
Как закрыть сайт от индексации в robots.txt
Поисковые роботы сканируют всю информацию в интернете, но владельцы сайтов могут ограничить или запретить доступ к своему ресурсу. Для этого нужно закрыть сайт от индексации через служебный файл robots.txt.
Если закрывать сайт полностью не требуется, запрещайте индексацию отдельных страниц. Пользователям не следует видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря. Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Как закрыть сайт полностью
Обычно ресурс закрывают полностью от индексации во время разработки или редизайна. Также закрывают сайты, на которых веб-мастера учатся или проводят эксперименты.
Запретить индексацию сайта можно для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
|
Запрет для всех |
User-agent: * Disallow: / |
|
Запрет для отдельного робота |
User-agent: YandexImages Disallow: / |
|
Запрет для всех, кроме одного робота |
User-agent: * Disallow: / User-agent: Yandex Allow: / |
Как закрыть отдельные страницы
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:
- административная панель;
- служебные каталоги;
- личный кабинет;
- формы регистрации;
- формы заказа;
- сравнение товаров;
- избранное;
- корзина;
- каптча;
- всплывающие окна и баннеры;
- поиск на сайте;
- идентификаторы сессий.
Желательно запрещать индексацию т.н. мусорных страниц. Это старые новости, акции и спецпредложения, события и мероприятия в календаре. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
|
Отдельной страницы |
User-agent: * Disallow: /contact.html |
|
Раздела |
User-agent: * Disallow: /catalog/ |
|
Всего сайта, кроме одного раздела |
User-agent: * Disallow: / Allow: /catalog |
|
Всего раздела, кроме одного подраздела |
User-agent: * Disallow: /product Allow: /product/auto |
|
Поиска на сайте |
User-agent: * Disallow: /search |
|
Административной панели |
User-agent: * Disallow: /admin |
Как закрыть другую информацию
Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
Запрет индексации
|
Типа файлов |
User-agent: * Disallow: /*.jpg |
|
Папки |
User-agent: * Disallow: /images/ |
|
Папку, кроме одного файла |
User-agent: * Disallow: /images/ Allow: file.jpg |
|
Скриптов |
User-agent: * Disallow: /plugins/*.js |
|
utm-меток |
User-agent: * Disallow: *utm= |
|
utm-меток для Яндекса |
Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 1.
Вариант 2.
<meta name=”robots” content=”none”/>
Атрибут “content” имеет следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
Таким образом, можно запретить индексацию содержимого, но разрешить ссылки. Для этого укажите content=”noindex, follow”. На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений.
Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические — когда правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в инструментах Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксические — когда неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.
Шпаргалка
-
Для запрета на индексацию сайта используйте два варианта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех краулеров. Другой вариант — пропишите запрет через мета-тег robots в файле index.html внутри тега . -
Закрывайте служебные информацию, устаревающие данные, скрипты, сессии и utm-метки. Для каждого запрета создавайте отдельное правило. Запрещайте всем поисковым роботам через * или указывайте название конкретного краулера. Если вы хотите разрешить только одному роботу, прописывайте правило через disallow. -
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверяйте файл через инструменты Яндекс.Вебмастер и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льорентэ.
Файл robots.txt — настройка и директивы robots.txt, запрещаем индексацию страниц
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
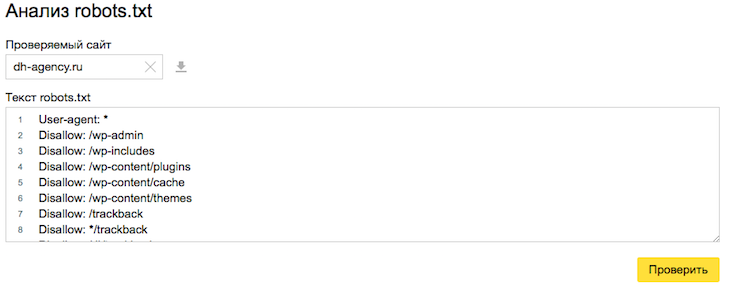
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.

Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!
Как закрыть сайт или его страницы от индексации: подробная инструкция
Что нужно закрывать от индексации
Важно, чтобы в поисковой выдаче были исключительно целевые страницы, соответствующие запросам пользователей. Поэтому от индексации в обязательном порядке нужно закрывать:
1. Бесполезные для посетителей страницы или контент, который не нужно индексировать. В зависимости от CMS, это могут быть:
- страницы административной части сайта;
- страницы с личной информацией пользователей, например, аккаунты в блогах и на форумах;
- дубли страниц;
- формы регистрации, заказа, страница корзины;
- страницы с неактуальной информацией;
- версии страниц для печати;
- RSS-лента;
- медиа-контент;
- страницы поиска и т.д.
2. Страницы с нерелевантным контентом на сайте, который находится в процессе разработки.
3. Страницы с информацией, предназначенной для определенного круга лиц, например, корпоративные ресурсы для взаимодействий между сотрудниками одной компании.
4. Сайты-аффилиаты.
Если вы закроете эти страницы, процесс индексации других, наиболее важных для продвижения страниц сайта ускорится.
Способы закрытия сайта от индексации
Закрыть сайт или страницы сайта от поисковых краулеров можно следующими способами:
- С помощью файла robots.txt и специальных директив.
- Добавив метатеги в HTML-код отдельной страницы.
- С помощью специального кода, который нужно добавить в файл .htaccess.
- Воспользовавшись специальными плагинами (если сайт сделан на популярной CMS).
Далее рассмотрим каждый из этих способов.
С помощью robots.txt
Robots.txt — текстовый файл, который поисковые краулеры посещают в первую очередь. Здесь для них прописываются указания — так называемые директивы.
Этот файл должен соответствовать следующим требованиям:
- название файла прописано в нижнем регистре;
- он имеет формат .txt;
- его размер не превышает 500 КБ;
- находится в корне сайте;
- файл доступен по адресу URL сайта/robots.txt, а при его запросе сервер отправляет в ответ код 200 ОК.
В robots.txt прописываются такие директивы:
- User-agent. Показывает, для каких именно роботов предназначены директивы.
- Disallow. Указывает роботу на то, что некоторое действие (например, индексация) запрещено.
- Allow. Напротив, разрешает совершать действие.
- Sitemap. Указывает на прямой URL-адрес карты сайта.
- Clean-param. Помогает роботу Яндекса правильно определять страницу для индексации.
- Crawl-delay. Позволяет задать роботу Яндекса диапазон времени между окончанием загрузки одной страницы и началом загрузки другой. Измеряется в секундах.
Имейте в виду: поскольку информация в файле robots.txt — это скорее указания или рекомендации, нежели строгие правила, некоторые системы могут их игнорировать. В таком случае в индекс попадут все страницы вашего сайта.
Полный запрет сайта на индексацию в robots.txt
Вы можете запретить индексировать сайт как всем роботам поисковой системы, так и отдельно взятым. Например, чтобы закрыть весь сайт от робота Яндекса, который сканирует изображения, нужно прописать в файле следующее:
User-agent: YandexImages Disallow: /
Чтобы закрыть для всех роботов:
User-agent: * Disallow: /
Чтобы закрыть для всех, кроме указанного:
User-agent: * Disallow: / User-agent: Yandex Allow: /
В данном случае, как видите, индексация доступна для роботов Яндекса.
Запрет на индексацию отдельных страниц и разделов сайта
Для запрета на индексацию одной страницы достаточно прописать ее URL-адрес (домен не указывается) в директиве файла:
User-agent: * Disallow: /registration.html
Чтобы закрыть раздел или категорию:
User-agent: * Disallow: /category/
Чтобы закрыть все, кроме указанной категории:
User-agent: * Disallow: / Allow: /category
Чтобы закрыть все категории, кроме указанной подкатегории:
User-agent: * Disallow: /uslugi Allow: /uslugi/main
В качестве подкатегории здесь выступает «main».
Запрет на индексацию прочих данных
Чтобы скрыть директории, в файле нужно указать:
User-agent: * Disallow: /portfolio/
Чтобы скрыть всю директорию, за исключением указанного файла:
User-agent: * Disallow: /portfolio/ Allow: avatar.png
Чтобы скрыть UTM-метки:
User-agent: * Disallow: *utm=
Чтобы скрыть скриптовые файлы, нужно указать следующее:
User-agent: * Disallow: /scripts/*.ajax
По такому же принципу скрываются файлы определенного формата:
User-agent: * Disallow: /*.png
Вместо .png подставьте любой другой формат.
Через HTML-код
Запретить индексировать страницу можно также с помощью метатегов в блоке <head> в HTML-коде.
Атрибут «content» здесь может содержать следующие значения:
- index. Разрешено индексировать все содержимое страницы;
- noindex. Весь контент страницы, кроме ссылок, закрыт от индексации;
- follow. Разрешено индексировать ссылки;
- nofollow. Разрешено сканировать контент, но ссылки при этом закрыты от индексации;
- all. Все содержимое страницы подлежит индексации.
Открывать и закрывать страницу и ее контент можно для краулеров определенной ПС. Для этого в атрибуте «name» нужно указать название робота:
- yandex — обозначает роботов Яндекса:
- googlebot — аналогично для Google.
Помимо прочего, существует метатег Meta Refresh. Как правило, Google не индексирует страницы, в коде которых он прописан. Однако использовать его именно с этой целью не рекомендуется.
Так выглядит фрагмент кода, запрещающий индексировать страницу:
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>...</body>
</html>Чтобы запретить индексировать страницу краулерам Google, нужно ввести:
<meta name="googlebot" content="noindex, nofollow"/>
Чтобы сделать то же самое в Яндексе:
<meta name="yandex" content="none"/>
На уровне сервера
В некоторых случаях поисковики игнорируют запреты и продолжают индексировать все данные. Чтобы этого не происходило, рекомендуем попробовать ограничить возможность посещения страницы для отдельных краулеров на уровне сервера. Для этого в файл .htaccess в корневой папке сайта нужно добавить специальный код. Для краулеров Google он будет таким:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
Для краулеров Яндекса таким:
SetEnvIfNoCase User-Agent "^Yandex" search_bot
На WordPress
В процессе создания сайта на готовой CMS нужно закрывать его от индексации. Здесь мы разберем, как сделать это в популярной CMS WordPress.
Закрываем весь сайт
Закрыть весь сайт от краулеров можно в панели администратора: «Настройки» => «Чтение». Выберите пункт «Попросить поисковые системы не индексировать сайт». Далее система сама отредактирует файл robots.txt нужным образом.
Закрытие сайта от индексации через панель администратора в WordPress
Закрываем отдельные страницы с помощью плагина Yoast SEO
Чтобы закрыть от индексации как весь сайт, так и его отдельные страницы или файлы, установите плагин Yoast SEO.
Для запрета на индексацию вам нужно:
- Открыть страницу для редактирования и пролистать ее вниз до окна плагина.
- Настроить режим индексации на вкладке «Дополнительно».
Закрытие от индексации с помощью плагина Yoast SEO
Настройка режима индексации
Запретить индексацию сайта на WordPress можно также через файл robots.txt. Отметим, что в этом случае требуется особый подход к редактированию данного файла, так как необходимо закрыть различные служебные элементы: страницы рассылок, панели администратора, шаблоны и т.д. Если этого не сделать, в поисковой выдаче могут появиться нежелательные материалы, что негативно скажется на ранжировании всего сайта.
Как узнать, закрыт ли сайт от индексации
Есть несколько способов, которыми вы можете воспользоваться, чтобы проверить, закрыт ли ваш сайт или его отдельная страница от индексации или нет. Ниже рассмотрим самые простые и удобные из них.
В Яндекс.Вебмастере
Для проверки вам нужно пройти верификацию в Яндексе, зайти в Вебмастер, в правом верхнем углу найти кнопку «Инструменты», нажать и выбрать «Проверка ответа сервера».
Проверка возможности индексации страницы в Яндекс.Вебмастере
В специальное поле на открывшейся странице вставляем URL интересующей страницы. Если страница закрыта от индексации, то появится соответствующее уведомление.
Так выглядит уведомление о запрете на индексацию страницы
Таким образом можно проверить корректность работы файла robots.txt или плагина для CMS.
В Google Search Console
Зайдите в Google Search Console, выберите «Проверка URL» и вставьте адрес вашего сайта или отдельной страницы.
Проверка возможности индексации в Google Search Console
С помощью поискового оператора
Введите в поисковую строку следующее: site:https:// + URL интересующего сайта/страницы. В результатах вы увидите количество проиндексированных страниц и так поймете, индексируется ли сайт поисковой системой или нет.
Проверка индексации сайта в Яндексе с помощью специального оператора
Проверка индексации отдельной страницы
С помощью такого же оператора проверить индексацию можно и в Google.
С помощью плагинов для браузера
Мы рекомендуем использовать RDS Bar. Он позволяет увидеть множество SEO-показателей сайта, в том числе статус индексации страницы в основных поисковых системах.
Плагин RDS Bar
Итак, теперь вы знаете, когда сайт или его отдельные страницы/элементы нужно закрывать от индексации, как именно это можно сделать и как проводить проверку, и можете смело применять новые знания на практике.
Закрываем сайт от индексации в файле robots.txt
Введение
Сегодня трафик из поисковых систем для многих сайтов является основным источником посетителей. Для того, что бы Ваш ресурс появился в поиске, Yandex (Google, Rambler и т.д.) должен сначала найти его, а затем скачать к себе в базу. Этот процесс и называется индексацией.
Индексация проводится не один и не два раза. Робот посещает Ваш сайт на протяжении всей его «жизни» или до момента запрета. Именно о запрете сегодня и пойдет речь.
Запретить индексацию означает не дать участвовать в поиске всему сайту или определенному списку страниц.
Для чего нужен запрет индексации
Существует множество причин для полного и частичного запрета. Разберем по порядку.
Нежелание участвовать в поиске. Самая банальная причина. Вы просто не хотите, что бы сайт участвовал в результатах поиска.
Сайт находится в разработке. Робот индексирует сайт всегда, вне зависимости от того, находится он в разработке или уже закончен.
Поэтому, если работы проводятся не на локальном хостинге, то необходимо запретить поисковым системам индексировать сайт до тех пор, пока он не будет готов. Вот лишь ряд причин, почему необходимо скрывать от поисковика все, что еще не доделали.В процессе разработки размещается демо контент, уникальность которого крайне низка. Видеть такой материал поисковая система не должна.
Сайт разрабатывается без наполнения и окончательной структуры. Не нужно вводить в заблуждение поисковую систему, иначе ресурс будет признан не интересным для пользователей еще до того, как его наполнят.
Во время технических работ появляется множество дублей страниц. Нельзя допустить попадания их в индекс.
Ряд других технических причин.
Информация не для поиска. На любом сайте существуют страницы и разделы, которые не должны участвовать в поиске. К ним относится система управления сайта, результаты вычислений, дубликаты URL, неуникальный контент, не индексируемые документы и т.д.
- Страницы в разработке. Если сайт уже давно присутствует в поиске, но часть страниц находится на стадии редактирования, то их необходимо скрыть от индексирующего робота.
Запрещаем индексацию сайта
Для того, что бы полностью запретить индексацию сайта, необходимо, что бы при обращении к нему робот получал запрет в виде инструкции. Сделать это можно двумя способами.
При помощи robots.txt
Это наиболее распространенный и менее трудозатратный способ. Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
User-agent: *
Disallow: /
Таким образом вы запрещаете индексацию для любой поисковой системы. Но есть возможность запрета и для конкретного поисковика, к примеру, Яндекса.
User-agent: Yandex
Disallow: /
Подробнее о синтаксисе и работе с файлом robots.txt — https://dh-agency.ru/category/vnutrennyaya-optimizaciya/robots-txt/
При помощи тэгов
Так же, существует способ закрыть свой сайт при помощи специального тэга. Он будет «говорить» индексирующему роботу при обращении к странице, что ее загружать не надо.
<meta name=»robots» content=»noindex»>
Данный тэг необходимо разместить на каждой странице Вашего сайта.
Параметр поля «name» зависит от робота, к которому Вы обращаетесь. К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
<meta name=»googlebot» content=»noindex»>
О том, какие значения может принимать параметр «content», читайте ниже.
Запрещаем индексацию страницы
Запрет индексации одной единственной страницы отличается от запрета всего сайта только наличием дополнительной инструкции и URL адреса. Причем исключить из индекса можно не только конкретный адрес, но и маску. Однако возможность эта имеется только при работе с файлом robots.txt.
При помощи robots.txt
Для запрета конкретной страницы (спектра страниц по маске) используется инструкция «Disallow:». Синтаксис крайне простой:
Disallow: /wp-admin (исключаем всю папку wp-admin)
Disallow: /wp-content/plugins (исключаем папку plugins, которая находится в wp-content)
Disallow: /img/images.jpg (исключаем изображение images.jpg, которое находится в папке img)
Disallow: /dogovor.pdf (исключаем файл /dogovor.pdf)
Disallow: */trackback (исключаем папку trackback в любой папке первого уровня)
Disallow: /*my (исключаем любую папку заканчивающуюся на my)
Все достаточно просто, не правда ли? Но это позволяет избавиться от множества проблем во время продвижения сайта. Актуализируйте robots.txt каждый месяц в зависимости от апдейтов Яндекса и Гугла.
При помощи тэгов
Исключение возможно и при помощи тэга <meta name=»robots» content=»noindex»>. Для этого необходимо просто вписать его в код конкретной страницы, которую Вы хотите закрыть от поисковиков.
Данный тэг размещается в <head> сайта, наряду с другими meta тэгами.
Стоит отметить, что значение параметра «content» может быть не только «noindex». Рассмотрим все возможные варианты.
| noindex | Самый распространенный параметр. Запрещает индексацию. |
| index | Обратный предыдущему параметр. Разрешает индексацию. Обычно не применяется, так как поисковая система по умолчанию индексирует все. |
| follow | Разрешает следовать по ссылкам, которые расположены на странице. Так же редко применяется, так как и без данного тэга краулер будет переходить по ссылкам. |
| nofollow | Запрещает переходить по ссылкам. |
Популярные ошибки
Существует множество мелких и досадных ошибок, из-за которых можно потерять кучу времени и сил.
- Запрет индексации в CMS.
У ряда CMS (к примеру, у WordPress) и шаблонов по умолчанию стоит галочка — «не индексировать сайт». Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.

К сожалению, не все вспоминают о ней по окончании работ.
- Синтаксические ошибки.
Синтаксические ошибки в файле robots.txt и тэгах часто приводят к совершенно непредсказуемым последствиям. Вам повезет, если после такого недочета в индекс просто попадут лишние страницы. Очень часто весь сайт закрывается, что в последствии приводит к полной потере органического трафика.
Для того, что бы избежать подобных ошибок, необходимо несколько раз перепроверить изменения, а так же воспользоваться инструментами валидации синтаксиса. К примеру, стандартным сервисом Яндекса.
Яндекс Вебмастер -> Инструменты -> Анализ robots.txt
- Неверное использование масок.
Неверное использование масок может привести к исключению целого дерева страниц, документов и разделов. Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.

Делаем выводы
Сам по себе технический процесс исключения достаточно прост. Вся работа заключается в выяснении того, что необходимо исключить и на какой срок.
Если Вы не уверены в правильности своих действий, лучше оставьте в индексе все. Поисковая система сама выберет то, что для нее важно.
Но мы настоятельно рекомендуем обратиться за консультацией при малейших сомнениях.
Как закрыть сайт от индексации в robots.txt, через htaccess и мета-теги
Привет уважаемые читатели seoslim.ru! Некоторые пользователи интернета удивляются, какими же быстродействующими должны быть компьютеры Яндекса, чтобы в несколько секунд просмотреть все сайты в глобальной сети и найти ответ на вопрос?
Но на самом деле за пару секунд изучить все данные WWW не способна ни одна современная, даже самая мощная вычислительная машина.
Давайте сегодня пополним наши знания о всемирной сети и разберемся, как поисковые машины ищут и находят ответы на вопросы пользователей и каким образом можно им запретить это делать.
Что такое индексация сайта
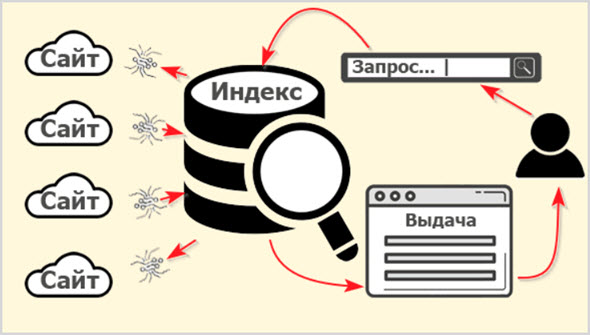
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Это полезно знать: Какую роль в работе сайта играют DNS-сервера
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
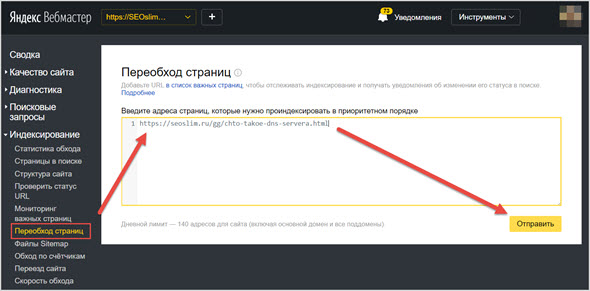
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Как скрыть сайт от индексации поисковыми системами
Сбором информации в интернете и занесением его в базу данных поисковой системы занимаются автоматические программы, называемые роботами-индикаторами. Веб-мастера часто называют этих роботов сокращенно «ботами».
Слово «боты» вы могли уже встречать в различных мессенджерах. В этих системах быстрой коммуникации боты тоже являются компьютерными программами, выполняющими определенные функции или задачи.
Так вот, для того, чтобы роботы-индексаторы не занесли определенные веб-страницы или контент в Index поисковика, следует сформировать специальные команды, которые указывают ботам, что некоторые страницы на сайте посещать запрещено, а некоторый контент не следует заносить в поисковые базы.
Настроить команды запрета индексации можно несколькими способами, которые мы и рассмотрим ниже.
Запрет в robots.txt
В корневой папке сайта на удаленном сервере хостинг-провайдера имеется файл с именем robots.txt.
- Что такое корневая папка сайта? Корневая папка или каталог – это то место, которому в первую очередь производится запрос из браузера, когда пользователь обращается к какому-нибудь ресурсу в интернете. То есть, это исходная папка с которой начинаются все запросы к веб-ресурсу.
- Файл robots.txt – это пакетный командный файл, в котором содержатся директивы для ПС, ответственных за индексацию контента.
Говоря простыми словами, robots.txt это специальный файл, предназначенный для поисковых роботов. Что, собственно, понятно из самого имени документа – Robots, что означает «роботы».
Отредактировать файл с командами для роботов ПС можно вручную в простом текстовом редакторе, добавить или удалить команды, изменить отдельные записи.
У каждой поисковой системы действует множество роботов, которые ответственны за индексацию разного рода контента. Отдельные роботы ищут и заносят в базу изображения, текст, скрипты и все остальное, что только может иметь значение для нормальной работы интернет-проекта.
Роботов индексаторов довольно много, перечислим только некоторых из них:
- Yandex – главный робот, ответственный за индексацию проекта в поисковой системе Яндекс.
- YaDirectBot – робот, ответственный за индексацию веб-страниц, на которых опубликована реклама контекстной системы Яндекс Директ.
- Yandex/1.02.000 (F) – робот, занимающийся индексации фавиконов, иконок сайта, которые пользователь видит во вкладках браузера и в сниппетах на странице выдачи.
- Yandex Images – индексация изображений.
Как вы понимаете, директивы или команды следует задавать для каждого конкретного робота в том случае, если вы желаете задать правила поведения индексация индексируемых роботов в отношении определенного типа контента.
Если же необходимо задать правила индексации для всей поисковой системы, тогда в файле robots.txt прописывается директива для главного робота.
В поисковой системе Google работают свои роботы:
- Googlebot – основной бот Google.
- Googlebot Video – сбор информации о видеороликах, размещенных на площадке.
- Googlebot Images – индексация картинок.
А теперь давайте рассмотрим, как выглядят сами директивы или команды для поисковых роботов.
- Команда User-agent: определяет, какому конкретному роботу предназначена директива. Если в этой команде указана звездочка * – это означает что команда предназначена для всех, любых поисковых роботов.
- Команда Disallow означает запрет индексации, а команда Allow означает разрешение индексации.
Например, команда User-agent: Yandex задает правила поведения для всех поисковых роботов Яндекса. Если юзер-агент не задан, то команды будут действовать для всех поисковых систем.
В общем-то, для того, чтобы вручную редактировать файл robot.txt, не нужно быть опытным программистам.
В профессиональных конструкторах сайтов и системах управления контентом обычно предусмотрен отдельный интерфейс для настройки файла robots.txt. Знать конкретные названия поисковых роботов и разбираться в директивах необходимости нет. Достаточно указать то, что вам нужно в самом файле.
Рассмотрим для примера некоторые команды.
- User-agent: *
- Disallow: /
Эта директива запрещает обход проекта любым роботам всех поисковых систем. Если же будет указана директива Allow — сайт открыт для индексации.
Следующая команда запрещает обход всем поисковым системам, кроме Яндекса.
- User-agent: *
- Disallow: /
- User-agent: Yandex
- Allow: /
Чтобы запретить индексацию только отдельных страниц, создается вот такая команда – запрет на обход страниц «Контакты» и «О компании».
- User-agent: *
- Disallow: /contact/
- Disallow: /about/
Закрыть целый отдельный каталог сайта:
- User-agent: *
- Disallow: /catalog/
Закрыть папку с картинками:
Не индексировать файлы с указанным расширением:
- User-agent: *
- Disallow: /*.jpg
Различных команд, с помощью которых можно управлять поисковыми роботами, существует достаточно много. Веб-мастер может в широких пределах регулировать схему индексации веб-страниц и отдельных типов контента.
Запрет индексации через htaccess
На серверах Apache для управления доступом используется файл .htaccess (hypertext access).
Особенностью функционирования этого файла является то, что его команды распространяются только на папку или каталог, в которых этот файл размещен. Если этот файл помещается в корневой каталог, то его директивы будут действовать на весь ресурс.
Возникает логичный вопрос, зачем использовать более сложный .htaccess, если задать порядок индексации можно в файле robots.txt?
Дело в том, что далеко не все роботы не всех поисковых систем подчиняются команда файла robots.txt. Зачастую поисковые роботы просто игнорируют этот файл.
С другой стороны, директивы .htaccess являются всеобъемлющими по отношению к сайтам, размещенным на серверах типа Apache.
Хотя файл .htaccess тоже является текстовым и может быть отредактирован веб-мастером в простом редакторе, настройка этого файла скорее является прерогативой опытных специалистов техподдержки хостинг-провайдера. Поскольку команд у него намного больше и неопытному человеку очень легко допустить критические ошибки, которые приведут к неправильной работе проекта.
Следующая команда предназначена для запрета индексации сайта определенным поисковым роботам:
SetEnvIfNoCase User-Agent
Далее прописывается конкретный робот поисковой системы.
Для каждого робота команда прописывается отдельной строкой.
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
Как вы могли заметить, хотя .htaccess является простым текстовым файлом, он не имеет расширения txt, а должен иметь именно указанный формат, в противном случае сервер его не распознает.
С помощью админ панели WordPress
Зайдите в административную панель своего блога на WordPress и выберите раздел «Настройки». Нажмите на пункт Меню «Чтение».
После перехода в интерфейс «Чтение», вы найдете следующие возможности для настройки индексации.
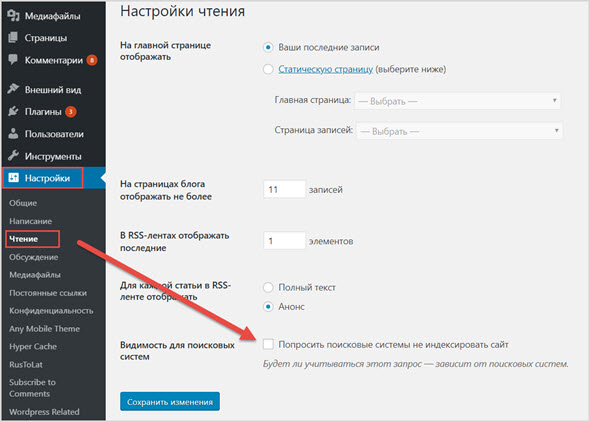
Отметьте пункт «Попросить поисковые системы не индексировать сайт», если не хотите, чтобы контент был доступен в открытом интернете. Не забудьте сохранить изменения.
Как видите, при помощи админ панели WordPress можно сделать только общие запреты или разрешения. Для более тонких настроек индексации следует использовать файл robots.txt и .htaccess.
С помощью meta-тега
Управлять индексацией можно и с помощью тегов в HTML-документе веб-страницы.
Директивы добавляются в файле header.php в контейнере <head> … </head>.
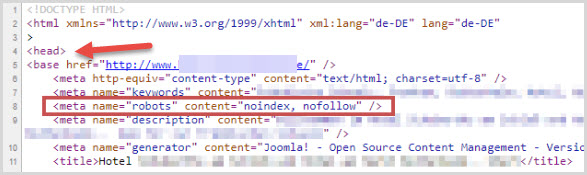
Команда выглядит следующим образом:
<meta name=”robots” content=”noindex, nofollow”/>
Это означает, что поисковым роботам запрещается индексация контента. Если вместо robots указа точное имя бота определенной поисковой машины, то запрет будет касаться только ее роботов.
На этом все, как видите существует много методов, которые позволят скрыть площадку от поисковых систем. Какой использовать вам, решайте сами.
Только помните, что проанализировать правильность директив относительно индексации сайта можно с помощью инструментов Яндекса для веб-мастеров либо через SEO-сервисы.
Запрет индексации страниц сайта в robots.txt
21 августа 2014
Просмотров: 7 370

При посещении сайта, поисковый робот использует ограниченое количество ресурсов для индексации. То есть поисковый робот за одно посещение может скачать определенное количество страниц. В зависимости от частоты обновления, объема, количества документов и многих других факторов, роботы могут приходить чаще и скачивать больше страниц.
Чем больше и чаще скачиваются страницы — тем быстрее информация с Вашего сайта попадает в поисковую выдачу. Кроме того, что страницы будут быстрее появляться в поиске, изменения в содержании документов также быстрее вступают в силу.
Быстрая индексация сайта
Быстрая индексация страниц сайта помогает бороться с воровством уникального контента, позволяет повысить релевантность страницы сайта за счет ее свежести и актуальности. Но самое главное. Более быстрая индексация позволяет отслеживать как те или иные изменения влияют на позиции сайта в поисковой выдаче.
Плохая, медленная индексация сайта
Почему сайт плохо индексируется? Причин может быть множество и вот основные причины медленной индексации сайта.
- Страницы сайта медленно загружаются. Это может стать причиной полного исключения сайта из индекса.
- Сайт редко обновляется. Зачем роботу часто приходить на сайт, на котором новые страницы появляются раз в месяц.
- Неуникальный контент. Если на сайте размещен ворованый контент (статьи, фотографии), поисковая система снизит трастовость (доверие) к вашему сайту и снизит расход ресурсов на его индексацию.
- Большое количество страниц. Если на сайте много страниц и не настроен last modified, то на индексацию или переиндексацию всех страниц сайта может уйти очень много времени.
- Сложная структура сайта. Запутанная структура сайта и большие количество вложений сильно затрудняют индексацию страниц сайта.
- Много «лишних» страниц. На каждом сайте есть целевые страницы, содержание которых статично, уникально и полезно для пользователей и побочные страницы, вроде страниц пагинации, авторизации или страниц фильтров. Если подобные страницы существуют, их как правило очень много, но в индексацию попадают далеко не все. А страницы, которые попадают — конкурируют с целевыми страницами. Все эти страницы регулярно переиндексируются, расходуя и так ограниченый ресурс, выделенный на индексацию вашего сайта.
- Динамические страницы. Если на сайте существуют страницы, содержимое которых не зависит от динамических параметров (пример: site.ru/page.html?lol=1&wow=2&bom=3), в результате может появиться множество дублей целевой страницы site.ru/page.html.
Есть и другие причины плохой индексации сайта. Однако, самой распространенной ошибкой является плохо настроенный robots.txt.
Убрать из индексации все лишнее
Существует множество возможностей рационально использовать ресурсы, которые выделяют поисковики на индексацию сайта. И широкие возможности для управления индексацией сайта открывает именно robots.txt.
Используя дерективы Allow, Disallow, Clean-param и другие, можно эффективно распределить не только внимание поискового робота, но и существенно снизить нагрузку на сайт.
Для начала, нужно исключить из индексации все лишнее, используя дерективу Disallow.
Например, запретим страницы логина и регистрации:
Disallow: /login Disallow: /register
Запретим индексацию тегов:
Disallow: /tag
Некоторых динамических страниц:
Disallow: /*?lol=1
Или всех динамических страницы:
Disallow: /*?*
Или сведем на нет страницы с динамическими параметрами:
Clean-param: lol&wow&bom /
На многих сайтах, число страниц найденых роботом может отличаться от числа страниц в поиске в 3 и более раз. То есть, более 60% страниц сайта не участвуют в поиске и являются баластом, который нужно либо ввести в поиск, либо избавится от него. Исключив, нецелвые страницы и приблизив количество страниц в поиске к 100% вы увидите существенный прирост к скорости индексации сайта, рост позиций в поисковой выдаче и больше трафика.
Подробнее про индексацию сайта, влияние индексации на выдачу, правильную настройку robots.txt, генерацию sitemap.xml, настройку last modified страниц сайта, другие способы ускорения индексации сайта и причины плохой индексации сайта читайте в следующих постах. А тем временем.
Сбрасывайте ненужный баласт и быстрее идите в топ.
Получайте бесплатные уроки и фишки по интернет-маркетингу
Как закрыть сайт от индексации с noindex/robots.txt?
Когда вы занимаетесь SEO для сайт, то часто нужно скрыть какую-либо часть сайта или же целую страницу целиком. В этой записи я расскажу о том как это можно сделать.
Если вам нужно закрыть какую-либо определенную страницу сайта, то можно воспользоваться meta тэгом, который запретить индексацию целой страницы.
Чтобы запретить индексацию страницы для всех ботов, то вы можете воспользоваться HTML кодом ниже.
<meta name="robots" content="noindex">
Если вы нацелены на определенный поисковик (например: Google), то вы можете это сделать как показано ниже.
<meta name="googlebot" content="noindex">
Официального источника можно найти по этой ссылке.
Если вам нужно спрятать из индексации определенную часть страницы вашего сайта, то вы можете воспользоваться <noindex> тэгом.. Как в примере ниже.
<noindex>
<p>Боты не будут этого считывать</p>
</noindex>Все что указано внутри noindex остается вне видимости бота. В целом, информация внутри все равно читается им, но остается проигнорирована при поиске какой-либо информации через поисковик.
robots.txt является самым распространенным видом установки ограничения для просмотра контента ботами. Другими словами, данный файл устанавливает инструкции для ботов (что можно смотреть, а что нет).
Идеального варианта этого файла не существует. Для каждого проекта должен иметься свой собственный robots.txt файл, который правильно настроен и скрывает нежелательные папки/разделы сайта.
Имейте ввиду, что не все боты будут следовать этому файлу. Есть множество других плохих и хороших ботов, которые просто путешествуют по вебу, собирают информацию и тд.
Что я точно вам могу сказать: robots.txt не будет проигнорирован известными поисковыми системами.
Некоторые из примеров я использовал с этого источника. Если кому интересно, зайдите и посмотрите (достаточно не плохой ресурс).
Пример 1
Данный пример имеет два свойства.
User-agent— которое говорит роботу, что любой тип может посетить страницуDisallow— запрещает индексировать какие-либо страницы на сайте, который установит этотrobots.txt
User-agent: * Disallow: /
А вот этот пример (ниже), разрешить посещать любые страницы сайта.
User-agent: * Disallow:
Пример 2
Пример ниже запрещает ботам посещать папку cgi-bin и tmp в корне сайта. Вы можете прописывать сколько захотите Disallow, чтобы полностью расписать инструкции для бота.
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/
Пример 3
Данный пример использует два разных правила.
Первое — это устанавливает правила только для User-agent: Google бота. И разрешает ему анализировать любые страницы сайта.
Второе — это все остальные боты User-agent: *, которые не могут смотреть никакие страницы сайта.
User-agent: Google Disallow: User-agent: * Disallow: /
Чтобы запретить индексаю для определенного файла, можно просто прописать полный путь до файла, от корня сайта. Например, у вас есть файл main.hml, который находится в /src/ папку, то ваш robots будет выглядеть как на примере ниже:
User-agent: * Disallow: /src/main.html
Файл robots.txt — настройка и директивы robots.txt, запрещаем индексирование страниц
Robots.txt — это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится настоящий блокнотом, я рекомендую Notepad ++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи
- В чем его польза
- Директивы и правила написания
- Мета-тег Роботы и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен робот.txt
Как я уже говорил выше — с помощью файла robots.txt мы можем ограничить доступ к поисковым ботовам к документам, т.е. мы напрямую влияем на индексцию сайта. Чаще всего закрывают от индексции:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом.Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые будут бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в копипастятся разные интересные статьи с сайтов конкурентов — то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http: // site.ru / robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «ЯндексМедиа», то общие директивы user-agent не используются для него. Пример написания:
Пользовательский агент: ЯндексБот Disallow: / cart # будет только основным индексирующим роботом Яндекса
Запретить / Разрешить. Это запрет / разрешение индексции конкретного документа или разделу.Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Разрешить». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексцию страницы — просто введи относительный путь до нее (Disallow: / blog / post-1).
Пользовательский агент: Яндекс Запретить: / Разрешить: / статьи # Запрещаем индексцию сайта, кроме 1 раздела статей
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую).Знак доллара означает прерывание. Примеры использования:
Disallow: / page * # запрещает все страницы, конструкции http://site.ru/page Disallow: / arcticles $ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Карта сайта. Если вы используете карту сайта (sitemap.xml) — то в robots.txt она должна указываться так:
Карта сайта: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта).Это правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Хост: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow / Allow.
Задержка сканирования: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно информацию.Прописывать Clean-param следует для динамических страниц:
Clean-param: ref / category / books # указываем, что наша основная страница, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с обязательным
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
Пользовательский агент: Яндекс. Disallow: / cart Разрешить: / cart / images Карта сайта: http://site.ru/sitemap.xml Хост: site.ru Crawl-delay: 2
Мета-тег роботов и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google.Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow / nofollow и index / noindex . Это разрешение / запрет перехода по ссылкам и разрешение / запрет на индексцию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге
следующее:
Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
Пользовательский агент: Яндекс Запретить: / wp-content / uploads / Разрешить: / wp-content / uploads / * / * / Запретить: /wp-login.php Запретить: /wp-register.php Запретить: /xmlrpc.php Запретить: /template.html Disallow: / cgi-bin Запретить: / wp-admin Disallow: / wp-includes Запретить: / wp-content / plugins Запретить: / wp-content / cache Запретить: / wp-content / themes Запретить: / wp-trackback Запретить: / wp-feed Запретить: / wp-comments Disallow: * / trackback Disallow: * / feed Disallow: * / комментарии Запретить: / тег Запретить: / архив Запретить: * / trackback / Запрещение: * / feed / Запретить: * / комментарии / Запретить: /? Feed = Запретить: /? S = Хозяин: romanus.RU Пользовательский агент: * Запретить: / wp-content / uploads / Разрешить: / wp-content / uploads / * / * / Запретить: /wp-login.php Запретить: /wp-register.php Запретить: /xmlrpc.php Запретить: /template.html Disallow: / cgi-bin Запретить: / wp-admin Disallow: / wp-includes Запретить: / wp-content / plugins Запретить: / wp-content / cache Запретить: / wp-content / themes Запретить: / wp-trackback Запретить: / wp-feed Запретить: / wp-comments Disallow: * / trackback Disallow: * / feed Disallow: * / комментарии Запретить: / тег Запретить: / архив Запретить: * / trackback / Запрещение: * / feed / Запретить: * / комментарии / Запретить: /? Feed = Запретить: /? S = Карта сайта: https: // romanus.ru / sitemap.xml
Трэкбэки запрещаю, потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу, чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильных роботов для нужной CMS просто кликните по этой ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере — тут.
Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) — бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексцию страницы?
Как запретить индексцию зеркала?
Для магазина стоит закрывать корзину (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне роботы?
- Да, указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!
.
Создаем правильный файл robots.txt — настраиваем индексцию, директивы
- Зачем robots.txt в SEO?
- Создаем роботов самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Отклонить
- Разрешение индексации Разрешить
- Директива хост robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Роботы — это обыкновенный текстовой файл (.txt), который предоставляется в корне сайта наряду c index.php и другими системными системами. Его можно загрузить через FTP или создать в файлах менеджера у хост-провайдера. Создается данный файл как самый обыкновенный текстовой документ с общим форматом — TXT . Далее файлу присваивается имя РОБОТЫ .Выглядит это следующим образом:

(robots.txt в папке WordPress)
После создания самого файла нужно убедиться, что он доступен по ссылке ваш домен / robots.txt . Именно по этому адресу поисковая система будет искать данный файл.
Большинство систем управления сайтом роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, что обращает внимание оптимизатор при анализе / начале продвижения сайта — это роботс. Именно нем в располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главное зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса.Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем роботов самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен / robots.txt. Не допускается наличие вложений, к примеру ваш домен / page / robots.текст.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем онлайн-генераторы
Если создание своими руками это не для Вас, то существует множество онлайн-генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно.Этот вариант подойдет лишь тем, кто не хочет писать рутинные распространяющиеся варианты распространения правил сайтов.
Сгенерированный онлайн роботс нужно в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть набор шаблонов для распространенных CMS, таких как WordPress, Joomla !, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно.Шаблон позволяет не писать стандартные директивы, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.текст. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots с директивы User-agent :, которая указывает какой поисковой системы или для какого робота инструкции ниже. Пример использования:
Пользователь-агент: Яндекс User-agent: ЯндексБот Пользовательский агент: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота.Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Яндекс
| Название | Описание | Предназначение |
| ЯндексБот | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| ЯндексДирект | Работает контекстной рекламы | Оценивает сайты с точки зрения расположения на контекстных объявлений. |
| ЯндексДиректДин | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| ЯндексМедиа | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| ЯндексИзображения | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл роботов особым образом.Подробнее о нем можно прочесть у Яндекса. |
| ЯндексБлоги | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| Яндекс Новости | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| ЯндексПейджекер | Робот микроразметки | Данный робот отвечает за индексцию и распознание микроразметки сайта. |
| ЯндексМетрика | Робот Яндекс Метрики | Тут все и так ясно. |
| ЯндексМаркет | Робот Я |
.
Добавить комментарий