
Привет пока$ точное совпадение (начинается и заканчивается как Привет пока)воробушки соответствует любой строке, в которой есть текст воробушки
Квантификаторы — * + ? и {}
abc* соответствует строке, в которой после ab следует 0 или более символов c -> тестabc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bcОператор ИЛИ — | или []
a(b|c) соответствует строке, в которой после a следует b или c -> тестa[bc] как и в предыдущем примере
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор . с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее.
У операторов \d, \w и \s также есть отрицания ― \D, \W и \S соответственно.
Например, оператор \D будет искать соответствия противоположенные \d.
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например Обычные квантификаторы * + ? {m,n} являются жадными *? +? ?? {m,n}? *+ ++ ?+ {m,n+} подробнее Соответствие не будет найдено, поскольку после символа «<» .*+ «скушает» все оставшиеся: span>123</span> . После чего символ «>» будет не найден. буква n должна быть маленькой 852 0 Удобная шпаргалка по простым регулярным выражениям php с примерами. [0-9] — цифры от 0 до 9. [02468] — четная цифра. [A-Za-z0-9] — все символы латинского алфавита и цифры. \d{2} — две цифры. \w{2,} — от двух и более букв. \w{2,7} — от двух до семи букв. \d{,2} — до двух цифр. \d*- любое количество цифр подряд, включая ни одной. .* — любое количество любых символов, включая ни одного. \d? — ноль или одна цифра. конец$ — найдёт все строки, заканчивающиеся на слово "конец". \. — найдёт точки в тексте. \(.*\) — найдёт все символы в скобках. \d\d\d[56] — найдёт все четырёхзначные числа с цифрами 5 и 6 на конце, например, 2015 и 2016. Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание. Скачать в PDF, PNG. Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид: Здесь символ ^ обозначает начало строки. Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, d соответствует любой цифре от 0 до 9 включительно, w соответствует буквам и цифрам, а W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так: POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов. Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе каждое слово, включающее букву “q”, за которой не следует “werty”». Приведенный выше код начинается с поиска любых символов, кроме пробела ( [^s]* ), за которыми следует q . Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон: По умолчанию кванторы — «жадные». Поэтому квантор + , означающий «один или больше раз», будет соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код: Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой: Приведенный выше шаблон найдет в этой строке вот такую подстроку: Он оказался слишком жадным, захватив наибольший кусок текста, который смог. Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ? ) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности: Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»). Шаблон для нахождения точки таков: Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке. Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон: Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F: Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона из другой его части; а также при подстановке строк. Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»: Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более цифр ( [0-9]+ ), и наконец 1 . Последняя часть шаблона ссылается на первую группу и ищет то же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как 1 будет искать «aaa» после числа. Одним из наиболее полезных инструментов в регулярных выражениях является подстановка строк. При замене текста можно сослаться на найденную группу, используя $n . Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции): Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой: Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1 . Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ( $3 ). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или ), выделив им вторую группу, найденную по шаблону ( $2 ). Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще используется «/»), и выглядит все таким образом: Модификаторы добавляются в конец этой строки, вот так: Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон: Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG. Регулярные выражения позволяют найти в строке последовательности, соответствующие шаблону. Вместо набора символов может быть использовано обозначение любого символа — точка, может быть указан конкретный набор символов (поддерживаются последовательности — упоминавшиеся "0-9"). Может быть указано "кроме данного набора символов". Указатель количества символов в официальной документации по php называется "квантификатор". Термин удобный и не несет в себе кривотолков. Итак, квантификатор может иметь как конкретное значение — либо одно фиксированное ("<6>"), либо как числовой промежуток ("<6,8>"), так и абстрактное "любое число, в т.ч. 0" ("*"), "любое натуральное число" — от 1 до бесконечности ("+": "document[0-9]+. Для более гибкого поиска сочетаний эти связки "набор символов — квантификатор" можно объединять в метаструктуры. Как всякий гибкий инструмент, регулярные выражения гибки, но не абсолютно: зона их применения ограничена. Например, если вам надо заменить в тексте одну фиксированную строку на другую, фиксированную опять же, пользуйтесь str_replace. Разработчики php слезно умоляют не пользоваться ради этого сложными функциями ereg_replace или preg_replace, ведь при их вызове происходит процесс интерпретации строки, а это серьезно потребляет ресурсы системы. К сожалению, это любимые грабли начинающих php-программистов. Пользуйтесь функциями регулярных выражений только если вы не знаете точно, какая "там" строка. Из примеров: поисковый код , в котором из строки поиска вырезаются служебные символы и короткие слова а так же вырезаются лишние пробелы (вернее, все пробелы сжимаются: " +" заменяется на один пробел). Не пользуйтесь классом символов для обозначения всего лишь одного (вместо "[ ]+" вполне сойдет " +"). Не пишите в классе символов точку это ведь любой символ, тогда другие символы в классе будут просто лишними (а в негативном классе получится отрицание всех символов). Квантификатором можно указать как конкретное значение, так и пределы. Если число заданных подпадает под пределы квантификатора, фрагмент выражения считается совпавшим с разбираемой строкой. Синтаксис: Если нужно указать только необходимый минимум, а максимума нет, просто ставим запятую и не пишем второе число: "<5,>" ("минимум 5"). Для наиболее часто употребляемых квантификаторов есть специальные обозначения: На практике такие символы используются чаще, чем фигурные скобки. Функция preg_grep — Возвращает массив вхождений, которые соответствуют шаблону array preg_grep (string pattern, array input [, int flags]) preg_grep() возвращает массив, состоящий из элементов входящего массива input, которые соответствуют заданному шаблону pattern. Параметр flags может принимать следующие значения: PREG_GREP_INVERT Функция preg_match — Выполняет проверку на соответствие регулярному выражению int preg_match ( string pattern, string subject [, array matches [, int flags [, int offset]]]) Ищет в заданном тексте subject совпадения с шаблоном pattern В случае, если дополнительный параметр matches указан, он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске, и так далее. flags может принимать следующие значения: PREG_OFFSET_CAPTURE Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset). Функция preg_match() возвращает количество найденных соответствий. Это может быть 0 (совпадения не найдены) и 1, поскольку preg_match() прекращает свою работу после первого найденного совпадения. Если необходимо найти либо сосчитать все совпадения, следует воспользоваться функцией preg_match_all(). Функция preg_match() возвращает FALSE в случае, если во время выполнения возникли какие-либо ошибки. Рекомендация: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Используйте для этого strpos() либо strstr(), поскольку они выполнят эту задачу гораздо быстрее. Функция preg_match_all — Выполняет глобальный поиск шаблона в строке int preg_match_all (string pattern, string subject, array matches [, int flags [, int offset]]) Ищет в строке subject все совпадения с шаблоном pattern и помещает результат в массив matches в порядке, определяемом комбинацией флагов flags. После нахождения первого соответствия последующие поиски будут осуществляться не с начала строки, а от конца последнего найденного вхождения. Дополнительный параметр flags может комбинировать следующие значения (необходимо понимать, что использование PREG_PATTERN_ORDER одновременно с PREG_SET_ORDER бессмысленно): PREG_PATTERN_ORDER Как мы видим, $out[0] содержит массив полных вхождений шаблона, а элемент $out[1] содержит массив подстрок, содержащихся в тегах. PREG_SET_ORDER В таком случае массив $matches[0] содержит первый набор вхождений, а именно: элемент $matches[0][0] содержит первое вхождение всего шаблона, элемент $matches[0][1] содержит первое вхождение первой подмаски, и так далее. Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора. PREG_OFFSET_CAPTURE В случае, если никакой флаг не используется, по умолчанию используется PREG_PATTERN_ORDER. Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset). Возвращает количество найденных вхождений шаблона (может быть нулем) либо FALSE, если во время выполнения возникли какие-либо ошибки. Функция preg_quote — Экранирует символы в регулярных выражениях string preg_quote (string str [, string delimiter]) Функция preg_quote() принимает строку str и добавляет обратный слеш перед каждым служебным символом. ] $ ( ) < >= ! | : Функция preg_replace — Выполняет поиск и замену по регулярному выражению mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit]) Выполняет поиск в строке subject совпадений с шаблоном pattern и заменяет их на replacement. В случае, если параметр limit указан, будет произведена замена limit вхождений шаблона; в случае, если limit опущен либо равняется -1, будут заменены все вхождения шаблона. Replacement может содержать ссылки вида \n либо (начиная с PHP 4.0.4) $n, причем последний вариант предпочтительней. Каждая такая ссылка, будет заменена на подстроку, соответствующую n’нной заключенной в круглые скобки подмаске. n может принимать значения от 0 до 99, причем ссылка \0 (либо $0) соответствует вхождению всего шаблона. Подмаски нумеруются слева направо, начиная с единицы. При использовании замены по шаблону с использованием ссылок на подмаски может возникнуть ситуация, когда непосредственно за маской следует цифра. В таком случае нотация вида \n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией $<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1. Результатом работы этого примера будет: Если во время выполнения функции были обнаружены совпадения с шаблоном, будет возвращено измененное значение subject, в противном случае будет возвращен исходный текст subject. Первые три параметра функции preg_replace() могут быть одномерными массивами. В случае, если массив использует ключи, при обработке массива они будут взяты в том порядке, в котором они расположены в массиве. Указание ключей в массиве для pattern и replacement не является обязательным. Если вы все же решили использовать индексы, для сопоставления шаблонов и строк, участвующих в замене, используйте функцию ksort() для каждого из массивов. В случае, если параметр subject является массивом, поиск и замена по шаблону производятся для каждого из его элементов. Возвращаемый результат также будет массивом. В случае, если параметры pattern и replacement являются массивами, preg_replace() поочередно извлекает из обоих массивов по паре элементов и использует их для операции поиска и замены. Если массив replacement содержит больше элементов, чем pattern, вместо недостающих элементов для замены будут взяты пустые строки. В случае, если pattern является массивом, а replacement — строкой, по каждому элементу массива pattern будет осущесвтлен поиск и замена на pattern (шаблоном будут поочередно все элементы массива, в то время как строка замены остается фиксированной). Вариант, когда pattern является строкой, а replacement — массивом, не имеет смысла. Модификатор /e меняет поведение функции preg_replace() таким образом, что параметр replacement после выполнения необходимых подстановок интерпретируется как PHP-код и только после этого используется для замены. Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса. Этот пример выведет: Функция preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием функции обратного вызова mixed preg_replace_callback (mixed pattern, callback callback, mixed subject [, int limit]) Поведение этой функции во многом напоминает preg_replace(), за исключением того, что вместо параметра replacement необходимо указывать callback функцию, которой в качестве входящего параметра передается массив найденных вхождений. Ожидаемый результат — строка, которой будет произведена замена. Функция preg_split — Разбивает строку по регулярному выражению array preg_split (string pattern, string subject [, int limit [, int flags]]) Возвращает массив, состоящий из подстрок заданной строки subject, которая разбита по границам, соответствующим шаблону pattern. В случае, если параметр limit указан, функция возвращает не более, чем limit подстрок. Специальное значение limit, равное -1, подразумевает отсутствие ограничения, это весьма полезно для указания еще одного опционального параметра flags. flags может быть произвольной комбинацией следующих флагов (соединение происходит при помощи оператора ‘|’): PREG_SPLIT_NO_EMPTY PREG_SPLIT_DELIM_CAPTURE PREG_SPLIT_OFFSET_CAPTURE Для чего используются регулярные выражения: PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP . Ниже приведен синтаксис функций регулярных выражений, таких как preg_match , preg_split или PHP regexp replace : «имя_функции» — это либо preg_match , либо preg_split , либо preg_replace . Теперь рассмотрим практические примеры использования упомянутых выше функций. В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе . В приведенном ниже коде показан вариант реализации данного примера: Рассмотрим ту часть кода, которая отвечает за вывод «preg_match (‘/ guru /’, $ my_url)» . «preg_match(…)» — функция PHP match regexp . Теперь рассмотрим сложный PHP regexp пример, в котором проверяется валидность адреса электронной почты: Результат: адрес электронной почты name@company.[a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире. Метасимволы являются полезными, когда речь идет о сопоставлении на соответствие шаблонам. Данная публикация представляет собой перевод статьи « PHP Regular Expressions » , подготовленной дружной командой проекта Интернет-технологии.ру^. бег$
бег$бег
бегун\b Граница слова а\b а он когда завтра? \bон вон он \B Не граница слова \Bон вон он \G Предыдущий успешный поиск \Ga aaa aaa (поиск остановился на 4-й позиции — там, где не нашлось a) . любой символ кроме символа новой строки «\n» м.й мой май мама Символьный класс — Набор символов в квадратных скобках [ ] в данном месте — один из перечисленных символов 2[19]5 215 265 21 295 он[?!] тон? Нет, не тон. Полутон! Возможно указание диапазонов символов.  [:word:]]
[:word:]]Квантификация (сколько раз предшествующее выражение может встречаться.) {n} ровно n раз [0-9]{3} 316 29 15 1 {m,n} от m до n раз [0-9]{2,3} 316 29 15 1 {m,} не менее m раз cто{2,}й стой, стоой, стооой {0,n} не более n раз сто{0,3}й стой, стоой, стооой, стоооой * ноль или более раз. Эквивалентно {0,} сто* ст сто стоо + Один или более раз. Эквивалентно {1,} сто+ ст сто стоо ? Ноль или одно. Эквивалентно {0,1} сто? ст сто стоо cт?л стол стул ст5л стл Жадная и ленивая квантификация Жадная квантификация Максимально длинная строка из возможных <.  *>
*><span>123</span> \(.+\) (812)234, (812)235 cт.{3,}й стооооой. Что это за лай Ленивая квантификация Минимально длинная строка из возможных <.*?> <span>123</span> \(.+?\) (812)234,(812)235 ст.{3,}?й стооооой. Что это за лай Сверхжадная Действует как жадный, при этом не возвращается к точке возврата <.*+> <span>123</span> 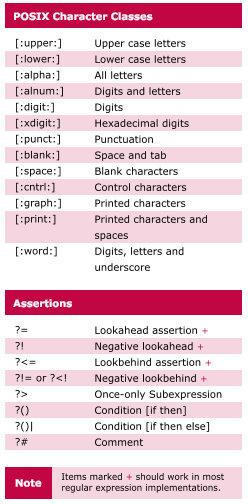
Группировка () для групировки. Шаблон внутри как единое целое. может быть квантифицирован ([a-z][0-9]-)+ a7-b9-c26-e5-d13 (ab){3} abcabababcdab для получения значения сегодня ([0-9]+) сегодня 18 января. $1 — вернёт ’18’ группировка без обратной связи
(?:)отмена получения значения. сегодня (?:[0-9]+) $1 ничего не вернёт () \1 … \9 обозначения от \1 до \9 для проверки на совпадение с ранее найденной подстрокой ([0-9])\1 88, 96, 99, 25, 11 ([а-я])[а-я]*\1 сос, нос, кок, тот (..|..) или первая часть или вторая (\+7|8)-[0-9-]* 8-812-243-12-63, +7-376-9052412 (он|ты|я) я, ты, он, она — вместе дружная семья атомарная групировка (?>шаблон) запрещает проверку любых других вариантов внутри группы, когда один вариант уже найден.  + отмена получения значения
+ отмена получения значенияa(?>bc|b|x)cc abccaxcc
но не abccaxcc : вариант x найден, остальные проигнорированы. $1 тоже ничего не вернёт(?i) (?s) (?m) (?g) (?x) (?r) Включает соответствующий модификатор (?i)onE onE, one, OnE (?-i) (?-s) (?-m) (?-g) (?-x) (?-r) Выключает модификатор (?-i)onE onE, oNe, one, OnE (?i-sm) Включает и выключает несколько модификаторов (?i-s:шаблон) Включает/Выключает модификаторы только в пределах группы (?i)o(?-i:n)E onE, oNe, one, OnE, oNE (?#комментарий) группа не проверяется на вхождение в текст. [0-9](?#одна цифра)d5 PHP: Регулярные выражения с примерами

Метасимволы групп и диапазонов символов () Круглые скобки. Группировка выражений. [] Квадратные скобки. Ряды, диапазоны символов. {} Фигурные скобки. Повтор предыдущего символа/-ов. * Звездочка. Любое число предыдущих символов. ? Знак вопроса. Повтор 0 или 1 раз предыдущего символа. Ограничитель жадности (если идёт после + или *)  а-я] — любой символ, кроме строчных букв русского алфавита.
а-я] — любой символ, кроме строчных букв русского алфавита.$ Знак доллара. Конец строки. \n Новая строка в Unix (от англ. newline — "разделитель строк"). \r\n Новая строка в Windows. \r Возврат каретки (от англ. return — "возврат"). \t Табуляция (от англ. Tab — "табуляция"). \ Обратный слэш. Позволяет использовать любой символ в буквальном значении. Метасимволы групп символов . Точка. Любой символ. \d Цифра от 0 до 9 (от англ. digit — "цифра"). 
\D Не цифра (любой символ кроме цифр от 0 до 9). \s Пробел и табуляция (от англ. space — "пробел"). \S Непустой символ (любой, кроме пробела и табуляции). \w Все буквы, цифры и знак подчеркивания (‘_’) (от англ. word — "слово"). \W Все символы, кроме букв, цифр и подчеркивания. Php регулярные выражения символ - Вэб-шпаргалка для интернет предпринимателей!
Квантификаторы
Аналог Пример Описание ? a? одно или ноль вхождений «а» + a+ одно или более вхождений «а» * a* ноль или более вхождений «а» Модификаторы
 a
aaaa aaa начало строки $ a$ aaa aaa конец строки A Aa aaa aaa
aaa aaaначало текста z az aaa aaa
aaa aaaконец текста a
aaaa aaa
aaa aaaграница слова, утверждение: предыдущий символ словесный, а следующий — нет, либо наоборот B BaB aaa aaa отсутствие границы слова G Ga aaa aaa Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a Якоря
 Без него шаблон соответствовал бы любой строке, содержащей цифру.
Без него шаблон соответствовал бы любой строке, содержащей цифру.Символьные классы
POSIX
Утверждения
 s]* ).
s]* ).Кванторы
Экранирование в регулярных выражениях
 Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать « . » в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования.
Однако, возникает проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто использовать « . » в качестве шаблона — это приведет к нахождению практически всего. Итак, вам необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с помощью знака экранирования. <|>в качестве их буквальных значений.
<|>в качестве их буквальных значений.Q не соответствует ничему, только экранирует все символы вплоть до E E не соответствует ничему, только прекращает экранирование, начатое Q Подстановка строк
Группы и диапазоны

, где вместо n подставить номер нужной группы. Вам может понадобиться шаблон, соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется с помощью групп: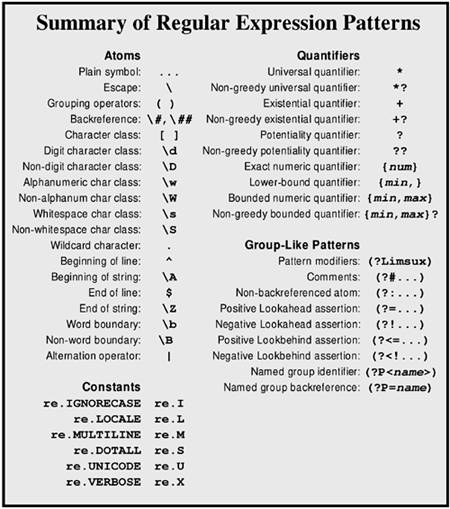 Скажем, вы хотите выделить в тексте все слова «wish» жирным начертанием. Для этого вам следует использовать функцию замены по регулярному выражению, которая может выглядеть так:
Скажем, вы хотите выделить в тексте все слова «wish» жирным начертанием. Для этого вам следует использовать функцию замены по регулярному выражению, которая может выглядеть так:Модификаторы шаблонов
 Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.Мета-символы
 Например шаблон "Вася(.*)Пупкин" позволит найти последовательность когда между словами Вася и Пупкин будет любое количество любых символов. Если надо найти шесть цифр, то пишем "[0-9]<6>" (если, например, от шести до восьми цифр, тогда "[0-9]<6,8>"). Здесь разделены такие вещи как указатель набора символов и указатель необходимого количества:
Например шаблон "Вася(.*)Пупкин" позволит найти последовательность когда между словами Вася и Пупкин будет любое количество любых символов. Если надо найти шесть цифр, то пишем "[0-9]<6>" (если, например, от шести до восьми цифр, тогда "[0-9]<6,8>"). Здесь разделены такие вещи как указатель набора символов и указатель необходимого количества: txt"), "либо 0, либо 1" ("?"). По умолчанию квантификатор для данного набора символов равен единице ("document[0-9].txt").
txt"), "либо 0, либо 1" ("?"). По умолчанию квантификатор для данного набора символов равен единице ("document[0-9].txt"). При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация "(.*)" в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон "двигается" программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация "(.*)" означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.
При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация "(.*)" в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон "двигается" программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация "(.*)" означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.Набор символов
. точка любой символ [ ] квадратные скобки класс символов ("любое из").  ]
]Кроме пробельных символов | (одно|другое) На этом месте может быть один из перечисленных вариантов, например: (Вася|Петя|Маша). Если Вы не хотите, чтобы это попало в выборку используйте (?: . ) Квантификатор
* "звёздочка" или знак умножения + плюс ? вопросительный знак  " и "$" совпадают с началом и концом отдельных строк.
" и "$" совпадают с началом и концом отдельных строк.s символ "." (точка) совпадает и с переносом строки (по умолчанию нет) A привязка к началу текста E заставляет символ "$" совпадать только с концом текста. Игнорируется, если установлен парамерт m. U Инвертирует "жадность" для каждого квантификатора (если же после квантификатора стоит "?", этот квантификатор перестает быть "жадным"). e Строка замены интерпретитуется как PHP код. Функции для работы с регулярными выражениями
preg_grep
В случае, если этот флаг установлен, функция preg_grep(), возвращает те элементы массива, которые не соответствуют заданному шаблону pattern.
Результат, возвращаемый функцией preg_grep() использует те же индексы, что и массив исходных данных. Если такое поведение вам не подходит, примените array_values() к массиву, возвращаемому preg_grep() для реиндексации.
Пример кода:preg_match
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.Пример кода
Пример кода
Пример кода
preg_match_all
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит массив полных вхождений шаблона, элемент $matches[1] содержит массив вхождений первой подмаски, и так далее.Пример кода
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее.Пример кода
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.Пример кода
Пример кода
preg_quote
Пример кода
Пример кода
preg_replace
Пример кода: Замена по нескольким шаблонам
Пример кода: Использование модификатора /e
Пример кода: Преобразует все HTML-теги к верхнему регистру
preg_replace_callback
Пример кода
preg_split
В случае, если этот флаг указан, функция preg_split() вернет только непустые подстроки.
В случае, если этот флаг указан, выражение, заключенное в круглые скобки в разделяющем шаблоне, также извлекается из заданной строки и возвращается функцией. Этот флаг был добавлен в PHP 4.0.5.
В случае, если этот флаг указан, для каждой найденной подстроки, будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение. ) для создания сложных выражений.Регулярные выражения в PHP
«/…/» — косые черты обозначают начало и конец регулярного выражения.
«‘/шаблон/’» — шаблон, который нам нужно сопоставить.
«объект» — строка, с которой нужно сопоставлять шаблон.Preg_match
«‘/Guru/’» — шаблон регулярного выражения.
«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.PH/ — любая строка, которая начинается с PH.$ Обозначает шаблон в конце строки. /com$/ — guru99.com,yahoo.com и т.д. * Обозначает любое количество символов, ноль или больше. /com*/ — computer, communication и т.д. + Требуется вхождение перед метасимволом символа (ов) хотя бы один раз. /yah+oo/ — yahoo. Символ экранирования. /yahoo+.com/ — воспринимает точку, как дословное значение. […] Класс символов. /[abc]/ — abc. a-z Обозначает строчные буквы. /a-z/ — cool, happy и т.д. A-Z Обозначает заглавные буквы. /A-Z/ — WHAT, HOW, WHY и т.д. 0-9 Обозначает любые цифры от 0 до 9. /0-4/ — 0,1,2,3,4.
«+@[a-zA-Z0-9-]» соответствует символу @ , за которым следуют буквы в нижнем или верхнем регистре, цифры от 0 до 9 или дефисы.
«+.[a-zA-Z.]<2,5>$/» указывает точку, используя обратную косую черту, затем должны следовать любые буквы в нижнем или верхнем регистре, количество символов в конце строки должно быть от 2 до 5.Заключение
Рекомендуем к прочтению
список полезных регулярных выражений PHP
От автора: никогда не забуду, как на экзамене в академии преподаватель отобрал у меня шпаргалку, и не только не выгнал из аудитории, но еще и поставил четверку (конечно, хорошо допытав перед этим). По мнению этого профессора, студент, написавший шпору, уже наполовину готов к сдаче экзамена. Сегодня мы займемся написанием шпаргалки, которая включает в себя список полезных регулярных выражений PHP.
Просто жуть!
Если честно, то у меня аллергия на регулярные выражения. Вот и сейчас, вспоминая о них, у меня появляется насморк, головная боль, резь в глазах и другие «отмазки», чтобы не писать о регулярках .
Но слинять не получится, так как надо сдавать материал редактору. Да и мне самому не помешает шпора. А то с этими выражениями регулярный головняк получается. В общем, приступим.
Полезные паттерны
Вот список регулярных выражений PHP, которые часто востребованы среди «сайтостроителей»:
Ищем email
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Паттерн для проверки пароля длинной 7-21 символов, состоящего из латинских символов, цифр, нижнего подчеркивания и тире
Ищем графические файлы определенного формата
Ищем строку, начинающуюся с указанного слова:
Ищем строку, заканчивающуюся указанным словом:
Если у вас есть примеры для этого списка регулярных выражений PHP, поделитесь ими в комментариях к материалу. Авось кому-то из коллег пригодится .
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Хотите изучить регулярные выражения на PHP?
Посмотрите 12-ти часовой видео курс по регулярным выражениям на PHP!
Смотреть
Общие Регулярные Выражения - CodeRoad
Есть ли в интернете сайт, на котором перечислены распространенные регулярные выражения, или есть утилита, которая поможет вам создать их на основе образца текста?
Спасибо!
.net
regex
Поделиться
Источник
Chris
01 декабря 2008 в 16:54
10 ответов
- Почему регулярные выражения так противоречивы?
При изучении регулярных выражений (иначе известных как RegEx-es) есть много людей, которые, кажется, видят регулярные выражения как священный Grail. Что - то, что выглядит таким сложным-просто должно быть ответом на любой вопрос. Они склонны думать, что любая проблема разрешима с помощью...
- MySql и регулярные выражения
Кто-нибудь знает, как получить немного более подробное сообщение об ошибке wrt MySql и регулярные выражения (т. е. позицию символа, в которой возникает проблема) или есть ли инструмент, который вы можете использовать, чтобы опробовать регулярные выражения без необходимости проб и ошибок с базой...
Поделиться
netadictos
01 декабря 2008 в 16:58
12
- Expresso -хороший инструмент регулярных выражений.
- Regular-Expressions.info -хороший учебник
- Regexlib имеет много общих регулярных выражений.
Поделиться
NikolaiDante
01 декабря 2008 в 16:58
2
Поскольку несколько человек упомянули RegexBuddy , который я разработал, я добавлю, что RegexBuddy включает в себя библиотеку регулярных выражений для многих общих целей.
Я не знаю ни одного инструмента на рынке сегодня, который мог бы автоматически генерировать регулярные выражения на основе образца текста. Такие инструменты, как RegexBuddy, работают наоборот. Вы создаете regex, и инструмент указывает, соответствует ли он вашему образцу текста или нет. RegexBuddy предоставляет меню "Вставить маркер" на вкладке "Создать", которое значительно упрощает создание регулярного выражения.
Поделиться
Jan Goyvaerts
03 декабря 2008 в 08:29
- Генеративные регулярные выражения
Обычно в нашей работе мы используем регулярные выражения в операциях захвата или сопоставления . Однако регулярные выражения можно использовать - по крайней мере, вручную-для создания юридических предложений, соответствующих регулярному выражению. Конечно, некоторые регулярные выражения могут...
- Python регулярные выражения
что такое регулярные выражения, которые будут идентифицировать класс допустимых чисел NRIC (включая конечные алфавиты)
1
В модуле Regexp::Common на CPAN перечислены многие распространенные регулярные выражения.
Поделиться
Stig Brautaset
10 июля 2009 в 21:05
1
У Роя Ошерова есть хороший набор бесплатных инструментов regex. На самом деле, я думаю, что Regulazy может быть именно тем, что вы ищете. Его страница инструментов не работает, но вы можете найти ссылки для загрузки @ http://weblogs.asp.net/rosherove/pages/tools-and-framework-by-roy-osherove.aspx . Попробуйте поискать в его блоге дополнительную информацию о Regulazy.
Поделиться
jkchong
03 декабря 2008 в 08:55
1
RegexPal -это потрясающая онлайн-проверка регулярных выражений, встроенная в JavaScript. Он также содержит краткую ссылку прямо на сайте и ссылку на почти полную ссылку из developer.mozilla.org.
Поделиться
J.C. Yamokoski
03 декабря 2008 в 09:02
1
есть несколько потрясающих инструментов для создания регулярных выражений на основе образца текста, я думаю, что один из них называется regexbuddy (я посмотрю его, когда я не на своем телефоне), но на сайте regexlib.com есть много регулярных выражений для общих целей.
Поделиться
Quintin Robinson
01 декабря 2008 в 16:57
1
Информация о регулярных выражениях -это сайт, который должен дать вам то, что вам нужно
На странице примеров есть хороший выбор примеров, а также страница инструментов для утилит
Поделиться
Binary Worrier
01 декабря 2008 в 16:57
0
Для инструмента Windows RegX
Попробуйте M Squared Technologies - Regx - Это бесплатно.
Хорошо подходит для одной строки, проб и ошибок.
http://mSquaredTechnologies.com
Поделиться
Unknown
01 декабря 2008 в 17:09
0
Я очень, очень удивлен, что об этом не упоминалось:
Он создает регулярное выражение из известной строки путем извлечения полей. Поначалу это немного неудобно, но как только вы его получите, он станет очень мощным и полезным.
И если мне разрешат опубликовать бесстыдный плагин, я также создал свою собственную часто используемую таблицу regex .
Поделиться
Fábio Santos
28 ноября 2012 в 00:43
Похожие вопросы:
Регулярные выражения и Assembly
Я знаю 8086 Assembly и учусь MIPS Assembly. Кроме того, я изучаю регулярные выражения, тогда я хочу знать: Как я могу использовать на них регулярные выражения?
Стоят ли регулярные выражения хлопот?
Меня поражает, что регулярные выражения плохо понимаются большинством разработчиков. Меня также поражает, что для многих проблем, где используются регулярные выражения, вместо них можно использовать...
Как обрабатываются регулярные выражения?
Как обрабатываются регулярные выражения?
Почему регулярные выражения так противоречивы?
При изучении регулярных выражений (иначе известных как RegEx-es) есть много людей, которые, кажется, видят регулярные выражения как священный Grail. Что - то, что выглядит таким сложным-просто...
MySql и регулярные выражения
Кто-нибудь знает, как получить немного более подробное сообщение об ошибке wrt MySql и регулярные выражения (т. е. позицию символа, в которой возникает проблема) или есть ли инструмент, который вы...
Генеративные регулярные выражения
Обычно в нашей работе мы используем регулярные выражения в операциях захвата или сопоставления . Однако регулярные выражения можно использовать - по крайней мере, вручную-для создания юридических...
Python регулярные выражения
что такое регулярные выражения, которые будут идентифицировать класс допустимых чисел NRIC (включая конечные алфавиты)
SQL Server регулярные выражения
Интересно, можно ли включить регулярные выражения в оператор SQL на SQL Server? Я только нахожу, что Oracle поддерживает регулярные выражения.
Понимаете регулярные выражения?
Я пытаюсь понять регулярные выражения. [ ] \ - $ + | ? ( ) { } (метасимволы). Составление регулярного выражения заключается в правильной комбинации специальных символов с другими для задания определенных условий и группировок.
Метасимволы нельзя использовать в выражении в их прямом значении. Если возникает такая потребность, то их необходимо экранировать.
Экранирование в регулярном выражении заключается в постановке перед метасимволом обратного слеша \.
Значения специальных символов в регулярных выражениях:
* звездочка — ноль или более предшествующих символов
Например, регулярному выражению «cart*» будут соответствовать строки «cart», «cartoon», «carte».
. точка — один любой символ
Например, регулярному выражению «c.t» будут соответствовать строки «cart», «cat», «count».
Точка также часто используется вместе со звездочкой. Выражение «.*» означает любое число любых символов.
+ плюс — один или более предыдущих символов, которые повторяются
Например, регулярному выражению «20+» соответствуют «20», «200», «2000».cat» отберет строки «cat», «catalog», «catalogue».
$ доллар — конец строки
Означает пустую последовательность в конце строки.
( ) круглые скобки — группировка
Оператор используется для группировки и ограничения области действия других операторов.
Например, регулярному выражению «(20)+» будут соответствовать строки «20», «2020», «202020».
[ ] квадратные скобки — список символов, один из которых может присутствовать в тексте
Квадратные скобки определяют набор символов, которые могут присутствовать в тексте. Например, для «cart» это будут символы «c», «a», «r» и «t».
- дефис — границы последовательности символов в квадратных скобках
Используется совместно с квадратными скобками для задания диапазона символов. Например, «[a-z]» означает все символы латиницы, а «[0-9]» — любое число.
{ } фигурные скобки — количество повторений предыдущего символа
В скобках указывается число повторений идущего перед ними символа. Например, регулярное выражение «.{3}» будет означать любые последовательности из 3х символов.
Вместе с фигурными скобками для задания диапазона используется запятая. Т.е. «.{3,5}» это последовательности от 3х до 5ти символов, а «.{3,}» — последовательности от 3х символов и выше.
| вертикальная черта — оператор "ИЛИ"
Задает условие или-или. Например, для «cart(e|on)» соответствием будут варианты «carte» или «cartoon».
\ обратный слеш — экранирование специальных символов
Если специальный символ должен учитываться именно как символ, а не оператор, его необходимо экранировать, поставив перед ним обратный слеш. Например, в IP-адресе с регулярным выражением «12\.26\.44\.(0+)» перед точкой в маске ставится обратный слеш и она интерпретируются как точка, а не любой символ.
Есть также метасимволы, которые заменяют определенные готовые конструкции. Здесь важен регистр: один и тот же символ в разных регистрах имеет противоположные значения.
\b — обозначает не символ, а границу между символами;
\B — не граница слова;
\d — цифра;
\D — не цифра;
\s — пробел;
\S — не пробел;
\w — буквенный или цифровой символ или знак подчеркивания;
\W — любой символ, кроме буквенного или цифрового символа или знака подчеркивания.
Объединяя спецсимволы и константы в определенные комбинации, получаем бесконечное число шаблонов поиска.
Описание поддерживаемых метасимволов, а также примеры, можно найти в справочных разделах от Яндекс и Google.
Или сохраните таблицу-шпаргалку по регулярным выражениям, чтобы они всегда были под рукой?
Regex против регулярных выражений
да. И нет. На данном этапе это семантический вопрос - он зависит от того, что подразумевается под регулярным выражением .
В настоящее время 99 процентов людей, которые упоминают регулярные выражения, действительно говорят о регулярных выражениях. Для них (и для Rex) regex - это аббревиатура регулярного выражения . Еще одна распространенная аббревиатура (проигрывающая войну аббревиатур) - regexp .Распространенными множественными числами являются регулярных выражений , регулярных выражений и даже регулярных выражений (спасибо, Ларри Уолл).
(прямая ссылка)
Краткая история Regex
А как насчет сотого человека? На самом деле, это соотношение, вероятно, ближе к одному на тысячу. Но у этого человека есть особые претензии, потому что давным-давно (1950-е, на заре информатики) регулярное выражение относилось к тому, что математик Стивен Клини описал как регулярный язык , который сам называл математическое свойство, называемое регулярностью .Механизмы регулярных выражений, которые соответствовали этой регулярности , назывались детерминированными конечными автоматами (DFA). Имя отца регулярных выражений (Стивен Клини) увековечено в звездочке Клини , маленьком символе в A *, который сообщает механизму, что символ A должен совпадать ноль или более раз.
В конце 1960-х Кен Томпсон из Bell Labs написал их в редакторе QED , а в 1970-х они превратились в программы и утилиты Unix, такие как grep , sed и AWK .
Эти инструменты сделали сопоставление текста намного проще, чем альтернатива - написание специальных программ синтаксического анализа для каждой задачи. Естественно, некоторые увидели потенциал для еще более мощных шаблонов сопоставления текста. В 1980-х годах программисты не могли устоять перед желанием расширить существующий синтаксис регулярных выражений, чтобы сделать их шаблоны еще более полезными - в первую очередь Генри Спенсер с его библиотекой regex , затем Ларри Уолл с языком Perl, который затем использовал расширенную библиотеку Спенсера. .
Механизмы, обрабатывающие этот расширенный синтаксис регулярных выражений, больше не были DFA - они называются недетерминированными конечными автоматами (NFA).На этом этапе шаблоны регулярных выражений уже не могли быть названы обычными в математическом смысле. Вот почему сегодня небольшое меньшинство людей (большинство из которых имеют адреса электронной почты, заканчивающиеся на .edu ) будут утверждать, что то, что мы называем регулярным выражением , не является регулярным выражением.
Для всех остальных… Регулярные выражения и регулярные выражения? То же самое.
Perl оказал огромное влияние на разновидности регулярных выражений, используемых сегодня в большинстве современных движков. Вот почему современные регулярные выражения часто называют в стиле Perl.Различия в функциях движков регулярных выражений значительны, поэтому, на мой взгляд, говорить о регулярных выражениях в стиле Perl имеет смысл только тогда, когда кто-то хочет прояснить, что он не говорит о марке математически правильных выражений типа башни из слоновой кости.
Но если вы действительно хотите избежать двусмысленности, просто скажите regex , поскольку это одно слово, которое компьютерные ученые в белых халатах не используют.
Краткое руководство: справочная таблица Regex
Учебное пособие по
Regex - регулярные выражения имеют много применений
, август 2014 г .: В последнее время я добавил много новых страниц с регулярными выражениями и провел капитальный ремонт старых.У меня еще не было времени отредактировать эту страницу, поэтому, пожалуйста, имейте в виду, что не соответствует тому же стандарту, что и большинство страниц в руководстве. Я знаю и работаю над этим. :)
Regex - это подарок, который продолжает дарить. Изучив его, вы обнаружите, что он пригодится во многих местах, где вы не планировали его использовать. На этой странице мы сначала рассмотрим ряд контекстов и программ, в которых вы можете найти регулярное выражение. Затем мы кратко рассмотрим некоторые разновидности регулярных выражений, с которыми вы можете столкнуться.Наконец, мы изучим несколько примеров шаблонов регулярных выражений в таких контекстах, как:
✽ Переименование файла
✽ Текстовый поиск
✽ Веб-директивы (Apache)
✽ Запросы к базе данных (MySQL)
Отказ от ответственности: я давно не редактировал эту страницу. В результате контент не такой безупречный, как на большинстве других моих страниц. Я надеюсь, что скоро доберусь до него.
Ситуации, в которых регулярное выражение может спасти положение
Вот некоторые вещи, в которых вам могут помочь регулярные выражения.
1. Захват текста в файлах или проверка ввода текста при программировании на таких языках, как C, Java или PHP.
2. Поиск (и, возможно, замена) текста в файлах при использовании расширенного текстового редактора, такого как EditPad Pro и Notepad ++ в Windows (или TextWrangler / BBEdit в OSX), автономного инструмента замены, такого как ABA Replace, или старого доброго grep ( связанная страница имеет лучший grep командной строки для Windows).
Несколько слов об упомянутых инструментах. Среди текстовых редакторов EditPad Pro находится в особой лиге, потому что его движок регулярных выражений был запрограммирован создателем RegexBuddy.Если вы хотите попробовать EditPad Pro, загрузите бесплатную пробную версию . В бесплатном Notepad ++ раньше отсутствовал отдел регулярных выражений, но, начиная с версии 6, в нем использовался отличный движок PCRE, хотя интерфейс все еще неуклюжий. В OSX бесплатный TextWrangler, его старший брат BBEdit, оба заявляют, что используют PCRE. Что они не говорят, так это то, что они используют версию PCRE 4.0 от 17 февраля 2003 - или мне так кажется, поскольку она поддерживает [: blank:] из 4.0, но не \ X из 5.0. Это означает, что не хватает многих пикантных функций.Тем не менее, PCRE десятилетней давности намного лучше, чем JavaScript.
Для замены в текстовых файлах люблю ABA Replace. Он выполняет одну работу, и делает это блестяще: ищет и заменяет текст в файле или сразу во многих файлах. В окне результатов результаты меняются мгновенно, когда вы настраиваете выражение, так же, как в RegexBuddy.
Я использую регулярное выражение для переименования файлов, поиска в файлах, для выполнения крупномасштабных замен в коде, в коде (PHP), в базах данных (mySQL) и для управления моим веб-сервером (Apache).
3. Поиск и замена на страницах кода при использовании в среде IDE, такой как Visual Studio, Komodo IDE или даже урезанный вариант ECMAScript от Dreamweaver.
4. Для расширенного поиска и замены при использовании программного обеспечения для творчества, такого как Adobe Indesign.
5. Переименование ста файлов за раз в расширенном файловом менеджере, таком как Directory Opus, или в переименователе, таком как PFrank (Win) или A Better Finder Rename (OSX).
Спешу добавить, что "подобного" Directory Opus действительно нет.Opus - уникальный инструмент, на мой взгляд, самый важный инструмент повышения производительности, который может иметь пользователь Windows! Почему такое экстравагантное заявление? Потому что для большинства пользователей огромное количество компьютерного времени незаметно исчезает в черной дыре файловых операций - поиска, перемещения и переименования файлов. Если вы еще не видели его, вы действительно обязаны совершить поездку по функциям Directory Opus или установить бесплатную полнофункциональную 60-дневную пробную версию.
6. Поиск из командной строки с использованием однострочников Perl и таких утилит, как grep, sed и awk .
7. Поиск записей в базе данных.
8. Сообщая Apache, как вести себя с определенными IP-адресами, URL-адресами или браузерами, например, в htaccess.
9. Помочь вам скоротать утомительные дневные рабочие часы, обмениваясь задачами с регулярными выражениями с коллегами.
Если я пропустил важную категорию, напишите мне комментарий внизу страницы.
Regex ароматизаторы
Как я уверен, вы знаете, регулярные выражения известны под разными именами: regex или все более редкое regexp и их множественное число regexp , regexps или regexen .
Что еще более важно, регулярное выражение также имеет множество разновидностей. В окне RegexBuddy, замечательного маленького инструмента регулярных выражений, без которого я не могу работать (подробнее об этом позже, бесплатная пробная версия скачать здесь), я могу выбирать между контекстами, такими как C #, Python, Java, PHP, Perl, Ruby, JavaScript. , Scala и многие другие. Видите ли, каждый, кто реализует движок регулярных выражений, делает это немного иначе, чем кто-либо другой.
Двигатели, стоящие за этими ароматизаторами, делятся на две основные группы:
✽ направленный на регулярное выражение (или NFA, что означает Недетерминированный конечный автомат )
✽ текстовый (или DFA, что означает Детерминированный конечный автомат )
Когда вы можете выбирать между NFA или DFA, NFA обычно является самым быстрым.Это действительно самая распространенная реализация в современных языках.
Вполне возможно, что вкус регулярного выражения, который вы используете, не совпадает с тем, что я использую, хотя это действительно было бы неудачей. Вот некоторые из разновидностей регулярных выражений, которые я часто использую, и их контекст:
✽ Вариант .NET при программировании на C #.
✽ Вариант PCRE при программировании на PHP и для Apache.
✽ Модуль regex Мэтью Барнетта для Python.
✽ Версия расширенного регулярного выражения POSIX (ERE) в mySQL.
✽ Версия JGSoft для поиска и замены в EditPad Pro.
✽ Варианты Java, JavaScript, Perl, Ruby и Objective-C при ответах на вопросы на форумах.
✽ Версия TR1 для переименования файлов в Directory Opus.
✽ Вариант ABA (основанный на библиотеке Генри Спенсера) в ABA Search Replace.
То, что работает с одним ароматом, очень часто работает с другим, но есть важные тонкости, которые я постараюсь выявить, когда мы будем изучать функции.
Поиск и замена из командной строки
Не зная языка Perl, если вы знаете регулярное выражение, вы можете создавать мощные однострочные команды Perl для выполнения в оболочке вашей операционной системы.Например, вы можете обернуть простое регулярное выражение \ bc \ w + внутри некоторого однострочного кода шаблона Perl, чтобы сопоставить или заменить все слова файла, начинающиеся с буквы c . Для получения дополнительных сведений см. Мою страницу о том, как создавать однострочные регулярные выражения Perl.
Среди утилит командной строки, которые понимают регулярные выражения, вы можете встретить grep, sed, awk и другие. Среди них grep - самый известный. Моя страница о grep содержит примеры, а также загрузку того, что, на мой взгляд, является лучшей версией grep для Windows (в ней используется движок PCRE).
Примеры регулярных выражений для переименования файлов
В этом разделе мы будем использовать синтаксис регулярных выражений Directory Opus. (На Mac я бы использовал специальный переименователь файлов под названием A Better Finder Rename, который, помимо функций регулярных выражений, представляет собой небольшую жемчужину, поскольку позволяет не-гикам создавать сложные операции переименования в серии простых шагов или «слоев». )
Функция переименования в Opus позволяет сохранять ваши любимые шаблоны регулярных выражений. Поскольку вы редко выполняете одну и ту же операцию переименования, я стараюсь сохранять регулярные выражения, которые я могу снова открыть и быстро настроить в соответствии со своими потребностями..] + $
Заменить: \ 1rar
Перевод: В начале имени файла жадно сопоставьте любые символы, затем точку, захватывая это в Группу 1. Жадная точка-звезда будет стрелять в конец имени файла, а затем вернуться к последняя точка. Этот захват является основой имени файла. После этого захвата сопоставьте любой символ, не являющийся точкой: расширение. Замените все это содержимым группы 1, выраженным как \ 1 или $ 1 (это захваченная основа, включающая точку) и «rar».-] *) — (. *) #
Заменить: \ 1 \ 2
Перевод: сопоставьте и захватите любые символы без тире в Группу 1, сопоставьте тире, затем съедите любые символы, захватив те, что находятся в Группе 2. Замените имя файла первой группой, за которой сразу же второй группой (тире нет). Символ решетки в первой строке (#) указывает механизму DOpus выполнять эту замену до тех пор, пока строка не перестанет изменяться. Таким образом, все тире удаляются один за другим.
Замена точек пробелами в именах файлов
Этот шаблон подходит для случаев, когда у вас есть 95 файлов, которые выглядят примерно так:
Имена файлов, подлежащих очистке:
..] +) $ # Жадно съедайте все, что не является точкой, до конца имени файла, захватывая это в группе 3 (это расширение)
Последний символ решетки (#) указывает Opus повторять операцию замены до тех пор, пока не останутся точки, которые можно есть, и имя файла не будет очищено. Строка замены берет захваченные группы и вставляет пробел вместо каждой точки.
Обмен двух частей имени файла
Предположим, вы назвали множество файлов фильмов в соответствии с этим шаблоном:
8.2 День сурка (1993) .avi
Число впереди — это рейтинг фильма на IMDB. Число в скобках в конце — год выхода фильма. Однажды вы решите, что вместо сортировки фильмов по рейтингу вы действительно хотите отсортировать их по году, а это означает, что в имени файла вы хотите поменять местами рейтинг и год. Вы хотите, чтобы ваши файлы выглядели так:
(1993) День сурка 8.2.avi
Без регулярных выражений у вас проблемы.(] *) # Во второй группе жадно фиксируйте все, что не является открывающей скобкой.
(\ ([\ d] {4} \)) # В третьей группе захватите открывающую скобку (которую нужно экранировать в регулярном выражении), четыре цифры и закрывающую скобку.
(. *) # В последней группе захватить что угодно.
Шаблон замены просто берет четыре группы и изменяет их порядок.
Примеры регулярных выражений для поиска текстовых файлов
Что хорошего в текстовых редакторах, если вы не можете выполнять сложный поиск? Я проверил эти примеры выражений в EditPad Pro, но они, вероятно, будут работать в Notepad ++ или в IDE, поддерживающей регулярные выражения.
Семибуквенное слово, содержащее слово «сено»
Некоторые примеры могут показаться надуманными, но иметь под рукой небольшую библиотеку готовых регулярных выражений — это просто потрясающе.
Шаблон поиска: (? = \ B \ w {7} \ b) \ w *? Hay \ w *
Перевод: Посмотрите прямо вперед, найдите слово из семи букв (границы \ b важны). Лениво съедайте любые символы слов, за которыми следует «сено», а затем съедайте любые символы слова. Мы знаем, что жадное сопоставление должно прекратиться, потому что слово состоит из семи символов.
Здесь, в нашем слове, мы разрешаем любые символы, которые регулярное выражение вызывает «символы слова», которые, помимо букв, также включают цифры и символы подчеркивания. Если нам нужен более консервативный шаблон, нам просто нужно изменить поиск:
Традиционное слово (только буквы): (? I) (? = \ B [AZ] {7} \ b) \ w *? Hay \ w *
В этом шаблоне при поиске вы можете видеть, что я заменил \ w {7} на [AZ] {7}, что соответствует семи заглавным буквам. Чтобы включить строчные буквы, мы могли бы использовать [A-Za-z] {7}.(? =. *? \ bbubble \ b). *? \ bgum \ b. *
Перевод: пока я привязан к началу строки, ищите любые символы, за которыми следует слово , пузырек . Мы могли бы использовать второй просмотр вперед для поиска gum , но быстрее просто сопоставить всю строку, позаботившись о совпадении gum на подходе.
Строка Содержит «мальчик» или «купи»
Схема поиска: \ bb [ou] y \ b
Перевод: внутри слова (внутри двух границ \ b) сопоставьте символ b , затем один символ, который равен либо o , либо u , затем y .
Найти повторяющиеся слова, например «the»
Это популярный пример в литературе по регулярным выражениям. Не знаю, как вы, но не так часто случается, что ошибочно повторяющиеся слова попадают в мой текст. Если этот пример настолько популярен, вероятно, потому, что это короткий шаблон, который отлично демонстрирует мощь регулярного выражения.
Вы можете найти миллион способов написать повторяющийся шаблон слов. В этом я использовал классы POSIX (доступные в Perl и PHP), что позволило нам добавлять дополнительные знаки препинания между словами в дополнение к дополнительному пробелу.
Шаблон поиска: \ b ([[: alpha:]] +) [[: punct:]] + \ 1
Перевод: после разделителя слов в первой группе захватите положительное количество букв, затем съедите пробелы или знаки препинания, а затем сопоставьте то же слово, которое мы захватили ранее в первой группе.
Если вы не хотите использовать знаки препинания, просто используйте \ s + вместо [[: punct:]] +.
Помните, что \ s съедает любых пробелов, включая символы новой строки, табуляции и вертикальные табуляции, поэтому, если это не то, что вы хотите, используйте [] + для указания пробелов.(?!. * резинка) (?!. * ванна). *? пузырь. *
Перевод: в начале строки заявите, что следующее не является «никакими символами, затем gum », подтвердите, что следующее не будет «никакими символами, затем ванна », затем сопоставьте всю строку, убедившись, что вы выбрали пузырь в пути.
Адрес электронной почты
Если мне когда-нибудь придется искать адрес электронной почты в текстовом редакторе, честно говоря, я просто ищу @. Это показывает мне как правильно сформированные адреса, так и адреса, авторы которых дают волю своему творчеству, например, набрав DOT вместо точки.
Когда дело доходит до проверки пользовательского ввода, вам нужно выражение, которое проверяет правильность формата адресов. Существуют тысячи регулярных выражений адресов электронной почты. В конце концов, никто не может точно сказать вам, действителен ли адрес, пока вы не отправите сообщение и не ответит получатель.
Регулярное выражение ниже заимствовано из главы 4 превосходной книги Яна Гойверта, Поваренная книга регулярных выражений . Я согласен с рассуждениями Яна о том, что вам действительно нужно выражение, которое работает с 999 адресами из тысячи, выражение, которое не требует большого обслуживания, например, заставляя вас добавлять новые домены верхнего уровня. («расставьте что-нибудь») каждый раз, когда власти, отвечающие за эти вещи, решают, что пора запускать имена, заканчивающиеся чем-то вроде dot-phone или dot-dog.
Шаблон поиска: (? I) \ b [A-Z0-9 ._% + -] + @ (?: [A-Z0-9 -] + \.) + [AZ] {2,6} \ b
Давайте развернем эту:
(? i) # Включить режим без учета регистра
\ b # Позиционировать движок на границе слова
[A-Z0-9 ._% + -] + # Сопоставить один или несколько символов в скобках: буквы, цифры , точка, подчеркивание, процент, плюс, минус. Да, некоторые из них редко встречаются в адресах электронной почты.
@ # Соответствует @
(?: [A-Z0-9 -] + \.) + # Соответствует одной или нескольким строкам, за которыми следует точка, такие строки состоят из букв, цифр и дефисов. Это домены и поддомены, например, пост. и microsoft. на post.microsoft.com
[A – Z] {2,6} # Сопоставьте от двух до шести букв, например US, COM, INFO. Это должен быть домен верхнего уровня. Да, это тоже соответствует СОБАКЕ. Вы должны решить, хотите ли вы достичь точности бритвы за счет необходимости поддерживать ваше регулярное выражение при введении новых TLD.
\ b # Соответствует границе слова
Примеры регулярных выражений для директив веб-сервера (Apache)
Если вы используете Apache, скорее всего, у вас есть регулярные выражения где-то в вашем файле .htaccess или в файле конфигурации httpd.conf. Как и PHP, Apache использует регулярные выражения типа PCRE.
Вот несколько примеров.
Перенаправление в новый каталог
Иногда вы решаете изменить структуру каталогов.Посетители, которые переходят по старой ссылке, будут запрашивать старые URL-адреса. Вот как может помочь регулярное выражение в htaccess.
RewriteRule old_dir /(.*)$ new_dir / $ 1 [L, R = 301]
Объяснение: Старый URL-адрес записан в Группу 1 и добавлен в конец нового пути.
Ориентация на определенные браузеры
BrowserMatch \ bMSIE no-gzip
Эта директива проверяет, содержит ли имя браузера пользователя «MSIE» (с границей слова перед «M»).Если это так, Apache применяет то, что следует в строке. (В этом случае no-gzip говорит Apache не сжимать контент.)
Таргетинг на определенные файлы
Заголовочный набор Cache-Control «max-age = 43200»
В первой строке этой директивы htaccess для кэширования файлов есть небольшие файлы, соответствующие регулярному выражению, оканчивающиеся точкой и «htm» или «html».
Другие регулярные выражения в Apache
RewriteCond% {HTTP_USER_AGENT} ^ Zeus.13 $ 90 187
Цель: в правиле перезаписи проверить, равен ли час часу дня.
В Apache есть и другие варианты использования регулярных выражений. Эти примеры должны дать вам представление. Для получения дополнительной информации вы можете просмотреть страницу руководства для mod_rewrite, страницу mod_rewrite, руководство по перезаписи и расширенное руководство по перезаписи.
Использует ли Apache ту же версию PCRE, что и PHP?
Не обязательно. Чтобы узнать, какая версия PCRE PHP используется, посмотрите на результат phpinfo () и найдите PCRE.Помимо номера версии, вы найдете ссылку на каталог: что-то вроде pcre-regex = / opt / pcre. Другой способ найти эту папку - запустить ldd / some / path / php | grep pcre в оболочке, где some / path - это путь, возвращаемый функцией which php.
Вы можете использовать этот каталог в командной строке оболочки, чтобы получить дополнительную информацию о вашей версии PCRE:
/ opt / pcre / bin / pcretest -C
На cPanel EasyApache устанавливает PCRE в папку / opt, поэтому, если PHP сообщает о папке выше, вы можете ожидать, что mod_rewrite и PHP используют одну и ту же версию PCRE (если в cPanel нет ошибки).
При других установках вам может потребоваться найти все установленные версии pcretest, чтобы увидеть, какие версии установлены:
find / -name pcretest
Примеры регулярных выражений для поиска записей в базе данных (MySQL)
Чтобы проиллюстрировать базовое использование регулярных выражений в MySQL, вот пример, который выбирает записи, поле YourField которых заканчивается на «ty».
ВЫБРАТЬ * ИЗ YourDatabase ГДЕ YourField REGEXP 'ty $';
Вот второй пример выбора полей, которые содержат , а не , содержащие цифру:
SELECT * FROM YourDatabase WHERE YourField NOT REGEXP "[[: digit:]]";
Вы можете использовать RLIKE вместо REGEXP, поскольку они являются синонимами.Но зачем тебе это?
Регулярные выражения в MySQL нацелены на соответствие стандарту POSIX 1003.2, также известному как библиотека «regex 7» Гарри Спенсера. На странице документации MySQL для REGEXP указано, что она неполная, но что полная информация включена в исходные коды MySQL, в файл regex.7… Хорошо, это затруднительно, но давайте загрузим исходный код. О, нет, нельзя, нужен специальный установщик только для того, чтобы скачать исходный код. Неважно, вот копия справочной страницы regex (7).
Если вы создаете запросы на каком-либо языке программирования перед их отправкой в MySQL, вы должны обратить особое внимание на экранирование спорных символов в строке регулярного выражения.В вашем языке, вероятно, есть функция, которая подготовит строку для передачи в базу данных.
Если вы привыкли к регулярным выражениям, подобным Perl, вариант MySQL POSIX будет звучать как детский лепет. Если вам нужно больше мощности, вы можете рассмотреть библиотеку PCRE для MySQL. Поскольку я обновляю свой сервер MySQL для основных выпусков, риск прямой несовместимости немного высок, и я придерживаюсь регулярного выражения (7).
Элементы стиля Regex
Регулярные выражения - шпаргалка
Эта шпаргалка предназначена для быстрого напоминания основных концепций, связанных с использованием регулярных выражений, и предполагает, что вы уже понимаете их использование.Если вы новичок в регулярных выражениях, мы настоятельно рекомендуем вам с самого начала изучить руководство по регулярным выражениям.
Щелкните заголовок раздела, чтобы перейти на соответствующую страницу руководства, чтобы узнать больше об этих концепциях.
Основные метасимволы
- . (точка или точка)
- Любой персонаж.
- []
- Диапазон. Подберите любой из этих символов.]
- Диапазон. Соответствует любому символу, который не является одним из них.
- \ (обратная косая черта)
- Побег. Удаление или добавление особого значения к символу.
Множители
- *
- Ноль или более совпадений.
- +
- Соответствует один или несколько раз.
- ?
- Соответствует нулю или единице раз.
- {x}
- Совпадение ровно x раз.
- {x, y}
- Совпадение от x до y раз.
- {x,}
- Соответствует не менее x раз.
Сокращенные классы символов
- \ с
- Все, что считается пробелом.
- \ S
- Все, что не считается пробелом.
- \ d
- Цифра (например, 0–9)
- \ D
- Все, что не является цифрой.
- Начало строки.
- $
- Конец строки.
- \ <
- Начало слова.
- \>
- Конец слова.
- \ b
- Начало или конец слова.
Группировка и обратные ссылки
- Можно использовать где угодно на любом пути.
- ()
- Создайте группировку.
- \ x (x = цифра)
- Соответствует тому, что было найдено в соответствующей группе.
Чередование
- |
- Соответствует тому, что находится слева или справа от символа трубы.
Просмотр вперед и назад
- (? = Х)
- Позитивный взгляд в будущее.
- (?! X)
- Отрицательный прогноз.
- (? <= X)
- Позитивный взгляд назад.
- (?
- Отрицательный взгляд назад.
PHP Regex Cheat Sheet
Шей Андерсон, октябрь 2008 г.
? - 0 или 1 вхождение
* - 0 и более случаев
+ - 1 и более вхождений
{n} - n = количество повторов
{n, m} - n = минимальное количество случаев, m = максимальное количество случаев
{n,} - не менее n вхождений
{, m} - не более m вхождений
.и $ соответствуют началу и концу строк
с - Dotall -. класс включает новую строку
x - Расширенные комментарии и пробелы
e - preg_replace позволяет оценивать замену только как код PHP
S - Дополнительный анализ паттерна
U - Выкройка не жадная
u - шаблон обрабатывается как UTF-8
Утверждения - PHP
(? = ...) - Утверждение положительного просмотра вперед foo (? = Bar) соответствует foo, если за ним следует bar
(?! ...) - Отрицательное утверждение foo (?! Bar) соответствует foo, если за ним не следует bar
(? (? (?>) - Одноразовые подшаблоны (?> \ D +) бар Повышение производительности при отсутствии бара
(? (X)) - Условные подшаблоны
(? (3) foo | fu) bar - Соответствует foo, если 3-й подшаблон соответствует, fu, если нет
(? #) - Комментарий (? # Шаблон делает x y или z)
Синтаксис шаблона
The Ultimate Regex Cheat Sheet (регулярные выражения)
Регулярное выражение или регулярное выражение - это текстовая строка, которая позволяет разработчикам создавать шаблон, который может помочь им сопоставлять, управлять и находить текст.w]
регулярное выражение = / b /; // Соответствует границе слова, где символ слова - [a-zA-Z0-9_]
Эти мета-символы имеют предопределенное значение и упрощают использование различных типичных шаблонов.
/ * сопоставление с использованием квантификаторов * /
регулярное выражение = /X./; // соответствует любому символу
регулярное выражение = / X * /; // Соответствует нулю или нескольким повторениям буквы X, сокращенно от {0,}
регулярное выражение = / X + - /; // соответствует одному или нескольким повторениям буквы X, сокращенно от {1,}
регулярное выражение = / X? /; // не находит или не находит одну букву X, сокращенно от {0,1}.
регулярное выражение = // d {3}; // соответствует трем цифрам.{} описывает порядок предыдущего либерального
регулярное выражение = // d {1,4}; // означает, что d должно встречаться хотя бы один раз и не более четырех
Количественная оценка помогает разработчикам определить, как часто встречается элемент.
/ * диапазоны символов * /
регулярное выражение = / [аз-я] /; // соответствует всем строчным буквам
регулярное выражение = / [A-Z] /; // соответствует всем заглавным буквам
регулярное выражение = / [e-l] /; // соответствует строчным буквам от e до l (включительно)
регулярное выражение = / [F-P] /; // соответствует всем заглавным буквам от F до P (включительно)
регулярное выражение = / [0-9] /; // соответствует всем цифрам
регулярное выражение = / [5-9] /; // соответствует любой цифре от 5 до 9 (включительно)
регулярное выражение = / [a-d1-7] /; // соответствует букве между a и d и цифрам от 1 до 7, но не d1
регулярное выражение = / [a-zA-Z] /; // соответствует всем строчным и прописным буквам
регулярное выражение = / [^ a-zA-Z] /; // соответствует не буквенным
/ * сопоставление с использованием якорей * /
регулярное выражение = / ^ The /; // соответствует любой строке, которая начинается с «The»
регулярное выражение = / конец $ /; // соответствует строке, которая заканчивается на конец
регулярное выражение = / ^ Конец $ /; // точное совпадение строки, начинающейся с «The» и заканчивающейся «End»
/ * escape-символы * /
регулярное выражение = / а /; // сопоставить звонок или будильник
регулярное выражение = / е /; // соответствует escape-последовательности
регулярное выражение = / f /; // соответствует подаче формы
регулярное выражение = / n /; // соответствует новой строке
регулярное выражение = / Q… E /; // игнорирует любые особые значения того, что сопоставляется
регулярное выражение = / г /; // соответствует возврату каретки
регулярное выражение = / v /; // соответствует вертикальной табуляции
Важно отметить, что escape-символы чувствительны к регистру.
/ * сопоставление с использованием флагов * /
регулярное выражение = / я /; // игнорирует регистр в шаблоне (разрешены верхний и нижний регистр)
регулярное выражение = / м /; // многострочное соответствие
регулярное выражение = / с /; // соответствие новым строкам
регулярное выражение = / х /; // разрешить пробелы и комментарии
регулярное выражение = / j /; // разрешены повторяющиеся имена групп
регулярное выражение = / U /; // неладное совпадение
Помимо регулярных выражений, флаги также могут использоваться для помощи разработчикам в сопоставлении с образцом./ * соответствие определенной строке * /
регулярное выражение = / петь /; // ищет строку между косой чертой 9 с учетом регистра)… соответствует «sing», «sing123»
регулярное выражение = / петь / я; // ищет строку между косой чертой (без учета регистра) ... соответствует "sing", "SinNG", "123SinNG"
регулярное выражение = / привет / г; // ищет несколько вхождений строки между косой чертой ...
/ * группы * /
regex = / это (шипит)? жарко на улице /; // соответствует "на улице очень жарко" и "на улице жарко"
regex = / это (?: шипит)? жарко снаружи /; // то же, что и выше, за исключением того, что это не захватывающая группа
регулярное выражение = / делать (собаки) как пицца 1 /; // соответствует "любят ли собаки пиццы"
regex = / делать (собакам) нравится (пицца)? нравитесь ли вы 2 1? /; // соответствует "собакам нравится пицца? любите ли вы пиццу собакам?"
/ * взгляд вперед и назад * /
регулярное выражение = / d (? = r) /; // соответствует 'd', только если за ним следует 'r', но 'r' не будет частью общего совпадения регулярного выражения
регулярное выражение = / (? <= r) d /; // соответствует 'd', только если за ним следует 'r', но 'r' не будет частью общего совпадения регулярного выражения
Final Verdict
Как описано в этой статье, регулярное выражение может применяться в нескольких полях, и я уверен, что вы сталкивались по крайней мере с одним из этих методов в своей карьере разработчика программного обеспечения.Другие продвинутые приложения не обсуждались в этой статье, но вы можете быть уверены, что ознакомились с ними, когда разберетесь со стандартными регулярными выражениями.
Полезные ресурсы
10 шпаргалок по регулярным выражениям, которые можно добавить в закладки для разработчиков и системного администратора
Регулярное выражение (Regex) - это сложный метод поиска строк. Он включает в себя последовательность различных символов, определяющих конкретный шаблон поиска. Он в основном используется для алгоритмов поиска по строкам.
Используя Regex, вы можете искать некоторые символы, которые вам могут понадобиться для доступа и обработки.Вы можете сделать это, создав соответствующий шаблон для данных, которые вы хотите извлечь. Он реализован на многих языках программирования, таких как Java, JavaScript, Python, PHP и других.
Итак, вы когда-нибудь сталкивались с проблемами при извлечении данных из символьной строки? Это может быть сложно, поскольку существуют миллионы и триллионы данных.
Здесь вы можете использовать шпаргалки Regex, чтобы найти ту строку символов, которую вы искали. И чтобы помочь вам сэкономить ваше время и усилия, вот некоторые из лучших шпаргалок по Regex, на которые вы можете смотреть при парсинге веб-страниц или кодировании.
Держите!
Cheatography: Этот сайт - один из лучших для поиска шпаргалок. Вы можете найти краткое руководство, которое Дэйв Чайлд курировал для регулярных выражений (Regex). Он включает символы, утверждения, диапазоны и образцы шаблонов, которые помогут вам быстро приступить к работе. Он охватывает якоря, квантификаторы, escape-последовательности, классы символов, общие метасимволы, модификаторы шаблонов, специальные символы и многое другое. Вы можете скачать эту шпаргалку или добавить ее в закладки в браузере.
Rexegg.com: Эта шпаргалка содержит часто используемые регулярные выражения на разных языках, включая Python. Он включает в себя символы, логику, кванторы, пробелы, классы символов, границы и привязки, встроенные модификаторы, классы POSIX, операции классов, обзор и синтаксис. Все таблицы легко читаются, и вы также можете найти ссылку, чтобы узнать 1001 способ использования Regex.
Dev. Независимо от того, какой уровень навыков у вас как у разработчика, эта шпаргалка будет вам полезна.Куратором этого списка регулярных выражений является Эмма Бостиан, и она дает чистый синтаксис для каждой темы. Темы, которые она рассмотрела, включают в себя тестирование регулярных выражений, тестирование нескольких шаблонов, игнорирование случаев, сопоставление переменных, извлечение совпадений из массивов, сопоставление символов, алфавитов и чисел; ленивое сопоставление, сопоставление начальных и конечных шаблонов строк и многие другие сопоставления.
MDN Web Docs: это еще одно место, где можно найти отличную шпаргалку по Regex. Он проведет вас через полное руководство по Regex с синтаксисом и включает объяснения и примеры, понятные как продвинутым, так и новичкам.Его содержимое включает выражения для классов символов, квантификаторов, утверждений, экранирования свойств Unicode, а также диапазонов и групп. Если вы хотите получить дополнительную информацию по определенной теме, щелкните ссылку, связанную с соответствующим заголовком.
KeyCDN: перейдите на этот сайт, чтобы понять Regex с примерами, инструментами и объяснениями. Вы можете найти выражения и их соответствующее описание, чтобы лучше понять концепцию. Он начинается с некоторых основ Regex, а затем с краткого обзора токенов Regex и того, как они работают в выражениях.Затем он включает выражения для квантификаторов, классов символов, специальных символов, групп, замен строк и утверждений. Вы также найдете примеры Regex, такие как сопоставление адресов электронной почты и номеров телефонов, а также инструменты (Regexr, Regex101 и RegexPal) для тестирования синтаксиса Regex.
DebuggexBeta: Если вы поклонник одностраничной шпаргалки, этот веб-сайт для вас. Просто сохраните его в своем браузере и обращайтесь к нему всякий раз, когда вам это нужно. Эта шпаргалка по Regex охватывает основы Regex, классы символов, флаги, утверждения, квантификаторы, специальные символы, замены и группы.Вы также можете фильтровать выражения, вводя ключевое слово в поле в верхней части веб-страницы.
Factory Mind: если вы новичок, продвинутый разработчик или разработчик среднего уровня, эта шпаргалка по Regex от Джонни Фокса поможет вам, пока вы в затруднении. Вы можете использовать его на разных языках программирования, включая Java, Python, Ruby, Perl, C ++, C #, JavaScript и другие. Он начинается с основных тем, таких как привязки, квантификаторы, операторы ИЛИ, классы символов и флаги.Затем вы найдете темы среднего уровня, такие как захват и группировка, выражения в квадратных скобках, а также ленивые и жадные совпадения. В конечном итоге вы можете найти выражения для сложных тем, таких как границы, обратные ссылки, ретроспективные и ретроспективные исследования.
OverAPI.com: этот классный веб-сайт со шпаргалкой по Regex охватывает все основные темы и примеры. Вы можете найти разные цвета, успокаивающие ваши глаза, в качестве фона для каждой темы, написанной белым. Он охватывает якоря, квантификаторы, символы, POSIX, группы, модификаторы, строку и утверждения.
На пути к науке о данных: эта таблица регулярных выражений удобна и напоминает вам обо всех концепциях и выражениях, которые вам нужны, как разработчику. Он написан Radian Krisno и начинается с базового введения в Regex, а затем с примеров решения некоторых проблем. Он охватывает необработанную строку, специальные последовательности, метасимволы, функцию, группу захвата и многое другое. Каждая тема хорошо объяснена с хорошими примерами и выводами.
DataQuest: Эта шпаргалка по Regex полезна, особенно если вы разработчик Python.В нем есть правильное объяснение каждой темы, выражения и персонажа. Вы найдете выражения для специальных символов, классов символов, наборов, групп, функций модулей и ценные ресурсы для Python. Кроме того, вы можете бесплатно скачать его PDF-файл.
Заключение
Это все, что у нас есть, если вы ищете хорошую шпаргалку по RegEx. Используйте эти полезные ресурсы для поиска строки символов и ускорения очистки веб-страниц или других вариантов использования. Вы также можете изучить эти удобные инструменты RegEx.
Perl | Шпаргалка по регулярным выражениям
Регулярные выражения или регулярные выражения являются важной частью программирования на Perl . Он используется для поиска указанного текстового шаблона. В этом случае набор символов вместе формирует шаблон поиска. Он также известен как regexp . Когда пользователь изучает регулярное выражение, может возникнуть потребность в быстром взгляде на те концепции, которые он нечасто использовал. Чтобы обеспечить эту возможность, создается шпаргалка по регулярным выражениям, которая содержит различные классы, символы, модификаторы и т. Д.которые используются в регулярном выражении.
Классы символов
Классы символов используются для сопоставления строки символов. Эти классы позволяют пользователю сопоставлять любой диапазон символов, о котором пользователь не знает заранее.
| Классы | Объяснение | |
|---|---|---|
| [abc.] | Включает только один из указанных символов, то есть 'a', 'b', 'c' или '.' | |
| [aj] | It включает все символы от a до j. | |
| [a-z] | Включает все символы нижнего регистра от a до z.cde] | Это соответствует тому, что за символами a и b не должны следовать c, d и e. |
| \ s | Соответствует [\ f \ t \ n \ r], то есть подаче формы, табуляции, новой строке и возврату каретки. | |
| \ W | Дополнение \ w | |
| \ D | Дополнение \ d | |
| \ S | Дополнение \ s |
61 907
$ str = "45char" ;
если ( $ str = ~ / [\ w] /)
{
print «Найдено совпадение \ n»
}
еще
{
печать «Совпадение не найдено \ n» ;
}
Выход:
Соответствие найдено
Якоря
Якоря вообще не соответствуют ни одному символу.
Пример:
|
Вывод:
Match Not Found
Мета-символы
Метасимволы используются для сопоставления шаблонов в регулярных выражениях Perl.
Квантификаторы
Они используются для проверки специальных символов. Существует три типа кванторов
- ‘?’ Соответствует 0 или 1 вхождению символа.
- «+» Соответствует 1 или более вхождению символа.
- ‘*’ Соответствует 0 или более появлению символов.
| Использование квантификаторов | Объяснение |
|---|---|
| a? | Проверяет, встречается ли «a» 0 или 1 раз. |
| a + | Проверяет, встречается ли «а» 1 или более раз |
| a * | Проверяет, встречается ли «а» 0 или более раз |
| a {2, 6} | Это проверяет, встречается ли «а» от 2 до 6 раз |
| a {2,} | Проверяет, встречается ли «а» от 2 до бесконечности |
| a {2} | Проверяет, встречается ли «а» 2 время. |
Пример:
|
Вывод:
Соответствие найдено
Модификаторы
| Модификаторы | Объяснение |
|---|---|
| \ g | Это вхождение, используемое для замены строки. |
| \ gc | Позволяет продолжить поиск после неудачного совпадения \ g. |
| \ s | Строка обрабатывается как одна строка. |
| i | Отключает чувствительность к регистру. |
| \ x | Он игнорирует все пробелы. |
| (? #Text) | Используется для добавления комментария в код. |
| (?: Шаблон) | Он используется для сопоставления шаблона группы без захвата. |
| (? | Шаблон) | Используется для сопоставления шаблона теста ветвления. |
| (? = Шаблон) | Используется для утверждения положительного прогноза. |
| (?! Шаблон) | Используется для утверждения отрицательного просмотра вперед. |
| (<= pattern) | Используется для положительного просмотра утверждения. |
| ( | Используется для отрицательного просмотра утверждения. |
Модификаторы пробела
| Модификаторы | Пояснение |
|---|---|
| \ t | Используется для вставки пространства табуляции |
| \ r | Символ возврата каретки |
| \ h | Используется для вставки горизонтального пробела. |
| \ v | Используется для вставки вертикального пробела. |
| \ L | Используется для символов нижнего регистра. |
| \ U | Используется для символов верхнего регистра. |
Квантификаторы - модификаторы
| Максимальное | Минимальное | Пояснение |
|---|---|---|
| ? | ?? | Может произойти 0 или 1 раз |
| + | +? | Это может происходить 1 или более раз. |
| * | *? | Может встречаться 0 или более раз. |
| {3} | {3}? | Должно совпадать ровно 3 раза. |
| {3,} | {3,}? | Должен совпадать не менее 3 раз. |
| {3, 7} | {3, 7}? | Должны совпадать не менее 3 раз, но не более 7 раз. |
Группирование и захват
Внутри регулярного выражения эти группы упоминаются как «\ 1», а за пределами регулярного выражения эти группы упоминаются как «$ 1».Эти группы могут быть извлечены путем присвоения переменной в контексте списка, известного как захват . Группирующая конструкция (…) создает группы захвата, известные как буферы захвата .
| (…) | Они используются для группировки и захвата. |
| \ 1, \ 2, \ 3 | Во время сопоставления регулярных выражений они используются для захвата буферов. |
| $ 1, $ 2, $ 3 | Во время успешного сопоставления они используются для захвата переменных. |
| (?:…) | Они используются для группировки без захвата. 2025 © Все права защищены. |
Добавить комментарий