабет». В таких случаях мы также можем создавать стоп-слова для конкретных областей, а не использовать опубликованный список стоп-слов.
Например, такие термины, как «mcg», «dr» и «пациент», могут иметь меньшую силу при создании интеллектуальных приложений по сравнению с такими терминами, как «сердце», «отказ» и «диабет». В таких случаях мы также можем создавать стоп-слова для конкретных областей, а не использовать опубликованный список стоп-слов.
А как насчет стоп-фраз?
Стоп-фразы похожи на стоп-слова, только вместо удаления отдельных слов вы исключаете фразы. Например, если фраза «хороший элемент» очень часто встречается в вашем тексте, но имеет очень низкую способность распознавания или приводит к нежелательному поведению в ваших результатах, можно добавить такие фразы в качестве стоп-фраз.Конечно, можно строить «стоп-фразы» так же, как вы составляете стоп-слова. Например, вы можете рассматривать фразы, которые очень редко встречаются в вашем корпусе, как стоп-фразы. Точно так же вы можете рассматривать фразы, которые встречаются почти в каждом документе в вашем корпусе, как стоп-фразу.
Опубликованные списки стоп-слов
Если вы хотите использовать опубликованные списки стоп-слов, вот несколько, которые вы можете использовать:
- Список стоп-слов Snowball — этот список стоп-слов публикуется с Snowball Stemmer
- Terrier Список стоп-слов — это довольно полный список стоп-слов, опубликованный с пакетом Terrier.
- Минимальный список стоп-слов — это список стоп-слов, который я составил, состоящий из определителей, координирующих союзов и предлогов
- Создайте свой собственный список стоп-слов — в этой статье в основном описывается автоматический метод создания списка стоп-слов для ваших конкретных данных набор (например, твиты, клинические тексты и т. д.)
Создание списков стоп-слов для конкретных доменов
Хотя опубликованный набор стоп-слов довольно просто использовать, во многих случаях использование таких стоп-слов совершенно недостаточно для определенных приложений.Например, в клинических текстах такие термины, как «мкг» «доктор». и «пациент» встречаются почти в каждом документе, с которым вы сталкиваетесь. Таким образом, эти термины можно рассматривать как потенциальные стоп-слова для интеллектуального анализа и поиска клинических текстов. Точно так же для твитов такие термины, как «#», «RT», «@username» могут потенциально рассматриваться как стоп-слова. Список стоп-слов для общеязыкового языка, как правило, НЕ охватывает такие специфические термины. Вот написанная мной статья, в которой рассказывается о том, как создавать списки стоп-слов для конкретных доменов.
Список стоп-слов для общеязыкового языка, как правило, НЕ охватывает такие специфические термины. Вот написанная мной статья, в которой рассказывается о том, как создавать списки стоп-слов для конкретных доменов.
Связанные
Интернет-руководство по SEO: стоп-слова Google
Большинство поисковых систем не рассматривают чрезвычайно распространенные слова, чтобы ускорить результаты поиска или сэкономить место на диске. Эти отфильтрованные слова известны как «стоп-слова» .
Ниже приведен полный список слов, игнорируемых поисковыми системами:
а и | следовательно | см. их |
 е.
е. 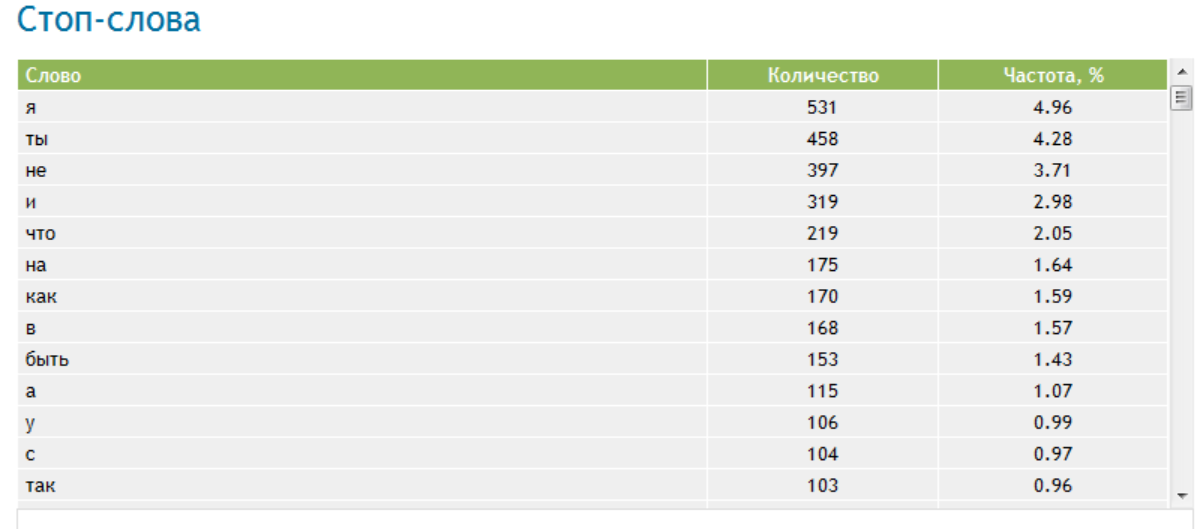
Список английских стоп-слов NLTK · GitHub
Список английских стоп-слов NLTK · GitHub
Мгновенно делитесь кодом, заметками и фрагментами.
| и | |
| мне | |
| мой | |
| сам | |
| ср | |
| наш | |
| наши | |
| себя | |
| вы | |
| ваш | |
| ваш | |
| себя | |
| сами | |
| он | |
| ему | |
| его | |
| сам | |
| она | |
| ее | |
| ее | |
| сама | |
| это | |
| это | |
| сам | |
| они | |
| их | |
| их | |
| их | |
| себя | |
| какой | |
| , который | |
| кто | |
| ком | |
| это | |
| , что | |
| эти | |
| те | |
| утра | |
| это | |
| это | |
| было | |
| были | |
| быть | |
| было | |
| является | |
| есть | |
| имеет | |
| было | |
| , имеющий | |
| до | |
| делает | |
| сделал | |
| делаю | |
| a | |
| и | |
| и | |
| но | |
| если | |
| или | |
| потому что | |
| как | |
| С | по |
| , а | |
| из | |
| в | |
| по | |
| для | |
| с | |
| около | |
| против | |
| между | |
| в | |
| С | по |
| в течение | |
| до | |
| после | |
| выше | |
| ниже | |
| С | по |
| из | |
| вверх | |
| вниз | |
| в | |
| из | |
| по | |
| от | |
| более | |
| под | |
| снова | |
| далее | |
| , затем | |
| один раз | |
| здесь | |
| там | |
| когда | |
| где | |
| почему | |
| как | |
| все | |
| любой | |
| оба | |
| штука | |
| несколько | |
| подробнее | |
| самое | |
| другое | |
| какой-то | |
| такой | |
| № | |
| или | |
| не | |
| Только | |
| собственный | |
| то же | |
| так | |
| чем | |
| тоже | |
| очень | |
| с | |
| т | |
| банка | |
| будет | |
| всего | |
| дон | |
| должен | |
| сейчас |
Вы не можете выполнить это действие в настоящее время. Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.
Что такое стоп-слова? | Опиноз Аналитика
Стоп-слова — это набор часто используемых слов в языке. Примеры стоп-слов на английском языке: «a», «the», «is», «are» и т. Д. Стоп-слова обычно используются в интеллектуальном анализе текста и обработке естественного языка (NLP) для исключения слов, которые так часто используются, что они несут очень мало полезной информации.
Например, в контексте поисковой системы, если ваш поисковый запрос — «какое стоп-слово?» , вы хотите, чтобы поисковая система фокусировалась на обнаружении документов, которые говорят о стоп-слове , поверх документов, которые говорят о , что такое .
Это можно сделать, поддерживая список стоп-слов (который можно настраивать вручную или автоматически) и предотвращая анализ всех слов из списка стоп-слов. В этом примере слова
В этом примере слова , которые являются , можно исключить, оставив только слова: стоп-слово .Это гарантирует, что тематически релевантные документы будут иметь высокий рейтинг в результатах поиска.
Стоп-слова для контекста
Хотя стоп-слова обычно используются для удаления слов с низкой информацией, стоп-слова также могут стать мощным средством добавления контекста. Например, в запросе «что такое стоп-слово?» , , если вы знаете, что это на самом деле вопрос что такое , а не вопрос как на , вы можете дополнительно уточнить результаты, показываемые пользователям.Один из способов узнать это — просто взглянуть на не тематические слова. Если у вас есть эта контекстная информация, вместо того, чтобы оценивать «Как использовать стоп-слова?» в самом верху результатов поиска вы можете научить свои алгоритмы ранжировать документы, связанные с вопросом «Что такое стоп-слова?» намного выше.
Где найти список стоп-слов?
Существуют установленные списки стоп-слов, которые можно легко подключить и использовать. Некоторые из списков стоп-слов являются результатом исследовательской работы НЛП, а некоторые просто вручную составлены разными людьми.Вот несколько слов на разных языках, которые вы можете попробовать:
Некоторые из списков стоп-слов являются результатом исследовательской работы НЛП, а некоторые просто вручную составлены разными людьми.Вот несколько слов на разных языках, которые вы можете попробовать:
Списки стоп-слов для конкретного домена
Хотя использовать опубликованный набор стоп-слов довольно просто, во многих случаях таких стоп-слов недостаточно. Например, в клинических текстах такие термины, как «мкг» «доктор». и «пациент» встречаются почти в каждом документе, с которым вы сталкиваетесь. Таким образом, эти термины можно рассматривать как потенциальные стоп-слова для интеллектуального анализа и поиска клинических текстов.
Точно так же для твитов такие термины, как «#», «RT», «@username» могут потенциально рассматриваться как стоп-слова.К сожалению, стоп-слова для конкретных языков не охватывают термины, относящиеся к предметной области. Хорошая новость заключается в том, что вы можете легко создать свой собственный список стоп-слов для конкретной предметной области. В этой статье рассказывается о нескольких идеях о том, как создавать такие списки.
В этой статье рассказывается о нескольких идеях о том, как создавать такие списки.
Связанные
75 стоп-слов, часто встречающихся в SEO, и когда их следует использовать
От заголовков блогов до заголовков URL-адресов, вы можете не осознавать, как часто вы используете стоп-слова для SEO.Но, честно говоря, если Google не обращает на них особого внимания, зачем вам это делать?
Исследования показывают, что 25% сообщений в блогах состоят из стоп-слов. Однако эти слова практически не имеют отношения к теме поста. Это слова, которые помогают составлять предложения и объединять идеи, и они не оказывают большого влияния на результаты поиска Google.
Но чрезмерное использование стоп-слов может повлиять на ваш бренд в долгосрочной перспективе. Они затрудняют обработку контента поисковыми системами, что может негативно повлиять на то, как они индексируют ваши страницы.
В этом посте мы подробно расскажем, что такое стоп-слова для SEO, как они могут повредить или помочь вашему присутствию в Интернете и какие слова считаются стоп-словами Google и другими поисковыми системами.
Что такое стоп-слова в SEO?
Мы постоянно используем стоп-слова, вне зависимости от того, в сети ли мы или в повседневной жизни. Это статьи, предлоги и фразы, которые объединяют ключевые слова и помогают нам формировать полные, связные предложения.
Общие слова, такие как its, an, the, for и that, считаются стоп-словами.Хотя они важны для устного общения, стоп-слова обычно не имеют большого значения для SEO и часто игнорируются поисковыми системами.
Давайте рассмотрим некоторые из наиболее распространенных стоп-слов в разделе ниже.
Общие стоп-слова SEO
Самыми распространенными стоп-словами для SEO являются местоимения, артикли, предлоги и союзы. Сюда входят такие слова, как a, an, the и, it, for, or, но, in, my, your, our и their.
Когда люди ищут что-то в Интернете, поисковые системы, такие как Google, пропускают эти слова в своих результатах, потому что они не связаны с ключевыми словами в поиске.Таким образом, вместо того, чтобы искать контент, связанный с этими словами, Google полностью удаляет их и расставляет приоритеты по ключевым словам.
Итак, в следующий раз, когда вы попытаетесь подсчитать количество слов при написании сообщения в блоге, попробуйте заполнить это открытое пространство ключевыми словами, а не заполнителем, который не улучшит ваше SEO.
Хотя было бы здорово загружать ваш контент только значимыми ключевыми словами, на самом деле стоп-слова необходимы для каждого типа копии. В конце концов, даже если вы занимаетесь высоким рейтингом в Google, это не будет иметь большого значения, если ваш контент непонятен или не находит отклика у вашей аудитории.
Полезны ли стоп-слова для SEO?
Есть время и место для стоп-слов SEO. Прежде всего, стоп-слова помогают читателю понять содержание. Чтение заголовков и подзаголовков без стоп-слов может сбивать с толку.
Вы также можете найти случаи, когда стоп-слова помогают различать две темы. Например, вы можете выполнить поиск по запросу «фламинго» и увидеть информацию о красивых ярко-розовых птицах. Добавьте «the» впереди, и вы будете перенаправлены на YouTube, чтобы послушать группу The Flamingos. В данном случае это крошечное стоп-слово из трех букв имеет огромное значение.
В следующем разделе давайте рассмотрим другие случаи, когда вам следует обращать внимание на стоп-слова, чтобы оптимизировать поисковый рейтинг вашего контента.
Удаление стоп-слов
Следует ли удалять стоп-слова из всего своего контента?
Как и все остальное, это зависит от того, как вы их используете. Если ваши заголовки, заголовки, заголовки URL-адресов и ключевые слова имеют смысл без них, то их можно удалить.
Стоп-слов для SEO в заголовках
Если ваши заголовки не имеют смысла, когда вы вынимаете эти артикли или предлоги, то лучше их оставить. В конце концов, вы хотите, чтобы ваша аудитория действительно щелкала и читала ваш контент. Если наиболее важные части, включая заголовок, не имеют смысла, веб-сайт может показаться непрофессиональным или даже спамерским.
Обычно имеет смысл оставлять стоп-слова в заголовках и заголовках, так как это элементы навигации для пользователей, перемещающихся по вашему контенту. Просто имейте в виду, что оптимальное количество символов для заголовков составляет 50-60 символов, поскольку поисковые системы отсекают более длинные заголовки, которые могут упустить важную информацию для посетителя. Если в заголовке есть длинные стоп-слова, подумайте о том, чтобы переписать их, чтобы сбалансировать краткость и ясность.
Просто имейте в виду, что оптимальное количество символов для заголовков составляет 50-60 символов, поскольку поисковые системы отсекают более длинные заголовки, которые могут упустить важную информацию для посетителя. Если в заголовке есть длинные стоп-слова, подумайте о том, чтобы переписать их, чтобы сбалансировать краткость и ясность.
стоп-слов в URL-ярлыках
Когда дело доходит до URL-ярлыков, стоп-слова обычно не имеют большого значения для SEO. Однако они актуальны, если делают ваш URL-адрес особенно длинным. Google ранжирует URL-адреса на основе их длины, и более длинные URL-адреса обычно имеют более низкий рейтинг, чем более короткие, как показано в таблице ниже.
Источник изображения
стоп-слов как ключевых слов
Как мы уже говорили в предыдущем разделе, бывают случаи, когда стоп-слова имеют решающее значение для составления ключевых слов, потому что они отличают собственное существительное от чего-то еще. Например, если вы искали «Джетс Нью-Йорк», вы, вероятно, получили бы список рейсов, прибывающих и вылетающих из Нью-Йорка. Но если вы введете запрос «Нью-Йорк Джетс», то вместо этого получите информацию о профессиональной футбольной команде.
Но если вы введете запрос «Нью-Йорк Джетс», то вместо этого получите информацию о профессиональной футбольной команде.
Теперь, когда мы знакомы с тем, что такое стоп-слова и когда их следует использовать, давайте рассмотрим более широкий список стоп-слов, о которых следует помнить при создании и оптимизации контента.
75 стоп-слов в SEO
Есть еще много стоп-слов, но вот список некоторых из наиболее распространенных стоп-слов, о которых следует помнить при создании контента в Интернете.
А Около Фактически Почти Также Хотя Всегда Am Ан и Любая Аре Как по адресу Be стал Стать Но по Банка Может Сделал До Ли каждый Либо Остальное для из Было Имеет Иметь Отсюда Как Я Если В IS IT ЕГО | ПРОСТО МАЯ МОЖЕТ БЫТЬ Я Могущество Шахта Должен Мой Шахта Должен Мой Ни то, ни другое Нор Не из О Хорошо Когда Где В то время как Где угодно Каждый раз Ли Какой в то время как Кто Кого Кто угодно Чей Почему Воля с В пределах Без Будет Есть Еще Вы Ваш |
Использование стоп-слов SEO
стоп-слов для SEO важны, если вы хотите создать сильную стратегию SEO и получить высокий рейтинг в поисковых системах, таких как Google.
Добавить комментарий