
Как я html-парсер на php писал, и что из этого вышло. Вводная часть / Хабр
Привет.
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Это самый простой список того, что должен уметь парсер. По-хорошему, он еще должен отправлять информацию об ошибках, если таковые были найдены в исходном документе.
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
- Отделение обычного текста от тегов
- Сортировка всех полученных тегов в dom дерево
Это что касается непосредственно парсинга документа. Про поиск элементов я буду говорить чуть позже далее в этой главе.
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего «<» идет тег, а не текст? Об этом я расскажу в следующих частях. Пока что этого вполне хватит.
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
[0] => Array
(
[is_closing] =>
[is_singleton] =>
[pointer] => 215
[tag] => div
[0] => Array //открывается подмассив
(
[0] => Array
(
[is_closing] =>
[is_singleton] =>
[pointer] => 238
[tag] => div
[id] => Array
(
[0] => tjojo
)
[0] => Array //открывается подмассив
(
[0] => Array //Текст записывается в виде отдельного тега
(
[tag] => __TEXT
[0] => Привет!
)
[1] => Array
(
[is_closing] => 1
[is_singleton] =>
[pointer] => 268
[tag] => div
)
)
)
)
)
Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ «>» не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>». - Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.<tag some =><!--И что там написано? А никто не знает, как и парсер--> - Ошибка html синтаксиса
Данная ошибка возникает в двух случаях: Либо у атрибута тега в названии есть «<«, либо если знак «=» ставится дважды, хотя значение еще не было передано.<tag some = ='something'><!--Случайная ошибка, с кем не бывает--> <tag <some ='something'><!--И что это? Тег там, где должен быть атрибут? Непорядок--> - Слишком много открывающих тегов
Данная ошибка часто встречается на сайтах, и говорит она о том, что открывающих тегов больше, чем закрывающих.<div> <div id = ='wefwe'> Привет! </div> <!--И куда делся </div>?-->
Данная ошибка не является критической и будет решаться парсером. - Слишком много закрывающих тегов
То же самое, что и прошлая ошибка, только наоборот.<div id = ='wefwe'> Привет! </div> </div><!--И что ты собрался закрывать?-->
Данная ошибка также не является критической. - Children элемент не найден
В этом случаи парсер просто будет выводить пустой массив.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
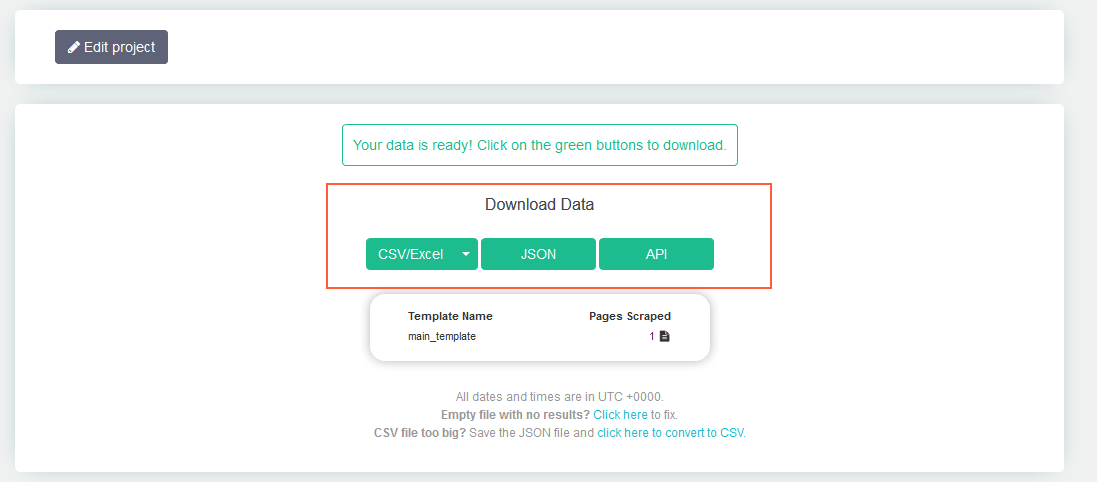
Парсинг любого сайта «для чайников»: ни строчки программного кода
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он вообще нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Что такое парсинг
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот самый сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться некие услуги от компаний, они стоят относительно дорого и называется это так: «мы напишем вам парсер». То есть «мы создадим некую программу либо на Python, либо на каком-то еще языке, которая будет собирать эту информацию с нужного вам сайта». Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ пользуетесь, но просто не знаете, что в ней такой функционал есть. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, какие-то коды, теги и все-все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать — сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
Вот у нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег <span> с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке. Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос?
Мы идем в один из парсеров. В данном случае я воспользуюсь программой Screaming Frog Seo Spider.
Она бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных мета-тегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. И напоминаю, что мы хотели с сайта (в данном случае с сайта Московский дом мебели) собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем еще назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять?
Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить вообще по всему сайту, по всем разделам. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Что с этим делать дальше. Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен у нас в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все-все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без всяких там пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
Вот у нас теперь связка такая: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе. Единственное, что нужно всегда помнить, что h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в эксель адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти самые фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде пишутся свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии.
Давайте попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А там, где у нас карточки товаров — собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — у него характеристик много.
Вы хотите собрать в эксель все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по данной характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> у нас содержится название характеристики и ее значение.
Значит, нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog. Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Я покажу на одном примере — загружу один URL. Начнем с того, что посмотрим, где они лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки, перед тем как будет делаться скриншот — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание. При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
Итак, пожалуйста, мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span с значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
- Любую информацию с почти любого сайта. Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно таки сложно. Но большинство сайтов можно спарсить.
- Цены, наличие товаров, любые характеристики, фото, 3D-фото.
- Описание, отзывы, структуру сайта.
- Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения:
- Использовать VPN.
- В настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча
Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти.
Такое ограничение можно обойти, но это долго и дорого.
***
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
Осваиваем парсинг сайта: короткий туториал на Python
Постоянно в Интернете, ничего не успеваете? Парсинг сайта спешит на помощь! Разбираемся, как автоматизировать получение нужной информации.
Чтобы быть в курсе, кто получит кубок мира в 2019 году, или как будет выглядеть будущее страны в ближайшие 5 лет, приходится постоянно зависать в Интернете. Но если вы не хотите тратить много времени на Интернет и жаждете оставаться в курсе всех событий, то эта статья для вас. Итак, не теряя времени, начнём!
Доступ к новейшей информации получаем двумя способами. Первый – с помощью API, который предоставляют медиа-сайты, а второй – с помощью парсинга сайтов (Web Scraping).
Использование API предельно просто, и, вероятно, лучший способ получения обновлённой информации – вызвать соответствующий программный интерфейс. Но, к сожалению, не все сайты предоставляют общедоступные API. Таким образом, остаётся другой путь – парсинг сайтов.
Парсинг сайта
Это метод извлечения информации с веб-сайтов. Эта методика преимущественно фокусируется на преобразовании неструктурированных данных – в формате HTML – в Интернете в структурированные данные: базы данных или электронные таблицы. Парсинг сайта включает в себя доступ к Интернету напрямую через HTTP или через веб-браузер. В этой статье будем использовать Python, чтобы создать бот для получения контента.
Последовательность действий
- Получить URL страницы, с которой хотим извлечь данные.
- Скопировать или загрузить HTML-содержимое страницы.
- Распарсить HTML-содержимое и получить необходимые данные.
Эта последовательность помогает пройти по URL-адресу нужной страницы, получить HTML-содержимое и проанализировать необходимые данные. Но иногда требуется сперва войти на сайт, а затем перейти по конкретному адресу, чтобы получить данные. В этом случае добавляется ещё один шаг для входа на сайт.
Пакеты
Для анализа HTML-содержимого и получения необходимых данных используется библиотека Beautiful Soup. Это удивительный пакет Python для парсинга документов формата HTML и XML.
Для входа на веб-сайт, перехода к нужному URL-адресу в рамках одного сеанса и загрузки HTML-содержимого будем использовать библиотеку Selenium. Selenium Python помогает при нажатии на кнопки, вводе контента и других манипуляциях.
Погружение в код
Сначала импортируем библиотеки, которые будем использовать:
# импорт библиотек from selenium import webdriver from bs4 import BeautifulSoup
Затем укажем драйверу браузера путь к Selenium, чтобы запустить наш веб-браузер (Google Chrome). И если не хотим, чтобы наш бот отображал графический интерфейс браузера, добавим опцию headless в Selenium.
Браузеры без графического интерфейса (headless) предоставляют автоматизированное управление веб-страницей в среде, аналогичной популярным веб-браузерам, но выполняются через интерфейс командной строки или с использованием сетевых коммуникаций.
# путь к драйверу chrome
chromedriver = '/usr/local/bin/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument('headless') # для открытия headless-браузера
browser = webdriver.Chrome(executable_path=chromedriver, chrome_options=options)После настройки среды путём определения браузера и установки библиотек приступаем к HTML. Перейдём на страницу входа и найдём идентификатор, класс или имя полей для ввода адреса электронной почты, пароля и кнопки отправки, чтобы ввести данные в структуру страницы.
# Переход на страницу входа
browser.get('http://playsports365.com/default.aspx')
# Поиск тегов по имени
email = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_UserName')
password = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_Password')
login = browser.find_element_by_name('ctl00$MainContent$ctlLogin$BtnSubmit')Затем отправим учётные данные в эти HTML-теги, нажав кнопку «Отправить», чтобы ввести информацию в структуру страницы.
# добавление учётных данных для входа
email.send_keys('********')
password.send_keys('*******')
# нажатие на кнопку отправки
login.click()После успешного входа в систему перейдём на нужную страницу и получим HTML-содержимое страницы.
# После успешного входа в систему переходим на страницу «OpenBets»
browser.get('http://playsports365.com/wager/OpenBets.aspx')
# Получение HTML-содержимого
requiredHtml = browser.page_sourceКогда получили HTML-содержимое, единственное, что остаётся, – парсинг. Распарсим содержимое с помощью библиотек Beautiful Soup и html5lib.
html5lib – это пакет Python, который реализует алгоритм парсинга HTML5, на который сильно влияют современные браузеры. Как только получили нормализованную структуру содержимого, становится доступным поиск данных в любом дочернем элементе тега html. Искомые данные присутствуют в теге table, поэтому ищем этот тег.
soup = BeautifulSoup(requiredHtml, 'html5lib')
table = soup.findChildren('table')
my_table = table[0]Один раз находим родительский тег, а затем рекурсивно проходим по дочерним элементам и печатаем значения.
# получение тегов и печать значений
rows = my_table.findChildren(['th', 'tr'])
for row in rows:
cells = row.findChildren('td')
for cell in cells:
value = cell.text
print (value)Чтобы выполнить указанную программу, установите библиотеки Selenium, Beautiful Soup и html5lib с помощью pip. После установки библиотек команда #python <program name> выведет значения в консоль.
Так парсятся данные с любого сайта.
Если же парсим веб-сайт, который часто обновляет контент, например, результаты спортивных соревнований или текущие результаты выборов, целесообразно создать задание cron для запуска этой программы через конкретные интервалы времени.
Используете парсинг сайта?
Для вывода результатов необязательно ограничиваться консолью, правда?
Как вы предпочитаете отображать данные подобных программ: выводить на панель уведомлений, отправлять на почту или иначе? Делитесь полезными находками 🙂
Надеемся, вам понравилась статья.
Оригинал
5 инструментов для автоматизированного парсинга сайта
1. Что такое парсинг сайтов2. Зачем и когда используют парсинг3. Как парсить данные с помощью различных сервисов и инструментов
4. Законно ли парсить чужие сайты
Подводим итоги
В работе специалистов сферы информационных технологий часто возникает задача собрать какую-либо информацию с сайтов, например необходимо провести парсинг товаров с сайта конкурента. И она априори не может быть лёгкой.
Поэтому для автоматизированного и упрощённого извлечения и группировки данных был придуман парсинг.
В этом посте я собрала информацию о том, что это, как работает и для чего нужно, а также поделюсь методами и инструментами, с которыми парсинг станет для вас не такой сложной задачей.
1. Что такое парсинг сайтов
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов в несколько этапов:
- Построение запроса для получения первоначальной информации.
- Извлечение информации согласно прописанному алгоритму.
- Формирование и структурирование информации.
- Сохранение полученных данных.
Чтоб извлекались только определённые данные, в программе задаётся специальный язык поиска, который описывает шаблоны строк — регулярное выражение. Регулярное выражение основано на использовании набора определённых символов, которые описывают информацию, нужную для поиска. Подробнее о работе с регулярными выражениями вы можете узнать на посвящённом им сайте.
Инструменты для парсинга называются парсерами — это боты, запрограммированные на отсеивание баз данных и извлечение информации.
Чаще всего парсеры настраиваются для:
- распознавания уникального HTML;
- извлечения и преобразования контента;
- хранения очищенных данных;
- извлечения из API.
2. Зачем и когда используют парсинг
Зачастую парсинг используется для таких целей:
- Поиск контактной информации. Парсинг помогает собирать почту, номера телефонов с разных сайтов и соцсетей.
- Проверка текстов на уникальность.
- Отслеживание цен и ассортимент товаров-конкурентов.
- Проведение маркетинговых исследований, например, для мониторинга цен конкурентов для работы с ценообразованием своих товаров.
- Превращение сайтов в API. Это удобно, когда нужно работать с данными сайтов без API и требуется создать его для них.
- Мониторинг информации с целью поддержания её актуальности. Часто используется в областях, где быстро меняется информация (прогноз погоды, курсы валют).
- Копирование материалов с других сайтов и размещение его на своём (часто используется на сайтах-сателлитах).
Выше перечислены самые распространённые примеры использования парсинга. На самом деле их может быть столько, сколько хватит вашей фантазии.
3. Как парсить данные с помощью различных сервисов и инструментов
Способов парсить данные сайтов, к счастью, создано великое множество: платных и бесплатных, сложных и простых.
Предлагаю ознакомиться с представителями разных типов и разобрать, как работает каждый.
Google Spreadsheet
С помощью функций в таблицах Google можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим самые популярные и полезные функции и их применение.
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
=IMPORTHTML(«ссылка на страницу»; запрос «table» или «list»; порядковый номер таблицы/списка)
Пример использования
Нужно выгрузить табличные данные со страницы сайта.
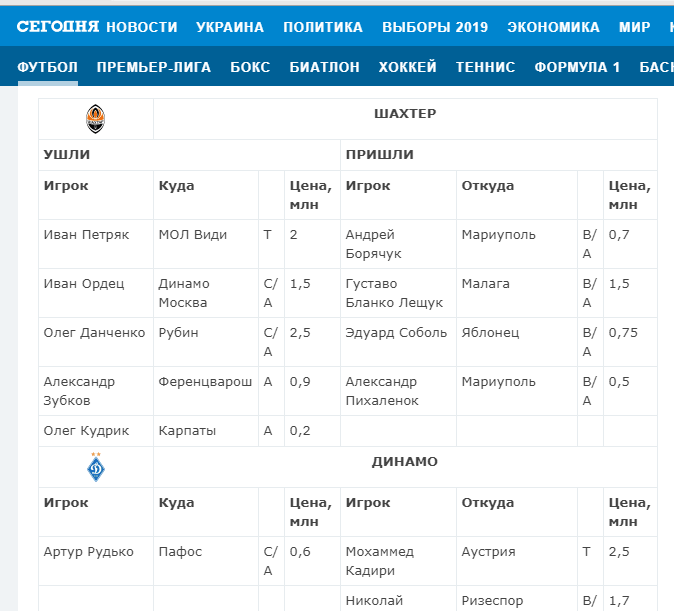
Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
=IMPORTHTML(«https://www.segodnya.ua/sport/football/onlayn-tablica-transferov-chempionata-ukrainy-1288750.html»;»table»;1)
Вставляем формулу в таблицу и смотрим результат:
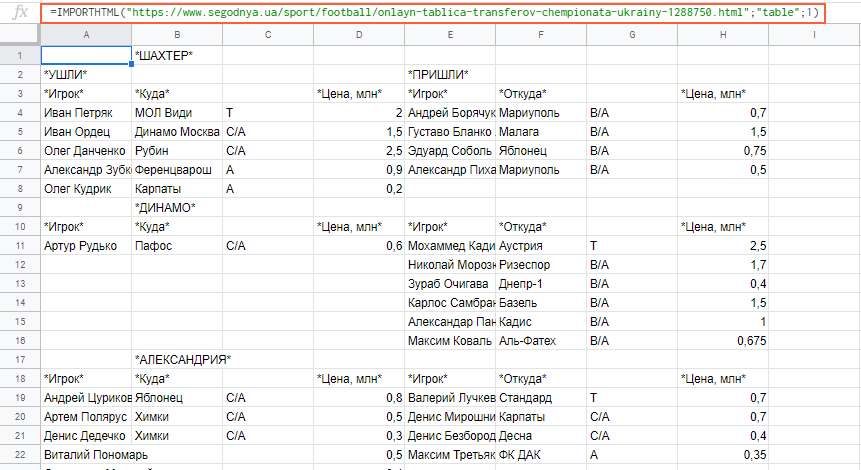
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
=IMPORTXML(«ссылка»; «//XPath запрос»)
Пример использования
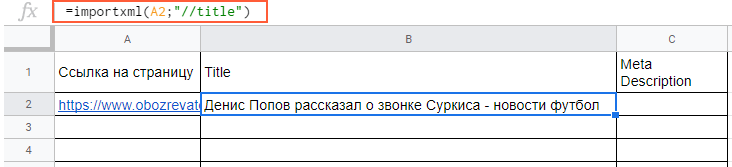
Вытягиваем title и meta description. В первом случае в формуле просто прописываем слово title:
=importxml(A2;»//title»)
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
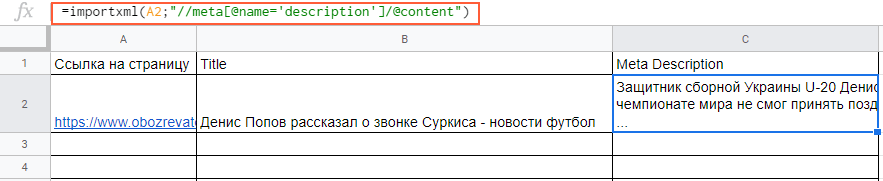
С парсингом description нужно немного больше заморочиться, а именно прописать его XPath. Он будет выглядеть так:
meta[@name=’description’]/@content
В случае с другими любыми данными XPath можно скопировать прямо из кода страницы.

Вставляем в формулу и получаем содержимое meta description.
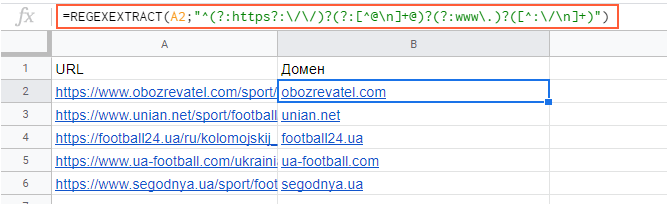
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:
=REGEXEXTRACT(A2;»^(?:https?:\/\/)?(?:[^@\n]+@)?(?:www\.)?([^:\/\n]+)»)
Подробнее об этой и других функциях таблиц вы можете почитать в справке Google.
Import.io
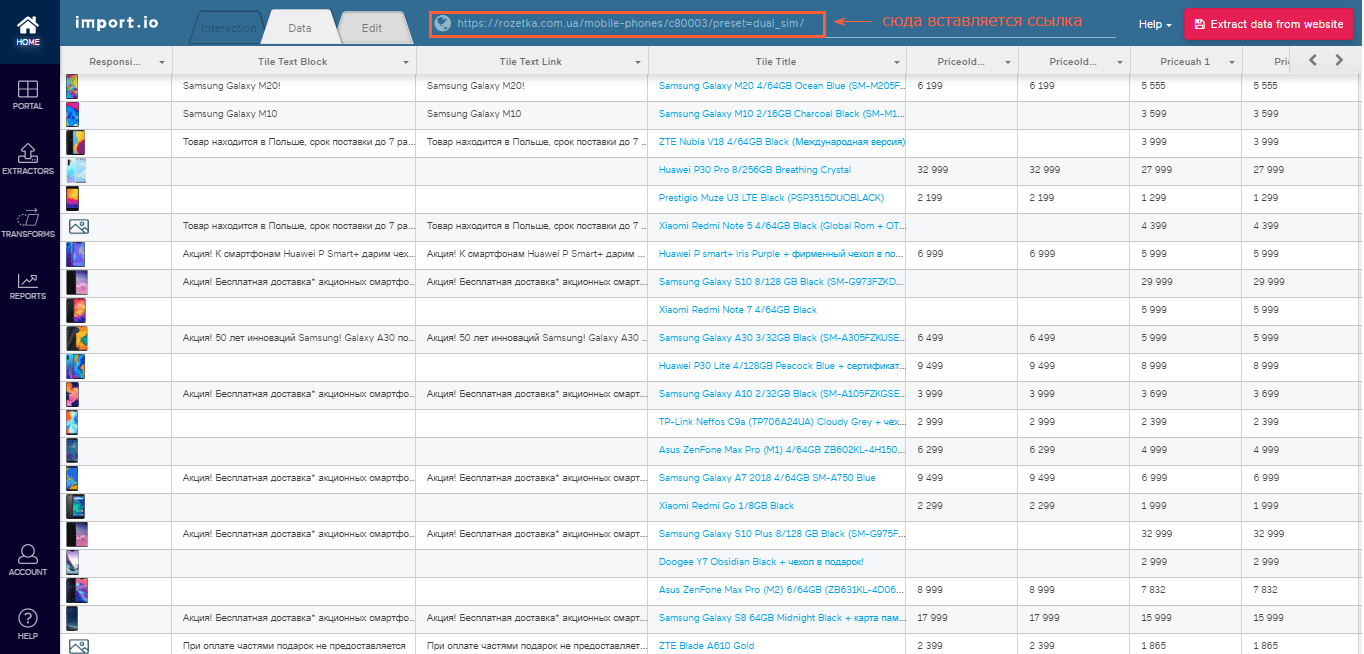
Эта онлайн-платформа позволяет парсить и формировать данные с веб-страниц, а также экспортировать результаты в форматах Excel, CSV, NDJSON. Для использования import.io не требуется знания языков программирования и написания кода.
Чтобы начать парсить, необходимо вставить ссылку страницы, из которой вы хотите тянуть данные, и нажать на кнопку «Extract data».
Для экспорта отчётов нажмите на иконку сохранения, затем перейдите в раздел «Extractors» и нажмите на кнопку скачивания.

Netpeak Spider
Netpeak Spider проводит SEO-аудит и позволяет проводить кастомный парсинг данных с сайтов.
Функция парсинга позволяет настраивать до 15 условий поиска, которые будут выполняться одновременно.
Чтобы извлечь данные со страниц сайта, выполните такие действия:
- Откройте страницу, с которой хотите собрать данные.
- Скопируйте XPath или CSS-селектор нужного элемента (например, цены).
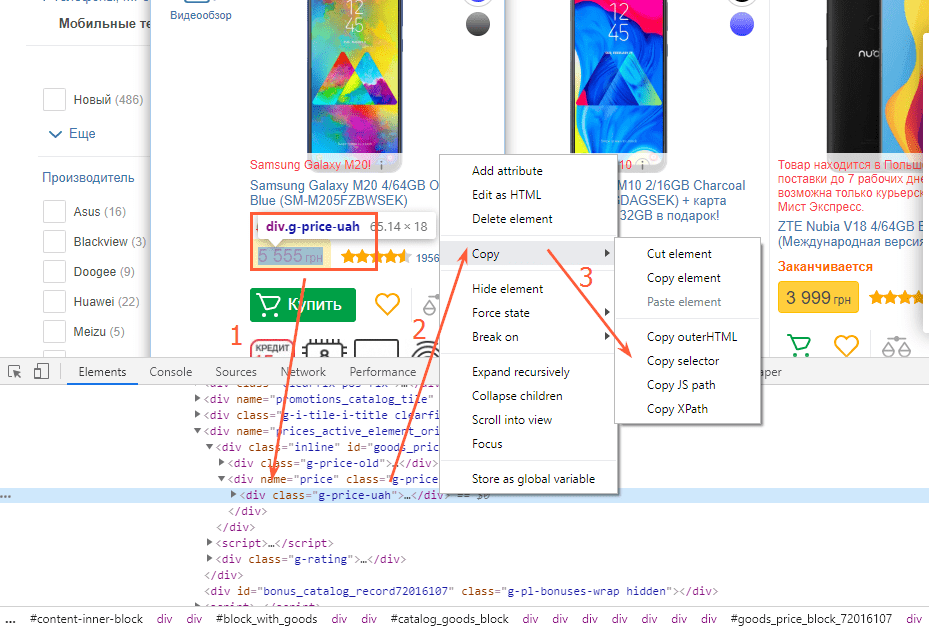
- Откройте программу, перейдите в меню настроек «Парсинг» и включите функцию (поставить «галочку»).
- Выберите нужный режим поиска и область «Внутренний текст».
- Вставьте XPath или CSS-селектор, который вы ранее скопировали.
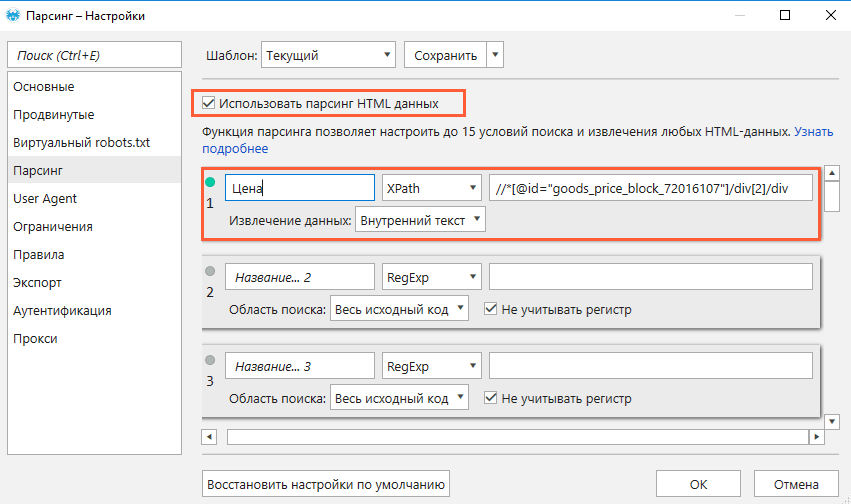
- Сохраните настройки.
- Вставьте домен сайта в адресную строку или загрузите список нужных страниц (через меню «Список URL» или горячими клавишами Ctrl+V, если список сохранён в буфер обмена).
- Нажмите «Старт».

- По завершении анализа перейдите на боковую панель, откройте вкладку «Отчёты» → «Парсинг» и ознакомьтесь с результатами.
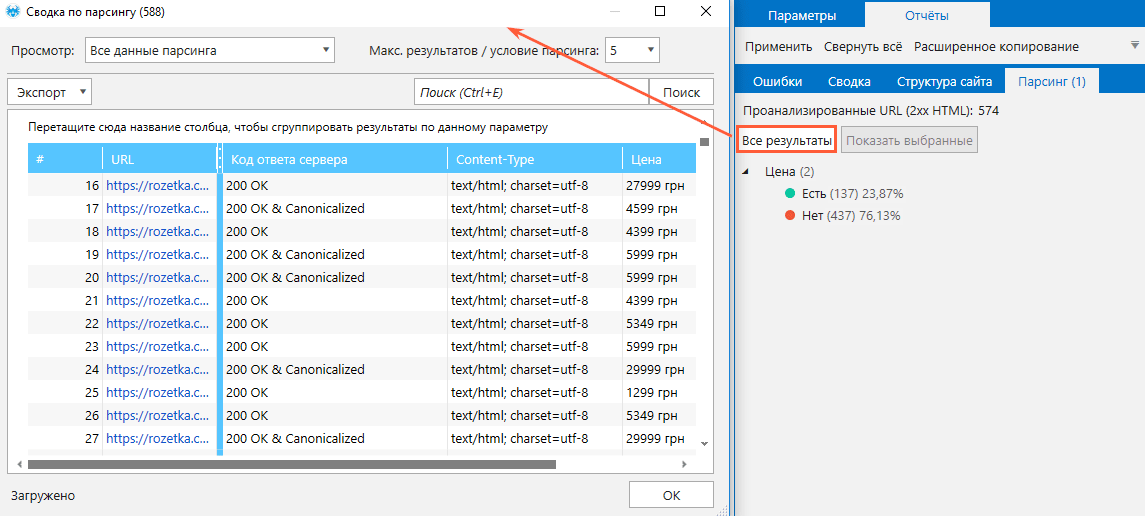
При необходимости выгрузите данные в формате Excel или CSV с помощью кнопки «Экспорт».
Netpeak Checker
Это десктопный инструмент, который предназначен для массового анализа доменов и URL и частично повторяет функционал Netpeak Spider (сканирует On-Page параметры страниц).
Netpeak Checker позволяет за считаные минуты спарсить выдачу поисковых систем Google, Яндекс, Bing и Yahoo.
Чтобы запустить парсинг, проделайте следующее:
- Из основного окна программы перейдите в окно инструмента «Парсер ПС».
- Пропишите запросы, по которым будет парситься выдача. Если в запросе несколько слов, каждое слово должно отделяться знаком «+» без пробела.

- Перейдите на соседнюю вкладку «Настройки», где вы можете выбрать поисковые системы, выставить нужное количество результатов и выбрать тип сниппета.
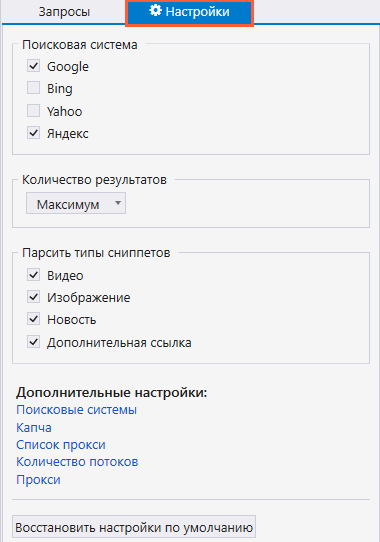
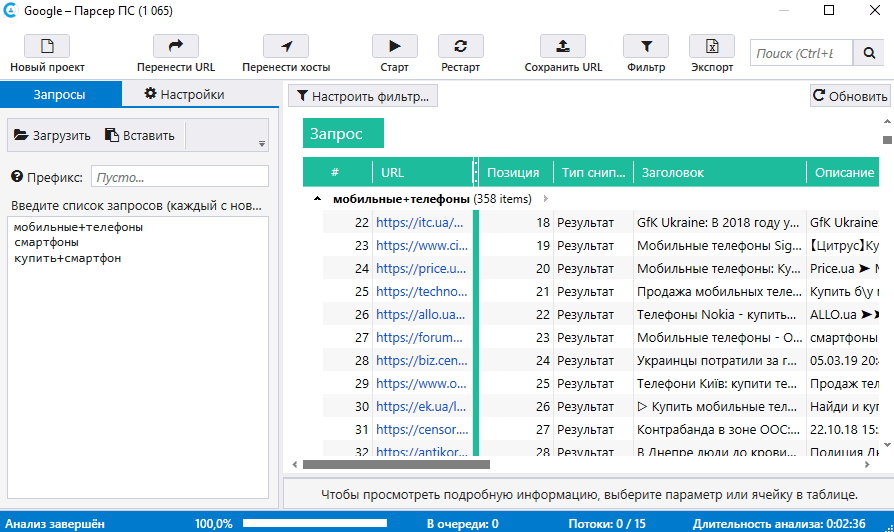
- Нажмите на «Старт», чтобы запустить парсинг.
- По завершении ознакомьтесь с полученными результатами в таблице.
ParseHub
Приложение ParseHub позволяет парсить сайты и обрабатывать JavaScript, AJAX, файлы cookie и работать с одностраничными приложениями.
Процедура извлечения данных со страниц или сайта строится таким образом:
- Создайте новый проект и введите адрес сайта или страницы, с которой вы хотите спарсить данные.
- После того как загрузка закончилась, начинайте выбирать нужные элементы (все элементы, которые вы выберете, отобразятся слева).
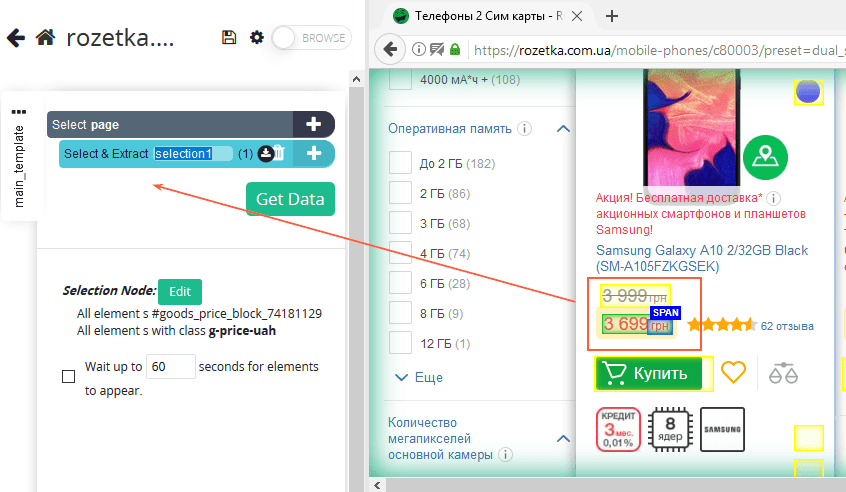
- После того как вы выбрали все нужные элементы, нажмите на кнопку «Get Data».

- Затем нажмите «Run».
- После завершения анализа скачайте полученные данные в удобном для вас формате.
4. Законно ли парсить чужие сайты
Парсинг данных с чужих сайтов не является нарушением закона, если при этом:
- извлекаемая информация размещена в открытом доступе и не составляет коммерческую тайну;
- не нарушаются авторские права и условия обслуживания;
- автоматизированный парсинг осуществляется законным доступом;
- парсинг не нарушает работу сайта.
Если вы не совсем уверены в своих действиях и опасаетесь, что можете преступить закон, перед парсингом лучше проконсультироваться с юристом.
Подводим итоги
Сбор и систематизация веб-данных — это трудозатратный процесс, который может отнимать несколько (даже десятков) часов. Но стоит его автоматизировать, и дело идёт на лад: времязатраты значительно сокращаются, а извлечение информации становится более эффективным. Для автоматизации есть немало программ и сервисов, которые отлично справляются с ролью парсера: можно тестировать и выбирать на свой вкус.
Но помните, что прежде чем собирать и заимствовать какие-либо данные с чужих сайтов, необходимо убедиться, не является ли это нарушением закона.
Поделитесь своими методами автоматизации парсинга в комментариях и расскажите, возникали ли у вас какие-либо проблемы при этом?
Подписаться на рассылку
Еще по теме:

Юля Телижняк
Контент-маркетолог в компании Netpeak Software.
В IT с 2016 года, в серьёзном IT — с 2018. Пишу о SEO и контент-маркетинге, публикуюсь на внешних площадках.
Люблю природу, музыку и собак.
Любимая цитата: Ягода, добытая без труда, не доставляет наслаждения.
Оцените мою статью:
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
![]()
Как создать парсер на python c помощью Scrapy. Пошагово ~ PythonRu
Научимся писать парсеры с помощью Scrapy, мощного фреймворка для извлечения, обработки и хранения данных.
В этом руководстве вы узнаете, как использовать фреймворк Python, Scrapy, с помощью которого можно обрабатывать большие объемы данных. Обучение будет основано на процессе построения скрапера для интернет-магазина Aliexpress.com.
Базовые знания HTML и CSS помогут лучше и быстрее освоить материал.
Обзор Scrapy
")
Веб-скрапинг (парсинг) стал эффективным путем извлечения информации из сети для последующего принятия решений и анализа. Он является неотъемлемым инструментом в руках специалиста в области data science. Дата сайентисты должны знать, как собирать данные с веб-страниц и хранить их в разных форматах для дальнейшего анализа.
Любую страницу в интернете можно исследовать в поисках информации, а все, что есть на странице — можно извлечь. У каждой страницы есть собственная структура и веб-элементы, из-за чего необходимо писать собственных сканеров для каждой страницы.
Scrapy предоставляет мощный фреймворк для извлечения, обработки и хранения данных.
Scrapy использует Spiders — автономных сканеров с определенным набором инструкций. С помощью фреймворка легко разработать даже крупные проекты для скрапинга, так чтобы и другие разработчики могли использовать этот код.
Scrapy vs. Beautiful Soup
Подписывайтесь на телеграм каналы
В этом разделе будет дан обзор одного из самых популярных инструментов для парсинга, BeautifulSoup, и проведено его сравнение со Scrapy.
Scrapy — это Python-фреймворк, предлагающий полноценный набор инструментов и позволяющий разработчикам не думать о настройке кода.
BeautifulSoup также широко используется для веб-скрапинга. Это пакет Python для парсинга документов в форматах HTML и XML и извлечения данных из них. Он доступен для Python 2.6+ и Python 3.
Вот основные отличия между ними:
| Scrapy | BeautifulSoup |
|---|---|
| Функциональность | |
| Scrapy — это самый полный набор инструментов для загрузки веб-страниц, их обработки и сохранения в файлы и базы данных | BeautifulSoup — это в принципе просто парсер HTML и XML, требующий дополнительных библиотек, таких как requests и urlib2 для открытия ссылок и сохранения результатов. |
| Кривая обучения | |
| Scrapy — это движущая сила веб-сканирования, предлагающая массу способов парсинга страниц. Обучение тому, как он работает, требует много времени, но после освоения процесс сканирования превращается в одну строку кода. Потребуется время, чтобы стать экспертом в Scrapy и изучить все его особенности | BeautifulSoup относительно прост для понимания новичкам в программировании и позволяет решать маленькие задачи за короткий срок. |
| Скорость и нагрузка | |
| Scrapy с легкостью выполняет крупную по объему работу. Он может сканировать несколько ссылок одновременно менее чем за минуту в зависимости от общего количества. Это происходит плавно благодаря Twister, который работает асинхронно (без блокировки) | BeautifulSoup используется для простого и эффективного парсинга. Он работает медленнее Scrapy, если не использовать multiprocessing. |
| Расширяемость | |
Scrapy предоставляет функциональность Item pipelines, с помощью которой можно писать функции для веб-сканера. Они будут включать инструкции о том, как робот должен проверять, удалять и сохранять данные в базу данных. Spider Contracts используются для проверки парсеров, благодаря чему можно создавать как базовые, так и глубокие парсеры. Он же позволяет настраивать множество переменных: повторные попытки, перенаправление и т. д. | Если проект не предполагает большого количества логики, BeautifulSoup отлично для этого подходит, но если нужна настраиваемость, например прокси, управление куки и распределение данных, то Scrapy справляется лучше. |
Синхронность означает, что необходимо ждать, пока процесс завершит работу, прежде чем начинать новый, а асинхронный позволяет переходить к следующему процессу, пока предыдущий еще не завершен.
Установка Scrapy
С установленным Python 3.0 (и новее) при использовании Anaconda можно применить команду conda для установки scrapy. Напишите следующую команду в Anaconda:
conda install -c conda-forge scrapy
Чтобы установить Anaconda, посмотрите эти руководства PythonRu для Mac и Windows.
Также можно использовать установщик пакетов pyhton pip. Это работает в Linux, Mac и Windows:
pip install scrapy
Scrapy Shell
Scrapy предоставляет оболочку веб-сканера Scrapy Shell, которую разработчики могут использовать для проверки своих предположений относительно поведения сайта. Возьмем в качестве примера страницу с планшетами на сайте Aliexpress. С помощью Scrapy можно узнать, из каких элементов она состоит и понять, как это использовать в конкретных целях.
Откройте командную строку и напишите следующую команду:
scrapy shell
При использовании Anaconda можете написать эту же команду прямо в anaconda prompt. Вывод будет выглядеть приблизительно вот так:
2020-03-14 16:28:16 [scrapy.utils.log] INFO: Scrapy 2.0.0 started (bot: scrapybot)
2020-03-14 16:28:16 [scrapy.utils.log] INFO: Versions: lxml 4.3.2.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1c 28 May 2019), cryptography 2.6.1, Platform Windows-10-10.0.18362-SP0
....
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
Необходимо запустить парсер на странице с помощью команды fetch в оболочке. Он пройдет по странице, загружая текст и метаданные.
fetch(“https://www.aliexpress.com/category/200216607/tablets.html”)
Примечание: всегда заключайте ссылку в кавычки, одинарные или двойные
Вывод будет следующий:
2020-03-14 16:39:53 [scrapy.core.engine] INFO: Spider opened
2020-03-14 16:39:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.aliexpress.com/robots.txt> (referer: None)
2020-03-14 16:39:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.aliexpress.com/category/200216607/tablets.html> (referer: None)
Парсер возвращает response (ответ), который можно посмотреть с помощью команды view(response). А страница откроется в браузере по умолчанию.
С помощью команды print(response.text) можно посмотреть сырой HTML.
Отобразится скрипт, который генерирует страницу. Это то же самое, что вы видите по нажатию правой кнопкой мыши в пустом месте и выборе «Просмотр кода страница» или «Просмотреть код». Но поскольку нужна конкретная информация, а не целый скрипт, с помощью инструментов разработчика в браузере необходимо определить требуемый элемент. Возьмем следующие элементы:
- Название планшета
- Цена планшета
- Количество заказов
- Имя магазина
Нажмите правой кнопкой по элементу и кликните на «Просмотреть код».
Инструменты разработчика сильно помогут при работе с парсингом. Здесь видно, что есть тег <a> с классом item-title, а сам текст включает название продукта:
<a data-p4p="true" href="//aliexpress.ru
/item/32719104234.html?spm=a2g0o.productlist.0.0.248552054LjgSt&
amp;algo_pvid=ff95978b-3cdf-4d85-8ab6-da9c1cf5f78b&
algo_expid=ff95978b-3cdf-4d85-8ab6-da9c1cf5f78b-0&
btsid=0b0a3f8115842002308095415e318f&
ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_"
title="Планшет с 10,1-дюймовым дисплеем, восьмиядерным
процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ 128 ГБ, 10
дюймов" target="_blank" data-spm-anchor-
id="a2g0o.productlist.0.0">Планшет с 10,1-дюймовым дисплеем,
восьмиядерным процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ
128 ГБ, 10 дюймов</a>
Использование CSS-селекторов для извлечения
Извлечь эту информацию можно с помощью атрибутов элементов или CSS-селекторов в виде классов. Напишите следующее в оболочке Scrapy, чтобы получить имя продукта:
response.css(".item-title::text").extract_first()
Вывод:
'Планшет с 10,1-дюймовым дисплеем, восьмиядерным процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ 128 ГБ, 10 дюймов'
extract_first() извлекает первый элемент, соответствующий селектору css. Для извлечения всех названий нужно использовать extract():
response.css(".item-title::text").extract()
Следующий код извлечет ценовой диапазон этих продуктов:
response.css(".price-current::text").extract()
То же можно повторить для количества заказов и имени магазина.
Использование XPath для извлечения
XPath — это язык запросов для выбора узлов в документах типа XML. Ориентироваться по документу можно с помощью XPath. Scrapy использует этот же язык для работы с объектами документа HTML. Использованные выше CSS-селекторы также конвертируются в XPath, но в большинстве случаев CSS очень легко использовать. И тем не менее важно значить, как язык работает в Scrapy.
Откройте оболочку и введите fetch("https://www.aliexpress.com/category/200216607/tablets.html/") как и раньше. Попробуйте написать следующий код:
response.xpath('/html').extract()
Он покажет весь код в теге <html>. / указывает на прямого потомка узла. Если нужно получить теги <div> в html, то необходимо писать:
response.xpath('/html//div').extract()
Для XPath важно научиться понимать, как используются / и //, чтобы ориентироваться в дочерних узлах.
Если необходимо получить все теги <div>, то нужно написать то же самое, но без /html:
response.xpath("//div").extract()
Можно и дальше фильтровать начальные узлы, чтобы получить нужные узлы с помощью атрибутов и их значений. Это синтаксис использования классов и их значений.
response.xpath("//div[@class='quote'/span[@class='text']").extract()
response.xpath("//div[@class='quote']/span[@class='text']/text()").extract()
Используйте text() для извлечения всего текста в узлах
Создание проекта Scrapy и собственного робота (Spider)
Парсинг хорошо подходит для создания агрегатора, который будет использоваться для сравнения данных. Например, нужно купить планшет, предварительно сравнив несколько продуктов и их цены. Для этого можно исследовать все страницы и сохранить данные в файл Excel. В этом примере продолжим парсить aliexpress.com на предмет информации о планшетах.
Создадим робота (Spider) для страницы. В первую очередь необходимо создать проект Scrapy, где будут храниться код и результаты. Напишите следующее в терминале или anaconda.
scrapy startproject aliexpress
Это создаст скрытую папку в директории с Python или Anaconda по умолчанию. Она будет называться aliexpress, но можно выбрать любое название. Структура директории следующая:

| Файл/папка | Назначение |
|---|---|
scrapy.cfg | Файл настройки развертывания |
aliexpress/ | Модуль Python проекта, отсюда импортируется код |
__init.py__ | Файл инициализации |
items.py | Python файл с элементами проекта |
pipelines.py | Файл, который содержит пайплайн проекта |
settings.py | Файл настроек проекта |
spiders/ | Папка, в которой будут храниться роботы |
__init.py__ | Файл инициализации |
После создания проекта нужно перейти в новую папку и написать следующую команду:
scrapy genspider aliexpress_tabletshttps://www.aliexpress.com/category/200216607/tablets.html
Это создает файл шаблона с названием aliexpress_tables.py в папке spiders, как и было описано выше. Вот код из этого файла:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
def parse(self, response):
pass
В коде можно увидеть name, allowed_domains, start_urls и функцию parse.
- name — это имя робота. Удачные и правильно подобранные имена позволят проще отслеживать всех имеющихся роботов. Они должны быть уникальны, ведь именно они используются для запуска командой
scrapy crawl name_of_spider. - allowed_domains (опционально) — список разрешенных для парсинга доменов. Запрос к URL, не указанным в этом списке, не будет выполнен. Он должен включать только домен сайта (например, aliexpress.com), а не целый URL, указанный в
start_urls, иначе возникнут ошибки. - start_urls — запрос к упомянутым URL. С них робот начнет проводить поиск, если конкретный URL не указан. Первыми загруженными страницами будут те, что указаны здесь. Последующие запросы будут генерироваться последовательно из данных, сохраненных в начальных URL.
- parse — эта функция вызывается, когда парсинг URL успешно выполнен. Ее еще называют функцией обратного вызова.
Response(используемый в оболочке Scrapy) возвращается как результат парсинга, передается этой функции, а внутри нее находится код для извлечения.
можно использовать функцию
parse()из BeautifulSoup в Scrapy для парсинга HTML-документа.
Примечание: извлечь данные можно с помощью css-селекторов, используя как
response.css(), так и XPath (XML), что позволит получить доступ к дочерним элементам. Примерresponse.xpath()будет описан в коде функцииpass().
Добавим изменения в файл aliexpress_tablet.py. В start_urls теперь еще один URL. Логику извлечения можно указать в функции pass():
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html',
'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
def parse(self, response):
print("procesing:"+response.url)
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
for item in row_data:
scraped_info = {
'page': response.url,
'product_name': item[0],
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
yield scraped_info
zip()берет n элементов итерации и возвращает список кортежей. Элемент с индексом i в кортеже создается с помощью элемента с индексом i каждого элемента итерации.
yield используется каждый раз при определении функции генератора. Функция генератора — это обычная функция, отличие которой в том, что она использует yield вместо return. yield используется каждый раз, когда вызывающая функция требует значения. Функция с yield сохраняет свое локальное состояние при выполнении и продолжает исполнение с того момента, где остановилась после того, как выдала одно значение. В данном случае yield возвращает Scrapy сгенерированный словарь, который будет обработан и сохранен.
Теперь можно запустить робота и посмотреть результат:
scrapy crawl aliexpress_tablets
Экспорт данных
Данные должны быть представлены в форматах CSV или JSON, чтобы их можно было анализировать. Этот раздел руководства посвящен тому, как получить такой файл из имеющихся данных.
Для сохранения файла CSV откройте settings.py в папке проекта и добавьте следующие строки:
FEED_FORMAT="csv"
FEED_URI="aliexpress.csv"
После сохранения settings.py снова запустите scrapy crawl aliexpress_tablets в папке проекта. Будет создан файл aliexpress.csv.
Примечание: при каждом запуске паука он будет добавлять файл.
Feed Export также может добавить временную метку в имя файла. Или его можно использовать для выбора папки, куда необходимо сохранить данные.
%(time)s— заменяется на временную метку при создании ленты%(name)s— заменяется на имя робота
Например:
- Сохранить по FTP используя по одной папке на робота:
Изменения для FEED, сделанные в settings.py, будут применены ко всем роботам в проекте. Можно указать и отдельные настройки для конкретного робота, которые перезапишут те, что есть в settings.py.
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html',
'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.json",
'FEED_FORMAT': 'json'}
def parse(self, response):
print("procesing:"+response.url)
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
for item in row_data:
scraped_info = {
'page': response.url,
'product_name': item[0],
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
yield scraped_info
response.url вернет URL страницы, с которой был сгенерирован ответ. После запуска парсера с помощью scrapy crawl aliexpress_tables можно просмотреть json-файл в каталоге проекта.
Следующие страницы, пагинация
Вы могли обратить внимание на две ссылки в start_urls. Вторая — это страница №2 результатов поиска планшетов. Добавлять все ссылки непрактично. Робот должен быть способен исследовать все страницы сам, а в start_urls указывается только одна стартовая точка.
Если у страницы есть последующие, в ее конце всегда будут навигационные элементы, которые позволяют перемещаться вперед и назад.
Вот такой код:
<div><div><div><div><button disabled="" aria-label="Previous page, current page 1" type="button" role="button"><i></i>Предыдущая</button><div><button aria-label="Page 1, 7 pages" type="button" role="button">1</button>
...
<button aria-label="Page 7, 7 pages" type="button" role="button">7</button></div><button aria-label="Next page, current page 1" type="button" role="button">След. стр.<i></i></button></div></div><div><span>Всего 24 стр</span><span>Перейти на страницу</span><span><input aria-label="Large" autocomplete="off" value=""></span><span>ОК</span></div></div></div>
Здесь видно, что тег <span> с классом .ui-pagination-active — это текущая страница, а дальше идут теги <a> со ссылками на следующие страницы. Каждый раз нужно будет получать тег <a> после тега <span>. Здесь в дело вступает немного CSS. В этом случае нужно получить соседний, а на дочерний узел, так что потребуется сделать CSS-селектор, который будет искать теги <a> после тега <span> с классом .ui-pagination-active.
Запомните! У каждой веб-страницы собственная структура. Нужно будет изучить ее, чтобы получить желаемый элемент. Всегда экспериментируйте с response.css(SELECTOR) в Scrapy Shell, прежде чем переходить к коду.
Измените aliexpress_tabelts.py следующим образом:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.json",
'FEED_FORMAT': 'json'}
def parse(self, response):
print("procesing:"+response.url)
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
for item in row_data:
scraped_info = {
'page': response.url,
'product_name': item[0],
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
yield scraped_info
NEXT_PAGE_SELECTOR = '.ui-pagination-active + a::attr(href)'
next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse)
В этом коде:
- Сначала извлекается ссылка следующей страницы с помощью
next_page = response.css(NET_PAGE_SELECTOR).extract_first(), а потом, если переменнаяnext_pageполучает ссылку и она не пустая, запускается телоif. response.urljoin(next_page)— методparse()будет использовать этот метод для построения нового URL и получения нового запроса, который будет позже направлен вызову.- После получения нового URL он парсит ссылку, исполняя тело
forи снова начинает искать новую страницу. Так будет продолжаться до тех пор, пока страницы не закончатся.
Теперь можно просто расслабиться и смотреть, как робот парсит страницы. Этот извлечет все из последующих страниц. Процесс займет много времени, а размер файла будет 1,1 МБ.
Scrapy сделает для вас все!
Из этого руководства вы узнали о Scrapy, о его отличиях от BeautifulSoup, о Scrapy Shell и о создании собственных проектов. Scrapy перебирает на себя весь процесс написания кода: от создания файлов проекта и папок до обработки дублирующихся URL. Весь процесс парсинга занимает минуты, а Scrapy предоставляет поддержку всех распространенных форматов данных, которые могут быть использованы в других программах.
Теперь вы должны лучше понимать, как работает Scrapy, и как использовать его в собственных целях. Чтобы овладеть Scrapy на высоком уровне, нужно разобраться со всеми его функциями, но вы уже как минимум знаете, как эффективно парсить группы веб-страниц.
Осваиваем парсинг сайта: короткий туториал на Python
Постоянно в Интернете, ничего не успеваете? Парсинг сайта спешит на помощь! Разбираемся, как автоматизировать получение нужной информации.
Чтобы быть в курсе, кто получит кубок мира в 2019 году, или как будет выглядеть будущее страны в ближайшие 5 лет, приходится постоянно зависать в Интернете. Но если вы не хотите тратить много времени на Интернет и жаждете оставаться в курсе всех событий, то эта статья для вас. Итак, не теряя времени, начнём!
Доступ к новейшей информации получаем двумя способами. Первый – с помощью API, который предоставляют медиа-сайты, а второй – с помощью парсинга сайтов (Web Scraping).
Использование API предельно просто, и, вероятно, лучший способ получения обновлённой информации – вызвать соответствующий программный интерфейс. Но, к сожалению, не все сайты предоставляют общедоступные API. Таким образом, остаётся другой путь – парсинг сайтов.
Парсинг сайта
Это метод извлечения информации с веб-сайтов. Эта методика преимущественно фокусируется на преобразовании неструктурированных данных – в формате HTML – в Интернете в структурированные данные: базы данных или электронные таблицы. Парсинг сайта включает в себя доступ к Интернету напрямую через HTTP или через веб-браузер. В этой статье будем использовать Python, чтобы создать бот для получения контента.
Последовательность действий
- Получить URL страницы, с которой хотим извлечь данные.
- Скопировать или загрузить HTML-содержимое страницы.
- Распарсить HTML-содержимое и получить необходимые данные.
Эта последовательность помогает пройти по URL-адресу нужной страницы, получить HTML-содержимое и проанализировать необходимые данные. Но иногда требуется сперва войти на сайт, а затем перейти по конкретному адресу, чтобы получить данные. В этом случае добавляется ещё один шаг для входа на сайт.
Пакеты
Для анализа HTML-содержимого и получения необходимых данных используется библиотека Beautiful Soup. Это удивительный пакет Python для парсинга документов формата HTML и XML.
Для входа на веб-сайт, перехода к нужному URL-адресу в рамках одного сеанса и загрузки HTML-содержимого будем использовать библиотеку Selenium. Selenium Python помогает при нажатии на кнопки, вводе контента и других манипуляциях.
Погружение в код
Сначала импортируем библиотеки, которые будем использовать:
# импорт библиотек from selenium import webdriver from bs4 import BeautifulSoup
Затем укажем драйверу браузера путь к Selenium, чтобы запустить наш веб-браузер (Google Chrome). И если не хотим, чтобы наш бот отображал графический интерфейс браузера, добавим опцию headless в Selenium.
Браузеры без графического интерфейса (headless) предоставляют автоматизированное управление веб-страницей в среде, аналогичной популярным веб-браузерам, но выполняются через интерфейс командной строки или с использованием сетевых коммуникаций.
# путь к драйверу chrome
chromedriver = '/usr/local/bin/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument('headless') # для открытия headless-браузера
browser = webdriver.Chrome(executable_path=chromedriver, chrome_options=options)После настройки среды путём определения браузера и установки библиотек приступаем к HTML. Перейдём на страницу входа и найдём идентификатор, класс или имя полей для ввода адреса электронной почты, пароля и кнопки отправки, чтобы ввести данные в структуру страницы.
# Переход на страницу входа
browser.get('http://playsports365.com/default.aspx')
# Поиск тегов по имени
email = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_UserName')
password = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_Password')
login = browser.find_element_by_name('ctl00$MainContent$ctlLogin$BtnSubmit')Затем отправим учётные данные в эти HTML-теги, нажав кнопку «Отправить», чтобы ввести информацию в структуру страницы.
# добавление учётных данных для входа
email.send_keys('********')
password.send_keys('*******')
# нажатие на кнопку отправки
login.click()После успешного входа в систему перейдём на нужную страницу и получим HTML-содержимое страницы.
# После успешного входа в систему переходим на страницу «OpenBets»
browser.get('http://playsports365.com/wager/OpenBets.aspx')
# Получение HTML-содержимого
requiredHtml = browser.page_sourceКогда получили HTML-содержимое, единственное, что остаётся, – парсинг. Распарсим содержимое с помощью библиотек Beautiful Soup и html5lib.
html5lib – это пакет Python, который реализует алгоритм парсинга HTML5, на который сильно влияют современные браузеры. Как только получили нормализованную структуру содержимого, становится доступным поиск данных в любом дочернем элементе тега html. Искомые данные присутствуют в теге table, поэтому ищем этот тег.
soup = BeautifulSoup(requiredHtml, 'html5lib')
table = soup.findChildren('table')
my_table = table[0]Один раз находим родительский тег, а затем рекурсивно проходим по дочерним элементам и печатаем значения.
# получение тегов и печать значений
rows = my_table.findChildren(['th', 'tr'])
for row in rows:
cells = row.findChildren('td')
for cell in cells:
value = cell.text
print (value)Чтобы выполнить указанную программу, установите библиотеки Selenium, Beautiful Soup и html5lib с помощью pip. После установки библиотек команда #python <program name> выведет значения в консоль.
Так парсятся данные с любого сайта.
Если же парсим веб-сайт, который часто обновляет контент, например, результаты спортивных соревнований или текущие результаты выборов, целесообразно создать задание cron для запуска этой программы через конкретные интервалы времени.
Используете парсинг сайта?
Для вывода результатов необязательно ограничиваться консолью, правда?
Как вы предпочитаете отображать данные подобных программ: выводить на панель уведомлений, отправлять на почту или иначе? Делитесь полезными находками 🙂
Надеемся, вам понравилась статья.
Оригинал
Бенчмарк HTML парсеров / Хабр
Переписывал в островке кусок одного сервиса с Python на Erlang. Сам сервис занимается тем, что скачивает по HTTP значительное количество однотипных HTML страниц и извлекает из них некоторую информацию. Основная CPU нагрузка сервиса приходится на парсинг HTML в DOM дерево.
Сперва захотелось сравнить производительность Erlang парсера mochiweb_html с используемым из Python lxml.etree.HTML(). Провел простейший бенчмарк, нужные выводы сделал, а потом подумал что неплохо было бы добавить в бенчмарк ещё парочку-другую парсеров и платформ, оформить покрасивее, опубликовать код и написать статью.
На данный момент успел написать бенчмарки на Erlang, Python, PyPy, NodeJS и С в следующих комбинациях:
- Erlang — mochiweb_html
- CPython — lxml.etree.HTML
- CPython — BeautifulSoup 3
- CPython — BeautifulSoup 4
- CPython — html5lib
- PyPy — BeautifulSoup 3
- PyPy — BeautifulSoup 4
- PyPy — html5lib
- Node.JS — cheerio
- Node.JS — htmlparser
- Node.JS — jsdom
- C — libxml2 (скорее для справки)
В тесте сравниваются скорость обработки N итераций парсера и пиковое потребление памяти.
Интрига: кто быстрее — Python или PyPy? Как сказывается иммутабельность Erlang на скорости парсинга и потреблении памяти? Насколько быстра V8 NodeJS? И как на всё это смотрит код на чистом C.
Термины
Скорее всего вы с ними знакомы, но почему бы не повторить?
Нестрогий HTML парсер — парсер HTML, который умеет обрабатывать некорректный HTML код (незакрытые теги, знаки > < внутри тегов <script>, незаэскейпленные символы амперсанда &, значения атрибутов без кавычек и т.п.). Понятно, что не любой поломанный HTML можно восстановить, но можно привести его к тому виду, к которому его приводит браузер. Примечательно, что большая часть HTML, которая встречается в интернете, является в той или иной степени невалидной!
DOM дерево — Document Object Model если говорить строго, то DOM это тот API, который предоставляется яваскрипту в браузере для манипуляций над HTML документом. Мы немного упростим задачу и будем считать, что это структура данных, которая представляет из себя древовидное отображение структуры HTML документа. В корне дерева находится элемент <html>, его дочерние элементы — <head> и <body> и так далее. Например, в Python документ
<html lang="ru-RU">
<head></head>
<body>Hello, World!</body>
</html>Можно в простейшем виде представить как
("html", {"lang": "ru-RU"}, [
("head", {}, []),
("body", {}, ["Hello, World!"])
])Обычно HTML преобразуют в DOM дерево для трансформации или для извлечения данных. Для извлечения данных из дерева очень удобно использовать XPath или CSS селекторы.
Конкурсанты
- Erlang
- Mochiweb html parser. Единственный нестрогий HTML парсер для Erlang. Написан на эрланге.
- CPython
- lxml.etree.HTML биндинг libxml2. Cython
- BeautifulSoup 3 Написанный на python HTML DOM парсер (3-я версия).
- BeautifulSoup 4 HTML DOM парсер с подключаемыми бекендами.
- html5lib Написанный на питоне DOM парсер, ориентированный на HTML5.
- PyPy (те же парсеры, что и CPython, кроме lxml)
- BeautifulSoup 3
- BeautifulSoup 4
- html5lib
- Node.JS
- cheerio написанный на JS HTML DOM парсер с поддержкой jQuery API
- htmlparser HTML DOM парсер на чистом JS
- jsdom написанный на JS HTML DOM парсер с навороченным API, похожем на API браузера
- C
- libxml2 Написанный на C нестрогий HTML SAX/DOM парсер.
Цели
Вообще, парсинг HTML (как и JSON) интересен тем, что документ нужно просматривать посимвольно. В нём нет инструкций вроде «следующие 10Кб — это сплошной текст, его копируем как есть». Если мы встретили в тексте тег <p>, то нам нужно последовательно просматривать все последующие символы на наличие конструкции </. Тот факт, что HTML может быть невалидным, заставляет «перепроверять всё по 2 раза». Потому что, например, если мы встретили тег <option>, то далеко не факт, что встретим закрывающий </option>. Вторая проблема, которая обычно возникает с такими форматами — экранирование спецсимволов. Например, если весь документ это <html>...100 мегабайт текста... & ...ещё 100 мегабайт текста...</html>, то парсер будет вынужден создать в памяти полную копию содержимого тега с единственным изменением — «&», преобразованный в «&» (хотя некоторые парсеры просто разбивают такой текст на 3 отдельных куска).
Необходимость строить в памяти довольно большую структуру — дерево из мелких объектов, накладывает довольно жесткие требования на управление памятью, сборщик мусора, на оверхед на создание множества мелких объектов.
Нашим бенчмарком хотим:
- Сравнить производительность и потребление памяти различных нестрогих HTML DOM парсеров.
- Изучить стабильность работы парсера. Возрастет ли время обработки одной страницы и объём потребляемой памяти с ростом числа итераций?
- Как зависит скорость парсинга и потребление памяти от размера HTML документа.
- Ну и оценить эффективность платформы: скорость работы со строками, эффективность менеджмента памяти
Проверять качество работы парсера в плане полноты восстановления поломанных документов не будем. Сравнение удобства API и наличие инструментов для работы с деревом тоже оставим за кадром.
Условия и методика тестирования
Программа один раз считывает документ с диска в память и затем N раз последовательно парсит его в цикле.
Парсер на каждой итерации должен строить в памяти полное DOM дерево.
После N итераций программа печатает время работы цикла и завершается.
Каждый парсер запускаем на наборе из нескольких HTML документов на N = 10, 50, 100, 400, 600 и 1000 итераций.
Измеряем User CPU, System CPU, Real runtime и (примерное?) пиковое потребление памяти с помощью /usr/bin/time.
HTML документы:
- page_google.html (116Kb) — выдача гугла, 50 результатов на странице. Очень много встроенного в страницу HTML и JS, мало текста, весь HTML в одну строку.
- page_habrahabr-70330.html (1,6Mb) — статья на хабре с 900 комментариями. Очень большая страница, много тегов, пробелов и табуляции.
- page_habrahabr-index.html (95Kb) — главная страница habrahabr. Типичная страница блога.
- page_wikipedia.html (99Kb) — статья на wikipedia. Хотел страничку, на которой будет много текста и мало тегов, но выбрал не самую удачную. В итоге много тегов и встроенного CSS.
На самом деле понял, что большинство документов одинакового размера только под конец, но переделывать не стал, т.к. сам процесс измерения занимает довольно много времени. А так было бы интересно отследить различные зависимости ещё и от размера страницы. UPD: готовится вторая часть статьи, в ней будем парсить сайты из TOP1000 Alexa.
Тесты запускал последовательно на Ubuntu 3.5.0-19-generic x86_64, процессор Intel Core i7-3930K CPU @ 3.20GHz × 12. (Нафига 12 ядер, если тесты запускать последовательно? Эхх…)
Код
Весь код доступен на github. Можете попробовать запустить самостоятельно, подробные инструкции есть в README файле. Даже нет — настоятельно рекомендую не верить мне, а проверить как поведут себя тесты на вашем окружении!
Tip: если хотите протестировать только часть платформ (например, не хотите устанавливать себе Erlang или PyPy), то это легко задается переменной окружения PLATFORMS.
Буду рад пулл-реквестам с реализацией парсеров на других языках (PHP? Java? .NET? Ruby?), постараюсь добавить в результаты (в первую очередь интересны нативные реализации — биндинги к libxml как правило не отличаются по скорости). Интересно было бы попробовать запустить тесты на каких-нибудь других интересных HTML файлах (большая вложенность тегов, различные размеры файлов).
Результаты
Вот сырые результаты измерений в виде CSV файлов results-1000.csv results-600.csv results-400.csv results-100.csv results-50.csv results-10.csv. Попробуем их проанализировать, для этого воспользуемся скриптом на языке R (находится в репозитории с бенчмарком в папке stats/).
Скорость
Для исследования зависимости скорости работы парсера от числа итераций, построим гистограммы зависимости [времени на обработку одной страницы] от [числа итераций]. Время на обработку одной страницы считаем как время работы парсера, разделенное на число итераций. В идеальном варианте скорость работы парсера не должна зависеть от числа итераций, а лучше — должна возрастать (за счет JIT например).
Все графики кликабельны! Не ломайте глаза!
Зависимость времени на обработку документа от числа итераций парсера (здесь и далее — для каждой HTML страницы отдельный график).
Столбики одинаковой высоты — хорошо, разной — плохо. Видно, что для большинства парсеров зависимости нет (все столбики одинаковой высоты). Исключение составляют только BeautifulSoup 4 и html5lib под PyPy; по какой-то причине у них с ростом числа итераций производительность снижается. То есть если ваш парсер на PyPy должен работать продолжительное время, то производительность будет постепенно снижаться. Неожиданно…
Теперь самый интересный график — средняя скорость обработки одной странички каждым парсером. Построим box-plot диаграмму.
Среднее время на обработку документа.
Чем выше находится бокс — тем медленнее работает парсер. Чем больше бокс по площади, тем больше разброс значений (т.е. выше зависимость производительности от числа итераций). Видно, что парсер на C лидирует, за ним следуют lxml.etree, почти вплотную парсеры на NodeJS и Erlang, потом bsoup3 парсер на PyPy, парсеры на CPython и потом с большим отрывом те же парсеры, запущенные на PyPy. Вот так сюрприз! PyPy всем сливает.
Ещё одна странность — bsoup 3 парсеру на Python чем-то не понравилась страничка википедии :-).
Пример табличных данных:
> subset(res, (file=="page_google.html") & (loops==1000))[ c("platform", "parser", "parser.s", "real.s", "user.s") ]
platform parser parser.s real.s user.s
6 c-libxml2 libxml2_html_parser.c 2.934295 2.93 2.92
30 erlang mochiweb_html.erl 13.346997 13.51 13.34
14 nodejs cheerio_parser.js 5.303000 5.37 5.36
38 nodejs htmlparser_parser.js 6.686000 6.72 6.71
22 nodejs jsdom_parser.js 98.288000 98.42 98.31
33 pypy bsoup3_parser.py 40.779929 40.81 40.62
57 pypy bsoup4_parser.py 434.215878 434.39 433.91
41 pypy html5lib_parser.py 361.008080 361.25 360.46
65 python bsoup3_parser.py 78.566026 78.61 78.58
49 python bsoup4_parser.py 33.364880 33.45 33.43
60 python html5lib_parser.py 200.672682 200.71 200.70
67 python lxml_parser.py 3.060202 3.08 3.08Память
Теперь посмотрим на использование памяти. Сперва посмотрим, как потребление памяти зависит от числа итераций. Снова построим гистограммы. В идеале все столбики одного парсера должны быть одинаковой высоты. Если потребление растет с увеличением числа итераций, то это указывает на утечки памяти или проблемы со сборщиком мусора.
Потребление памяти в зависимости от числа итераций парсера.
Занятно. Bsoup4 и html5lib под PyPy заняли по 5Гб памяти после 1000 итераций по 1Мб файлу. (Привел здесь только 2 графика, т.к. на остальных такая же картина). Видно, что с ростом числа итераций практически линейно растет и потребляемая память. Получается, что PyPy просто не совместим с Bsoup4 и html5lib парсерами. С чем это связано и кто виноват я не знаю, но зато понятно, что использование PyPy без тщательной проверки совместимости со всеми используемыми библиотеками — весьма рискованное занятие.
Выходит, что комбинация PyPy с этими парсерами выбывает. Попробуем убрать их с графиков:
Потребление памяти в зависимости от числа итераций парсера (без Bsoup4 и html5lib на PyPy).
Видим, что для парсера на C все столбики практически идентичной высоты. То же самое для lxml.etree. Для большинства парсеров потребление памяти при 10 итерациях немного меньше. Возможно просто time не успевает её замерить. NodeJS парсер jsdom ведет себя довольно странно — у него потребление памяти для некоторых страниц скачет весьма случайным образом, но в целом виден рост потребления памяти со временем. Возможно какие-то проблемы со сборкой мусора.
Сравним усредненное потребление памяти для оставшихся парсеров. Построим box-plot.
Усредненное потребление памяти.
Видим, что расстановка примерно такая же, как в сравнении скорости, но у Erlang потребление памяти оказалось ниже, чем у NodeJS. lxml.etree требует памяти примерно в 2 раза больше, чем C libxml2, но меньше чем любой другой парсер. NodeJS парсер jsdom несколько выпадает из общей картины, потребляя ~ в 2 раза больше памяти, чем другие NodeJS парсеры — видимо у него значительный оверхед, связанный с созданием дополнительных атрибутов у элементов DOM дерева.
Пример табличных данных:
> subset(res, (file=="page_google.html") & (loops==1000))[ c("platform", "parser", "maximum.RSS") ]
platform parser maximum.RSS
6 c-libxml2 libxml2_html_parser.c 2240
30 erlang mochiweb_html.erl 21832
14 nodejs cheerio_parser.js 49972
38 nodejs htmlparser_parser.js 48740
22 nodejs jsdom_parser.js 119256
33 pypy bsoup3_parser.py 61756
57 pypy bsoup4_parser.py 1701676
41 pypy html5lib_parser.py 1741944
65 python bsoup3_parser.py 42192
49 python bsoup4_parser.py 54116
60 python html5lib_parser.py 45496
67 python lxml_parser.py 9364
Оверхед на запуск программы
Это уже не столько тест HTML парсера, сколько попытка выяснить какую платформу стоит использовать для написания консольных утилит. Просто небольшое дополнение (раз у нас уже есть данные). Оверхед платформы — это время, которое программа тратит не на непосредственно работу, а на подготовку к ней (инициализация библиотек, считывание HTML файла и т.п.). Что бы его вычислить, вычтем из времени, которое вывела утилита time — «time.s», время, которое замерили вокруг цикла парсера — «parser.s».
Видно, что оверхед в большинстве случаев несущественный. Примечательно, что у Erlang он сравнимый с Python. Можно предположить, что он зависит от массивности библиотек, которые программа импортирует.
Выводы
Как видим — реализация на C впереди планеты всей (но и кода в ней получилось побольше).
Биндинг libxml2 к питону (lxml.etree.HTML) работает практически с такой же скоростью, но потребляет в 2 раза больше памяти (скорее всего оверхед собственно интерпретатора). Выходит, предпочтительный парсер на Python — это lxml.
Парсер на голом Erlang показывает на удивление высокие результаты, несмотря на приписываемые эрлангу «копирования данных на каждый чих» ©. Скорость сравнима с простыми парсерами на NodeJS и выше, чем у Python парсеров. Потребление памяти ниже только у C и lxml. Стабильность отличная. Такой парсер можно выпускать в продакшн (что я и сделал).
Простые парсеры на NodeJS работают очень быстро — в 2 раза медленнее сишной libxml. V8 работает крайне эффективно. Но памяти потребляют на уровне с Python, причем память расходуется не слишком стабильно (расход памяти может вырасти при увеличении числа итераций с 10 до 100, но потом стабилизируется). Парсер jsdom для простого парсинга явно не подходит, т.к. у него слишком высокие накладные расходы. Так что для парсинга HTML в NodeJS лучший выбор — cheerio.
Парсеры на чистом Python сливают как по скорости, так и по потреблению памяти, причем результаты сильно скачут на разных страницах. Но при этом ведут себя стабильно на разном количестве итераций (GC работает равномерно?)
Но больше всех удивил PyPy. То ли какие-то проблемы с GC, то ли задача для него не подходящая, то ли парсеры реализованы неудачно, то ли я где-то накосячил, но производительность парсеров на PyPy снижается с ростом числа итераций, а потребление памяти линейно растет. Bsoup3 парсер более-менее справляется, но его показатели находятся на уровне с CPython. Т.е. для парсинга на PyPy подходит только Bsoup3, но заметных преимуществ перед CPython он не дает.
Ссылки
Код бенчмарка Мой блог
Document Object Model
Присылайте свои реализации! Это очень просто!
UPD:
Результаты для добавленных парсеров (графики, CSV):
golang (3 шт, один быстрее С(!!!))
haskell (крайне неплохо)
java (openjdk, oracle-jre) (автоматически параллелится, занимая ~150% CPU, user CPU > real CPU)
perl
php + tidy
ruby (биндинг к libxml)
dart (очень медленный)
mono (2 шт) (автоматически параллелится, занимая ~150% CPU, user CPU > real CPU)
Полноценную статью + исследование зависимости скорости и потребления памяти от размера страницы по TOP1000 Alexa будет позже (надеюсь).
синтаксический анализ — Как создать парсер HTML?
Переполнение стека
- Около
Продукты
- Для команд
Переполнение стека
Общественные вопросы и ответыПереполнение стека для команд
Где разработчики и технологи делятся частными знаниями с коллегамиВакансии
Программирование и связанные с ним технические возможности карьерного ростаТалант
Нанимайте технических специалистов и создавайте свой бренд работодателяРеклама
Обратитесь к разработчикам и технологам со всего мира
.
Как сделать HTML-парсер на JavaScript
Переполнение стека
- Около
Продукты
- Для команд
Переполнение стека
Общественные вопросы и ответыПереполнение стека для команд
Где разработчики и технологи делятся частными знаниями с коллегамиВакансии
Программирование и связанные с ним технические возможности карьерного ростаТалант
Нанимайте технических специалистов и создавайте свой бренд работодателяРеклама
Обратитесь к разработчикам и технологам со всего мира- О компании
Загрузка…
.
html.parser — Простой анализатор HTML и XHTML — документация Python 3.8.6
Исходный код: Lib / html / parser.py
Этот модуль определяет класс HTMLParser , который служит основой для
анализ текстовых файлов, отформатированных в HTML (язык гипертекстовой разметки) и XHTML.
- класс
html.parser.HTMLParser( * , convert_charrefs = True ) Создайте экземпляр анализатора, способный анализировать недопустимую разметку.
Если convert_charrefs равно
True(по умолчанию), все символы
ссылки (кроме тех, что вскрипте/стиляэлементов) являются
автоматически преобразуется в соответствующие символы Unicode.Экземпляр
HTMLParserполучает данные HTML и вызывает методы обработчика.
когда начальные теги, конечные теги, текст, комментарии и другие элементы разметки
столкнулся. Пользователь должен создать подклассHTMLParserи переопределить его
методы для реализации желаемого поведения.Этот синтаксический анализатор не проверяет соответствие конечных тегов начальным тегам и не вызывает конечный тег.
обработчик для элементов, которые закрываются неявно путем закрытия внешнего элемента.Изменено в версии 3.4: добавлен аргумент ключевого слова convert_charrefs .
Изменено в версии 3.5: значение по умолчанию для аргумента convert_charrefs теперь
True.
Пример приложения парсера HTML
В качестве базового примера ниже приведен простой анализатор HTML, который использует
HTMLParser класс для печати начальных тегов, конечных тегов и данных
по мере их появления:
из HTML.парсер импорт HTMLParser
класс MyHTMLParser (HTMLParser):
def handle_starttag (self, tag, attrs):
print ("Обнаружен начальный тег:", тег)
def handle_endtag (сам, тег):
print ("Обнаружен конечный тег:", тег)
def handle_data (self, data):
print ("Обнаружены некоторые данные:", данные)
parser = MyHTMLParser ()
parser.feed (' Test '
' Разбери меня!
')
Тогда на выходе будет:
Обнаружен начальный тег: html. Обнаружен начальный тег: голова Обнаружен начальный тег: title Обнаружены некоторые данные: Тест Обнаружен конечный тег: название Обнаружен конечный тег: голова Обнаружен начальный тег: body Обнаружен начальный тег: h2 Обнаружил некоторые данные: Разбери меня! Обнаружен конечный тег: h2 Обнаружен конечный тег: body Обнаружен конечный тег: html
Экземпляры HTMLParser имеют следующие методы:
-
HTMLParser.корма( данные ) Подать текст синтаксическому анализатору. Он обрабатывается постольку, поскольку состоит из
комплектные элементы; неполные данные буферизуются до тех пор, пока не будет подано больше данных или
Вызываетсяclose (). данные должны бытьstr.
-
HTMLParser.закрыть() Принудительная обработка всех буферизованных данных, как если бы за ними следовал конец файла
отметка. Этот метод может быть переопределен производным классом для определения дополнительных
обработка в конце ввода, но переопределенная версия всегда должна вызывать
метод базового классаHTMLParserclose ().
-
HTMLParser.сброс() Сбросить экземпляр. Теряет все необработанные данные. Это неявно вызывается в
время создания.
-
HTMLParser.getpos() Возвращает текущий номер строки и смещение.
-
HTMLParser.get_starttag_text() Вернуть текст последнего открытого начального тега.Обычно это не должно
необходимы для структурированной обработки, но могут быть полезны при работе с HTML «как
развернут »или для повторного создания входных данных с минимальными изменениями (пробел между
атрибуты могут быть сохранены и т. д.).
Следующие методы вызываются при обнаружении элементов данных или разметки
и они предназначены для переопределения в подклассе. Базовый класс
реализации ничего не делают (кроме handle_startendtag () ):
-
HTMLParser.handle_starttag( тег , attrs ) Этот метод вызывается для обработки начала тега (например,
).Тег аргумент — это имя тега, преобразованное в нижний регистр. Атрибуты
аргумент — это список из(имя, значение)пар, содержащих найденные атрибуты
внутри скобок тега<>. Имя будет переведено в нижний регистр,
и кавычки в значении были удалены, а ссылки на символы и сущности
были заменены.Например, для тега
будет называтьсяhandle_starttag ('a', [('href', 'https://www.cwi.nl/')]).Все ссылки на сущности из
html.entitiesзаменяются на.
20,2. html.parser — Простой анализатор HTML и XHTML — документация Python 3.4.10
Исходный код: Lib / html / parser.py
Этот модуль определяет класс HTMLParser, который служит основой для
анализ текстовых файлов, отформатированных в HTML (язык гипертекстовой разметки) и XHTML.- класс html.parser.HTMLParser ( strict = False , * , convert_charrefs = False )
Создайте экземпляр анализатора.
Если convert_charrefs имеет значение True (по умолчанию: False), все символы
ссылки (кроме тех, что находятся в элементах скрипта / стиля)
автоматически преобразуется в соответствующие символы Unicode.
Использование convert_charrefs = True приветствуется и станет
значение по умолчанию в Python 3.5.Если strict False (по умолчанию), синтаксический анализатор примет и проанализирует
недопустимая разметка. Если strict True, синтаксический анализатор вызовет
HTMLParseError вместо этого, если это не так
умеет разбирать разметку.Использование strict = True не рекомендуется и
аргумент strict устарел.Экземпляр HTMLParser получает данные HTML и вызывает методы обработчика.
когда начальные теги, конечные теги, текст, комментарии и другие элементы разметки
столкнулся. Пользователь должен создать подкласс HTMLParser и переопределить его
методы для реализации желаемого поведения.Этот синтаксический анализатор не проверяет соответствие конечных тегов начальным тегам и не вызывает конечный тег.
обработчик для элементов, которые закрываются неявно путем закрытия внешнего элемента.Изменено в версии 3.2: добавлен аргумент strict .
Не рекомендуется с версии 3.3, будет удалено в версии 3.5: аргумент strict и строгий режим объявлены устаревшими.
Синтаксический анализатор теперь также может принимать и анализировать недопустимую разметку.Изменено в версии 3.4: добавлен аргумент ключевого слова convert_charrefs .
Также определено исключение:
- исключение html.parser.HTMLParseError
Исключение, вызываемое классом HTMLParser при обнаружении ошибки
при синтаксическом разборе и строгом — True. Это исключение предусматривает три
атрибуты: msg — краткое сообщение, объясняющее ошибку,
Lineno — это номер строки, на которой была сломана конструкция.
обнаружено, а смещение — это количество символов в строке в
который запускает конструкция.Устарело с версии 3.3, будет удалено в версии 3.5: это исключение устарело, поскольку оно никогда не создавалось анализатором.
(когда используется нестрогий режим по умолчанию).
20.2.1. Пример приложения для синтаксического анализа HTML
В качестве базового примера ниже приведен простой анализатор HTML, который использует
HTMLParser класс для печати начальных тегов, конечных тегов и данных
по мере их появления:из html.parser импорт HTMLParser класс MyHTMLParser (HTMLParser): def handle_starttag (self, tag, attrs): print ("Обнаружен начальный тег:", тег) def handle_endtag (сам, тег): print ("Обнаружен конечный тег:", тег) def handle_data (self, data): print ("Обнаружены некоторые данные:", данные) parser = MyHTMLParser () парсер.feed ('Тест ' 'Разбери меня!
')Тогда на выходе будет:
Обнаружен начальный тег: html. Обнаружен начальный тег: голова Обнаружен начальный тег: title Обнаружены некоторые данные: Тест Обнаружен конечный тег: название Обнаружен конечный тег: голова Обнаружен начальный тег: body Обнаружен начальный тег: h2 Обнаружил некоторые данные: Разбери меня! Обнаружен конечный тег: h2 Обнаружен конечный тег: body Обнаружен конечный тег: html
экземпляров HTMLParser имеют следующие методы:
- HTMLParser.канал ( данные )
Подать текст синтаксическому анализатору. Он обрабатывается постольку, поскольку состоит из
комплектные элементы; неполные данные буферизуются до тех пор, пока не будет подано больше данных или
close () вызывается. данные должны быть str.
- HTMLParser.close ()
Принудительная обработка всех буферизованных данных, как если бы за ними следовал конец файла
отметка. Этот метод может быть переопределен производным классом для определения дополнительных
обработка в конце ввода, но переопределенная версия всегда должна вызывать
метод базового класса HTMLParser close ().
- HTMLParser.reset ()
Сбросить экземпляр. Теряет все необработанные данные. Это неявно вызывается в
время создания.
- HTMLParser.getpos ()
Возвращает текущий номер строки и смещение.
- HTMLParser.get_starttag_text ()
Возвращает текст последнего открытого начального тега. Обычно это не должно
необходимы для структурированной обработки, но могут быть полезны при работе с HTML «как
развернут »или для повторного создания входных данных с минимальными изменениями (пробел между
атрибуты могут быть сохранены и т. д.).
Следующие методы вызываются при обнаружении элементов данных или разметки
и они предназначены для переопределения в подклассе. Базовый класс
реализации ничего не делают (кроме handle_startendtag ()):- HTMLParser.handle_starttag ( тег , attrs
.
Добавить комментарий