
Как распознать PDF файл онлайн
Извлечь текст из PDF-файла методом обычного копирования можно далеко не всегда. Часто страницы подобных документов представляют собой отсканированное содержимое их бумажных вариантов. Для преобразования таких файлов в полностью редактируемые текстовые данные используются специальные программы с функцией Optical Character Recognition (OCR).
Такие решения являются весьма сложными в реализации и, следовательно, стоят немалых денег. Если потребность в распознавании текста с PDF у вас возникает регулярно, вполне целесообразно будет приобрести соответствующую программу. Для редких же случаев более логичным будет воспользоваться одним из доступных онлайн-сервисов с подобными функциями.
Как распознать текст с PDF онлайн
Конечно, набор возможностей онлайн-сервисов OCR, в сравнении с полноценными десктопными решениями, более ограничен. Но и работать с такими ресурсами можно либо же совсем бесплатно, либо за символическую плату. Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Способ 1: ABBYY FineReader Online
Компания-разработчик сервиса — одна из лидеров в области оптического распознавания документов. ABBYY FineReader для Windows и Mac является мощным решением для преобразования PDF в текст и дальнейшей работы с ним.
Веб-аналог программы, конечно же, уступает ей по функционалу. Тем не менее сервис умеет распознавать текст со сканов и фотографий на более чем 190 языках. Поддерживается преобразование PDF-файлов в документы Word, Excel и т.п.
Онлайн-сервис ABBYY FineReader Online
- Прежде чем приступить к работе с инструментом, создайте аккаунт на сайте или войдите при помощи учетной записи Facebook, Google или Microsoft.
Чтобы перейти к окну авторизации, щелкните по кнопке «Вход» в верхней панели меню.
- Осуществив вход, импортируйте нужный PDF-документ в FineReader, воспользовавшись кнопкой «Загрузить файлы».

Затем нажмите «Выбрать номера страниц» и укажите желаемый промежуток для распознавания текста.
- Далее выберите языки, присутствующие в документе, формат итогового файла и нажмите на кнопку «Распознать».
- После обработки, длительность которой полностью зависит от объема документа, вы можете скачать готовый файл с текстовыми данными просто щелкнув по его названию.
Либо же экспортируйте его в один из доступных облачных сервисов.
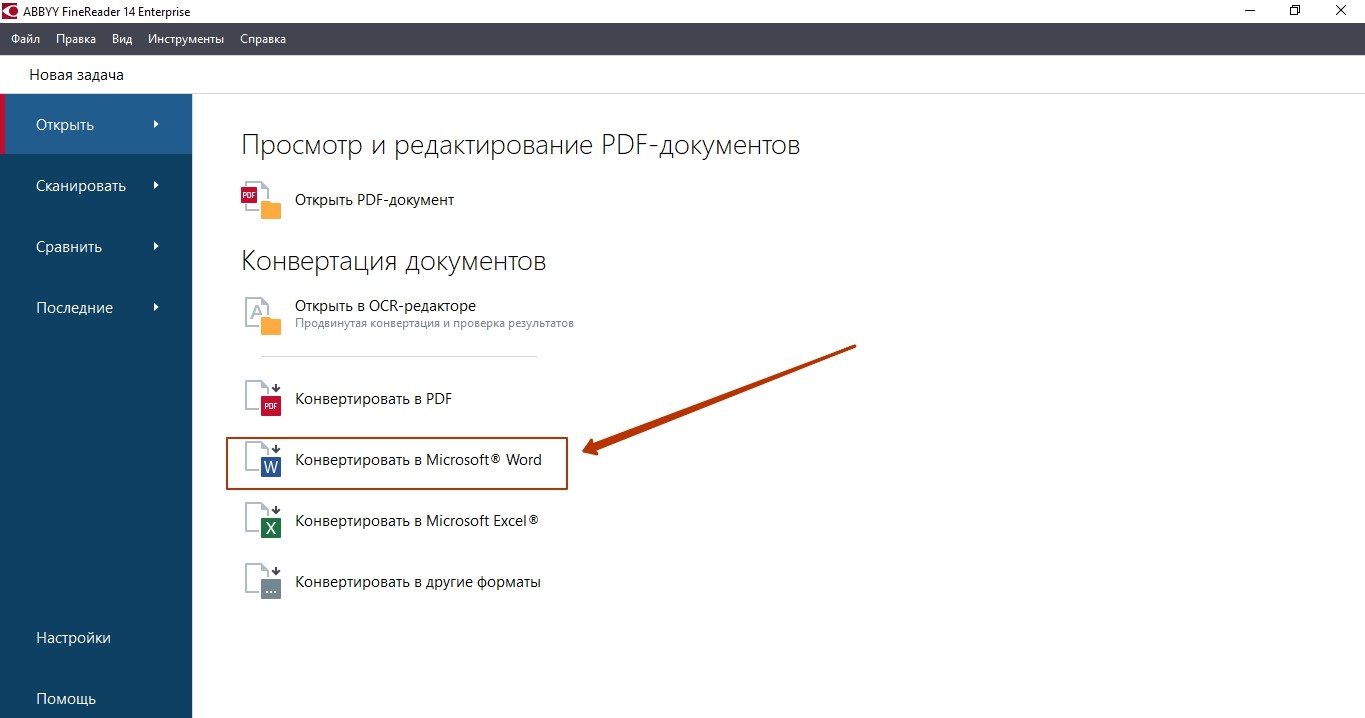
Сервис отличается, вероятно, наиболее точными алгоритмами распознавания текста на изображениях и PDF-файлах. Но, к сожалению, его бесплатное использование ограничено пятью обрабатываемыми страницами в месяц. Чтобы работать с более объемными документами, придется купить годовую подписку.
Тем не менее, если функция OCR нужна совсем уж редко, ABBYY FineReader Online — отличный вариант для извлечения текста из небольших PDF-файлов.
Способ 2: Free Online OCR
Простой и удобный сервис для оцифровки текста. Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
При регистрации пользователь получает возможность обрабатывать многостраничные документы, однако бесплатное количество этих самых страниц ограничено 50 единицами.
Онлайн-сервис Free Online OCR
- Чтобы распознать текст из PDF как «гость», без авторизации на ресурсе, воспользуйтесь соответствующей формой на главной странице сайта.
Выберите нужный документ с помощью кнопки «Файл», укажите основной язык текста, выходной формат, затем дождитесь загрузки файла и нажмите «Конвертировать».
- По окончании процесса оцифровки нажмите «Скачать выходной файл» для сохранения готового документа с текстом на компьютере.
Для авторизованных же пользователей последовательность действий несколько иная.
- Воспользуйтесь кнопкой «Регистрация» или «Вход» в верхней панели меню, чтобы, соответственно, создать учетную запись Free Online OCR либо зайти в нее.
- После авторизации в панели распознавания, удерживая клавишу «CTRL», выберите до двух языков исходного документа из предложенного списка.
- Укажите дальнейшие параметры извлечения текста из PDF и нажмите кнопку «Выбрать файл» для загрузки документа в сервис.
Затем, чтобы приступить к распознаванию, щелкните «Конвертировать».
- По окончании обработки документа нажмите на ссылку с названием выходного файла в соответствующей колонке.
Результат распознавания сразу же будет сохранен в памяти вашего компьютера.
При необходимости извлечь текст из небольшого PDF-документа можно смело прибегать к использованию вышеописанного инструмента. Для работы же с объемными файлами придется купить дополнительные символы во Free Online OCR либо же прибегнуть к другому решению.
Способ 3: NewOCR
Полностью бесплатный OCR-сервис, позволяющий извлекать текст практически из любых графических и электронных документов вроде DjVu и PDF. Ресурс не накладывает ограничений на размер и количество распознаваемых файлов, не требует регистрации и предлагает широкий набор сопутствующих функций.
NewOCR поддерживает 106 языков и умеет корректно обрабатывать даже низкокачественные сканы документов. Есть возможность вручную выбирать область для распознавания текста на странице файла.
Онлайн-сервис NewOCR
- Так, приступить к работе с ресурсом вы можете сразу, без необходимости выполнения лишних действий.
Прямо на главной странице размещена форма для импорта документа на сайт. Чтобы загрузить файл в NewOCR, воспользуйтесь кнопкой «Выберите файл» в разделе «Select your file». Затем в поле «Recognition language(s)» укажите один или более языков исходного документа, после чего нажмите «Upload + OCR».
- Задайте предпочитаемые настройки распознавания, выберите нужную страницу для извлечения текста и щелкните по кнопке «OCR».
- Прокрутите страницу немного ниже и найдите кнопку «Download».
Щелкните по ней и в выпадающем списке выберите необходимый формат документа для скачивания. После этого готовый файл с извлеченным текстом будет загружен на ваш компьютер.

Инструмент удобный и достаточно качественно распознает все символы. Впрочем, обработку каждой страницы импортированного PDF-документа нужно запускать самостоятельно и выводится она в отдельный файл. Можно, конечно, сразу копировать результаты распознавания в буфер обмена и объединять их с другими.
Тем не менее, учитывая вышеописанный нюанс, большие объемы текста с помощью NewOCR извлекать весьма затруднительно. С малыми же файлами сервис справляется «на ура».
Способ 4: OCR.Space
Простой и понятный ресурс для оцифровки текста, позволяет распознавать PDF-документы и выводить результат в TXT-файл. Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
Онлайн-сервис OCR.Space
- Регистрироваться для работы с инструментом не нужно.
Просто перейдите по ссылке выше и загрузите PDF-документ на сайт с компьютера при помощи кнопки «Выберите файл» либо из сети — по ссылке.
- В выпадающем списке «Select OCR language» выберите язык импортированного документа.
Затем запустите процесс распознавания текста, щелкнув по кнопке «Start OCR!».
- По окончании обработки файла ознакомьтесь с результатом в поле «OCR’ed Result» и нажмите «Download», чтобы скачать готовый TXT-документ.
Если вам нужно просто извлечь текст из PDF и при этом финальное его форматирование совсем не важно, OCR.Space — хороший выбор. Единственное, документ должен быть «одноязычным», так как распознавание двух и более языков одновременно в сервисе не предусмотрено.
Читайте также: Бесплатные аналоги FineReader
Оценивая онлайн-инструменты, представленные в статье, следует отметить, что наиболее точно и качественно с функцией OCR справляется FineReader Online от ABBYY. Если для вас важна именно максимальная точность распознавания текста, лучше всего рассмотреть конкретно этот вариант. Но и заплатить за него, скорее всего, также придется.
Если же нужна оцифровка небольших документов и вы готовы самостоятельно исправлять ошибки за сервисом, целесообразно использовать NewOCR, OCR.Space или Free Online OCR.
Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
Pdf to doc распознать текст online
Как работает наш OCR сервис
Что такое OCR
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ? Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения». Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Метод является более гибким и может работать с большим количеством печатных или рукописных документов.
Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
 Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Как отредактировать текст из PDF-файла? Преобразуйте PDF в текстовый документ при помощи функции оптического распознавания символов (OCR). Если вам надо извлечь текст, студия PDF2Go — идеальное решение.
- Загрузите PDF-документ.
- Нажмите на «Сохранить изменения».

Оставайтесь на связи:
Преобразуйте PDF в текст при помощи функции OCR
бесплатно в любом месте
Преобразование PDF в текстовый файл
Вам доводилось редактировать текст в PDF-файле? Мы знаем, как справиться с этой задачей. Преобразуйте PDF-документ в простой текстовый файл при помощи функции оптического распознавания символов (OCR).
Просто загрузите PDF, а мы сделаем всё остальное. После загрузки документа на PDF2Go мы извлечём текст при помощи функции OCR и создадим файл формата TXT.
Просто и безопасно
PDF2Go не занимает место в телефоне и не представляет угрозы для компьютера.
Этот конвертер с функцией OCR работает онлайн и не требует регистрации или установки приложения для извлечения текста из PDF-файлов.
Для сканов и не только
Вам больше не надо перепечатывать отсканированную книгу или статью вручную. Наш онлайн-инструмент позволяет преобразовать PDF-файл и извлечь текст из любого скана (даже с картинки!).
Если у вас есть PDF, в котором нельзя редактировать текст, воспользуйтесь нашим конвертером, чтобы преобразовать документ в текстовый файл формата TXT.
Переживаете за безопасность?
Когда загружаешь PDF на сайт для преобразования в текстовый формат, последнее, о чём хочется беспокоиться, — что станет с файлом. Мы избавим вас от сомнений.
Все права остаются за вами, никто не просматривает содержимое файлов. Читайте подробности в Политике конфиденциальности.
Что можно преобразовать?
Этот онлайн-конвертер отвечает поставленной задаче: вы можете преобразовать PDF в текстовый формат. Из любого PDF-файла можно получить редактируемый текст.
Из:
В:
Текстовый файл TXT
Оптическое распознавание символов
Всё, что вам потребуется для преобразования PDF-файла на сайте PDF2Go — это надёжное подключение к сети и браузер. Приложение работает с любого устройства. Конвертируйте PDF-файлы в формат TXT:
- дома
- на работе
- в пути
- в любом удобном месте
Вам надо сконвертировать и скачать хотя бы один файл, чтобы оценить конвертацию
Распознавать текст с помощью OCR и создавать файлы PDF с возможностью поиска
- Защищенная с помощью SSL передача файлов
- Автоматическое удаление файла с сервера через один час
- Сервера расположены в Германии
Выберите файлы, к которым вы хотите применить OCR или перетащите файлы в активное поле. Измените настройки и запустите OCR. Через несколько секунд вы можете скачать ваши новые файлы PDF с возможностью поиска.
Измените настройки и запустите OCR. Через несколько секунд вы можете скачать ваши новые файлы PDF с возможностью поиска.
Вы можете изменить несколько параметров для управления процессом OCR. Вы можете сохранить в формате PDF/A, удалить артефакты и помехи, просмотреть страницы, установить мета информацию и присоединить к одному финальному файлу.
Мы максимально упрощаем распознавание текста через OCR. Вам не нужно устанавливать и беспокоиться о каком-либо программном обеспечении, вам просто нужно выбрать файлы, для которых вы хотите применить OCR.
Вам не нужна специальная система для распознавания текста через OCR. Этот инструмент OCR работает в вашем браузере и, следовательно, функционирует во всех операционных системах. Просто перетащите свои файлы и запустите OCR.
Вам не нужно загружать или устанавливать какое-либо программное обеспечение. Текст распознается на наших серверах в облаке и, следовательно, не будет потреблять какие-либо ресурсы вашего компьютера.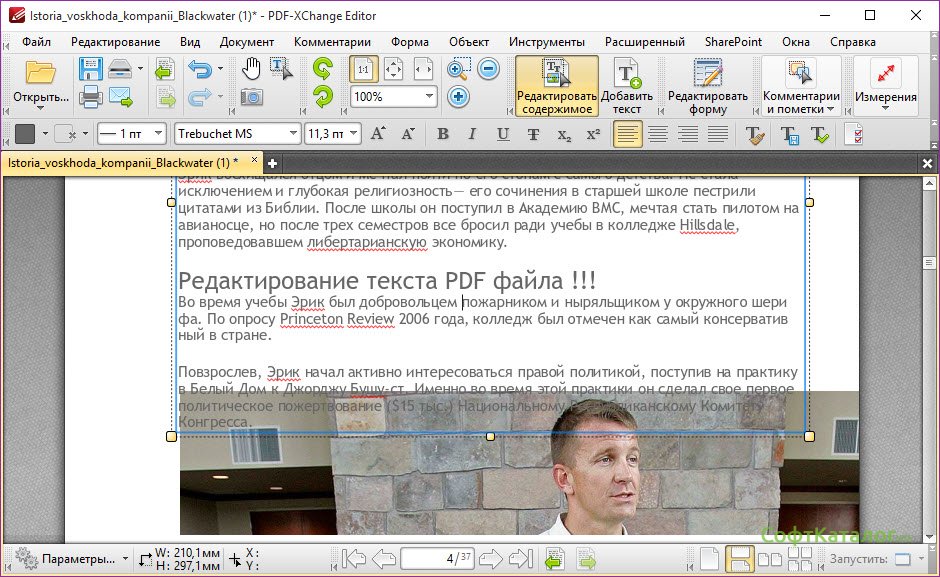
Это приложение OCR не хранит ваши файлы на нашем сервере дольше, чем это необходимо. Ваши файлы и результаты будут удалены с нашего сервера через короткий промежуток времени. Передача файлов защищена SSL.
Этот инструмент позволяет мне очень легко применять OCR к моим отсканированным документам и счетам-фактурам. Я получаю PDF/A с возможностью поиска и архивирования.
Я использую это приложение для конвертации изображений и фотографий, сделанных с помощью моего смартфона в файлы PDF с возможностью поиска, чтобы я мог выполнять поиск и копировать текст.
Сервисы для распознавания текста — подборка лучших | Сканеры | Блог
Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Попробовать тут
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
 dns-shop.ru&autoplay=1><img src=https://img.youtube.com/vi/CT9WnFPQmT8/hqdefault.jpg><svg width=68 height=48><path fill=#f00 d=’M66.52,7.74c-0.78-2.93-2.49-5.41-5.42-6.19C55.79,.13,34,0,34,0S12.21,.13,6.9,1.55 C3.97,2.33,2.27,4.81,1.48,7.74C0.06,13.05,0,24,0,24s0.06,10.95,1.48,16.26c0.78,2.93,2.49,5.41,5.42,6.19 C12.21,47.87,34,48,34,48s21.79-0.13,27.1-1.55c2.93-0.78,4.64-3.26,5.42-6.19C67.94,34.95,68,24,68,24S67.94,13.05,66.52,7.74z’></path><path fill=#fff d=’M 45,24 27,14 27,34′></path></svg></a>» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
dns-shop.ru&autoplay=1><img src=https://img.youtube.com/vi/CT9WnFPQmT8/hqdefault.jpg><svg width=68 height=48><path fill=#f00 d=’M66.52,7.74c-0.78-2.93-2.49-5.41-5.42-6.19C55.79,.13,34,0,34,0S12.21,.13,6.9,1.55 C3.97,2.33,2.27,4.81,1.48,7.74C0.06,13.05,0,24,0,24s0.06,10.95,1.48,16.26c0.78,2.93,2.49,5.41,5.42,6.19 C12.21,47.87,34,48,34,48s21.79-0.13,27.1-1.55c2.93-0.78,4.64-3.26,5.42-6.19C67.94,34.95,68,24,68,24S67.94,13.05,66.52,7.74z’></path><path fill=#fff d=’M 45,24 27,14 27,34′></path></svg></a>» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Sodapdf.com
Попробовать тут
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
WinScan2PDF
Попробовать тут
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Free Online OCR
Попробовать тут
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt.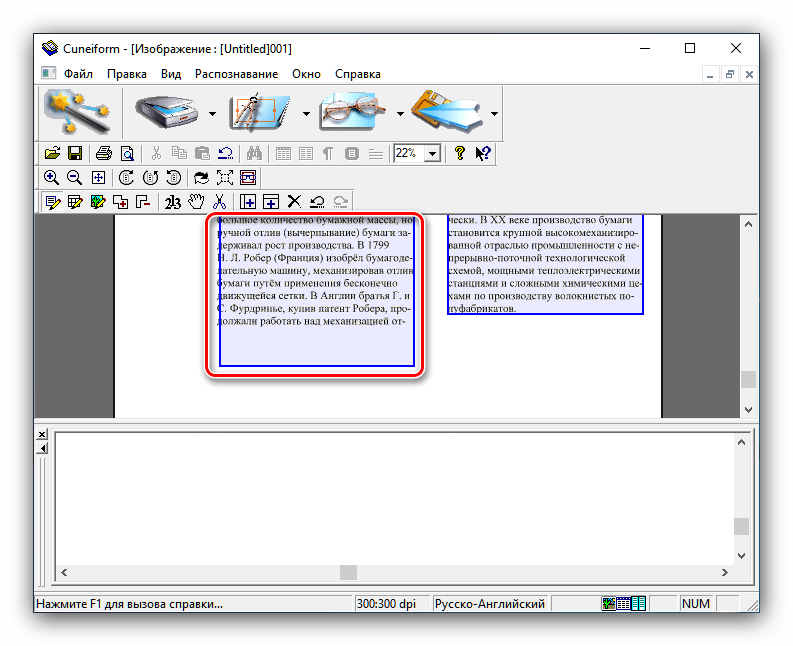 Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Microsoft OneNote
Попробовать тут
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Readiris
Попробовать тут
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский.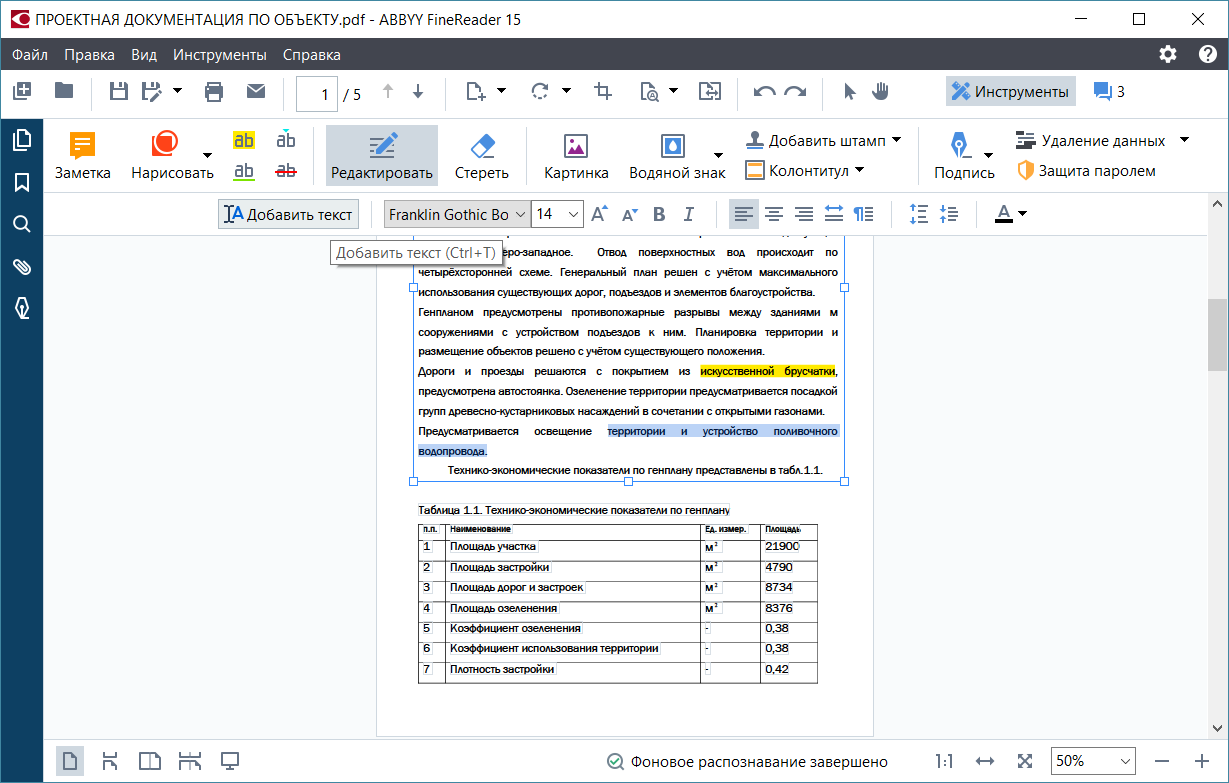 Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Img2txt.com
Попробовать тут
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.
OCR CuneiForm
Попробовать тут
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
iOS, Android
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Как распознать текст PDF на Mac (включая MacOS 10.14 Mojave)
PDF-документы на основе изображений подходят как для личного, так и для делового использования. Однако при редактировании файлов такого типа могут возникнуть сложности. Особенно, если у вас нет подходящего программного обеспечения.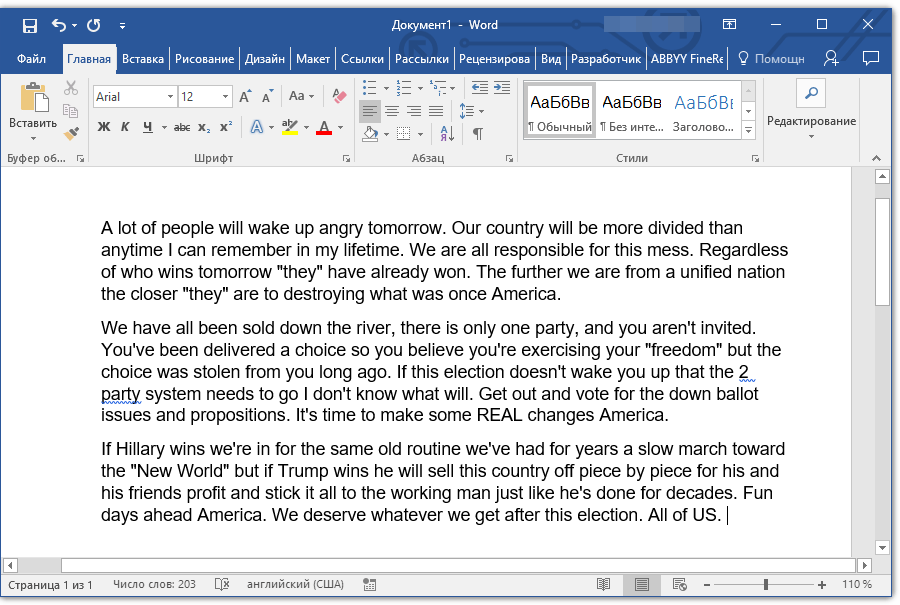 Для редактирования, копирования отсканированных PDF-файлов, а так же для осуществления поиска по ним вам нужно найти программу с возможностью оптического распознавания символов (OCR). В этой статье мы расскажем вам об отличном программном обеспечении с функцией оптического распознавания символов для Mac – PDFelement для Mac. Мы также объясним, как распознавать текст в PDF на Mac.
Для редактирования, копирования отсканированных PDF-файлов, а так же для осуществления поиска по ним вам нужно найти программу с возможностью оптического распознавания символов (OCR). В этой статье мы расскажем вам об отличном программном обеспечении с функцией оптического распознавания символов для Mac – PDFelement для Mac. Мы также объясним, как распознавать текст в PDF на Mac.
Как распознать текст PDF на Mac
Распознавать текст на Mac легко, если вы используете подходящие инструменты – например, PDFelement. Ниже мы расскажем вам о том, как использовать все его продуманные функции.
Шаг 1. Импорт отсканированного PDF-файла
Откройте PDFelement для Mac. Откройте отсканированный PDF-файл в программе. Для этого нажмите «Открыть файл» в нижнем левом углу экрана и выберите файл, текст которого нужно распознать.
Шаг 2. Распознавание PDF с помощью функции распознавания текста
После открытия отсканированного файла программа предложит вам выполнить распознавание символов (OCR). После нажатия на кнопку «Выполнить распознавание символов (OCR)» на экране появится всплывающее окно. В нем вам нужно будет выбрать язык распознавания, соответствующий содержимому вашего PDF. Вы также можете указать нужное разрешение и диапазон страниц для распознавания текста. По завершении нажмите кнопку «OK». Распознавание текста будет выполнено немедленно.
После нажатия на кнопку «Выполнить распознавание символов (OCR)» на экране появится всплывающее окно. В нем вам нужно будет выбрать язык распознавания, соответствующий содержимому вашего PDF. Вы также можете указать нужное разрешение и диапазон страниц для распознавания текста. По завершении нажмите кнопку «OK». Распознавание текста будет выполнено немедленно.
Шаг 3. Редактирование PDF (необязательно)
После завершения распознавания новый PDF-файл с возможностью поиска и редактирования откроется в программе автоматически. Чтобы начать редактирование контента, нажмите кнопку «Редактировать». Узнайте больше о том, как редактировать отсканированные PDF на Mac здесь.
Лучшее программное обеспечение для распознавания текста на Mac
PDFelement для Mac позволяет редактировать не только стандартные, но и отсканированные PDF-файлы. Благодаря передовой технологии оптического распознавания, PDF-файлы, созданные на основе изображений, можно сразу же преобразовывать в редактируемый текст. Программа позволяет распознавать тексты на разных языках, включая английский, японский, корейский, испанский, немецкий, португальский, китайский и французский.
Программа позволяет распознавать тексты на разных языках, включая английский, японский, корейский, испанский, немецкий, португальский, китайский и французский.
Кроме того, в PDFelement для Mac есть множество инструментов для редактирования, которые позволяют изменять текст, изображения и страницы, добавлять разметку и комментарии к PDF-файлам и т.д. С помощью этой программы вы можете конвертировать PDF-файл в различные форматы (Excel, Word, HTML, изображения, PPT, EPUB, текст и т.д.) и обратно. Оно полностью совместимо с macOS X 10.10 (Yosemite), 10.11 (El Capitan), 10.12 (Sierra), 10,13 (High Sierra) и 10,14 (Mojave).
Советы: Preview не поддерживает распознавание текста на Mac
Preview – это встроенная программа для Mac, с помощью которой вы можете читать, редактировать и управлять PDF-файлами, кроме отсканированных PDF. Если ваш PDF-документ – это отсканированный или созданный на основе изображений PDF-файл, отредактировать его или внести какие-либо изменения в PDF-файл с помощью Preview будет невозможно, т. к. в данной программе отсутствует функция OCR.
к. в данной программе отсутствует функция OCR.
Советы: В Automator нельзя извлекать текст из отсканированных PDF-файлов
Automator часто используется для извлечения текста из PDF-файлов, однако в случае с отсканированными PDF-файлами данная функция не работает. Извлечь текст из отсканированных или основанных на изображениях PDF-файлов невозможно, поскольку данная программа не поддерживает распознавание текста.
Советы: В Adobe Reader для Mac невозможно распознавать PDF-файлы
Пользователи Mac часто используют Adobe Reader для Mac для просмотра и управления PDF-документами, т.к. это бесплатный инструмент. Однако этот инструмент также не поддерживает технологию OCR. Для работы над отсканированным или созданным на основе изображений PDF-файлом вам нужно будет заплатить за обновленную версию Adobe Acrobat.
Как редактировать PDF-файл: 3 лучших способа 💻
Тип документов PDF используют для электронных книг, журналов, бизнес-презентаций с большим количество графики и стилей. При форматировании и печати таких файлов сохраняется структура текста, что и сделало этот формат наиболее популярным выбором. Однако изменять ПДФ-файлы намного сложнее, чем обычные текстовые документы. Рассказываем, как редактировать PDF файл сразу несколькими способами.
При форматировании и печати таких файлов сохраняется структура текста, что и сделало этот формат наиболее популярным выбором. Однако изменять ПДФ-файлы намного сложнее, чем обычные текстовые документы. Рассказываем, как редактировать PDF файл сразу несколькими способами.
Как отредактировать ПДФ с помощью специальных программ
Чаще всего для изменения ПДФ-файла применяют специальный компьютерный софт. Для базового редактирования можно использовать бесплатный Adobe Reader, в котором можно добавлять текст, картинки и электронную подпись. Более продвинутые действия потребуют покупки Adobe Acrobat Pro. Он предлагает более широкий спектр инструментов и даже распознает текст со сканов.
Также бесплатно отредактировать документы можно в программе для чтения Foxit Reader. В нем файлы можно подписывать, комментировать и шифровать. Также в макет можно добавлять текст (в том числе из буфера обмена с сохранением стиля) и штампы.
Стоит учитывать, что в большинстве случаев бесплатные варианты накладывают ограничения, например, водяной знак. В целом бесплатный период имеется практически у всех продуктов, так что, если вам нужно сделать разовое действие, можете воспользоваться демо-версией премиум-продукта. Сравнить, какой редактор вам подходит, можно при помощи подробного обзора https://free-pdf.ru/.
Как изменить текст в ПДФ документе с помощью онлайн-сервисов
Если требуется добавить небольшие правки, можно обойтись без специальной программы. Существует большой выбор онлайн-сервисов на русском языке, которые позволяют изменять ПДФ-файл прямо в браузере. Их плюсом является простое управление, так что разобраться, как отредактировать PDF файл, сможет даже новичок.
Один из самых популярных сайтов для редактирования электронной документации – PDF24. Список возможностей этого бесплатного сервиса впечатляет: файлы можно сжать, конвертировать, извлечь изображения, объединить или разделить на страницы и многое другое.
Редактирование ПДФ-файлов на этом сайте сводится к добавлению текстовых и графических элементов. Чтобы удалить какие-то фразы или исправить грамматические ошибки, потребуется сначала прогнать PDF через OCR (распознавание текста). Дополнительно к этому редактор позволяет редактировать только одностраничные документы.
Если вы хотите узнать, как изменить ПДФ файл с несколькими листами, альтернативой можно назвать сайт ILovePDF. В основном сервис направлен на преобразование PDF в другой формат и создание цифровой книги из отсканированных файлов, Word, Excel и других. Также на сайте есть PDF-редактор, благодаря которому в документ можно добавить картинки, текст и геометрические фигуры. В отличие от PDF24, сервис показал быструю работу с многостраничными книгами, но функции распознавания текста здесь нет.
Стоит отметить, что, в отличие от программ для ПК, эти сервисы представляют собой пакет отдельных инструментов. Это значит, что за один раз вы можете выполнить одно действие. Затем потребуется скачать документ и заново загружать его на сервер, что значительно замедляет рабочий процесс.
Изменение PDF через текстовые редакторы
Как уже упоминалось, для изменения содержимого в документации онлайн потребуется распознать текст или преобразовать файл в Ворд. Но если вы работаете со стандартным ПДФ, а не отсканированными бумагами, документ можно обработать на компьютере в самом Microsoft Word.
Эта функция была добавлена в офисный пакет, начиная с версии 2013 года. Программа открывает и распознает файлы, созданные в любом PDF-редакторе. Так что вопросов как исправить текст в ПДФ, не возникнет: просто выделяйте нужные фрагменты и редактируйте, как обычный документ. Результат можно сохранить в PDF, DOC, RTF или текстовый файл.
Однако все же MS Word – это в первую очередь текстовой редактор, поэтому он часто некорректно отображает структуру. К примеру, софт не умеет работать со встроенными шрифтами, а таблицы и графики могут отображаться неправильно, форматирование заголовков сбивается.
Если вас это не смущает, но вам не хочется покупать дорогостоящий Word, бесплатной альтернативой станет Libre Office. Приложение повторяет практически все функции платного конкурента, в проекте можно удалять элементы, писать новый текст и вставлять фигуры. Есть даже специальный режим экспорта в PDF.
Заключение
Итак, мы рассмотрели, как редактировать пдфки и возможно ли сделать это без помощи специальных программ. В целом, чтобы внести небольшие корректировки можно использовать бесплатные онлайн-сервисы или открыть ПДФ в текстовых редакторах. Однако для полноценной работы с цифровой документацией, например, если нужно уменьшить шрифт, замазать фразы, заменить элементы или открыть битый файл ПДФ, потребуется скачать специализированный софт.
Открытие PDF-файлов в Word — Word
Чтобы открыть PDF-файл без преобразования в документ Word, откройте его прямо там, где он хранится (например, дважды щелкните значок PDF-файла в папке «Документы»).
Однако если вы хотите изменить PDF-файл, откройте его в Word. Word создаст копию PDF-файла, преобразуя его в документ Word и пытаясь воссоздать макет исходного PDF-файла. У вас всегда будет исходный PDF-файл на тот случай, если вы не захотите сохранять версию, преобразованную Word.
Преобразование PDF в Word лучше всего работает с файлами, которые в основном состоят из текста, например деловыми, юридическими и научными документами. Но при открытии PDF-файла в Word его внешний вид может отличаться от исходного.
Если PDF-файл в основном состоит из диаграмм и других иллюстраций, вся страница может отображаться как изображение. В таком случае текст невозможно будет редактировать.
Иногда приложению Word не удается обнаружить элемент, поэтому версия в Word может не совпадать с исходным PDF-файлом. Например, если Word не удается обнаружить сноску, она отображается как обычный текст и может находиться не в нижней части страницы.
Элементы документов, которые плохо преобразуются
Некоторые элементы часто приводят к проблемам при преобразовании из PDF-файла в формат Word. Если они есть в PDF-файле, рекомендуется открывать его напрямую, а не преобразовывать в документ Word:
-
таблицы с интервалами между ячейками;
-
цвета и границы страниц;
-
исправления;
-
рамки;
-
сноски, занимающие более одной страницы;
-
концевые сноски;
-
звук, видео и активные элементы PDF;
-
закладки PDF;
-
теги PDF;
-
примечания PDF;
-
такие эффекты шрифтов, как свечение и тень (в файлах Word эти эффекты представляются в виде изображений).
Как выполняется преобразование
PDF является фиксированным форматом файлов, то есть в файле сохраняется расположение текста, рисунков и векторных изображений на странице, но в нем не обязательно хранятся связи между ними. Большинство PDF-файлов не включают сведения о таких структурных элементах содержимого, как абзацы, таблицы и столбцы. Например, таблицы в PDF-файлах хранятся в виде набора строк, не связанных с содержимым за пределами ячеек таблицы.
Разные программы представляют одинаковое содержимое, используя разные структуры в PDF-файлах. Например, PDF-файл может содержать невидимый текст, графику и изображения. Они могут использовать разные границы текста. Но вы не видите эту разницу при просмотре PDF-файла в средстве чтения.
При открытии PDF-файла приложение Word использует систему сложных правил для определения объектов (например, заголовков, списков, таблиц и т. д.), которые лучше всего представляют исходный PDF-файл, и их расположения в документе Word.
Online сервисы распознавание текста. Просто. Бесплатно и удобно. | Учи Урок информатики
Онлайн распознавание текста – это процесс преобразования символов из сканированного документа или изображения с помощью специальных алгоритмов машинного обучения (веб-программ в случае использования online сервисов). Распознавание текста позволяет нам существенно сэкономить время, ведь их не нужно печатать самостоятельно. Сегодня с помощью оптической технологии распознавания текста OCR в большом количестве создается огромное количество отсканированных книг журналов, которые потом можно читать на компьютере. Оптическое распознавание текста завоевало себе место на рынке информационных услуг и стало популярным, ведь после процедуры определения символов, текст можно не только прочитать, но и перевести с помощью автоматического переводчика, внести правки и форматировать его, применяя различные стили.
К сожалению, данная технология не может распознать информацию из PDF со стопроцентной точностью, поэтому после завершения распознавания текста на изображении необходимо сравнивать результат и исходные документы (если форматируется большой документ или книга).
1. Онлайн-словарь для распознавания текста ABBYY
Самая популярная программа-словарь, которая имеет функцию определения текста с изображений и других типов документов. Данное приложение позволяет пользователю моментально получить тестовый вариант фотографии и перевести его на более чем на 50 языков мира. Чтобы распознать текст с помощью данного сервиса, следуйте инструкции:
- Зайдите на официальный сайт веб-приложения и нажмите на кнопку «Распознать», которая находится в центре страницы. Официальная ссылка на сервис: https://finereaderonline.com/ru-ru
- Загрузите файл, с которого необходимо распознать инфо;
- Следующим шагом необходимо выбрать язык конечного документа. Даже если вам не нужно переводить текст, выберите необходимый язык, ведь для каждого из них программа выбирает соответствующую кодировку символов, что позволяет более точно отображать символы;
Последний шаг – необходимо выбрать формат конечного файла. С помощью данного сервиса можно переводить текст с PDF в Word, а также с форматов djvu и jpg.
2. Сервис Online-Ocr
Данный сервис позволяет без регистрации создать текстовый документ из отсканированного файла или из самой обычной картинки. Данный сервис был первым, кто использовал технологию оптического определения машинного текста. Приведем пример распознавания с ПДФ в Ворд:
- Зайдите на сайт сервиса: http://www.onlineocr.net/
- Нажмите на клавишу «выбрать файл» и найдите на своем компьютере необходимый пдф документ, с которого будет определен текст. Максимальный размер входящего документа равен пяти мегабайтам;
- Выберите язык входящего документа и формат конечного файла из предложенного списка поддерживаемых форматов.
- Нажмите кнопку «Конвертировать»;
Процесс конвертации занимает максимум 5 минут, данный показатель зависит от размера входящего файла, от его кодировки и сложности визуального оформления.
3. Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок. К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.
Ссылка на сервис: www.free-ocr.com
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла. Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации. Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться. Самое точное направление распознавания – с формата JPEG в ворд.
Источник: http://geek-nose.com/onlajn-raspoznavanie-teksta/
Пожалуйста, оцените статью
4.2 из 5. (Всего голосов:259)
Все статьи раздела
Преобразование изображения PDF в читаемый PDF | Технологические решения
Метод 1. Средство сканирования и распознавания текста
Инструмент улучшения сканирования попытается превратить отсканированные изображения или фотографии бумажных документов в PDF-файлы с возможностью выбора текста. Этот инструмент также очистит контраст страницы и сгладит страницы, где текст может изгибаться из-за книжных переплетов.
Шаг 1. Выберите Scan and OCR Tool
.
Выберите инструмент «Сканирование и распознавание текста» на панели инструментов в правой части экрана.В верхней части экрана откроется панель инструментов.
Шаг 2. Выберите вариант улучшения.
Чтобы улучшить качество документа, выберите параметр «Улучшить» на панели инструментов «Улучшить сканирование», затем выберите «Отсканированный документ».
Шаг 3.Узнавайте и улучшайте
Установите флажок «Распознать текст» и нажмите кнопку «Улучшить». После завершения распознавания текста сохраните документ.
Шаг 4. Правильно распознать текст
По-прежнему в инструменте «Улучшить сканирование» откройте раскрывающийся список «Распознать текст» и выберите «Исправить распознанный текст».Установите флажок «Проверить распознанный текст» и просмотрите подозрительный текст, обнаруженный инструментом, исправьте при необходимости и нажмите «Принять». Сохраните ваш документ.
Шаг 5. Автоматическая маркировка документа
После того, как весь текст будет распознан, перейдите на панель тегов и щелкните правой кнопкой мыши на Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали.Более крупный и жирный текст обычно распознается как заголовок 1 и заголовок 2, даже если они не должны быть заголовками.
Шаг 6. Проверьте и обновите теги документа
Параметр автоматической пометки не будет на 100% правильным. При необходимости проверьте и обновите теги документа. Сохраните ваш документ.
Метод 2. Инструмент редактирования PDF
Параметр «Редактировать PDF» не пытается исправить качество сканирования до распознавания текста и не дает вам возможность исправить распознанный текст.
Шаг 1. Выберите инструмент «Редактировать PDF»
Выберите инструмент «Редактировать PDF» на панели инструментов в правой части экрана.
Acrobat Pro автоматически запустит распознавание текста для вашего документа. После завершения сканирования вы сможете редактировать и выделять большую часть текста в документе. Не забудьте сохранить документ.
Если вы не можете выделить весь текст, определите, является ли текст изображением или нет.Некоторые изображения текста или рукописного ввода могут не распознаваться OCR.
Мы не рекомендуем использовать изображения текста, потому что текст, встроенный в изображения, не может быть обработан вспомогательными технологиями, такими как программы чтения с экрана. В то же время изображения текста создают проблему для мобильной реакции, поскольку изображения текста могут искажаться и становиться неразборчивыми при открытии на мобильном устройстве или планшете. Вы можете попробовать «Улучшенное сканирование» в качестве другого варианта распознавания текста.Короткий раздел рукописного ввода, как и подписи, может быть помечен как рисунок и снабжен альтернативным текстом с соответствующим ему текстом. Для более длинных рукописных документов рассмотрите возможность повторного ввода текста в новый документ.
Шаг 2. Автоматическая маркировка документа
После того, как весь текст будет распознан, перейдите на панель тегов и щелкните правой кнопкой мыши на Нет доступных тегов. Выберите опцию «Добавить теги в документ». Функция Auto-Tag попытается интерпретировать ваш документ на основе размера и стиля шрифтов, которые вы использовали.Более крупный и жирный текст обычно распознается как заголовок 1 и заголовок 2, даже если они не должны быть заголовками.
Шаг 3. Проверьте и обновите теги документа
Параметр автоматической пометки не будет на 100% правильным. При необходимости проверьте и обновите теги документа. Сохраните ваш документ.
10 лучших бесплатных программ для оптического распознавания текста для работы с отсканированными файлами PDF
OCR — это технология, используемая для преобразования файлов изображений в редактируемый текст.Файлы на основе изображений относятся к документам, которые были отсканированы из учебников, журналов или любых текстовых источников и обычно сохраняются в формате PDF. OCR может извлекать текст из этих изображений и делать его редактируемым. В этой статье мы представим 10 лучших бесплатных программ для распознавания текста , которые помогут вам легко редактировать отсканированные файлы PDF.
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement может легко помочь вам в работе со отсканированными документами PDF благодаря передовой технологии распознавания текста.Эта функция может распознавать текст в отсканированных PDF-файлах, чтобы сделать ваш файл и текст доступными для редактирования. Кроме того, он также может конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы документов, такие как Excel, Word, PPT, Text и другие. Качество вашего исходного документа также будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять как интерактивные, так и неинтерактивные формы и создавать новые формы с различными вариантами заполнения форм и создания форм.
2. FreeOCR
Этот онлайн-инструмент OCR совершенно бесплатный и не требует регистрации или предоставления адреса электронной почты. Он поддерживает такие типы файлов изображений, как GIF, JPG, BMP, TIFF или PDF с текстом в несколько столбцов. И он распознает более 30 различных языков. Размер загрузки ограничен 2 МБ или 5000 пикселей, и вы можете загружать только 10 изображений в час.
3. i2OCR
i2OCR имеет возможность загружать типы файлов изображений, такие как JPEG, TIF, BMP, PNG, PBM, GIF, PPM, PGM или URL-адрес изображения.Эта программа позволяет конвертировать изображения с вашего локального диска или из Интернета. Регистрация не требуется. Он поддерживает документы PDF с текстом в несколько столбцов и распознает 33 языка. В отличие от FreeOCR, он позволяет пользователям загружать изображения без каких-либо ограничений по количеству.
4. Онлайн OCR
Online OCR может преобразовывать фотографии и цифровые изображения в текст. Он распознает 32 языка и конвертирует отсканированные PDF-файлы в форматы Text, Word и RTF. Он также извлекает текст из изображений JPG, JPEG, BMP, TIFF и GIF и преобразует его в редактируемые документы Word, Text, PDF, Excel или HTML.Вы можете конвертировать 15 изображений в час.
5. Бесплатное онлайн-распознавание текста
Free Online OCR может преобразовывать снимки экрана, отсканированные документы, факсы и фотографии в доступный для поиска и редактируемый текст, такой как TXT, DOC, RTF и PDF. Он поддерживает форматы BMP, PDF, PNG, TIFF, JPG (JPEG) и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Вам необходимо убедиться, что размер любого загруженного файла не превышает 100 МБ.Эта программа позволит вам сжать целевой файл и оптимизировать его для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR — это удобный и мощный конвертер изображений OCR, предназначенный как для профессиональных, так и для домашних пользователей. Он может читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т. Д. И конвертировать файлы в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Независимо от размера отсканированного PDF-файла или файла изображения onOCR справится с этим.Бесплатное распознавание текста может преобразовать нередактируемый документ в текст, который можно копировать и редактировать любым удобным для вас способом. Он также позволяет обрабатывать как большие, так и маленькие изображения и превращать их в редактируемый текст.
9. Инвестинтех
Able2Extract от Investintech — это мощный инструмент для управления PDF-файлами, который можно использовать для преобразования отсканированных PDF-файлов в более 10 различных редактируемых типов файлов. Вы также можете создавать защищенные PDF-файлы практически из любого типа файлов, просматривать и редактировать PDF-файлы, извлекать текст из отсканированного документа, а также изменять и предварительно просматривать преобразованный файл.
10. OCRGeek
OCRGeek.com позволяет выполнять онлайн-оптическое распознавание текста партиями. Это позволяет без проблем загружать несколько файлов одновременно. Весь процесс быстрый и легкий. Все ваши документы будут сразу упорядочены и преобразованы в формат TXT. OCRgeek может поддерживать следующие форматы ввода: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Видео: 5 лучших программ для распознавания текста
Если вы хотите узнать больше полезных видеороликов о PDFelement и других продуктах Wondershare, вы можете найти больше в сообществе Wondershare Video Community.
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
Как извлечь текст из PDF за секунды
Извлечь текст из PDF непросто. Не многие программы чтения PDF-файлов способны извлекать текст из изображений PDF или сканированных PDF-файлов. Проблема усугубляется, если в вашем PDF-файле есть графики или таблицы или любые другие нелинейные данные, которые нельзя просто скопировать и вставить.В этой статье мы обсудим, как легко извлечь текст из PDF за секунды.
Вы хотите, чтобы правильный текст извлекался из PDF каждый раз без ошибок. Лучше всего это сделать с помощью технологии распознавания текста.
Что такое OCR?
OCR — это оптическое распознавание символов. OCR — это интеллектуальная технология, которая считывает и извлекает текст из изображений и PDF-файлов. Это самый быстрый, дешевый и умный способ извлечения текста из любого счета, отсканированного PDF-файла или изображения.Вы можете сделать это на компьютерах Linux, Windows или Mac, а также на языке Python.
Как извлечь текст из PDF
Шаг 1. Загрузите PDF-файл
Войдите в наш инструмент OCR и выберите файл PDF для загрузки. Вы можете автоматизировать этот процесс или загружать по одному документу за раз.
Шаг 2: Добавьте правила синтаксического анализа
Перед тем, как отделить текст от PDF, добавьте правила для автоматизации и ускорения процесса. Таким образом, наша система будет знать, как обрабатывать такие вещи, как электронная почта и номера телефонов.
Шаг 3. Экспортируйте и сохраните текст.
Вот и все. Ваш текст будет извлечен прямо из изображения или PDF-файла, чтобы вы могли использовать его по своему усмотрению. Мы даже структурируем его для вас в соответствии с вашими правилами.
Docparser на 100% бесплатен в течение 14 дней. Кредитная карта не требуется
В качестве облачного решения Docparser доступен, где бы вы ни находились. Используйте любой компьютер или мобильное устройство и извлекайте текст из PDF за 30 секунд.
Какой тип текста можно извлекать из PDF-файлов?
- Счета-фактуры
- Заказы на поставку
- Формы заявлений
- Стандартизированные контракты
- Заказы на доставку
- накладная
- Наряд на работу
- Сгенерированный отчет
- Выписки из банка
- Заполняемая форма PDF
Docparser позволяет не только легко и удобно извлекать данные из pdf, но также может сделать это программным и автоматическим.Он также может извлекать текст из PDF-файлов с помощью командной строки.
После загрузки документа вы можете извлекать текст из PDF-файлов для преобразования PDF-файлов в электронные таблицы, файлы MS Word, JSON, XML и CSV.
Наш превосходный механизм синтаксического анализа поставляется с предустановками синтаксического анализа, которые можно настроить в соответствии с требованиями вашего бизнеса. Если ваш PDF-файл содержит табличные или графические данные, воспользуйтесь нашим механизмом синтаксического анализа. После того, как вы настроите свои правила синтаксического анализа, Docparser позаботится обо всем остальном. Он запоминает ваши настройки для одного и того же типа документов и файлов, поэтому вам не нужно настраивать его снова и снова.
Если у вас есть пакет файлов, из которых нужно извлечь текст, не беспокойтесь. Вы также можете одновременно загружать пакет файлов и обрабатывать их одновременно. Таким образом вы экономите время и силы.
Docparser также может быть интегрирован с сотнями приложений как во внешнем, так и в бэк-энде вашего бизнес-процесса. Эти интеграции делают процесс извлечения данных автоматическим. Вы можете импортировать документы, используя интеграции, и извлекать из них текст, или вы можете извлекать данные и экспортировать их в любом приложении или формате, который вам нравится.
В общем, если ваш бизнес имеет дело с огромным количеством PDF-файлов любого типа, то есть изображений, отсканированных файлов, вы можете безопасно и надежно использовать Docparser для автоматизации рабочего процесса вашего бизнеса. После настройки процесс извлечения данных из PDF-файлов выполняется автоматически без какого-либо ручного вмешательства.
Извлечение текста из PDF-файла с любого компьютера или мобильного устройства
Docparser — это облачное программное обеспечение, которое можно использовать в любой операционной системе — Windows, Mac или Linux.Это не EXE-файл, предназначенный для конкретной машины. Вы можете работать со своим Docparser и получать к нему доступ с любого компьютера в любом месте.
Даже если вы собираетесь использовать его на мобильном телефоне, вам не нужно загружать какое-либо приложение. Просто откройте docparser.com/, войдите в систему и извлеките любой текст, который вам нужно извлечь из файлов PDF.
Есть ли у вас какие-либо индивидуальные бизнес-требования? Не знаете, как вписать Docparser в свой рабочий процесс? Вам нужно извлечь данные из ваших пользовательских файлов PDF? Сообщите нам, и мы свяжемся с вами, чтобы помочь.
Оптическое распознавание символов и как это работает
Ручка и бумага могут быть устаревшими, но они не исчезли полностью. Предпочитаете ли вы делать заметки вручную или работать с формами, которые заполняются вручную, бывают моменты, когда вам нужно перенести эту информацию в цифровую форму.
Набор рукописных данных любого типа — утомительный способ оцифровки. Вот где оптическое распознавание символов спасает положение.
Что такое оптическое распознавание символов (OCR)?
Технология оптического распознавания символов (OCR) означает оптическое распознавание символов.Это популярное программное обеспечение для распознавания текста внутри изображений, например отсканированных документов и фотографий. OCR используется для преобразования практически любых изображений, содержащих письменный текст (напечатанный, рукописный или напечатанный), в машиночитаемые данные.
Оцифровка документов с помощью OCR позволяет выполнять поиск по ключевым словам в тексте. Lumin PDF предлагает OCF как одну из многих полезных функций для работы с PDF.
Как работает OCR?
OCR преобразует отсканированную или рукописную страницу в машиночитаемую версию.Что касается PDF, это означает, что вы можете сканировать документы, загружать их в Lumin и вносить необходимые изменения в соответствии с вашими предпочтениями. Технология OCR экономит время; Кроме того, если вы потеряете исходную версию файла из-за сбоя и у вас есть бумажная копия, вам просто нужно отсканировать ее, и с этого момента больше не нужно набирать ее заново. Отсканировав документ, вы сможете вносить изменения прямо в сам файл и быстро искать нужные части документов.
Что такое Lumin PDF?
По сути Lumin PDF — это программа, предназначенная для облегчения работы с файлами PDF как для занятых профессионалов, так и для государственных служащих, студентов.Возможно, вы сталкивались с пересылкой по электронной почте, чтобы внести небольшие изменения в файл PDF, или многократным сканированием документа PDF для добавления подписи. Мы считаем, что вы, возможно, расстроились из-за рутинной работы с PDF. Однако не волнуйтесь, эти дни давно в прошлом. Lumin PDF заменяет утомительные методы редактирования PDF эффективными цифровыми процессами.
Как работает Lumin PDF?
Lumin PDF позволяет пользователям загружать, редактировать и совместно работать над файлами PDF в облаке. Вы также можете подключить Lumin PDF к Google Диску, чтобы получить доступ к вашим сохраненным документам.Lumin PDF предоставляет вам надежный набор полезных функций, которые сделают повседневную работу с файлами PDF простой и интуитивно понятной.
Lumin предлагает все функции, необходимые для быстрой и простой работы с PDF:
Когда дело доходит до аннотирования файлов PDF, многие люди ограничены в возможностях эффективного аннотирования. Lumin PDF решает эту проблему с помощью надежного набора эффективных функций. Lumin PDF позволяет комментировать документы PDF в Интернете, на Mac, Windows или с мобильного устройства. Вы также можете использовать Lumin PDF как расширение для Google Диска и комфортно работать с Google Docs, Google Sheets и вашими PDF-файлами.С помощью Lumin PDF вы можете:
- Добавить комментарии в файл PDF
- Добавить комментарии в файл PDF с помощью параметра «Свободный текст»
- Сделать комментарий к файлу PDF, нарисовав
- Добавить фигуры
- Выделить фигуры
- Вставить изображение
Страницы PDF часто требуют корректировки. Однако вы можете не знать, как это сделать, или не иметь надежных инструментов, чтобы выполнить это без каких-либо нежелательных хлопот. Lumin PDF имеет множество полезных функций для эффективного выполнения различных манипуляций со страницами.Используя Lumin PDF, вы сможете:
- Поворачивать страницы
- Удалить страницы
- Изменить порядок страниц в PDF
- Вставить пустую страницу
- Обрезать страницы
Нет необходимости просматривать хлопоты загрузки и выгрузки для внесения небольших изменений в документ PDF. Используя Lumin PDF, вы можете общаться с членами вашей команды прямо в документе. Вместо того, чтобы тратить время на пересылку форм и документов между членами команды или клиентами, вы можете использовать Lumin PDF для мгновенного редактирования и совместной работы и более быстрых результатов для вашей организации.Lumin PDF предоставляет пользователям онлайн-инструменты для удобного редактирования. Оптическое распознавание символов — одно из них.
Онлайн-сканер PDF OCR — преобразование PDF в редактируемый текст
Как распознать PDF?
Используйте конвертер OCR в pdfFiller, чтобы извлекать и систематизировать данные из любых ваших файлов.
В своих документах выберите файл, который вы будете использовать в качестве шаблона, и воспользуйтесь функцией Извлечь в Bulk .
Добавляйте и редактируйте поля с извлеченными вами данными. Добавьте имена в поля для облегчения соответствия столбцу в электронной таблице.
Загрузите документы, изображения или отсканированные файлы, которые необходимо распознать, и нажмите Пуск .
Загрузите электронную таблицу, содержащую извлеченные данные из вашего шаблона.
Как использовать технологию распознавания текста PDF с pdfFiller:
1
Откройте файл, который вы будете использовать в качестве шаблона, и определите в нем поля данных.
2
Загрузите любые похожие документы, из которых вам нужно извлечь данные.
3
Распознайте текст в файлах и экспортируйте его.
4
Загрузите электронную таблицу, содержащую извлеченные данные.
PDF7: выполнение оптического распознавания текста в отсканированном PDF-документе для отображения фактического текста
Цель этого метода — гарантировать, что визуально отображаемый текст
представлен таким образом, что его можно воспринимать без его
визуальное представление, мешающее его читабельности.
Документ, состоящий из отсканированных изображений текста, изначально недоступен
потому что содержание документа — изображения, а не текст, доступный для поиска.
Вспомогательные технологии не могут читать или извлекать слова; пользователи не могут
выделять, редактировать, изменять размер или перекомпоновку текста, а также они не могут изменять текст и фон
цвета; и авторы не могут управлять PDF-файлом для обеспечения доступности.
По этим причинам авторам следует использовать реальный текст, а не изображения.
текста, используя инструмент разработки, такой как Microsoft Word или Oracle Open
Office для создания и преобразования содержимого в PDF.
Если авторы не имеют доступа к исходному файлу и инструменту разработки,
отсканированные изображения текста можно преобразовать в PDF с помощью оптических символов
распознавание (OCR). Затем Adobe Acrobat Pro можно использовать для создания доступных
текст.
Этот пример показан с Adobe Acrobat Pro. Существуют и другие программные инструменты, выполняющие аналогичные функции. См. Список других программных инструментов в PDF Authoring Tools, которые обеспечивают поддержку специальных возможностей.
В этом примере используется простое сканированное изображение текста на одной странице.Для обеспечения
что фактический текст хранится в документе, выполните следующие действия:
Отсканируйте документ с максимально возможным разрешением для улучшения
производительность OCR.Загрузите отсканированный документ в Acrobat Acrobat Pro. Выберите Документ> OCR.
Распознавание текста> Распознать текст с помощью OCR …В следующем диалоговом окне выберите переключатель Все страницы в разделе Страницы
(или Текущая страница, если вы конвертируете только одну страницу), а затем выберите
ХОРОШО.В списке «Параметры» выберите «Изменить». В следующем диалоговом окне выберите
Форматированный текст и графика в раскрывающемся списке «Стиль вывода PDF».
Это важно для обеспечения доступности.В зависимости от разрешения и четкости текста OCR преобразует
изображения слов и символов в фактический текст. Напишите что Acrobat
Pro не распознает, указан как «подозреваемый в распознавании текста» или
текстовый элемент, который, как подозревает Acrobat, был распознан неправильно.Чтобы исправить подозреваемых, выберите «Документ»> «Распознавание текста»> «Найти».
Первый подозреваемый OCR. Acrobat Pro представляет каждого подозреваемого по одному,
которые можно исправить с помощью инструментов коррекции Acrobat Pro.Выполнить «Дополнительно»> «Специальные возможности»> «Добавить теги к документу»
Проверка доступности: «Дополнительно»> «Специальные возможности»> «Полный»
Проверить …
Примечание: В качестве альтернативы вы можете использовать Документ> OCR
Распознавание текста> Найти всех подозреваемых OCR для отображения всех подозреваемых OCR
в то же время для более быстрого редактирования.
На следующем изображении показан отсканированный одностраничный документ в Adobe Acrobat.
Pro.
На следующем изображении показано преобразованное содержимое после добавления тегов в
документ. Вероятно, потребуется использовать TouchUp Reading
Инструмент заказа и панель тегов, чтобы правильно пометить контент для предполагаемого
итоговый документ. В этом примере изображение спирального переплета книги
был отмечен при преобразовании. Использовался инструмент TouchUp Reading Order.
, чтобы скрыть изображение как фоновое (декоративное) (см. PDF4: Скрытие декоративных изображений с помощью тега Artifact в документах PDF ).Рецепт
заголовки были помечены как заголовки первого уровня.
Примечание. Acrobat Pro может автоматически добавлять теги при запуске файла.
через OCR.
Этот пример показан в действии на рабочем примере генерации фактического текста и результата выполнения OCR.
Ресурсы предназначены только для информационных целей, без какой-либо поддержки.
Процедура
Для каждой страницы, преобразованной в текст с помощью OCR, убедитесь, что результат
PDF-файл был преобразован правильно одним из следующих способов:Прочтите PDF-документ с помощью программы чтения с экрана или инструмента, который читает вслух, прислушиваясь к тому, что весь текст читается правильно
и в правильном порядке чтения.Сохраните документ как текст и убедитесь, что преобразованный текст
является полным и в правильном порядке чтения.Используйте инструмент, способный отображать преобразованный контент
чтобы открыть PDF-документ и убедиться, что весь текст был преобразован
и находится в правильном порядке чтения.Используйте инструмент, который открывает доступ к документу
API и убедитесь, что весь текст был преобразован и находится в правильном
порядок чтения.
Ожидаемые результаты
Если это достаточный метод для критерия успеха, неудача этой процедуры тестирования не обязательно означает, что критерий успеха не был удовлетворен каким-либо другим способом, только то, что этот метод не был успешным реализованы и не могут использоваться для подтверждения соответствия.
Исправление отсканированных документов | Технологии преподавания и обучения
Исправление для обеспечения доступности более эффективно при запуске с цифровым документом.Идеальная ситуация — начать с исходного документа, который был сохранен в формате PDF надлежащим образом с помощью специальных возможностей, таких как теги и использование заголовков в качестве закладок. Если источником является отсканированный документ, который сохраняется / конвертируется в PDF, рабочий процесс значительно усложняется.
Как проверить доступность PDF-текста
Сначала определите, был ли документ PDF создан из цифрового текста или из отсканированного изображения текста. Отсканированное изображение текста недоступно, и к нему необходимо применить оптическое распознавание символов (OCR).Есть два процесса, чтобы указать, будет ли текст доступен для чтения с экрана: щелчок по документу или попытка выделить текст.
Вариант A. Щелкните документ
Часто самый простой способ проверить текст — это щелкнуть документ, чтобы увидеть, выделяется ли текст или вся страница. Открыв документ в Adobe Acrobat, щелкните в любом месте документа. Если выделяется вся страница, скорее всего, это отсканированное изображение. Если отображается курсор, документ PDF содержит текст.
Вариант Б. Попробуйте выделить текст
Альтернативный способ проверить текст в PDF-файле — попытаться выделить весь текст.В верхнем меню навигации Acrobat нажмите «Изменить», а затем «Выбрать все».
Выделенные текстовые элементы. Если текстовые элементы выделены, документ содержит текст. (См. Рисунок 1)
[Рис. 1] Снимок экрана документа в Adobe Acrobat под названием «Фокус на полевой эпидемиологии», на котором показаны выделенные текстовые элементы.
Если «Выбрать все неактивно». Если «Выбрать все» не активен (это происходит, если документ, представляющий собой изображение, уже выбран / выделен или если вы запустили определенный инструмент), нажмите «Редактировать», а затем нажмите «Редактировать текст и изображения»).Или, когда вы нажимаете «Выбрать все», появляется окно с предупреждением о сканированной странице, вы знаете, что документ не содержит текста. Окно предупреждения немедленно предложит вам решить, запускать ли распознавание текста. (Пример снимка экрана см. На Рисунке 2)
[Рис. 2] Скриншот окна Adobe Acrobat с документом в виде изображения, отсканированная версия документа под названием «Оценка достоверности и надежности диагностических и проверочных тестов». Вверху документа появляется окно «Предупреждение о сканированной странице», в котором указано: «Эта страница содержит только изображение.Хотите запустить распознавание текста, чтобы текст на этой странице стал доступным? »Пользователи могут выбрать« Да »или« Нет »для запуска программного обеспечения для распознавания текста.
Как создать редактируемый текст в Adobe Acrobat
При создании редактируемого текста процесс начинается с запуска распознавания текста. Если вы проверили наличие текста и отображается окно «Предупреждение о сканированной странице», щелкните ссылку «Да», чтобы запустить распознавание текста.
Как запустить распознавание текста вручную
Чтобы вручную создать редактируемый текст, выполните одно из следующих действий:
- В меню Acrobat нажмите «Редактировать», а затем нажмите «Редактировать текст и изображения»
- Нажмите «Редактировать PDF» на панели инструментов (по умолчанию правая сторона экрана), и вам будет предложено начать распознавание текста.
Установить язык и параметры распознавания
Как только вы дадите разрешение, процесс распознавания текста, «Оптическое распознавание символов (OCR)» начнется немедленно.В зависимости от того, запускаете ли вы процесс из окна предупреждения или вручную, он может предложить вам использовать английский в качестве языка документа до или после завершения процесса распознавания текста.
Ручной процесс автоматически преобразует документ в редактируемый текст и изображения.
Если вы используете процесс через окно предупреждения, вы также можете выбрать, для каких страниц распознавать текст, параметры вывода и размер понижающей дискретизации.
- Использовать настройки по умолчанию для всех страниц
- Выберите соответствующий язык
- Установить для вывода редактируемый текст и изображения
- Оставьте для параметра Downsample To значение по умолчанию, которое является максимальным значением
См. Рисунок 3, где показан пример снимка экрана с предупреждением «Распознать текст».
[Рис. 3] Снимок экрана с окном «Распознать текст» и меню в Adobe Acrobat, которые позволяют пользователям выбирать свои настройки для инструмента оптимального распознавания символов. Пользователи могут выбрать «Все страницы», «Текущая страница» или установить выбор страницы (например, со страницы 1 на страницу 3). Меню «Настройки» содержит «Язык документа» и раскрывающееся меню для вывода инструмента, включая «Изображения с возможностью поиска», «Изображение с возможностью поиска (точное) и« Редактируемый текст и изображения »(выделено на снимке экрана).Кнопки «ОК» и «Отмена» переключают элементы управления в этом окне.
Проверить точность и отредактировать текстовые ошибки
Если исходный материал представляет собой отсканированный документ (текст без возможности выбора), необходимо выполнить оптическое распознавание символов (OCR), чтобы преобразовать изображение в редактируемый текст. Adobe Acrobat отлично справляется с распознаванием текста в документе, но почти никогда не будет идеальным. Текст, который часто выглядит растянутым, не будет идентифицирован, а текст в изображениях, диаграммах и графиках часто неверен.
Варианты устранения проблем со сканированными документами
После завершения процесса оптического распознавания текста вам необходимо просмотреть конечный продукт и исправить любые ошибки. Есть два варианта:
- Экспорт документа и повторное сохранение
- Использование инструмента чтения и редактирования Adobe Acrobat
Вариант 1. Экспорт в Microsoft Word, исправление ошибок и повторное сохранение в формате PDF
Этот вариант может быть самым простым способом исправить текстовые ошибки, особенно если отсканированный документ длинный или явно вызывает проблемы с распознаванием (например,g., размазанный текст, искривленные слова у внутреннего корешка книги и т. д.). Выполните следующие действия, чтобы экспортировать и повторно сохранить документ.
Шаг первый. Щелкните «Файл». Щелкните «Экспорт в». Щелкните «Microsoft Word». Нажмите «Word Document»
Шаг второй. Выберите место для сохранения документа Word, затем нажмите «Сохранить».
Шаг третий. Откройте сохраненный текстовый документ (желательно с открытым PDF-файлом на другом экране монитора), затем визуально сравните документы и исправьте любые ошибки.
Шаг четвертый. Сохраните документ Word как новый файл PDF.
- Office 2016 и более поздние версии. Щелкните «Файл», а затем «Сохранить как Adobe PDF». Нажмите «Параметры» и обязательно установите следующие флажки: «Включить специальные возможности и отображение с тегами Adobe PDF» и «Создать закладки», а затем нажмите «Преобразовать заголовки слов в закладки». Нажмите «ОК», а затем введите имя файла, которое позволит вам отличить исправленный файл от оригинала, а затем нажмите «Сохранить».«
- Office 2010 и 2013. Щелкните «Сохранить как», затем щелкните стрелку раскрывающегося списка рядом с параметром «Сохранить как тип» и, наконец, щелкните «PDF». Щелкните «Параметры» и обязательно установите флажок «Теги структуры документа для обеспечения доступности». Нажмите «ОК», затем введите имя файла, которое позволит вам отличить измененный файл от оригинала, а затем нажмите «Сохранить».
Вариант 2. Используйте параметр Adobe Acrobat «Прочитать вслух и отредактировать»
Эта функция позволяет работать с PDF напрямую.Это может быть отличным решением для коротких документов с четким сканированием, но может быть сложно использовать для длинных документов или документов с большим количеством ошибок.
Шаг первый. В строке меню Acrobat нажмите «Просмотр», затем «Чтение вслух» и, наконец, «Активировать чтение вслух», чтобы включить программу чтения. (Пример снимка экрана см. На рис. 4)
Шаг второй. Вернитесь в «Просмотр» и выберите «Читать только эту страницу» или «Читать до конца документа». Использование того же «Просмотр» и затем щелчок по меню «Прочитать вслух» во время работы инструмента чтения вслух позволит вам приостановить / возобновить и остановить голос.
Шаг третий. Щелкните «Редактировать». Нажмите «Редактировать текст и изображения» и используйте функции редактирования Adobe Acrobat, чтобы исправить любой ошибочный текст.
[Рисунок 4] Снимок экрана окна Adobe Acrobat с живым документом и двумя открытыми меню.
Добавить комментарий