
|
|
Если вы не нашли ответ на свой вопрос — свяжитесь с нами. |
 FineReader Online спроектирован исключительно для выполнения основных сценариев. Если вы ищете профессиональное OCR-решение,
FineReader Online спроектирован исключительно для выполнения основных сценариев. Если вы ищете профессиональное OCR-решение,
 Для этого на странице входа выберите внешний сервис и далее следуйте инструкции.
Для этого на странице входа выберите внешний сервис и далее следуйте инструкции.
Online сервисы распознавание текста. Просто. Бесплатно и удобно. | Учи Урок информатики
Онлайн распознавание текста – это процесс преобразования символов из сканированного документа или изображения с помощью специальных алгоритмов машинного обучения (веб-программ в случае использования online сервисов). Распознавание текста позволяет нам существенно сэкономить время, ведь их не нужно печатать самостоятельно. Сегодня с помощью оптической технологии распознавания текста OCR в большом количестве создается огромное количество отсканированных книг журналов, которые потом можно читать на компьютере. Оптическое распознавание текста завоевало себе место на рынке информационных услуг и стало популярным, ведь после процедуры определения символов, текст можно не только прочитать, но и перевести с помощью автоматического переводчика, внести правки и форматировать его, применяя различные стили.
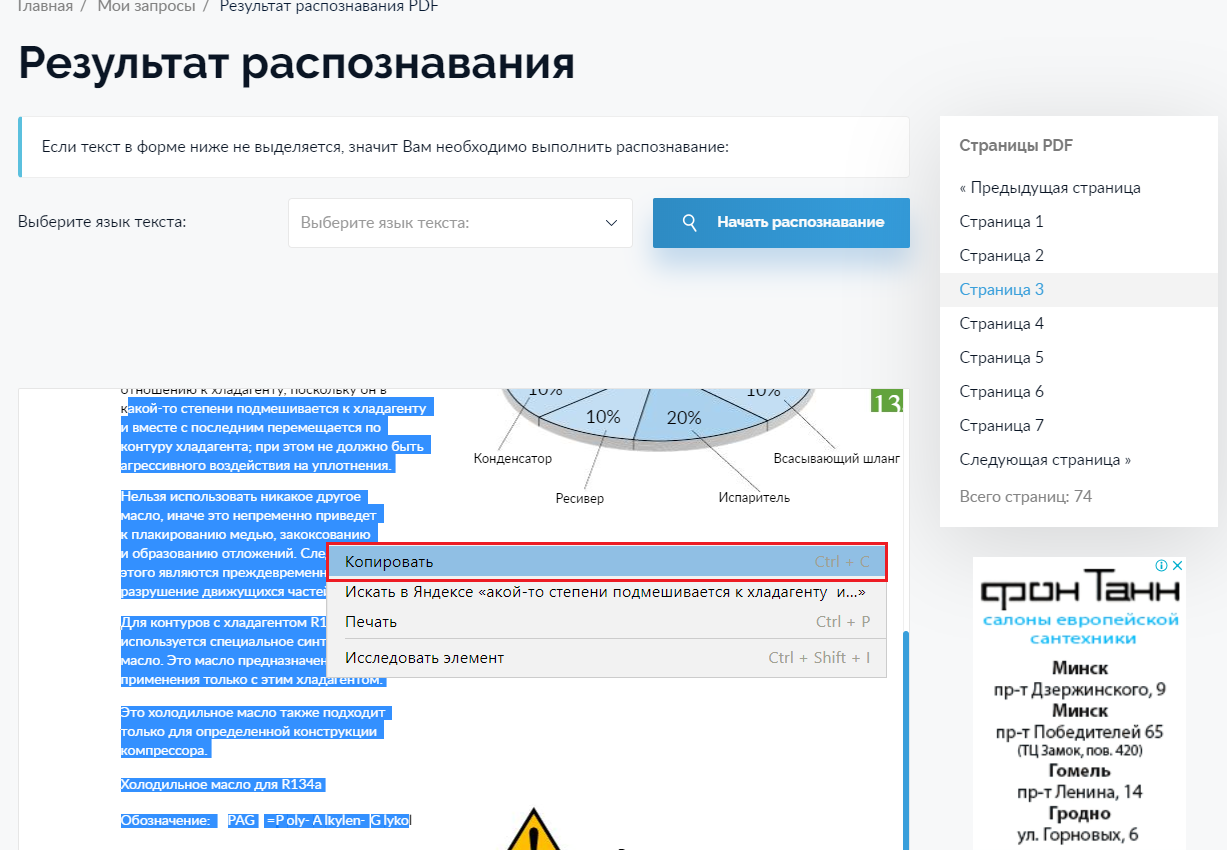
К сожалению, данная технология не может распознать информацию из PDF со стопроцентной точностью, поэтому после завершения распознавания текста на изображении необходимо сравнивать результат и исходные документы (если форматируется большой документ или книга).
1. Онлайн-словарь для распознавания текста ABBYY
Самая популярная программа-словарь, которая имеет функцию определения текста с изображений и других типов документов. Данное приложение позволяет пользователю моментально получить тестовый вариант фотографии и перевести его на более чем на 50 языков мира. Чтобы распознать текст с помощью данного сервиса, следуйте инструкции:
- Зайдите на официальный сайт веб-приложения и нажмите на кнопку «Распознать», которая находится в центре страницы. Официальная ссылка на сервис: https://finereaderonline.com/ru-ru
- Загрузите файл, с которого необходимо распознать инфо;
- Следующим шагом необходимо выбрать язык конечного документа.
 Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
 Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Последний шаг – необходимо выбрать формат конечного файла. С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
2. Сервис Online-Ocr
Данный сервис позволяет без регистрации создать текстовый документ из отсканированного файла или из самой обычной картинки. Данный сервис был первым, кто использовал технологию оптического определения машинного текста. Приведем пример распознавания с ПДФ в Ворд:
- Зайдите на сайт сервиса: http://www.onlineocr.net/
- Нажмите на клавишу «выбрать файл» и найдите на своем компьютере необходимый пдф документ, с которого будет определен текст. Максимальный размер входящего документа равен пяти мегабайтам;
- Выберите язык входящего документа и формат конечного файла из предложенного списка поддерживаемых форматов.
- Нажмите кнопку «Конвертировать»;

Процесс конвертации занимает максимум 5 минут, данный показатель зависит от размера входящего файла, от его кодировки и сложности визуального оформления.
3. Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок. К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
Ссылка на сервис: www.free-ocr.com
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла. Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации. Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться. Самое точное направление распознавания – с формата JPEG в ворд.
Самое точное направление распознавания – с формата JPEG в ворд.
Источник: http://geek-nose.com/onlajn-raspoznavanie-teksta/
Пожалуйста, оцените статью
4.2 из 5. (Всего голосов:259)
Все статьи раздела
PDF в Excel и Word Онлайн бесплатно. Перевести ПДФ в Эксель и Ворд. Распознать таблицу или картинку
Заменить точку на запятую в Excel. Разделитель в Excel, как поменять?
Как сделать красивую надпись в Excel
Как перевести картинку или PDF в Excel и Word онлайн бесплатно? Вопрос насущный и постоянно возникающий у коллег. У меня, конечно, есть FineReader — программа для перевода картинок и сканов в текстовые документы любого формата. Я пользуюсь ей со студенческих времен, когда теорию с книг надо было перенести в рефераты или диплом, не перепечатывая их. Помнится, мне это замечательно сэкономило время, чтобы глубже изучить Excel и использовать его в дипломе! Но ноутбук не всегда со мной, поэтому ниже я сделал обзор сервисов по бесплатному распознаванию текстов онлайн (и никаких пиратских скачиваний).
Часто меня спрашивают, как быстро заменить FineReader, да еще online и бесплатно. Пришлось заняться этой проблемой 😉 5-7 лет назад веб-сервисы казались в России еще каким-то далеким будущим, поэтому я каждый раз открываю для себя бесплатные облачные сервисы привычных оффлайн программ. Поэтому приведу небольших список самых популярных программ конвертеров изображений — для этого будем конвертировать текст на фоне таблицы Excel в не самом лучшем качестве (чтобы проверить качество распознавания текста):
и фото таблицы в стандартном качестве (чтобы посмотреть как распознаются таблицы):
посмотрим, что представлено в интернете
1. PDF в Excel и Word онлайн бесплатно ABBYY FineReader Online
finereaderonline.com
Как, наверное, и должно быть, на первом месте «родной» ABBYY FineReader. Сервис в полном объеме был запущен в середине 2011 года и за эти годы претерпел положительные изменения.
Зарегистрировался. Загрузил фото или PDF, выбрал язык, выбрал формат выводимого документа. Можно сохранить в Excel. Распознает таблицы и выводит их в xlsx документы. Все здорово, все работает на 5+
Распознование (текст) на 9,5 из 10.
Но это был бы не ABBYY, если бы сервис был полностью бесплатным.
После регистрации вам дается только 10 бесплатных страниц, для разового использования идеально подходит. Но если нужно распознавать каждый день или если у вас 100 страниц, сервис не подходит. Будем искать альтернативу.
2. FRee OCR, convertio.co и прочее
Все это довольно известные сервисы распознавания. Их в интернете достаточно много. К сожалению, для PDF распознает только первую страницу в большинстве случаев, или заявлено, что распознает, но не делает этого
Тут все просто. Во всех конвертерах загружаем документ с компьютера, выбираем язык (не везде), жмем Start. Распознается, скачиваем, сохраняем.
Качество распознования 7 из 10.
Распознает довольно сносно обычный текст. Не распознает таблицы (не сохраняет их форму тем более). Нельзя сохранить в Excel или любой табличный редактор текст.
Таких сервисов как эти я пересмотрел штук 15 и сперва опечалился, т.к. считаю, сервис перевода PDF в Excel Онлайн бесплатно очень нужен.
Но потом, я нашел:
3. www.onlineocr.net
Отличный бесплатный сервис все же есть. Здесь можно выбрать язык, что сразу увеличивает качество распознавания текста. Получившиеся данные можно сохранить как в Word, так и в Excel. Можно скопировать результат сразу из браузера. Скачав файл xlsx, вы сохраните даже структуру таблицы — поверьте мне, для бесплатных сервисов — это огромная редкость! Можно распознать PDF или картинку, так же без видимо усложнений.
Работает быстро.
Качество распознавания 7 из 10 (если смотреть по PNG или JPEG).
Уточнение: Неплохо распознает таблицу в PDF, но я рекомендую перевести скан таблицы в jpeg перед началом работы и после распознавать уже как картинку. Так качество опознанного текста получится еще лучше!
Хороший сервис для распознавания PDF в Excel Онлайн, а также распознавания картинок в текст.
Что в итоге
Воду в сите не удержишь, как говорится, и на хороший платный продукт всегда появится бесплатный аналог, сопоставимого качества. Будь это Excel или FineReader.
Уверен, сервис online распознания картинок и защищенных текстов бесплатно будет вам полезен. PDF в Excel и Word онлайн бесплатно может помочь для диплома или лабораторных студентам, а может и сотрудникам компании, которым надо использовать документ, сохраненный только на бумаге.
Удачи!
Поделитесь нашей статьей в ваших соцсетях:
Похожие статьи
Заменить точку на запятую в Excel. Разделитель в Excel, как поменять?
Как сделать красивую надпись в Excel
5 конвертеров PDF в Word онлайн
Во время работы с электронными документами, пользователи часто сталкиваются с необходимостью преобразовать файлы из одного формата в другой формат, например, из PDF в Word онлайн или с помощью соответствующей программы.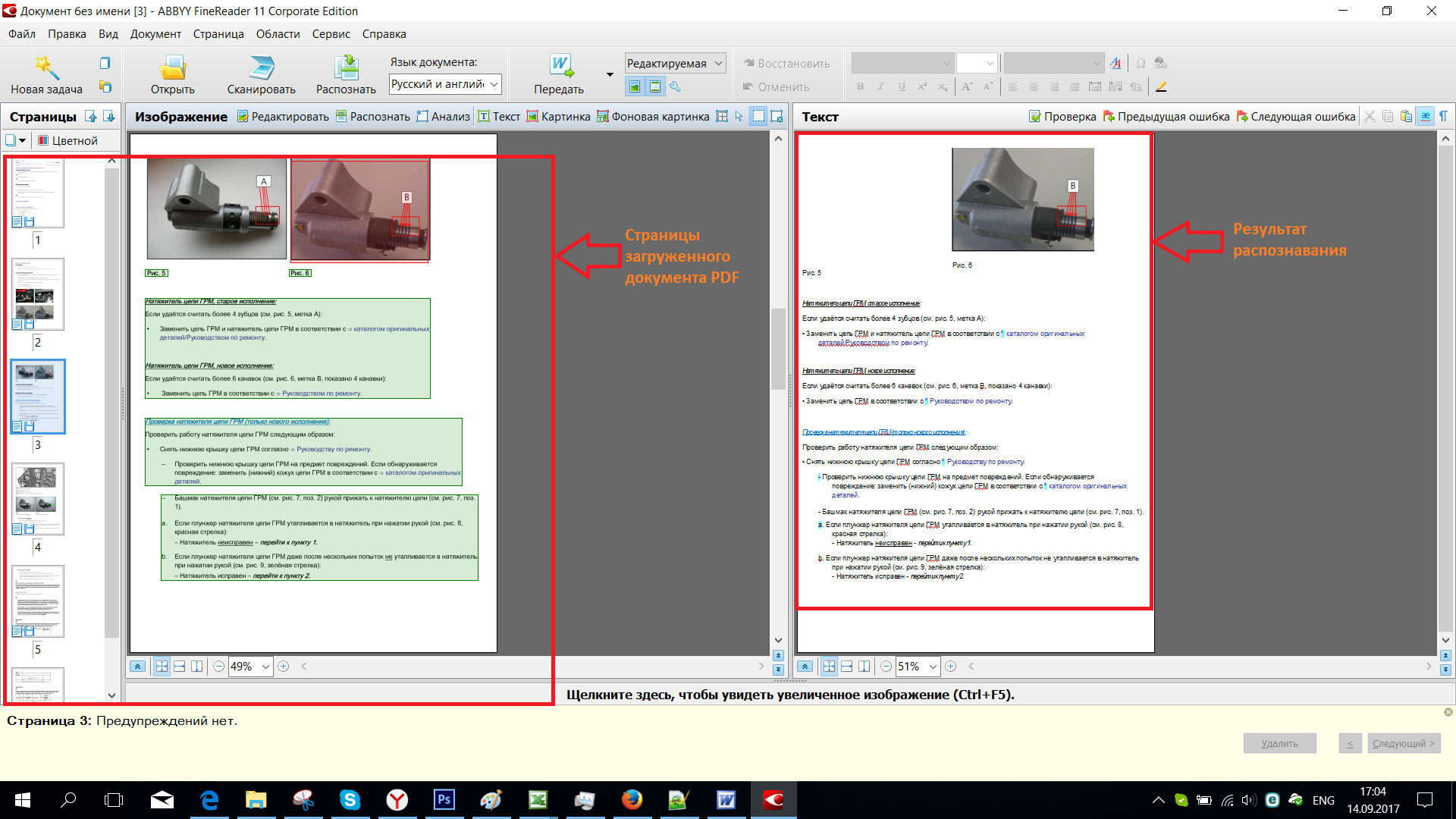 Часто на ПК нет приложений, способных выполнить необходимые операции.
Часто на ПК нет приложений, способных выполнить необходимые операции.
В этом случае, пользователь может конвертировать ПДФ в Ворд онлайн в интернете, без установки на компьютер дополнительного программного обеспечения. Всю работу по преобразованию исходного файла ПДФ в Ворд выполняет онлайн конвертер на удаленном сервере.
PDF и Word — одни из самых распространенных форматов для работы с электронными документами. Но между этими форматами есть существенные различия.
PDF (Portable Document Format) — универсальный переносной формат, созданный в компании Adobe, предназначенный для сохранения электронных книг, инструкций, бланков и форм. Файлы формата имеют расширение «.pdf». Одной из особенностей формата PDF является трудное редактирование исходного документа.
Word — офисная программа, входящая в состав Microsoft Office, широко используемая на предприятиях и в организациях, а также обычными пользователями для создания документов различного типа. У формата Word имеются два расширения файлов «. docx» и «.doc». В отличие от формата PDF, файлы Word легко редактировать.
docx» и «.doc». В отличие от формата PDF, файлы Word легко редактировать.
Принимая во внимание вышесказанное, становится понятно, что для проведения редактирования исходного документа в формате PDF, его необходимо преобразовать в другой формат, позволяющий без труда выполнить нужные действия по редактированию документа, в нашем случае — в формат Word.
Нам необходимо перевести ПДФ в Ворд онлайн. Для этого потребуется использовать сервис в интернете, поддерживающий такую возможность.
Перевод ПДФ в Ворд онлайн имеет свои плюсы и минусы. Из положительных моментов отметим ненужность установки специализированного программного обеспечения на компьютер. У этого способа есть свои недостатки: программы на ПК лучше справляются со большими и сложными документами, на сервисах имеются лимиты на размер исходного файла и размер передаваемых данных.
Следует учитывать, что при конвертировании из PDF в Word не всегда получается хороший результат: после обработки некоторые символы не распознаются, изменяется исходное форматирование. Поэтому необходимо проверить готовый файл и исправить ошибки.
Поэтому необходимо проверить готовый файл и исправить ошибки.
Исходный PDF файл может быть с текстовым содержимым или создан из картинок. В случае, если PDF состоит из изображений, собранных в один файл, необходимо выполнить распознавание текста из ПДФ в Ворд онлайн с помощью инструментов OCR — оптического распознавания символов.
Чтобы решить эту задачу на многих сервисах используется встроенный инструмент OCR (Optical Character Recognition) — технология перевода текста с изображений в обычный текст.
В этом руководстве вы найдете инструкции по конвертированию ПДФ в Ворд онлайн на популярных сервисах: PDF2Go, Online-convert.com, Convertio.co, iLovePDF, Sejda.
Онлайн конвертер PDF в Word на PDF2Go
Сервис PDF2Go имеет 26 инструментов, предназначенных для работы с форматом PDF. PDF2Go помимо обычного конвертирования документа выполняет распознавание ПДФ в Ворд онлайн.
Выполните следующие действия:
- Откройте страницу сайта PDF2Go.
- Нужно нажать на кнопку «Выберите файл», опустить файл с ПК в специальную форму, ввести URL-адрес сайта или добавить файл из облачных хранилищ Dropbox или Google Drive.

- Обратите внимание на параметры конвертирования, установите подходящие настройки.
В разделе «Настройки» нужно выбрать подходящие опции:
- Формат файла — «*.docx» или «*.doc».
- Тип преобразования — в виде изображений или конвертирование с помощью OCR в редактируемый текст версткой (для обычного PDF) или распознаванием (для из изображений).
- Улучшить OCR — перевод исходного документа в монохромный формат для лучшего распознавания.
- Нажмите на кнопку «Начать» для того, чтобы запустить конвертор PDF Word онлайн.
- Далее происходит процесс обработки файла на сервисе.
- Конвертация ПДФ в Ворд онлайн завершена, нажмите на кнопку «Скачать» для загрузки файла на компьютер, загрузите документ в облачное хранилище, или скачайте архив в виде ZIP файла.
Как перевести PDF в Word онлайн на Online-convert.com
Сервис «Он-лайн конвертер документов» Online-convert.com предоставляет услуги по конвертированию текстовых и медиа файлов в другие форматы. Конвертер поддерживает извлечение текста из изображений (OCR) из файла PDF.
Конвертер поддерживает извлечение текста из изображений (OCR) из файла PDF.
Чтобы извлечь текст из ПДФ в Ворд онлайн пройдите шаги:
- Перейдите по ссылке на страницу сервиса online-convert.com.
- Выполните одно из предложенных действий: перетащите файлы в форму на странице сайта, нажмите на кнопку «Выберите файлы», введите URL-адрес, загрузите файл из Dropbox или Google Drive.
- Перейдите в раздел «Дополнительные настройки», чтобы выбрать параметры конвертирования.
Здесь доступны следующие опции:
- Оптическое распознавание текста.
- Выбор языка текста.
- Выбор второго языка текста.
- Оптимизация — «Разметка» или «Текст».
- Монохромный режим.
- Нажмите на кнопку «Начать конвертирование».
- Перевод из PDF в Word онлайн закончен, скачайте обработанный файл на компьютер, загрузите ZIP архив на ПК, или загрузите документ в облако.
Файлы хранятся на сервисе Online-convert в течение 24 часов.
Как перевести ПДФ в Ворд бесплатно на Convertio.co
Convertio.co — сервис для конвертирования медиа файлов большого количества форматов, работающий на русском языке.
Обратите внимание на то, что сервис без регистрации конвертирует файлы размером до 100 МБ.
Необходимо пройти последовательные шаги:
- Зайдите на страницу сайта Convertio.co.
- Сначала выберите начальный формат — PDF, а затем итоговый формат — DOCX или DOC.
- Перетащите файл в форму или нажмите на кнопку «Выберите файлы», чтобы добавить документ с компьютера, с «облаков» Google Drive или Dropbox, или по URL-адресу.
- На следующей веб-странице нажмите на кнопку «Конвертировать».
- Документ преобразован из ПДФ в Ворд онлайн, нажмите на кнопку «Скачать» для загрузки готового файла на компьютер.
Обработанные файлы хранятся на сервисе в течение 24 часов.
Конвертер текста ПДФ в Ворд на iLovePDF
На сервисе iLovePDF можно конвертировать файлы из PDF в Word онлайн бесплатно. Здесь имеется 23 инструмента, поддерживающих работу с форматом PDF.
Здесь имеется 23 инструмента, поддерживающих работу с форматом PDF.
Вам также может быть интересно:
Вам потребуется совершить следующие действия:
- Войдите на страницу сервиса iLovePDF.
- Нажмите на кнопку «Выбрать PDF файл», перетащите документ с ПК, или добавьте из облачных хранилищ Google Drive или Dropbox.
- Нажмите на кнопку «Преобразовать в Word».
- Дождитесь окончания процесса, а затем скачайте готовый файл на ПК, поделитесь ссылкой на скачивание, отсканируйте QR-код, загрузите документ Word в Google Диск или Dropbox.
Как конвертировать PDF в Word онлайн на Sejda
Онлайн сервис Sejda предоставляет большое количество инструментов для работы с файлами в формате PDF. Этот сервис работает на английском языке.
Пройдите последовательные шаги:
- Перейдите на страницу сервиса Sejda.
- Перетащите мышью файл в специальную область на странице сервиса, или нажмите на кнопку «Upload PDF files» для загрузки файла с ПК, из облачных хранилищ Dropbox, Google Drive, OneDrive, или по URL-адресу.
- В окне «Choose an option» (Выбрать опцию) нужно активировать одну из кнопок: «Keep layout» (Сохранить макет) или «Optimize for legibility» (Оптимизировать для разборчивости).
- После выбора параметров нажмите на кнопку «Continue» (Продолжить).
- Затем проходит конвертация PDF в Word онлайн.
- Нажмите на кнопку «Download» для скачивания документа Word на компьютер, сохраните файл в облачных хранилищах Dropbox, OneDrive, Google Drive, отправьте по e-mail на электронную почту.
Файлы хранятся на сервере в течение 2 часов, после чего автоматически удаляются. Бесплатно можно конвертировать до 10 страниц или 50 МБ, разрешено выполнять не более 3 задач в 1 час.
Выводы статьи
Форматы PDF и Word часто используются для хранения электронных документов. При работе на компьютере происходят ситуации, при которых необходимо файл ПДФ конвертировать в Ворд онлайн, если на компьютере нет программного обеспечения, имеющего подобные функции. Для решения этой задачи можно преобразовать PDF Word онлайн на сервисах в интернете: PDF2Go, Online-convert.com, Convertio.co, iLovePDF, Sejda.
Для решения этой задачи можно преобразовать PDF Word онлайн на сервисах в интернете: PDF2Go, Online-convert.com, Convertio.co, iLovePDF, Sejda.
Как конвертировать PDF в Word онлайн (видео)
Похожие публикации:
https://vellisa.ru/convert-pdf-to-word-online5 конвертеров PDF в Word онлайнhttps://vellisa.ru/wp-content/uploads/2020/08/0-1.pnghttps://vellisa.ru/wp-content/uploads/2020/08/0-1.pngВасилийТекстВо время работы с электронными документами, пользователи часто сталкиваются с необходимостью преобразовать файлы из одного формата в другой формат, например, из PDF в Word онлайн или с помощью соответствующей программы. Часто на ПК нет приложений, способных выполнить необходимые операции. В этом случае, пользователь может конвертировать ПДФ в Ворд онлайн в…ВасилийВасилий [email protected]Автор 700+ статей на сайте Vellisa.ru. Опытный пользователь ПК и ИнтернетИнтернет и программы для всех
Оптическое распознавание текста
Оптическое распознавание текста позволяет преобразовывать изображения текста PDF документа в редактируемый текстовый формат, который поддерживает возможность поиска текста в документе, его копирование и редактирование. Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Для включения оптического распознавания текста выберите в главном меню Документ > Распознавание текста. В диалоговом окне укажите следующие параметры:
- Диапазон страниц Укажите диапазон страниц, на которых необходимо произвести распознавание текста.
- Языки Укажите язык/языки распознаваемого текста. Желательно выбирать минимальное количество вариантов. Это улучшит качество распознавания текста.
Если распознавание текста используется первый раз, данный список будет пустым. Для добавления языков нажмите кнопку Установить языки.
- Установить языки Установите маркеры, чтобы выбрать необходимые варианты. В диалоговом окне перечислены языки, для которых поддерживается распознавание текста в Master PDF Editor.
- Шрифт Выберите вариант шрифта, который будет использоваться в документе после распознавания текста. При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа.
- Текст с возможностью поиска При выборе данной опции после завершения процедуры распознавания текст будет доступен для поиска и копирования. Распознанный текст вставится в документ как невидимый под своим изображением.
- Редактируемый текст При выборе данной опции после завершения процедуры распознавания текст будет доступен для редактирования. Распознанный текст вставится поверх изображения с данным текстом. Само изображение при этом затирается фоном.
- Вручную редактировать весь распознанный текст При выборе данной опции во время процедуры распознавания текста открывается диалоговое окно, в котором будет отображаться:
 При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа.
При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа.- Оригинал Фрагмент изображения с текстом
- Текст Соответствующий изображению автоматически распознанный текст.
В диалоговом окне поочередно будет отображаться каждый фрагмент изображения PDF документа с соответствующим ему распознанным текстом. Здесь можно редактировать распознанный текст перед вставкой в документ.
Здесь можно редактировать распознанный текст перед вставкой в документ.
- Да Автоматически распознанный/редактированный текст запишется в документ. В диалоговом окне отобразится следующее изображение и текст к нему.
- Да для всех Все изображения будут распознаны автоматически и записаны в документ. Данное диалоговое окно больше не появится
- Не текст Текущий распознанный текст не является текстовым фрагментом. Отменяет вставку текста в текущем фрагменте.
- Отмена Отмена распознавания текста
Страница не найдена — Информационные технологии в школе
Требованиями установлено, что документы, самостоятельно разрабатываемыеи утверждаемые образовательной организацией, размещаются на Сайте в форме электронных документов, подписанных простой электронной подписьюв соответствии с Федеральным законом от 6 апреля 2011 г. № 63-ФЗ«Об электронной подписи» (далее — Федеральный закон № 63-ФЗ). Электронный документ — до […]
№ 63-ФЗ«Об электронной подписи» (далее — Федеральный закон № 63-ФЗ). Электронный документ — до […]
В разделе «Профилактика нарушений обязательных требований» официального сайта Федеральной службы по надзору в сфере образования и науки (официальный сайт Рособрнадзора) опубликован комментарий Федеральной службы по надзору в сфере образования и науки в связи с актуализацией Требований к структуре официального сайта образовательной организации в информационно […]
Приказ Федеральной службы по надзору в сфере образования и науки от 14.08.2020 № 831 «Об утверждении Требований к структуре официального сайта образовательной организации в информационно-телекоммуникационной сети «Интернет» и формату представления информации»(Зарегистрирован 12.11.2020 № 60867) — Скачать PDF-файл для качественной печати (748 Кб) — Печать д […]
До 28 августа 2020 года на сайте общеобразовательной организации должна быть размещена информация: раздел «Особенности организации учебного процесса в 2020-2021 учебном году», раздел «Горячее питание в школе». (01.09.2020 вступают в силу изменения в статье 37 закона об образовании, введенные ФЗ от 01.03.2020 №47-ФЗ, об обеспечении учеников начальной школы (с […]
(01.09.2020 вступают в силу изменения в статье 37 закона об образовании, введенные ФЗ от 01.03.2020 №47-ФЗ, об обеспечении учеников начальной школы (с […]
Правительство РФ дополнило перечень информации, размещаемой на официальном сайте образовательной организации. В частности, с 22 июля на сайте необходимо указывать: численность обучающихся, являющихся иностранными гражданами; места осуществления образовательной деятельности при использовании сетевой формы реализации образовательных программ; места проведения […]
Как отредактировать PDF на Mac и распознать текст на изображении
Вскоре после того, как я купил свой первый Mac, встал вопрос о приложении для редактирования PDF. Возможность открывать такие файлы для чтения с помощью встроенной утилиты «Просмотр» была приятным сюрпризом, но когда нужно было отредактировать текст, изображение или добавить подпись, приходилось искать сторонние решения. Apple вроде могла бы добавить мощный редактор PDF в macOS, но, увы, его там нет — и, скорее всего, появится он не раньше, чем приложение «Калькулятор» на iPad.
Apple вроде могла бы добавить мощный редактор PDF в macOS, но, увы, его там нет — и, скорее всего, появится он не раньше, чем приложение «Калькулятор» на iPad.
Годных редакторов PDF для Mac не так много
На ум сразу приходит решение от Adobe, и действительно оно весьма неплохое, но после пробного периода встает вопрос об оформлении подписки. А она стоит совсем недешево. Но скачивать какие-то непонятные программы тоже не хочется, поэтому оптимальный выход — найти альтернативу в Mac App Store. Все приложения, которые туда попадают, проходят тщательный отбор модераторами, так что в их качестве можно быть уверенным.
В итоге выбор остановился на PDFelement 7. Это приложение выполняет все задачи, которые требуются от редактора PDF: позволяет изменять текст и изображения, добавлять аннотации и водяные знаки, объединять несколько PDF-файлов в один и даже извлекать данные из PDF, который сделаны в виде изображения (как большинство сканов, например).
Интерфейс приложения напоминает продукты Microsoft Office, но основные элементы управления размещены слева и справа. Среди них быстрый доступ к редактированию текста, изображений, ссылок, форм и другим инструментам. Справа можно посмотреть оставленные закладки и, например, комментарии других пользователей.
Среди них быстрый доступ к редактированию текста, изображений, ссылок, форм и другим инструментам. Справа можно посмотреть оставленные закладки и, например, комментарии других пользователей.
Минималистичный интерфейс, похожий на Microsoft Word
Разобраться в приложении можно за несколько секунд, все довольно интуитивно
После недавнего обновления редактировать PDF стало еще удобнее — за пару кликов выделяем цветом интересующий текст, создаем пометки в виде всплывающего или встроенного текста, добавляем аннотации в виде геометрических фигур, линий или стрелок. Либо же вносим изменения в сам текст документа, воспользовавшись клавиатурой. Приложение также позволяет добавлять колонтитулы, номера страниц, водяные знаки и другие элементы оформления.
А вот это прям круто — распознавание картинок в любом PDF
Есть совместное редактирование, так что аннотации увидят все ваши коллеги с доступом к документу
Готовый файл можно экспортировать в один из популярных форматов (не только PDF, но и MS Office, текстовые документы или графические файлы).
Помимо этого, приложение умеет конвертировать файлы в PDF и обратно, создавать PDF из отсканированных изображений, распознавать текст для последующего редактирования. Например, если у вас отсканированная таблица в PDF, вы хотите ее немного подкорректировать и распечатать. Заходите в «Инструменты» и выбираете «Оптическое распознавания текста». И на выходе получаете документ, полностью готовый для редактирования.
Оптическое распознавание текста позволяет перевести любой скан в формат для редактирования
Позаботились разработчики и о конфиденциальности. Для обеспечения дополнительной защиты вы можете внести необходимые настройки доступа. Например, вы можете сами определять границы свободы для пользователей, у которых на компьютере окажется ваш файл, и запретить им редактировать или даже просматривать его при отсутствии необходимого пароля. Все это в дополнение к возможности оставить водяной знак. Инструменты защиты выделены в отдельное меню для удобства.
Защитить документ водяным знаком? Нет ничего проще
В специальном меню доступны опции для защиты и объединения PDF
Кстати, помимо настольной версии у PDFelement имеется и версия для iPhone и iPad, в которой тоже можно аннотировать PDF-документы, хотя и не поддерживается оптическое распознавание текста.
Чем удобно еще такое приложение, как PDFelement 7, так это гибкой системой подписок. Если вам нужны только основные функции, можно оформить стандартную подписку, а для доступа к профессиональным возможностям вроде распознавания текста предусмотрена профессиональная подписка. Но даже в простой подписке вы сможете добавлять аннотации и пометки к документам, объединять файлы в PDF, а также перемещать, удалять и добавлять страницы. Тем же, кто желает максимально близко подружиться с форматом PDF, лучше оформить профессиональную подписку. Поскольку приложение доступно в Mac App Store, есть различные варианты доступа к программе — от подписки на 1, 3 или 12 месяцев до бессрочной лицензии. А если вы не уверены в покупке, вы всегда можете воспользоваться демо-версией, доступной по ссылке ниже.
Название: PDFelement 7
Издатель/разработчик: Wondershare
Цена: Бесплатно / Подписка
Совместимость: Windows, Mac
Ссылка: Установить
Как распознать PDF бесплатно онлайн
Оптическое распознавание символов, аббревиатура которого — OCR, — это функция, которая оцифровывает документы на основе изображений и делает их редактируемыми. Помимо того, что текст можно редактировать, он также позволяет выполнять поиск содержимого в отсканированном файле PDF. Более того, вы сможете копировать и вставлять отсканированный файл. Эта функция часто включается в программное обеспечение для получения потрясающих результатов. В этой статье мы рассмотрим 6 лучших бесплатных инструментов, которые помогут вам OCR PDF в Интернете.
Помимо того, что текст можно редактировать, он также позволяет выполнять поиск содержимого в отсканированном файле PDF. Более того, вы сможете копировать и вставлять отсканированный файл. Эта функция часто включается в программное обеспечение для получения потрясающих результатов. В этой статье мы рассмотрим 6 лучших бесплатных инструментов, которые помогут вам OCR PDF в Интернете.
6 лучших инструментов для онлайн-распознавания текста PDF
1. Hipdf
Важно отметить, что HiPDF предлагает функции оптического распознавания текста, которые позволяют преобразовывать отсканированные PDF-файлы во что-то, что доступно для поиска, выбора и редактирования. Он прост в использовании с дружественным пользовательским интерфейсом и может выполнять другие задачи преобразования, такие как преобразование из PDF в Word, Excel, изображение, PPT или преобразование из этих форматов в PDF. Его платформа защищена, поскольку в ней используется высококлассное шифрование SSL, а это означает, что ваши документы защищены на платформе.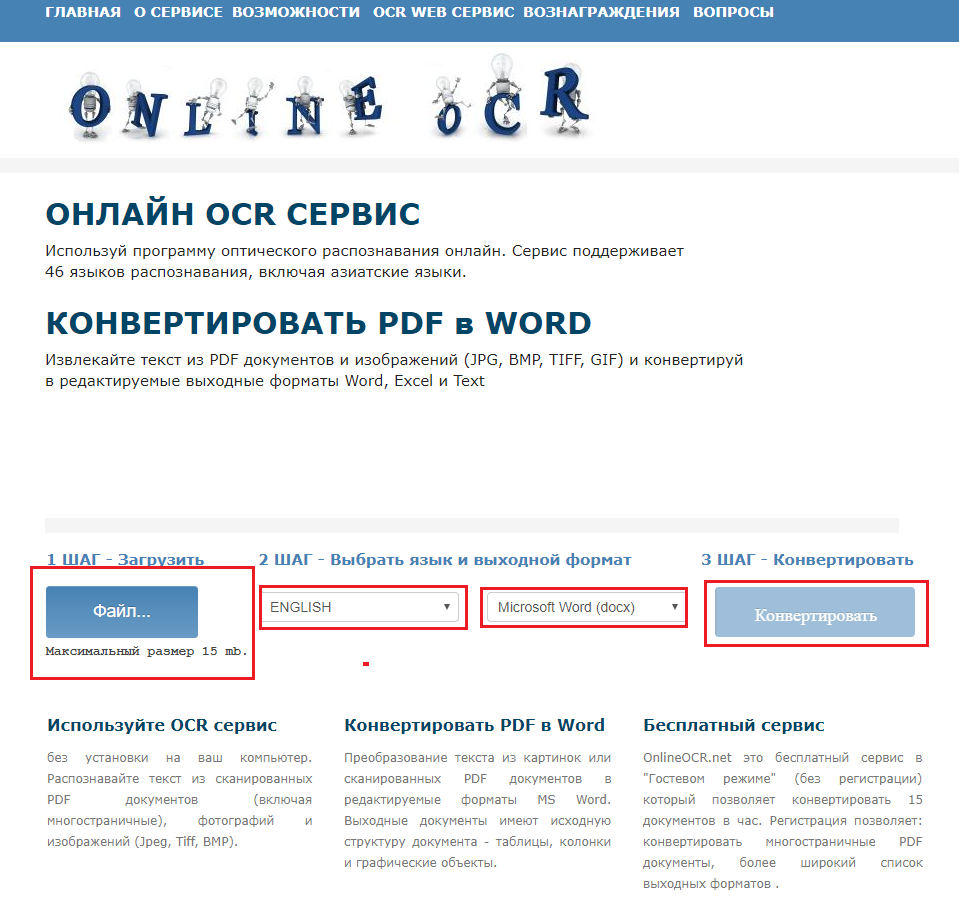 HiPDF — один из лучших, вы можете посетить этот конвертер PDF в Word онлайн OCR, чтобы узнать.
HiPDF — один из лучших, вы можете посетить этот конвертер PDF в Word онлайн OCR, чтобы узнать.
2. OnlineOCR
Одним из бесплатных веб-сайтов, предлагающих функцию OCR, является Online OCR. Этот сайт позволяет конвертировать PDF в редактируемые форматы, такие как Word, Excel и Text. Кроме того, этот красивый веб-сайт позволяет извлекать изображения и тексты из вашего PDF-файла. Он-лайн OCR является многоязычным и поддерживает до 46 языков, включая английский, датский, китайский, корейский, эстонский финский и многие другие.Вам нужно просто зарегистрироваться, чтобы пользоваться всеми его функциями.
3. Бесплатное онлайн-распознавание текста
Еще один бесплатный веб-сайт, оснащенный бесплатной технологией OCR PDF, — Free Online OCR. Его OCR позволяет конвертировать отсканированные PDF-файлы, снимки экрана и изображения в такие форматы, как Word, Excel и тексты. Его пользовательский интерфейс удобен и позволяет загружать файл и выбирать его выходной формат, а затем просто конвертировать.
4. Бесплатное OCR
Free OCR также является еще одним популярным веб-сайтом с бесплатным OCR PDF, который позволяет конвертировать отсканированные файлы и фотографии в документы.Прелесть этого сайта в том, что он не требует регистрации при отправке адреса электронной почты. Когда вы находитесь на сайте, просто загрузите отсканированный файл и выберите язык OCR, а затем конвертируйте. Он поддерживает до 29 языков OCR, таких как английский, французский, словацкий, украинский, польский и многие другие.
5. i2OCR
i2OCR — еще одно бесплатное онлайн-средство распознавания текста, которое позволяет распознавать отсканированные файлы. Его OCR поддерживает более 70 языков, используемых по всему миру. Он также поддерживает основные форматы изображений, такие как PNG, JPEG, BMP и многие другие.На этом веб-сайте вы сможете распознавать отсканированные файлы и изображения с помощью оптического распознавания текста всего за несколько кликов. Он выводит эти файлы в Word, Text и форматы, совместимые с Adobe PDF.
6. NewOCR
Сайт
NewOCR также является бесплатным онлайн-оптическим распознаванием текста, который не может не попасть в нашу пятерку лучших. Это программное обеспечение имеет возможность оцифровывать ваши изображения и отсканированные документы и преобразовывать их в обычный текст, Word и Adobe Acrobat. Это позволяет многократно загружать файлы изображений на сайт. Более того, этот сайт поддерживает 106 языков OCR.NewOCR — один из немногих веб-сайтов, распознающих математические уравнения.
Ограничения онлайн-инструментов распознавания текста PDF
Бесплатные онлайн-инструменты полезны, когда вы выполняете оптическое распознавание символов для небольших документов или изображений. По большей части это экономически выгодно и доступно для использования, во всяком случае, они даже не требуют регистрации. Напротив, у этих сайтов есть ограничения, о которых говорится ниже.
- Они предлагают ограниченные форматы вывода по сравнению с программным обеспечением.
- Размер файла для оцифровки ограничен определенным МБ в зависимости от веб-сайта, обычно 100 МБ.
- Бесплатное онлайн-распознавание текста поддерживает только английский язык распознавания текста.
- Некоторым требуется регистрация для доступа к некоторым функциям.

Лучшее программное обеспечение для оптического распознавания текста для настольных ПК для работы с отсканированными PDF-файлами
Как отмечалось выше, онлайн-инструменты оптического распознавания текста предлагают решение, но с некоторыми ограничениями. Чтобы обуздать это, вам нужно использовать настольный инструмент OCR, который предлагает широкий спектр функций.Инструмент идеи — PDFelement. Этот инструмент имеет передовую функцию распознавания текста, которая делает ваш отсканированный файл и изображения доступными для редактирования и поиска. Кроме того, эта функция многоязычна и поддерживает популярные во всем мире языки, такие как корейский, голландский, английский, финский, немецкий, французский и многие другие.
Помимо выполнения оптического распознавания текста для файлов на основе изображений, PDFelement также предлагает широкий набор инструментов редактирования, позволяющих выделять, комментировать, изменять тексты, добавлять заметки и упоминать лишь некоторые из них. Он может выводить ваш PDF-файл в Word, PPT, текст, Excel, изображения, EPUB и т. Д.а также создание PDF из пустых документов, HTML, изображений и снимков экрана. Вы также можете создавать формы и заполнять формы.
Скачать или купить PDFelement бесплатно прямо сейчас!
Скачать или купить PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Извлечь текст из изображения и PDF
Данные, полученные с помощью Google Vision OCR Данные, полученные с помощью Tesseract OCR
. Бесплатная онлайн-служба Nanonets OCR (оптическое распознавание символов) позволяет извлекать текст из изображений и документов точно, в масштабе и на нескольких языках.Большинство API-интерфейсов OCR сегодня просто делают слепой дамп неструктурированных данных в изображениях и документах; и много времени уходит на очистку извлеченного текста и данных. Nanonets — это единственное средство OCR для распознавания текста, которое представляет извлеченный текст и данные в четко структурированных и организованных форматах, которые можно полностью настроить. Собранные данные могут быть представлены в виде таблиц, позиций или любого другого формата.
Бесплатная онлайн-служба Nanonets OCR (оптическое распознавание символов) позволяет извлекать текст из изображений и документов точно, в масштабе и на нескольких языках.Большинство API-интерфейсов OCR сегодня просто делают слепой дамп неструктурированных данных в изображениях и документах; и много времени уходит на очистку извлеченного текста и данных. Nanonets — это единственное средство OCR для распознавания текста, которое представляет извлеченный текст и данные в четко структурированных и организованных форматах, которые можно полностью настроить. Собранные данные могут быть представлены в виде таблиц, позиций или любого другого формата.
Хотите извлекать текст из изображений и PDF-файлов? Требуется бесплатное онлайн-оптическое распознавание текста для распознавания текста PDF или извлечения данных PDF? Ознакомьтесь с онлайн-API OCR Nanonets в действии и начните создавать собственные модели OCR бесплатно!
Вот три способа использования Nanonets OCR для обнаружения и извлечения текста из изображений или извлечения данных из PDF-файлов и других типов документов.
Оглавление
Как извлекать текст из изображений и PDF-файлов с помощью предварительно обученных моделей оптического распознавания символов Nanonets
Nanonets имеет предварительно обученные модели оптического распознавания символов для конкретных типов документов, перечисленных ниже. Каждая предварительно обученная модель OCR обучена точно соотносить текст в изображении / типе документа с соответствующим полем, таким как имя, адрес, дата, срок действия и т. Д.
- Счета-фактуры
- Квитанции
- Водительские права (США)
- Паспорта
- Карточки меню
- Резюме
- Номерные знаки
- Показания счетчиков
- Транспортные контейнеры
Наносети онлайн OCR & OCR API имеют много интересных вариантов использования.
Шаг 1. Выберите подходящую модель OCR
Войдите в Nanonets и выберите модель OCR, соответствующую файлу или документу, из которого вы хотите извлечь текст и данные в цифровом виде. Если ни одна из предварительно обученных моделей OCR не соответствует вашим требованиям, вы можете пропустить и узнать, как создать свою собственную модель OCR.
Если ни одна из предварительно обученных моделей OCR не соответствует вашим требованиям, вы можете пропустить и узнать, как создать свою собственную модель OCR.
Nanonets предварительно обученные модели OCR
Шаг 2: Добавьте файлы
Добавьте файлы / изображения / документы, из которых вы хотите извлечь текст.Вы можете добавить столько файлов, сколько захотите.
Добавьте файлы
Шаг 3: Тест
Подождите несколько секунд, пока модель запустится и извлечет текст / данные из изображения / документа.
Выполняется распознавание и извлечение текста
Шаг 4. Подтвердить
Быстро проверьте данные, извлеченные из каждого файла, проверив вид таблицы справа. Вы можете легко дважды проверить, правильно ли распознан текст и сопоставлен ли он с соответствующим полем или тегом.
Проверить наличие извлеченного текста в виде таблицы
На этом этапе вы даже можете редактировать / исправлять значения полей и метки.Наносети не связаны шаблоном документа.
Редактировать извлеченный текст или данные
Извлеченные данные могут отображаться в формате «Список» или «JSON».
Представление извлеченного текста в виде списка в формате JSON
Вы можете установить флажок рядом с каждым значением или полем, которое вы проверяете, или щелкнуть «Проверить данные» для немедленного продолжения.
Проверить данные
Шаг 5: Экспорт
После проверки всех файлов. Вы можете экспортировать аккуратно организованные данные в виде файлов xml, xlsx или csv.
Экспорт извлеченных данных
Обратите внимание на то, как извлеченные данные организованы и представлены в аккуратном, удобном и понятном формате.
Аккуратно представленные экспортированные данные
Как извлекать текст из изображений и PDF-файлов путем создания пользовательской модели Nanonets OCR
Создание пользовательской модели OCR с Nanonets очень просто. Обычно вы можете построить, обучить и развернуть модель для любого типа документа на любом языке менее чем за 25 минут (в зависимости от количества файлов, используемых для обучения модели).Посмотрите видео ниже, чтобы выполнить первые 4 шага этого метода:
 youtube.com/embed/LnOMJDtCCNY?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Как обучить свою собственную модель OCR с помощью Nanonets
youtube.com/embed/LnOMJDtCCNY?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Как обучить свою собственную модель OCR с помощью Nanonets
Шаг 1. Создайте свою собственную модель OCR
Войдите в Nanonets и нажмите «Создать свою собственную модель OCR» .
Создайте свою собственную модель OCR
Шаг 2: Загрузите обучающие файлы / изображения
Загрузите файлы примеров, которые будут использоваться для обучения моделей OCR. Точность модели OCR, которую вы создаете, во многом будет зависеть от качества и количества файлов / изображений, загруженных на этом этапе.
Загрузка файлов обучения. Загрузка файлов обучения.
. Шаг 3. Добавление комментариев к файлам / изображениям.
. или данные с соответствующим полем или меткой.Этот важный шаг научит вашу модель OCR извлекать соответствующий текст из изображений и связывать его с настраиваемыми полями, соответствующими вашим потребностям.
Добавление комментариев к обучающему файлу Аннотирование обучающего файла
Вы также можете добавить новую метку для аннотирования текста или данных. Помните, что Nanonets не связаны шаблоном документа.
Добавление новой метки Аннотации с новой меткой
Шаг 4: Обучите пользовательскую модель OCR
После завершения аннотации для всех обучающих файлов / изображений нажмите «Обучить модель».Обучение обычно занимает от 20 минут до 2 часов в зависимости от количества файлов и моделей в очереди для обучения. Вы можете перейти на платный план, чтобы получить более быстрые результаты на этом этапе (обычно менее 20 минут).
Обучите свою модель OCR
Nanonets использует глубокое обучение для создания различных моделей OCR и их сравнения друг с другом на точность. Затем Nanonets выбирает лучшую модель OCR (на основе ваших входных данных и уровней точности). На вкладке «Метрики модели» показаны различные измерения и сравнительный анализ, которые позволили Nanonets выбрать лучшую модель OCR среди всех созданных. Вы можете переобучить модель (предоставив более широкий диапазон обучающих изображений и улучшенные аннотации) для достижения более высокого уровня точности.
Вы можете переобучить модель (предоставив более широкий диапазон обучающих изображений и улучшенные аннотации) для достижения более высокого уровня точности.
Метрики модели OCR Метрики модели OCR
Или, если вас устраивает точность, нажмите «Тест», чтобы протестировать и проверить, работает ли эта пользовательская модель OCR должным образом на образце изображений или файлов, из которых необходимо передать текст / данные. извлечен.
Шаг 5. Тестирование и проверка данных
Добавьте несколько образцов изображений для тестирования и проверки пользовательской модели OCR.
Проверка производительности модели OCR Проверка точности извлеченного текста
Если текст был распознан, извлечен и представлен надлежащим образом, экспортируйте файл. Как вы можете видеть ниже, извлеченные данные были организованы и представлены в аккуратном формате.
Аккуратно перечисленные экспортированные данные
Поздравляем, вы создали и обучили свой собственный онлайн-инструмент распознавания текста!
Как обучить свои собственные модели для программного обеспечения OCR или приложения OCR с помощью NanoNets API
Если у вас есть программное обеспечение или приложение OCR, вот подробное руководство по обучению ваших собственных моделей OCR с использованием Nanonets API.
Шаг 1. Клонируйте репо
git clone https://github.com/NanoNets/nanonets-ocr-sample-python
CD наносети-ОКР-образец-Python
запросы на установку sudo pip
sudo pip install tqdm Шаг 2: Получите бесплатный ключ API
Получите бесплатный ключ API с https://app.nanonets.com/#/keys
Шаг 3. Установите ключ API как переменную среды
экспорт NANONETS_API_KEY = ВАШ_API_KEY_GOES_HERE
Шаг 4. Создайте новую модель
python./code/create-model.py
Примечание: это генерирует MODEL_ID, который вам нужен для следующего шага
Шаг 5: Добавить идентификатор модели в качестве переменной среды
экспорт NANONETS_MODEL_ID = YOUR_MODEL_ID
Шаг 6: Загрузите обучающие данные
Соберите набор данных обучающих изображений или документов, из которых вы хотите распознать и извлечь текст. Когда у вас есть готовый набор данных в папке изображений (файлы изображений), начните выгрузку набора данных.
питон ./code/upload-training.py
Шаг 7. Обучите модель
После загрузки изображений начните обучение модели
python ./code/train-model.py
Шаг 8: Получение состояния модели
Обучение модели занимает около 30 минут. После обучения модели вы получите электронное письмо. А пока вы можете проверить состояние модели
watch -n 100 python ./code/model-state.py
Шаг 9: Сделайте прогноз
После обучения модели.Вы можете делать прогнозы, используя модель
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
7 причин, по которым Nanonets OCR API лучше, чем другие OCR API
Преимущества использования Nanonets по сравнению с другими OCR API выходят за рамки просто лучшей точности в отношении извлечения текста из изображений. Вот 7 причин, по которым вам следует подумать об использовании Nanonets OCR API для распознавания текста вместо других OCR API.
- Работа с пользовательскими данными. Большинство API-интерфейсов OCR довольно жестко относятся к типу данных, с которыми они могут работать.Обучение модели OCR для варианта использования требует большой степени гибкости в отношении требований и спецификаций; OCR для обработки счетов будет сильно отличаться от OCR для паспортов! Наносеть не скована такими жесткими ограничениями. Nanonets использует ваши собственные данные для обучения моделей OCR, которые лучше всего подходят для удовлетворения конкретных потребностей вашего бизнеса.
- Работа с неанглийскими или несколькими языками. Поскольку Nanonets фокусируется на обучении с использованием пользовательских данных, он имеет уникальные возможности для построения единой модели OCR, которая может извлекать текст из документов на любом языке или на нескольких языках одновременно.
- Практически не требует постобработки — текст, извлеченный с помощью моделей OCR, должен быть грамотно структурирован и представлен в понятном формате; в противном случае значительное время и ресурсы уходят на реорганизацию данных в значимую информацию. В то время как большинство API-интерфейсов OCR просто захватывают и выгружают данные из изображений и документов, Nanonets извлекает только релевантные данные и автоматически сортирует их по интеллектуально структурированным полям, упрощая просмотр и понимание.
- Непрерывное обучение — предприятия часто сталкиваются с динамично меняющимися требованиями и потребностями.Чтобы преодолеть потенциальные препятствия, Nanonets OCR API позволяет легко повторно обучать ваши модели с использованием новых данных. Это позволяет вашей модели OCR адаптироваться к непредвиденным изменениям.
- С легкостью справляется с общими ограничениями данных — Nanonets OCR API использует методы глубокого обучения и обнаружения объектов для преодоления общих ограничений данных, которые сильно влияют на распознавание и извлечение текста. Nanonets OCR может распознавать и обрабатывать рукописный текст, изображения текста на нескольких языках одновременно, изображения с низким разрешением, изображения с новыми или курсивными шрифтами и разных размеров, изображения с темным текстом, наклонный текст, случайный неструктурированный текст, шум изображения, размытые изображения и больше. Традиционные API-интерфейсы OCR просто не приспособлены для работы в таких условиях; им требуются данные с очень высоким уровнем достоверности, что не является нормой в реальных сценариях.
- Не требуется собственная команда разработчиков — не нужно беспокоиться о найме разработчиков и привлечении талантов для персонализации Nanonets API в соответствии с требованиями вашего бизнеса. Наносети были созданы для беспроблемной интеграции. Вы также можете легко интегрировать Nanonets с большинством программного обеспечения CRM, ERP или RPA.
- Настройка, настройка, настройка — вы можете захватить столько полей текста / данных, сколько захотите, с помощью Nanonets OCR.Вы даже можете создавать собственные правила проверки, которые работают с вашими конкретными требованиями к распознаванию и извлечению текста. Наносети вообще не связаны шаблоном вашего документа. Вы можете собирать данные в таблицах или позициях или в любом другом формате!
 В то время как большинство API-интерфейсов OCR просто захватывают и выгружают данные из изображений и документов, Nanonets извлекает только релевантные данные и автоматически сортирует их по интеллектуально структурированным полям, упрощая просмотр и понимание.
В то время как большинство API-интерфейсов OCR просто захватывают и выгружают данные из изображений и документов, Nanonets извлекает только релевантные данные и автоматически сортирует их по интеллектуально структурированным полям, упрощая просмотр и понимание. Традиционные API-интерфейсы OCR просто не приспособлены для работы в таких условиях; им требуются данные с очень высоким уровнем достоверности, что не является нормой в реальных сценариях.
Традиционные API-интерфейсы OCR просто не приспособлены для работы в таких условиях; им требуются данные с очень высоким уровнем достоверности, что не является нормой в реальных сценариях.И вот несколько историй успеха, в которых компании успешно использовали наносети для достижения намеченных целей:
- Nanonets OCR позволило компании из списка Fortune 500 в США создать решение для автоматизированной обработки счетов для 5+ языков с 95% точность, автоматизируя до 80% ручного ввода данных вместе с локальными развертываниями.
- Nanonets API также оснастил крупное кадровое агентство в Европе для обработки 10 различных типов документов — свидетельств об образовании, иммиграционных форм, выписок с банковских счетов, идентификационных карт и т. Д. С использованием различных шаблонов, чтобы помочь увеличить бизнес в 2 раза в год.

Занимается ли ваша компания распознаванием текста в цифровых документах, изображениях или PDF-файлах? Вы задавались вопросом, как точно извлекать текст из изображений? У Nanonets есть множество вариантов использования, которые могут оптимизировать производительность вашего бизнеса, сократить расходы и ускорить рост. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Или ознакомьтесь с API Nanonets OCR в действии и начните создавать собственные модели OCR бесплатно!
Дополнительная литература
Обновление # 1 :
Добавлены дополнительные материалы для чтения о различных подходах к извлечению текста из файлов PDF изображений
Обновление # 2 :
Добавлены дополнительные материалы для чтения о различных подходах к извлечению текста из файлов PDF изображений
Начните использовать нанонетки для автоматизации
Попробуйте модель или закажите демонстрацию сегодня!
ПОПРОБУЙ
Мобильный сканер PDF в App Store
Превратите свое устройство в мощный портативный сканер документов с функциями распознавания текста OCR с помощью бесплатного приложения Adobe Scan.
Используйте мобильный сканер документов Adobe Scan, чтобы превратить все — квитанции, заметки, документы, фотографии, визитки, доски — в файл Adobe PDF или JPEG с содержимым, которое можно повторно использовать из каждого сканированного PDF-файла или фотографии.
С помощью бесплатного мобильного сканера вы можете сканировать все, что угодно. Используйте быстрый PDF-сканер, чтобы создать фото или PDF-сканирование. Сканируйте и возвращайтесь к другим важным вещам.
ЗАПИСЫВАЙТЕ ДОКУМЕНТЫ, КНИГИ, НАЛОГОВЫЕ ЧЕНЫ И ДРУГОЕ
Сканируйте все с точностью с помощью этого мобильного приложения для сканирования PDF-файлов.Усовершенствованная технология обработки изображений автоматически определяет ваши документы на наличие границ, повышает резкость отсканированного содержимого и распознает текст (OCR).
УЛУЧШИТЬ СКАНИРОВАНИЕ С ПРИЛОЖЕНИЕМ ADOBE ДЛЯ СКАНИРОВАНИЯ И РЕДАКТИРОВАНИЯ
Подправьте отсканированные фотографии и документы из камеры. Будь то PDF-файл или фотография, вы можете предварительно просмотреть, изменить порядок, обрезать, повернуть и настроить цвет.
ПОВТОРНОЕ ИСПОЛЬЗОВАНИЕ СКАНИРОВАНИЙ С OCR
Превратите отсканированную фотографию в высококачественный документ Adobe PDF, который раскрывает содержимое с помощью автоматического распознавания текста (OCR).Вы можете повторно использовать контент после сканирования PDF-документов благодаря OCR. Используйте его как книжный сканер для быстрой оцифровки массовых страниц.
СКАНИРОВАТЬ ВСЕГДА, В ЛЮБОЕ ВРЕМЯ
Захватывайте формы, налоговые квитанции, заметки и визитные карточки с помощью этого мобильного сканера. Приложение Adobe Scan для сканирования можно использовать в качестве сканера библиотечной книги или сканера бизнес-квитанций и даже позволяет сканировать многостраничные документы и сохранять их одним касанием.
ПЕРЕРАБОТКА СОДЕРЖИМОГО
Сканер Adobe Scan to PDF позволяет сканировать и использовать любой контент.Бесплатное встроенное оптическое распознавание символов (OCR) позволяет повторно использовать отсканированный контент, создавая высококачественный PDF-файл, с которым можно работать в бесплатном приложении Adobe Acrobat Reader. Вы даже можете превратить Adobe Scan в сканер налоговых квитанций, чтобы с легкостью выделять расходы.
Вы даже можете превратить Adobe Scan в сканер налоговых квитанций, чтобы с легкостью выделять расходы.
ОЧИСТКА ОТКАЗОВ
Удалите и отредактируйте недостатки, сотрите пятна, отметки, складки и даже почерк.
БЫСТРО НАЙТИ ДОКУМЕНТЫ В ФОТОБИБЛИОТЕКЕ
Это мощное приложение для сканирования автоматически находит документы и квитанции на ваших фотографиях и превращает их в отсканированные PDF-файлы, так что вам не придется.Автоматическое распознавание текста превращает текст в контент, который вы можете редактировать, изменять размер и использовать в других документах. У вас много расходов? Сканер бизнес-чеков поможет сопоставить все ваши расходы.
СОХРАНИТЕ ВИЗИТКИ В КОНТАКТЫ
Сканирование визитных карточек превращает Adobe Scan в быстрый сканер и считыватель визиток. Контактная информация будет автоматически извлечена при использовании сканера визитных карточек, поэтому вы можете быстро добавить в свои контакты.
ПОЛУЧАЙТЕ БОЛЬШЕ НА ПЕРЕДАЧЕ
Сохраняйте каждое сканированное изображение PDF в Adobe Document Cloud для мгновенного доступа и совместного использования. Даже длинные юридические документы можно обрабатывать и сканировать с помощью приложения сканирования Adobe Scan, которое позволяет искать, выбирать и копировать текст. Вы также можете открыть отсканированный PDF-файл в Acrobat Reader, чтобы выделить ключевые разделы и добавить комментарии к документам.
Даже длинные юридические документы можно обрабатывать и сканировать с помощью приложения сканирования Adobe Scan, которое позволяет искать, выбирать и копировать текст. Вы также можете открыть отсканированный PDF-файл в Acrobat Reader, чтобы выделить ключевые разделы и добавить комментарии к документам.
ПОДКЛЮЧИТЬСЯ
Adobe Scan соединяет вас с лучшими в мире службами документов, которые позволяют делать еще больше с вашими PDF-файлами. Редактируйте PDF-файлы и отсканированные фотографии, конвертируйте в Microsoft Office, заполняйте и подписывайте и отправляйте на отслеживаемые подписи.
ИНФОРМАЦИЯ О ПОКУПКЕ В ПРИЛОЖЕНИИ
Если вы хотите получить больше от сканированных изображений, вы можете приобрести подписку на пакет PDF за 9 долларов США.99 / месяц (включая экспорт в PDF).
• Оплата будет снята с вашей учетной записи iTunes после подтверждения покупки.
• Подписки автоматически продлеваются, если автоматическое продление не отключено по крайней мере за 24 часа до окончания текущего периода. Вы можете управлять автоматическим продлением или отключить его в настройках учетной записи Apple ID в любое время после покупки.
Вы можете управлять автоматическим продлением или отключить его в настройках учетной записи Apple ID в любое время после покупки.
Условия и положения: использование вами этого приложения регулируется Общими условиями использования Adobe (https://adobe.com/go/terms_linkfree_en) и Политикой конфиденциальности Adobe (http: // www.adobe.com/go/privacy_policy_linkfree_en).
Не продавать мою личную информацию: https://www.adobe.com/privacy/ca-rights-linkfree.html
OCR PDF-файлов, отсканированных изображений и т. Д. И сохранение распознанного текста как PDF с возможностью поиска или текста с помощью программы DocuFreezer OCR Converter
Почему у меня такое плохое распознавание текста? 7 шагов для повышения точности распознавания
Текст может быть неправильным или поврежденным после преобразования с помощью OCR. Краткий совет — убедитесь, что входные файлы имеют высокое качество — большой формат и высокое разрешение.Понимание ограничений процесса оптического распознавания символов может помочь вам помочь механизму оптического распознавания текста получать более точные результаты. Результаты распознавания считаются хорошими, если распознанный текст имеет точность 98-99% (неверно 1-2% распознавания).
Краткий совет — убедитесь, что входные файлы имеют высокое качество — большой формат и высокое разрешение.Понимание ограничений процесса оптического распознавания символов может помочь вам помочь механизму оптического распознавания текста получать более точные результаты. Результаты распознавания считаются хорошими, если распознанный текст имеет точность 98-99% (неверно 1-2% распознавания).
Ниже приведены несколько советов, которые помогут вам добиться лучших результатов распознавания текста.
# 1 Улучшение качества исходных изображений
Одним из наиболее важных факторов является DPI (количество точек на дюйм). Сканируйте документы с разрешением 300 или выше точек на дюйм. Желательно сканировать с разрешением 600 точек на дюйм, чтобы захватить как можно больше информации об изображении.При высоком разрешении изображения движок OCR должен уметь распознавать высокие контрасты, границы символов, пиксельный шум и выровненные символы.
# 2 Выберите выходной формат без потерь при сканировании
Чтобы программа OCR могла более точно извлекать текст, выберите формат файла без потерь, например TIFF. При сканировании в TIFF без сжатия никакая информация об изображении (грубо говоря, пиксели) не будет потеряна. Поэтому при сканировании исходного файла выбирайте формат файла без потерь, например TIFF или высококачественный PDF.
При сканировании в TIFF без сжатия никакая информация об изображении (грубо говоря, пиксели) не будет потеряна. Поэтому при сканировании исходного файла выбирайте формат файла без потерь, например TIFF или высококачественный PDF.
# 3 Повышение контрастности изображений
Контрастность и плотность — жизненно важные факторы, которые следует учитывать перед распознаванием текста. При использовании сканера (или редактора изображений, если нет возможности отсканировать документ еще раз), вы можете настроить гамму и контраст, чтобы получить более четкие результаты. Настройте высокий контраст так, чтобы символы были различимы.
# 4 Увеличить размер текста исходных изображений
Рекомендуемый размер текста в отсканированных документах — 10 пунктов или больше.Для достижения наилучших результатов постарайтесь, чтобы высота текста была не менее 20 пикселей.
Существует минимальный размер текста для разумной точности. Учитывайте разрешение, а также размер точки — точность распознавания падает ниже 10 пунктов, быстро ниже 8 пунктов (с разрешением 300 точек на дюйм). При 10pt и 300 DPI высота по оси x обычно составляет около 20 пикселей. Если высота x меньше 10 пикселей, у вас очень мало шансов на получение точных результатов, а буквы ниже 8 пикселей будут «удалены».
При 10pt и 300 DPI высота по оси x обычно составляет около 20 пикселей. Если высота x меньше 10 пикселей, у вас очень мало шансов на получение точных результатов, а буквы ниже 8 пикселей будут «удалены».
Быстрая проверка — подсчитать пиксели x-высоты ваших символов (x-height — высота нижнего регистра).Вы можете сделать это с помощью инструмента для сохранения снимков экрана (например, Lightshot) или редактора изображений, такого как Photoshop.
# 5 Выбирайте только те языки, которые содержатся в ваших документах
Если в используемом вами программном обеспечении OCR есть возможность выбирать между языками (например, DocuFreezer), выбирайте только те, которые есть в исходных документах. Чем меньше языков выбрано — тем лучше. Это поможет избежать неправильного толкования персонажей.
# 6 Избегайте поворота или перекоса текста и делайте строки текста горизонтальными
Когда страница была отсканирована не прямо, текст может быть повернут.Если текст страницы слишком перекошен или повернут, это серьезно влияет на качество распознавания текста. Чтобы решить эту проблему, попробуйте снова отсканировать документ, чтобы линии слов были горизонтальными. Или слегка поверните цифровое изображение с помощью редактора изображений.
Чтобы решить эту проблему, попробуйте снова отсканировать документ, чтобы линии слов были горизонтальными. Или слегка поверните цифровое изображение с помощью редактора изображений.
# 7 Убрать темные границы и другие объекты рядом с персонажами
Отсканированные страницы могут иметь темные края вокруг себя. Их можно обрабатывать как дополнительные символы, особенно если они различаются по форме и градации. Если слишком много шума или объектов, вы можете улучшить изображение с помощью GIMP.Увеличить изображение в 2,5 раза; затем выделите фон возле букв с помощью инструмента Magic Wand и удалите его; повысить резкость изображения с помощью фильтра «Нерезкость меток».
Часто невозможно выполнить все эти условия, и может потребоваться вычитка. Вы можете использовать средство проверки грамматики / орфографии, например Grammarly. Всегда проверяйте и исправляйте любые ошибки, прежде чем публиковать текст, созданный с помощью OCR.
распознаватель NPen ++. Int J Doc Anal Recognit 3: 169-180
S. Jaeger et al .: Распознавание рукописного ввода в Интернете: распознаватель NPen ++ 179
Jaeger et al .: Распознавание рукописного ввода в Интернете: распознаватель NPen ++ 179
точки, сглаживание, нормализация наклона, вычисление equidis-
точек танта (повторная выборка) и удаление с задержкой удары.
Набор функций, вычисленных в NPen ++, объединяет
как локальную, так и глобальную информацию о траектории
пера. В то время как локальные объекты описывают форму траектории
в определенный момент времени, глобальные объекты имеют дело
с пространственной информацией, охватывающей более широкий временной контекст.
NPen ++ считает важными оба типа информации.
Следующие локальные и глобальные характеристики вычисляются в
NPen ++: вертикальное положение, направление письма, кривизна,
перо вверх / вниз, «шляпа» -функция, аспект, извилистость, lin-
ухо, наклон , восходящие / нисходящие и контекстные карты.
Контекстные карты — это новый подход, сочетающий глобальные функциональные возможности
офлайн с локальной онлайн-информацией. Они про
Они про
отображают дополнительную пространственную информацию о частях траектории
, которые могут иметь большое временное расстояние до каждой
другой. Контекстные карты увеличивают общий уровень распознавания
примерно на 1%. Однако одним из недостатков контекстных карт
является то, что они увеличивают размер векторов признаков более чем на
, чем на 50%, что, в свою очередь, увеличивает сложность нейронной сети
.Тем не менее, мы считаем, что контекстные карты
являются важным подходом для включения онлайн-
, а также офлайн-распознавания, которое выходит за рамки комбинации
двух отдельных онлайн и офлайн распознавателей.
NPen ++ использует эффективный поиск по дереву и метод отсечения
, чтобы обеспечить производительность в реальном времени для словарей очень большого размера
. Показатели распознавания, указанные в этой статье
, варьируются от 96% для словаря на 5000 слов до
91. 2% за словарь на 50 000 слов. Следовательно, можно сказать, что
2% за словарь на 50 000 слов. Следовательно, можно сказать, что
является успешным примером передачи
MS-TDNN из области
распознавания речи в задачу распознавания рукописного ввода. Кроме того, MS-
TDNN представляет собой мощную архитектуру, которая позволяет обучать
и распознавать всю иерархию рукописных данных
, начиная от отдельных символов и заканчивая целыми предложениями.
Мы предполагаем, что перенос основных методов
NPen ++ на другие языки, такие как русский, греческий,
или арабский, требует лишь незначительных изменений в системе
NPen ++.Для азиатских языков, однако, потребуется несколько серьезных изменений
из-за разной структуры
этих языков. Например, базовые показатели
, вычисленные NPen ++, не будут работать для таких языков, как
, таких как китайский или японский. Поскольку азиатский иероглиф с точки зрения сложности напоминает латинское слово
, оптимальное число состояний
, представляющих символ, будет, по-видимому, отличаться от числа состояний в западных письменах
. В практических экспериментах мы достигли оптимальной производительности
В практических экспериментах мы достигли оптимальной производительности
полностью обученной системы NPen ++
, когда использовали три состояния. Тем не менее, мы обнаружили, что ob-
обслужил некоторые небольшие улучшения с четырьмя или даже пятью состояниями
для некоторых меньших подмножеств наших трех баз данных.
Возможное улучшение, которое мы не использовали
в NPen ++, — это контекстно-зависимые состояния, которые уже
готовы к использованию при распознавании речи [12]. Представление различных стилей письма, таких как печатные и курсивные стили,
с использованием отдельных моделей также может быть потенциальным улучшением NPen ++, которое заслуживает дальнейшего исследования.
В принципе, базовая архитектура NPen ++ позволяет
распознавать следы, то есть распознавать части траектории во время записи. Тем не менее, для распознавания бега может потребоваться модификация
на некоторых этапах предварительной обработки.
В частности, базовые линии, вычисленные в начале
траектории, будут ненадежными из-за недостаточного
числа локальных максимумов или минимумов.
Представленная система NPen ++ может быть легко расширена, чтобы обеспечить распознавание полных предложений.Для этого мы встроили поиск по дереву в цикл обратной связи
, объединяющий выходные данные древовидной структуры с
корневыми узлами через дополнительное состояние, представляющее пробелы между
промежуточными словами. Наши первые эксперименты с распознаванием предложений были очень обнадеживающими. Тем не менее, эти
экспериментов все еще находятся на начальной стадии, и
нуждаются в улучшении. Что наиболее важно, следующим важным шагом должно стать исследование более сложных языковых моделей, таких как tri-
граммов.
Список литературы
1. С. Абрамовски, Х. Мюллер: Geometrisches Modellieren
(на немецком языке), т. 75 из Reihe Informatik. BI, Mannheim
BI, Mannheim
Wien Z¨urich, 1991
2. Y. Bengio, Y.L. Кун .: Нормализация слов для онлайн-распознавания рукописных слов
. В: Proc. Int. Конф. на
Распознавание образов, стр. 409–413, 1994
3. Г. Боччиньоне, А. Кьянезе, Л.П. Корделла, А. Марчелли:
Восстановление динамической информации из статического почерка —
ing.Pattern Recognition, 26 (3): 409–418, 1993
4. Т. Цезарь, Дж. М. Глогер, Э. Мандлер: Предварительная обработка и
извлечение признаков
для системы распознавания рукописного ввода —
tem. В: 2nd IAPR Int. Конф. по анализу документов и распознаванию
, стр. 408–411, Цукуба, Япония, 1993
5. Демпстер А.П., Лэрд Н.М., Д.Б. Рубин .: Максимум
Вероятность неполных данных с помощью алгоритма EM.
J. R. Stat. Soc., 39: 1–38, 1977
6. D.С. Doermann, A. Rosenfeld: Восстановление временной
информации из статических изображений почерка. Int. J.
Comput. Видение, 15: 143–164, 1995
Видение, 15: 143–164, 1995
7. J.G.A. Долфинг, Р. Хаб-Умбах: Представление сигналов —
для скрытой марковской модели, основанной на интерактивной руке —
Распознавание письма. В: Proc. IEEE Int. Конф. on Acous-
tics, Speech and Signal Processing, Мюнхен, 1997
8. I. Guyon, P. Albrecht, Y. Le Cun, J. Denker, W. Hub-
bard.: Дизайн распознавателя символов нейронной сети
для сенсорного терминала. Распознавание образов, 24 (2): 105–
119, 1991
9. Хилд Хилд .: Buchstabiererkennung mit neuroonalen Netzen
в Auskunftssystemen (на немецком языке). Кандидатская диссертация, Университет
, город Карлсруэ, 1997. Шейкер, Германия
10. Х. Хильд, А. Вайбель: Независимое подключение к докладчику
Распознавание букв с многоуровневой временной задержкой Neu-
ral Network . В: 3-я Европейская конф.по речи, связь и технологии
(EUROSPEECH), т. 2, стр.
1481–1484, Берлин, 1993
11. С. Йегер: Восстановление динамической информации из статических,
С. Йегер: Восстановление динамической информации из статических,
Рукописные изображения в виде слов. Кандидатская диссертация, Университет
Фрайбург, 1998. Фёльбах, Германия
12. А. Космала, Дж. Роттланд, Г. Риголл: Исследование
использования триграфов в курсиве большого словарного запаса
Распознавание почерка. В: Proc. IEEE Int. Конф.на
Акустика, речь и обработка сигналов, Мюнхен, 1997
13. P.M. Лалликан, К. Виард-Годен: Подход Калмана
для восстановления порядка инсульта по офлайн-почерку.
В: 4-й внутр. Конф. по анализу и распознаванию документов
(ICDAR), стр. 519–522, 1997 г.
5 Проверенные и проверенные бесплатные онлайн-сервисы OCR
У вас есть документ PDF или изображение, которое вы хотели бы преобразовать в текст? Недавно кто-то прислал мне по почте документ, который мне нужно было отредактировать и отправить обратно с исправлениями.Человек не смог найти цифровую копию, поэтому мне было поручено перевести весь этот текст в цифровой формат.
Я ни за что не собирался часами набирать все обратно, поэтому в итоге я сделал красивую высококачественную фотографию документа, а затем пробрался через кучу онлайн-сервисов OCR, чтобы посмотреть, какая из них даст мне лучшие результаты.
В этой статье я рассмотрю несколько моих любимых бесплатных сайтов для распознавания текста. Стоит отметить, что большинство этих сайтов предоставляют базовую бесплатную услугу, а затем имеют платные опции, если вам нужны дополнительные функции, такие как большие изображения, многостраничные документы PDF, разные языки ввода и т. Д.
Также хорошо знать заранее, что большинство этих служб не смогут соответствовать форматированию вашего исходного документа. В основном они предназначены для извлечения текста, и все. Если вам нужно, чтобы все было в определенном макете или формате, вам придется сделать это вручную, как только вы получите весь текст из OCR.
Кроме того, наилучшие результаты для получения текста будут получены из документов с разрешением от 200 до 400 точек на дюйм. Если у вас изображение с низким разрешением, результаты будут не такими хорошими.
Если у вас изображение с низким разрешением, результаты будут не такими хорошими.
Наконец, я тестировал множество сайтов, которые просто не работали. Если вы используете бесплатное онлайн-распознавание текста в Google, вы увидите несколько сайтов, но некоторые из сайтов в первой десятке результатов даже не завершили преобразование. У некоторых истекал тайм-аут, другие выдавали ошибки, а некоторые просто застревали на странице «конвертация», поэтому я даже не стал упоминать эти сайты.
Для каждого сайта я протестировал два документа, чтобы увидеть, насколько хорош будет результат. Для своих тестов я просто использовал свой iPhone 5S, чтобы сфотографировать оба документа, а затем загрузил их прямо на веб-сайты для преобразования.
Если вы хотите увидеть, как выглядели изображения, которые я использовал для своего теста, я прикрепил их сюда: Test1 и Test2. Обратите внимание, что это не версии изображений с полным разрешением, снятые с телефона. При загрузке на сайты я использовал изображение в полном разрешении.
ОнлайнOCR
OnlineOCR.net — чистый и простой сайт, который показал очень хорошие результаты в моем тесте. Главное, что мне нравится в нем, так это то, что на нем нет большого количества рекламы, как это обычно бывает с такими нишевыми сайтами с услугами.
Для начала выберите свой файл и дождитесь завершения загрузки. Максимальный размер загрузки для этого сайта составляет 100 МБ. Если вы зарегистрируете бесплатную учетную запись, вы получите несколько дополнительных функций, таких как больший размер загрузки, многостраничные PDF-файлы, разные языки ввода, больше конверсий в час и т. Д.
Затем выберите язык ввода и формат вывода. Вы можете выбрать Word, Excel или обычный текст. Нажмите кнопку Convert , и вы увидите текст, отображаемый внизу в поле вместе со ссылкой для скачивания.
Если вам нужен только текст, просто скопируйте и вставьте его из поля. Однако я предлагаю вам загрузить документ Word, потому что он на удивление отлично справляется с сохранением макета исходного документа.
Например, когда я открыл документ Word для своего второго теста, я был удивлен, обнаружив, что в документе есть таблица с тремя столбцами, как на изображении.
Из всех сайтов этот был безусловно лучшим. Если вам нужно много конверсий, то стоит зарегистрироваться.
Для полноты картины я также собираюсь добавить ссылку на файлы вывода, созданные каждой службой, чтобы вы могли сами увидеть результаты. Вот результаты OnlineOCR: Test1 Doc и Test2 Doc.
Обратите внимание, что при открытии этих документов Word на компьютере вы получите сообщение в Word о том, что они получены из Интернета и редактирование отключено. Это нормально, потому что Word не доверяет документам из Интернета, и вам действительно не нужно разрешать редактирование, если вы просто хотите просмотреть документ.
i2OCR
Еще одним сайтом, который дал неплохие результаты, был i2OCR. Процесс очень похож: выберите язык, файл и нажмите Извлечь текст .
Вам придется подождать здесь минуту или две, потому что этот сайт занимает немного больше времени. Кроме того, на шаге 2 убедитесь, что ваше изображение отображается при предварительном просмотре правой стороной вверх, иначе на выходе вы получите кучу тарабарщины. По какой-то причине изображения с моего iPhone отображались на моем компьютере в портретном режиме, но в альбомном, когда я загружал их на этот сайт.
Мне пришлось вручную открыть изображение в приложении для редактирования фотографий, повернуть его на 90 градусов, затем повернуть обратно в портретное положение и затем снова сохранить. После завершения прокрутите вниз, и вы увидите предварительный просмотр текста вместе с кнопкой загрузки.
Этот сайт показал хорошие результаты при первом тестировании, но не очень хорошо показал себя во втором тесте, в котором использовалась структура столбцов. Вот результаты i2OCR: Test1 Doc и Test2 Doc.
БесплатноOCR
Free-OCR. com возьмет ваши изображения и преобразует их в простой текст. У него нет возможности экспортировать в формат Word. Выберите файл, выберите язык и нажмите Start .
com возьмет ваши изображения и преобразует их в простой текст. У него нет возможности экспортировать в формат Word. Выберите файл, выберите язык и нажмите Start .
Сайт работает быстро, и вы получите результат довольно быстро. Просто щелкните ссылку, чтобы загрузить текстовый файл на свой компьютер.
Как и в случае с NewOCR, упомянутым ниже, на этом сайте все буквы T в документе используются с заглавной буквы. Я понятия не имею, почему он это сделал, но по какой-то странной причине этот сайт и NewOCR сделали это.Изменить это несложно, но это утомительный процесс, который вам не нужно делать.
Вот результаты FreeOCR: Test1 Doc и Test2 Doc.
ABBYY FineReader Online
Чтобы использовать FineReader Online, вам необходимо зарегистрировать учетную запись, которая дает вам 15-дневную бесплатную пробную версию для OCR до 10 страниц бесплатно. Если вам нужно сделать только одноразовое распознавание текста для пары страниц, вы можете воспользоваться этой услугой. Убедитесь, что вы щелкнули ссылку подтверждения в электронном письме с подтверждением после регистрации.
Убедитесь, что вы щелкнули ссылку подтверждения в электронном письме с подтверждением после регистрации.
Щелкните Распознать вверху, а затем щелкните Загрузить , чтобы выбрать файл. Выберите свой язык, формат вывода и затем нажмите Распознать внизу. У этого сайта чистый интерфейс и без рекламы.
В моих тестах этот сайт смог захватить текст из первого тестового документа, но когда я открыл документ Word, он был абсолютно огромен, поэтому в итоге я сделал это снова и выбрал простой текст в качестве выходного формата.
Для второго теста со столбцами документ Word был пуст, и я даже не смог найти текст.Не уверен, что там произошло, но похоже, что он не может обрабатывать ничего, кроме простых абзацев. Вот результаты FineReader: Test1 Doc и Test2 Doc.
новыхOCR
Следующий сайт, NewOCR.com, был в порядке, но не так хорош, как первый сайт. Во-первых, это реклама, но, к счастью, не тонна. Сначала вы выбираете файл, а затем нажимаете кнопку Preview .
Сначала вы выбираете файл, а затем нажимаете кнопку Preview .
Затем вы можете повернуть изображение и настроить область, в которой вы хотите сканировать текст.Это очень похоже на то, как процесс сканирования работает на компьютере с подключенным сканером.
Если в документе несколько столбцов, вы можете нажать кнопку Анализ макета страницы , и он попытается разбить текст на столбцы. Нажмите кнопку OCR, подождите несколько секунд, пока оно завершится, а затем прокрутите вниз, когда страница обновится.
В первом тесте весь текст получился правильно, но по какой-то причине каждая буква T в документе была заглавной! Понятия не имею, зачем он это сделал, но это произошло.Во втором тесте с включенным анализом страницы он получил большую часть текста, но макет был полностью отключен.
Вот результаты NewOCR: Test1 Doc и Test2 Doc.
Заключение
Как видите, бесплатное использование, к сожалению, не всегда дает хорошие результаты. Первый упомянутый сайт на сегодняшний день является лучшим, потому что он не только отлично распознал весь текст, но и сумел сохранить формат исходного документа.
Первый упомянутый сайт на сегодняшний день является лучшим, потому что он не только отлично распознал весь текст, но и сумел сохранить формат исходного документа.
Если вам нужен просто текст, то большинство вышеперечисленных веб-сайтов смогут сделать это за вас.Если у вас есть вопросы, не стесняйтесь комментировать. Наслаждаться!
PDF-страниц OCR с возможностью поиска — SimpleIndex
Разработка решения для управления документами
Если вы еще не определились с планом организации отсканированных изображений для последующего поиска, вам следует уделить некоторое время рассмотрению возможных вариантов. Существует несколько способов поиска и просмотра документов, отсканированных с помощью SimpleIndex ® :
- Используйте SimpleSearch , чтобы использовать поиск по ключевым словам для поиска и просмотра проиндексированных документов.
- Используйте SimpleView для просмотра папок, поиска файлов, просмотра, редактировать и комментировать отсканированные документы без базы данных
- Используйте стороннюю систему управления документами для интегрированного поиска, просмотра, рабочего процесса, соответствия HIPAA и других функций, ориентированных на документы
- Используйте SharePoint для совместного использования документов в Интернете, создания пользовательских рабочих процессов документов и использования записей стандарты управления
- Используйте панель поиска Windows для поиска имен и содержимого файлов, хранящихся в Windows Server 2008 или более поздней версии.
- Интегрируйте SimpleIndex напрямую с вашим индивидуальным приложением с помощью интерфейса командной строки
- Работайте с нашей командой профессиональных услуг или авторизованным дилером, чтобы создать индивидуальное решение или прямую интеграцию практически с любым приложением
- Используйте настраиваемую базу данных или электронную таблицу, например MS Access, SQL Server или Excel для хранения данных индекса и предоставления ссылок на сохраненные изображения документов

Использование
SimpleSearch
SimpleSearch включен во все версии SimpleIndex и также может быть лицензирован сам по себе . SimpleSearch реализует тот же интерфейс SimpleIndex в режиме «Извлечение», скрывая все меню и панели инструментов, используемые для сканирования. Вместо этого для поиска используются поля индекса, обычно используемые для присвоения значений.
SimpleSearch может использовать встроенную базу данных SimpleIndex для выполнения поиска или подключения к любой другой базе данных, даже для существующих бизнес-приложений. Пользователи просто вводят значения индекса, которые они хотят найти, и SimpleIndex отображает совпадения.Также поддерживаются частичное соответствие и полнотекстовый поиск. Отображаемые документы можно распечатать, отправить по электронной почте или открыть в соответствующем приложении (Word, Adobe Reader, Excel и т. Д.). SimpleSearch может просматривать несколько распространенных форматов изображений, файлы PDF и может просматривать файлы для любого приложения с поддержкой OLE, установленного на вашем компьютере (MS Office, приложения Adobe, AutoCad и т. Д.)
Использование системы управления документами
Есть широкий спектр систем управления документами малого и среднего бизнеса, доступных сегодня на рынке.Они управляют сохраненными изображениями и индексными данными, а также предоставляют пользователям интерфейс для поиска и просмотра этих изображений. Многие из них выполняют расширенные функции, такие как управление рабочим процессом, отслеживание версий и аудит доступа на соответствие требованиям HIPAA. SimpleIndex может взаимодействовать с этими системами, что делает его идеальным интерфейсом для сканирования для использования с большинством систем управления документами на рынке.
Многие из них выполняют расширенные функции, такие как управление рабочим процессом, отслеживание версий и аудит доступа на соответствие требованиям HIPAA. SimpleIndex может взаимодействовать с этими системами, что делает его идеальным интерфейсом для сканирования для использования с большинством систем управления документами на рынке.
Интеграция с программным обеспечением для управления документами осуществляется через файлы журнала индексации, которые создает SimpleIndex .Документы сканируются и индексируются с помощью SimpleIndex , и создается файл журнала, в котором перечисляются каждое сканированное изображение и связанная с ним индексная информация. Практически все системы управления документами поставляются со стандартными или дополнительными компонентами, которые позволяют автоматически импортировать изображения и индексировать информацию в формате, который предоставляет SimpleIndex .
Многие системы управления документами имеют модуль сканирования, который продается отдельно по значительно большей цене, чем SimpleIndex . С одним сканером SimpleIndex может обеспечить более простой и экономичный интерфейс сканирования, чем модуль по умолчанию. При использовании нескольких сканеров невысокая стоимость SimpleIndex позволяет реализовать распределенный захват документов за небольшую часть стоимости, которую он стоил бы в противном случае.
С одним сканером SimpleIndex может обеспечить более простой и экономичный интерфейс сканирования, чем модуль по умолчанию. При использовании нескольких сканеров невысокая стоимость SimpleIndex позволяет реализовать распределенный захват документов за небольшую часть стоимости, которую он стоил бы в противном случае.
Использование панели поиска Windows
В Windows Server 2008 или более поздней версии вы можете включить службу поиска Windows и параметры индексации, которые поставляются с ней, чтобы быстро находить файлы с помощью поиска в верхнем углу окна проводника.Как только Windows Search настроен на сервере, на вашем локальном компьютере просто выберите любой общий диск или папку, в которой вы хотите быстро найти, и добавьте их в библиотеку. Когда вы вводите слово или фразу в строке поиска, Windows будет искать не только по всем именам файлов, но и по их содержимому. Более подробную информацию о настройке возможности поиска в Windows Server можно найти здесь.
Добавить комментарий