
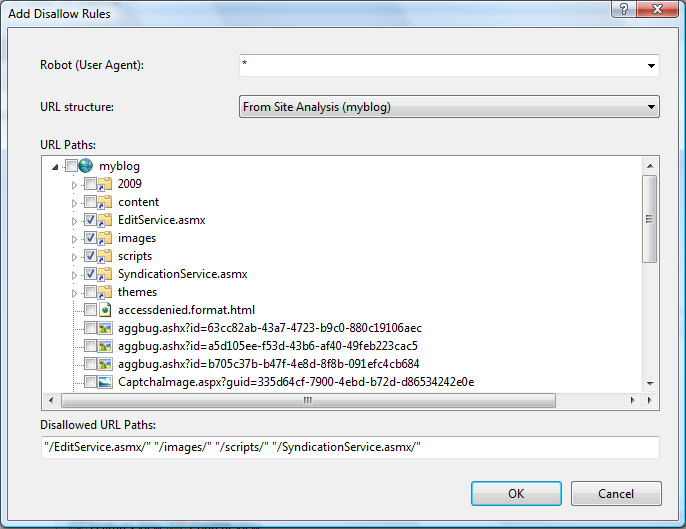
Как запретить индексацию страницы с помощью robots.txt?
От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
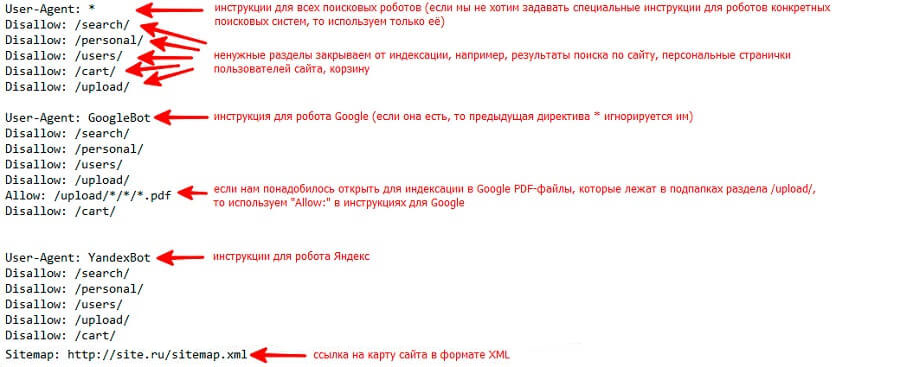
User-agent: *
Disallow: /kontakty/
Disallow: /about/
Disallow: /uslugi/
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/ |
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Естественно, указываем настоящие url-адреса. Если же вам необходимо не индексировать страничку //blog.ru/about-me, то в robots.txt нужно прописать так:
Если же вам необходимо не индексировать страничку //blog.ru/about-me, то в robots.txt нужно прописать так:
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
<meta name = «robots» content = «noindex,nofollow»>
<meta name = «robots» content = «noindex,nofollow»> |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.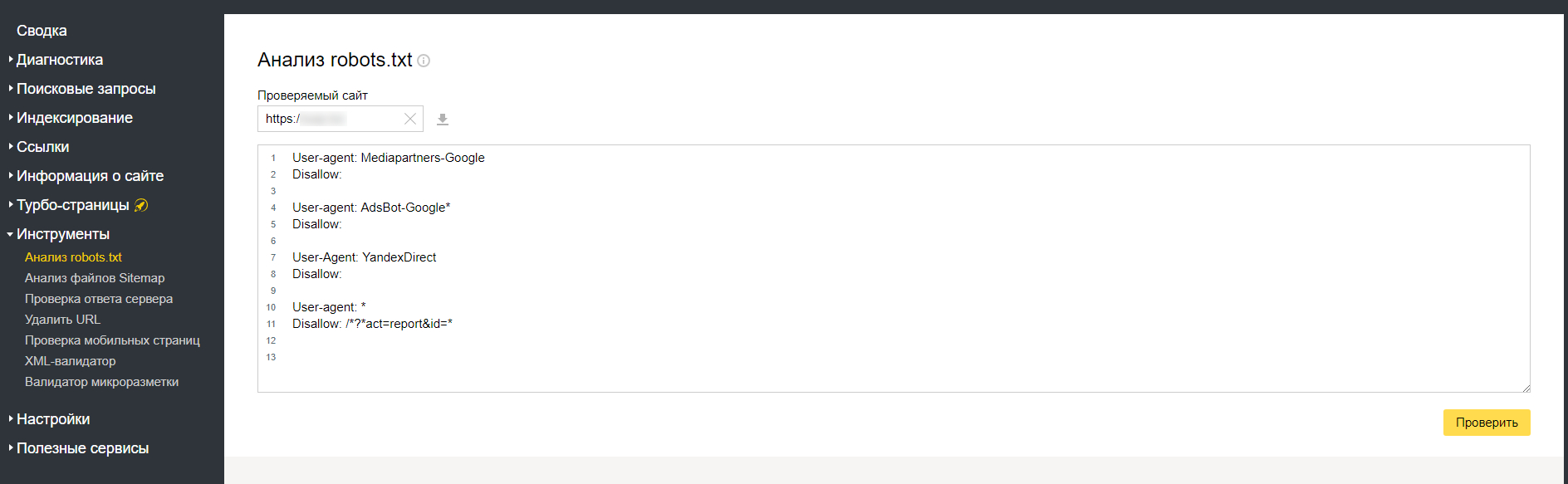
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.
Запрещается использовать более двух значений. Например:
<meta name = «robots» content = «noindex,nofollow, follow»>
<meta name = «robots» content = «noindex,nofollow, follow»> |
И любые другие. В этом случае мы видим противоречие.
В этом случае мы видим противоречие.
Итог
Наиболее удобным способом закрытия страницы для поискового робота я вижу использование мета-тега. В таком случае вам не нужно будет постоянно, сотни раз редактировать файл robots.txt, чтобы открыть или закрыть очередной url, а это решение принимается непосредственно при создании новых страниц.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотреть
Запрет индексации страниц/директорий через robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов.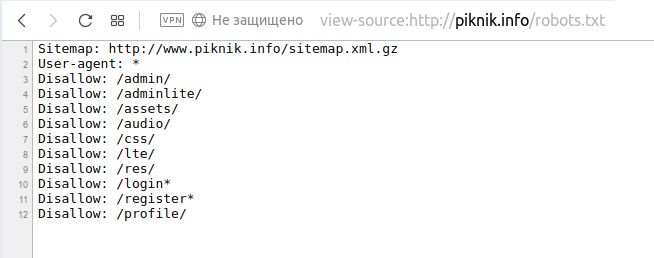
Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx.txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
- User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
- Disallow: / # будет запрещено индексирование всего сайта
- Disallow: /page/ # будет запрещено индексирование директории /page/
Примеры:
Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots. txt):
txt):
User-agent: *
Disallow:
Пример:
Разрешить индексировать сайт только ботам Yandex, Google, Rambler с задержкой 4сек между опросами страниц.
User-agent: *
Disallow: /
User-agent: Yandex
Crawl-delay: 4
Disallow:
User-agent: Googlebot
Crawl-delay: 4
Disallow:
User-agent: StackRambler
Crawl-delay: 4
Disallow:
Как закрыть сайт от индексации в robots.txt
Автор
wbooster
На чтение
3 мин
Просмотров
1707
Опубликовано
В процессе проведения редизайна или же разработки ресурса нередко бывают ситуации, когда требуется предотвратить посещение поисковых роботов и по сути, закрыть ресурс от индексации. Сделать это можно посредством закрытия сайта в коне сайта. в данном случае используется текстовый файл robots.txt.
в данном случае используется текстовый файл robots.txt.
Файл находится на файловом хранилище Вашего сайта, найти его можно с помощью файловых менеджеров, через хостинг (файловый менеджер на хостинге) или через админку сайта (доступно не во всех CMS).
kak-zakryt-sajt-v-robots-txt.img
Данные строки закроют сайт от индексации поисковым роботом Google:
User-agent: Google
Disallow: /
А с помощью данных строк, мы закроем сайт для всех поисковых систем.
User-agent: *
Disallow: /
Закрытие отдельной папки
Также существует возможность в указанном файле осуществить процесс закрытия конкретной папки. Посредством таких действий осуществляется закрытие всех файлов, которые присутствуют в указанной папке. Прописывается следующее:
User-agent: *
Disallow: /papka/
Можно будет в такой ситуации отдельно указать на те файлы в папке, которые могут быть открыты для дальнейшей индексации.
Если же вы хотите закрыть не только конкретную папку, а также все вложенные внутри папки, то используйте звездочку на конце папке:
User-agent: *
Disallow: /papka/*
Если же у вас 2 правила, которые могут конфликтовать между собой, то в данном случае поисковые роботы выставят приоритет по наиболее длинной строчке. То есть, для роботов, нет последовательности строчек.
То есть, для роботов, нет последовательности строчек.
Цифрами мы обозначили, по какому приоритету будет идти строчки:
То есть, в данном случае папка /papka/kartinki/logotip/ будет закрыта, однако остальные файлы и папки в /papka/kartinki/ будут открыты.
Закрытие отдельного файла
Тут все производится в том же формате, как и при закрытии папки, но в процессе указания конкретных данных, нужно четко определить файл, который вы хотели бы скрыть от поисковой системы.
User-agent: *
Disallow: /papka/kartinka.jpg
Если же вы хотите закрыть папку, однако открыть доступ к файлу, то используйте директиву Allow:
User-agent: *
Allow: /papka/kartinka.jpg
Disallow: /papka/
Проверка индекса документа
Чтобы осуществить проверку нужно воспользоваться специализированным сервисом Яндекс.Вебмастер.
Скрытие картинок
Чтобы картинки, расположенные на страницах вашего интернет ресурса, не попали в индекс, рекомендуется в robots. txt, ввести команду – Disallow, а также указать четкий формат картинок, которые не должны посещаться поисковым роботом.
txt, ввести команду – Disallow, а также указать четкий формат картинок, которые не должны посещаться поисковым роботом.
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
Можно ли закрыть поддомен?
Опять же используется директория Disallow, при этом указания на закрытие должно осуществляться исключительно в файле robots.txt конкретного поддомена. Дубли на поддоменне при использовании CDN могут стать определенной проблемой. В данном случае обязательно нужно использовать запрещающий файл с указанием четко определенных дублей, чтобы они не появлялись в индексе и не влияли на продвижение интернет ресурса.
Чтобы осуществить блокировку других поисковых систем вместо Yandex, нужно будет указать данные поискового робота. Для этого можно воспользоваться специализированными программами, чтобы иметь четкие назначения роботов той или же иной системы.
Закрытие сайта или же страницы при помощи мета-тега
Можно процесс закрытия осуществить посредством применения мета-тега robots. В определенных ситуациях данный вариант закрытия считается более предпочтительным, так как он влияет на различные поисковые системы и требует введение определенного кода (в коде обязательно прописываются данные конкретного поискового робота).
В определенных ситуациях данный вариант закрытия считается более предпочтительным, так как он влияет на различные поисковые системы и требует введение определенного кода (в коде обязательно прописываются данные конкретного поискового робота).
Как правило, данную строку пишут в теге <head> или </footer>:
<meta name=”robots” content=”noindex, nofollow”/>
Или
<meta name=”robots” content=”none”/>
Также, мы можем написать отдельное правило для каждого поискового паука:
Google:
<meta name=”googlebot” content=”noindex, nofollow”/>
Яндекс:
<meta name=”yandex” content=”none”/>
Как закрыть сайт от индексации Google, Яндекс в robots txt ✔ PROject SEO
Многие вебмастера при работе с сайтом могут вносить правки, которые сильно сказываются на его дизайне и функционале. В некоторых случаях это может быть связано с разработкой нового оформления для проекта, добавлении различных фишек и т. п. В результате возникает ситуация, когда требуется закрыть сайт от индексации в поисковых системах, чтобы поисковые боты не видели веб-сайт на стадии разработки.
п. В результате возникает ситуация, когда требуется закрыть сайт от индексации в поисковых системах, чтобы поисковые боты не видели веб-сайт на стадии разработки.
На помощь в данном случае придет файл robots.txt, который должен лежать в корневой папке проекта. Чтобы закрыть сайт от индексации во всех поисковых системами потребуется разместить в файл robots.txt следующие строки:
User-agent: *
Disallow: /
Иногда вы можете запретить индексировать сайт отдельным поисковым роботам (у каждого поисковика имеется свой), для этого потребуется вместо звездочки в robots.txt прописать обращение к поисковому роботу.
- Yandex – для Яндекса
- Googlebot – для Google.
Запретить индексацию папки или директории сайта
С помощью роботса также можно закрывать отдельные разделы сайта. Для этого следует добавить вот такие значения:
User-agent: *
Disallow: /name/
Где name – название папки. Это запретит индексацию всех адресов сайта, которые расположены внутри раздела name.
При этом можно дополнительно прописать инструкцию, которая позволит открыть для индексации отдельный файл. Для этого прописываем следующие строки:
User-agent: *
Disallow: /name/
Allow: /name/page_1
В результате роботы поисковых систем не будут сканировать все содержимое папки name, кроме раздела page_1.
Данную инструкцию также можно отдельно прописывать для поисковых ботов.
Запретить индексацию изображений
С помощью роботса можно без проблем закрыть индексацию изображений на сайте. Для этого разместите в файле строку Dissallow: с указанием формата изображений, который не должен быть проиндексирован поисковыми ботами. Например:
Disallow: *.png
Закрыть от индексации поддомены
Поисковые системы распознают все поддомены как отдельные сайты. Поэтому необходимо на каждом из них размещать свой роботс.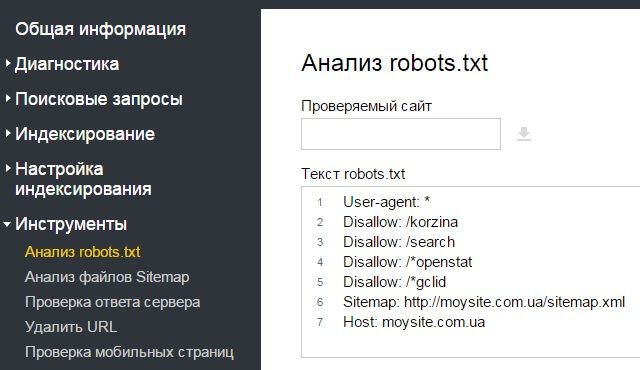 Находится он в корневой папке вашего поддомена. Чтобы закрыть от индексации нужный вам поддомен, добавьте файл robots.txt инструкцию, которая была указана выше.
Находится он в корневой папке вашего поддомена. Чтобы закрыть от индексации нужный вам поддомен, добавьте файл robots.txt инструкцию, которая была указана выше.
Список дополнительных директив, которые используются в файле robots.txt
Помимо стандартных директив, Google, Яндекс и прочие поисковики знают еще несколько.
- Sitemap – распознается всеми поисковиками. Данная директива дает возможность указать путь к карте сайта в формате sitemap.xml.
- Clean-param – эта директива распознается только Яндексом. С ее помощью можно запретить индексацию get-параметров вашего сайта, которые приводят к дублированию страниц. Например, при наличии на той или иной странице utm-меток, она будет иметь одинаковый контент при разных url.
- Crawl-delay – распознается большинством поисковых систем. С ее помощью вы можете указать минимальное значение времени, за которое с сервера будет произведено скачивание 2-х файлов.
Инструкции для других поисковых систем
С помощью строки User-agent: вы можете обратиться в robots. txt к разным известных поисковых систем. Каждая из них имеет своего робота, который проводит сканирование страниц сайта. Помимо стандартных обращений к Яндексу и Google, которые были описаны выше, можно прописать обращения и к другим поисковым ботам.
txt к разным известных поисковых систем. Каждая из них имеет своего робота, который проводит сканирование страниц сайта. Помимо стандартных обращений к Яндексу и Google, которые были описаны выше, можно прописать обращения и к другим поисковым ботам.
- Бинг – MSNBot;
- Yahoo – Slurp;
Закрыть страницу от индексации
Помимо файла robots.txt можно запретить к индексации ту или иную страницу проекта. Для этого используется мета-тег robots, который должен быть прописан в html-коде сайта. Поисковики воспринимают его, и он имеет довольно высокий приоритет. Для того чтобы запретить индексирование URL, добавьте в код следующие строки:
<meta name=»robots» content=»noindex, nofollow»/>
Или
<meta name=»robots» content=»noindex, follow»/>
Также можно использовать альтернативный вариант:
<meta name=»robots» content=»none»/>
Мета тег дает возможность обращаться к поисковым ботам. Для этого нужно заменить в нем строчку robots на yandex или googlebot.
Для этого нужно заменить в нем строчку robots на yandex или googlebot.
08.02.2019
1003
Управление robots.txt
Общие правила
Данная вкладка служит для указания общих правил для индексирования сайта поисковыми системами. В поле отображается текущий набор инструкций. Любая из инструкций (кроме User-Agent: *) может быть удалена, если навести на нее курсор мыши и нажать на «крестик». Для генерации инструкций необходимо воспользоваться кнопками, расположенными рядом с полем.
| Кнопка | Описание |
|---|---|
| Стартовый набор | Позволяет задать набор стандартных правил и ограничений (закрываются от индексации административные страницы, личные данные пользователя, отладочная информация).
Если часть стандартного набора уже задана, то будут добавлены только необходимые отсутствующие инструкции. |
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек.) между запросами поискового робота. |
| Карта сайта | Позволяет задать ссылку к файлу карты сайта sitemap. xml. xml. |
Яндекс
Настройка правил и ограничений для роботов Яндекса. Настройку можно выполнить как сразу для всех роботов Яндекса (вкладка «Yandex»), так и каждого в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации.  В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы.
|
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек.) между запросами поискового робота. |
Настройка правил и ограничений для роботов Google. Настройка выполняется для каждого робота в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
Редактировать
На данной вкладке представлено текстовое поле, в котором можно вручную отредактировать содержимое файла robots. txt.
txt.
Смотрите также
© «Битрикс»,
2001-2021,
«1С-Битрикс», 2021
Наверх
ROBOTS.TXT. Правильный роботс | Блог Хостинг Украина
Основной синтаксис
User-Agent: робот для которого будут применяться следующие правила (например, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (можно указать большой список таких директив с каждой новой строки)
Каждая группа User-Agent / Disallow должны быть разделены пустой строкой. Но, не пустые строки не должны существовать в рамках группы (между User-Agent и последней директивой Disallow).
Символ хэш (#) может быть использован для комментариев в файле robots.txt: для текущей строки всё что после # будет игнорироваться.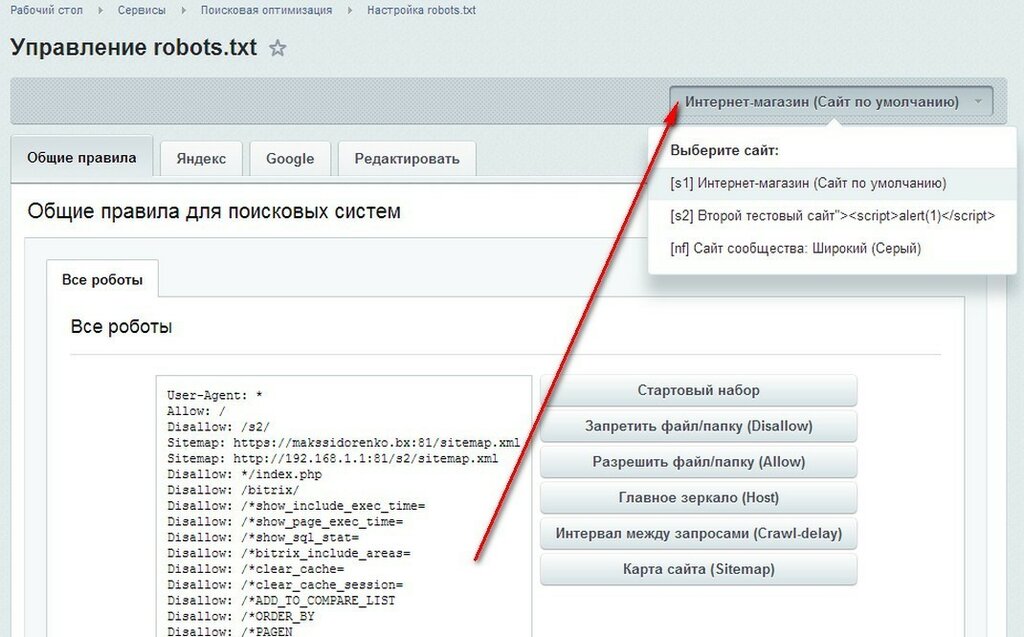 Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Каталоги и имена файлов чувствительны к регистру: «catalog», «Catalog» и «CATALOG» – это всё разные директории для поисковых систем.
Host: применяется для указание Яндексу основного зеркала сайта. Поэтому, если вы хотите склеить 2 сайта и делаете постраничный 301 редирект, то для файла robots.txt (на дублирующем сайте) НЕ надо делать редирект, чтобы Яндекс мог видеть данную директиву именно на сайте, который необходимо склеить.
Crawl-delay: можно ограничить скорость обхода вашего сайта, так как если у вашего сайта очень большая посещаемость, то, нагрузка на сервер от различных поисковых роботов может приводить к дополнительным проблемам.
Регулярные выражения: для более гибкой настройки своих директив вы можете использовать 2 символа
* (звездочка) – означает любую последовательность символов
$ (знак доллара) – означает конец строки
Основные примеры использования robots.
 txt
txt
Запрет на индексацию всего сайта
User-agent: *
Disallow: /
Эту инструкцию важно использовать, когда вы разрабатываете новый сайт и выкладываете доступ к нему, например, через поддомен.
Очень часто разработчики забывают таким образом закрыть от индексации сайт и получаем сразу полную копию сайта в индексе поисковых систем. Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
А такая конструкция ПОЗВОЛЯЕТ индексировать весь сайт:
User-agent: *
Disallow:
Запрет на индексацию определенной папки
User-agent: Googlebot
Disallow: /no-index/
Запрет на посещение страницы для определенного робота
User-agent: Googlebot
Disallow: /no-index/this-page.html
Запрет на индексацию файлов определенного типа
User-agent: *
Disallow: /*. pdf$
pdf$
Разрешить определенному поисковому роботу посещать определенную страницу
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Ссылка на Sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Нюансы с использованием данной директивы: если у вас на сайте постоянно добавляется уникальный контент, то
-
лучше НЕ добавлять в robots.txt ссылку на вашу карту сайта, -
саму карту сайта сделать с НЕСТАНДАРТНЫМ названием sitemap.xml (например, my-new-sitemap.xml и после этого добавить эту ссылку через «вебмастерсы» поисковых систем),
так как, очень много недобросовестных вебмастеров парсят с чужих сайтов контент и используют для своих проектов.
Шаблон для WordPress
Allow: /wp-content/themes/*.js
Allow: /wp-content/themes/*.css
Allow: /wp-includes/js/*.css Allow: /wp-includes/js/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/plugins/*.css
Шаблон для Joomla
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /templates/*.png
Allow: /templates/*.gif
Allow: /templates/*.ttf
Allow: /templates/*.svg
Allow: /templates/*.woff
Allow: /components/*.css
Allow: /components/*.js
Allow: /media/*.js Allow: /media/*.css
Allow: /plugins/*.css Allow: /plugins/*.js
Шаблон для Bitrix
Allow: /bitrix/templates/*.js
Allow: /bitrix/templates/*.png
Allow: /bitrix/templates/*. jpg
jpg
Allow: /bitrix/templates/*.gif
Allow: /bitrix/cache/css/*.css
Allow: /bitrix/cache/js/s1/*.js
Allow: /upload/iblock/*.jpg
Allow: /upload/iblock/*.png
Allow: /upload/iblock/*.gif
Шаблон для DLE
Allow: /engine/classes/*.css
Allow: /engine/classes/*.js
Allow: /templates/
Разобравшись с простым синтаксисом команд для робота, также важно учесть и такие значения мета-тега robots
Данному мета-тегу можно присвоить четыре варианта значений.
Атрибут content может содержать следующие значения:
index, noindex, follow, nofollow
Если значений несколько, они разделяются запятыми.
В настоящее время лишь следующие значения важны:
Директива INDEX говорит роботу, что данную страницу можно индексировать.
Директива FOLLOW сообщает роботу, что ему разрешается пройтись по ссылкам, присутствующим на данной странице.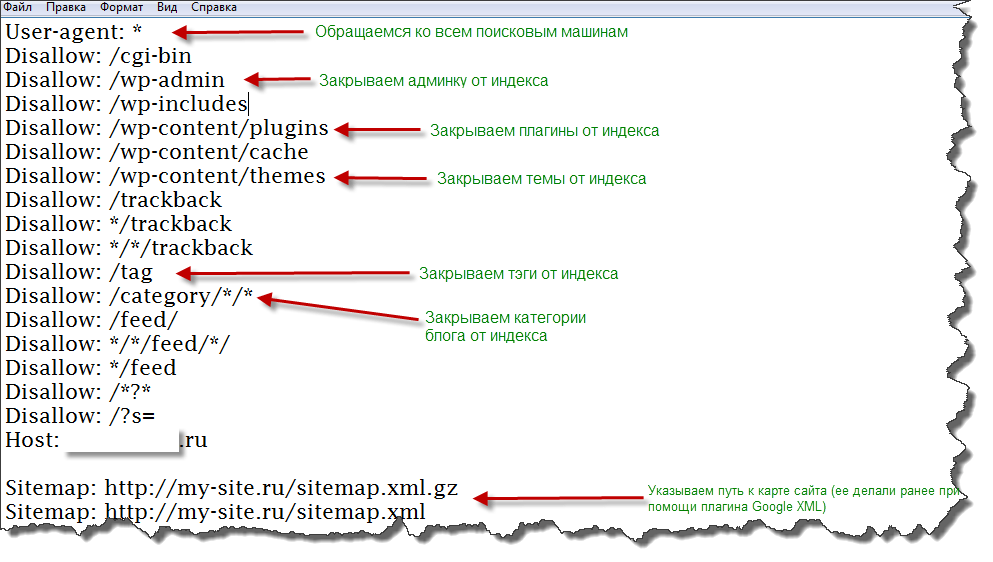 Некоторые авторы утверждают, что при отсутствии данных значений, поисковые сервера по умолчанию действуют так, как если бы им даны были директивы INDEX и FOLLOW.
Некоторые авторы утверждают, что при отсутствии данных значений, поисковые сервера по умолчанию действуют так, как если бы им даны были директивы INDEX и FOLLOW.
Итак, глобальные директивы выглядят так:
Индексировать всё = INDEX, FOLLOW
Не индексировать ничего = NOINDEX,NOFLLOW
Примеры мета-тега robots:
Заказывайте хостинг и выбирайте домен в компании «Хостинг Украина».
У нас качественный и надежный сервис, удобное система управления через админ-панель, интеллектуальные системы защиты и техническая поддержка, которая поможет решить все возникающие вопросы в любое время суток.
Наши цены: SSD хостинг от 1$, VPS на SSD от 12$, Cloud (облачный) хостинг от 3$, облачный VPS от 6$.
Присоединяйтесь к «Хостинг Украина» и мы позаботимся о технической стороне вашего бизнеса.
FAQ robots.
 txt: часто задаваемые вопросы
txt: часто задаваемые вопросы
Robots.txt — что это?
Файл robots.txt — это индексный файл в текстовом формате, который рекомендует поисковым роботам (например, Google, Yandex) какие страницы сканировать, а какие нет.
Нужен или нет robots.txt?
Однозначно да. Он помогает поисковым роботам быстрее разобраться какие страницы нужно индексировать, а какие нет.
Где находится файл robots.txt?
Файл располагается в корневой папке сайта и доступный для просмотра по адресу: https://site.ua/robots.txt
Как выглядит стандартный robots.txt?
Robots.txt пример:
Что должно быть в robots.txt?
Атрибуты robots.txt:
- User-agent — описывает каким именно роботам нужно смотреть инструкцию. Существует около 300 поисковых роботов (Googlebot, Yandexbot и т.д.). Чтобы указать инструкции сразу для всех роботов следует прописать:
Другие роботы:
- Ahrefsbot;
- Exabot;
- SemrushBot;
- Baiduspider;
- Mail.
 RU_Bot.
RU_Bot.
Список ненужных ботов ЗДЕСЬ. - Disallow — указывает роботу, что не нужно сканировать.
Открыть для сканирования весь сайт (robots.txt разрешить все):Запретить сканирование всего сайта (robots.txt запретить все):
Robots.txt запретить индексацию папки:
Запретить индексацию страницы в robots.txt:
Запретить индексацию конкретного файла:
Запрет индексации всех файлов на сайте с расширением .pdf:
Запретить индексацию поддомена в robots.txt:
Каждый поддомен имеет свой файл robots.txt. Если его нет — создайте и добавьте в корневую папку поддомена.
Закрыть все кроме главной в robots.txt: - Allow — разрешает роботу сканировать сайт/папку/конкретную страницу.
Например, чтобы разрешить роботу сканировать страницы каталога, а все остальное закрыть:
 RU_Bot.
RU_Bot.
Как выглядит Robots.txt для Гугла и Яндекса?
Как указать главное зеркало в robots.
 txt?
txt?
Для обозначения главного зеркала (копии сайта, доступной по разным адресам) используют атрибут Host.
Host в robots.txt:
Как прописать карту сайта в robots.txt?
Карта сайта (sitemap.xml) сообщает поисковым роботам приоритетные страницы для индексации. Она находится по адресу: https://site.com/sitemap.xml.
Sitemap в robots.txt:
Что обозначают символы в robots.txt?
Наиболее часто используются следующие символы:
- “/” — закрытие от робота весь сайт/папку/страницу;
- “*” — любая последовательность символов;
- “$” — ограничение действия знака “*”;
- “#” — комментарии, которые не учитываются роботами.
Как настроить robots.txt?
В файле обязательно нужно отдельно для каждого робота прописать, что открыто для сканирования и что закрыто, прописать хост и карту сайта.
Файлы robots.txt различаются между собой в зависимости от используемой CMS.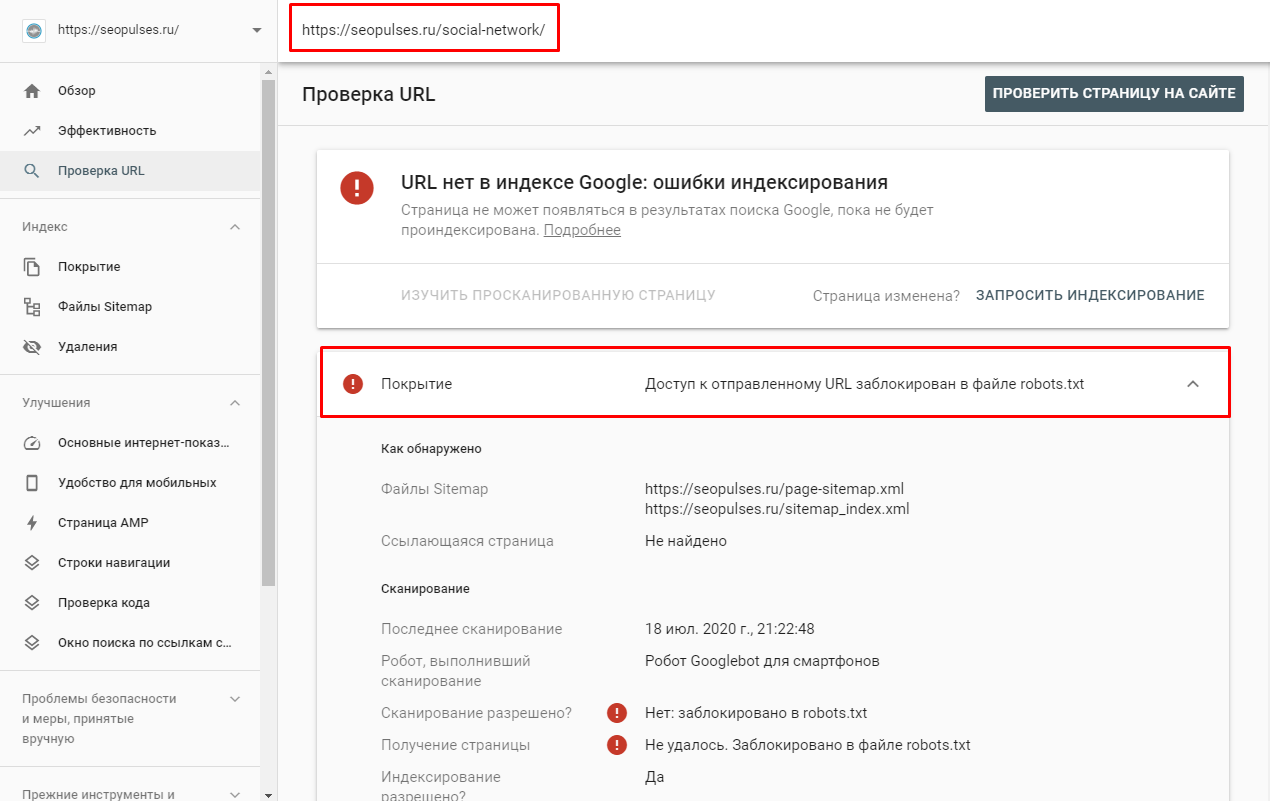
Рекомендуем закрывать от индексации страницы: авторизации, фильтрации, поиска, страницу 404, вход в админку.
Пример идеального robots.txt:
Как проверить robots.txt?
Чтобы проверить валидность robots.txt (правильно ли заполнен файл) — используйте инструмент для вебмастеров Google Search Console. Для этого достаточно ввести код файла в форму, указать сайт и Вы получите отчет о корректности файла:
Ошибки в robots.txt
- Перепутали местами инструкции.
Неправильно:Правильно:
- Записали пару директорий сразу в одной инструкции:
- Не правильное название файла — не Robot.txt и не ROBOTS.TXT, а robots.txt!
- Правило User-agent не должно быть пустым, обязательно нужно указывать для каких роботов оно действует.
- Следите, чтобы не указать лишних символов в файле (“/”, “*”, “$” и т.д.).
- Не открывайте для сканирования страницы, которые не нужны в индексе.

Подойдите со всей ответственностью к формированию файла robots.txt — и будет Вам счастье 😉
Robots.txt Введение и руководство | Центр поиска Google
Файл robots.txt сообщает сканерам поисковых систем, к каким URL-адресам сканер может получить доступ на вашем сайте.
Это используется в основном для того, чтобы избежать перегрузки вашего сайта запросами; это не
механизм для защиты веб-страницы от Google . Чтобы веб-страница не попала в Google,
блочная индексация с помощью noindex
или защитите страницу паролем.
Что такое роботы.txt используется для?
Файл robots.txt используется в первую очередь для управления трафиком сканеров на ваш сайт, а также
обычно , чтобы хранить файл вне Google, в зависимости от типа файла:
Влияние robots. txt на разные типы файлов txt на разные типы файлов | |
|---|---|
| Интернет-страница | Вы можете использовать файл robots.txt для веб-страниц (HTML, PDF или другие Не используйте файл robots.txt как средство, чтобы скрыть свои веб-страницы от поиска Google. Если другие страницы указывают на вашу страницу с описательным текстом, Google все равно может проиндексировать Если ваша веб-страница заблокирована файлом robots.txt , ее URL-адрес все еще может |
| Медиа-файл | Используйте файл robots.txt для управления трафиком сканирования, а также для предотвращения изображений, видео и |
| Файл ресурсов | Вы можете использовать файл robots.txt, чтобы заблокировать файлы ресурсов, такие как неважное изображение, сценарий, или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не будут существенно повлияет убыток . Однако если их отсутствие ресурсы затрудняют понимание страницы поисковым роботом Google, не блокируйте их, иначе Google не сможет хорошо анализировать страницы, зависящие от эти ресурсы. |
Поймите ограничения роботов.txt файл
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этой блокировки URL.
метод. В зависимости от ваших целей и ситуации вы можете рассмотреть другие механизмы
убедитесь, что ваши URL-адреса не могут быть найдены в Интернете.
- Директивы robots.txt могут поддерживаться не всеми поисковыми системами.
Инструкции в файлах robots.txt не могут принудить сканер к вашему сайту; работает
гусеницу подчиняться им.Хотя робот Googlebot и другие уважаемые веб-сканеры подчиняются
инструкции в файле robots.txt, другие сканеры не могут. Поэтому, если вы хотите сохранить
информация защищена от веб-сканеров, лучше использовать другие методы блокировки, такие как
защита паролем личных файлов на вашем сервере. - Разные поисковые роботы по-разному интерпретируют синтаксис.
Хотя респектабельные поисковые роботы следуют директивам в файле robots.txt, каждый поисковый робот
могут интерпретировать директивы по-разному.Вы должны знать
правильный синтаксис для адресации
разные поисковые роботы, так как некоторые могут не понимать определенные инструкции. - Страница, запрещенная в robots. txt, может
все равно будут проиндексированы, если на них есть ссылки с других сайтов.
Хотя Google не будет сканировать и индексировать контент, заблокированный файлом robots.txt, мы все же можем
найти и проиндексировать запрещенный URL, если на него есть ссылки из других мест в Интернете. Как результат,
URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки
в ссылках на страницу все еще может отображаться в результатах поиска Google.Чтобы правильно предотвратить ваш URL
от появления в результатах поиска Google,
защитить паролем файлы на вашем сервере,
используйте метатегnoindexили заголовок ответа,
или удалите страницу полностью.
 txt, может
txt, может Важно : сочетание нескольких директив сканирования и индексирования может вызвать
некоторые директивы для противодействия другим директивам. Узнайте, как
совместить сканирование с директивами индексирования и обслуживания.
Создайте файл robots.txt файл
Если вы решили, что он вам нужен, узнайте, как
создайте файл robots.txt.
Файл Robots.txt [Примеры 2021] [Запретить]
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на своем веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям.REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта.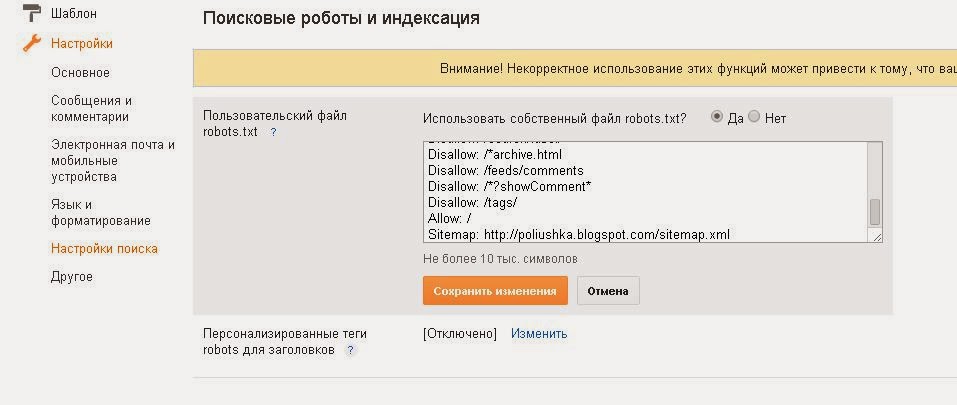 Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:
User-agent: [имя user-agent] Disallow: [URL-строка, которую нельзя сканировать]
Вместе эти две строки считаются полными robots.txt — хотя один файл роботов может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами пользовательского агента, каждая из которых запрещает или разрешает правило только применяется к агентам-пользователям, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот будет только обратить внимание (и следовать директивам в) наиболее конкретной группе инструкций .
Вот пример:
Msnbot, discobot и Slurp все вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt
Блокирование доступа всех поисковых роботов к содержимому
User-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt укажет всем поисковым роботам не сканировать никакие страницы www.example .com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контенту
User-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www. example.com, включая домашнюю страницу.
example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папки
User-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис предписывает только поисковому роботу Google (имя агента пользователя Googlebot) не сканировать страницы, которые содержать строку URL www.example.com/example-subfolder/.
Блокировка определенного поискового робота с определенной веб-страницы
Пользовательский агент: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только поисковому роботу Bing (имя пользовательского агента Bing) избегать сканирование конкретной страницы www.example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
Поисковые системы выполняют две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.

Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой — в конечном итоге просматривая многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».”
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt не содержит , а не содержит директив, запрещающих действия пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.
txt должен быть помещен в каталог верхнего уровня веб-сайта.Robots.txt чувствителен к регистру: файл должен называться «robots.txt» (не Robots.txt, robots.TXT и т. Д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваших роботов.txt файл. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы хотите или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельных роботов.txt файлы. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.
txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
 txt должен быть помещен в каталог верхнего уровня веб-сайта.
txt должен быть помещен в каталог верхнего уровня веб-сайта. txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).Выявление критических предупреждений robots.txt с помощью Moz Pro
Функция сканирования сайта Moz Pro проверяет ваш сайт на наличие проблем и выделяет срочные ошибки, которые могут помешать вам появиться в Google.Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Начать бесплатную пробную версию
Технический синтаксис robots.txt
Синтаксис Robots.txt можно рассматривать как «язык» файлов robots.txt . Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. К ним относятся:
User-agent: Конкретный поисковый робот, которому вы даете инструкции для сканирования (обычно это поисковая система).
Список большинства пользовательских агентов можно найти здесь.Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы.Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Sitemap: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
 Список большинства пользовательских агентов можно найти здесь.
Список большинства пользовательских агентов можно найти здесь.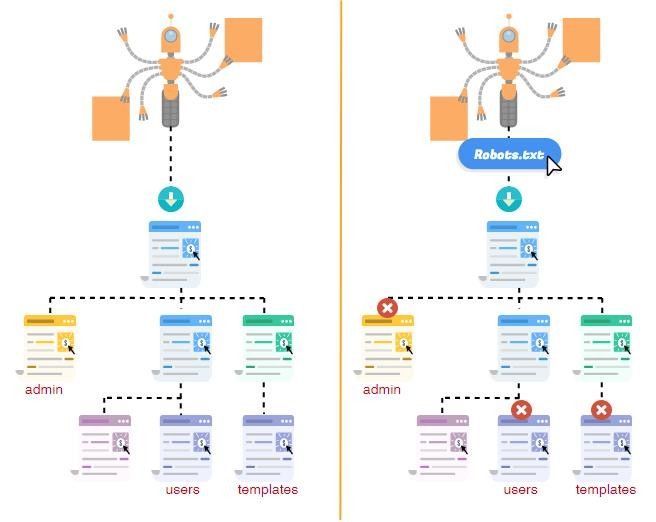
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно заблокировать или разрешить, файлы robots.txt могут стать довольно сложными, поскольку они позволяют использовать сопоставление с образцом для охвата диапазона возможных вариантов URL.И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа — звездочка (*) и знак доллара ($).
- * — это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Когда бы они ни заходили на сайт, поисковые системы и другие роботы-сканирующие веб-сайты (например, сканер Facebook Facebot) знают, что нужно искать роботов.txt файл. Но они будут искать этот файл только в в одном конкретном месте : в основном каталоге (обычно это корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ). Даже если страница robots.txt действительно существует, существует, скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, он не будет обнаружен пользовательскими агентами, и поэтому сайт будет обрабатываться так, как если бы на нем вообще не было файла robots.
Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ). Даже если страница robots.txt действительно существует, существует, скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, он не будет обнаружен пользовательскими агентами, и поэтому сайт будет обрабатываться так, как если бы на нем вообще не было файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта. Хотя это может быть очень опасным, если вы случайно запретите роботу Google сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может быть очень кстати.
Некоторые распространенные варианты использования включают:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц с результатами внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Запрещение поисковым системам индексировать определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots. txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (действующей) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Лучшие практики SEO
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т.
Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Некоторые поисковые системы имеют несколько пользовательских агентов.
Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить свой URL-адрес robots.txt в Google.
 Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.
Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.Robots.txt vs meta robots vs x-robots
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это фактический текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они являются на самом деле, все три выполняют разные функции. Файл robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Файл robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Приложите свои навыки к работе
Moz Pro может определить, блокирует ли ваш файл robots.txt наш доступ к вашему веб-сайту. Попробовать >>
Как запретить Google индексировать определенные веб-страницы
Апрель 25, 2019 |
Автор: Tinny
При поисковой оптимизации типичная цель состоит в том, чтобы как можно больше страниц вашего веб-сайта проиндексировали и просканировали поисковыми системами, такими как Google.
Распространенное заблуждение состоит в том, что это может улучшить рейтинг SEO. Однако так бывает не всегда. Часто необходимо сознательно запретить поисковым системам индексировать определенные страницы вашего сайта для повышения SEO. Одно исследование показало, что органический поисковый трафик увеличился на 22% после удаления повторяющихся веб-страниц, в то время как Moz сообщил об увеличении органического поискового трафика на 13,7% после удаления малоценных страниц.
веб-страниц, которые не нужно индексировать
Как уже упоминалось, не все страницы вашего веб-сайта должны индексироваться поисковыми системами.Как правило, они включают, но не ограничиваются, следующее:
- Целевые страницы для объявлений
- Страницы благодарности
- Конфиденциальность и страницы политики
- Страницы администратора
- Дубликаты страниц (например, похожий контент, размещенный на нескольких веб-сайтах, принадлежащих одной компании)
- Малоценные страницы (например, устаревший контент много лет назад, но что-то достаточно ценное, чтобы его нельзя было удалить с вашего сайта)
Перед деиндексированием важно провести тщательный аудит содержания вашего веб-сайта, чтобы у вас был систематический подход к определению, какие страницы включить, а какие исключить.
Как запретить Google индексировать определенные веб-страницы
Есть четыре способа деиндексировать веб-страницы из поисковых систем: метатег «noindex», X-Robots-Tag, файл robots.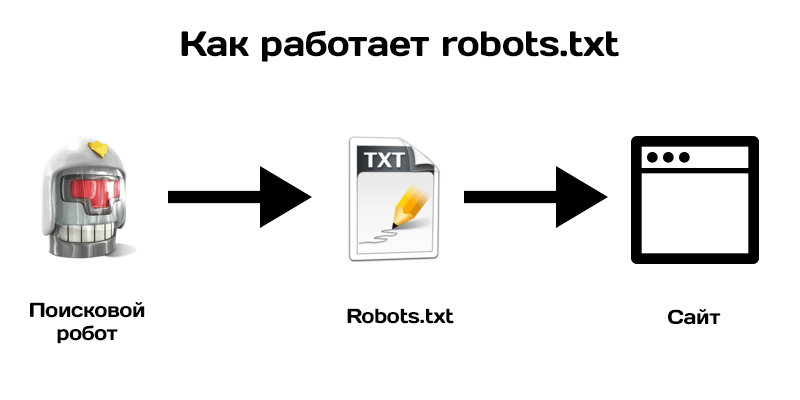 txt и с помощью инструментов Google для веб-мастеров.
txt и с помощью инструментов Google для веб-мастеров.
1. Использование метатега «noindex»
Самый эффективный и простой инструмент для предотвращения индексации Google определенных веб-страниц — это метатег «noindex». По сути, это директива, которая сообщает сканерам поисковой системы, что не должен индексировать веб-страницу, и, следовательно, не будет отображаться в результатах поиска.
Как добавить метатег «noindex»:
Все, что вам нужно сделать, это вставить следующий тег в раздел разметки HTML страницы:
В зависимости от вашей системы управления контентом (CMS) вставка этого метатега должна быть довольно простой. Для таких CMS, как WordPress, которые не позволяют пользователям получать доступ к исходному коду, используйте такой плагин, как Yoast SEO. Здесь следует отметить, что вам нужно сделать это для каждой страницы, которую вы хотите деиндексировать.
Кроме того, если вы хотите, чтобы поисковые системы одновременно деиндексировали вашу веб-страницу, а , а не , следуйте ссылкам на этой странице (например, в случае страниц с благодарностью, где вы не хотите, чтобы поисковые системы индексировали ссылку на ваше предложение ) используйте «noindex» с метатегом «nofollow»:
2. Использование HTTP-заголовка X-Robots-Tag
В качестве альтернативы вы можете использовать X-Robots-Tag, который вы добавляете в заголовок HTTP-ответа заданного URL-адреса.По сути, он имеет тот же эффект, что и тег «noindex», но с дополнительными опциями для определения условий для различных поисковых систем. Для получения дополнительной информации см. Руководство Google здесь.
Как добавить X-Robots-Tag:
В зависимости от используемого веб-браузера может быть довольно сложно найти и отредактировать заголовок ответа HTTP. Для Google Chrome вы можете использовать инструменты разработчика, такие как ModHeader или Modify Header Value. Вот примеры X-Robots-Tag для определенных функций:
Вот примеры X-Robots-Tag для определенных функций:
X-Robots-Tag: noindex
- Чтобы установить разные правила деиндексации для разных поисковых систем:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
3.Использование файла robots.txt
Файл robots.txt в основном используется для управления трафиком сканеров поисковых систем от перегрузки вашего веб-сайта запросами. Однако следует отметить, что этот тип файлов не предназначен для сокрытия веб-страниц от Google; скорее, он используется для предотвращения появления изображений, видео и других мультимедийных файлов в результатах поиска.
Как использовать файл robots.txt, чтобы скрыть медиафайлы от Google:
Использование robots.txt довольно технически. По сути, вам нужно использовать текстовый редактор для создания стандартного текстового файла ASCII или UTF-8, а затем добавить этот файл в корневую папку вашего веб-сайта.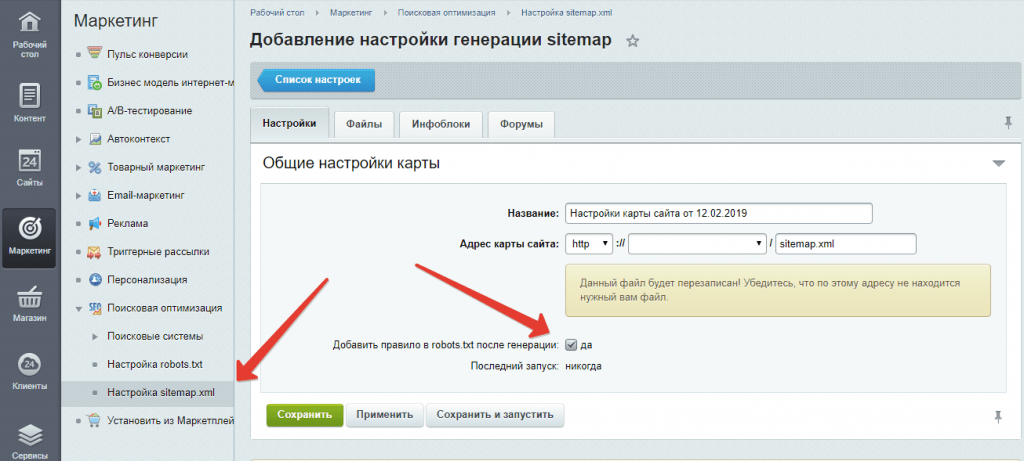 Чтобы узнать больше о том, как создать файл robots.txt, ознакомьтесь с руководством Google здесь. Google также создал отдельные руководства для скрытия определенных медиафайлов от появления в результатах поиска:
Чтобы узнать больше о том, как создать файл robots.txt, ознакомьтесь с руководством Google здесь. Google также создал отдельные руководства для скрытия определенных медиафайлов от появления в результатах поиска:
4. Использование Инструментов Google для веб-мастеров
Вы также можете временно заблокировать страницы из результатов поиска Google с помощью инструмента удаления URL-адресов Google для веб-мастеров. Обратите внимание, что это применимо только к Google; у других поисковых систем есть свои собственные инструменты. Также важно учитывать, что это удаление носит временный характер.Чтобы безвозвратно удалить веб-страницы из результатов поиска, ознакомьтесь с инструкциями Google здесь.
Как использовать инструменты Google Remove URL для временного исключения страниц:
Процедура довольно проста. Откройте инструмент удаления URL-адресов и выберите принадлежащий вам ресурс в Search Console. Выберите Временно скрыть и введите URL-адрес страницы. После этого выберите Очистить URL-адрес из кеша и временно удалите из поиска . Это скрывает страницу из результатов поиска Google на 90 дней, а также очищает кешированную копию страницы и фрагменты из индекса Google.Для получения дополнительной информации ознакомьтесь с руководством Google здесь.
После этого выберите Очистить URL-адрес из кеша и временно удалите из поиска . Это скрывает страницу из результатов поиска Google на 90 дней, а также очищает кешированную копию страницы и фрагменты из индекса Google.Для получения дополнительной информации ознакомьтесь с руководством Google здесь.
Завершение
Для получения вашего запроса на деиндексирование в Google может потребоваться время. Часто требуется несколько недель, чтобы изменения вступили в силу. Если вы заметили, что ваша страница все еще отображается в результатах поиска Google, скорее всего, это связано с тем, что Google не сканировал ваш сайт с момента вашего запроса. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента «Просмотреть как Google».
Если вы хотите узнать больше или вам нужна помощь с какими-либо потребностями в области SEO, Ilfusion имеет необходимые знания и опыт, чтобы помочь вам.Позвоните нам по телефону 888-420-5115 или отправьте нам электронное письмо по адресу [адрес электронной почты защищен].
Теги: сканирование, поиск google, google +, индекс, метатеги, поисковые системы, SEO
Категория: SEO
Как разблокировать Robots.txt и удалить тег noindex
Устранение неполадок, связанных с индексированием и сканированием: с чего начать
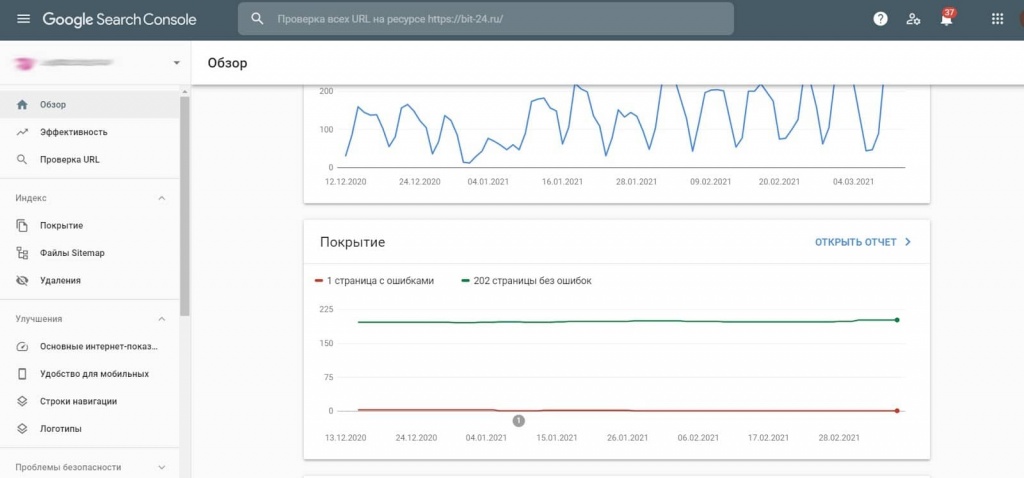
Прежде всего, давайте попробуем сузить проблему. Для этого войдите в Google Search Console. Затем скопируйте и вставьте URL-адрес главной страницы своего веб-сайта в файл robots.txt tester и нажмите «Отправить». (На данный момент этот инструмент существует только в старой версии Google Search Console.) Если он «ЗАБЛОКИРОВАН», см. Проблему № 1, если «РАЗРЕШЕН», см. Проблему № 2 ниже.
Проблема №1: Домен или URL-адрес заблокирован файлом robots.txt
Если линия запрета горит красным, и вы видите слово «ЗАБЛОКИРОВАНО», появившееся в поле в правом нижнем углу, как на скриншоте ниже, robots. txt является виновником. Чтобы отменить это, вам потребуется доступ к файлу robots.txt для вашего сайта.
* Если вы не тот человек, который обычно играет на серверной части вашего веб-сайта, я настоятельно рекомендую вам обратиться к разработчику вашего веб-сайта, ИТ-специалисту или кому-либо еще, кто занимается обслуживанием веб-сайта.
В приведенном выше примере происходят две вещи, одна хорошая и одна плохая, в зависимости от нашего текущего затруднительного положения. Этот URL-адрес, / wp-admin / , намеренно запрещен, поскольку мы не хотим, чтобы серверная часть нашего веб-сайта сканировалась какой-либо из поисковых систем.Это должно остаться.
Однако проблема в строке Disallow: / . Эта строка, или лучше сказать косая черта, блокирует сканирование вашего веб-сайта всеми поисковыми системами… ну, например, все это. Итак, чтобы разблокировать robots.txt, эту часть необходимо удалить из файла robots.txt.
Буквально достаточно одного персонажа, чтобы бросить гаечный ключ в вещи. После внесения в файл необходимых изменений верните URL-адрес домашней страницы в тестер robots.txt, чтобы проверить, приветствует ли ваш сайт поисковые системы.Если что-то идет плохо, в поле в правом нижнем углу зеленым цветом будет указано «РАЗРЕШЕНО», и теперь поисковые системы могут начать сканирование сайта.
Это исправление должно успешно разблокировать robots.txt по всему сайту (или, по крайней мере, для любой страницы, которая специально не обозначена как запрещенная, как с / wp-admin / URL выше), но не стесняйтесь копировать и вставлять пару дополнительных страниц сайта в в инструмент тестера, чтобы убедиться, что проблема решена не только для вашей домашней страницы.
Если вы хотите узнать больше об этой конкретной марке ботов, посетите Yoast.com, полное руководство по robots.txt.
Проблема № 2: Удаление метатега noindex в WordPress
Если проблема не в том, что беспокоит ваш веб-сайт, поскольку во всем, что происходит «РАЗРЕШЕНО» (как и должно быть), есть еще одна распространенная причина, по которой ваш веб-сайт WordPress может не отображаться в поиске — надоедливый тег noindex.
Чтобы проверить, так ли это, вернитесь к новой версии Search Console, вставьте любой URL-адрес в поле поиска «Проверить любой URL-адрес в…» вверху страницы и нажмите Enter.
Если в отчете о проверке URL отображается следующее сообщение: Нет: в метатеге robots обнаружен «noindex», это означает, что весь этот шум вызывает единственный флажок в серверной части WordPress.
Чтобы разблокировать поисковые системы от индексации вашего веб-сайта, выполните следующие действия:
- Войдите в WordPress
- Перейдите в «Настройки» → «Чтение»
- Прокрутите страницу вниз до места, где написано «Видимость для поисковых систем»
- Снимите флажок рядом чтобы «Не рекомендовать поисковым системам индексировать этот сайт»
- Нажмите кнопку «Сохранить изменения» ниже
Если вы используете плагин Yoast SEO — WordPress, также проверьте настройки сообщений в блоге, чтобы убедиться, что они установлены аналогичным образом. чтобы разрешить индексацию.
Когда это будет завершено, вернитесь в Search Console и повторно отправьте URL-адрес, который вы пробовали ранее. Если ваши настройки настроены правильно, все должно петь другую мелодию. Теперь, когда вы отправляете URL-адрес, в отчете о проверке URL-адресов не должно быть всех предупреждений и сообщений об ошибках, по крайней мере, тех, которые связаны с индексированием и возможностью сканирования, и вы сможете «Запросить индексирование», что, как я полагаю, было вашей целью с самого начала. .
Я надеюсь, что это поможет, но если описанные выше шаги не помогли решить вашу текущую проблему, я рекомендую ознакомиться с этой статьей поддержки веб-мастеров Google о «noindex», чтобы узнать больше.
Очевидная, но важная часть SEO — добиться того, чтобы ваш сайт отображался в результатах поиска. Для этого вам необходимо убедиться, что ваш веб-сайт можно сканировать и индексировать, что означает удаление тега «noindex» и разблокировку robots.txt из общедоступных частей вашего сайта. Эти настройки необходимы для успеха, поэтому сделайте себе одолжение и не игнорируйте предупреждения Search Console или нестабильное поведение, устраняйте эти проблемы с помощью советов и ресурсов, приведенных выше.
Google отменяет поддержку роботов.txt Noindex
Google официально объявил, что GoogleBot больше не будет подчиняться директиве Robots.txt, связанной с индексированием. Издатели, использующие директиву noindex в robots.txt, должны до 1 сентября 2019 г. удалить ее и начать использовать альтернативу.
Robots.txt Noindex Неофициальный
Директива noindex robots.txt не поддерживается, потому что это не официальная директива.
Google ранее поддерживал эту директиву robots.txt, но теперь это будет не так.Обратите на это должное внимание и руководствуйтесь соответствующим образом.
Google в основном подчиняется директиве Noindex
StoneTemple опубликовал статью, в которой отмечалось, что Google в основном подчиняется директиве noindex в robots.txt.
Реклама
Продолжить чтение ниже
Их вывод на тот момент был:
«В конечном счете, директива NoIndex в Robots.txt довольно эффективна.
Идея весьма полезна. Однако наши тесты не показали 100-процентного успеха, поэтому это не всегда работает ».
 Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и благодаря тому, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса.
Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и благодаря тому, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса.Это уже не так. Директива noindex robots.txt больше не поддерживается.
Это официальный твит Google:
«Сегодня мы прощаемся с недокументированными и неподдерживаемыми правилами в robots.txt.
Если вы полагались на эти правила, узнайте о возможных вариантах в нашем блоге».
Реклама
Продолжить чтение ниже
Это соответствующая часть объявления:
«В интересах поддержания здоровой экосистемы и подготовки к потенциальным будущим выпускам с открытым исходным кодом мы удаляем весь код, который обрабатывает неподдерживаемые и неопубликованные правила (например, noindex) 1 сентября 2019 г.
 «
«Как управлять сканированием?
В официальном блоге Google перечислены пять способов управления индексированием:
- Noindex в метатегах robots
- 404 и 410 коды состояния HTTP
- Защита паролем
- Disallow в robots.txt
- Search Console Удалить инструмент URL
Прочтите официальное объявление Google здесь:
https://webmasters.googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html
Прочтите официальный твит Google здесь
https://twitter.com/googlewmc/status/1145950977067016192
Что это такое и как их использовать?
Три слова, приведенные выше, могут звучать как SEO gobbledegook, но это слова, которые стоит знать, поскольку понимание того, как их использовать, означает, что вы можете управлять роботом Googlebot. Это весело.
Итак, начнем с основ: есть три способа контролировать, какие части вашего сайта будут сканироваться поисковыми системами:
- Noindex: указывает поисковым системам не включать ваши страницы в результаты поиска.
- Disallow: запрещает сканирование ваших страниц.
- Nofollow: говорит им не переходить по ссылкам на вашей странице.
Что такое метатег Noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный метод запрета индексации страницы — это добавить тег в заголовок HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница не должна быть заблокирована (запрещена) в файле robots.txt файл. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы поисковые системы не индексировали вашу страницу, просто добавьте следующее в раздел:
Вторая часть тега содержимого здесь указывает, что необходимо переходить по всем ссылкам на этой странице, которые мы обсудим ниже.
В качестве альтернативы тег noindex можно использовать в теге X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Дополнительную информацию см. В сообщении разработчиков Google о спецификациях метатега Robots и HTTP-заголовка X-Robots-Tag.
Как я могу использовать Noindex в файле Robots.txt?
Тег noindex в файле robots.txt также указывает поисковым системам не включать страницу в результаты поиска, но это более быстрый и простой способ не индексировать сразу много страниц, особенно если у вас есть доступ к вашему robots.txt. файл. Например, вы не можете индексировать любые URL-адреса в определенной папке.
Вот пример директивы noindex, которую можно поместить в файл robots.txt:
Noindex: / robots-txt-noindexed-page /
Однако Google не рекомендует использовать этот метод: Джон Мюллер заявил, что «не следует полагаться на него».
Что такое запретительная директива?
Запрещение страницы означает, что вы даете поисковым системам указание не сканировать ее, что необходимо сделать в файле robots. txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.
txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.
Чтобы добавить запрет, просто добавьте в файл robots.txt следующую строку:
Запретить: / your-page-url /
Если на странице есть внешние ссылки или канонические теги, указывающие на нее, ее все равно можно проиндексировать и ранжировать, поэтому важно сочетать запрет с тегом noindex, как описано ниже.
Предупреждение: запрещая страницу, вы фактически удаляете ее со своего сайта.
Запрещенные страницы не могут передавать PageRank где-либо еще — поэтому любые ссылки на этих страницах фактически бесполезны с точки зрения SEO — а запрет на включение страниц, которые должны быть включены, может иметь катастрофические последствия для вашего трафика, поэтому будьте особенно осторожны при написании запрещающих директив.
Как я могу объединить Noindex и Disallow?
Noindex (страница) + Disallow: Disallow не может сочетаться с noindex на странице, потому что страница заблокирована, и поэтому поисковые системы не будут сканировать ее, чтобы знать, что они не должны оставлять страницу вне индекс.
Noindex (robots.txt) + Disallow : предотвращает появление страниц в индексе, а также предотвращает сканирование страниц. Однако помните, что через эту страницу не может пройти PageRank.
Чтобы объединить запрет с noindex в файле robots.txt, просто добавьте обе директивы в файл robots.txt:
Запретить: / example-page-1/
Запретить: / example-page-2/
Noindex: / example-page-1/
Noindex: / example-page-2/
Что такое тег Nofollow?
Тег nofollow в ссылке указывает поисковым системам не использовать ссылку для определения важности связанных страниц (PageRank) или обнаружения дополнительных URL-адресов на том же сайте.
Обычно nofollows использует ссылки в комментариях и другом контенте, который вы не контролируете, платные ссылки, встраиваемые элементы, такие как виджеты или инфографику, ссылки в гостевых сообщениях или что-нибудь не по теме, на которое вы все еще хотите связать людей.
Исторически сложилось так, что оптимизаторы поисковых систем также избирательно исключали переход по ссылкам, чтобы направлять внутренний PageRank на более важные страницы.
Теги Nofollow могут быть добавлены в одном из двух мест:
- страницы (чтобы nofollow все ссылки на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
nofollow не предотвратит полное сканирование связанной страницы; он просто предотвращает сканирование по этой конкретной ссылке. Наши и другие тесты показали, что Google не будет сканировать URL-адрес, который он находит в ссылке nofollowed.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница отображается в файле Sitemap, эта страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL, о котором уже знают поисковые системы, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и представил два новых атрибута ссылки, а именно:
- rel = «sponsored» — Атрибут sponsored следует использовать для идентификации ссылок, предназначенных для рекламных целей, при наличии соглашений о спонсорстве и компенсации.
- rel = «ugc» — В качестве атрибута для пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например для сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, sponsored или ugc, теперь обрабатываются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как раньше использовалось для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние и мнения экспертов.
Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние и мнения экспертов.
Что такое Noindex Nofollow?
Как упоминалось выше, добавление тега nofollow к странице не препятствует ее полному сканированию.Поэтому, чтобы предотвратить индексирование, вам также нужно не индексировать страницу. Это позволит Google сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вам также следует запретить это (см. Выше).
Другие директивы: Canonical Tags, Pagination и Hreflang
Есть и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса:
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать.Канонизированные (т. Е. Вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента предназначены для какого региона, чтобы они могли определить приоритетность правильной версии для каждой аудитории.Все эти версии останутся в индексе.
 Е. Вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
Е. Вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.Сколько времени вам следует потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны для SEO эффективность сканирования и бюджет сканирования, и, хотя обычной практикой является запрещение и noindex большие группы страниц, которые не имеют никакой пользы для поисковых систем или читателей (например, back -end кода, который используется только для работы сайта или некоторых типов дублированного контента), решение о том, скрывать ли много отдельных страниц, вероятно, не лучший вариант использования времени и усилий.
Google любит индексировать как можно больше URL-адресов, поэтому, если нет особой причины скрыть страницу от поисковых систем, обычно можно оставить решение на усмотрение Google. В любом случае, даже если вы скроете страницы от поисковых систем, Google все равно будет проверять, изменились ли эти URL-адреса. Это особенно актуально, если есть ссылки, указывающие на эту страницу; даже если Google забыл об URL-адресе, он может снова обнаружить его в следующий раз, когда на него будет найдена ссылка.
Тестирование с помощью Search Console, DeepCrawl и Robotto
Тестовые роботы.txt с помощью Search Console
Тестер robots.txt в Search Console (в разделе «Сканирование») — популярный и в значительной степени эффективный способ проверить новую версию вашего файла на наличие ошибок до того, как он будет опубликован, или проверить конкретный URL, чтобы убедиться, что он заблокирован:
Однако этот инструмент не работает точно так же, как Google, с некоторыми небольшими различиями в конфликтующих правилах разрешения / запрета, которые имеют одинаковую длину.
Инструмент тестирования robots.txt сообщает, что это разрешено, однако Google сказал: «Если результат не определен, robots.txt могут разрешить или запретить сканирование. По этой причине не рекомендуется полагаться на то, что какой-либо из результатов будет использоваться повсеместно ».
Подробнее читайте в этом обсуждении на справочном форуме в Центре веб-мастеров.
Найти все неиндексируемые страницы с помощью DeepCrawl
Запустите универсальное сканирование без каких-либо ограничений (но с применением условий robots.txt), чтобы DeepCrawl мог вернуть все ваши URL-адреса и показать вам все индексируемые / неиндексируемые страницы.
Если у вас есть параметры URL, которые были заблокированы для робота Google с помощью Search Console, вы можете имитировать эту настройку для сканирования, используя поле «Удалить параметры» в разделе Расширенные настройки> Перезапись URL .
Затем вы можете использовать следующие отчеты, чтобы убедиться, что сайт настроен так, как вы ожидали при первом сканировании, а затем объединить их со встроенными журналами изменений при последующих сканированиях.
Индексация> Страницы Noindex
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, HTTP-заголовке или файле robots.txt файл.
Индексация> Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за запрещающего правила в файле robots.txt. На панели управления вашего отчета есть цифры для обоих этих отчетов:
Используйте наши интуитивно понятные отчеты в каждом из наших отчетов, чтобы проверять определенные папки и выявлять шаблоны в URL-адресах, которые в противном случае вы могли бы пропустить:
Протестируйте новый файл robots.txt с помощью DeepCrawl
Используйте роботов DeepCrawl.txt Функция перезаписи в расширенных настройках для замены живого файла на пользовательский.
Затем при следующем запуске сканирования вы можете использовать тестовую версию вместо активной.
В отчетах о добавленных и удаленных запрещенных URL-адресах будет показано, какие именно URL-адреса были затронуты измененным файлом robots. txt, что упростит оценку.
txt, что упростит оценку.
Для получения дополнительной информации прочтите наше руководство по управлению изменениями robots.txt с помощью DeepCrawl.
Хотите больше такого?
Мы надеемся, что этот пост был полезен для вас, когда вы узнали больше о noindex, nofollow и disallow для управления сканированием вашего сайта.
Вы можете узнать больше об этих темах в нашей Технической библиотеке SEO или, если вы хотите узнать, как проводить технический SEO-аудит, прочитайте наше руководство.
Кроме того, если вы заинтересованы в том, чтобы быть в курсе последних обновлений Google и рекомендациями по передовому опыту, почему бы не заглянуть в наши электронные письма?
Loop Me In!
Автор
Сэм Марсден
Сэм Марсден — менеджер по поисковой оптимизации и контенту DeepCrawl.Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых публикаций, таких как Search Engine Journal и State of Digital.
Теги
Управление роботами
Robots.txt: Как создать идеальный файл для SEO
В этой статье мы расскажем, что такое robot.txt в SEO, как он выглядит и как его правильно создать. Это файл, который отвечает за блокировку индексации страниц и даже всего сайта.Неправильная структура файла — обычная ситуация даже среди опытных SEO-оптимизаторов, поэтому остановимся на типичных ошибках при редактировании robot.txt.
Что такое Robots.txt?
Robots.txt — это текстовый файл, информирующий поисковых роботов о том, какие файлы или страницы закрыты для сканирования и индексации. Документ размещается в корневом каталоге сайта.
Давайте посмотрим, как работает robot.txt. У поисковых систем две цели:
- Для сканирования сети для обнаружения контента;
- Индексировать найденный контент, чтобы показывать его пользователям по идентичным поисковым запросам.
Для индексации поисковый робот посещает URL-адреса с одного сайта на другой, просматривая миллиарды ссылок и веб-ресурсов.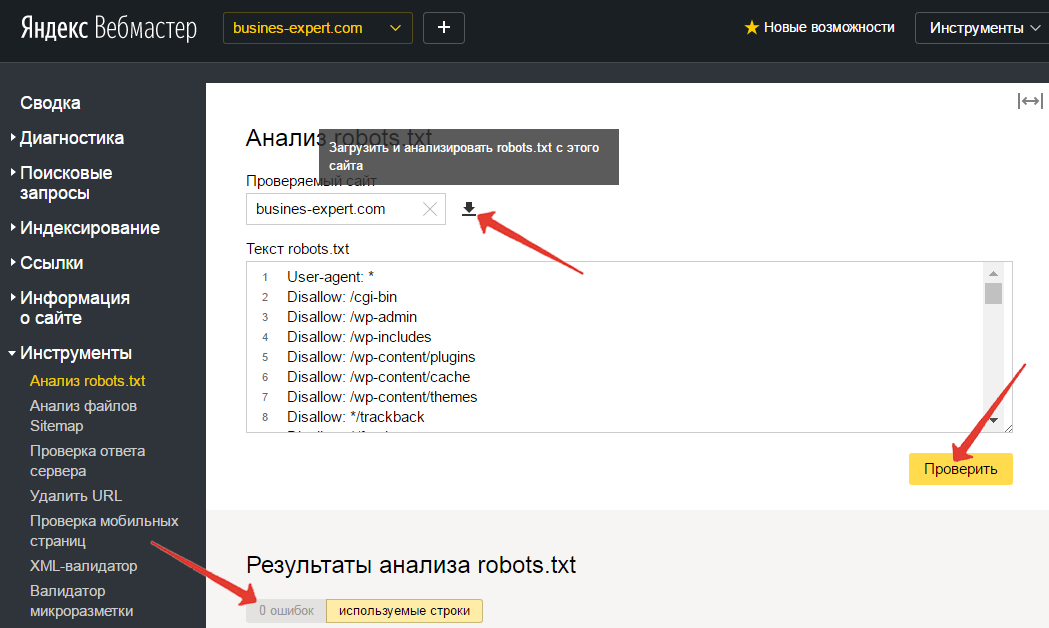 После открытия сайта система ищет файл robots.txt. Если сканер находит документ, он сначала сканирует его, а после получения от него инструкций продолжает сканирование страницы.
После открытия сайта система ищет файл robots.txt. Если сканер находит документ, он сначала сканирует его, а после получения от него инструкций продолжает сканирование страницы.
Если в файле нет директив или он не создается вообще, робот продолжит сканирование и индексацию без учета данных о том, как система должна выполнять эти действия.Это может привести к индексации нежелательного содержания поисковой системой.
Но многие SEO-специалисты отмечают, что некоторые поисковые системы игнорируют инструкции в файле robot.txt. Например, парсеры электронной почты и вредоносные robots. Google также не воспринимает документ как строгую директиву, но рассматривает его как рекомендацию при сканировании страницы.
User-agent и основные директивы
Агент пользователя
У каждой поисковой системы есть свои собственные пользовательские агенты.Robots.txt прописывает правила для каждого. Вот список самых популярных поисковых ботов:
- Google: Googlebot
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
При создании правила для всех поисковых систем используйте этот символ: (*). Например, давайте создадим бан для всех роботов, кроме Bing. В документе это будет выглядеть так:
Например, давайте создадим бан для всех роботов, кроме Bing. В документе это будет выглядеть так:
Пользовательский агент: *
Запрещено: /
Пользовательский агент: Bing
Разрешить: /
Роботы.txt может содержать различное количество правил для поисковых агентов. При этом каждый робот воспринимает только свои директивы. То есть, инструкции для Google, например, не актуальны для Yahoo или какой-либо другой поисковой системы. Исключение будет, если вы укажете один и тот же агент несколько раз. Тогда система выполнит все директивы.
Важно указать точные имена поисковых ботов; в противном случае роботы не будут следовать указанным правилам.
Директивы
Это инструкции по сканированию и индексации сайтов поисковыми роботами.
Поддерживаемые директивы
Это список директив, поддерживаемых Google:
1. Запретить
Позволяет закрыть доступ поисковых систем к контенту. Например, если вам нужно скрыть каталог и все его страницы от сканера для всех систем, то файл robots.txt будет иметь следующий вид:
Например, если вам нужно скрыть каталог и все его страницы от сканера для всех систем, то файл robots.txt будет иметь следующий вид:
Пользовательский агент: *
Запрещено: / catalog /
Если это для конкретного краулера, то это будет выглядеть так:
Пользовательский агент: Bingbot
Запрещено: / catalog /
Примечание: Укажите путь после директивы, иначе роботы его проигнорируют.
2. Разрешить
Это позволяет роботам сканировать определенную страницу, даже если она была ограничена. Например, вы можете разрешить поисковым системам сканировать только одно сообщение в блоге:
.
Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Также можно указать robots.txt, чтобы разрешить весь контент:
Пользовательский агент: *
Разрешить: /
Примечание. Поисковые системы Google и Bing поддерживают эту директиву.Как и в случае с предыдущей директивой, всегда указывайте путь после , разрешите .
Поисковые системы Google и Bing поддерживают эту директиву.Как и в случае с предыдущей директивой, всегда указывайте путь после , разрешите .
Если вы ошиблись в robots.txt, запретят и разрешат будут конфликтовать. Например, если вы упомянули:
Пользовательский агент: *
Disallow: / blog / что такое SEO
Разрешить: / blog / что такое SEO
Как видите, URL разрешен и запрещен для индексации одновременно. Поисковые системы Google и Bing будут отдавать приоритет директиве с большим количеством символов.В данном случае это , запретить . Если количество символов одинаково, то будет использоваться директива allow , то есть ограничивающая директива.
Другие поисковые системы выберут первую директиву из списка. В нашем примере это , запрещает .
3. Карта сайта
Карта сайта, указанная в robots.txt, позволяет поисковым роботам указывать адрес карты сайта.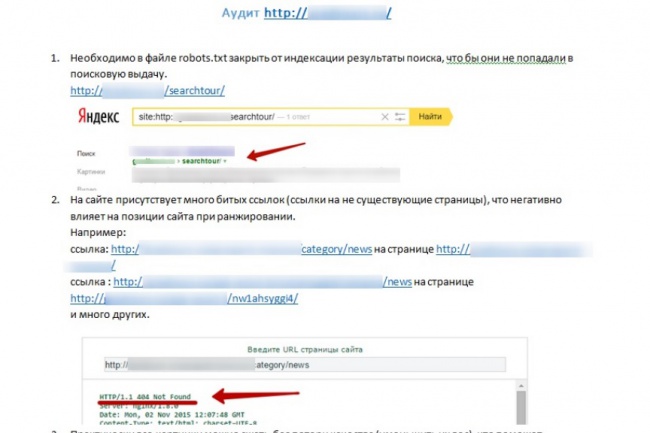 Вот пример такого файла robots.txt:
Вот пример такого файла robots.txt:
Карта сайта: https: // www.site.com/sitemap.xml
Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Если карта сайта указана в Google Search Console, то этой информации Google будет достаточно. Но другие поисковые системы, такие как Bing, ищут его в robots.txt.
Не нужно повторять директиву для разных роботов, она работает для всех. Рекомендуем записать его в начале файла.
Примечание : вы можете указать любое количество карт сайта.
Вы также можете прочитать соответствующую статью XML-руководство по файлам Sitemap: лучшие приемы, советы и инструменты.
Директивы без поддержки
1. Задержка сканирования
Ранее директива показывала задержку между сканированиями. Google в настоящее время не поддерживает его, но может быть указан для Bing. Для робота Googlebot скорость сканирования указывается в консоли поиска Google.
Например:
Пользовательский агент: Bingbot
Задержка сканирования: 10
2.Noindex
Для робота Googlebot в файле robots.txt noindex никогда не поддерживался. Мета-теги роботов используются для исключения страницы из поисковой системы.
3. Nofollow
Это не поддерживается Google с прошлого года. Вместо этого используется атрибут URL rel = «nofollow».
Примеры robots.txt
Рассмотрим пример стандартного файла robot.txt:
Карта сайта: https://www.site.com/sitemap.xml
Пользовательский агент: Googlebot
Запретить: / blog /
Разрешить: / blog / что такое SEO
Пользовательский агент: Bing
Запретить: / blog /
Разрешить: / blog / что такое SEO
Примечание: Вы можете указать любое количество пользовательских агентов и директив по своему усмотрению. Всегда пишите команды с новой строки.
Всегда пишите команды с новой строки.
Почему Robots.txt важен для SEO?
Файл
Robots txt для SEO играет важную роль, поскольку он позволяет вам давать инструкции поисковым роботам, какие страницы вашего сайта следует сканировать, а какие нет. Кроме того, файл позволяет:
- Избегайте дублирования контента в результатах поиска;
- Блокировать закрытые страницы; например, если вы создали промежуточную версию;
- Запретить индексирование определенных файлов, например PDF-файлов или изображений; и
- Увеличьте бюджет сканирования Google.Это количество страниц, которые может сканировать робот Googlebot. Если на сайте их много, то поисковому роботу потребуется больше времени, чтобы просмотреть весь контент. Это может негативно повлиять на рейтинг сайта. Вы можете закрыть неприоритетные страницы со сканера, чтобы бот мог проиндексировать только те страницы, которые важны для продвижения.
Если на вашем сайте нет контента для управления доступом, возможно, вам не потребуется создавать файл robots. txt. Но мы все же рекомендуем создать его, чтобы лучше оптимизировать свой сайт.
txt. Но мы все же рекомендуем создать его, чтобы лучше оптимизировать свой сайт.
Robots.txt и Мета-теги роботов
Мета-теги robots не являются директивами robots.txt; они являются фрагментами HTML-кода. Это команды для поисковых роботов, которые позволяют сканировать и индексировать контент сайта. Они добавляются в раздел страницы.
Мета-теги роботов состоят из двух частей:
- name = ”‘. Здесь нужно ввести название поискового агента, например, Bingbot.
- content = ». Вот инструкции, что должен делать бот.
Итак, как выглядят роботы? Взгляните на наш пример:
Существует два типа мета-тегов роботов:
- Тег Meta Robots: указывает поисковым системам, как сканировать определенные файлы, страницы и подпапки сайта.
- Тег X-robots: фактически выполняет ту же функцию, но в заголовках HTTP. Многие эксперты склоняются к мнению, что теги X-robots более функциональны, но требуют открытого доступа к файлам . php и .htaccess или к серверу. Поэтому использовать их не всегда возможно.
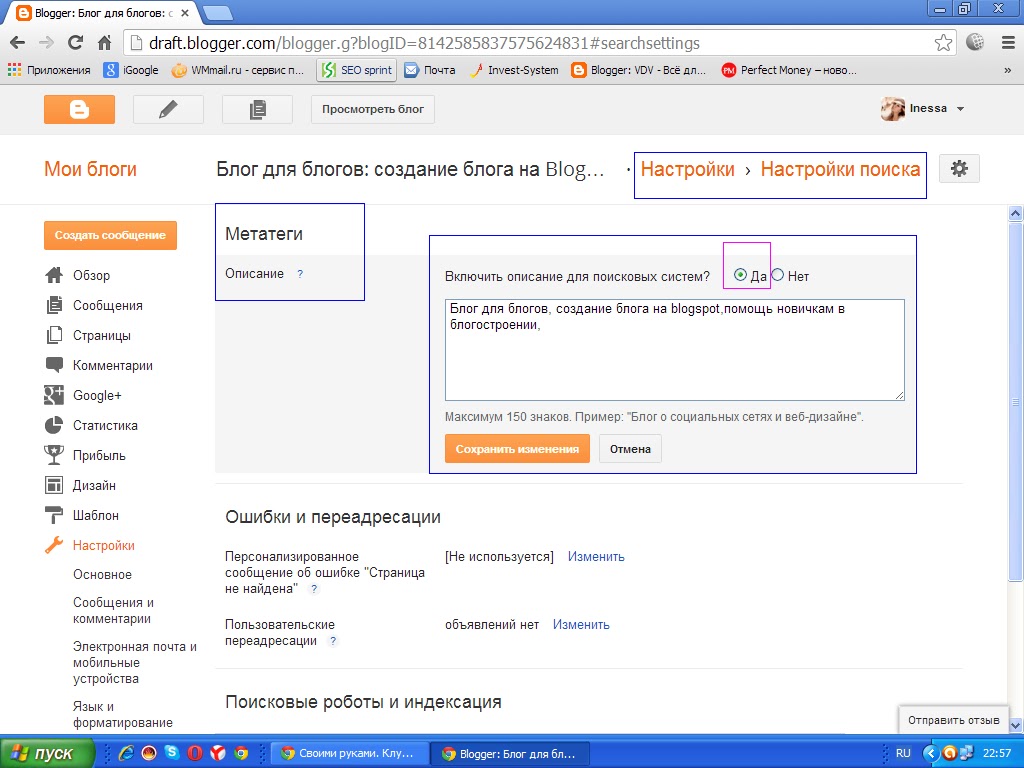 php и .htaccess или к серверу. Поэтому использовать их не всегда возможно.
php и .htaccess или к серверу. Поэтому использовать их не всегда возможно.В таблице ниже приведены основные директивы для мета-тегов роботов с учетом поисковых систем.
Содержимое файла robots.txt должно соответствовать мета-тегам robots.Самая распространенная ошибка, которую допускают SEO-оптимизаторы: в robots.txt закрывают страницу от сканирования, а в данных мета-тегов роботов открывают.
Многие поисковые системы, включая Google, отдают приоритет содержанию robots.txt, чтобы важную страницу можно было скрыть от индексации. Вы можете исправить это несоответствие, изменив содержание в метатегах robots и в документе robots.txt.
Как найти Robots.txt?
Robots.txt можно найти во внешнем интерфейсе сайта.Этот способ подходит для любого сайта. Его также можно использовать для просмотра файла любого другого ресурса. Просто введите URL-адрес сайта в строку поиска своего браузера и добавьте в конце /robots.txt. Если файл найден, вы увидите:
Нил Патель
Или откроется пустой файл, как в примере ниже:
Нил Патель
Также вы можете увидеть сообщение об ошибке 404, например, здесь:
MOZ
Если при проверке robots. txt на своем сайте, вы обнаружили пустую страницу или ошибку 404, значит, файл для ресурса не был создан или в нем были ошибки.
txt на своем сайте, вы обнаружили пустую страницу или ошибку 404, значит, файл для ресурса не был создан или в нем были ошибки.
Для сайтов, разработанных на базе CMS WordPress и Magento 2, есть альтернативные способы проверки файла:
- Вы можете найти robots.txt WordPress в разделе WP-admin. На боковой панели вы найдете один из плагинов Yoast SEO, Rank Math или All in One SEO, которые генерируют файл. Подробнее читайте в статьях Yoast против Rank Math SEO, Пошаговое руководство по установке плагина Rank Math, Настройка плагинов SEO, Yoast против All in One SEO Pack.
- В Magento 2 файл можно найти в разделе Content-Configuration на вкладке Design.
Для платформы Shopware сначала необходимо установить плагин, который позволит вам создавать и редактировать robots.txt в будущем.
Как создать Robots.txt
Для создания robots.txt вам понадобится любой текстовый редактор. Чаще всего специалисты выбирают Блокнот Windows. Если этот документ уже был создан на сайте, но вам нужно его отредактировать, удалите только его содержимое, а не весь документ.
Вне зависимости от ваших целей формат документа будет выглядеть как стандартный образец robot.txt:
Карта сайта: URL – адрес (рекомендуем всегда указывать)
user – agent: * (или укажите имя определенного поискового бота)
Disallow: / (путь к контенту, который вы хотите скрыть)
Затем добавьте оставшиеся директивы в необходимом количестве.
Вы можете ознакомиться с полным руководством от Google по созданию правил для поисковых роботов здесь.Информация обновляется, если поисковая система вносит изменения в алгоритм создания документа.
Сохраните файл под именем robot.txt.
Для создания файла можно использовать генератор robots.txt.
Инструменты SEO Книга
Основным преимуществом этой услуги является то, что она помогает избежать синтаксических ошибок.
Где разместить Robots.txt?
Файл robots.txt по умолчанию находится в корневой папке сайта. Управлять сканером на сайте.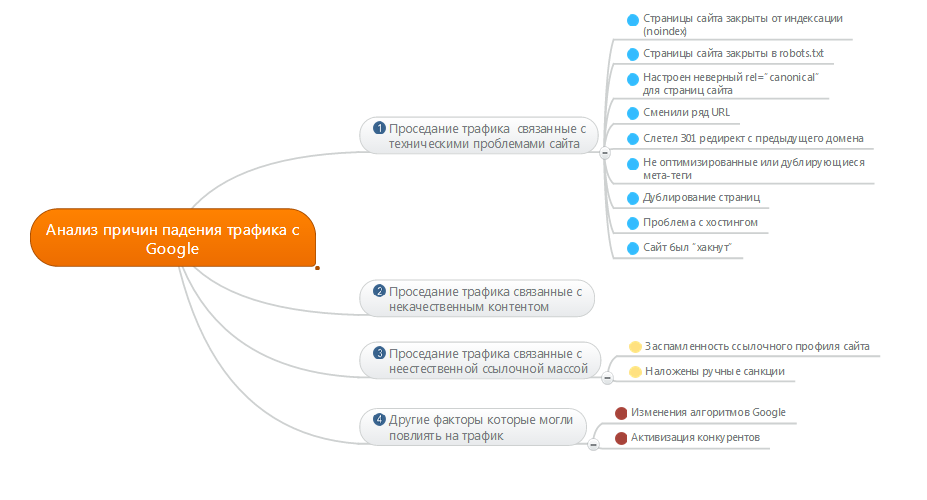 com, документ должен находиться по адресу sitename.com/robots.txt.
com, документ должен находиться по адресу sitename.com/robots.txt.
Если вы хотите контролировать сканирование контента на субдоменах, например, blog.sitename.com, документ должен находиться по этому URL-адресу: blog.sitename.com/robots.txt.
Используйте любой FTP-клиент для подключения к корневому каталогу.
Лучшие практики оптимизации Robots.txt для SEO
- Маски (*) можно использовать для указания не только всех поисковых роботов, но и идентичных URL-адресов на сайте. Например, если вы хотите закрыть от индексации все категории продуктов или разделы блога с определенными параметрами, то вместо их перечисления вы можете сделать следующее:
user – agent: *
Запретить: / blog / *?
Боты не будут сканировать все адреса в подпапке / blog / со знаком вопроса.
- Не используйте документ robots.txt для скрытия конфиденциальной информации в результатах поиска. Иногда другие страницы могут ссылаться на контент вашего сайта, и данные будут индексироваться в обход директив. Чтобы заблокировать страницу, используйте пароль или NoIndex.
- В некоторых поисковых системах есть несколько ботов. Например, у Google есть агент для общего поиска контента — Googlebot и Googlebot-Image, который сканирует изображения. Рекомендуем прописать директивы для каждого из них, чтобы лучше контролировать процесс сканирования на сайте.
- Используйте символ $ для обозначения конца URL-адресов. Например, если вам нужно отключить сканирование файлов PDF, директива будет выглядеть так: Disallow: / * .pdf $.
- Вы можете скрыть версию страницы для печати, так как это технически дублированный контент. Сообщите ботам, какой из них можно сканировать. Это полезно, если вам нужно протестировать страницы с одинаковым содержанием, но с разным дизайном.
- Обычно при внесении изменений содержимое robots.txt кэшируется через 24 часа. Можно ускорить этот процесс, отправив адрес файла в Google.
- При написании правил указывайте путь как можно точнее. Например, предположим, что вы тестируете французскую версию сайта, находящуюся в подпапке / fr /. Если вы напишете такую директиву: Disallow: / fr, вы закроете доступ к другому контенту, который начинается с / fr. Например: / французская парфюмерия /. Поэтому всегда добавляйте «/» в конце.
- Для каждого поддомена необходимо создать отдельный файл robots.txt.
- Вы можете оставлять в документе комментарии оптимизаторам или себе, если вы работаете над несколькими проектами.Чтобы ввести текст, начните строку с символа «#».
 Чтобы заблокировать страницу, используйте пароль или NoIndex.
Чтобы заблокировать страницу, используйте пароль или NoIndex. Например, предположим, что вы тестируете французскую версию сайта, находящуюся в подпапке / fr /. Если вы напишете такую директиву: Disallow: / fr, вы закроете доступ к другому контенту, который начинается с / fr. Например: / французская парфюмерия /. Поэтому всегда добавляйте «/» в конце.
Например, предположим, что вы тестируете французскую версию сайта, находящуюся в подпапке / fr /. Если вы напишете такую директиву: Disallow: / fr, вы закроете доступ к другому контенту, который начинается с / fr. Например: / французская парфюмерия /. Поэтому всегда добавляйте «/» в конце.Как проверить файл robots.txt
Проверить корректность созданного документа можно в Google Search Console. Поисковая система предлагает бесплатный тестер robots.txt.
Чтобы начать процесс, откройте свой профиль для веб-мастеров.
Выберите нужный веб-сайт и нажмите кнопку «Сканировать» на левой боковой панели.
Нил Патель
Вы получите доступ к сервису роботов Google.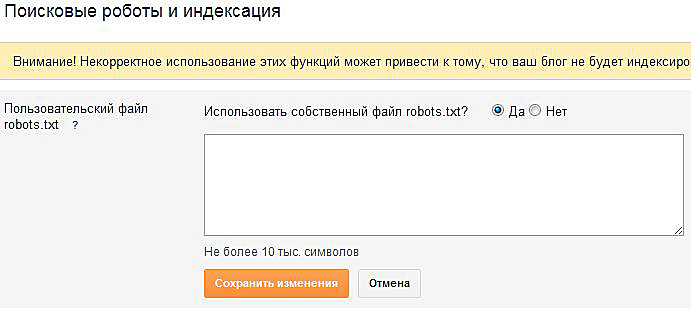 txt тестер.
txt тестер.
Нил Патель
Если адрес robots.txt уже был введен в поле, удалите его и введите свой собственный. Нажмите кнопку test в правом нижнем углу.
Нил Патель
Если текст изменится на «разрешено», значит ваш файл был создан правильно.
Вы также можете протестировать новые директивы прямо в инструменте, чтобы проверить, насколько они верны. Если ошибок нет, вы можете скопировать текст и добавить его в файл robots.txt документ. Подробные инструкции по использованию сервиса читайте здесь.
Распространенные ошибки в файлах Robots.txt
Ниже приведен список наиболее распространенных ошибок, которые допускают веб-мастера при работе с файлом robots.txt.
- Имя состоит из прописных букв. Файл называется просто robots.txt. Не используйте заглавные буквы.
- Он содержит неверный формат поискового агента. Например, некоторые специалисты пишут имя бота в директиве: Disallow: Googlebot. Всегда указывайте роботов после строки пользовательского агента.
- Каждый каталог, файл или страницу следует записывать с новой строки. Если вы добавите их в один, боты проигнорируют данные.
- Правильно напишите директиву host, если она вам нужна в работе.
 Всегда указывайте роботов после строки пользовательского агента.
Всегда указывайте роботов после строки пользовательского агента.Неправильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Правильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Хост: www.sitename.com
5. Неверный заголовок HTTP.
Неправильно:
Content-Type: text / html
Правильно:
Content-Type: text / plain
Не забудьте проверить отчет об охвате в Google Search Console. Там будут отображаться ошибки в документе.
Рассмотрим самые распространенные.
1. Доступ к URL-адресу заблокирован:
Эта ошибка появляется, когда один из URL-адресов в карте сайта заблокирован роботами.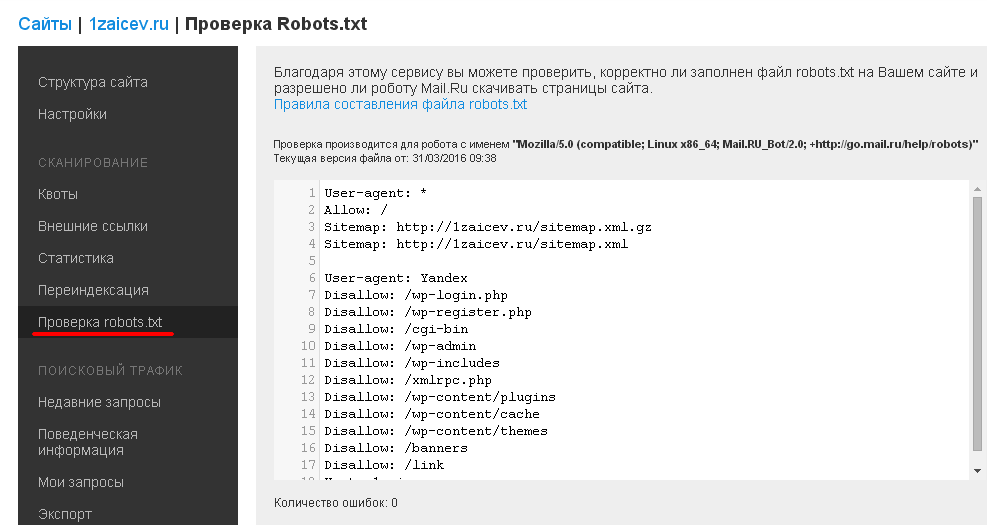 текст. Вам необходимо найти эти страницы и внести в файл изменения, чтобы снять запрет на сканирование. Чтобы найти директиву, блокирующую URL, вы можете использовать тестер robots.txt от Google. Основная цель — исключить дальнейшие ошибки при блокировке приоритетного контента.
текст. Вам необходимо найти эти страницы и внести в файл изменения, чтобы снять запрет на сканирование. Чтобы найти директиву, блокирующую URL, вы можете использовать тестер robots.txt от Google. Основная цель — исключить дальнейшие ошибки при блокировке приоритетного контента.
2. Запрещено в robots.txt:
Сайт содержит контент, заблокированный файлом robots.txt и не индексируемый поисковой системой. Если эти страницы необходимы, то вам необходимо снять блокировку, убедившись, что страница не запрещена для индексации с помощью noindex.
Если вам нужно закрыть доступ к странице или файлу, чтобы исключить их из индекса поисковой системы, мы рекомендуем использовать метатег robots вместо директивы disallow. Это гарантирует положительный результат. Если не снять блокировку сканирования, то поисковая система не найдет noindex, и контент будет проиндексирован.
3. Контент индексируется без блокировки в документе robots.txt:
Некоторые страницы или файлы могут все еще присутствовать в индексе поисковой системы, несмотря на то, что они запрещены в robots. текст. Возможно, вы случайно заблокировали нужный контент. Чтобы исправить это, исправьте документ. В других случаях для вашей страницы следует использовать метатег robots = noindex. Подробнее читайте в статье Возможности ссылок Nofollow. Новая тактика SEO.
текст. Возможно, вы случайно заблокировали нужный контент. Чтобы исправить это, исправьте документ. В других случаях для вашей страницы следует использовать метатег robots = noindex. Подробнее читайте в статье Возможности ссылок Nofollow. Новая тактика SEO.
Как закрыть страницу из индексации в Robots.txt
Одна из основных задач robots.txt — скрыть определенные страницы, файлы и каталоги от индексации в поисковых системах. Вот несколько примеров того, какой контент чаще всего блокируется от ботов:
- Дублированный контент;
- страниц пагинации;
- Категории товаров и услуг;
- Контентные страницы для модераторов;
- Интернет-корзины для покупок;
- Чаты и формы обратной связи; и
- Страницы благодарности.
Чтобы предотвратить сканирование содержимого, следует использовать директиву disallow. Давайте рассмотрим примеры того, как можно заблокировать поисковым агентам доступ к различным типам страниц.
1. Если вам нужно закрыть определенную подпапку:
user – agent: (укажите имя бита и добавьте *, если правило должно применяться ко всем поисковым системам)
Disallow: / name – subfolder /
2. Если закрыть определенную страницу на сайте:
user – agent: (* или имя робота)
Disallow: / name –subfolder / page.HTML
Вот пример того, как интернет-магазин указывает запрещающие директивы:
Журнал поисковых систем
Оптимизаторы заблокировали весь контент и страницы, которые не являются приоритетными для продвижения в результатах поиска. Это увеличивает краулинговый бюджет некоторых поисковых роботов, например Googlebot. Это действие позволит улучшить рейтинг сайтов в будущем, конечно, с учетом других важных факторов.
Мы не рекомендуем скрывать конфиденциальную информацию с помощью директивы disallow, так как вредоносные системы могут обойти блокировку.
Добавить комментарий