
[0-9]{10}$’
Поделиться
Casimir et Hippolyte
04 июня 2013 в 15:57
Похожие вопросы:
Разбор математического выражения с помощью регулярного выражения
Я хочу разобрать математическое выражение с помощью регулярного выражения. Например, выражение -4-2-1 разбирается на -4, -, 2, — и 1. Однако из моего regex я могу получить только-, 4, -, 2, -, 1 это…
увеличение последней цифры строки с помощью регулярного выражения
как увеличить последнюю цифру строки с помощью регулярного выражения, то есть от 44test1222 до 44test1223 я увеличил его, но как это изменить? мое регулярное выражение в коде JavaScript выглядит…
Можно ли это решить с помощью регулярного выражения?
Я пытаюсь извлечь цифры между словами в этой строке. 110.0046102.005699.0008103.0104…. Я хочу извлечь 4 цифры после точки (point/period). 110.0046 102.0056 99.0008 103.0104 Мне было интересно,…
110.0046 102.0056 99.0008 103.0104 Мне было интересно,…
Как получить все цифры из строки с помощью регулярных выражений ruby
Как получить все цифры из строки предложения типа Lorem 123 ipsum 456 879 => 123456879 с помощью регулярного выражения в ruby?
проверка регулярного выражения с помощью Java
Мне нужно проверить строку с помощью регулярного выражения, строка должна быть похожа на createRobot(x,y), где x и y-цифры. У меня есть что-то вроде String ins; Pattern ptncreate=…
Как обновить табличные значения с помощью регулярного выражения?
Привет, можно ли обновить email и ссылки на веб-сайт с помощью регулярного выражения. в моей мета-таблице wordpress post Я теряю все значения metakey. У меня есть только мета-значения. можно ли…
Как получить числовое значение из строки с помощью регулярного выражения
Как получить числовое значение из следующей строки с помощью регулярного выражения AD . 6547 BNM Результат должен быть таким .6547
6547 BNM Результат должен быть таким .6547
как получить отдельные параметры с помощью регулярного выражения
Вот строка func(abc, def, ghi) , я хочу получить отдельный параметр с помощью регулярного выражения ‘\.*\’ , но это не работает, он будет соответствовать всем аргументам. Как получить отдельный…
получить только целое число из word с помощью регулярного выражения
Я не очень хорошо разбираюсь в регулярных выражениях , поэтому мне нужна ваша помощь в приведенном ниже вводе мне нужно получить с помощью регулярного выражения только целое число в последней скобке…
Получить математические выражения (отдельные буквы, цифры, уравнения…) с помощью regex (в python)
Я новичок в regex и хотел бы сопоставить (в моей python-программе) математические выражения в строке с использованием regex. Математические выражения — это для меня (сейчас) одиночные буквы, цифры и…
Шпаргалка по регулярным выражениям — Exlab
Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка.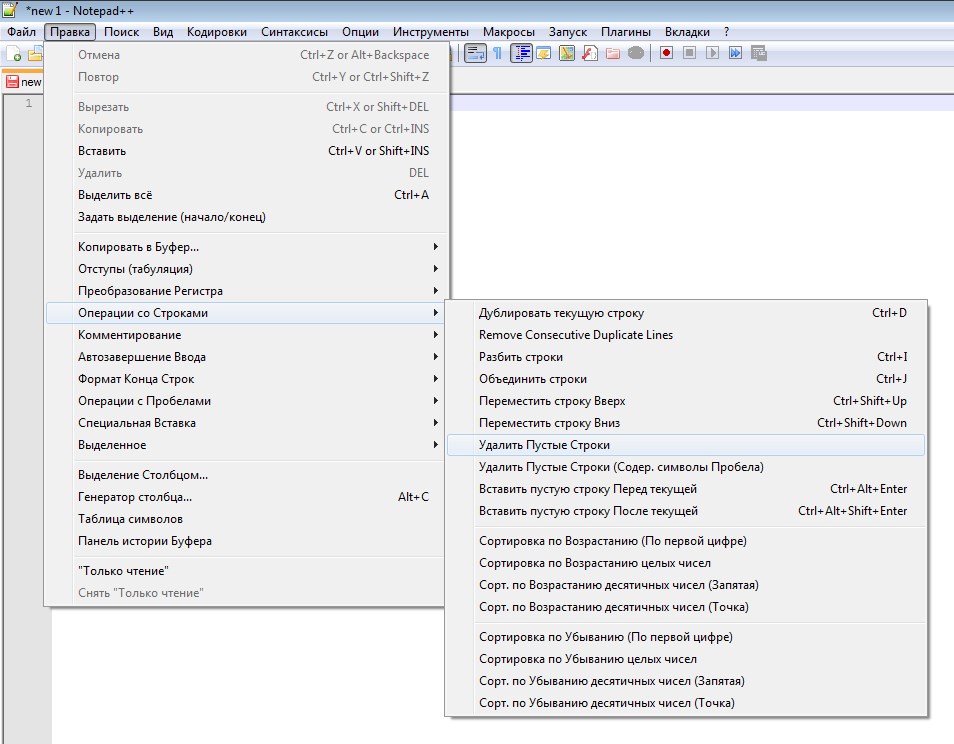 обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \d соответствует любой цифре от 0 до 9 включительно, \w соответствует буквам и цифрам, а \W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
\w\s
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”». \s]*).
\s]*).
Образцы шаблонов
В этой группе представлены образцы шаблонов. С их помощью вы можете увидеть, как можно использовать регулярные выражения в ежедневной практике. Однако заметьте, что они не обязательно будут работать в любом языке программирования, поскольку каждый из них обладает индивидуальными особенностями и различным уровнем поддержки регулярных выражений.
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
a{10,20}
По умолчанию кванторы — «жадные». Поэтому квантор +, означающий «один или больше раз», будет соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
Посмотрите на этот код:
".*"
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
<a href="helloworld.htm" title="Привет, Мир">Привет, Мир</a>
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
"helloworld.htm" title="Привет, Мир"
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
".*?"
Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ?) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности:
"helloworld.htm"
"Привет, Мир"
Специальные символы
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать «
Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать «.» в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования.
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
\.
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования.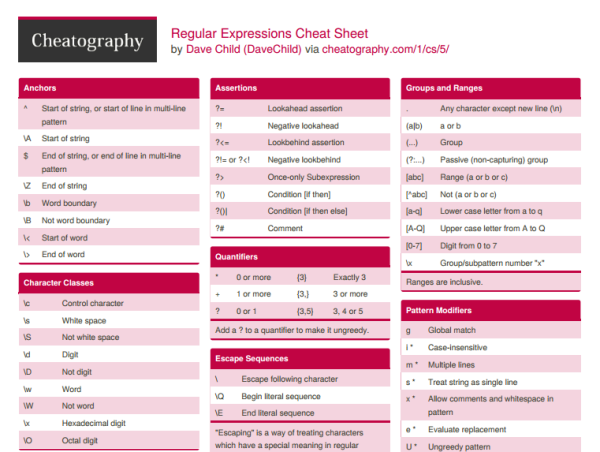 Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
[A-Fa-f0-9]
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
[^A-Fa-f0-9]
Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк.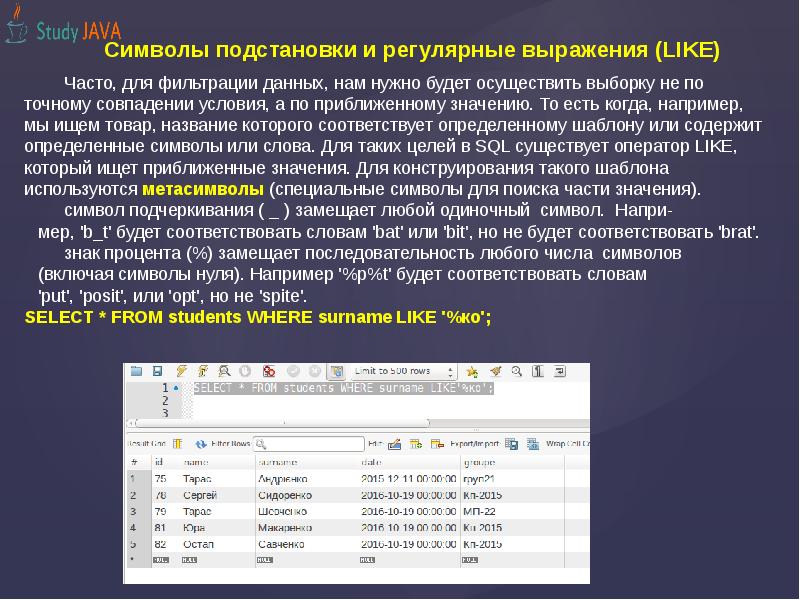
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
(ab|bc)
Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать \n, где вместо n подставить номер нужной группы. Вам может понадобиться шаблон, соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется с помощью групп:
(aaa|bbb)[0-9]+\1
Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более цифр ([0-9]+), и наконец \1. Последняя часть шаблона ссылается на первую группу и ищет то же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1 будет искать «aaa» после числа. A-Za-z0-9])
A-Za-z0-9])
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
$1<b>$2</b>$3
Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1. Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ($3). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или <strong>), выделив им вторую группу, найденную по шаблону ($2).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
Это может быть любой символ (чаще используется «/»), и выглядит все таким образом:
/pattern/
Модификаторы добавляются в конец этой строки, вот так:
/pattern/i
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
\(
Рекомендуем также:
Как мне проверить, является ли значение целым числом в MySQL?
Лучшее, что я мог придумать для переменной, — это int. Это комбинация функций MySQL CAST()и LENGTH().
Этот метод будет работать со строками, целыми числами, типами данных double / float.
SELECT (LENGTH(CAST(<data> AS UNSIGNED))) = (LENGTH(<data>)) AS is_intсм. демонстрацию http://sqlfiddle.com/#!9/ff40cd/44
демонстрацию http://sqlfiddle.com/#!9/ff40cd/44
он завершится неудачно, если в столбце будет однозначное значение. если столбец имеет значение ‘A’, тогда Cast (‘A’ как UNSIGNED) будет оцениваться как 0, а LENGTH (0) будет равно 1. поэтому LENGTH (Cast (‘A’ as UNSIGNED)) = LENGTH (0) будет оцениваться как 1 = 1 => 1
Истинный Вакас Малик совершенно не хочет проверить этот случай. патч есть.
SELECT <data>, (LENGTH(CAST(<data> AS UNSIGNED))) = CASE WHEN CAST(<data> AS UNSIGNED) = 0 THEN CAST(<data> AS UNSIGNED) ELSE (LENGTH(<data>)) END AS is_int;Полученные результаты
**Query #1**
SELECT 1, (LENGTH(CAST(1 AS UNSIGNED))) = CASE WHEN CAST(1 AS UNSIGNED) = 0 THEN CAST(1 AS UNSIGNED) ELSE (LENGTH(1)) END AS is_int;
| 1 | is_int |
| --- | ------ |
| 1 | 1 |
---
**Query #2**
SELECT 1.1, (LENGTH(CAST(1 AS UNSIGNED))) = CASE WHEN CAST(1. 1 AS UNSIGNED) = 0 THEN CAST(1.1 AS UNSIGNED) ELSE (LENGTH(1.1)) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #3**
SELECT "1", (LENGTH(CAST("1" AS UNSIGNED))) = CASE WHEN CAST("1" AS UNSIGNED) = 0 THEN CAST("1" AS UNSIGNED) ELSE (LENGTH("1")) END AS is_int;
| 1 | is_int |
| --- | ------ |
| 1 | 1 |
---
**Query #4**
SELECT "1.1", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1.1" AS UNSIGNED) = 0 THEN CAST("1.1" AS UNSIGNED) ELSE (LENGTH("1.1")) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #5**
SELECT "1a", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1a" AS UNSIGNED) = 0 THEN CAST("1a" AS UNSIGNED) ELSE (LENGTH("1a")) END AS is_int;
| 1a | is_int |
| --- | ------ |
| 1a | 0 |
---
**Query #6**
SELECT "1.1a", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("1.1a" AS UNSIGNED) = 0 THEN CAST("1.1a" AS UNSIGNED) ELSE (LENGTH("1.1a")) END AS is_int;
| 1.1a | is_int |
| ---- | ------ |
| 1. 1a | 0 |
---
**Query #7**
SELECT "a1", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("a1" AS UNSIGNED) = 0 THEN CAST("a1" AS UNSIGNED) ELSE (LENGTH("a1")) END AS is_int;
| a1 | is_int |
| --- | ------ |
| a1 | 0 |
---
**Query #8**
SELECT "a1.1", (LENGTH(CAST("a1.1" AS UNSIGNED))) = CASE WHEN CAST("a1.1" AS UNSIGNED) = 0 THEN CAST("a1.1" AS UNSIGNED) ELSE (LENGTH("a1.1")) END AS is_int;
| a1.1 | is_int |
| ---- | ------ |
| a1.1 | 0 |
---
**Query #9**
SELECT "a", (LENGTH(CAST("a" AS UNSIGNED))) = CASE WHEN CAST("a" AS UNSIGNED) = 0 THEN CAST("a" AS UNSIGNED) ELSE (LENGTH("a")) END AS is_int;
| a | is_int |
| --- | ------ |
| a | 0 |
1 AS UNSIGNED) = 0 THEN CAST(1.1 AS UNSIGNED) ELSE (LENGTH(1.1)) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #3**
SELECT "1", (LENGTH(CAST("1" AS UNSIGNED))) = CASE WHEN CAST("1" AS UNSIGNED) = 0 THEN CAST("1" AS UNSIGNED) ELSE (LENGTH("1")) END AS is_int;
| 1 | is_int |
| --- | ------ |
| 1 | 1 |
---
**Query #4**
SELECT "1.1", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1.1" AS UNSIGNED) = 0 THEN CAST("1.1" AS UNSIGNED) ELSE (LENGTH("1.1")) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #5**
SELECT "1a", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1a" AS UNSIGNED) = 0 THEN CAST("1a" AS UNSIGNED) ELSE (LENGTH("1a")) END AS is_int;
| 1a | is_int |
| --- | ------ |
| 1a | 0 |
---
**Query #6**
SELECT "1.1a", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("1.1a" AS UNSIGNED) = 0 THEN CAST("1.1a" AS UNSIGNED) ELSE (LENGTH("1.1a")) END AS is_int;
| 1.1a | is_int |
| ---- | ------ |
| 1. 1a | 0 |
---
**Query #7**
SELECT "a1", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("a1" AS UNSIGNED) = 0 THEN CAST("a1" AS UNSIGNED) ELSE (LENGTH("a1")) END AS is_int;
| a1 | is_int |
| --- | ------ |
| a1 | 0 |
---
**Query #8**
SELECT "a1.1", (LENGTH(CAST("a1.1" AS UNSIGNED))) = CASE WHEN CAST("a1.1" AS UNSIGNED) = 0 THEN CAST("a1.1" AS UNSIGNED) ELSE (LENGTH("a1.1")) END AS is_int;
| a1.1 | is_int |
| ---- | ------ |
| a1.1 | 0 |
---
**Query #9**
SELECT "a", (LENGTH(CAST("a" AS UNSIGNED))) = CASE WHEN CAST("a" AS UNSIGNED) = 0 THEN CAST("a" AS UNSIGNED) ELSE (LENGTH("a")) END AS is_int;
| a | is_int |
| --- | ------ |
| a | 0 | 1 AS UNSIGNED) = 0 THEN CAST(1.1 AS UNSIGNED) ELSE (LENGTH(1.1)) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #3**
SELECT "1", (LENGTH(CAST("1" AS UNSIGNED))) = CASE WHEN CAST("1" AS UNSIGNED) = 0 THEN CAST("1" AS UNSIGNED) ELSE (LENGTH("1")) END AS is_int;
| 1 | is_int |
| --- | ------ |
| 1 | 1 |
---
**Query #4**
SELECT "1.1", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1.1" AS UNSIGNED) = 0 THEN CAST("1.1" AS UNSIGNED) ELSE (LENGTH("1.1")) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #5**
SELECT "1a", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1a" AS UNSIGNED) = 0 THEN CAST("1a" AS UNSIGNED) ELSE (LENGTH("1a")) END AS is_int;
| 1a | is_int |
| --- | ------ |
| 1a | 0 |
---
**Query #6**
SELECT "1.1a", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("1.1a" AS UNSIGNED) = 0 THEN CAST("1.1a" AS UNSIGNED) ELSE (LENGTH("1.1a")) END AS is_int;
| 1.1a | is_int |
| ---- | ------ |
| 1.
1 AS UNSIGNED) = 0 THEN CAST(1.1 AS UNSIGNED) ELSE (LENGTH(1.1)) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #3**
SELECT "1", (LENGTH(CAST("1" AS UNSIGNED))) = CASE WHEN CAST("1" AS UNSIGNED) = 0 THEN CAST("1" AS UNSIGNED) ELSE (LENGTH("1")) END AS is_int;
| 1 | is_int |
| --- | ------ |
| 1 | 1 |
---
**Query #4**
SELECT "1.1", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1.1" AS UNSIGNED) = 0 THEN CAST("1.1" AS UNSIGNED) ELSE (LENGTH("1.1")) END AS is_int;
| 1.1 | is_int |
| --- | ------ |
| 1.1 | 0 |
---
**Query #5**
SELECT "1a", (LENGTH(CAST("1.1" AS UNSIGNED))) = CASE WHEN CAST("1a" AS UNSIGNED) = 0 THEN CAST("1a" AS UNSIGNED) ELSE (LENGTH("1a")) END AS is_int;
| 1a | is_int |
| --- | ------ |
| 1a | 0 |
---
**Query #6**
SELECT "1.1a", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("1.1a" AS UNSIGNED) = 0 THEN CAST("1.1a" AS UNSIGNED) ELSE (LENGTH("1.1a")) END AS is_int;
| 1.1a | is_int |
| ---- | ------ |
| 1. 1a | 0 |
---
**Query #7**
SELECT "a1", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("a1" AS UNSIGNED) = 0 THEN CAST("a1" AS UNSIGNED) ELSE (LENGTH("a1")) END AS is_int;
| a1 | is_int |
| --- | ------ |
| a1 | 0 |
---
**Query #8**
SELECT "a1.1", (LENGTH(CAST("a1.1" AS UNSIGNED))) = CASE WHEN CAST("a1.1" AS UNSIGNED) = 0 THEN CAST("a1.1" AS UNSIGNED) ELSE (LENGTH("a1.1")) END AS is_int;
| a1.1 | is_int |
| ---- | ------ |
| a1.1 | 0 |
---
**Query #9**
SELECT "a", (LENGTH(CAST("a" AS UNSIGNED))) = CASE WHEN CAST("a" AS UNSIGNED) = 0 THEN CAST("a" AS UNSIGNED) ELSE (LENGTH("a")) END AS is_int;
| a | is_int |
| --- | ------ |
| a | 0 |
1a | 0 |
---
**Query #7**
SELECT "a1", (LENGTH(CAST("1.1a" AS UNSIGNED))) = CASE WHEN CAST("a1" AS UNSIGNED) = 0 THEN CAST("a1" AS UNSIGNED) ELSE (LENGTH("a1")) END AS is_int;
| a1 | is_int |
| --- | ------ |
| a1 | 0 |
---
**Query #8**
SELECT "a1.1", (LENGTH(CAST("a1.1" AS UNSIGNED))) = CASE WHEN CAST("a1.1" AS UNSIGNED) = 0 THEN CAST("a1.1" AS UNSIGNED) ELSE (LENGTH("a1.1")) END AS is_int;
| a1.1 | is_int |
| ---- | ------ |
| a1.1 | 0 |
---
**Query #9**
SELECT "a", (LENGTH(CAST("a" AS UNSIGNED))) = CASE WHEN CAST("a" AS UNSIGNED) = 0 THEN CAST("a" AS UNSIGNED) ELSE (LENGTH("a")) END AS is_int;
| a | is_int |
| --- | ------ |
| a | 0 |см. демонстрацию
Регулярные выражения Oracle (regular expression)
Регулярные выражения произошли из теорий автоматов и формальных языков, поэтому поначалу производят устрашающее впечатление. Однако, их базовые понятия являются простыми и в то же время мощными. xyz соответсвует только строке, начинающейся с «xyz» — другие вхождения не учитываются)
xyz соответсвует только строке, начинающейся с «xyz» — другие вхождения не учитываются)
Оператор REGEXP_LIKE
REGEXP_LIKE(исходная_строка, шаблон[, параметр_сопоставления])
| исходная_строка | поддерживает символьные типы данных (CHAR, VARCHAR2, CLOB, NCHAR, NVARCHAR2 и NCLOB, но не LONG) |
| шаблон | это другое название регулярного выражения |
| параметр_сопоставления | позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра |
Используется подобно оператору like в части where или же при определении ограничения на таблицу (constraint) .
Пример использования регулярных выражений:
Функция REGEXP_INSTR
REGEXP_INSTR(исходная_строка, шаблон[, начальная_позиция [, вхождение [, опция_возврата [, параметр_сопоставления ] ] ] ] )
| исходная_строка | поддерживает символьные типы данных (CHAR, VARCHAR2, CLOB, NCHAR, NVARCHAR2 и NCLOB, но не LONG) |
| шаблон | регулярное выражение |
| начальная_позиция | позиция, с которой должен начинаться поиск |
| вхождение | по умолчанию имеет значение 1, если пользователь не укажет поиск последовательных вхождений |
| опция_возврата | значение по умолчанию 0, тогда возвратится начальная позиция шаблона; при значении 1 возвращается позиция символа, следующего за шаблоном |
| параметр_сопоставления | позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра |
Функция возвращает позицию символа, находящегосяв начале или конце соответствия для шаблона, так же как и ее аналог instr.
В отличие от instr, функция regexp_instr работает с начала строки и двигается вперед в поисках шаблона. Она не может начать с конца строки и перемещаться в обратном направлении.
Функция REGEXP_SUBSTR
REGEXP_SUBSTR(исходная_строка, шаблон[, позиция [, вхождение [,параметр_сопоставления]]])
| исходная_строка | поддерживает символьные типы данных (CHAR, VARCHAR2, CLOB, NCHAR, NVARCHAR2 и NCLOB, но не LONG) |
| шаблон | регулярное выражение |
| позиция | позиция, с которой необходимо начинать поиск |
| вхождение | по умолчанию имеет значение 1 |
| параметр_сопоставления | позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра |
Функция REGEXP_SUBSTR возвращает подстроку, которая соответствует шаблону.
Пример использования регулярных выражений:
Функция REGEXP_REPLACE
REGEXP_REPLACE(исходная_строка, шаблон [, строка_замены [, позиция[,вхождение, [параметр_сопоставления]]]])
| исходная_строка | поддерживает символьные типы данных (CHAR, VARCHAR2, CLOB, NCHAR, NVARCHAR2 и NCLOB, но не LONG) |
| шаблон | регулярное выражение |
| шаблон замены | текст для замены каждого вхождения |
| позиция | позиция, с которой необходимо начинать поиск |
| вхождение | по умолчанию имеет значение 1 |
| параметр_сопоставления | позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра |
REGEXP_REPLACE возвращает измененную входную строку, в которой все вхождения шаблона заменены значением, переданным в параметре строка_замены. привет» соответствует «привет, как дела», но не «как дела, привет»
привет» соответствует «привет, как дела», но не «как дела, привет»
Таблица 2: Квантификаторы и операторы повтора
| Квантификатор | Описание | Пример |
| * | Встречается 0 и более раз | REGEXP_REPLACE(str, ’11*’, ‘1’) Результат: test11 => test1 11123345 => 123345 |
| ? | Встречается 0 или 1 раз | |
| + | Встречается 1 и более раз | REGEXP_LIKE(str,’5+’) Результат: test11 => false 11123345 => true |
| {m} | Встречается ровно m раз | REGEXP_LIKE(str,’3{2}’) Результат: test11 => false 11123345 => true |
| {m,} | Встречается по крайней мере m раз | |
| {m, n} | Встречается по крайней мере m раз, но не более n раз |
Таблица 3: Предопределенные символьные классы POSIX
| Класс символов | Описание |
. | Любой символ |
| [:alpha:] | Буквы |
| [:lower:] | Буквы в нижнем регистре |
| [:upper:] | Буквы в верхнем регистре |
| [:digit:] | Цифры |
| [:alnum:] | Буквы и цифры |
| [:space:] | Пробелы (не печатаемые символы), такие как перевод каретки, новая строка, вертикальная табуляция и подача страницы |
| [:punct:] | Знаки препинания |
| [:cntrl:] | Управляющие символы (не печатаемые) |
| [:print:] | Печатаемые символы |
Таблица 4: Альтернативное сопоставление и группировка выражений
| Метасимвол | Описание | |
| | | Альтернатива | Разделяет альтернативные варианты, часто используется с оператором группировки () |
| ( ) | Группа | Группирует подвыражения для альтернативы, квантификатора или ссылочности |
| [char] | Список символов | Обозначает список символов; большинство метасимволов в списке символов представляют собой литеры, за исключением символьных классов и метасимволов ^ и — |
| [^char] | Список символов | Список символов, которые не должны присутствовать в строке |
Таблица 5: Метасимвол ссылки
| Метасимвол | Описание | |
| \digit | Обратная косая черта | За ней следует цифра от 1 до 9, обратная косая черта связана с предыдущим сопоставлением с соответствующим номером заключенного в скобки подвыражения. (Заметьте: Обратная косая черта может иметь другое значение в регулярном выражении; в зависимости от контекста она может означать также символ Escape |

Более полную информацию можно прочитать здесь Using Regular Expressions in Oracle Database
Похожие записи:
Regex для чисел и диапазона номеров (с примерами) — Regex Tutorial
Из этой статьи вы узнаете, как сопоставить числа и диапазон чисел в регулярных выражениях. Диапазон чисел Regex включает соответствие от 0 до 9, от 1 до 9, от 0 до 10, от 1 до 10, от 1 до 12, от 1 до 16 и 1-31, 1-32, 0-99, 0-100, 1-100, 1-127, 0-255, 0-999, 1-999, 1-1000 и 1-9999.
Первое, что нужно помнить о регулярных выражениях, это то, что
они не знают чисел, они не умеют считать и не умеют
Понимать 1-100 означает любое число от 1 до 100.Причина в регулярном выражении
работает только с текстом, а не с числами, поэтому вам нужно немного
осторожность при работе с числами и диапазонами номеров или числовыми диапазонами в
регулярное выражение, операции поиска, проверки или замены.
Если вы хотите изучить регулярное выражение для чисел и любой диапазон чисел с логикой и простыми и практическими примерами, я предлагаю вам ознакомиться с этим простым и точным курсом регулярных выражений с пошаговым подходом. Этот видеокурс научит вас логике и философии регулярных выражений для различных диапазонов чисел.
Только на
Например, допустим, если вы хотите сопоставить любое число от 1 до 100, и вы
напишите для него регулярное выражение как
/ [1-100]
/
и
надеюсь, что он будет соответствовать всем числам от 1 до 100, тогда ваше регулярное выражение
будет работать, но даст неожиданный результат. Это регулярное выражение будет соответствовать только двум
числа, да, всего два числа и в этом нет никаких сомнений. Вы можете представить
какие два числа? Если вы посмотрите на это, вы узнаете, что это
будет соответствовать только 0 и 1 и ничего больше.Аналогично диапазон
[0-255] будет соответствовать 0,1,2,5. Во-первых, это диапазон 0-2, который находится в
класс символов будет соответствовать 0,1,2 и 5, записанным два раза, будет соответствовать 5.
Теперь давайте приступим к логике и философии сопоставления чисел и числа.
диапазоны в регулярных выражениях.
Числа в регулярном выражении
Самый простой
совпадение чисел — буквальное совпадение. Если вы хотите сопоставить 3, просто напишите
/ 3 /
или если вы хотите сопоставить 99, напишите / 99 / и он будет успешным
соответствие. Аналогично для соответствия 2019 напишите / 2019 / и это число
буквальное совпадение.Но вы можете видеть, что это не гибко, так как это очень сложно.
чтобы знать о конкретном числе в тексте или число может встречаться в
диапазоны.
\ d для
однозначные или многозначные числа
Для соответствия любому
числа от 0 до 9 мы используем \ d в регулярном выражении. Он будет соответствовать любой отдельной цифре
число от 0 до 9.
\ д
означает [0-9] или соответствует любому числу от 0 до 9.
Вместо того
запись 0123456789 сокращенная версия [0-9], где [] используется для
диапазон символов.
[1-9] [0-9]
будет соответствовать двузначному числу от 10 до 99.
Но если вы
хотите сопоставить любое количество цифр, например 2,55,235, 9875 a
квантификатор добавлен в конец
/ \ d + /
где + — квантификатор, который соответствует одному
и как можно больше раз.
Две или три цифры
совпадение чисел
Кому
соответствует двузначному числу / \ d {2} / используется, где {} — это
квантификатор и 2 означает совпадение два раза или просто двузначное число.
Аналогично / \ d {3} / используется для сопоставления трехзначного числа, и поэтому
на.
Соответствие регулярному выражению для диапазона чисел
Сейчас
о числовых диапазонах и их кодах регулярных выражений со смыслом.$ Символы используются для начала или конца
нить.
Регулярное выражение для диапазона 0-9
Соответствовать
числовой диапазон 0-9, то есть любое число от 0 до 9, регулярное выражение простое
/ [0-9] /
Регулярное выражение от 1 до 9
Для соответствия любому
число от 1 до 9, регулярное выражение простое
/ [1-9] /
Подобно тебе
можно использовать / [3-7] / для соответствия любому числу от 3 до 7 или / [2-5] / для соответствия
2,3,4,5
Regex
от 0 до 10
Кому
числа от 0 до 10 — это начало небольшого осложнения, а не
так много, но используется другой подход. Эта серия разбита на
Эта серия разбита на
к двум компонентам.
1. от 0 до 9
2. 10
И регулярное выражение
будет написано для компонентов
/ \ b ([0-9] | 10) \ b /
Пояснение:
Для двоих
комплектующих пишем две штуки
1. от 0 до
9 [0-9] и
2.
10 10 и мы используем группу и используем
|
оператор, который называется оператором ИЛИ, что означает либо 0-9
или 10
здесь.
Regex для 1 до
10
Аналогично для
От 1 до 10 регулярное выражение будет
\ b ([1-9] | 10) \ b
Regex
с 1 по 12
\ b ([1-9] | 1 [0-2]) \ b
Ассортимент
от 1 до 12 делится на два диапазона
1.От 1 до 9
-> [1-9]
2. 10–12
-> 1 [0-2]
Regex для 1
к 16
\ b ([1-9] | 1 [0-6]) \ b
В этом случае
диапазон делится на
1. 1 до 9
2. 10–16
Regex
для диапазона номеров 1-31
\ b ([1-9] | [12] [0-9] | 3 [01]) \ b
Здесь диапазон 1-31
делится на три компонента по требованию
1. 1–9 -> [0–9]
2. 10–29 ->
[12] [0-9]
3.С 30 по 31 ->
3 [01]
Regex
для 1-32
Регулярное выражение для
От 1 до 32 — это
\ b ([1-9] | [12] [0-9] | 3 [0-2]) \ b
1. 1–9 -> [0–9]
2. 10–29 ->
[12] [0-9]
3. 30 до 32 ->
3 [02]
Regex для
0-99
Обычный
выражение для диапазона от 0 до 99 —
\ b ([0-9] | [1-9] [0-9]) \ b
Это диапазон
разделены на два диапазона
1. от 0 до 9
-> [0-9]
2. 10–99
-> [1-9] [0-9]
Regex для
0–100
Regex для
диапазон от 0 до 100 —
\ b ([0-9] | [1-9] [0-9] | 100) \ b
Здесь
Ассортимент разделен на три компонента, а дополнительный компонент
тогда предыдущий диапазон равен 100.
Regex
для 1-100
Обычный
выражение для этого диапазона —
\ b ([1-9] | [1-9] [0-9] | 100) \ b
1. Первая
компонент от 1 до 9
2. Второй
часть от 10 до 99
3. Третья часть — 100
Regex для
1-127
Regex для
диапазон от 1 до 127 —
\ b ([1-9] | [1-9] [0-9] | 1 [01] [0-9] | 12 [0-7]) \ b
Числовой
диапазон от 1 до 127 делится на
1. 1 до 9
2. 10 до 99
3. 100 до 119
4. 120–127
Regex
для 0-255
Это диапазон
также разделен на три части.
1. 0-199
Регулярное выражение для
этот компонент
[01]? [0-9] [0-9]?
2. Второй
часть 200-249 и регулярное выражение для этой части
2 [0-4] [0-9]
3. Наконец
последняя часть — 250-255
25 [0-5]
Полный
регулярное выражение
/ \ b ([01]? [0-9] [0-9]? | 2 [0-4] [0-9] | 25 [0-5])
Подробнее
подробности см. в регулярном выражении
для ip-адреса
Regex
для 0-999
([0-9] | [1-9] [0-9] | [1-9] [0-9] [0-9])
Регулярное выражение для
диапазон от 0 до 999 разделен на три части,
1.От 0 до 9
2. 10 до 99
3. 100 до 999
Regex
для 1-999
Обычный
выражение для 1-999 —
([1-9] | [1-9] [0-9] | [1-9] [0-9] [0-9])
Regex
для диапазона номеров 1-1000
Код регулярного выражения для соответствия диапазону от 1
до 1000 —
([1-9] | [1-9] [0-9] | [1-9] [0-9] [0-9] | 1000)
Regex
для 1-9999
Regex для
диапазон от 1 до 9999 —
([1-9] | [1-9] [0-9] | [1-9] [0-9] [0-9] | [1-9] [0-9] [0-9] [0-9])
| Классы символов | |
|---|---|
| .abc $ | начало / конец строки |
| \ b | граница слова |
| Экранированные символы | |
| \. \ * \\ | экранированные специальные символы |
| \ t \ n \ r | табуляция, перевод строки, возврат каретки |
| \ u00A9 | экранирование юникода © |
| Группы и поиск | |
| (abc) | группа захвата |
| \ 1 | обратная ссылка на группу № 1 |
| (?: Abc) | группа без захвата |
| (? = Abc) | положительный прогноз |
| (?! Abc) | негативный прогноз |
| Квантификаторы и чередование | |
| а * а + а? | 0 или более, 1 или более, 0 или 1 |
| а {5} а {2,} | ровно пять, два или больше |
| a {1,3} | между одним и тремя |
| а +? а {2,}? | совпадений как можно меньше |
| ab | cd | соответствует ab или cd |
Сопоставление с образцом с регулярными выражениями
Вы хотите выполнить сопоставление с образцом
а не буквальное сравнение.
Используйте оператор REGEXP и регулярное выражение
шаблон, описанный в этом разделе. Или используйте шаблон SQL, описанный
в рецепте 4.7.
SQL-шаблонов (см. Рецепт 4.7), скорее всего, будут
реализованы другими системами баз данных, поэтому они
разумно переносимый за пределы MySQL. С другой стороны,
они несколько ограничены. Например, вы можете
легко написать шаблон SQL % abc% для поиска строк
которые содержат abc , но вы не можете написать ни одного
Шаблон SQL для идентификации строк, содержащих любой из символов
a , b или c .Вы также не можете сопоставить содержимое строки на основе типов символов, таких как
буквы или цифры. Для таких операций MySQL поддерживает другой тип
операции сопоставления с образцом на основе регулярных выражений и
оператор REGEXP (или
НЕ REGEXP , чтобы перевернуть
смысл матча). [] REGEXP
сопоставление использует другой набор элементов шаблона, чем
% и _ (ни один из
в регулярных выражениях):
Образец | Какому шаблону соответствует |
|---|---|
| Начало строки |
| Конец строки |
| Любой символ, не указанный в квадратных скобках |
| Чередование; соответствует любому из шаблонов |
| Ноль или более экземпляров предыдущего элемента |
| Один или несколько экземпляров предыдущего элемента |
| |
| |
Возможно, вы уже знакомы с этим шаблоном регулярного выражения
символов, потому что многие из них такие же, как и используемые
vi , grep ,
sed и другие утилиты Unix, поддерживающие обычные
выражения…pp ‘;
+ ——— +
| имя |
+ ——— +
| медь |
+ ——— +
Кроме того, регулярные выражения имеют другие возможности и могут
выполнять такие виды совпадений, которые не могут быть выполнены с помощью шаблонов SQL. Например,
регулярные выражения могут содержать классы символов, соответствующие любому
персонаж в классе:
Чтобы написать класс символов, перечислите символы, которые должен класс
совпадать в квадратных скобках. Таким образом, узор
[abc]соответствует либоa,
bилиc.0-9] соответствует чему угодно, кроме цифр.
MySQL, обычный
Возможности выражения также поддерживают классы символов POSIX. Эти
соответствуют определенным наборам символов, как описано в следующей таблице.
Класс POSIX | Какому классу соответствует |
|---|---|
| Буквенные и цифровые символы |
| Буквенные символы |
| Пробел (символы пробела или табуляции) |
| Управляющие символы |
| цифр |
| Графические (непустые) символы |
| Буквенные символы в нижнем регистре |
| Графические символы или пробелы |
| Знаки препинания |
| Пробел, табуляция, новая строка, возврат каретки |
| Буквенные символы в верхнем регистре |
| шестнадцатеричных цифр ( |
Классы POSIX предназначены для использования внутри классов символов, поэтому вы
используйте их в квадратных скобках.Следующее выражение соответствует
значения, содержащие любой символ шестнадцатеричной цифры:
mysql> ВЫБЕРИТЕ имя, имя REGEXP '[[: xdigit:]]' FROM metal;
+ ---------- + ---------------------------- +
| имя | name REGEXP '[[: xdigit:]]' |
+ ---------- + ---------------------------- +
| медь | 1 |
| золото | 1 |
| железо | 0 |
| свинец | 1 |
| ртуть | 1 |
| платина | 1 |
| серебро | 1 |
| олово | 0 |
+ ---------- + ---------------------------- + Регулярные выражения могут содержать чередования.Синтаксис выглядит как
это:
альтернатива1|альтернатива2| ...
альтернатива
похож на символьный класс в том смысле, что он соответствует, если есть
альтернатив совпадают. Но в отличие от класса персонажей,
альтернативы не ограничиваются одиночными символами — они могут быть
струны или даже узоры. Например, следующее чередование
соответствует строкам, которые начинаются с гласной или заканчиваются на
er :
mysql> ВЫБЕРИТЕ имя ИЗ металла ГДЕ имя REGEXP '^ [aeiou] | er $';
+ -------- +
| имя |
+ -------- +
| медь |
| железо |
| серебро |
+ -------- + Для группировки чередований можно использовать круглые скобки..* b. * $ ‘
Регулярные выражения не соответствуют значениям NULL . Этот
верно как для REGEXP , так и для
НЕ REGEXP :
mysql> ВЫБЕРИТЕ NULL REGEXP '. *', NULL NOT REGEXP '. *';
+ ------------------ + ---------------------- +
| NULL REGEXP '. *' | NULL NOT REGEXP '. *' |
+ ------------------ + ---------------------- +
| NULL | NULL |
+ ------------------ + ---------------------- + Дело в том, что обычный выражение соответствует строке, если шаблон
найти где-нибудь в строке означает, что вы должны позаботиться о том, чтобы
непреднамеренно указать шаблон, соответствующий пустой строке.если ты
do, он вообще будет соответствовать любому значению , отличному от NULL. Для
Например, шаблон a * соответствует любому количеству
символа, даже ни одного. Если ваша цель - соответствовать
только строки, содержащие непустые последовательности a
символов, используйте вместо них a + . В
+ требует одного или нескольких экземпляров предыдущего
элемент шаблона для совпадения.
Как и в случае сопоставления шаблонов SQL, выполняемого с использованием LIKE ,
совпадения регулярных выражений выполняются с REGEXP
иногда эквивалентны сравнениям подстрок.[0-9] + '
Это то, что LEFT () не может сделать (и
как и , как , если на то пошло).
Только числа в регулярном выражении (регулярное выражение) - WiseTut
Числа могут быть сопоставлены или найдены с помощью шаблонов регулярных выражений. Регулярное выражение может быть выражено без символа или буквы и содержит только числа. Это регулярное выражение может использоваться только для чисел на разных платформах или языках программирования, таких как C #, Java, JavaScript и т. Д. Regex - это общий язык выражений, в котором разные текстовые шаблоны могут быть выражены по-разному.
Совпадение номеров по одному
\ d используется для выражения одного числа в регулярном выражении. Число может быть любым числом, которое является единственным числом. \ D можно использовать для сопоставления одного числа.
\ d
В качестве альтернативы можно использовать [0-9] для сопоставления одного числа в регулярном выражении. [0-9] означает, что от 0 до 9 может совпадать одно число. В этом случае буквы не могут совпадать.
[0-9]
Группа номеров совпадений
Группа номеров также может быть сопоставлена с регулярным выражением.[0-9] + долларов США
Сопоставление числовых диапазонов с регулярным выражением
Поскольку регулярные выражения имеют дело с текстом, а не с числами, сопоставление числа в заданном диапазоне требует немного дополнительной осторожности. Вы не можете просто написать [0-255], чтобы соответствовать числу от 0 до 255. Хотя регулярное выражение является допустимым, оно соответствует чему-то совершенно другому. [0-255] - это класс символов с тремя элементами: диапазон символов 0-2, символ 5 и символ 5 (снова). Этот класс символов соответствует одной цифре 0, 1, 2 или 5, как и [0125].
Поскольку регулярные выражения работают с текстом, обработчик регулярных выражений обрабатывает 0 как один символ и 255 как три символа. Чтобы соответствовать всем символам от 0 до 255, нам понадобится регулярное выражение, которое соответствует от одного до трех символов.
Регулярное выражение [0-9] соответствует однозначным числам от 0 до 9. [1-9] [0-9] соответствует двузначным числам от 10 до 99. Это простая часть.
Сопоставление трехзначных чисел немного сложнее, поскольку нам нужно исключить числа с 256 по 999.1 [0-9] [0-9] принимает значения от 100 до 199. 2 [0-4] [0-9] соответствует 200–249. Наконец, 25 [0-5] добавляет 250 до 255.
Как вы можете видеть, что вам нужно разделить числовой диапазон на диапазоны с одинаковым количеством цифр и каждый из тех диапазонов, которые допускают одинаковые вариации для каждой цифры. В трехзначном диапазоне в нашем примере числа, начинающиеся с 1, позволяют использовать все 10 цифр для следующих двух цифр, а числа, начинающиеся с 2, ограничивают количество цифр, которым разрешено следовать.
Соединяя все это вместе с помощью чередования, получаем: [0-9] | [1-9] [0-9] | 1 [0-9] [0-9] | 2 [0-4] [0-9] ] | 25 [0-5].Это соответствует нужным нам числам, с одной оговоркой: поиск по регулярным выражениям обычно допускает частичные совпадения, поэтому наше регулярное выражение будет соответствовать 123 в 12345. Есть два решения этой проблемы.
Поиск числовых диапазонов
Если вы ищете эти числа в более крупном документе или строке ввода, используйте границы слов, чтобы требовать, чтобы перед и после любого допустимого совпадения был не-словесный символ (или вообще не было символа). Затем регулярное выражение становится \ b ([0-9] | [1-9] [0-9] | 1 [0-9] [0-9] | 2 [0-4] [0-9] | 25 [ 0-5]) \ b.Поскольку у оператора альтернативы самый низкий приоритет из всех, скобки необходимы для группировки альтернатив. Таким образом, механизм регулярных выражений попытается сопоставить границу первого слова, затем попробует все альтернативы, а затем попытается сопоставить границу второго слова после совпавших чисел. Механизмы регулярных выражений рассматривают все буквенно-цифровые символы, а также подчеркивание, как символы слова.
Проверка числовых диапазонов
Если вы используете регулярное выражение для проверки ввода, вы, вероятно, захотите проверить, что все вводимые данные состоят из действительного числа.([012]? [0-9]? [0-9] | 3 [0-5] [0-9] | 36 [0-6]) $
Сделать пожертвование
Этот сайт только что сохранил вы путешествуете в книжный магазин? Сделайте пожертвование в поддержку этого сайта, и вы получите неограниченного доступа к этому сайту без рекламы!
Учебник по регулярным выражениям => Сопоставление различных чисел
Пример
[a-b] , где a и b - цифры в диапазоне от 0 до 9
[3-7] будет соответствовать одной цифре в диапазоне от 3 до 7. Соответствие нескольких цифр
\ d \ d будет соответствовать 2 последовательным цифрам
\ d + соответствует 1 или более цифрам подряд
\ d * будет соответствовать 0 или более последовательных цифр
\ d {3} будет соответствовать 3 цифрам подряд
\ d {3,6} будет соответствовать от 3 до 6 последовательных цифр
\ d {3,} будет соответствовать 3 или более последовательных цифрам
\ d в приведенных выше примерах можно заменить диапазоном номеров:
[3-7] [3-7] будет соответствовать двум последовательным цифрам, которые находятся в диапазоне от 3 до 7.
[3-7] + соответствует 1 или нескольким последовательным цифрам, которые находятся в диапазоне от 3 до 7.
[3-7] * будет соответствовать 0 или более последовательных цифр в диапазоне от 3 до 7.
[3-7] {3} будет соответствовать 3 последовательным цифрам в диапазоне от 3 до 7.
[3-7] {3,6} будет соответствовать от 3 до 6 последовательных цифр в диапазоне от 3 до 7.
[3-7] {3,} будет соответствовать 3 или более последовательных цифрам, которые находятся в диапазоне от 3 до 7.
Вы также можете выбрать конкретные цифры:
[13579] будет соответствовать только "нечетным" цифрам
[02468] будет соответствовать только "четным" цифрам
1 | 3 | 5 | 7 | 9 другой способ сопоставления «нечетных» цифр - | символ означает ИЛИ
Соответствующие числа в диапазонах, которые содержат более одной цифры:
\ d | 10 соответствует 0-10 однозначному значению ИЛИ 10.| символ означает ИЛИ
[1-9] | 10 соответствует цифрам от 1 до 10 в диапазоне от 1 до 9 ИЛИ 10
[1-9] | 1 [0-5] соответствует цифрам от 1 до 15 в диапазоне от 1 до 9 ИЛИ 1, за которым следует цифра от 1 до 5.
\ d {1,2} | 100 соответствует от 0 до 100 от одной до двух цифр ИЛИ 100
Соответствующие числа, которые делятся на другие числа:
\ d * 0 соответствует любому числу, которое делится на 10 - любому числу, оканчивающемуся на 0
\ d * 00 соответствует любому числу, которое делится на 100 - любому числу, оканчивающемуся на 00
\ d * [05] соответствует любому числу, которое делится на 5 - любому числу, оканчивающемуся на 0 или 5
\ d * [02468] соответствует любому числу, которое делится на 2 - любому числу, оканчивающемуся на 0,2,4,6 или 8
совпадающих чисел, которые делятся на 4 - любое число, равное 0, 4 или 8 или заканчивающееся на 00, 04, 08, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52, 56, 60, 64, 68, 72, 76, 80, 84, 88, 92 или 96
[048] | \ d * (00 | 04 | 08 | 12 | 16 | 20 | 24 | 28 | 32 | 36 | 40 | 44 | 48 | 52 | 56 | 60 | 64 | 68 | 72 | 76 | 80 | 84 | 88 | 92 | 96)
Это можно сократить.Например, вместо 20 | 24 | 28 мы можем использовать 2 [048] . Кроме того, поскольку 40-е, 60-е и 80-е имеют одинаковый узор, мы можем включить их: [02468] [048] , а остальные тоже имеют узор [13579] [26] . Таким образом, всю последовательность можно сократить до:
[048] | \ d * ([02468] [048] | [13579] [26]) - числа, делящиеся на 4
Сопоставление чисел, которые не имеют шаблона, подобного тем, которые делятся на 2,4,5,10 и т. Д., Не всегда может быть выполнено лаконично, и вам обычно приходится прибегать к диапазону чисел.Например, сопоставление всех чисел, которые делятся на 7 в диапазоне от 1 до 50, может быть выполнено простым перечислением всех этих чисел:
7 | 14 | 21 | 28 | 35 | 42 | 49
или ты мог бы сделать это так
7 | 14 | 2 [18] | 35 | 4 [29]
Как извлечь адреса электронной почты, номера телефонов и ссылки из текста
У вас есть электронное письмо или письмо с номерами телефонов, адресами электронной почты или ссылками на веб-сайты по всему тексту - и вы хотите получить список каждого из эти предметы сами по себе.Копирование и вставка утомительна и отнимает много времени, но разве компьютеры не предназначены для выполнения подобных задач за нас?
Они есть. Все, что вам нужно, это немного кода Regex или регулярного выражения и текстовый редактор, и вы можете вытащить данные, которые вы хотите, из своего текста, чтобы вставить в другое приложение. Или, если вы хотите автоматически извлекать текст из любого из нескольких сотен приложений для отправки в другое приложение, вы также можете сделать это с помощью Formatter от Zapier. Вот как использовать Regex в популярных текстовых редакторах или Formatter в популярных веб-приложениях.
Как извлечь текст с помощью Regex
Скрипты Regex выглядят как длинные строки случайного текста, но они могут быть самым эффективным способом найти любой текст, который вам нужен
Вы, вероятно, знакомы со встроенным в большинство приложения на вашем компьютере. Нажмите Control + F или Command + F , введите слово, которое вы хотите найти, и приложение будет выделяться каждый раз, когда это слово появляется в вашем тексте. Например, если вы ищете число «47» в предложении «Я купил 47 яблок», инструмент Find вашей программы выделит в этом предложении число 47 .
Что, если вместо этого вы захотите найти в тексте любое число? Возможно, теперь в вашем предложении говорится: «Я купил 47 яблок и 23 яйца», и вам нужен список чисел. Regex - или REGular EXpressions - вот что вы будете использовать. Regex позволяет указать компьютеру, какой тип типа текста вы ищете, используя собственный синтаксис. Допустим, мы хотим найти любое число. Мы бы выполнили поиск по регулярному выражению для [0-9] - это будет искать все, что содержит хотя бы одну цифру (цифры от 0 до 9).Хотите найти любой номер или на букву «а»? [0-9] | подойдет, поскольку регулярное выражение использует канал | означает или .
Итак, если вы ищете адреса электронной почты, вы можете просто выполнить поиск по запросу @ с помощью обычного инструмента Найти , чтобы выделить каждый адрес электронной почты, а также все, что включает символ @, хотя есть несколько вещей, кроме адресов электронной почты. делать. Однако подробный скрипт регулярного выражения может быть лучше. Он может найти все символы вокруг символа «@» и выбрать полный адрес электронной почты.А затем с помощью инструментов популярных текстовых редакторов вы можете скопировать каждый адрес электронной почты из своего текста.
Хотите узнать больше о Regex? Статья Regex Wikipedia хорошо объясняет основной синтаксис, а Regex Tester (на фото выше) и RegExr - отличные способы научиться использовать регулярное выражение с всплывающими окнами, которые объясняют, что скрипты делают, когда вы их пишете.
Regex - это странно, но на самом деле им легко пользоваться, поскольку в популярных приложениях есть инструменты регулярных выражений, а также готовые сценарии регулярных выражений.Сначала давайте проверим несколько быстрых сценариев регулярных выражений для извлечения ссылок, электронных писем и номеров телефонов, а затем узнаем, как использовать регулярное выражение в популярных программах редактирования текста Sublime Text, Notepad ++ и BBEdit:
Сценарии регулярных выражений для извлечения данных
Перед извлечением text в ваших приложениях, вам понадобится несколько скриптов регулярных выражений. _ `{|} ~ -] + (?: \._` {|} ~ -] +) * | "(?: [\ x01- \ x08 \ x0b \ x0c \ x0e- \ x1f \ x21 \ x23- \ x5b \ x5d- \ x7f] | \\ [\ x01 - \ x09 \ x0b \ x0c \ x0e- \ x7f]) * ") @ (?: (?: [a-z0-9] (?: [a-z0-9 -] * [a-z0-9] )? \.) + [a-z0-9] (?: [a-z0-9 -] * [a-z0-9])? | \ [(? 🙁 ?: 25 [0-5] | 2 [0-4] [0-9] | [01]? [0-9] [0-9]?) \.) {3} (?: 25 [0-5] | 2 [0-4] [0-9] | [01]? [0-9] [0-9]? | [A-z0-9 -] * [a-z0-9]: (?: [\ X01- \ x08 \ x0b \ x0c \ x0e- \ x1f \ x21- \ x5a \ x53- \ x7f] | \\ [\ x01- \ x09 \ x0b \ x0c \ x0e- \ x7f]) +) \])
Работает со всеми стандартные адреса электронной почты, субдомены и TLD - при условии, что в адресе электронной почты и домене используются стандартные английские символы.
Извлечение номеров телефонов ( изменено на основе сценария из Переполнение стека )
(?: (?: +? ([1-9] | [0-9] | [ 0-9] [0-9]) \ s (?: [.-] \ s )?)? (?: (\ S ( [2-9] 1 [02-9] ] | [02-8] 1 | [02-8] [02-9] ) \ s ) | ([1-9] | [0-9] 1 [02-9] | [ 02-8] 1 | [02-8] [02-9])) \ s (?: [.-] \ s )?)? ([2-9] 1 [02-9] | [02-9] 1 | [02-9] {2}) \ s (?: [.-] \ s )? ([0-9] {4}) (?: \ S (?: # | X.? | Ext.? | Extension) \ s (\ d +))?
Работает со всеми стандартными телефонными номерами, включая коды страны и города для большинства международных номеров. Все от +65 800123 4567 доб.405 до 02-201-1222 до 865.101.1000 и больше должно работать.
Просто используйте эти сценарии Regex в инструменте Find вашего текстового редактора, и они должны найти все ссылки, электронные письма и номера телефонов в вашем тексте.Затем выполните описанные выше действия, чтобы скопировать каждый из них в отдельный список.
Хотите еще скриптов регулярных выражений? RegExLib включает в себя широкий спектр готовых сценариев регулярных выражений, по которым вы можете выполнять поиск - и если вы не найдете то, что вам нужно, часто результаты поиска Google будут содержать нужные сценарии регулярных выражений.
Теперь давайте узнаем, как использовать регулярное выражение в Sublime Text, Notepad ++, BBEdit и Google Sheets:
Как использовать регулярное выражение в Sublime Text (Windows, Mac, Linux)
Функция поиска регулярного выражения в Sublime Text
Cross -платформенный текстовый редактор Sublime Text - один из самых простых способов извлечения текста с помощью регулярного выражения с помощью встроенного инструмента Find all .
В текстовом документе, из которого вы хотите извлечь определенный текст, нажмите Control + F или Command + F , чтобы открыть панель поиска. Щелкните значок * справа, чтобы включить режим регулярного выражения, затем введите или вставьте свой сценарий регулярного выражения. Теперь нажмите Найти все , и Sublime Text выделит и выберет все найденные экземпляры текста.
А вот и ссылки на наши извлеченные веб-сайты.
Хотите извлечь этот текст и поместить его в отдельный список? Просто нажмите Control + F или Command + F еще раз, затем создайте новый документ и вставьте свои результаты в список всех извлеченных вами вещей.
Sublime Text Цена: Бесплатная оценка; 70 долларов за пользовательскую лицензию
Как использовать регулярное выражение в Notepad ++ (Windows)
В Notepad ++ вы будете использовать функцию Replace, чтобы поместить каждый результат в отдельную строку
Бесплатный текстовый редактор Windows Notepad ++ имеет параметр регулярного выражения в его Find инструмент, но он не позволяет копировать текст так же, как это делает Sublime Text. Вместо этого мы будем использовать его, чтобы поместить каждый результат в отдельную строку, пометить эти строки закладками, а затем скопировать эти строки с закладками сами по себе.
Вот как это работает. Просто введите или вставьте текст в Блокнот ++ и нажмите Control + F , чтобы открыть инструмент поиска. Щелкните вкладку Replace , затем введите или вставьте сценарий регулярного выражения в поле Find what: . Под ним введите следующее в поле Заменить на: , чтобы поместить каждый результат в отдельную строку:
\ n \ 1 \ n
Теперь щелкните маркер Регулярное выражение в нижнем левом углу , затем нажмите кнопку Заменить все .Это должно привести к тому, что каждый из ваших результатов поиска по регулярному выражению будет в отдельной строке.
Чтобы скопировать только результатов регулярного выражения, вам нужно сделать еще две вещи. Сначала щелкните поле Mark в окне поиска, выберите строку Bookmark в параметрах и нажмите Mark All . Это поставит красную метку рядом с каждой строкой с вашими результатами регулярного выражения.
Наконец, щелкните меню поиска и выберите Закладка -> Копировать строки с закладками .Откройте новый документ и вставьте текст, и у вас будет список только текста, который вы хотели найти с помощью регулярного выражения.
Notepad ++ Цена: Бесплатная загрузка с открытым исходным кодом
Как использовать регулярное выражение в BBEdit (Mac)
Используйте опцию «Извлечь» в BBEdit, чтобы скопировать результаты регулярного выражения в новый документ.
Возможно, самый простой способ извлечь текст с помощью regex использует текстовый редактор Mac BBEdit. Просто введите текст в Regex, нажмите Command + F , чтобы открыть окно Find , и введите сценарий регулярного выражения в поле Find .Отметьте опцию Grep внизу страницы, чтобы запустить скрипт регулярного выражения (который в BBEdit питается от терминального приложения Grep , это еще один способ извлечения текста с помощью регулярного выражения).
Теперь нажмите кнопку Extract справа, и BBEdit создаст новый текстовый файл и добавит каждый из извлеченных вами элементов в документ. Это самый быстрый способ извлечь текст с помощью регулярного выражения.
BBEdit Цена: Бесплатная ознакомительная версия; Лицензия $ 49,99 на пользователя
Как использовать регулярное выражение в Google Таблицах (Интернет)
Если вам нужен только один результат регулярного выражения, функция Google Sheet ' = regextract позволяет вам использовать регулярное выражение внутри вашей электронной таблицы, чтобы найти первый результат соответствия.Просто введите = regextract (, затем введите текст, по которому нужно выполнить поиск, или выберите правильную ячейку, добавьте запятую, затем введите сценарий регулярного выражения в кавычках и добавьте закрывающую скобку в конце. Google Таблицы затем извлекут первое совпадение из вашего текста - и если ваш скрипт регулярного выражения включает в себя такие разделы, как изображенный скрипт, который проверяет каждую часть телефонного номера, Google Sheets разделит результат на одну ячейку для каждого раздела.
То же самое работает в Google Документы, хотя нет простого способа скопировать все результаты.Нажмите Control + F или Command + F , чтобы открыть диалоговое окно поиска, коснитесь значка с тремя точками, чтобы открыть диалоговое окно полного поиска, добавьте сценарий регулярного выражения в диалоговое окно Find и проверьте соответствие используя регулярные выражения box. Это позволит вам найти каждый элемент, соответствующий вашему запросу регулярного выражения, хотя вам придется вручную скопировать каждый результат, чтобы извлечь их из документа.
Google Таблицы и Документы Цена: Бесплатно для личного пользования; от 5 долларов в месяц G Suite Basic для использования в бизнесе
Извлечение адресов электронной почты, номеров телефонов и ссылок в Интернете
ConvertCSV может извлекать ваш текст в Интернете
Хотите что-то попроще? Существует ряд простых веб-приложений, которые могут извлекать нужный текст с помощью нескольких щелчков мышью.Самым универсальным из протестированных нами приложений является ConvertCSV.com. Он может извлекать адреса электронной почты, ссылки и номера телефонов, хотя не распознает столько вариаций, сколько приведенные выше сценарии регулярных выражений. И, если вам нужно, он может конвертировать ваши файлы электронных таблиц в разные форматы.
Вот некоторые из лучших бесплатных простых инструментов для извлечения текста в Интернете:
Автоматическое извлечение адресов электронной почты, номеров телефонов и ссылок с помощью Zapier
Zapier Formatter может автоматически извлекать электронные письма, ссылки и номера в любое время, когда в ваш Программы.
Regex отлично работает, когда у вас есть длинный документ с электронными письмами, ссылками и числами, и вам нужно извлечь их все. Но гораздо чаще вам нужно извлекать текст из одного объекта и использовать его непосредственно в другом приложении.
Например, предположим, что кто-то отправил вам электронное письмо со ссылкой, и вы хотите автоматически добавить эту ссылку в Pocket, чтобы вы могли прочитать ее позже. Или, возможно, вы сохранили свою контактную информацию в заметках Evernote и хотите извлечь адрес электронной почты и отправить автоматическое электронное письмо своим новым контактам.
Инструмент форматирования Zapier может помочь. Zapier - это инструмент автоматизации приложений, который объединяет более 750 приложений, поэтому всякий раз, когда что-то происходит в одном приложении, Zapier может запускать цепную реакцию, копируя ваш текст в другие приложения, чтобы добавлять контакты, запускать проекты, отправлять электронные письма и т. Д. И форматтер Zapier может, среди прочего, извлекать текст, чтобы вы получали именно то, что хотите, от своих приложений.
Вот как это работает. Сначала вы создадите новый Zap и выберите приложение, которое вы хотите запустить - или запустить - рабочий процесс.Мы выберем Gmail здесь, чтобы следить за ссылками в новых письмах.
Затем добавьте шаг форматирования и выберите действие Text . Выберите преобразование Extract URL , чтобы найти ссылку в электронном письме, нажмите кнопку + рядом с полем Input и выберите поле Body Plain , чтобы Zapier нашел ссылку в тексте электронного письма. Протестируйте этот шаг, и Zapier найдет эту первую ссылку в теле письма.
Хотите вместо этого узнать адрес электронной почты, номер телефона или отдельный номер, например цену? Просто выберите преобразование Extract Email Address , Extract Phone Number или Extract Number , чтобы найти эти элементы в вашем тексте.
Наконец, добавьте приложение действия в свой Zap. Здесь мы выберем Pocket. Выберите Save for Later , затем нажмите кнопку + рядом с полем URL и выберите ссылку на этапе Formatter.
Вуаля ! Теперь, когда вы получите электронное письмо со ссылкой, Zapier автоматически добавит его в ваш список чтения Pocket.
Вот готовый Zap, чтобы попробовать его с Gmail и Ontraport. Formatter Zapier может разделить имя отправителя на два поля и отправить адрес электронной почты для создания нового контакта в Ontraport:
Хотите использовать свои собственные запросы Regex в Zapier? Вы также можете сделать это с помощью шагов кода Zapier.Вот как это сделать ..
Теперь приступайте к созданию собственной автоматизации. Инструменты извлечения Zapier Formatter - это мощный способ найти в тексте то, что вам нужно, и затем использовать его в других приложениях. Если вам нужно скопировать контактную информацию, финансовые данные, ссылки на веб-сайты и т. Д., Formatter может помочь - автоматически и мгновенно.
Или, если вы хотите извлечь текст оптом на единовременной основе, регулярное выражение - ваш лучший новый друг.
У вас есть любимый скрипт регулярных выражений для извлечения текста? Мы будем рады услышать об этом в комментариях ниже!
Больше возможностей с Zapier Formatter
Хотите автоматизировать работу с текстом? Ознакомьтесь с другими руководствами из этой серии, чтобы узнать о других способах использования Formatter, а также с полезными советами для других приложений, которые вы, возможно, уже используете:
.
Добавить комментарий