
Как полностью скрыть сайт от индексации?
Про то, как закрыть от индексации отдельную страницу и для чего это нужно мы уже писали. Но могут возникнуть случаи, когда от индексации надо закрыть весь сайт или зеркало, что проблематичнее. Существует несколько способов. О них мы сегодня и расскажем.
Существует несколько способов закрыть сайт от индексации.
Запрет в файле robots.txt
Файл robots.txt отвечает за индексацию сайта поисковыми роботами. Найти его можно в корневой папке сайта. Если же его не существует, то его необходимо создать в любом текстовом редакторе и перенести в нужную директорию. В файле должны находиться всего лишь две строчки:
User-agent: *
Disallow: /
Остальные правила должны быть удалены.
Этот метод самый простой для скрытия сайта от индексации.
С помощью мета-тега robots
Прописав в шаблоне страниц сайта следующее правило <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/> в теге <head>, вы запретите его индексацию.
Как закрыть зеркало сайта от индексации
Зеркало — точная копия сайта, доступная по другому домену. Т.е. два разных домена настроены на одну и ту же папку с сайтом. Цели создания зеркал могут быть разные, но в любом случае мы получаем полную копию сайта, которую рекомендуется закрыть от индексации.
Сделать это стандартными способами невозможно, т.к. по адресам domen1.ru/robots.txt и domen2.ru/robots.txt открывается один и тот же файл robots.txt с одинаковым содержанием. В таком случае необходимо провести специальные настройки на сервере, которые позволят одному из доменов отдавать запрещающий robots.txt.
#104
Февраль’19
1289
21
#94
Декабрь’18
3379
28
#60
Февраль’18
3961
19
Как закрыть сайт или его страницы от индексации: подробная инструкция
Что нужно закрывать от индексации
Важно, чтобы в поисковой выдаче были исключительно целевые страницы, соответствующие запросам пользователей. Поэтому от индексации в обязательном порядке нужно закрывать:
Поэтому от индексации в обязательном порядке нужно закрывать:
1. Бесполезные для посетителей страницы или контент, который не нужно индексировать. В зависимости от CMS, это могут быть:
- страницы административной части сайта;
- страницы с личной информацией пользователей, например, аккаунты в блогах и на форумах;
- дубли страниц;
- формы регистрации, заказа, страница корзины;
- страницы с неактуальной информацией;
- версии страниц для печати;
- RSS-лента;
- медиа-контент;
- страницы поиска и т.д.
2. Страницы с нерелевантным контентом на сайте, который находится в процессе разработки.
3. Страницы с информацией, предназначенной для определенного круга лиц, например, корпоративные ресурсы для взаимодействий между сотрудниками одной компании.
4. Сайты-аффилиаты.
Если вы закроете эти страницы, процесс индексации других, наиболее важных для продвижения страниц сайта ускорится.
Способы закрытия сайта от индексации
Закрыть сайт или страницы сайта от поисковых краулеров можно следующими способами:
- С помощью файла robots.txt и специальных директив.
- Добавив метатеги в HTML-код отдельной страницы.
- С помощью специального кода, который нужно добавить в файл .htaccess.
- Воспользовавшись специальными плагинами (если сайт сделан на популярной CMS).
Далее рассмотрим каждый из этих способов.
С помощью robots.txt
Robots.txt — текстовый файл, который поисковые краулеры посещают в первую очередь. Здесь для них прописываются указания — так называемые директивы.
Этот файл должен соответствовать следующим требованиям:
- название файла прописано в нижнем регистре;
- он имеет формат .
 txt;
txt; - его размер не превышает 500 КБ;
- находится в корне сайте;
- файл доступен по адресу URL сайта/robots.txt, а при его запросе сервер отправляет в ответ код 200 ОК.
 txt;
txt;
В robots.txt прописываются такие директивы:
- User-agent. Показывает, для каких именно роботов предназначены директивы.
- Disallow. Указывает роботу на то, что некоторое действие (например, индексация) запрещено.
- Allow. Напротив, разрешает совершать действие.
- Sitemap. Указывает на прямой URL-адрес карты сайта.
- Clean-param. Помогает роботу Яндекса правильно определять страницу для индексации.
Имейте в виду: поскольку информация в файле robots.txt — это скорее указания или рекомендации, нежели строгие правила, некоторые системы могут их игнорировать. В таком случае в индекс попадут все страницы вашего сайта.
Полный запрет сайта на индексацию в robots.
 txt
txt
Вы можете запретить индексировать сайт как всем роботам поисковой системы, так и отдельно взятым. Например, чтобы закрыть весь сайт от робота Яндекса, который сканирует изображения, нужно прописать в файле следующее:
User-agent: YandexImages Disallow: /
Чтобы закрыть для всех роботов:
User-agent: * Disallow: /
Чтобы закрыть для всех, кроме указанного:
User-agent: * Disallow: / User-agent: Yandex Allow: /
В данном случае, как видите, индексация доступна для роботов Яндекса.
Запрет на индексацию отдельных страниц и разделов сайта
Для запрета на индексацию одной страницы достаточно прописать ее URL-адрес (домен не указывается) в директиве файла:
User-agent: * Disallow: /registration.html
Чтобы закрыть раздел или категорию:
User-agent: * Disallow: /category/
Чтобы закрыть все, кроме указанной категории:
User-agent: * Disallow: / Allow: /category
Чтобы закрыть все категории, кроме указанной подкатегории:
User-agent: * Disallow: /uslugi Allow: /uslugi/main
В качестве подкатегории здесь выступает «main».
Запрет на индексацию прочих данных
Чтобы скрыть директории, в файле нужно указать:
User-agent: * Disallow: /portfolio/
Чтобы скрыть всю директорию, за исключением указанного файла:
User-agent: * Disallow: /portfolio/ Allow: avatar.png
Чтобы скрыть UTM-метки:
User-agent: * Disallow: *utm=
Чтобы скрыть скриптовые файлы, нужно указать следующее:
User-agent: * Disallow: /scripts/*.ajax
По такому же принципу скрываются файлы определенного формата:
User-agent: * Disallow: /*.png
Вместо .png подставьте любой другой формат.
Через HTML-код
Запретить индексировать страницу можно также с помощью метатегов в блоке <head> в HTML-коде.
Атрибут «content» здесь может содержать следующие значения:
- index. Разрешено индексировать все содержимое страницы;
- noindex. Весь контент страницы, кроме ссылок, закрыт от индексации;
- follow. Разрешено индексировать ссылки;
- nofollow. Разрешено сканировать контент, но ссылки при этом закрыты от индексации;
- all. Все содержимое страницы подлежит индексации.
 Весь контент страницы, кроме ссылок, закрыт от индексации;
Весь контент страницы, кроме ссылок, закрыт от индексации;
Открывать и закрывать страницу и ее контент можно для краулеров определенной ПС. Для этого в атрибуте «name» нужно указать название робота:
- yandex — обозначает роботов Яндекса:
- googlebot — аналогично для Google.
Помимо прочего, существует метатег Meta Refresh. Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.
Так выглядит фрагмент кода, запрещающий индексировать страницу:
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>. Yandex" search_bot Yandex" search_bot
Yandex" search_botНа WordPress
В процессе создания сайта на готовой CMS нужно закрывать его от индексации. Здесь мы разберем, как сделать это в популярной CMS WordPress.
Закрываем весь сайт
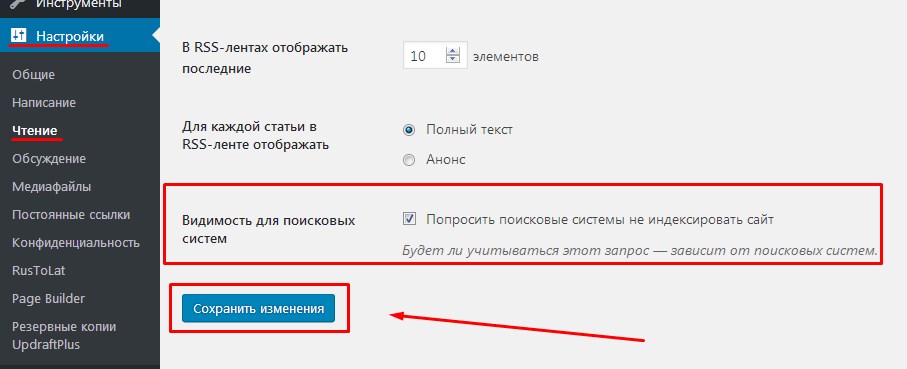
Закрыть весь сайт от краулеров можно в панели администратора: «Настройки» => «Чтение». Выберите пункт «Попросить поисковые системы не индексировать сайт». Далее система сама отредактирует файл robots.txt нужным образом.
Закрытие сайта от индексации через панель администратора в WordPress
Закрываем отдельные страницы с помощью плагина Yoast SEO
Чтобы закрыть от индексации как весь сайт, так и его отдельные страницы или файлы, установите плагин Yoast SEO.
Для запрета на индексацию вам нужно:
- Открыть страницу для редактирования и пролистать ее вниз до окна плагина.
- Настроить режим индексации на вкладке «Дополнительно».
Закрытие от индексации с помощью плагина Yoast SEO
Настройка режима индексации
Запретить индексацию сайта на WordPress можно также через файл robots. txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
Как узнать, закрыт ли сайт от индексации
Есть несколько способов, которыми вы можете воспользоваться, чтобы проверить, закрыт ли ваш сайт или его отдельная страница от индексации или нет. Ниже рассмотрим самые простые и удобные из них.
В Яндекс.Вебмастере
Для проверки вам нужно пройти верификацию в Яндексе, зайти в Вебмастер, в правом верхнем углу найти кнопку «Инструменты», нажать и выбрать «Проверка ответа сервера».
Проверка возможности индексации страницы в Яндекс.Вебмастере
В специальное поле на открывшейся странице вставляем URL интересующей страницы. Если страница закрыта от индексации, то появится соответствующее уведомление.
Так выглядит уведомление о запрете на индексацию страницы
Таким образом можно проверить корректность работы файла robots.txt или плагина для CMS.
В Google Search Console
Зайдите в Google Search Console, выберите «Проверка URL» и вставьте адрес вашего сайта или отдельной страницы.
Проверка возможности индексации в Google Search Console
С помощью поискового оператора
Введите в поисковую строку следующее: site:https:// + URL интересующего сайта/страницы. В результатах вы увидите количество проиндексированных страниц и так поймете, индексируется ли сайт поисковой системой или нет.
Проверка индексации сайта в Яндексе с помощью специального оператора
Проверка индексации отдельной страницы
С помощью такого же оператора проверить индексацию можно и в Google.
С помощью плагинов для браузера
Мы рекомендуем использовать RDS Bar. Он позволяет увидеть множество SEO-показателей сайта, в том числе статус индексации страницы в основных поисковых системах.
Плагин RDS Bar
Итак, теперь вы знаете, когда сайт или его отдельные страницы/элементы нужно закрывать от индексации, как именно это можно сделать и как проводить проверку, и можете смело применять новые знания на практике.
Какие страницы сайта следует закрывать от индексации поисковых систем
Индексирование сайта – это процесс, с помощью которого поисковые системы, подобные Google и Yandex, анализируют страницы веб-ресурса и вносят их в свою базу данных. Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
В сегодняшней статье я рассмотрю, как правильно настроить индексацию, какие страницы нужно открывать для роботов, а какие нет.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу. Вот некоторые из них:
- Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти. В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
- Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Что нужно скрывать от поисковиков
В первую очередь стоит ограничить индексирование всего сайта, который еще находится на стадии разработки. Именно так можно уберечь базу данных поисковых систем от некорректной информации. Если ваш веб-ресурс давно функционирует, но вы не знаете, какой контент стоит исключить из поисковой выдачи, то рекомендуем ознакомиться с нижеуказанными инструкциями.
PDF и прочие документы
Часто на сайтах выкладываются различные документы, относящиеся к контенту определенной страницы (такие файлы могут содержать и важную информацию, например, политику конфиденциальности).
Рекомендуется отслеживать поисковую выдачу: если заголовки PDF-файлов отображаются выше в рейтинге, чем страницы со схожим запросом, то их лучше скрыть, чтобы открыть доступ к наиболее релевантной информации. Отключить индексацию PDF и других документов вы можете в файле robots.txt.
Разрабатываемые страницы
Стоит всегда избегать индексации разрабатываемых страниц, чтобы рейтинг сайта не снизился. Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Копии сайта
Если вам потребовалось создать копию веб-ресурса, то в этом случае также необходимо все правильно настроить. В первую очередь укажите корректное зеркало с помощью 301 редиректа. Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Веб-страницы для печати
Иногда контент сайта требует уникальных функций, которые могут быть полезны для клиентов. Одной из таких является «Печать», позволяющая распечатать необходимые страницы на принтере. Создание такой версии страницы выполняется через дублирование, поэтому поисковые роботы могут с легкостью установить копию как приоритетную. Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name=»robots» content=»noindex, follow»/> либо в файле robots.txt.
Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name=»robots» content=»noindex, follow»/> либо в файле robots.txt.
Формы и прочие элементы сайта
Большинство сайтов сейчас невозможно представить без таких элементов, как личный кабинет, корзина пользователя, форма обратной связи или регистрации. Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Страницы служебного пользования
Формы авторизации в панель управления и другие страницы, используемые администратором сайта, не несут никакой важной информации для обычного пользователя. Поэтому все служебные страницы следует исключить из индексации.
Личные данные пользователя
Вся персональная информация должна быть надежно защищена – позаботиться о ее исключении из поисковой выдачи нужно незамедлительно. Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Страницы с результатами поиска по сайту
Как и в случае со страницами, содержащими личные данные пользователей, индексация такого контента не нужна: веб-страницы результатов полезны для клиента, но не для поисковых систем, так как содержат неуникальное содержание.
Сортировочные страницы
Контент на таких веб-страницах обычно дублируется, хоть и частично. Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Пагинация на сайте
Пагинация – без нее сложно представить существование любого крупного веб-сайта. Чтобы понять ее назначение, приведу небольшой пример: до появления типичных книг использовались свитки, на которых прописывался текст. Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Пагинация позволяет разделить большой массив данных на отдельные страницы для удобства использования. Отключать индексирование для такого типа контента нежелательно, требуется только настроить атрибуты rel=»canonical», rel=»prev» и rel=»next». Для Google нужно указать, какие параметры разбивают страницы – сделать это можно в Google Search Console в разделе «Параметры URL».
Помимо всего вышесказанного, рекомендуется закрывать такие типы страниц, как лендинги для контекстной рекламы, страницы с результатами поиска по сайту и поиск по сайту в целом, страницы с UTM-метками.
Какие страницы нужно индексировать
Ограничение страниц для поисковых систем зачастую становится проблемой – владельцы сайтов начинают с этим затягивать или случайно перекрывают важный контент. Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
- В некоторых случаях могут появляться страницы-дубликаты. Часто это связано со случайным созданием дублирующих категорий, привязкой товаров к нескольким категориям и их доступность по различным ссылкам. Для такого контента не нужно сразу же бежать и отключать индексацию: сначала проанализируйте каждую страницу и посмотрите, какой объем трафика был получен. И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
- Страницы смарт-фильтра – благодаря им можно увеличить трафик за счет низкочастотных запросов. Важно, чтобы были правильно настроены мета-теги, 404 ошибки для пустых веб-страниц и карта сайта.
Соблюдение индексации таких страниц может значительно улучшить поисковую выдачу, если ранее оптимизация не проводилась.
Как закрыть страницы от индексации
Мы детально рассмотрели список всех страниц, которые следует закрывать от поисковых роботов, но о том, как это сделать, прошлись лишь вскользь – давайте это исправлять. Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Способ 1: Файл robots.txt
Данный текстовый документ – это файл, который первым делом посещают поисковики. Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет. Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
- наименование прописано в нижнем регистре;
- формат указан как .txt;
- размер не должен превышать 500 Кб;
- местоположение – корень сайта;
- находится по адресу URL/robots.txt, при запросе сервер отправляет в ответ код 200.
Прежде чем переходить к редактированию файла, рекомендую обратить внимание на ограничивающие факторы.
- Директивы robots.txt поддерживаются не всеми поисковыми системами. Большинство поисковых роботов следуют тому, что написано в данном файле, но не всегда придерживаются правил. Чтобы полностью скрыть информацию от поисковиков, рекомендуется воспользоваться другими способами.
- Синтаксис может интерпретироваться по-разному в зависимости от поисковой системы. Потребуется узнать о синтаксисе в правилах конкретного поисковика.
- Запрещенные страницы в файле могут быть проиндексированы при наличии ссылок из прочих источников. По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.
Файл robots.txt включает в себя такие параметры, как:
- User-agent – создает указание конкретному роботу.
- Disallow – дает рекомендацию, какую именно информацию не стоит сканировать.
- Allow – аналогичен предыдущему параметру, но в обратную сторону.
- Sitemap – позволяет указать расположение карты сайта sitemap.xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
- Clean-param – позволяет убрать из индекса страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
- Crawl-delay – снижает нагрузку на сервер в том случае, если посещаемость поисковых ботов слишком велика. Обычно используется на сайтах с большим количеством страниц.

Теперь давайте рассмотрим, как можно отключить индексацию определенных страниц или всего сайта. Все пути в примерах – условные.
Пропишите, чтобы исключить индексацию сайта для всех роботов:
User-agent: * Disallow: /
Закрывает все поисковики, кроме одного:
User-agent: * Disallow: / User-agent: Google Allow: /
Запрет на индексацию одной страницы:
User-agent: * Disallow: /page.
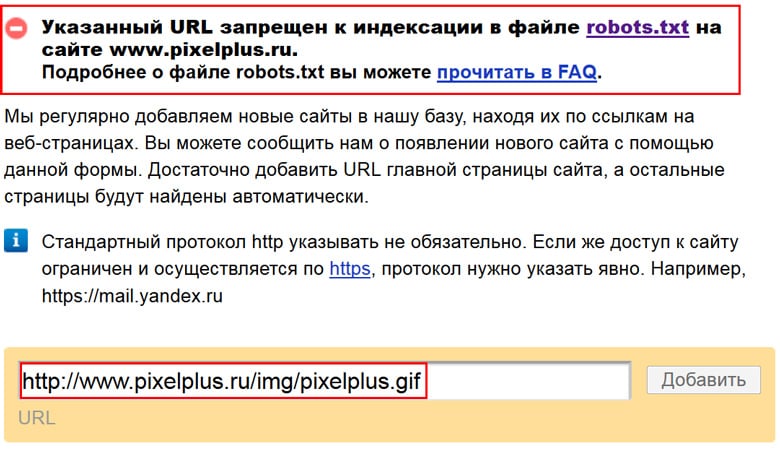 html
htmlЗакрыть раздел:
User-agent: * Disallow: /category
Все разделы, кроме одного:
User-agent: * Disallow: / Allow: /category
Все директории, кроме нужной поддиректории:
User-agent: * Disallow: /direct Allow: /direct/subdirect
Скрыть директорию, кроме указанного файла:
User-agent: * Disallow: /category Allow: photo.png
Заблокировать UTM-метки:
User-agent: * Disallow: *utm=
Заблокировать скрипты:
User-agent: * Disallow: /scripts/*.js
Я рассмотрел один из главных файлов, просматриваемых поисковыми роботами. Он использует лишь рекомендации, и не все правила могут быть корректно восприняты.
Способ 2: HTML-код
Отключение индексации можно осуществить также с помощью метатегов в блоке <head>. Обратите внимание на атрибут «content», он позволяет:
Обратите внимание на атрибут «content», он позволяет:
- активировать индексацию всей страницы;
- деактивировать индексацию всей страницы, кроме ссылок;
- разрешить индексацию ссылок;
- индексировать страницу, но запрещать ссылки;
- полностью индексировать веб-страницу.
Чтобы указать поискового робота, необходимо изменить атрибут «name», где устанавливается значение yandex для Яндекса и googlebot – для Гугла.
Пример запрета индексации всей страницы и ссылок для Google:
<html>
<head>
<meta name="googlebot" content="noindex, nofollow" />
</head>
<body>...</body>
</html>Также существует метатег под названием Meta Refresh. Он предотвращает индексацию в Гугле, однако использовать его не рекомендуется.
Способ 3: На стороне сервера
Если поисковые системы игнорируют запрет на индексацию, можно ограничить возможность посещения ботов-поисковиков на сервере. Yandex» search_bot
Yandex» search_bot
Способ 4: Для WordPress
На CMS запретить индексирование всего сайта или страницы гораздо проще. Рассмотрим, как это можно сделать.
Как скрыть весь сайт
Открываем административную панель WordPress и переходим в раздел «Настройки» через левое меню. Затем перемещаемся в «Чтение» – там находим пункт «Попросить поисковые системы не индексировать сайт» и отмечаем его галочкой.
В завершение кликаем по кнопке «Сохранить изменения» – после этого система автоматически отредактирует файл robots.txt.
Как скрыть отдельную страницу
Для этого необходимо установить плагин Yoast SEO. После этого открыть страницу для редактирования и промотать в самый низ – там во вкладке «Дополнительно» указать значение «Нет».
Способ 5: Сервисы для вебмастеров
В Google Search Console мы можем убрать определенную страницу из поисковика.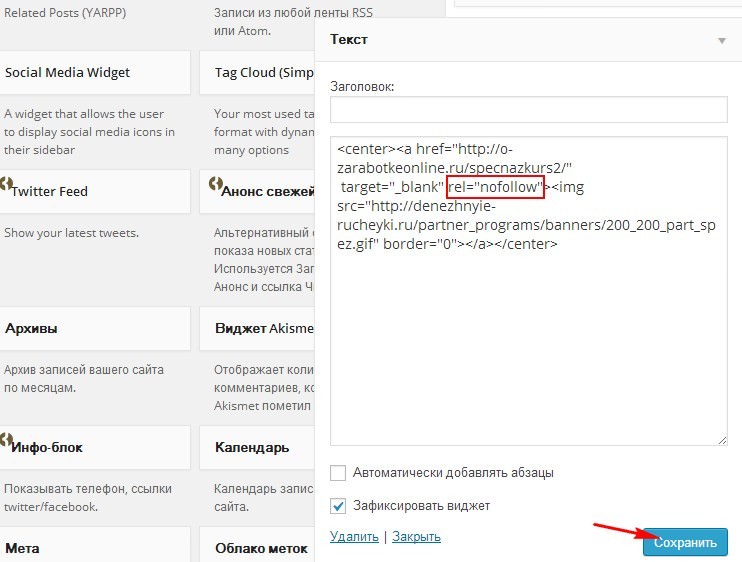 Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Процедура запрета на индексацию выбранной страницы может занять некоторое время. Аналогичные действия можно совершить в Яндекс.Вебмастере.
На этом статья подходит к концу. Надеюсь, что она была полезной. Теперь вы знаете, что такое индексация сайта и как ее правильно настроить. Удачи!
Закрыть сайт от индексации ᐈ Способы запретить индексацию
Содержание:
Индексация и способы закрыть информацию сайта
Индексация. Закрыть домен (или поддомен)
Индексация. Закрыть информацию по частям
Индексация. Закрыть отдельные страницы ресурса
Индексация и использование URL
Индексация и сомнительные способы закрытия контента
Индексация. Итоги
Индексация очень полезная вещь, однако бывают случаи, когда владельцам сайтов или вебмастерам нужно закрыть часть информации от индексации поисковых систем. Или же запретить обращение к ней. Часть из таких ситуаций можно перечислить:
Или же запретить обращение к ней. Часть из таких ситуаций можно перечислить:
- Необходимость закрыть техническую информацию.
- Запрещение индексации неуникальной информации.
- Закрыть страницы, которые для поискового робота выглядят как дубль другой страницы. При этом такие адреса могут быть полезны рядовому пользователю.
- Часто сайт может использовать на разных страницах повторяющуюся информацию. Для лучшей оптимизации сайта ее нужно закрыть от постороннего взгляда.
Есть несколько способов закрыть сайт от взгляда поисковика.
Используем robots.txt
В этом файле нужно прописать такие ряды:
User-agent: *
Disallow: /
От этого закрывается отображение домена для абсолютно всех поисковиков. Но если есть желание исключить лишь одну систему, следует указать ее название. Пример:
User-agent: Yahoo
Disallow: /
Также существует возможность запретить доступ всем поисковикам, кроме одного. Тогда оставляем строки без изменений, как в первом примере и ниже добавляем еще два ряда:
Тогда оставляем строки без изменений, как в первом примере и ниже добавляем еще два ряда:
User-agent: Yahoo
Allow: /
Минусом такого способа является не стопроцентная гарантия отсутствия индексации. Это маловероятно, но все же возможно. Для правильной корректировки роботс.txt используем онлайн-инструмент от Yandex. Держите ссылку http://webmaster.yandex.ru/robots.xml. Загружаем свой файл и сканируем его.
Использование мета-тега
Это очень легкий, но довольно затратный по времени метод. Особенно, если на вашем сайте существует большое количество страниц. Для его реализации необходимо в head нужных адресов указать ряды:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ абсолютно защищает ваш сайт от взгляда поисковиков. Его плюсом является отсутствия необходимости лезть роботс.
Индексация. Изменение атрибутов файла .htaccess
Этот способ позволяет закрыть доступ к ресурсу за паролем. В htaccess указываем ряды:
Такой способ также полностью закрывает доступ поисковикам к контенту сайта. Однако из-за наличия пароля сайт становится очень тяжело просканировать на наличие ошибок. Поскольку не все сервисы имеют возможность вводить пароль.
Есть множество вещей, доступ к которым следует закрыть (код, отдельный текст, ссылку на другие сайты, элементы меню), не закрывая при этом сам адрес. Сейчас очень популярный ранее метод с помощью noindex уже не используется. Его суть состояла в том, что в отдельный тег существовала возможность скопировать всю информацию, которую нужно было закрыть. Теперь мегапопулярным стал другой способ.
Использование JavaScript
В этом способе снова нужно использовать файл роботс. Его суть предполагает, что вся нужная информация кодируется с помощью яваскрипт, а после копируется в роботс и скрывается от индексации с помощью нужных тегов. Этот метод уменьшает «вес» ресурса, при его использовании быстродействие сайта увеличивается. Поэтому возможно улучшение ранжирования. Но есть один существенный минус. Google не одобряет данный способ и регулярно отсылает владельцам сайтов письма с просьбой открыть для индексации сокрытую информацию. По его заверениям информация должна быть идентичной и для пользователя, и для поискового робота.
Но несмотря на все усилия корпорации, этот способ остается достаточно популярным из-за эффективности.
Есть два способа, которые используются, чтобы закрыть ссылку на страницу от индексации.
Robots.txt
Для реализации первого способа добавляем в файл robots.txt такие строки:
User-agent: ag
Disallow: http://example.com/main
Это простой способ, но он не отличается надежностью. Страницы могут продолжать индексироваться. Но чтобы запретить их отображение, можно использовать еще один способ:
Мета-тег noindex
Второй способ является лучшим вариантом, поскольку в нем исключается воздействие роботс. Для его реализации в head всеx адресов, которые нужно закрыть от взгляда поисковых систем, вставляем тег:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Такой способ намного эффективнее использовать большим ресурсам, которым нужно закрывать больше сотни страниц. Однако, тогда у них отсутствует общий параметр.
Robots.txt
И снова вмешательство в этот файл поможет нам избежать индексации страниц. Добавляя в тег Disallow названия разделов и папок, мы можем исключать их из индексации. Примеры:
Disallow: /название папки/
Disallow: /название раздела/
Такой способ удобный, быстрый и простой в применении. Но он также полностью не гарантирует отсутствие индексирования нужных страниц. Поэтому мы рекомендуем использование мета-тега noidex в способе, описанном выше.
Редактирование файла robots.txt однозначно остается самым легким способом закрытия контента от индексации. Но в любом случае он больше нагружает файл, что скажется на быстродействии ресурса и его ранжировании. Тем более, чаще всего эти способы не гарантируют стопроцентную эффективность.
Есть возможность закрыть доступ для поисковых систем на уровне сервера.
Добавляем в бан отдельных User Agents
Такой способ позволяет заблокировать пользователя или робота, указав его нежелательным или опасным. Это позволяет запретить доступ к контенту своим конкурентам.
Способ используется для того, чтобы закрыть информацию от роботов онлайн-сервисов, которые анализируют источники трафика сайта, а также сео-оптимизации.
Это очень опасный метод, который часто приводит к нежелательным последствиям. Поэтому если вы не уверены в своих силах, следует обратиться к профессионалу.
Изменение HTTP-заголовка
Существует возможность прописать тег X-Robots как заголовок отдельной страницы. Такие методы идентичны тем, которые мы использовали при редактировании файла robots.txt. Нужно только указать имя пользователя (название поисковой системы).
Конкуренция в интернете с каждым днем вырастает все выше и напоминает промышленное шпионство больших корпораций. Поэтому владельцы сайтов и вебмастера вынуждены использовать любые способы, чтобы закрыть от посторонних глаз свою стратегию продвижения и способы сео-оптимизации.
Однако подобные методы используются и в банальных целях. Например, чтобы закрыть от индексации «мусор» на страницах ресурса. Как видим, индексация имеет две стороны.
Перечисленные выше методы не панацея, поэтому при недостаточных знаниях лучше обращаться к профессионалу.
Запрет индексации в robots.txt | REG.RU
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд можно выполнить в файле robots.txt запрет индексации.
Зачем нужен запрет индексации сайта через robots.txt
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Чтобы добавить новые сайты в базы, поисковые системы сканируют интернет с помощью специальных программ (поисковых роботов), которые анализируют содержимое веб-страниц. Этот процесс называется индексацией.
После того как впервые пройдет индексация, страницы сайта начнут отображаться в поисковой выдаче. Пользователи увидят их в процессе поиска информации в Яндекс и Google — самых популярных поисковых системах в рунете. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Если полезная информация в выдаче соседствует с технической информацией или неактуальным контентом — это затрудняет поиск нужных страниц и негативно сказывается на позиции сайта. Чтобы «лишние» страницы не отображались в поисковых системах, их нужно закрывать от индексации.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если не скрыть на время все страницы из поисковых систем, они могут проиндексироваться с ошибками, что отрицательно повлияет на позиции сайта в выдаче.
Для того чтобы частично или полностью убрать контент из поиска, достаточно сообщить поисковым роботам, что страницы не нужно индексировать. Для этого необходимо отключить индексацию в служебном файле robots.txt. Файл robots.txt — это текстовый документ, который создан для «общения» с поисковыми роботами. В нем прописываются инструкции о том, какие страницы сайта нельзя посещать и анализировать, а какие — можно.
Прежде чем начать индексацию, роботы обращаются к robots.txt на сайте. Если он есть — следуют указаниям из него, а если файл отсутствует — индексируют все страницы без исключений. Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда) Disallow.
Как запретить индексацию сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots.txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить индексацию всего сайта:
-
1.Откройте файл robots.txt.
-
2.Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /- Чтобы запретить индексацию в конкретной поисковой системе (например, в Яндекс):
User-agent: Yandex Disallow: /- Чтобы закрыть от индексации для всех поисковиков, кроме одного (например, Google)
User-agent: * Disallow: / User agent: Googlebot Allow: / -
3.Сохраните изменения в robots.txt.
Готово. Ресурс пропадет из поисковой выдачи выбранных ПС.
Запрет индексации папки
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, веб-разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
-
1.Откройте robots.txt.
-
2.Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
— Запрет только для Яндекса:
-
3.Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Где вместо catalog — укажите нужную папку.
-
4.Сохраните изменения.
Готово. Вы закрыли от индексации нужный каталог. Если требуется запретить несколько папок, последовательно пропишите для каждой директиву Disallow.
Как закрыть служебную папку wp-admin в плагине Yoast SEO
Как закрыть страницу от индексации в robots.txt
Если нужно закрыть от индексации конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
-
1.Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
-
2.Укажите, для каких поисковых роботов действует правило.
-
3.Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть. Например:
User-agent: * Disallow: /catalog/page.htmlГде вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
-
4.Сохраните изменения.
Готово. Теперь указанный файл не будет индексироваться и отображаться в результатах поиска.
Помогла ли вам статья?
4
раза уже помогла
Настройка индексирования. Какие страницы закрывать от поисковых роботов и как это лучше делать
Статья из блога АРТИЗАН-ТИМ.
Каким бы продуманным не был сайт, он всегда будет иметь страницы, нежелательные для индексации. Обработка таких документов поисковыми роботами снижает эффект SEO-оптимизации и может ухудшать позиции сайта в выдаче. В профессиональном лексиконе оптимизаторов за такими страницами закрепилось название «мусорные». На наш взгляд этот термин не совсем корректный, и вносит путаницу в понимание ситуации.
Мусорными страницами уместнее называть документы, не представляющие ценности ни для пользователей, ни для поисковых систем. Когда речь идет о таком контенте, нет смысла утруждаться с закрытием, поскольку его всегда легче просто удалить. Но часто ситуация не столь однозначна: страница может быть полезной с т.з. пользовательского опыта и в то же время нежелательной для индексации. Называть подобный документ «мусорным» — неправильно.
Такое бывает, например, когда разные по содержанию страницы создают для поисковиков иллюзию дублированного контента. Попав в индекс такой «псевдодубль» может привести к сложностям с ранжированием. Также некоторые страницы закрывают от индексации с целью рационализации краулингового бюджета. Количество документов, которые поисковики способны просканировать на сайте, ограниченно определенным лимитом. Чтобы ресурсы краулеров тратились исключительно на важный контент, и он быстрее попадал в индекс, устанавливают запрет на обход неприоритетных страниц.
Как закрыть страницы от индексации: три базовых способа
Добавление метатега Robots
Наличие атрибута noindex в html-коде документа сигнализирует поисковым системам, что страница не рекомендована к индексации, и ее необходимо изъять из результатов выдачи. В начале html-документа в блоке <head> прописывают метатег:
Эта директива воспринимается краулерами обеих систем — страница будет исключена из поиска как в Google, так и в «Яндексе» даже если на нее проставлены ссылки с других документов.
Варианты использования метатега Robots
Закрытие в robots.txt
Закрыть от индексации отдельные страницы или полностью весь сайт (когда это нужно — мы поговорим ниже) можно через служебный файл robots.txt. Прописав в нем одну из директив, поисковым системам будет задан рекомендуемый формат индексации сайта. Вот несколько основных примеров использования robots.txt
Запрет индексирования сайта всеми поисковыми системами:
User-agent: *
Disallow: /
Закрытие обхода для одного поисковика (в нашем случае «Яндекса»):
User-agent: Yandex
Disallow: /
Запрет индексации сайта всеми поисковыми системами, кроме одной:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Закрытие от индексации конкретной страницы:
User-agent: *
Disallow: / #частичный или полный URL закрываемой страницы
Отдельно отметим, что закрытие страниц через метатег Robots и файл robots.txt — это лишь рекомендации для поисковых систем. Оба этих способа не дают стопроцентных гарантий, что указанные документы не будут отправлены в индекс.
Настройка HTTP-заголовка X-Robots-Tag
Указать поисковикам условия индексирования конкретных страниц можно через настройку HTTP-заголовка X-Robots-Tag для определенного URL на сервере вашего сайта.
Заголовок X-Robots-Tag запрещает индексирование страницы
Что убирать из индекса?
Рассмотрев три основных способа настройки индексации, теперь поговорим о том, что конкретно нужно закрывать, чтобы оптимизировать краулинг сайта.
Документы PDF, DOC, XLS
На многих сайтах помимо основного контента присутствуют файлы с расширением PDF, DOC, XLS. Как правило, это всевозможные договора, инструкции, прайс-листы и другие документы, представляющие потенциальную ценность для пользователя, но в то же время способные размывать релевантность страницы из-за попадания в индекс большого объема второстепенного контента. В некоторых случаях такой документ может ранжироваться лучше основной страницы, занимая в поиске более высокие позиции. Именно поэтому все объекты с расширением PDF, DOC, XLS целесообразно убирать из индекса. Удобнее всего это делать в robots.txt.
Страницы с версиями для печати
Страницы с текстом, отформатированным под печать — еще один полезный пользовательский атрибут, который в то же время не всегда однозначно воспринимается поисковиками. Такие документы часто распознаются краулерами как дублированный контент, оказывая негативный эффект для продвижения. Он может выражаться во взаимном ослаблении позиций страниц и нежелательном перераспределении ссылочного веса с основного документа на второстепенный. Иногда поисковые алгоритмы считают такие дубли более релевантными, и вместо основной страницы в выдаче отображают версию для печати, поэтому их уместно закрывать от индексации.
Страницы пагинации
Нужно ли закрывать от роботов страницы пагинации? Данный вопрос становится камнем преткновения для многих оптимизаторов в первую очередь из-за диаметрально противоположных мнений на этот счет. Постраничный вывод контента на страницах листинга однозначно нужен, поскольку это важный элемент внутренней оптимизации. Но в необработанном состоянии страницы пагинации могут восприниматься как дублированный контент со всеми вытекающими последствиями для ранжирования.
Первый подход к решению этой проблемы — настройка метатега Robots. С помощью noindex, follow из индекса исключают все страницы пагинации кроме первой, но не запрещают краулерам переходить по ссылкам внутри них. Второй вариант обработки не предусматривает закрытия страниц. Вместо этого настраивают атрибуты rel=”canonical”, rel=”prev” и rel=”next”. Опыт показывает, что оба этих подхода имеют право на жизнь, хотя в своей практике мы чаще используем первый вариант.
Страницы служебного пользования
Технические страницы, предназначенные для административного использования, также целесообразно закрывать от индексации. Например, это может быть форма авторизации для входа в админку или другие служебные страницы. Удобнее всего это делать через директиву в robots.txt. Документы, к которым необходимо ограничить доступ, можно указывать списком, прописывая каждый с новой строки.
Директива в robots.txt на запрет индексации всеми поисковиками нескольких страниц
Формы и элементы для зарегистрированных пользователей
Речь идет об элементах, которые ориентированы на уже существующих клиентов, но не представляют ценности для остальных пользователей. К ним относят: страницы регистрации, формы заявок, корзину, личный кабинет и т.д. Индексацию таких элементов целесообразно ограничить как минимум из соображений оптимизации краулингового бюджета. На сайтах электронной коммерции отдельное внимание уделяют закрытию страниц, содержащих персональные данные клиентов.
Закрытие сайта во время технических работ
Создавая сайт с нуля или проводя его глобальную реорганизацию, например перенося на новую CMS, желательно разворачивать проект на тестовом сервере и закрывать его от сканирования всеми поисковыми системами в robots.txt. Это уменьшит риск попадания в индекс ненужных документов и другого тестового мусора, который в дальнейшем сможет навредить поисковому продвижению сайта.
Заключение
Настройка индексирования отдельных страниц — важный компонент поисковой оптимизации. Вне зависимости от технических особенностей каждый сайт имеет документы, нежелательные для попадания в индекс. Какой контент лучше скрывать от роботов и как это делать в каждом конкретном случае — мы подробно рассказали выше. Придерживаясь этих рекомендаций, вы оптимизируете ресурсы поисковых краулеров, обеспечите быстрые и эффективные обходы приоритетных страниц, и что самое важное — обезопаситесь от возможных проблем с ранжированием.
Читайте по теме:
Как оптимизировать страницы категорий онлайн-магазинов?
SEO-оптимизация главной страницы интернет-магазина. Подробное руководство
Как закрыть сайт от индексации: 5 способов
Закрытие сайта от индексации
Как закрыть сайт от индексации
Причины для запрета индексирования
Интернет-ресурсы скрывают от поисковых роботов в разных ситуациях, но чаще всего эта процедура проводится по одной из таких причин.
- При создании сайта. Допустим, вы на начальном этапе разработки и наполнения своей площадки контентом, меняете навигацию, интерфейс и других параметры. Как только начинается работа над сайтом, он и его наполнение еще не соответствуют всем вашим ожиданиям. Поэтому до окончательной доработки стоит скрыть свой ресурс от просмотра Google и «Яндексом», чтобы не индексировать неполноценные страницы. Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере.
- Когда веб-ресурс копируется. В некоторых случаях у разработчиков возникает необходимость в дублировании сайта, например, для тестирования на втором экземпляре доработок. И стоит сделать так, чтобы этот дубликат не индексировался. Иначе может пострадать оригинальный проект, и поисковики будут введены в заблуждение.
Способы закрытия индексации
Для решения этой задачи используются такие основные технологии:
- изменение настроек в WordPress;
- внесение команды в файл robots.txt;
- использование специального мета-тега;
- прописывание кода в настройках сервера;
- использование HTTP заголовка X-Robots-Tag.
1-й способ – Запрет на индексирование через WordPress
Для сайтов, созданных на базе этой системы, есть такой быстрый и несложный алгоритм действий для закрытия от роботов.
- В «Панели управления» находим пункт меню «Настройки».
- Заходим в раздел «Чтение».
- Здесь в пункте «Видимость для поисковых систем» ставим галочку возле надписи о рекомендации роботам не проводить индексацию.
- Сохраняем изменения.
В ответ на эти действия происходит автоматическое изменение файла robots.txt, корректируются правила, и таким образом отключается индексирование. При этом поисковая система оставляет за собой право решить, отключить робота или нет, даже несмотря на решение разработчика сайта. Опыт показывает, что от «Яндекса» можно не ждать таких решений, а Google иногда продолжает индексацию.
2-й способ – Изменение файла robots.txt
Если сайт построен не на WordPress, или невозможно закрыть доступ в этой системе по другим причинам, можно провести ручное удаление из поисковых систем. Сделать это также довольно просто. Создаем стандартный текстовый документ robots с расширением txt. Дальше вставляем его в корневую папку сайта, чтобы была возможность открывать его по адресу sait.com (ru, рф и т. п.)/robots.txt, где sait.com – url вашего ресурса. Файл пока пустой, и предстоит его заполнить необходимыми командами, при помощи которых можно полностью запретить доступ к сайту или закрыть только некоторые его участки. Есть несколько вариантов этой операции, каждый из которых мы рассмотрим дальше.
Полное закрытие для всех поисковиков
С этой целью прописываем в роботс такие строки:
Usеr-аgеnt: *
Dіsаllоw: /
После сохранения файла robots.txt сайт будет полностью закрыт для индексации ботами всех поисковых систем, и они не смогут ни обрабатывать информацию, размещенную на вашем ресурсе, ни вносить ее в свою базу данных. Для проверки результата, как уже упоминалось, можно ввести в браузере такую строку: sait.com (адрес вашего сайта)/robots.txt. При правильном выполнении задачи на странице появится содержащаяся в файле информация. Если же появится ошибка 404, это в большинстве случаев говорит о том, что файл скопирован не туда.
Отключение индексации одной папки
В команде дополнительно указываем ее название:
Usеr-аgеnt: *
DіsаІІоw: /fоІdеr/
Этот способ позволяет полностью скрыть файлы, размещенные в определенной папке.
Блокировка индексирования «Яндексом»
В первой строке меняем «*» на название бота поисковика:
Usеr-аgеnt: Yаndех
DіsаІІоw: /
Убедиться в том, что сайт удален из индекса «Яндекса», можно путем его добавления в «Вебмастер». После этого нужно перейти в раздел «роботс» по адресу https://webmaster.yandex.ru/tools/robotstxt/. Ссылки на несколько документов сайта вставляем в поле для url и кликаем «Проверить». Подтверждением успешного запрета индексации является появление надписи «Запрещено правилом /*?*».
Закрытие сайта от бота Google
Принцип построения команды тот же. Только меняется название бота:
Usеr-аgеnt: GооgІеbоt
DіsаІІоw: /
При проверке используется тот же прием, что и для «Яндекса». На панели инструментов Google Search Console должны появиться надпись «Заблокировано по строке» напротив соответствующей ссылки и команда, запрещающая ботам индексацию сайта. Но велика вероятность получить ответ «Разрешено», который говорит о вашей ошибке или о том, что поисковик разрешил индексацию страниц, для которых в robots прописан запрет. Как уже упоминалось выше, поисковые роботы воспринимают содержимое этого файла не как руководство к действию, а как набор рекомендаций, поэтому они оставляют за собой право решать, индексировать сайт или нет.
Запрет индексации другими поисковыми системами
У каждого поисковика свои боты с оригинальными именами, что позволяет веб-мастерам прописывать для них персональные команды в robots.txt. О «Яндексе» и Google мы уже писали. Вот еще три робота популярных поисковиков:
- МSNВоt – бот поисковой системы Віng;
- SputnіkВоt – «Спутника»;
- Slurр – Yаhоо.
Блокировка картинок
Для запрета индексации изображений в зависимости от их формата прописываются такие команды:
Usеr-Аgеnt: *
DіsаІІоw: *.jрg (*.gіf или *.рng)
Закрытие поддомена
В этом случае нужно учитывать один важный нюанс. У каждого поддомена свой файл robots.txt, находящийся, как правило, в его корневой папке. В нем нужно прописать стандартную команду блокировки:
Usеr-аgеnt: *
Dіsаllоw: /
При отсутствии такого документа его необходимо создать.
Этот способ закрытия сайта или его отдельных элементов от поисковых роботов считается одним из лучших. Он заключается в прописывании с тегами <head> и </head> такого кода:
<mеtа nаmе=”rоbоts” соntеnt=”nоnе”/>
или такого:
<mеtа nаmе=”rоbоts” соntеnt=”nоіndех, nоfоІІоw”/>
Место размещения кода значения не имеет.Googlebot» search_bot
Она заблокирует доступ для бота Google. Дальше нужно повторить операцию и прописать такие же строки для других поисковиков, но с названиями их ботов: Yаndех, msnbоt, MаіІ, Yаhоо, Rоbоt, Snарbоt, Раrsеr, WоrdРrеss, рhр, ВІоgPuІsеLіvе, bоt, Ароrt, іgdеSрydеr и sріdеr. Всего должно получиться 15 команд.
5-й способ – Использование X-Robots-Tag
В этом случае также настраивается блокировка через .htaccess, но при этом меняется заголовок НТТР X-Robots-Tag, который дает поисковикам указания, для понимания которых не нужно загружать сам документ. Такие инструкции авторитетнее, так как не нужно тратить ресурсы на изучение содержимого. Кроме того, этот метод подходит для любых видов контента.
Он используется с такими же директивами, как и Meta Robots: nоnе, nоіndех, nоаrсhіvе, nоfоІІоw и т. д. Есть два способа применения X-Robots-Tag. Первый – при помощи РНР, а второй – через настройку файла .htaccess.
Проверка индексирования сайта и отдельных страниц
Чтобы определить, индексируется сайт (страница, отдельный материал) в поисковике или нет, можно использовать один из таких четырех способов.
- Через панель инструментов «Вебмастера». Это самый популярный вариант. Находим в меню раздел индексирования сайта и проверяем, какие страницы попали в поиск.
- С использованием операторов поисковиков. Если указать команду «site: url сайта» в строке поиска Google или «Яндекса», можно определить, какое примерное количество страниц попало в индекс.
- При помощи расширений и плагинов. Можно провести автоматическую проверку индексирования через специальные приложения. Лидер по популярности среди таких плагинов – RDS bar.
- Посредством специальных сторонних сервисов. Они наглядно демонстрируют, что попало в индекс, а каких страниц там нет. Есть и платные, и бесплатные варианты таких инструментов.
Подведем итоги
Независимо от причины, по которой поисковым роботам закрывается доступ к ресурсу в целом, определенным страницам или материалам, можно использовать любой из описанных выше способов блокировки. Их несложно реализовать, и для этого не требуется большое количество времени. Вам вполне под силу самостоятельно скрыть от поисковых ботов определенную информацию, но следует помнить, что не каждый из методов дает 100-процентный результат.
Теги
Вам также будет интересно
API закрытия индекса | Руководство по Elasticsearch [7.14]
Закрывает индекс.
Для закрытия открытых индексов используется API закрытия индексов.
Закрытый индекс заблокирован для операций чтения / записи и не позволяет
все операции, которые разрешают открытые индексы. Невозможно проиндексировать
документы или для поиска документов в закрытом индексе. Это позволяет
закрытые индексы, чтобы не поддерживать внутренние структуры данных для
индексирование или поиск документов, что снижает накладные расходы на
кластер.
При открытии или закрытии индекса мастер отвечает за
перезапуск осколков индекса, чтобы отразить новое состояние индекса.
Затем осколки пройдут обычный процесс восстановления. В
данные открытых / закрытых индексов автоматически тиражируются
кластер, чтобы обеспечить безопасное хранение достаточного количества копий осколков
всегда.
Вы можете открывать и закрывать несколько индексов. Выдается ошибка
если запрос явно ссылается на отсутствующий индекс. Такое поведение может быть
отключено с помощью параметра ignore_unavailable = true .
Все индексы можно открывать или закрывать сразу, используя _all в качестве имени индекса.
или указав шаблоны, которые их все идентифицируют (например, * ).
Определение индексов с помощью подстановочных знаков или _все можно отключить, установив
action.destructive_requires_name флаг в файле конфигурации на true .
Этот параметр также можно изменить через api настроек обновления кластера.
Закрытые индексы занимают значительный объем дискового пространства, что может вызвать
проблемы в управляемых средах.Индексы закрытия можно отключить в настройках кластера.
API, установив cluster.indices.close.enable на false . По умолчанию это , правда .
В следующем примере показано, как закрыть индекс:
POST / my-index-000001 / _close
API возвращает следующий ответ:
{
"подтверждено": правда,
"shards_acknowledged": правда,
"индексы": {
"my-index-000001": {
"закрыто": правда
}
}
} остановить индексирование Google — qaru
Я должен добавить сюда свой ответ, поскольку принятый ответ на самом деле не затрагивает проблему должным образом.Также помните, что предотвращение сканирования Google не означает, что вы можете сохранить конфиденциальность своего контента.
Мой ответ основан на нескольких источниках: https://developers.google.com/webmasters/control-crawl-index/docs/getting_started
https://sites.google.com/site/webmasterhelpforum/en/faq—crawling—indexing—ranking
Файл robots.txt управляет сканированием, но не индексированием! Эти два совершенно разных действия выполняются отдельно. Некоторые страницы могут сканироваться, но не индексироваться, а некоторые могут даже индексироваться, но никогда не сканироваться.Ссылка на не просканированную страницу может существовать на других веб-сайтах, что заставит индексатор Google следовать по ней и пытаться проиндексировать.
Вопрос касается индексации, которая собирает данные о странице, чтобы они могли быть доступны через результаты поиска. Его можно заблокировать добавлением метатега:
или добавление HTTP-заголовка в ответ:
X-Robots-Тег: noindex
Если речь идет о сканировании, вы, конечно, можете создать роботов.txt и введите следующие строки:
Пользовательский агент: *
Запретить: /
Сканирование — это действие, выполняемое для сбора информации о структуре одного конкретного веб-сайта. Например. вы добавили сайт с помощью Инструментов Google для веб-мастеров. Сканер примет это в учетную запись и зайдет на ваш сайт в поисках robots.txt . Если он ничего не найдет, он будет считать, что может сканировать что угодно (очень важно также иметь файл sitemap.xml , чтобы помочь в этой операции и указать приоритеты и определить частоту изменений).Если он найдет файл, он будет следовать правилам. После успешного сканирования он в какой-то момент запустит индексирование просканированных страниц, но вы не можете сказать, когда …
Важно : все это означает, что ваша страница по-прежнему может отображаться в результатах поиска Google независимо от robots.txt .
Я надеюсь, что по крайней мере некоторые пользователи прочитают этот ответ, и он будет понятен, поскольку очень важно знать, что происходит на самом деле.
Запретить Google индексировать ваш сайт / Майкл Ли
Пока я разрабатываю веб-сайт клиента, в корне его веб-сайта есть простая страница, которая скоро появится.Я решил также настроить поддомен, чтобы я мог использовать его в качестве среды разработки, а также отправить его в качестве ссылки клиенту, чтобы они могли видеть подробное представление о ходе работы и фактически взаимодействовать с веб-сайтом.
Одна проблема с этим заключается в том, что хотя я хочу, чтобы корневой домен со следующей страницей был проиндексирован Google, я не хотел, чтобы субдомен индексировался, потому что в какой-то момент, когда сайт будет готов, я, вероятно, удалю поддомен.
noindex метод
Согласно Google, включение метатега со значением содержимого noindex и значением имени robots приведет к тому, что робот Googlebot полностью исключит страницу из результатов поиска Google при следующем сканировании.
Так выглядит метатег noindex в заголовке вашей веб-страницы.
<заголовок>
Ваш крутой веб-сайт
Метатег должен быть включен на каждую страницу, которую робот Googlebot не должен индексировать. Если вы хотите полностью заблокировать бота, а не сообщать, какие отдельные страницы не индексировать, вам нужно использовать метод robots.txt .
метод robots.txt
Другой метод — заблокировать индексирование вашего сайта роботами-роботами поисковых систем. Для этого вы создадите файл robots.txt и поместите его в корень домена. Этот метод также предполагает, что у вас есть доступ для загрузки файлов на ваш сервер.
Содержимое robots.txt будет:
Пользовательский агент: *
Запретить: /
Указывает всем сканерам не сканировать весь домен. Так, например, если у меня есть поддомен dev.example-url.com , и я хочу заблокировать только поддомен dev , я хочу разместить файл robots.txt в корне поддомена.
http://dev.example-url.com/robots.txt
Мне нужны оба?
Нет, вам нужен только один метод, но помните, что с тегом noindex вам нужно будет добавить его на каждую страницу, которую вы не хотите индексировать, в то время как robots.txt проинструктирует поисковый робот не индексировать весь поддомен.
Индексирование | Справочник по API | Документация Algolia
Рекомендуется использовать клиент Kotlin API, который лучше подходит для разработки под Android.
Создание индексов
Вам не нужно явно создавать индекс, Algolia создает его автоматически при первом добавлении объекта.
Объекты не имеют схемы, поэтому для начала индексации не требуется предварительная настройка.
Если вы хотите настроить свой индекс, в разделе настроек содержатся подробные сведения о дополнительных настройках.
Убедитесь, что вы не используете какую-либо конфиденциальную или личную информацию (PII) в качестве имени индекса , включая имена пользователей, идентификаторы или адреса электронной почты.
Имена индексов появляются в сетевых запросах, вы должны считать их общедоступными.
Объекты индекса
Схема объектов
Объекты, которые вы индексируете, не имеют схемы : они могут содержать любое количество полей, с любым определением и содержанием.
Движок не ожидает, что содержат ваши данные,
кроме некоторых проблем с форматированием,
и objectID .
ID объекта
Каждому объекту (записи) в индексе в конечном итоге требуется уникальный идентификатор,
называется objectID . Вы можете самостоятельно создать objectID и отправить его при индексировании. Если вы не отправите objectID , Algolia сгенерирует его для вас.
Отправленная или сгенерированная, после добавления записи она имеет уникальный идентификатор, называемый objectID .
Вы можете использовать этот идентификатор позже с любым методом, который должен ссылаться на конкретную запись, например saveObjects или partialUpdateObjects .
Добавление, обновление и частичное обновление объектов
addObjects
Метод addObjects не требует objectID .
- Если вы укажете
objectID:- Если
objectIDне существует в индексе, Algolia создает запись - Если
objectIDуже существует, Algolia заменяет запись
- Если
- Если вы не укажите
objectID:- Algolia генерирует
objectIDи возвращает его в ответе
- Algolia генерирует
сохранитьОбъекты
Метод saveObjects требует objectID .
- Если существует
objectID, Algolia заменяет запись - Если
objectIDприсутствует, но не существует, Algolia создает запись - Если
objectIDне указан , метод возвращает ошибку
partialUpdateObjects
Метод partialUpdateObjects требует objectID .
- Если существует
objectID, Algolia заменяет атрибуты - Если
objectIDуказан, но не существует, Algolia создает новую запись - Если
objectIDне указан , метод возвращает ошибку
Примечание. , как упоминалось ранее, partialUpdateObjects не заменяет весь объект, а добавляет, удаляет или обновляет переданные вами атрибуты.Остальные атрибуты остаются нетронутыми. Это отличается от addObjects и saveObjects , которые заменяют весь объект.
Для всех методов индексации
- Метод для всех трех может быть в единственном или множественном числе.
- Если единственное число (например,
addObject), метод принимает один объект в качестве параметра - Если во множественном числе (например,
addObjects), метод принимает один или несколько объектов
- Если единственное число (например,
Примечание: см. Отдельные методы для получения дополнительной информации о синтаксисе и использовании.
Терминология
Объект и запись
В документации термины «объект» и «запись» используются как синонимы.
Хотя они, безусловно, могут быть разными в области компьютерных наук,
в домене Алголии они такие же:
- индексы содержат «объекты» или «записи»
- JSON содержит «объекты» или «записи»
Индексы и индексы
В документации эти слова используются как синонимы. Первое — это американское написание, тогда как API часто использует британское написание.
Атрибуты
Все объекты и записи содержат атрибуты, иногда называемые полями или элементами. Некоторые атрибуты представляют собой пары «ключ-значение», тогда как другие могут быть более сложными, как коллекция или объект.
Асинхронные методы
Большинство этих методов асинхронны. На самом деле при вызове этих методов вы добавляете новое задание в очередь: именно это задание, а не метод, на самом деле выполняет желаемое действие .Обычно движок выполняет работу за секунды, если не за миллисекунды. Но все зависит от очереди: если в очереди несколько ожидающих задач, новое задание должно дождаться своей очереди.
Чтобы помочь управлять этой асинхронной индексацией, каждый метод возвращает уникальный taskID , который можно использовать с методом waitTask . Использование метода waitTask гарантирует, что задание завершено, прежде чем приступить к новым запросам. Вы можете использовать это для управления зависимостями.Например, при удалении индекса перед созданием нового индекса с тем же именем или при очистке индекса перед добавлением новых объектов.
Скрытие страницы от поисковых систем · Справочный центр Shopify
Эта страница была напечатана 25 августа 2021 года. Чтобы просмотреть текущую версию, посетите https://help.shopify.com/en/manual/promoting-marketing/seo/hide-a-page-from-search-engines.
Поисковые системы, такие как Google, постоянно сканируют Интернет в поисках новых данных.Когда ваш сайт сканируется, файл robots.txt вашего магазина блокирует содержимое страницы, которое в противном случае могло бы снизить эффективность вашей стратегии SEO из-за кражи PageRank.
Если вы внесли изменения или добавили страницу на свой сайт и хотите, чтобы Google повторно сканировал ваши URL-адреса, у вас есть два варианта. Вы можете использовать инструмент проверки URL-адресов или отправить карту сайта в Google. Для получения дополнительной информации см. Попросите Google повторно сканировать ваши URL-адреса.
По умолчанию файл robots.txt сообщает ботам (обычно роботам, индексирующим поисковые системы, или «сканерам»), какие страницы или файлы они должны или не должны запрашивать для просмотра с веб-сайта. Например, страница корзины покупок не должна просматриваться поисковыми системами, потому что она уникальна для отдельных клиентов и бесполезна для индексации поисковой системой.
Все магазины Shopify имеют предварительно настроенный и оптимизированный шаблон robots.txt.liquid . Если вы хотите отредактировать файл robots.txt, обратитесь к разделу «Редактирование robots.текст.
Вы можете скрыть страницы, которые не включены в ваш файл robots.txt.liquid , настроив раздел файла макета theme.liquid вашего магазина. Вам нужно добавить код для noindex определенных страниц.
Шагов:
От администратора Shopify перейдите в интернет-магазин > Темы .
Найдите тему, которую хотите отредактировать, и нажмите Действия > Изменить код .
В приложении Shopify нажмите Магазин .
В разделе Каналы продаж коснитесь Интернет-магазин .
Коснитесь Управление темами .
Найдите тему, которую хотите отредактировать, и нажмите Действия > Изменить код .
В приложении Shopify нажмите Магазин .
В разделе Каналы продаж коснитесь Интернет-магазин .
Коснитесь Управление темами .
Найдите тему, которую хотите отредактировать, и нажмите Действия > Изменить код .
Щелкните файл макета
theme.liquid.Чтобы исключить шаблон поиска, вставьте следующий код в раздел
{%, если шаблон содержит "поиск"%} {% endif%}Чтобы исключить определенную страницу, вставьте следующий код в раздел
{% если дескриптор содержит 'дескриптор-страницы-вы-хотите-исключить'%} {% endif%}Убедитесь, что вы заменили
page-handle-you-want-to-excludeправильным дескриптором страницы.Нажмите Сохранить .
Общие индексы | IntelliJ IDEA
Одним из возможных способов сокращения времени индексации является использование общих индексов. В отличие от обычных индексов, которые создаются локально, общие индексы генерируются один раз, а затем повторно используются на другом компьютере всякий раз, когда они необходимы.
Для получения дополнительной информации об индексировании и других способах сокращения времени индексирования см. Индексирование.
IntelliJ IDEA может подключаться к выделенному ресурсу для загрузки общих индексов для ваших библиотек JDK и Maven и построения общих индексов для кода вашего проекта.Всякий раз, когда IntelliJ IDEA необходимо переиндексировать ваше приложение, он будет использовать доступные общие индексы и будет создавать локальные индексы для остальной части проекта. Обычно это быстрее, чем создание локальных индексов для всего приложения с нуля.
Убедитесь, что подключаемый модуль установлен.
Чтобы иметь возможность использовать общие индексы проекта, в настройках должен быть включен подключаемый модуль Shared Project Indexes:
В диалоговом окне «Настройки / Предпочтения» Ctrl + Alt + S , выберите плагины.
Перейдите на вкладку «Установлено», введите
Shared Project Indexesи убедитесь, что рядом с ним установлен флажок.В противном случае установите флажок, чтобы включить плагин.
Примените изменения и закройте диалоговое окно. Если будет предложено, перезапустите среду IDE.
Когда вы запускаете проект, IntelliJ IDEA одновременно обрабатывает локальные и общие индексы. Это может увеличить загрузку ЦП на вашем компьютере. Если вы хотите избежать этого, включите опцию Ждать общих индексов в.
Общие индексы для библиотек JDK и Maven
Индексы для библиотек JDK и Maven создаются JetBrains и хранятся на выделенном ресурсе CDN. Когда вы открываете проект, IntelliJ IDEA показывает уведомление, предлагающее вам включить автоматическую загрузку.
Если вы пропустили уведомление, вы можете настроить эти параметры в настройках.
В диалоговом окне «Настройки / Предпочтения» выберите.
Выберите параметр «Загружать автоматически» для библиотек JDK и Maven, чтобы позволить IntelliJ IDEA автоматически загружать индексы всякий раз, когда они необходимы.
Или выберите Спрашивать перед загрузкой, если вы предпочитаете подтверждать каждую загрузку вручную.
индексы JDK будут загружены в index / shared_indexes в системном каталоге IDE. После этого IntelliJ IDEA будет использовать подходящие индексы всякий раз, когда они необходимы.
Общие индексы проектов
Чтобы иметь возможность использовать общие индексы проектов, в пакете должен быть включен подключаемый модуль Project Shared Indexes.
Общие индексы проектов создаются для всех исходных кодов проектов, библиотек и пакетов SDK.Вы можете сгенерировать их на одном компьютере, а затем применить на другом компьютере. Это главное преимущество общих индексов перед обычными индексами.
Использование общих индексов целесообразно для крупных проектов, где индексация может занять много времени, создавая неудобства для участвующих групп. Для небольших проектов мы рекомендуем другие способы сокращения времени индексации.
Перед тем, как начать
Для обеспечения совместимости индексов используйте одну и ту же версию IDE на исходном и конечном компьютерах.
На исходном и конечном компьютере могут быть разные операционные системы.
Однако в предыдущих версиях IntelliJ IDEA общие индексы проекта зависели от ОС. Обратитесь к документации, соответствующей вашей версии IDE, с помощью переключателя версий в верхнем левом углу этой страницы.
Совместное использование индексов проекта из командной строки
Для совместного использования индексов проекта установите инструмент командной строки и подготовьте IDE.Таким образом вы убедитесь, что кеши или другие внутренние файлы не влияют на информацию, которую вы собираетесь экспортировать из своего проекта.
После экспорта индексов и связанных метаданных загрузите их в хранилище файлов. Затем другие члены вашей группы могут настроить свои IDE для автоматического подключения к этому хранилищу и загрузки индексов, когда они понадобятся.
Подготовка файлового хранилища
Для совместного использования индексов из командной строки требуется файловое хранилище, в котором будут храниться экспортированные индексы проекта.
Установите cdn-layout-tool
Чтобы иметь возможность экспортировать и публиковать индексы проектов, установите cdn-layout-tool — инструмент JetBrains для работы с общими индексами проектов:
Загрузите последнюю версию инструмента из Космическое хранилище.
После загрузки файла .zip извлеките его содержимое в удобное место.
Среди содержимого файла .zip есть каталог bin. Там вы найдете сценарий запуска для конкретной ОС, который вам понадобится позже для генерации метаданных.
cdn-layout-tool и все его зависимости также публикуются как артефакты Maven.
Подготовьте IDE для совместного использования индексов проектов
Создайте следующие каталоги или удалите содержимое из существующих:
-
/ ide-system -
/ ide-config -
/ ide-log
Обратите внимание, что в разных операционных системах временный каталог имеет другое расположение.
-
Скопируйте
/ bin / idea.properties в каталог . Для получения дополнительной информации о idea.properties см. Общие свойства. Переименуйте idea.properties в ide.properties в
. Измените следующие свойства в файле
/ide.properties: - idea.system.path =
/ ide-system - idea.config.path =
/ ide-config - idea.log.path =
/ ide-log
Если у вас нет этих свойств в файле, добавьте их в конце.
- idea.system.path =
Задайте временную переменную среды, чтобы указать файл настраиваемых свойств IDE. Для этого выполните следующую команду:
set IDEA_PROPERTIES =
\ ide.properties export IDEA_PROPERTIES =
= /ide.properties
Экспорт индексов проекта
Убедитесь, что что каталог
/ generate-output пуст. Если такого каталога нет, не создавайте его, так как это будет сделано автоматически во время экспорта. Запустите среду IDE со следующей командной строкой, чтобы экспортировать индексы проекта в
/ generate-output. <Средство запуска командной строки IDE> проект dump-shared-index —output =
/ generate-output —tmp = / temp —project-dir = —project-id = —commit = Вы можете найти исполняемый скрипт для запуска IntelliJ IDEA в каталоге установки в bin.Чтобы использовать этот исполняемый сценарий в качестве средства запуска командной строки, добавьте его в свою систему
ПУТЬ, как описано в разделе «Интерфейс командной строки».- Синтаксис
idea.bat dump-shared-index project —output =
/ generate-output —tmp = / temp —project-dir = —project-id = — -commit = - Параметры
По умолчанию IntelliJ IDEA не предоставляет средство запуска командной строки.Для получения информации о создании сценария запуска для IntelliJ IDEA см. Интерфейс командной строки.
- Синтаксис
идея dump-shared-index project —output =
/ generate-output —tmp = / temp —project-dir = —project-id = —commit = - Параметры
Вы можете найти исполняемый скрипт для запуска IntelliJ IDEA в каталоге установки в bin.Чтобы использовать этот исполняемый сценарий в качестве средства запуска командной строки, добавьте его в свою систему
ПУТЬ, как описано в разделе «Интерфейс командной строки».- Синтаксис
idea.sh dump-shared-index project —output =
/ generate-output —tmp = / temp —project-dir = —project-id = — -commit = - Параметры
Экспорт может занять некоторое время.По завершении процесса в
/ generate-output помещаются следующие файлы: - shared-index-project-
— .ijx.xz - shared-index-project-
— .metadata.json - shared-index-project-
— .sha256
Скопируйте сгенерированные файлы в новую папку
Создайте новый каталог
/ indexes и загрузите туда все содержимое вашего удаленного файлового хранилища. Вы можете создать новый каталог внутри каталога, в котором есть подкаталог
/ generate-output. Это может быть любой каталог, например ~ / indexes / project / <имя проекта> / / share. Скопируйте сгенерированные файлы (.ijx.xz, .metadata.json, .sha256) из
/ generate-output в подкаталог / индексирует созданный подкаталог (в нашем случае — share). Это может быть любая папка, например
/ indexes / project / <имя проекта> / / .
Сгенерировать метаданные
Сгенерировать вспомогательные файлы, используемые IDE для поиска и загрузки общих индексов. Для этого запустите cdn-layout-tool со следующей командной строкой.
—indexes-dir = —url = <корневой URL-адрес хранилища файлов> - Опции
- Пример
/Users/User/Desktop/cdn-layout-tool-0.7.52/bin/cdn-layout-tool —indexes-dir = / var / folder / dr / xxx_x00x0x00000x0xx / xxx_x00x0x00000x0xx T / indexes —url = https: // my-file-storage.com / intellij-indexes
Загрузите файлы индекса в хранилище файлов
Загрузите все файлы из
/ indexes в хранилище файлов как есть. Если в хранилище уже есть загруженные индексные файлы, обновите их.
Загрузка индексов из файлового хранилища
После загрузки индексов проекта в файловое хранилище их можно загрузить и применить на другом компьютере.
В каталоге проекта создайте новый файл intellij.yaml и добавьте следующий код:
sharedIndex:
проект:
— url:Замените
URL-адресом вашего файлового хранилища в следующем формате: <корневой URL-адрес хранилища файлов> / project / . В диалоговом окне «Настройки / Предпочтения» Ctrl + Alt + S выберите.
В области «Общие индексы проекта» выберите способ загрузки общих индексов из хранилища.
Выберите «Загрузить автоматически», чтобы разрешить IntelliJ IDEA автоматически загружать индексы JDK всякий раз, когда они необходимы, или выберите «Спрашивать перед загрузкой», если вы предпочитаете подтверждать каждую загрузку вручную.
Примените изменения и закройте диалоговое окно.
Индексы проекта будут загружены в index / shared_indexes в системном каталоге IDE.
Поместите файл
Удалите загруженные общие индексы
Если вам больше не нужны индексы проекта (например, если проект больше не находится в разработке), вы можете удалить их все вместе. В этом случае IDE удалит обычные индексы и все загруженные общие индексы для проекта и JDK.
В главном меню выберите.
В открывшемся диалоговом окне выберите «Очистить загруженные общие индексы» и нажмите «Недействительно и перезапустить».
Последнее изменение: 11 августа 2021 г.
Что это означает и как его использовать
Если вы исследовали серверную часть WordPress, то, возможно, заметили параметр, который гласит: «Не рекомендуется поисковым системам индексировать этот сайт», и задались вопросом, что это означает.
Или, может быть, вы ищете способ скрыть свой сайт от нежелательных посетителей и задаетесь вопросом, достаточно ли этого маленького флажка, чтобы ваш контент оставался конфиденциальным.
Что означает эта опция? Что именно он делает с вашим сайтом? И почему вам не следует полагаться на него, даже если вы пытаетесь скрыть свой контент?
Вот ответы и несколько других методов деиндексации вашего сайта и блокировки доступа к определенным страницам.
Что означает «препятствовать поисковым системам индексировать этот сайт»?
Вы когда-нибудь задумывались, как поисковые системы индексируют ваш сайт и оценивают его SEO? Они делают это с помощью автоматизированной программы, называемой пауком, также известной как робот или краулер.Пауки «сканируют» сеть, посещая веб-сайты и регистрируя весь ваш контент.
Google использует их, чтобы решать, как ранжировать и размещать ваш веб-сайт в результатах поиска, извлекать рекламные сообщения из ваших статей для страницы результатов поиска и вставлять ваши изображения в изображения Google.
Когда вы отметите «Не разрешать поисковым системам индексировать этот сайт», WordPress изменяет ваш файл robots.txt (файл, который дает паукам инструкции о том, как сканировать ваш сайт). Он также может добавить метатег в заголовок вашего сайта, который сообщает Google и другим поисковым системам не индексировать какой-либо контент на всем вашем сайте.
Ключевое слово здесь — «отговорить»: поисковые системы не обязаны выполнять этот запрос, особенно поисковые системы, которые не используют стандартный синтаксис robots.txt , который использует Google.
Поисковые роботы
по-прежнему смогут найти ваш сайт, но правильно настроенные сканеры прочитают ваш robots.txt и уйдут, не индексируя контент и не показывая его в результатах поиска.
Раньше эта опция в WordPress не мешала Google показывать ваш веб-сайт в результатах поиска, просто индексируя его содержание.Вы по-прежнему можете видеть, что ваши страницы отображаются в результатах поиска с ошибкой типа «Информация об этой странице недоступна» или «Описание этого результата недоступно из-за файла robots.txt на сайте».
Пока Google не индексировал страницу, они также не скрывали ее полностью. Эта аномалия привела к тому, что люди могли посещать страницы, которые им не предназначались. Благодаря WordPress 5.3 он теперь работает правильно, блокируя как индексацию, так и листинг сайта.
Вы можете себе представить, как это разрушит ваше SEO, если вы включите его случайно.Крайне важно использовать эту опцию только в том случае, если вы действительно не хотите, чтобы кто-либо видел ваш контент — и даже в этом случае это может быть не единственная мера, которую вы хотите предпринять.
Почему вы не хотите индексировать свой сайт
Веб-сайты созданы для того, чтобы их видели люди. Вы хотите, чтобы пользователи читали ваши статьи, покупали ваши продукты, потребляли ваш контент — зачем вам намеренно пытаться блокировать поисковые системы?
Есть несколько причин, по которым вы можете захотеть скрыть часть или весь свой сайт.
- Ваш сайт находится в разработке и не готов к публикации.
- Вы используете WordPress в качестве системы управления контентом, но хотите сохранить конфиденциальность указанного контента.
- Вы пытаетесь скрыть конфиденциальную информацию.
- Вы хотите, чтобы ваш сайт был доступен только небольшому количеству людей по ссылке или только через приглашения, а не через общедоступные страницы поиска.
- Вы хотите разместить некоторый контент за платным доступом или другими воротами, например статьи, эксклюзивные для информационных бюллетеней.
- Вы хотите отрезать трафик к старым, устаревшим статьям.
- Вы хотите предотвратить получение штрафов SEO на тестовых страницах или дублировании контента.
Для некоторых из них есть более эффективные решения — использование надлежащего автономного сервера разработки, установка приватности ваших статей или размещение их под паролем — но есть законные причины, по которым вы можете захотеть деиндексировать часть или весь свой сайт.
Как проверить, не отпугивает ли ваш сайт поисковые системы
Хотя у вас могут быть законные причины для деиндексации вашего сайта, для вас может быть ужасным шоком узнать, что вы включили эту настройку без всякого намерения или оставили ее включенной случайно.Если вы получаете нулевой трафик и подозреваете, что ваш сайт не индексируется, вот как это подтвердить.
Один из простых способов — установить флажок Краткий обзор , расположенный на главном экране панели администратора. Просто войдите в свой сервер и установите флажок. Если вы видите сообщение «Поисковые системы не одобряют», значит, вы активировали эту настройку.
«Краткий обзор» на панели управления WordPress.
Еще более надежный способ — проверить файл robots.txt .Вы можете легко проверить это в браузере, даже не заходя на свой сайт.
Чтобы проверить robots.txt и , все, что вам нужно сделать, это добавить /robots.txt в конец URL-адреса вашего сайта. Например: https://kinsta.com/robots.txt
Если вы видите Disallow: / , значит, весь ваш сайт заблокирован от индексации.
«Запретить» в robots.txt.
Если вы видите Disallow: , за которым следует путь URL-адреса, например Disallow: / wp-admin / , это означает, что любой URL-адрес с путем / wp-admin / заблокирован.Такая структура является нормальной для некоторых страниц, но если, например, она блокирует / blog / , на котором есть страницы, которые вы хотите проиндексировать, это может вызвать проблемы!
Теперь, когда WordPress использует метатеги вместо robots.txt для деиндексации вашего сайта, вы также должны проверить свой заголовок на наличие изменений.
Войдите в свой сервер и перейдите в Внешний вид > Редактор тем . Найдите заголовок темы (header.php) и найдите следующий код:
noindex, nofollow в заголовке.php.
Вы также можете проверить functions.php на наличие тега noindex , поскольку с помощью этого файла можно удаленно вставить код в заголовок.
Если вы найдете этот код в своих файлах темы, значит, ваш сайт не индексируется Google. Но вместо того, чтобы удалять его вручную, давайте сначала попробуем отключить исходную настройку.
Как препятствовать индексации поисковыми системами в WordPress
Если вы хотите пропустить лишние шаги и сразу перейти к исходным настройкам, вот как активировать или деактивировать опцию «Отказать поисковым системам» в WordPress.
Войдите в свою панель управления WordPress и перейдите к Настройки > Чтение . Ищите вариант Видимость в поисковых системах с флажком «Не рекомендовать поисковым системам индексировать этот сайт».
Флажок видимости поисковой системы.
Если вы обнаружите, что он уже включен и хотите, чтобы ваш сайт был проиндексирован, снимите флажок. Если вы собираетесь запретить индексирование своего сайта, проверьте это (и запишите где-нибудь заметку, напоминающую вам выключить его позже!).
Теперь нажмите Сохранить изменения, , и все готово. Переиндексация вашего сайта или его удаление из результатов поиска может занять некоторое время.
Если ваш сайт все еще деиндексирован, вы также можете удалить код noindex из файла заголовка или вручную отредактировать robots.txt , чтобы убрать флаг «Запретить».
Итак, это достаточно просто, но по каким причинам вам следует избегать этого варианта или, по крайней мере, не полностью полагаться на него?
Недостатки использования опции «Оттолкнуть поисковые системы»
Вроде просто — поставьте галочку, и никто не сможет увидеть ваш сайт.Разве этого не достаточно? Почему вам не следует использовать эту опцию отдельно?
Когда вы включаете этот параметр или любой другой подобный ему, все, что он делает, — это добавление тега в ваш заголовок или в файл robots.txt . Как показывают более старые версии WordPress, которые по-прежнему позволяют отображать ваш сайт в результатах поиска, небольшой сбой или другая ошибка может привести к тому, что люди увидят ваши предположительно скрытые страницы.
Кроме того, поисковые системы должны выполнить запрос о запрете сканирования вашего сайта.Основные поисковые системы, такие как Google и Bing, обычно будут использовать это, но не все поисковые системы используют один и тот же синтаксис robots.txt , и не все пауки, сканирующие Интернет, рассылаются поисковыми системами.
Например, одной службой, использующей поисковые роботы, является Wayback Machine. А если ваш контент проиндексирован такой службой, он навсегда останется в Интернете.
Машина обратного пути.
Вы можете думать, что только потому, что на вашем новом сайте нет ссылок, он защищен от пауков, но это неправда.Существование на общем сервере, отправка электронного письма со ссылкой на ваш веб-сайт или даже посещение вашего сайта в браузере (особенно в Chrome) может открыть ваш сайт для сканирования.
Подпишитесь на информационный бюллетень
Хотите узнать, как мы увеличили трафик более чем на 1000%?
Присоединяйтесь к 20 000+ других, которые получают нашу еженедельную рассылку с инсайдерскими советами по WordPress!
Подпишитесь сейчас
Если вы хотите скрыть контент, не рекомендуется добавлять параметр и надеяться, что он поможет.
И давайте проясним: если контент, который вы деиндексируете, носит конфиденциальный или личный характер, вам ни в коем случае не следует полагаться на robots.txt или метатег, чтобы скрыть его.
И последнее, но не менее важное: эта опция полностью скроет ваш сайт от поисковых систем, в то время как во многих случаях вам нужно деиндексировать только определенные страницы.
Итак, что вы должны делать вместо этого метода или вместе с ним?
Другие способы предотвращения индексации поисковыми системами
Хотя вариант, предоставляемый WordPress, обычно выполняет свою работу, в определенных ситуациях часто лучше использовать другие методы сокрытия контента.Даже сам Google говорит, что не используйте robots.txt для скрытия страниц.
Пока у вашего сайта есть доменное имя и он находится на общедоступном сервере, невозможно гарантировать, что ваш контент не будет виден или проиндексирован поисковыми роботами, если вы не удалите его или не скроете за паролем или требованиями входа в систему.
Тем не менее, какие лучшие способы скрыть ваш сайт или определенные страницы на нем?
Блокировать поисковые системы с помощью .htaccess
Хотя его реализация функционально такая же, как при простом использовании опции «Отказать поисковым системам», вы можете захотеть использовать вручную.htaccess , чтобы заблокировать индексацию вашего сайта.
Вам нужно будет использовать программу FTP / SFTP для доступа к вашему сайту и открыть файл .htaccess, обычно расположенный в корневой папке (первая папка, которую вы видите при открытии сайта) или в public_html . Добавьте этот код в файл и сохраните:
Заголовочный набор X-Robots-Tag "noindex, nofollow" Примечание. Этот метод работает только для серверов Apache. Серверы NGINX, например, работающие на Kinsta, должны будут добавить этот код в .conf , который можно найти в / etc / nginx / (здесь вы можете найти пример реализации метатега):
add_header X-Robots-Tag "noindex, nofollow"; Защита секретных страниц паролем
Если есть определенные статьи или страницы, которые поисковые системы не должны индексировать, лучший способ скрыть их — защитить свой сайт паролем. Таким образом, только вы и нужные вам пользователи сможете видеть этот контент.
К счастью, эта функция встроена в WordPress, поэтому устанавливать какие-либо плагины не нужно.Просто перейдите на страницу сообщений и нажмите на ту, которую хотите скрыть. Отредактируйте свою страницу и найдите меню Статус и видимость > Видимость с правой стороны.
Если вы не используете Gutenberg, процесс будет аналогичным. Вы можете найти такое же меню в поле Publish .
Измените видимость на Защищено паролем и введите пароль, затем сохраните — и теперь ваш контент скрыт от широкой публики.
Установка защиты сообщения паролем.
Что делать, если вы хотите защитить паролем весь свой сайт? Требовать пароль для каждой страницы непрактично.
Пользователям Kinsta повезло: вы можете включить защиту паролем на Сайтах > Инструменты , требуя как имя пользователя, так и пароль.
В противном случае вы можете использовать плагин ограничения содержимого (например, защищенный паролем). Пожалуйста, установите и активируйте его, затем перейдите к Настройки > Защищено паролем и включите Защищенный паролем статус .Это дает вам более точный контроль, даже позволяя вам занести в белый список определенные IP-адреса.
Этот плагин не обновлялся более 11 месяцев на момент написания этой статьи. Он может больше не поддерживаться или поддерживаться и может иметь проблемы совместимости с последними версиями WordPress.
Установка защиты сообщения паролем.
Установите плагин WordPress
Когда функциональности WordPress по умолчанию недостаточно, хороший плагин часто может решить ваши проблемы.
Например, если вы хотите деиндексировать определенные страницы, а не весь сайт, у Yoast есть эта опция.
В Yoast SEO вы можете открыть страницу, которую хотите скрыть, и найти опцию на вкладке Advanced : Разрешить поисковым системам показывать это сообщение в результатах поиска? Измените его на № , и страница будет скрыта.
Настройки Yoast SEO
Следует отметить, что оба они полагаются на те же методы, что и параметр WordPress по умолчанию, чтобы препятствовать индексации поисковыми системами, и имеют те же недостатки.Некоторые поисковые системы могут не удовлетворить ваш запрос. Вам нужно будет использовать другие методы, если вы действительно хотите полностью скрыть это содержание.
Еще одно решение — заплатить доступ к вашему контенту или скрыть его за обязательным логином. Плагины Simple Membership или Ultimate Member могут помочь вам настроить бесплатный или платный контент для членства.
Плагин
Simple Membership.
Используйте промежуточный сайт для тестирования
При работе над тестовыми проектами или незавершенными веб-сайтами лучше всего скрывать их — использовать промежуточный или разрабатываемый сайт.Эти веб-сайты являются частными, часто размещаются на локальном компьютере, доступ к которым не имеет никто, кроме вас и других лиц, которым вы разрешили.
Многие веб-хосты предоставят вам простые в развертывании промежуточные сайты и позволят вам разместить их на общедоступном сервере, когда вы будете готовы. Kinsta предлагает промежуточный сайт для всех планов в один клик.
Вы можете получить доступ к своим промежуточным сайтам в MyKinsta, перейдя на Сайты > Информация и щелкнув раскрывающееся меню Изменить среду . Нажмите Промежуточная среда , а затем кнопку Создать промежуточную среду .Через несколько минут ваш сервер разработки будет готов к тестированию.
Если у вас нет доступа к простому способу создания промежуточного сайта, плагин WP STAGING может помочь вам продублировать вашу установку и переместить ее в папку для легкого доступа.
Использование консоли поиска Google для временного скрытия веб-сайтов
Google Search Console — это служба, которая позволяет вам заявлять права собственности на свои веб-сайты. Это дает возможность временно заблокировать Google от индексации определенных страниц.
У этого метода есть несколько проблем: он эксклюзивен для Google (поэтому такие сайты, как Bing, не пострадают) и действует всего 6 месяцев.
Но если вам нужен быстрый и простой способ временно удалить свой контент из результатов поиска Google, это способ сделать это.
Если вы еще этого не сделали, вам нужно добавить свой сайт в Google Search Console. После этого откройте Removals и выберите Temporary Removals > New Request . Затем нажмите Удалить только этот URL и укажите ссылку на страницу, которую вы хотите скрыть.
Это еще более надежный способ блокировки контента, но опять же, он работает исключительно для Google и длится всего 6 месяцев.
Сводка
Есть много причин, по которым вы можете захотеть скрыть контент на своем сайте, но использование опции «Отказать поисковым системам от индексации этого сайта» — не лучший способ убедиться, что такой контент не виден.
Если вы не хотите скрыть весь свой веб-сайт от Интернета, вам никогда не следует выбирать эту опцию, поскольку это может нанести огромный ущерб вашему оптимизатору поисковых систем, если его случайно переключить.
И даже если вы действительно хотите скрыть свой сайт, этот вариант по умолчанию — ненадежный метод. Он должен сочетаться с защитой паролем или другими блокировками, особенно если вы имеете дело с конфиденциальным контентом.
Используете ли вы какие-либо другие методы, чтобы скрыть свой сайт или его части? Дайте нам знать в комментариях.
Экономьте время, деньги и повышайте производительность сайта с помощью:
- Мгновенная помощь от экспертов по хостингу WordPress, 24/7.
- Интеграция Cloudflare Enterprise.
- Глобальный охват аудитории с 28 центрами обработки данных по всему миру.
- Оптимизация с помощью нашего встроенного мониторинга производительности приложений.
Все это и многое другое в одном плане без долгосрочных контрактов, поддержки миграции и 30-дневной гарантии возврата денег.
Добавить комментарий