
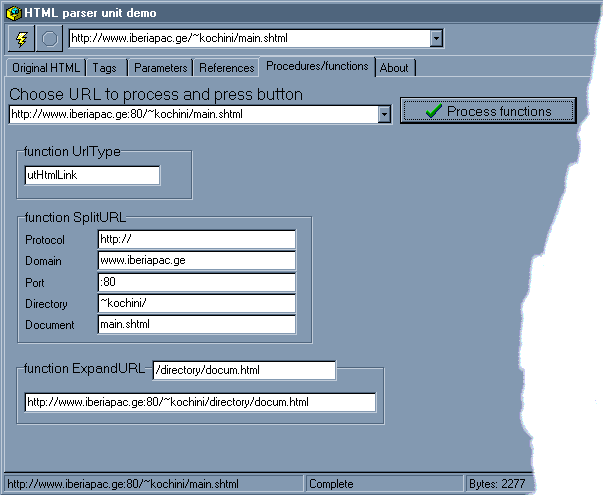
Как вы анализируете и обрабатываете HTML / XML в PHP?
Собственные XML-расширения
Я предпочитаю использовать одно из собственных расширений XML, поскольку они поставляются в комплекте с PHP, обычно работают быстрее всех сторонних библиотек и дают мне полный контроль над разметкой.
DOM
Расширение DOM позволяет вам работать с документами XML через API DOM с PHP 5. Это реализация объектной модели документов W3C Core Level 3, независимого от платформы и языка интерфейса, который позволяет программам и сценариям динамически получать доступ и обновлять содержание, структура и стиль документов.
DOM способен анализировать и изменять (неработающий) HTML реального мира и выполнять запросы XPath . Он основан на libxml .
Требуется некоторое время, чтобы стать продуктивным с DOM, но это время того стоит IMO. Поскольку DOM является независимым от языка интерфейсом, вы найдете реализации на многих языках, поэтому, если вам нужно изменить язык программирования, скорее всего, вы уже знаете, как использовать API DOM этого языка.
Базовый пример использования можно найти в Grabbing атрибут href элемента A, а общий концептуальный обзор можно найти в DOMDocument на php
Как использовать расширение DOM широко освещалось в StackOverflow , поэтому, если вы решите его использовать, вы можете быть уверены, что большинство проблем, с которыми вы столкнулись, могут быть решены с помощью поиска / просмотра Переполнения стека.
XMLReader
Расширение XMLReader — это синтаксический анализатор XML. Читатель действует как курсор, идущий вперед по потоку документов и останавливающийся на каждом узле в пути.
XMLReader, как и DOM, основан на libxml. Я не знаю, как вызвать модуль HTML Parser, так что скорее всего, использование XMLReader для анализа неработающего HTML может быть менее надежным, чем использование DOM, где вы можете явно указать ему использовать модуль синтаксического анализа HTML libxml.
Базовый пример использования можно найти при получении всех значений из тегов h2 с использованием php
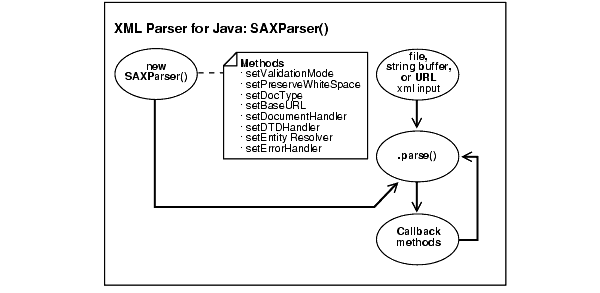
XML Parser
Это расширение позволяет создавать анализаторы XML, а затем определять обработчики для различных событий XML. Каждый анализатор XML также имеет несколько параметров, которые вы можете настроить.
Библиотека XML Parser также основана на libxml и реализует push-анализатор XML в стиле SAX . Это может быть лучшим выбором для управления памятью, чем DOM или SimpleXML, но с ним будет сложнее работать, чем парсером, реализованным XMLReader.
SimpleXml
Расширение SimpleXML предоставляет очень простой и легко используемый набор инструментов для преобразования XML в объект, который может обрабатываться с помощью обычных селекторов свойств и итераторов массива.
SimpleXML — это вариант, когда вы знаете, что HTML является верным XHTML. Если вам нужно разобрать битый HTML, даже не рассматривайте SimpleXml, потому что он захлебнется.
Базовый пример использования можно найти в разделе Простая программа для узла CRUD и значения узла файла XML, а в руководстве по PHP есть множество дополнительных примеров .
Сторонние библиотеки (на основе libxml)
Если вы предпочитаете использовать стороннюю библиотеку, я бы предложил использовать библиотеку, которая на самом деле использует DOM / libxml, а не разбор строки.
FluentDom — Репо
FluentDOM предоставляет jQuery-подобный свободный XML-интерфейс для DOMDocument в PHP. Селекторы пишутся в XPath или CSS (используя конвертер CSS в XPath). Текущие версии расширяют DOM, реализуя стандартные интерфейсы, и добавляют функции из DOM Living Standard. FluentDOM может загружать форматы, такие как JSON, CSV, JsonML, RabbitFish и другие. Может быть установлен через Composer.
HtmlPageDom
Wa72 \ HtmlPageDom` — это библиотека PHP для простого манипулирования HTML-документами.
Для обхода дерева DOM требуется DomCrawler из компонентов Symfony2 и расширяет его, добавляя методы для манипулирования деревом DOM HTML-документов.
 Для обхода дерева DOM требуется DomCrawler из компонентов Symfony2 и расширяет его, добавляя методы для манипулирования деревом DOM HTML-документов.
Для обхода дерева DOM требуется DomCrawler из компонентов Symfony2 и расширяет его, добавляя методы для манипулирования деревом DOM HTML-документов.phpQuery (не обновляется годами)
phpQuery — это цепочечный API-интерфейс на основе объектной модели документов (DOM), управляемый селектором на стороне сервера, основанный на jQuery JavaScript Library, написанный на PHP5, и обеспечивающий дополнительный интерфейс командной строки (CLI).
Также смотрите: https://github.com/electrolinux/phpquery
Zend_Dom
Zend_Dom предоставляет инструменты для работы с документами и структурами DOM. В настоящее время мы предлагаем Zend_Dom_Query, который предоставляет унифицированный интерфейс для запросов к документам DOM с использованием селекторов XPath и CSS.
QueryPath
QueryPath — это библиотека PHP для управления XML и HTML. Он предназначен для работы не только с локальными файлами, но и с веб-службами и ресурсами базы данных. Он реализует большую часть интерфейса jQuery (включая селекторы в стиле CSS), но он сильно настроен для использования на стороне сервера. Может быть установлен через Composer.
fDOMDocument
fDOMDocument расширяет стандартную модель DOM для использования во всех случаях ошибок вместо предупреждений или уведомлений PHP. Они также добавляют различные пользовательские методы и ярлыки для удобства и упрощения использования DOM.
сабля / XML
Sabre / xml — это библиотека, которая упаковывает и расширяет классы XMLReader и XMLWriter для создания простой системы отображения «xml to object / array» и шаблона проектирования. Написание и чтение XML является однопроходным, поэтому может быть быстрым и требовать мало памяти для больших XML-файлов.
FluidXML
FluidXML — это PHP-библиотека для управления XML с помощью лаконичного и свободного API.
 Он использует XPath и гибкий шаблон программирования, чтобы быть веселым и эффективным.
Он использует XPath и гибкий шаблон программирования, чтобы быть веселым и эффективным.Сторонний (не на основе libxml)
Преимущество использования DOM / libxml состоит в том, что вы получаете хорошую производительность из коробки, потому что вы основаны на собственном расширении. Однако не все сторонние библиотеки идут по этому пути. Некоторые из них перечислены ниже
PHP Простой HTML DOM Parser
- Анализатор HTML DOM, написанный на PHP5 +, позволяет очень просто управлять HTML!
- Требуется PHP 5+.
- Поддерживает неверный HTML.
- Найти теги на странице HTML с селекторами, как jQuery.
- Извлечение содержимого из HTML в одну строку.
Я вообще не рекомендую этот парсер. Кодовая база ужасна, а сам парсер довольно медленный и требует много памяти. Не все селекторы jQuery (такие как дочерние селекторы ) возможны. Любая из библиотек на основе libxml должна легко превзойти это.
PHP Html Parser
PHPHtmlParser — это простой, гибкий анализатор HTML, который позволяет вам выбирать теги с помощью любого селектора CSS, например, jQuery. Цель состоит в том, чтобы помочь в разработке инструментов, которые требуют быстрого и простого способа просмотреть html, независимо от того, действителен он или нет! Этот проект изначально поддерживался sunra / php-simple-html-dom-parser, но поддержка, похоже, прекратилась, так что этот проект — моя адаптация его предыдущей работы.
Опять же, я бы не рекомендовал этот парсер. Это довольно медленно с высокой загрузкой процессора. Также нет функции очистки памяти созданных объектов DOM. Эти проблемы особенно характерны для вложенных циклов. Сама документация является неточной и написанной с ошибками, без ответов на исправления с 14 апреля 16.
Ganon
- Универсальный токенизатор и HTML / XML / RSS DOM Parser
- Возможность манипулировать элементами и их атрибутами
- Поддерживает неверный HTML и UTF8
- Может выполнять расширенные CSS3-подобные запросы к элементам (например, jQuery — поддерживаются пространства имен)
- HTML beautifier (как HTML Tidy)
- Сократить CSS и Javascript
- Сортировка атрибутов, изменение регистра символов, корректный отступ и т.
- растяжимый
- Разбор документов с использованием обратных вызовов на основе текущего символа / токена
- Операции разделены на меньшие функции для легкого переопределения
- Быстро и легко
 Д.
Д.Никогда не использовал это. Не могу сказать, хорошо ли это.
HTML 5
Вы можете использовать вышеупомянутое для разбора HTML5, но могут быть причуды из-за разметки, которую позволяет HTML5. Так что для HTML5 вы хотите рассмотреть возможность использования выделенного парсера, как
html5lib
Реализации Python и PHP HTML-парсера на основе спецификации WHATWG HTML5 для максимальной совместимости с основными настольными веб-браузерами.
Мы можем увидеть больше выделенных парсеров после завершения HTML5. Существует также блог от W3 под названием How-To для разбора html 5, который стоит проверить.
WebServices
Если вам не нравится программировать на PHP, вы также можете использовать веб-сервисы. В общем, я нашел очень мало полезности для них, но это только я и мои варианты использования.
ScraperWiki .
Внешний интерфейс ScraperWiki позволяет извлекать данные в той форме, которую вы хотите использовать в Интернете или в своих собственных приложениях. Вы также можете извлечь информацию о состоянии любого скребка.
Регулярные выражения
Последнее и наименее рекомендуемое , вы можете извлекать данные из HTML с помощью регулярных выражений . В целом, использование регулярных выражений в HTML не рекомендуется.
Большинство фрагментов, которые вы найдете в Интернете для соответствия разметке, являются хрупкими. В большинстве случаев они работают только для очень конкретного фрагмента HTML. Крошечные изменения разметки, такие как добавление пробелов где-либо, добавление или изменение атрибутов в теге, могут привести к сбою RegEx, если он написан неправильно. Вы должны знать, что вы делаете, прежде чем использовать RegEx на HTML.
Вы должны знать, что вы делаете, прежде чем использовать RegEx на HTML.
HTML-парсеры уже знают синтаксические правила HTML. Регулярные выражения должны преподаваться для каждого нового RegEx, который вы пишете. RegEx хороши в некоторых случаях, но это действительно зависит от вашего варианта использования.
Вы можете написать более надежные парсеры , но написание полноценного и надежного пользовательского парсера с регулярными выражениями — пустая трата времени, когда вышеупомянутые библиотеки уже существуют и справляются с этим гораздо лучше.
Также см. Разбор HTML Путь Ктулху
книги
Если вы хотите потратить немного денег, посмотрите на
Я не связан с PHP Architect или авторами.
21 книга для самостоятельного изучения парсинга
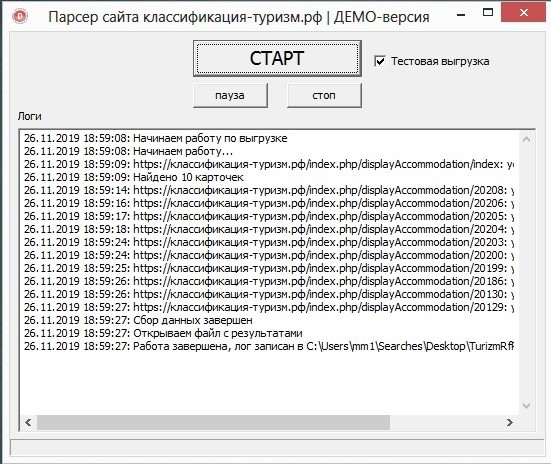
Моя компания занимается парсингом сайтов в России уже более трёх лет, ежедневно мы парсим порядка 500 крупнейших интернет-магазинов в России. Направление парсинга перспективно, т.к. информации все больше и всегда есть задача ее структурировать для последующего анализа.
{«id»:139845,»url»:»https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»title»:»21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share. php?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&title=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&text=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&text=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430&body=https:\/\/vc.
php?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&title=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&text=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga&text=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=21\u00a0\u043a\u043d\u0438\u0433\u0430 \u0434\u043b\u044f \u0441\u0430\u043c\u043e\u0441\u0442\u043e\u044f\u0442\u0435\u043b\u044c\u043d\u043e\u0433\u043e \u0438\u0437\u0443\u0447\u0435\u043d\u0438\u044f \u043f\u0430\u0440\u0441\u0438\u043d\u0433\u0430&body=https:\/\/vc. ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/books\/139845-21-kniga-dlya-samostoyatelnogo-izucheniya-parsinga»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
5025
просмотров
Для тех, кто хочет научиться парсингу самостоятельно, предлагаем следующую подборку из 21 книги (на английском языке), опираясь на рейтинг BookAuthority, который выбирает лучшие книги в мире, основываясь на публикациях, рекомендациях, рейтингах и мнениях. Мы специально оставили и английские названия книг, чтобы вам было проще их найти.
1. Краткое руководство по веб-парсингу на R (R Web Scraping Quick Start Guide)
Парсинг веб-сайтов становится все более популярными, поскольку данные — нефть 21 века. Благодаря этой книге вы получите ключевые знания об использовании XPath, regEX и веб-библиотек для R, таких как Rvest и RSelenium.
2. Наука о данных и R: конкретные примеры для вычислительных объяснений и решения проблем (Data Science in R)
Книга на реальных примерах рассказывает о задачах, связанных с решением вычислительных проблем, возникающих при анализе данных. Она раскрывает динамический и итеративный процесс, в помощью которого аналитики данных решают задачи, и рассказывает о различных способах поиска решений.
3. Изучаем Scrapy (Learning Scrapy)
В этой книге рассказывается о Scrapy v 1.0, который дает вам возможность без особых усилий извлекать (т.е. парсить) полезные данные практически из любого источника. Книга начинается с объяснения основ Scrapy Framework, после чего следует подробное описание того, как используя Python и сторонние API можно извлечь данные из любого источника, очистить их и сохранить в соответствии с вашими требованиями. Вы ознакомитесь с хранением информации в базах данных, с основами поисковых систем и работы с ними через Spark Streaming, платформу аналитики в реальном времени. К концу этой книги разработчики легко смогут получать любые данные для своих задач.
4. Веб-парсинг в Excel (Web Scraping with Excel)
Парсинг с Microsoft Excel может быть пугающим для непрограммистов и новичков. Эта книга, однако, демонстрирует, что с правильными знаниями и практикой этот навык может быть быстро и эффективно освоен каждым. Начинающие пользователи, начинающие разработчики VBA и опытные программисты найдут ценные уроки, советы и хитрости в этом простом, но в то же время лаконичном руководстве, которое поможет освоить этот ценный навык, который по-прежнему востребован.
5. Визуализация данных с Python и JavaScript (Data Visualization with Python and JavaScript)
Python и Javascript являются идеальным дополнением для превращения данных в многофункциональные интерактивные графики, которые затмят любые статичные изображения. Разработчики должны знать, как превратить необработанные данные, часто «грязные» или искаженные, в динамические интерактивные визуализации. Автор, используя интересные примеры и подчеркивая лучшие практики, учит, как использовать для этого возможности лучших в своем классе библиотек Python и Javascript.
6. Автоматизация маркетинга с помощью ботов (Automated Marketing with Webbots)
Что если ключ к эффективному маркетингу спрятан в ботах? Эта книга может стать окончательным ответом на вопросы, которые вас беспокоят. Побочными эффектами от чтения этой книги может стать внезапный подъем самооценки, беспрецедентная решительность при принятии маркетинговых решений, а также пожизненное пристрастие к автоматизации и парсингу данных.
7. Веб-парсинг на Python (Web Scraping with Python)
Книга рассказывает о том, как правильно получать данные с любых сайтов при помощи Python. Она предназначена для разработчиков, которые хотят использовать парсинг в законных целях. Предыдущий опыт программирования на Python полезен, но не обязателен. Любой человек, обладающий общими знаниями языков программирования, может прочесть книгу и понять основные принципы.
8. Автоматизированный сбор данных с помощью R: практическое руководство по парсингу веб-страниц и интеллектуальному анализу текста (Automated Data Collection With R)
Практическое руководство по поиску в сети и интеллектуальному анализу текста, как для начинающих, так и для опытных пользователей R. Книга представляет фундаментальные концепции архитектуры Сети и баз данных, рассказывает про HTTP, HTML, XML, JSON, SQL. Предоставляет основные методы для получения веб-документов и наборов данных (XPath и регулярные выражения). Представляет большой набор упражнений, которые помогут читателю понять каждую технику. В книге изучается как обучаемые, так и и необучаемые методы, очистка данных и управление текстом, приводятся тематические исследования, а также примеры для каждого из представленных методов.
Книга представляет фундаментальные концепции архитектуры Сети и баз данных, рассказывает про HTTP, HTML, XML, JSON, SQL. Предоставляет основные методы для получения веб-документов и наборов данных (XPath и регулярные выражения). Представляет большой набор упражнений, которые помогут читателю понять каждую технику. В книге изучается как обучаемые, так и и необучаемые методы, очистка данных и управление текстом, приводятся тематические исследования, а также примеры для каждого из представленных методов.
8. «Поваренная книга» парсинга на Python (Python Web Scraping Cookbook)
Эта книга, ориентированная на практические решения, научит вас методам разработки высокопроизводительных парсеров и поможет понять, как работают краулеры, карты сайтов, автоматизация форм, сайты на основе Ajax и кэш. В ней изучается ряд реальных сценариев, в которых полностью рассматриваются все части циклов разработки и жизненных циклов продуктов. Вы не только разовьете навыки проектирования и разработки надежных парсеров, но и развернете свою кодовую базу в AWS. Если вы занимаетесь разработкой программного обеспечения, разработкой продуктов или интеллектуальным анализом данных (или заинтересованы в создании продуктов на основе данных), то точно найдете эту книгу полезной, поскольку каждый рецепт в ней имеет четкую цель и задачу.
10. Краткое руководство по парсингу на Go (Go Web Scraping Quick Start Guide)
Парсинг — это процесс извлечения информации с использованием различных инструментов, которые получают и очищают данные. Go становится популярным языком для этого. Книга быстро объяснит вам, как собирать данные с различных веб-сайтов, используя библиотеки Go, такие как Colly и Goquery.
Go становится популярным языком для этого. Книга быстро объяснит вам, как собирать данные с различных веб-сайтов, используя библиотеки Go, такие как Colly и Goquery.
11. Цифровые социальные исследования (Digital Social Research)
Чтобы проанализировать социальные и поведенческие явления в нашем цифровом мире, необходимо понять основные исследовательские возможности и проблемы, специфичные для интернета и цифровых данных. Эта книга представляет собой обзор многих методов, которые являются частью инструментария цифрового социолога. Используя онлайн-методы в устоявшихся шаблонах социальных исследований, Джузеппе Вельтри обсуждает принципы и фреймворки, лежащие в основе каждого метода цифровых исследований. Это практическое руководство охватывает методологические вопросы, такие как работа с различными типами цифровых данных, вопросы их проверки, репрезентативности и выборки для больших данных. В нем рассматриваются различные неявные подходы к сбору данных (такие как парсинг веб-страниц и майнинг социальных сетей), а также явные методы (включая качественные методы, веб-опросы и эксперименты). Особое внимание уделяется вычислительным подходам к статистическому анализу, анализу текста и сетевому анализу. Книга будет отличным ресурсом для студентов и исследователей в области социальных и гуманитарных наук, проводящих цифровые исследования (или заинтересованных в них в будущем).
12. Веб-боты, пауки и экранные парсеры (Webbots, Spiders, and Screen Scrapers)
В Интернете имеется огромное количество данных, но их сортировка и ручной сбор могут быть утомительными и занимать много времени. Вместо того, чтобы бесконечно разглядывать одну страницу за другой, почему бы не позволить ботам сделать эту работу за вас? «Веб-боты, пауки и парсеры» покажет вам, как создавать простые программы на PHP/CURL для извлечения, анализа и архивирования данных, которые помогут принимать обоснованные решения.
Вместо того, чтобы бесконечно разглядывать одну страницу за другой, почему бы не позволить ботам сделать эту работу за вас? «Веб-боты, пауки и парсеры» покажет вам, как создавать простые программы на PHP/CURL для извлечения, анализа и архивирования данных, которые помогут принимать обоснованные решения.
13. Веб-парсинг на Python: собираем больше данных из интернета (Web Scraping with Python)
Если программирование — это волшебство, то парсинг, безусловно, является формой волшебства. Написав простую программу для автоматизации, вы сможете опрашивать веб-серверы, запрашивать данные и анализировать их для получения необходимой информации. Расширенное издание этой практической книги не только познакомит вас с поиском в интернете, но и послужит исчерпывающим руководством по сбору практически всех типов данных из современной Сети.
14. Парсинг для науки о данных на Python (Web Scraping for Data Science with Python)
В этой книге авторы стремятся предоставить краткое и современное руководство по парсингу сайтов, используя Python в качестве языка программирования. Эта книга написана для аудитории, специализирующейся на данных, и не скрывает никаких подробностей или лучших практик. Авторы сами являются учеными в области данных и считают, что веб-скрапинг является мощным инструментом в арсенале любого дата сайентиста, поскольку многие проекты в области данных начинаются с получения соответствующего набора данных. Так почему бы не использовать для этого сокровищницу информация — интернет?
15. «Поваренная книга» автоматизации на Python (Python Automation Cookbook)
«Поваренная книга» автоматизации на Python (Python Automation Cookbook)
Вы когда-нибудь делали одну и ту же монотонную офисную работу снова и снова? Или пытались найти простой способ сделать вашу жизнь лучше, автоматизируя некоторые из ваших повторяющихся задач? Используя рабочий проверенный подход, вы поймете, как автоматизировать все скучные вещи с помощью Python. «Поваренная книга» поможет вам получить четкое представление о том, как автоматизировать ваши бизнес-процессы с помощью Python, как искать новые возможности для роста с помощью парсинга веб-страниц, как анализировать информацию и создавать автоматические отчеты в виде электронных таблиц с графиками и автоматически генерировать электронные письма.
16. Практический парсинг веб-страниц с помощью Python (Hands-On Web Scraping with Python)
Парсинг веб-страниц — это важный метод, используемый во многих компаниях для сбора ценных данных. Эта книга позволит вам глубоко вникнуть в техники и методики парсинга. Вы узнаете, как эффективно извлекать данные, используя различные методы Python и других популярных инструментов.
17. Мгновенный веб-парсинг на PHP (Instant PHP Web Scraping)
Интернет подарил нам огромные объемы данных, свободно доступных для общего пользования. Однако сбор и обработка этих данных может занять много времени, если выполняется всё вручную. Тем не менее, парсинг может предоставить инструменты и фреймворки для получения данных за одно нажатие кнопки. ”Мгновенный веб-парсинг на PHP” предоставляет практические примеры и пошаговые инструкции, которые помогут вам разобраться с основными приемами, необходимыми для получения данных со страниц с помощью PHP. Книга даст вам знания и основу для создания веб-приложений для извлечения данных в самых разных целях — мониторинга, исследований, интеграции и т.п.
Тем не менее, парсинг может предоставить инструменты и фреймворки для получения данных за одно нажатие кнопки. ”Мгновенный веб-парсинг на PHP” предоставляет практические примеры и пошаговые инструкции, которые помогут вам разобраться с основными приемами, необходимыми для получения данных со страниц с помощью PHP. Книга даст вам знания и основу для создания веб-приложений для извлечения данных в самых разных целях — мониторинга, исследований, интеграции и т.п.
18. Веб-парсинг на PHP, вторая редакция (Web Scraping with PHP, 2nd Edition)
Узнайте, как автоматизировать веб с помощью PHP. Хотите получать данные с другого сайта, но API недоступен? Или API просто не предоставляет то, что нужно? Парсинг — проверенный временем метод сбора необходимой информации с веб-страницы. В этой книге вы познакомитесь с различными инструментами и библиотеками для получения, анализа и извлечения данных из HTML. За последние десять лет Интернет прошел большой путь. «Веб-парсинг на PHP» во второй редакции учитывает использование современных библиотек на основе PHP 7, написанных для более легкого взаимодействия с данными. Используете ли вы обычный PHP с cURL или популярный фреймворк, такой как Zend Framework или Symfony, эта книга полна примеров, показывающих, как использовать доступные классы и функции.
19. Начинаем работать с Beautiful Soup (Getting Started with Beautiful Soup)
Эта книга отлично подходит для всех, кто интересуется поиском и извлечением информации с сайтов. Однако для лучшего ее понимания требуются базовые знания Python, HTM и CSS. Beautiful Soup — это пакет Python для анализа документов HTML и XML. Он создает дерево синтаксического анализа для проанализированных страниц, которое можно использовать для извлечения данных из HTML, что полезно для очистки данных. При этом для написания приложения с использованием Beautiful Soup не требуется много кода.
Однако для лучшего ее понимания требуются базовые знания Python, HTM и CSS. Beautiful Soup — это пакет Python для анализа документов HTML и XML. Он создает дерево синтаксического анализа для проанализированных страниц, которое можно использовать для извлечения данных из HTML, что полезно для очистки данных. При этом для написания приложения с использованием Beautiful Soup не требуется много кода.
20. Практический веб-парсинг для науки о данных (Practical Web Scraping for Data Science)
Эта книга представляет собой полное и современное руководство по парсингу веба с использованием Python в качестве языка программирования. Написанная для аудитории, специализирующейся на науке о данных, книга рассказывает как о веб-технологиях, с которыми она работает, так и о, собственно, извлечении информации. Авторы рекомендуют парсинг как мощный инструмент для любого ученого, поскольку многие проекты в Data Science начинают как раз с получения соответствующего набора данных.
21. Парсинг динамических страниц с PhantomJS (Scraping the Dynamic Web with PhantomJS)
Поиск информации в Интернете всегда был сложной задачей. Веб-браузеры используют статический HTML для генерации DOM, при этом HTML не всегда является полным или правильным. К счастью, браузеры совершают невероятную работу по отрисовке страниц из плохо написанного или даже неработающего HTML. Существует несколько библиотек для различных платформ, которые пытаются упростить извлечение информации из статического HTML-кода. К сожалению, эти решения не являются надежными или простыми в использовании для среднего веб-разработчика. Чтобы еще больше усложнить ситуацию, сеть превращается в динамичную среду. Вместо изучения новых моделей извлечения информации с веб-страниц, почему бы не использовать jQuery для надежного извлечения информации из полностью визуализированного DOM в автоматическом режиме?
К сожалению, эти решения не являются надежными или простыми в использовании для среднего веб-разработчика. Чтобы еще больше усложнить ситуацию, сеть превращается в динамичную среду. Вместо изучения новых моделей извлечения информации с веб-страниц, почему бы не использовать jQuery для надежного извлечения информации из полностью визуализированного DOM в автоматическом режиме?
подробный видеокурс и программный код
В видеокурсе из семи уроков описывается парсинг сайтов с различной структурой при помощи Python третьей версии, библиотек requests и BeautifulSoup.
В этом видеокурсе Олег Молчанов подробно, не торопясь, рассказывает про парсинг сайтов при помощи Python 3. Раскрываются особенности парсинга многостраничных ресурсов, использования прокси с различными User-Agent, сохранения изображений и распознавания простого текста, а также быстрый мультипроцессорный парсинг сайтов.
В ряде случаев предлагаемые автором программные решения несколько устарели из-за изменения структуры страниц, подвергаемых парсингу. Автор курса не преследует цели создать идеальный парсер, а лишь излагает определенные концепции и иллюстрирует их примерами. Для облегчения вашей работы, мы привели исходные коды программ, набранные нами во время прохождения курса, с некоторыми поправками.
В уроке рассматривается мультипроцессорный парсинг на примере сайта CoinMarketCap.com. Сначала приводится пример однопоточного парсинга. Затем рассматривается, как модифицировать программу для реализации мультипроцессорного подхода при помощи библиотеки multiprocessing. Сравниваются временные интервалы, необходимые для парсинга в один и несколько потоков. Попутно рассказывается об экспорте данных в csv-файл.
Обратите внимание: для установки BeautifulSoup для Python 3 в видео указана неправильная команда. Правильный вариант: pip install beautifulsoup4 (либо для систем с двумя версиями Python: pip3 install beautifulsoup4).
Правильный вариант: pip install beautifulsoup4 (либо для систем с двумя версиями Python: pip3 install beautifulsoup4).
Программный код при однопоточном парсинге:
import csv
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_html(url):
response = requests.get(url)
return response.text
def get_all_links(html):
soup = BeautifulSoup(html, 'lxml')
tds = soup.find('table',).find_all('td', class_='currency-name')
links = []
for td in tds:
a = td.find('a', class_='currency-name-container').get('href')
link = 'https://coinmarketcap.com' + a
links.append(link)
return links
def text_before_word(text, word):
line = text.split(word)[0].strip()
return line
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
try:
name = text_before_word(soup.find('title').text, 'price')
except:
name = ''
try:
price = text_before_word(soup.find('div',
class_='col-xs-6 col-sm-8 col-md-4 text-left').text, 'USD')
except:
price = ''
data = {'name': name,
'price': price}
return data
def write_csv(i, data):
with open('coinmarketcap.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['name'],
data['price']))
print(i, data['name'], 'parsed')
def main():
start = datetime.now()
url = 'https://coinmarketcap.com/all/views/all'
all_links = get_all_links(get_html(url))
for i, link in enumerate(all_links):
html = get_html(link)
data = get_page_data(html)
write_csv(i, data)
end = datetime. now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()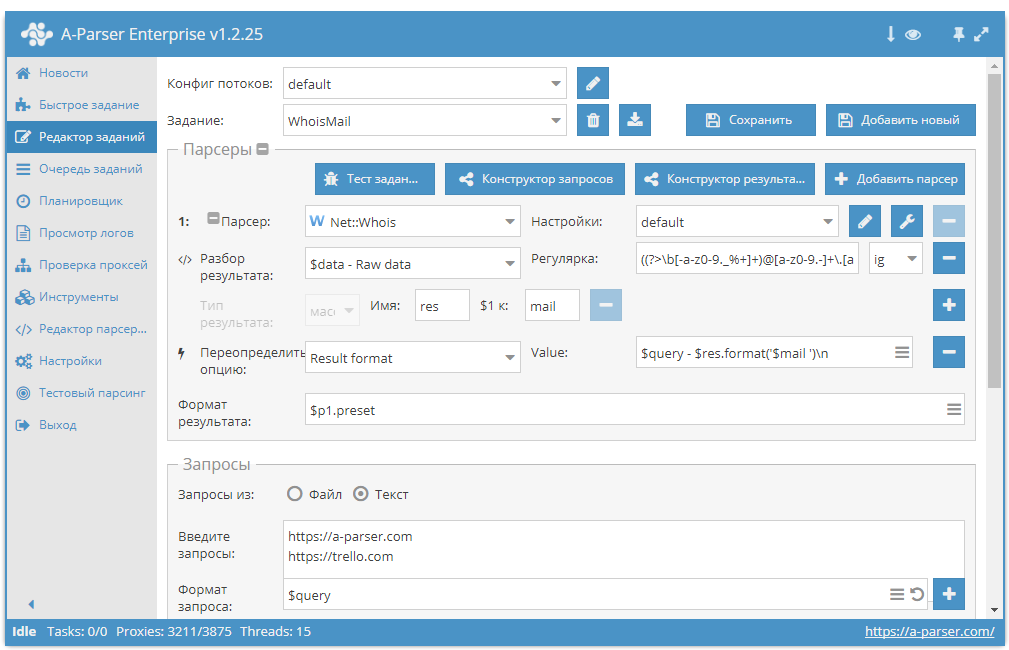 now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()
now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()Программный код при использовании мультипроцессорного парсинга с 40 процессами:
from multiprocessing import Pool
import csv
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_html(url):
response = requests.get(url)
return response.text
def get_all_links(html):
soup = BeautifulSoup(html, 'lxml')
tds = soup.find('table',).find_all('td', class_='currency-name')
links = []
for td in tds:
a = td.find('a', class_='currency-name-container').get('href')
link = 'https://coinmarketcap.com' + a
links.append(link)
return links
def text_before_word(text, word):
line = text.split(word)[0].strip()
return line
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
try:
name = text_before_word(soup.find('title').text, 'price')
except:
name = ''
try:
price = text_before_word(soup.find('div',
class_='col-xs-6 col-sm-8 col-md-4 text-left').text, 'USD')
except:
price = ''
data = {'name': name,
'price': price}
return data
def write_csv(data):
with open('coinmarketcap.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['name'],
data['price']))
print(data['name'], 'parsed')
def make_all(link):
html = get_html(link)
data = get_page_data(html)
write_csv(data)
def main():
start = datetime.now()
url = 'https://coinmarketcap.com/all/views/all'
all_links = get_all_links(get_html(url))
with Pool(40) as p:
p. map(make_all, all_links)
end = datetime.now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main() map(make_all, all_links)
end = datetime.now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()
map(make_all, all_links)
end = datetime.now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()Характерные времена могут разниться в зависимости от оборудования и текущего состояния сайта.
Во втором уроке рассматривается извлечение информации с многостраничного сайта по типу Avito.ru. В качестве примера берется задача поиска телефона по названию фирмы изготовителя с выводом названия товара, цены, ближайшей станции метро и ссылки объявления. Показывается простейший способ фильтрации нерелевантных блоков.
Обратите внимание: при многостраничном парсинге таких сайтов, как Avito.ru, ваш IP может быть временно забанен на совершение парсинга.
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url):
r = requests.get(url)
return r.text
def get_total_pages(html):
soup = BeautifulSoup(html, 'lxml')
divs = soup.find('div', class_='pagination-pages clearfix')
pages = divs.find_all('a', class_='pagination-page')[-1].get('href')
total_pages = pages.split('=')[1].split('&')[0]
return int(total_pages)
def write_csv(data):
with open('avito.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['title'],
data['price'],
data['metro'],
data['url']))
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
divs = soup.find('div', class_='catalog-list')
ads = divs.find_all('div', class_='item_table')
for ad in ads:
try:
div = ad.find('div', class_='description').find('h4')
if 'htc' not in div.text.lower():
continue
else:
title = div. text.strip()
except:
title = ''
try:
div = ad.find('div', class_='description').find('h4')
url = "https://avito.ru" + div.find('a').get('href')
except:
url = ''
try:
price = ad.find('div', class_='about').text.strip()
except:
price = ''
try:
div = ad.find('div', class_='data')
metro = div.find_all('p')[-1].text.strip()
except:
metro = ''
data = {'title':title,
'price':price,
'metro':metro,
'url':url}
write_csv(data)
def main():
url = "https://avito.ru/moskva/telefony?p=1&q=htc"
base_url = "https://avito.ru/moskva/telefony?"
page_part = "p="
query_par = "&q=htc"
# total_pages = get_total_pages(get_html(url))
for i in range(1, 3):
url_gen = base_url + page_part + str(i) + query_par
html = get_html(url_gen)
get_page_data(html)
if __name__ == '__main__':
main()
 text.strip()
except:
title = ''
try:
div = ad.find('div', class_='description').find('h4')
url = "https://avito.ru" + div.find('a').get('href')
except:
url = ''
try:
price = ad.find('div', class_='about').text.strip()
except:
price = ''
try:
div = ad.find('div', class_='data')
metro = div.find_all('p')[-1].text.strip()
except:
metro = ''
data = {'title':title,
'price':price,
'metro':metro,
'url':url}
write_csv(data)
def main():
url = "https://avito.ru/moskva/telefony?p=1&q=htc"
base_url = "https://avito.ru/moskva/telefony?"
page_part = "p="
query_par = "&q=htc"
# total_pages = get_total_pages(get_html(url))
for i in range(1, 3):
url_gen = base_url + page_part + str(i) + query_par
html = get_html(url_gen)
get_page_data(html)
if __name__ == '__main__':
main()
text.strip()
except:
title = ''
try:
div = ad.find('div', class_='description').find('h4')
url = "https://avito.ru" + div.find('a').get('href')
except:
url = ''
try:
price = ad.find('div', class_='about').text.strip()
except:
price = ''
try:
div = ad.find('div', class_='data')
metro = div.find_all('p')[-1].text.strip()
except:
metro = ''
data = {'title':title,
'price':price,
'metro':metro,
'url':url}
write_csv(data)
def main():
url = "https://avito.ru/moskva/telefony?p=1&q=htc"
base_url = "https://avito.ru/moskva/telefony?"
page_part = "p="
query_par = "&q=htc"
# total_pages = get_total_pages(get_html(url))
for i in range(1, 3):
url_gen = base_url + page_part + str(i) + query_par
html = get_html(url_gen)
get_page_data(html)
if __name__ == '__main__':
main()
Во второй части видео о парсинге Avito внимание фокусируется на совмещении парсинга с извлечением информации из изображений. Для этой задачи вместо библиотеки BeautifulSoup используется библиотека Selenium, работающая непосредственно с браузером на вашем компьютере. Для совместной работы может потребоваться файл драйвера браузера. Захват изображений и преобразование в текстовые строки осуществляется при помощи библиотек pillow и pytesseract.
from selenium import webdriver
from time import sleep
from PIL import Image
from pytesseract import image_to_string
class Bot:
def __init__(self):
self. driver = webdriver.Chrome() # or Firefox() or smth else
self.navigate()
def take_screenshot(self):
self.driver.save_screenshot('avito_screenshot.png')
def tel_recon(self):
image = Image.open('tel.gif')
print(image_to_string(image))
def crop(self, location, size):
image = Image.open('avito_screenshot.png')
x = location['x']
y = location['y']
width = size['width']
height = size['height']
image.crop((x, y, x+width, y+height)).save('tel.gif')
self.tel_recon()
def navigate(self):
self.driver.get('https://www.avito.ru/velikie_luki/telefony/lenovo_a319_1161088336')
button = self.driver.find_element_by_xpath(
'//button[@class="button item-phone-button js-item-phone-button
button-origin button-origin-blue button-origin_full-width
button-origin_large-extra item-phone-button_hide-phone
item-phone-button_card js-item-phone-button_card"]')
button.click()
sleep(3)
self.take_screenshot()
image = self.driver.find_element_by_xpath(
'//div[@class="item-phone-big-number js-item-phone-big-number"]//*')
location = image.location
size = image.size
self.crop(location, size)
def main():
b = Bot()
if __name__ == '__main__':
main()
 driver = webdriver.Chrome() # or Firefox() or smth else
self.navigate()
def take_screenshot(self):
self.driver.save_screenshot('avito_screenshot.png')
def tel_recon(self):
image = Image.open('tel.gif')
print(image_to_string(image))
def crop(self, location, size):
image = Image.open('avito_screenshot.png')
x = location['x']
y = location['y']
width = size['width']
height = size['height']
image.crop((x, y, x+width, y+height)).save('tel.gif')
self.tel_recon()
def navigate(self):
self.driver.get('https://www.avito.ru/velikie_luki/telefony/lenovo_a319_1161088336')
button = self.driver.find_element_by_xpath(
'//button[@class="button item-phone-button js-item-phone-button
button-origin button-origin-blue button-origin_full-width
button-origin_large-extra item-phone-button_hide-phone
item-phone-button_card js-item-phone-button_card"]')
button.click()
sleep(3)
self.take_screenshot()
image = self.driver.find_element_by_xpath(
'//div[@class="item-phone-big-number js-item-phone-big-number"]//*')
location = image.location
size = image.size
self.crop(location, size)
def main():
b = Bot()
if __name__ == '__main__':
main()
driver = webdriver.Chrome() # or Firefox() or smth else
self.navigate()
def take_screenshot(self):
self.driver.save_screenshot('avito_screenshot.png')
def tel_recon(self):
image = Image.open('tel.gif')
print(image_to_string(image))
def crop(self, location, size):
image = Image.open('avito_screenshot.png')
x = location['x']
y = location['y']
width = size['width']
height = size['height']
image.crop((x, y, x+width, y+height)).save('tel.gif')
self.tel_recon()
def navigate(self):
self.driver.get('https://www.avito.ru/velikie_luki/telefony/lenovo_a319_1161088336')
button = self.driver.find_element_by_xpath(
'//button[@class="button item-phone-button js-item-phone-button
button-origin button-origin-blue button-origin_full-width
button-origin_large-extra item-phone-button_hide-phone
item-phone-button_card js-item-phone-button_card"]')
button.click()
sleep(3)
self.take_screenshot()
image = self.driver.find_element_by_xpath(
'//div[@class="item-phone-big-number js-item-phone-big-number"]//*')
location = image.location
size = image.size
self.crop(location, size)
def main():
b = Bot()
if __name__ == '__main__':
main()
В этом видео на более абстрактном примере локальной страницы даны дополнительные примеры работы методов find и find_all библиотеки BeautifulSoup. Показывается, как находить включающие информацию блоки при помощи методов parent, find_parent и find_parents. Описаны особенности работы методов next_element и next_sibling, упрощающих поиск данных в пределах одного раздела. В конце видео рассматривается, как сочетать поиск в BeautifulSoup с регулярными выражениями.
В конце видео рассматривается, как сочетать поиск в BeautifulSoup с регулярными выражениями.
В пятом видео анализируется основной прием, помогающий избежать при парсинге бана или появления капчи посредством использования прокси-сервера с меняющимся адресом и изменения параметра User-Agent. Демонстрируется пример использования метода find_next_sibling. Рассмотрена передача IP и User-Agent при запросе библиотеки requests. Для использования актуального списка доступных прокси-серверов мы рекомендуем дополнить код парсером соответствующего сайта (в видео используются заранее подготовленные файлы со списками прокси и браузерных агентов).
import requests
from bs4 import BeautifulSoup
from random import choice, uniform
from time import sleep
def get_html(url, useragent=None, proxy=None):
print('get_html')
r = requests.get(url, headers=useragent, proxies=proxy)
return r.text
def get_ip(html):
print('get_ip')
print('New Proxy & User-Agent:')
soup = BeautifulSoup(html, 'lxml')
ip = soup.find('span', class_='ip').text.strip()
ua = soup.find('span', class_='ip').find_next_sibling('span').text.strip()
print(ip)
print(ua)
print('---------------------------')
def main():
url = 'https://sitespy.ru/my-ip'
useragents = open('useragents.txt').read().split('\n')
proxies = open('proxies.txt').read().split('\n')
for i in range(10):
# sleep(uniform(3, 6))
proxy = {'http': 'http://' + choice(proxies)}
useragent = {'User-Agent': choice(useragents)}
try:
html = get_html(url, useragent, proxy)
except:
continue
get_ip(html)
if __name__ == '__main__':
main()
https://www. youtube.com/watch?v=BLCmWzFbC0E
youtube.com/watch?v=BLCmWzFbC0E
В этом видеоуроке на примере двух сайтов объясняется, как обрабатывать сайты с ошибками или сайты, сделанные непрофессионалами. Первый ресурс https://us-proxy.org/ представляет пример сайта, который выглядит как многостраничный, но это лишь видимость – все данные загружаются на главную страницу при первом обращении к сайту. Во втором примере в структуре блога http://startapy.ru/ используется три вертикальных списка с необычным горизонтальным смещением размещаемых блоков при добавлении новых публикаций. В видеоуроке показано, как средства анализа браузеров в связи с некорректной версткой могут вводить нас в заблуждение, при том что BeautifulSoup отображает и использует исправленный вариант.
На примере сайта со свободными изображениями для фона рабочего стола https://www.hdwallpapers.in/ показывается процедура загрузки изображений с сайта – каждого в отдельную папку. Используются только библиотеки os (для работы с заданием пути сохранения файла) и requests. Показывается работа с блочной загрузкой файлов посредством метода iter_content.
import os
import requests
# url = 'https://www.hdwallpapers.in/thumbs/2018/spiral_silver_metal-t1.jpg'
# r = requests.get(url, stream=True) # stream for partial download
# with open('1.jpg', 'bw') as f:
# for chunk in r.iter_content(8192):
# f.write(chunk)
urls = [
'https://www.hdwallpapers.in/walls/messier_106_spiral_galaxy_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/helix_nebula_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/orion_nebula_hubble_space_telescope_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/solar_space-wide.jpg'
]
def get_file(url):
r = requests.get(url, stream=True)
return r
def get_name(url):
name = url. split('/')[-1]
folder = name.split('.')[0]
if not os.path.exists(folder):
os.makedirs(folder)
path = os.path.abspath(folder)
return path + '/' + name
def save_image(name, file_object):
with open(name, 'bw') as f:
for chunk in file_object.iter_content(8192):
f.write(chunk)
def main():
for url in urls:
save_image(get_name(url), get_file(url))
if __name__ == '__main__':
main()
 split('/')[-1]
folder = name.split('.')[0]
if not os.path.exists(folder):
os.makedirs(folder)
path = os.path.abspath(folder)
return path + '/' + name
def save_image(name, file_object):
with open(name, 'bw') as f:
for chunk in file_object.iter_content(8192):
f.write(chunk)
def main():
for url in urls:
save_image(get_name(url), get_file(url))
if __name__ == '__main__':
main()
split('/')[-1]
folder = name.split('.')[0]
if not os.path.exists(folder):
os.makedirs(folder)
path = os.path.abspath(folder)
return path + '/' + name
def save_image(name, file_object):
with open(name, 'bw') as f:
for chunk in file_object.iter_content(8192):
f.write(chunk)
def main():
for url in urls:
save_image(get_name(url), get_file(url))
if __name__ == '__main__':
main()
Drupal: Модуль Parser — парсинг сайтов
Описание
Модуль Parser предназначен для парсинга любых html страниц в сущности (ноды, термины, юзеры и т.д.). Собственно на этом описание модуля можно закончить =)
Принцип работы парсера похож на работу поисковиков — он загружает одну из страниц сайта, ищет на ней ссылки и начинает ходить по ним в глубь. Встретив страницу, которая попадает под условие «распарсить эту страницу», модуль создает объект сущности и начинает выполнять пользовательский php код, заполняя поля и свойства. Картинки выкачиваются на сервер, создаются отсутствующие термины, значения приводятся к нужному типу.
Использование
Сразу хочу предупредить, что без знаний php работать с модулем будет крайне затруднительно.
Задания парсера находятся по адресу admin/structure/parser_jobs. По умолчанию там есть только одно — Парсинг шаблонов с drupal.org, которое можно использовать как мануал.
Как начать парсить сайт:
- Создаём задание
admin/structure/parser_jobs/add. - В поле Стартовый URL указываем начальный адрес. С него парсер начнёт работу.
- В поле URL тестовой страницы указываем адрес любой страницы, которая в будущем будет распарсена в ноду. HTML код этой страницы будет использован в качестве полигона.
- В поле Глубина указываем глубину, до которой парсер будет шагать по найденным ссылкам (простыми словами, глубина — это количество кликов, которые надо сделать относительно страницы указанной в Стартовый URL, чтобы добраться до страницы с контентом).
- Заполняем белый и чёрный список адресов.
- В поле Код проверки для дальнейшего парсинга страницы пишем код, который должен вернуть TRUE, если текущая страница попадает под условие «распарсить страницу в ноду«.
- Указываем тип сущности, которая будут создаваться модулем.
- Для каждого поля пишем php код, возвращающий значение поля. В коде можно использовать весь функционал библиотеки phpQuery, парсинг с которой превращается в удовольствие 🙂 С помощью кнопок «проверить» смотрим результат работы кода.
- Делаем полный бэкап базы и файлов! При неправильной конфигурации модуль может насоздавать много лишних нод.
- Начинаем парсинг.

Модуль запоминает адреса и идентификаторы нод, созданные из этих адресов. При повторном парсинге, модуль лишь обновляет уже существующие ноды.
Скриншот 1
Скриншот 2
Скриншот 3
— Скачать модуль
— Пример парсинга сайта drupalsn.ru
Написанное актуально для
Parser 7.x-2.x
Похожие записи
Пример парсера для web сайтов.
Часто возникает задача периодически парсить какой-нибудь сайт на наличие новой информации. Например, если ты пишешь агрегатор контента с новостного сайта или форума, в котором нет поддержки RSS. Проще всего написать скрепер на Питоне и разобрать полученный HTML через beautifulsoup или регулярками. Однако есть более элегантный способ — самому сделать недостающие API для сайта и получать ответы в привычном JSON, как будто бы у сайта есть нативный API.
Не будем далеко ходить за примером и напишем парсер контента с сайта известного журнала. Как ты знаешь, сайты не сейчас не предоставляет никакого API для программного получения статей, кроме RSS. Однако RSS не всегда удобен, да и выдает далеко не всю нужную информацию. Исправим это!
ПОСТАНОВКА ЗАДАЧИ
Итак, наша задача: сделать API вида GET /posts, который бы отдавал десять последних статей в JSON. Также нам нужно иметь возможность задавать сдвиг, то есть раз за разом получать следующие десять постов.
Также нам нужно иметь возможность задавать сдвиг, то есть раз за разом получать следующие десять постов.
GET /posts
Ответ должен быть таким:
Также нужно иметь возможность получать следующие десять постов — со второй страницы, третьей и так далее. Это делается через GET-параметр вида GET /posts?page=2. Если page в запросе не указан, считаем его равным 1 и отдаем посты с первой страницы «Хакера». В общем, задача ясна, переходим к решению.
ФРЕЙМВОРК ДЛЯ ПАРСЕРА WEB САЙТОВ
WrapAPI — это довольно новый (пара месяцев от роду) сервис для построения мощных кастомных парсеров веба и предоставления к ним доступа по API. Не пугайся, если ничего не понял, сейчас поясню на пальцах. Работает так:
- Указываешь WrapAPI страницу, которую нужно парсить (в нашем случае главную «Хакера» — https://xakep.ru/).
- Говоришь, с какими параметрами обращаться к серверу, каким HTTP-методом (GET или POST), какие query-параметры передавать, какие POST-параметры в body, куки, хедеры. Короче, все, что нужно, чтобы сервер вернул тебе нормальную страничку и ничего не заподозрил.
- Указываешь WrapAPI, где на полученной странице ценный контент, который надо вытащить, в каком виде его представлять.
- Получаешь готовый URL для API вида GET /posts, который вернет тебе все выдранные с главной «Хакера» посты в удобном JSON!
Немного о приватности запросов
Ты наверняка уже задумался о том, насколько безопасно использовать чужой сервис и передавать ему параметры своих запросов с приватными данными. Тем более что по умолчанию для каждого нового API-проекта будет создаваться публичный репозиторий и запускать API из него сможет любой желающий. Не все так плохо:
1. Каждый API-репозиторий (а соответственно, и все API-запросы в нем) можно сделать приватным. Они не будут показываться в общем списке уже созданных API на платформе WrapAPI. Просто выбери достаточно сложное имя репозитория, и шанс, что на него кто-то забредет случайно, сведется к минимуму.
2. Любой запрос к WrapAPI требует специального токена, который нужно получить в своей учетке WrapAPI. То есть просто так узнать URL к твоему репозиторию и таскать через
ПРИГОТОВЛЕНИЯ
Несколько простых шагов перед началом.
1. Идем на сайт WrapAPI, создаем новую учетку и логинимся в нее.
2. Устанавливаем расширение для Chrome (подойдет любой Chromium-based браузер), открываем консоль разработчика и видим новую вкладку WrapAPI. 3. Переходим на нее и логинимся.
Это расширение нам понадобится для того, чтобы перехватывать запросы, которые мы собираемся эмулировать, и быстро направлять их в WrapAPI для дальнейшей работы. По логике работы это расширение очень похоже на связку Burp Proxy + Burp Intruder.
ОТЛАВЛИВАЕМ ЗАПРОСЫ
Теперь нужно указать WrapAPI, какой HTTP-запрос мы будем использовать для построения нашего API. Идем на сайт «Хакера» и открываем консоль разработчика, переключившись на вкладку WrapAPI.
Для получения постов я предлагаю использовать запрос пагинации, он доступен без авторизации и может отдавать по десять постов для любой страницы «Хакера», возвращая HTML в объекте JSON (см. ниже).
Чтобы WrapAPI начал перехватывать запросы, нажми Start capturing requests и после этого выполни целевой запрос (на пагинацию). Плагин поймает POST-запрос к странице https://xakep.ru/wp-admin/admin-ajax.php с кучей form/urlencoded-параметров в теле, в том числе и номером страницы. Ответом на запрос будет JSON-объект с параметром content, содержащий закешированный HTML-код с новыми постами. Собственно, этот блок и нужно парсить WrapAPI.
КОНФИГУРИРУЕМ WRAPAPI
После того как ты выбрал нужное имя для твоего репозитория (я взял test001 и endpoint posts) и сохранил его на сервер WrapAPI через расширение для Chrome, иди на сайт WrapAPI и открывай репозиторий. Самое время настраивать наш API.
Переходи на вкладку Inputs and request. Здесь нам понадобится указать, с какими параметрами WrapAPI должен парсить запрашиваемую страницу, чтобы сервер отдал ему валидный ответ.
Здесь нам понадобится указать, с какими параметрами WrapAPI должен парсить запрашиваемую страницу, чтобы сервер отдал ему валидный ответ.
Аккуратно перебей все параметры из пойманной WrapAPI полезной нагрузки (POST body payload) в поле слева. Для всех параметров, кроме paginated, выставь тип Constant. Это означает, что в запросы к серверу будут поставляться предопределенные значения, управлять которыми мы не сможем (нам это и не нужно). А вот для paginated выставляй Variable API, указав имя page. Это позволит нам потом обращаться к нашему API по URL вида GET / posts?page=5 (с query-параметром page), а на сервер уже будет уходить полноценный POST со всеми перечисленными параметрами.
[ad name=»Responbl»]
Заголовки запроса ниже можно не трогать, я использовал стандартные из Chromium. Если парсишь не «Хакер», а данные с какого-нибудь закрытого сервера, можешь подставить туда нужные куки, хедеры, basic-auth и все, что нужно. Одним словом, ты сможешь настроить свой запрос так, чтобы сервер безо всяких подозрений отдал тебе контент.
УЧИМ WRAPAPI НЕДОСТАЮЩИМ ФИЧАМ
Теперь нужно указать WrapAPI, как обрабатывать полученный результат и в каком виде его представлять. Переходи на следующую вкладку — Outputs and response.
Небольшой глоссарий, прежде чем идти дальше:
- Output — фильтр-постпроцессор контента, который принимает на входесырой ответ сервера, а возвращает уже модифицированный по заданным правилам. Они бывают нескольких типов. Самые часто используемые:
- JSON выбирает содержимое указанного атрибута, который подан на вход JSON-объекта, и возвращает его значение как строку;
- CSS выбирает элементы DOM по указанному CSS-селектору (например, ID или классу) и возвращает их значение, атрибут или весь HTML-тег целиком. Может вернуть как одну строку, так и массив найденных вхождений;
- Regular expression выбирает вхождения по регулярному выражению, в остальном то же, что и предыдущий output;
- HTTP Header выбирает значение HTTP-заголовка ответа сервера и возвращает его строкой;
- Cookie выбирает значение Cookie, полученной в ответе от сервера, и возвращает его строкой.
- Output Scenario — набор аутпутов, которые объединены в одну или несколько параллельных цепочек. По сути — почти весь набор препроцессоров, которые превращают серверный ответ в нужный нам формат.
- Test case — сохраненный ответ сервера, на котором тестируются обработчики и подбирается нужная цепочка аутпутов.
Создай новый test case, сохрани его под именем page1. Теперь посмотри, что вернул сервер. Это должен быть объект JSON, одно из полей которого содержит кусок HTTP-разметки с перечислением запрошенных постов.
Продолжение следует..
Click to rate this post!
[Total: 8 Average: 3.1]
XML парсер в массив на PHP
class myXMLparser {
//XML парсер
static function parse($xmlstring) {
$xml = xml_parser_create();
xml_parse_into_struct($xml, $xmlstring, $parsedSim);
xml_parser_free($xml);
unset($dataxml);
print_r($parsedSim);
$parsedSim = myXMLparser::convertXarToPar($parsedSim);
return $parsedSim;
}
/* функция преобразования */
static private function convertXarToPar(&$parsed) {
$data = array();
$cursor = 0;
myXMLparser::convertExplore($data, $parsed, $cursor);
return $data;
}
/* рекурсивная часть преобразователя */
static private function convertExplore(&$data, &$parsed, &$cursor) {
while (isset($parsed[$cursor])) {
$v = &$parsed[$cursor ++];
//type value analysis
switch($v[‘type’]) {
case ‘open’:
$tag = $v[‘tag’];
$j = &$data[];
$j[‘tag’] = $tag;
$j[‘value’] = isset($v[‘value’]) ? $v[‘value’] : »;
if (isset($v[‘attributes’])) $data += $v[‘attributes’];
myXMLparser::convertExplore($j, $parsed, $cursor);
break;
case ‘close’:
return;
case ‘cdata’:
if (empty($v[‘value’]) || trim($v[‘value’]) == ») break;
else {
$j = &$data[];
$j[‘value’] = trim($v[‘value’]);
}
break;
case ‘complete’:
$tag = $v[‘tag’];
$j = &$data[];
$j[‘tag’] = $tag;
$j[‘value’] = isset($v[‘value’]) ? $v[‘value’] : »;
if (isset($v[‘attributes’])) $j += $v[‘attributes’];
break;
}
}
}
}
Как разобрать JSON в PHP — Linux Подсказка
Полная форма JSON — это нотация объектов JavaScript. Это текстовый формат данных, подобный XML, который очень легко писать и интерпретировать как компьютерами, так и людьми. Он требует меньшей пропускной способности по сравнению с XML. Таким образом, он считается легковесным форматом обмена данными, который можно легко и быстро проанализировать и сгенерировать с помощью PHP или других языков. JSON по структуре очень похож на массивы PHP. Данные JSON создаются вложенными парами «ключ-значение», где значение может быть числом, строкой, логическим значением, нулем, объектом или массивом.В PHP используются две встроенные функции для кодирования и декодирования данных JSON. Это json_encode (), и json_decode (). В этом руководстве вы узнаете, как с помощью PHP различными способами генерировать и анализировать данные JSON.
Это текстовый формат данных, подобный XML, который очень легко писать и интерпретировать как компьютерами, так и людьми. Он требует меньшей пропускной способности по сравнению с XML. Таким образом, он считается легковесным форматом обмена данными, который можно легко и быстро проанализировать и сгенерировать с помощью PHP или других языков. JSON по структуре очень похож на массивы PHP. Данные JSON создаются вложенными парами «ключ-значение», где значение может быть числом, строкой, логическим значением, нулем, объектом или массивом.В PHP используются две встроенные функции для кодирования и декодирования данных JSON. Это json_encode (), и json_decode (). В этом руководстве вы узнаете, как с помощью PHP различными способами генерировать и анализировать данные JSON.
Кодирование данных JSON с использованием PHP
PHP использует метод json_encode () для преобразования массива PHP в данные JSON.
Пример-1:
В следующем примере объявляется массив, и после кодирования данные будут сгенерированы в формате json.
// Массив PHP
$ animals = array («Лев», «Обезьяна», «Лиса», «Олень», «Крыса», «Собака», «Кошка»);
echo json_encode ($ animals);
?>
Из пут:
Пример-2:
В следующем примере объявляется массив, и значения массива кодируются с использованием параметра JSON_FORCE_OBJECT для генерации данных JSON с парами ключ-значение.
// Массив PHP
$ food = array («Торт», «Шоколад», «Мороженое», «Пепси», «Хлеб», «Карри с рыбой», «Жареный цыпленок»);
// массив преобразуется в массив или объект
echo json_encode ($ food, JSON_FORCE_OBJECT);
?>
Выход:
Пример-3:
В следующем примере объявляется ассоциативный массив, который после кодирования генерирует данные JSON в виде пар ключ-значение без использования каких-либо параметров.
// Ассоциативный массив
$ people = array («John» => 35, «Peter» => 20, «Mark» => 68, «Lisa» => 30);
echo json_encode ($ person);
?>
Выход:
Следуя вышеуказанным шагам, вы можете легко преобразовать любой тип массива PHP в формат данных JSON с помощью метода json_encode (). Если вы хотите отправить или обменять небольшой объем данных из одного места в другое, вы можете преобразовать данные в формат JSON и легко их экспортировать.После импорта данных JSON вам нужно будет прочитать данные в формате PHP. Чтобы выполнить эту задачу, вы можете следовать следующей части этого руководства.
Декодирование данных JSON с использованием PHP
Вы можете анализировать или читать данные JSON из объекта JSON или любого файла JSON с помощью метода PHP json_decode (). Ниже приведены различные примеры синтаксического анализа данных JSON с использованием PHP.
Пример-1:
В следующем примере данные JSON назначаются в переменной, а метод PHP json_decode () используется для чтения данных в формате PHP.
// Сохранение данных JSON в переменной PHP
$ person = ‘{«John»: 35, «Peter»: 40, «Mac»: 28, «Lisa»: 20}’;
var_dump (json_decode ($ person));
?>
Выход:
В выходных данных показаны ключи и значения массива с типом данных. Здесь значение возраста любого человека задается числовым. Итак, на выходе отображается тип данных int.
Пример-2:
В следующем примере данные меток с номером рулона назначаются в формате JSON.Если вы используете необязательный логический параметр метода json_encode (), тогда на выходе будет показан тип объекта с общим количеством элементов. Здесь выходной объект массива shoes с 6 элементами.
// Сохранение данных JSON в переменной PHP
$ mark = ‘{«1001»: 95, «1002»: 80, «1003»: 78, «1004»: 90, «1005»: 83, » 1006 «: 92} ‘;
var_dump (json_decode ($ mark, true));
?>
Выход:
Пример -3:
В следующем примере показано, как можно прочитать каждый элемент данных JSON как индекс массива и свойство объекта. В скрипте переменная $ age, содержащая данные JSON, декодируется как массив и объект с использованием необязательного параметра true. Здесь генерируются два типа вывода. Элементы анализируются по индексу массива в первой части и анализируются по свойству объектов во второй части.
В скрипте переменная $ age, содержащая данные JSON, декодируется как массив и объект с использованием необязательного параметра true. Здесь генерируются два типа вывода. Элементы анализируются по индексу массива в первой части и анализируются по свойству объектов во второй части.
// Назначьте закодированную строку JSON переменной PHP
$ age = ‘{«Poll»: 55, «Devid»: 40, «Akbar»: 68, «Cally»: 70}’;
// Декодирование данных JSON в ассоциативный массив PHP
$ arr = json_decode ($ age, true);
echo «Анализ данных с помощью массива PHP
«;
// Доступ к значениям из ассоциативного массива
echo $ arr [«Опрос»].«
»;
echo $ arr [«Дэвид»]. «
«;
echo $ arr [«Акбар»]. «
«;
echo $ arr [«Калли»]. «
«;
$ obj = json_decode ($ age);
echo «Анализ данных с помощью объекта PHP
«;
// Доступ к значениям из возвращенного объекта
echo $ obj-> Poll. «
«;
echo $ obj-> Devid. «
«;
echo $ obj-> Акбар. «
«;
echo $ obj-> Калли. «
«;
?>
Выход:
Пример-4:
Использование цикла — наиболее эффективный способ чтения переменной массива.В следующем примере показано, как можно анализировать данные JSON с помощью цикла for после декодирования. Здесь имена свойств данных JSON назначаются как индекс массива, а значения свойств назначаются как значения массива.
// Назначьте закодированную строку JSON переменной PHP
$ age = ‘{«Poll»: 55, «Devid»: 40, «Akbar»: 68, «Cally»: 70}’;
// Декодирование данных JSON в ассоциативный массив PHP
$ array = json_decode ($ age, true);
// Цикл по ассоциативному массиву
foreach ($ array as $ key => $ value)
{
echo $ key.«=>». $ значение. «
»;
}
?>
Выход:
Пример-5:
В приведенных выше примерах данные JSON анализируются из конкретной переменной, но часто требуется анализ данных из файла JSON.
Предположим, у вас есть файл JSON с именем employee.json со следующим содержимым.
[
{«Имя»: «Адам», «Должность»: «Помощник менеджера»,
«Адрес»: {«Улица»: «1000 Brooklyn Meadow», «Город»: «Денвер»},
«Электронная почта»: «[электронная почта защищена]», «Телефон»: «+473497»},
{«Имя»: «Боб», «Должность»: «Менеджер»,
«Адрес»: {«Улица»: «Острый полумесяц, 23», «Город»: «Бристоль»},
«Электронная почта»: «[электронная почта защищена]», «Телефон»: «+ 479975047»},
{«Name»: «Kate», «Post»: «CEO»,
«Адрес»: {«Улица»: «Улица Юки, 7», «Город»: «Токио»},
«Электронная почта»: «[электронная почта защищена]», «Телефон»: «+47377800047»}
]
Вы должны использовать метод file_get_contents () для чтения файла JSON перед декодированием данных.В следующем скрипте данные файла JSON печатаются в виде массива, а в последней части скрипта показан способ чтения определенного значения свойства данных JSON. Здесь значения свойства « Name » печатаются с использованием цикла for.
// Чтение файла JSON
$ readjson = file_get_contents (’employee.json’);
// Декодирование JSON
$ data = json_decode ($ readjson, true);
// Распечатать данные
print_r ($ data);
echo «
Имена сотрудников:
«;
// Разбираем имя сотрудника
foreach ($ data as $ emp) {
echo $ emp [‘Name’].«
»;
}
?>
Прочитав и выполнив приведенные выше примеры этого руководства, вы сможете очень легко создавать или анализировать любые данные JSON с помощью PHP.
php-parser · pkg.go.dev
PHP-парсер, написанный на Go
В этом проекте используются инструменты goyacc и ragel для создания синтаксического анализатора PHP. Он анализирует исходный код в AST. Его можно использовать для написания инструментов статического анализа, рефакторинга, метрик и форматирования стиля кода.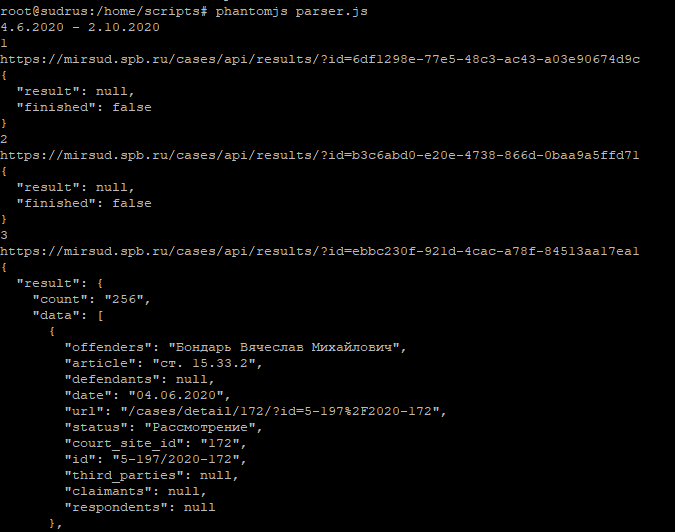
Попробовать онлайн: demo
Особенности:
- Полная поддержка синтаксиса PHP 5 и PHP 7
- Представление абстрактного синтаксического дерева (AST)
- Перемещение AST
- Разрешение имен в пространствах имен
- Синтаксический анализ файлов PHP с недопустимым синтаксисом
- Сохранение и печать свободно плавающих комментариев и пробелов
Кто использует
VKCOM / noverify — NoVerify — довольно быстрый линтер для PHP
quasilyte / phpgrep — phpgrep — это инструмент для поиска кода PHP с учетом синтаксиса
Пример использования
пакет основной
импорт (
"fmt"
"Операционные системы"
"github.com / z7zmey / php-parser / php7 "
"github.com/z7zmey/php-parser/visitor"
)
func main () {
src: = [] byte (` Дорожная карта
- График потока управления (CFG)
- Синтаксический анализатор PhpDocComment
- API стабилизации
Установить
иди на github.com / z7zmey / php-парсер
CLI
php-parser [флаги] <путь> ...
| флаг | тип | описание |
|---|---|---|
| -п | булев | путь к файлу печати |
| -d | строка | формат дампа: [custom, go, json, pretty-json] |
| -r | булев | разрешить имена |
| -ff | булев | разобрать и показать свободно плавающие строки |
| -проф | строка | запустить профилировщик: [cpu, mem, trace] |
| -php5 | булев | разбирается как PHP5 |
Выгрузить AST в стандартный вывод.
Преобразователь пространств имен
Преобразователь пространства имен - это посетитель, который разрешает полное имя узла и сохраняет в строку map [node.Node] строку структуру
- Для
Class,Интерфейс,Trait,Function,Константаузлов сохраняет имя с текущим пространством имен. - Для
Имя,Относительный,FullyQualifiedузлов, которые он разрешает,использует псевдонимыи сохраняет полное имя.
Разбор XML в PHP - Введение
Последнее изменение: 23 сентября 2020 г.
В PHP анализ XML-файла выполняется с использованием различных доступных расширений. Используя эти расширения, мы можем получать доступ, изменять, проверять и делать многое другое с XML-документом.
Методы синтаксического анализа, используемые этими расширениями синтаксического анализатора PHP XML: древовидный, потоковый и событийный. В этой статье мы увидим введение в эти расширения PHP.
Расширения синтаксического анализатора XML
В следующем листинге показаны расширения синтаксического анализатора XML, доступные в ядре PHP. Для всех этих расширений требуется расширение libxml , которое по умолчанию включено.
- Синтаксический анализатор SimpleXML
- Парсер DOM
- XMLParser
- Читатель XML
1. Синтаксический анализатор SimpleXML
- Синтаксический анализатор SimpleXML - это анализатор на основе дерева.
- Как правильно названо, этот синтаксический анализатор используется для синтаксического анализа простого XML-файла (не слишком длинного и без сложной структуры узлов).
- Он преобразует XML-файл и возвращает соответствующий объект SimpleXMLElement.
- Мы можем загрузить XML-файл или документ как строку для функций SimpleXML. Например, simplexml_load_file () принимает путь к XML-файлу, а simplexml_load_string () требует строку.
2. Парсер DOM
- Расширение парсера DOM в PHP используется для обработки сложных XML-файлов.
- Он используется как интерфейс для доступа и изменения данного XML-документа.
- Это также древовидный синтаксический анализатор, как и SimpleXML.
- Начиная с PHP 5, он обновлен с более старой версии DOM с помощью domxml .
- использует кодировку символов utf-8.
Расширение парсера DOM
Примечание:
Синтаксические анализаторы SimpleXML и DOM совместимы. Это означает, что функция DOM примет массив объектов SimpleXML для преобразования его в формат DOM. Точно так же функция SimpleXML принимает XML-документ в формате DOM для преобразования в массив объектов.
3. Синтаксический анализатор XML
- Это анализатор SAX, основанный на событиях.
- Это быстрее, чем два вышеупомянутых, поскольку не загружает весь XML-документ в память для синтаксического анализа.
- Создает парсеры XML, реализует классы манипулирования XML библиотеки парсеров Expat.
- Он поддерживает три типа кодировки символов: ISO-8859-1, US-ASCII и UTF-8.
- При использовании этого расширения нам необходимо создать экземпляр XMLParser (дескриптор парсера) для доступа к его функциям-членам.
- Это расширение синтаксического анализатора может работать с XML с пространством имен.
4.Читатель XML
- Это потоковый синтаксический анализатор, также известный как синтаксический анализатор запроса, поскольку он извлекает данные из заданного файла XML.
- Это лучший выбор PHP-расширений XML для чтения XML-документа, потому что он,
- быстрее
- работает с XML-документом высокой сложности
- поддерживает проверку XML
- Для использования этого расширения у нас должен быть PHP версии 5.1 и выше.
↑ Вернуться к началу
Парсер потоковой передачи JSON для PHP
Недавно я поискал анализатор потоковой передачи JSON, написанный на PHP, и не нашел его. Так что я написал свой собственный и делаю его доступным для всех, кто хочет его использовать.
Так что я написал свой собственный и делаю его доступным для всех, кто хочет его использовать.
Для тех, кто не знаком с потоковыми парсерами, дам краткое введение. Короче говоря, они полезны, если у вас очень большой документ и вы не хотите загружать все сразу в память.
Большинство (не потоковых) парсеров, включая, например, стандартные парсеры JSON, поставляемые с PHP, загружают в память весь документ и затем предоставляют вам доступ ко всему сразу. Преимущество этого подхода «весь документ сразу» заключается в том, что вы получаете произвольный доступ ко всем объектам в документе.Кроме того, программный интерфейс, который они предоставляют, может быть действительно удобным. В стандартной библиотеке PHP вы можете обработать собственный массив PHP для всего документа JSON, с которым действительно легко работать.
Обратной стороной является, как уже упоминалось, весь документ должен быть загружен в память. Для большинства веб-серверов или веб-сервисов это серьезное ограничение. Более того, это означает, что ваше приложение не может начать делать что-либо полезное с данными, пока все это не будет загружено в память.Потоковый анализатор, напротив, предоставляет вашему приложению доступ к данным почти сразу после того, как данные считываются PHP, поэтому может быть намного быстрее.
Когда я писал плагин для Magento, мне понадобился парсер потоковой передачи JSON , написанный на PHP. Я посмотрел на StackOverflow, PHP.net и, наконец, на Google. Для меня это довольно безумие, что, судя по всему, ни у кого не было такой потребности раньше, учитывая популярность JSON и PHP, но готово!
Пример парсера потоковой передачи JSON
Вот пример использования парсера потоковой передачи JSON в действии:
Ключевым элементом здесь является класс YourListener .Парсеры потоковой передачи используют модель событий, для которой требуется слушатель. Обычно, как только происходит «событие» (то есть какой-то объект или значение анализируется из документа JSON), слушатель уведомляется. Интерфейс довольно прост. Вот пример полной реализации слушателя:
Интерфейс довольно прост. Вот пример полной реализации слушателя:
Вы можете найти код на GitHub. Надеюсь, это сэкономит вам время.
Netscape HTTP Cooke File Parser В PHP
мне недавно потребовалось создать функцию, которая будет читать и извлекать куки из файла куки Netscape HTTP.Этот файл создается PHP при запуске CURL (с соответствующими включенными параметрами) и может использоваться в последующих вызовах CURL. Этот файл можно прочитать, чтобы узнать, какие файлы cookie были созданы после завершения работы CURL. Например, это тип файла, который может быть создан во время типичного вызова CURL.
# Netscape HTTP Cookie File
# http://curl.haxx.se/rfc/cookie_spec.html
# Этот файл был создан libcurl! Редактируйте на свой страх и риск.
www.example.com FALSE / FALSE 1338534278 cookiename value
Первые несколько строк представляют собой комментарии, поэтому их можно игнорировать. Данные cookie состоят из следующих элементов (в порядке их появления в файле.
- домен - Домен, который создал и может читать переменную.
- flag - Значение ИСТИНА / ЛОЖЬ, указывающее, все ли машины в данном домене могут получить доступ к переменной.Это значение устанавливается автоматически браузером в зависимости от значения, установленного вами для домена.
- путь - Путь в домене, для которого действительна переменная.
- secure - значение ИСТИНА / ЛОЖЬ, указывающее, требуется ли безопасное соединение с доменом для доступа к переменной.
- expiration - Время UNIX, по истечении которого истекает срок действия переменной.
- имя - Имя переменной.
- значение - Значение переменной.
Итак, функция, используемая для извлечения этой информации, будет выглядеть следующим образом. Он работает довольно просто и по сути возвращает массив найденных файлов cookie, если таковые имеются. Первоначально я пытался использовать символ решетки, чтобы определить начало прокомментированной строки, а затем попытаться извлечь что-нибудь еще, что содержало контент. Однако оказывается, что некоторые сайты добавляют файлы cookie с символом решетки в начале (да, даже для параметра URL). Поэтому безопаснее определять строку cookie, проверяя, есть ли в ней 6 символов табуляции.Затем он заменяется символом табуляции и преобразуется в массив элементов данных.
/ **
* Извлеките все файлы cookie, найденные из файла cookie. Эта функция ожидает получить
* строку, содержащую содержимое файла cookie, которое затем
* попытается извлечь и вернуть любые файлы cookie, найденные внутри.
*
* @param string $ string Содержимое файла cookie.
*
* @return array Массив файлов cookie, извлеченных из строки.
*
* /
функция extractCookies ($ string) {
$ cookies = array ();
$ lines = explode ("\ n", $ string);
// итерация по строкам
foreach ($ lines as $ line) {
// мы заботимся только о действительных строках def cookie
if ( isset ($ line [0]) && substr_count ($ line, "\ t") == 6) {
// получаем токены в массиве
$ tokens = explode ("\ t ", $ line);
// обрезка токенов
$ tokens = array_map ('trim', $ tokens);
$ cookie = array ();
// Извлечь данные
$ cookie ['domain'] = $ tokens [0];
$ cookie ['flag'] = $ tokens [1];
$ cookie ['путь'] = $ токены [2];
$ cookie ['secure'] = $ tokens [3];
// Преобразование даты в читаемый формат
$ cookie ['expiration'] = date ('Y-m-d h: i: s', $ tokens [4]);
$ cookie ['name'] = $ tokens [5];
$ cookie ['значение'] = $ токены [6];
// Запишите файл cookie.
$ cookie [] = $ cookie;
}
}
вернуть файлы cookie $;
}
Чтобы проверить эту функцию, я использовал следующий код. Он принимает URL-адрес (в данном случае google.com) и настраивает параметры для CURL, чтобы при загрузке страницы также создавался файл cookie. Затем этот файл анализируется с использованием вышеуказанной функции, чтобы узнать, какие файлы cookie в нем присутствуют.
// URL для извлечения файлов cookie из
$ url = 'http://www.google.com/';
// Создайте файл Cookiefar
$ cookiefile = tempnam ("/ tmp", "CURLCOOKIE");
// создать новый ресурс cURL
$ curl = curl_init ();
curl_setopt ($ curl, CURLOPT_RETURNTRANSFER, true);
// Установить пользовательский агент
curl_setopt ($ curl, CURLOPT_USERAGENT, "Mozilla / 5.0 (X11; U; Linux x86_64; en-US; rv: 1.9.1.3) Gecko / 200
Ubuntu / 9.04 (jaunty) Shiretoko / 3.5.3 ");
// установить URL и прочее соответствующие параметры
curl_setopt ($ curl, CURLOPT_URL, $ url);
curl_setopt ($ curl, CURLOPT_HEADER, true);
$ data = curl_exec ($ curl);
// закрыть ресурс cURL и освободить системные ресурсы
curl_close 9 ($
)
// Извлечь и сохранить все найденные файлы cookie
print_r (extractCookies (file_get_contents ($ cookiefile)));
При запуске эта функция производит следующий вывод.
Массив
(
[0] => Массив
(
[домен] => .
- 9000 TRUE)
[путь] => /
[secure] => FALSE
[expiration] => 2013-06-29 10:00:01
[name] => PREF
[значение] => ID = 051f529ee8937fc5: FF = 0: TM = 1309424401: LM = 1309424401: S = 4rhYyPL_bW9KxVHI
)
- Markdown Parser
Это гостевой пост Рэя Вильялобоса.Рэй собирается изучить множество различных разновидностей Markdown. Все они предлагают функции, выходящие за рамки того, что может делать оригинальный Markdown, но они предлагают разные функции между собой. Если вы выбираете версию для использования (или версию, которую вы предлагаете пользователям в своем веб-продукте), стоит знать, во что вы входите, так как сложно переключиться после того, как вы выбрали, и есть контент. это зависит от этих функций. Рэй, у которого есть курс по Markdown, расскажет, в каких версиях есть какие функции, чтобы помочь вам сделать осознанный выбор.
Markdown изменил стиль письма профессионалов во многих областях. Язык использует простой текст с минимальной разметкой и может преобразовывать его во все большее количество форматов. Однако не все парсеры уценки созданы одинаково. Поскольку исходная спецификация не развивалась со временем, альтернативные версии, такие как Multi-Markdown, GFM (Github Flavored Markdown), Markdown Extra и другие, расширили язык.
Первоначальный синтаксический анализатор был написан на Perl. Основные функции включают элементы синтаксического анализа (например, абзацы, разрывы строк, заголовки, цитаты, списки, блоки кода и горизонтальные правила) и элементы диапазона (ссылки, выделение, фрагменты кода и изображения).С тех пор язык не расширялся его создателем Джоном Грубером, поэтому появился ряд дополнений и реализаций с различными синтаксическими анализаторами, добавляющими поддержку различных реализаций по своему усмотрению или интерпретирующими способ анализа определенных элементов.
Выбор версии
Когда вы думаете о внедрении Markdown в проект, нужно многое учитывать, в том числе о языке, на котором вы будете разрабатывать, а также о функциях, которые вы хотите поддерживать. Первоначальная реализация была написана на Perl, но это не практичный вариант для каждого проекта.Существуют реализации на большинстве популярных языков, включая PHP, Ruby и JavaScript. Выбор языка повлияет на то, какие функции вы сможете поддерживать и какие библиотеки будут доступны. Давайте посмотрим на некоторые варианты:
Язык Библиотека (скачать проект) Perl Оригинальная версия JavaScript CommonMark, Marked, Markdown-it, Remarkable, Showdown Рубин Разметка со вкусом Github, Kramdown, Maruku, Redcarpet PHP Cebe Markdown, Ciconia, Parsedown, PHP Markdown Extended Питон Python Markdown Существуют дополнительные реализации на многих других языках, на всякий случай, если вы хотите реализовать Markdown на других языках.
Основные характеристики
Основной язык разметки поддерживает ряд весьма полезных функций по умолчанию. Хотя разные реализации поддерживают ряд расширенных функций, все они должны поддерживать как минимум следующий основной синтаксис: встроенный HTML, автоматические абзацы, заголовки, цитаты, списки, блоки кода, горизонтальные правила, ссылки, выделение, встроенный код и изображения.
Заслуживающие внимания расширения
Поскольку доступно множество версий уценки, некоторые из них существенно повлияли на другие версии.Настолько, что вы часто будете видеть их цитируемые как часть других версий. Например, библиотеки будут упоминать поддержку CommonMark, GFM или Multi-Markdown. Давайте посмотрим, что это значит.
GFM
Одна из причин, по которой Markdown стал настолько популярным среди разработчиков, заключается в том, что Github, платформа обмена с открытым исходным кодом, приняла и расширила язык с помощью версии под названием Github Flavored Markup (GFM), включив в него изолированные кодовые блоки, автоматическое связывание URL-адресов, зачеркивание, таблицы и даже возможность для создания задач в репозиториях.
Поддерживает : изолированные кодовые блоки, выделение синтаксиса, таблицы, автоматическое связывание URL-адресов, задачи, зачеркивание.
CommonMark
Недавно была предпринята попытка стандартизировать уценку. Группа разработчиков Markdown объединилась, чтобы создать версию, тесты и документацию для языка, что привело к более надежной спецификации языка под названием CommonMark. На этот раз реализация добавила изолированные кодовые блоки, но в основном подробно описала особенности реализации определенных функций для согласованного вывода и преобразования.В будущем было предложено гораздо больше расширений, которые приведут это в соответствие с тем, что доступно на других языках.
Этот формат относительно новый и не поддерживает множество функций, но он активно развивается, и есть планы добавить множество функций Multi-Markdown.
Поддерживает : изолированные кодовые блоки, автоматическое связывание URL
Мульти-уценка
Первым серьезным проектом, расширившим язык, стал Multi-Markdown. Он добавил ряд функций к языку, который поддерживается другими версиями.Первоначально он был написан на Perl, как Markdown, но затем перешел на C. Итак, если вы видите, что проект поддерживает Multi-Markdown, то, вероятно, он имеет большинство этих функций.
Поддерживает : изолированные кодовые блоки, выделение синтаксиса, таблицы, метаданные, фрагменты / перекрестные ссылки, ссылки, сноски, зачеркивание, списки определений, математика.
Дополнительные функции
Давайте посмотрим на функции, которые доступны в различных реализациях.
Кодовые блоки с ограждением
Одно из лучших дополнений для разработчиков - это возможность легко добавлять код к вашей уценке.Исходная реализация автоматически рассматривала блок текста как код, если он был с отступом в 4 пробела или одной табуляцией.
'' тело { маржа: 0; отступ: 0; цвет: # 222; цвет фона: белый; семейство шрифтов: без засечек; размер шрифта: 1.8рем; высота строки: 160%; font-weight: 400; } ``Доступно с:
Cebe Markdown, Ciconia, Github Flavored Markdown, Kramdown, Markdown-it, Marked, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Python Markdown, Redcarpet, Remarkable, ShowdownПодсветка синтаксиса
Добавление блоков кода - это замечательно, но по умолчанию интерпретаторы уценки просто обертывают блоки внутри тегов
и, что позволяет отображать текст как предварительно отформатированный текст шрифтом фиксированной ширины.Некоторые реализации могут улучшить это, позволяя вам указывать язык рядом с метками и могут включать синтаксический анализатор, который автоматически позволяет вам выбирать разные цветовые стили и указывать, на каком языке был написан ваш код, чтобы цвета были более значимыми.`` css тело { маржа: 0; отступ: 0; цвет: # 222; цвет фона: белый; семейство шрифтов: без засечек; размер шрифта: 1,8 бэр; высота строки: 160%; font-weight: 400; } ``Доступно с:
Ciconia, Github Flavored Markdown, Kramdown *, Marked, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Python Markdown, Redcarpet, Remarkable, Showdown* Часть этой поддержки не встроена в синтаксический анализатор, но зависит от других библиотек, например, выделения.js.
Столы
Написание таблиц в HTML может быть обременительным. Некоторые версии уценки могут позаботиться об этом, позволяя добавлять таблицы с довольно простым синтаксисом.
Размеры | Мегапикселей --- | --- 1920 x 1080 | 2,1 МП 3264 x 2448 | 8 МП 4 288 x 3 216 | 14 МПРендерит как это:
Размеры Мегапикселей 1,920 x 1080 2.1 МП 3264 x 2448 8 МП 4 288 x 3 216 14 МП Чтобы научиться создавать такие таблицы, потребуется несколько минут, но после того, как вы сделаете это несколько раз, вы подумаете об использовании HTML. Если вам нужна помощь в создании таблиц, ознакомьтесь с этим Генератором таблиц уценки.
Доступно с:
Cebe Markdown, Ciconia, Github Flavored Markdown, Kramdown, Markdown-it, Marked, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Python Markdown, Redcarpet, Remarkable, ShowdownАвтоматическое связывание URL
Это довольно простое расширение позволяет URL-адресам, которые естественным образом встречаются в вашем тексте, преобразовывать в ссылки через синтаксический анализатор.Это действительно удобно и полезно в такой реализации, как GFM, где создание интерактивных URL без дополнительной работы упрощает создание документации.
Доступно с:
Cebe Markdown, Ciconia, CommonMark, Github Flavored Markdown, Kramdown, Markdown-it, Marked, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Python Markdown, Redcarpet, Remarkable, ShowdownФрагменты / ссылки на перекрестные ссылки
С помощью HTML вы можете легко создавать ссылки внутри документа, используя решетку в теге привязки с идентификатором элемента на странице.Некоторые реализации позволяют создать ярлык для этого типа ссылки. Это особенно полезно, потому что позволяет быстро создавать перекрестные ссылки на собственный документ без необходимости писать кучу HTML.
Вы можете указать в документе ссылку на заголовок под названием «myheadline», используя этот [Мой заголовок] []. ## Мой Заголовок Слово «ссылка» рядом с этим будет содержать ссылку, которая ведет через href к заголовку выше.Другими словами, заголовок получает идентификатор, на который указывает ссылка.Доступно с:
Ciconia, Multi-Markdown, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Redcarpet, ShowdownПользовательские идентификаторы в заголовках
Еще одна полезная функция - это возможность иметь идентификаторы в заголовках, чтобы их было легче настраивать с помощью CSS. Некоторые парсеры автоматически помещают идентификаторы во все заголовки (особенно если они поддерживают фрагменты / перекрестные ссылки), поэтому эта функция не всегда необходима.Однако приятно, что в некоторых версиях вы можете настроить, как синтаксический анализатор присваивает имена идентификаторам, что иногда удобнее, чем автоматическое присвоение имен объектам.
### Пользовательские идентификаторы {# custom-id} Заголовок выше при отображении парсером будет иметь собственный идентификатор, который вы укажете в фигурных скобках.Доступен с:
Cebe Markdown, KramdownСноски и другие типы ссылок
Сноски позволяют создавать в документе ссылки на ссылки, которые размещаются внизу страницы уценки.Github Repo] для проекта.
#### Сноски
[Демо] (http://iviewsource.com/exercises/postcsslayouts)
[Репозиторий Github] (https://github.com/planetoftheweb/postcsslayouts)Доступно с:
Cebe Markdown, Kramdown, Markdown-it, Maruku, Multi-Markdown, Parsedown, PHP Markdown Extended, Python Markdown, Redcarpet, Remarkable, Showdown** Примечание **.
Задачи
Это особенность Github Flavored Markdown, которая стала популярной в некоторых реализациях. Он добавляет разметку списка дел, чтобы вы могли создавать флажки рядом с содержимым для имитации списка дел.
- [] Запустите `> npm-install`, чтобы установить зависимости проекта. - [X] Установите gulp.js через терминал Mac или Gitbash на ПК `> npm install -g gulp` - [] Выполните команду Gulp `> gulp`Доступно с:
Ciconia, Github Flavored Markdown, Markdown-it, Marked, Python Markdown, Redcarpet, ShowdownСписки определений
Хотя списки определений не так распространены, как списки других типов, это отличный способ кодирования определенных типов элементов в HTML, некоторые реализации добавляют способ их создания гораздо более простым способом.Есть два способа их определения, в зависимости от языка, с использованием двоеточия (`:`) или тильды (`~`), хотя реализация с двоеточиями более распространена.
ES6 / ES2015 : Новая версия популярного языка JavaScript. Машинопись ~ TypeScript - это язык, который является надмножеством JavaScript, который можно скомпилировать с помощью транспилятора в JavaScript, который будет работать с большинством браузеров.Доступно с:
Kramdown, Markdown-it *, Maruku, Multi-Markdown, PHP Markdown Extended, Python Markdown, Remarkable* требуется расширение
Математика
Возможность создавать математические формулы может быть полезна некоторым пользователям, поэтому язык для их создания появился в некоторых реализациях, таких как Multi-Markdown.
 google.com
google.com 
 Итак, когда в версии упоминается поддержка GFM, ищите эти расширения, которые будут реализованы.
Итак, когда в версии упоминается поддержка GFM, ищите эти расширения, которые будут реализованы.  Иногда это неудобно, поэтому некоторые реализации включали изолированные кодовые блоки, позволяя вам размещать три галочки (`) или, в некоторых случаях, тройную тильду (~) в начале блока текста, чтобы пометить его как код:
Иногда это неудобно, поэтому некоторые реализации включали изолированные кодовые блоки, позволяя вам размещать три галочки (`) или, в некоторых случаях, тройную тильду (~) в начале блока текста, чтобы пометить его как код: 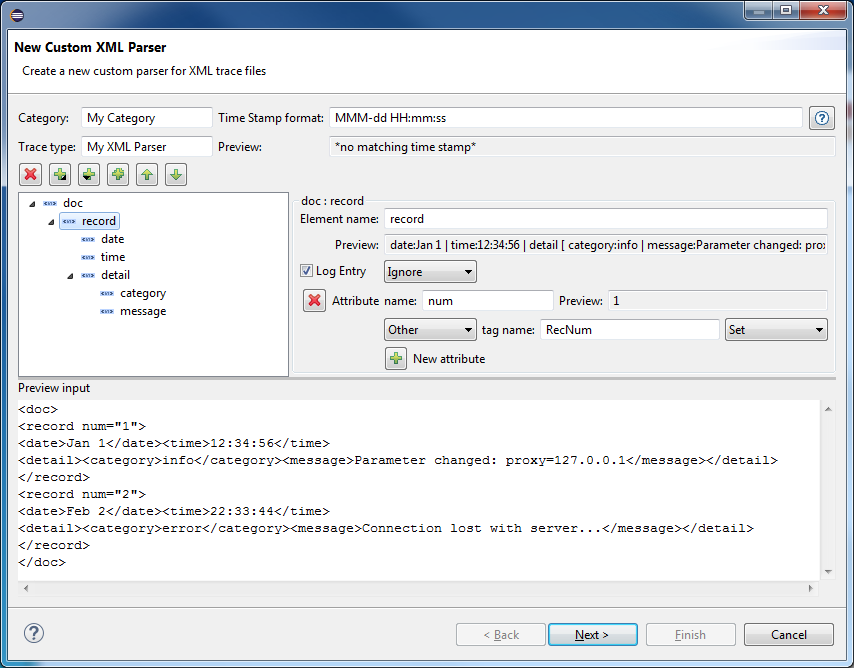
 Эта функция реализована по-разному, поэтому вам действительно нужно внимательно читать документацию для конкретной версии, которую вы будете использовать.
Эта функция реализована по-разному, поэтому вам действительно нужно внимательно читать документацию для конкретной версии, которую вы будете использовать. В парсерах есть много альтернативных методов ссылки, например Multi-Markdown. Их поддержка в отдельных версиях очень неоднородна.Это означает, что даже несмотря на то, что парсер рекламирует совместимость с несколькими уценками, разные парсеры будут реализовывать разные типы ссылок на ссылки. Сюда входят такие вещи, как цитаты, автоматически сгенерированные идентификаторы в заголовках, возможность создавать собственные идентификаторы, перекрестные ссылки и другие. Некоторые парсеры даже изобретают свои собственные особенности ссылок.
В парсерах есть много альтернативных методов ссылки, например Multi-Markdown. Их поддержка в отдельных версиях очень неоднородна.Это означает, что даже несмотря на то, что парсер рекламирует совместимость с несколькими уценками, разные парсеры будут реализовывать разные типы ссылок на ссылки. Сюда входят такие вещи, как цитаты, автоматически сгенерированные идентификаторы в заголовках, возможность создавать собственные идентификаторы, перекрестные ссылки и другие. Некоторые парсеры даже изобретают свои собственные особенности ссылок.
Добавить комментарий