
Регулярные выражения — Викиучебник
Регуля́рные выраже́ния (англ. regular expressions, жарг. регэ́кспы или ре́гексы) — система обработки текста, основанная на специальной системе записи образцов для поиска. Образец (англ. pattern), задающий правило поиска, по-русски также иногда называют «шаблоном», «маской».
Сейчас регулярные выражения используются многими текстовыми редакторами и утилитами для поиска и изменения текста на основе выбранных правил. Многие языки программирования уже поддерживают регулярные выражения для работы со строками. Например, Perl и Tcl имеют встроенный в их синтаксис механизм обработки регулярных выражений. Набор утилит (включая редактор sed и фильтр grep), поставляемых в дистрибутивах Unix, одним из первых способствовал популяризации понятия регулярных выражений.
Базовые понятия[править]
Регулярные выражения используются для сжатого описания некоторого множества строк с помощью шаблонов, без необходимости перечисления всех элементов этого множества. При составлении шаблонов используется специальный синтаксис, поддерживающий обычно следующие операции:
При составлении шаблонов используется специальный синтаксис, поддерживающий обычно следующие операции:
- Перечисление
- Вертикальная черта разделяет допустимые варианты. Например, «gray|grey» соответствует gray или grey.
- Группировка
- Круглые скобки используются для определения области действия и приоритета операторов. Например, «gray|grey» и «gr(a|e)y» являются разными образцами, но они оба описывают множество, содержащее gray и grey.
- Квантификация
- Квантификатор после символа или группы определяет, сколько раз предшествующее выражение может встречаться.
- {n,m}
- общее выражение, повторений может быть от n до m включительно.
- {n,}
- общее выражение, n и более повторений.
- {,m}
- общее выражение, не более m повторений.
- {n}
- общее выражение, ровно n повторений
- ?
- Знак вопроса означает 0 или 1 раз, то же самое, что и {0,1}.
 Например, «colou?r» соответствует и color, и colour.
Например, «colou?r» соответствует и color, и colour. - *
- Звёздочка означает 0, 1 или любое число раз ({0,}). Например, «go*gle» соответствует gogle, google, gooogle, ggle, и др.
- +
- Плюс означает хотя бы 1 раз ({1,}). Например, «go+gle» соответствует gogle, google и т. д. (но не ggle).
 Например, «colou?r» соответствует и color, и colour.
Например, «colou?r» соответствует и color, и colour.Конкретный синтаксис регулярных выражений зависит от реализации.
В теории формальных языков[править]
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно. На данном конечном алфавите Σ определены следующие константы:
- (пустое множество) ∅ обозначает ∅
- (пустая строка) ε обозначает множество {ε}
- (строка) a в Σ обозначает множество {a}
и следующие операции:
- (связь, конкатенация) RS обозначает множество { αβ | α из R и β из S }. Пример: {«ab», «c»}{«d», «ef»} = {«abd», «abef», «cd», «cef»}.
- (перечисление) R|S обозначает объединение R и S.
- (замыкание Клини, звезда Клини) R* обозначает минимальное надмножество из R, которое содержит ε и закрыто связью строк. Это есть множество всех строк, которые могут быть получены связью нуля или более строк из R. Например, {«ab», «c»}* = {ε, «ab», «c», «abab», «abc», «cab», «cc», «ababab», … }.
 Пример: {«ab», «c»}{«d», «ef»} = {«abd», «abef», «cd», «cef»}.
Пример: {«ab», «c»}{«d», «ef»} = {«abd», «abef», «cd», «cef»}.Многие книги используют символы ∪, + или ∨ для перечисления вместо вертикальной черты.
Традиционные регулярные выражения в Unix[править]
Синтаксис «базовых» регулярных выражений Unix на данный момент определён POSIX как устаревший, но он до сих пор широко распространён из соображений обратной совместимости. Многие Unix-утилиты используют такие регулярные выражения по умолчанию.
В этом синтаксисе большинство символов соответствуют сами себе («a» соответствует «a» и т.
- Звёздочка после выражения, соответствующего единичному символу, соответствует нулю или более копий этого выражения. Например, «[xyz]*» соответствует пустой строке, «x», «y», «zx», «zyx», и т. д.
- \n*, где n — это цифра от 1 до 9, соответствует нулю или более вхождений для соответствия n-го отмеченного подвыражения. Например, «\(a.\)c\1*» соответствует «abcab» и «abcaba», но не «abcac».
- Выражение, заключённое в «\(» и «\)» и сопровождаемое «*», следует считать неправильным. В некоторых случаях оно соответствует нулю или более вхождений строки, которая была заключена в скобки. В других, оно соответствует выражению, заключённому в скобки, учитывая символ «*».
 д.
д.Различные реализации регулярных выражений интерпретируют обратную косую черту перед метасимволами по-разному. Например, egrep и Perl интерпретируют скобки и вертикальную черту как метасимволы, если перед ними нет обратной косой черты и воспринимают их как обычные символы, если черта есть. \t\n\r\f\v]
\t\n\r\f\v]
Защита метасимволов[править]
Cпособ представить сами метасимволы ., — [ ] и другие в регулярных выражениях без интерпретации, то есть, в качестве простых (не специальных) символов — предварить их обратной косой чертой: \. Например, чтобы представить сам символ «точка» (просто точка, и ничего более), надо написать \. (обратная косая черта, а за ней — точка). Чтобы представить символ открывающей квадратной скобки [, надо написать \[ (обратная косая черта и следом за ней скобка [) и т.д. Сам метасимвол \ тоже может быть защищен, то есть представлен как \\ (две обратных косых черты), и тогда интерпретатор регулярных выражений воспримет его как простой символ обратной косой черты \. >]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного (ленивого, англ. lazy)— большинство реализаций позволяют это сделать, добавив после него знак вопроса.
>]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного (ленивого, англ. lazy)— большинство реализаций позволяют это сделать, добавив после него знак вопроса.
Например, выражению (<.*?>) соответствует не вся показанная выше строка, а отдельные теги (выделены цветом):
<p><b>Википедия</b> — свободная энциклопедия, в которой <i>каждый</i> может изменить или дополнить любую статью</p>
*?— «не жадный» («ленивый») эквивалент*+?— «не жадный» («ленивый») эквивалент+{n,}?— «не жадный» («ленивый») эквивалент{n,}
Использование «ленивых» квантификаторов, правда, может повлечь за собой обратную проблему, когда выражению соответствует слишком короткая строка.
Также существуют квантификаторы повышения жадности, то, что захвачено ими однажды, назад уже не отдается.
Сверхжадные квантификаторы (possessive quantifiers)
*+— «сверхжадный» эквивалент*++— «сверхжадный» эквивалент+{n,}+— «сверхжадный» эквивалент{n,}
Современные (расширенные) регулярные выражения в POSIX[править]
Регулярные выражения в POSIX аналогичны традиционному Unix-синтаксису, но с добавлением некоторых метасимволов:
| + | Указывает на то, что предыдущий символ или группа может повторяться один или несколько раз. В отличие от звёздочки, хотя бы одно повторение обязательно. |
| ? | Делает предыдущий символ или группу необязательной. Другими словами, в соответствующей строке она может отсутствовать, либо присутствовать ровно один раз. |
| | | Разделяет альтернативные варианты регулярных выражений. Один символ задаёт две альтернативы, но их может быть и больше, достаточно использовать больше вертикальных чёрточ |
AWK — Регулярные выражения — CoderLessons. The/’ Выполнив этот код, вы получите следующий результат —
Выход
There
Their
Конец линии
Это соответствует концу строки. Например, в следующем примере печатаются строки, заканчивающиеся буквой n .
пример
[jerry]$ echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
Выход
Выполнив этот код, вы получите следующий результат —
fun
fin
fan
Совпадает с набором символов
Используется для соответствия только одному из нескольких символов. Например, следующий пример соответствует шаблону Call и Tall, но не Ball .
пример
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[CT]all/'
Выход
Выполнив этот код, вы получите следующий результат —
Call
Tall
Эксклюзивный набор
В эксклюзивном наборе карат сводит на нет набор символов в квадратных скобках. Например, следующий пример печатает только Ball . CT]all/’
Выполнив этот код, вы получите следующий результат —
Выход
Ball
Внесение изменений
Вертикальная черта позволяет регулярным выражениям быть логически ИЛИ. Например, следующий пример печатает Ball and Call .
пример
[jerry]$ echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
Выполнив этот код, вы получите следующий результат —
Выход
Call
Ball
Ноль или одно вхождение
Это соответствует нулю или одному вхождению предыдущего символа. Например, следующий пример соответствует цвету, а также цвет . Мы сделали вас необязательным персонажем, используя ? ,
пример
[jerry]$ echo -e "Colour\nColor" | awk '/Colou?r/'
Выполнив этот код, вы получите следующий результат —
Выход
Colour
Color
Ноль или более вхождение
Это соответствует нулю или более вхождений предыдущего символа. Например, следующий пример соответствует ca, cat, catt и так далее.
пример
[jerry]$ echo -e "ca\ncat\ncatt" | awk '/cat*/'
Выполнив этот код, вы получите следующий результат —
Выход
ca
cat
catt
Одно или несколько вхождений
Это соответствует одному или нескольким вхождениям предыдущего символа. Например, приведенный ниже пример соответствует одному или нескольким вхождениям из 2 .
пример
[jerry]$ echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
Выполнив приведенный выше код, вы получите следующий результат —
Выход
22
123
234
222
группирование
Круглые скобки () используются для группировки и символа | используется для альтернатив. Например, следующее регулярное выражение соответствует строкам, содержащим либо Apple Juice, либо Apple Cake .
пример
[jerry]$ echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk
'/Apple (Juice|Cake)/'
Выполнив этот код, вы получите следующий результат —
Регулярные выражения — Традиция
Регуля́рные выраже́ния (англ. regular expressions, жарг. регэ́кспы или ре́гексы) — современная система поиска текстовых фрагментов в электронных документах, основанная на специальной системе записи образцов для поиска. Образец (англ. pattern), задающий правило поиска, по-русски также иногда называют «шаблоном», «маской», или на английский манер «па́ттерном». Регулярные выражения произвели прорыв в электронной обработке текста в конце XX века.
Распространённость[править]
Сейчас регулярные выражения используются многими текстовыми редакторами и утилитами для поиска и изменения текста на основе выбранных правил. Многие языки программирования уже поддерживают регулярные выражения для работы со строками. Например, Perl и Tcl имеют встроенный в их синтаксис механизм обработки регулярных выражений. Набор утилит (включая редактор sed и фильтр grep), поставляемых в дистрибутивах Unix, одним из первых способствовал популяризации понятия регулярных выражений.
Базовые понятия[править]
Регулярные выражения используются для сжатого описания некоторого множества строк с помощью шаблонов, без необходимости перечисления всех элементов этого множества. При составлении шаблонов используется специальный синтаксис, поддерживающий, обычно, следующие операции:
- Перечисление
- Вертикальная черта разделяет допустимые варианты. Например, «gray|grey» соответствует gray или grey.
- Группировка
- Круглые скобки используются для определения области действия и приоритета операторов. Например, «gray|grey» и «gr(a|e)y» являются разными образцами, но они оба описывают множество, содержащее gray и grey.
- Квантификация
- Квантификатор после символа или группы определяет, сколько раз предшествующее выражение может встречаться.
- {m,n}
- общее выражение, повторений может быть от m до n включительно.
- {m,}
- общее выражение, m и более повторений.
- {,n}
- общее выражение, не более n повторений.
- ?
- Знак вопроса означает 0 или 1 раз, то же самое, что и {0,1}. Например, «colou?r» соответствует и color, и colour.
- *
- Звёздочка означает 0, 1 или любое число раз ({0,}). Например, «go*gle» соответствует ggle, gogle, google и др.
- +
- Плюс означает хотя бы 1 раз ({1,}). Например, «go+gle» соответствует gogle, google и т. д. (но не ggle).
Конкретный синтаксис регулярных выражений зависит от реализации.
Истоки регулярных выражений лежат в теории автоматов и теории формальных языков. Эти области изучают вычислительные модели (автоматы) и способы описания и классификации формальных языков. В 1940-x гг. Уоррен Маккалак и Уолтер Питтс описали нервную систему, используя простой автомат в качестве модели нейрона. Математик Стивен Клини позже описал эти модели, используя свою систему математических обозначений, названную «регулярные множества». Кен Томпсон встроил их в редактор QED, а затем в редактор ed под UNIX. С этого времени регулярные выражения стали широко использоваться в Unix и Unix-подобных утилитах, например: expr, awk, Emacs, vi, lex и Perl.
Регулярные выражения в Perl и Tcl происходят от реализации, написанной Генри Спенсером. Филип Хазэль разработал библиотеку pcre (англ. Perl Compatible Regular Expressions — Perl-совместимые регулярные выражения), которая используется во многих современных инструментах, таких как PHP и Apache.
В теории формальных языков[править]
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно. На данном конечном алфавите Σ определены следующие константы:
- (пустое множество) ∅ обозначает ∅
- (пустая строка) ε обозначает множество {ε}
- (строка) a в Σ обозначает множество {a}
и следующие операции:
- (связь, конкатенация) RS обозначает множество { αβ | α из R и β из S }. Пример: {«ab», «c»}{«d», «ef»} = {«abd», «abef», «cd», «cef»}.
- (перечисление) R|S обозначает объединение R и S.
- (замыкание Клини, звезда Клини) R* обозначает минимальное супермножество из R, которое содержит ε и закрыто связью строк. Это есть множество всех строк, которые могут быть получены связью нуля или более строк из R. Например, {«ab», «c»}* = {ε, «ab», «c», «abab», «abc», «cab», «cc», «ababab», … }.
Многие книги используют символы ∪, + или ∨ для перечисления вместо вертикальной черты.
Традиционные регулярные выражения в Unix[править]
Синтаксис «базовых» регулярных выражений Unix на данный момент определён POSIX как устаревший, но он до сих пор широко распространён из соображений обратной совместимости. Многие Unix-утилиты используют такие регулярные выражения по умолчанию.
В этом синтаксисе большинство символов соответствуют сами себе («a» соответствует «a» и т. д.). Исключения из этого правила называются метасимволами:
. Соответствует любому единичному символу. [ ] Соответствует любому единичному символу из числа заключённых в скобки. Соответствует началу текста (или началу любой строки в мультистроковом режиме). $ Соответствует концу текста (или концу любой строки в мультистроковом режиме). \(\) Объявляет «отмеченное подвыражение», которое может быть использовано позже (см. следующий элемент: \n). «Отмеченное подвыражение» также является «блоком». \n Где n — это цифра от 1 до 9; соответствует n-му отмеченному подвыражению. Эта конструкция теоретически нерегулярна, она не была принята в расширенном синтаксисе регулярных выражений. * - Звёздочка после выражения, соответствующего единичному символу, соответствует нулю или более копий этого выражения. Например, «[xyz]*» соответствует пустой строке, «x», «y», «zx», «zyx», и т. д.
- \n*, где n — это цифра от 1 до 9, соответствует нулю или более вхождений для соответствия n-го отмеченного подвыражения. Например, «\(a.\)c\1*» соответствует «abcab» и «abcaba», но не «abcac».
- Выражение, заключённое в «\(» и «\)» и сопровождаемое «*», следует считать неправильным. В некоторых случаях, оно соответствует нулю или более вхождений строки, которая была заключена в скобки. В других, оно соответствует выражению, заключённому в скобки, учитывая символ «*».
\{x,y\} Соответствует последнему блоку, встречающемуся не менее x и не более y раз. Например, «a\{3,5\}» соответствует «aaa», «aaaa» или «aaaaa».
Различные реализации регулярных выражений интерпретируют обратную косую черту перед метасимволами по-разному. Например, egrep и Perl интерпретируют скобки и вертикальную черту как метасимволы, если перед ними нет обратной косой черты и воспринимают их как обычные символы, если черта есть.
Многие диапазоны символов зависят от выбранных настроек локализации. POSIX стандартизовал объявление некоторых классов и категорий символов, как показано в следующей таблице:
POSIX класс подобно означает [:upper:] [A-Z] символы верхнего регистра [:lower:] [a-z] символы нижнего регистра [:alpha:] [A-Za-z] символы верхнего и нижнего регистра [:alnum:] [A-Za-z0-9] цифры, символы верхнего и нижнего регистра [:digit:] [0-9] цифры [:xdigit:] [0-9A-Fa-f] шестнадцатеричные цифры [:punct:] [. >]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного — большинство реализаций позволяют это сделать, добавив после него знак вопроса. Второе решение, правда, может повлечь за собой обратную проблему, когда выражению соответствует слишком короткая строка.Современные (расширенные) регулярные выражения в POSIX[править]
Регулярные выражения в POSIX аналогичны традиционному Unix-синтаксису, но с добавлением некоторых метасимволов:
+ Указывает на то, что предыдущий символ или группа может повторяться один или несколько раз. В отличие от звёздочки, хотя бы одно повторение обязательно. ? Делает предыдущий символ или группу необязательной. Другими словами, в соответствующей строке она может отсутствовать, либо присутствовать ровно один раз. | Разделяет альтернативные варианты регулярных выражений. Один символ задаёт две альтернативы, но их может быть и больше, достаточно использовать больше вертикальных чёрточек. Необходимо помнить, что этот оператор использует максимально возможную часть выражения. По этой причине, оператор альтернативы чаще всего используется внутри скобок.
Также было отменено использование обратной косой черты: \{…\} становится {…} и \(…\) становится (…).
Perl-совместимые регулярные выражения (PCRE)[править]
Регулярные выражения в Perl имеют более богатый и в то же время предсказуемый синтаксис, чем даже в POSIX. По этой причине очень многие приложения используют именно Perl-совместимый синтаксис регулярных выражений.
- NFA (Nondeterministic Finite State Machine; Недетерминированные Конечные Автоматы) используют «жадный» алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (Deterministic Finite-state Automaton; Детерминированные Конечные Автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
- Билл Смит Методы и алгоритмы вычислений на строках (regexp) = Computing Patterns in Strings . — М.: «Вильямс», 2006. — С. 496. — ISBN 0-201-39839-7о книге
- Фридл Дж. Регулярные выражения. Библиотека программиста. — СПб.: Питер, 2001. 352 с. ISBN 5-318-00056-8.
- Бен Форта Освой самостоятельно регулярные выражения (regexp). PHP, Perl, JavaScript, Java, C#(си шарп), Visual Basic, ASP.NET,JSP, MySQL, Unix, Linux = Sams Teach Yourself Regular Expressions in 10 Minutes . — М.: «Вильямс», 2004. — С. 192. — ISBN 0-672-32566-7о книге
eo:Regula esprimo
hu:Szabályos kifejezés
Примеры sed в Linux — синтаксис и регулярные выражения
Операционная система Linux для упрощения ее эксплуатации поддерживает множество специализированных команд. Утилита «sed» — это специфический редактор, позволяющий работать с текстом путем его замены. С помощью данной команды можно редактировать различные файлы без их открытия.
Специальный редактор дает возможность найти, вставить, заменить или удалить определенные фрагменты в файле. Чтобы команда «sed» работала значительно быстрее, потребуется предварительно прописать данные и опции.
Синтаксис
Синтаксис данной утилиты не отличается сложностью. Он представлен в виде:
sed [параметры] [команды] (файл)
Первоначально необходимо изучить основные параметры, которые поддерживает команда:
- «-n» — дает возможность не выводить содержимое, присутствующее в буфере шаблона после каждой итерации.
- «-e» — позволяет выполнить команды, которые необходимы для редактирования текста.
- «-f» — дает возможность прочесть команды, которые были использованы при изменении файла.
- «-l». Опция позволяет указать требуемую длину строки.
- «-r». Опция применяется для включения поддержки синтаксиса расширенного типа, распространяющегося на активно используемые выражения.
- «-i». Функция предназначена для создания копии файла (в резерве) перед тем, как он будет отредактирован.
- «-s». Опция позволяет изучить несколько файлов единовременно. Они будут просмотрены не как длинные потоки, а как отдельные.
Чтобы выполнить несколько действий, используется аргумент «-e».
sed -e [команды] (файл)
Первоначально кажется, что данная утилита очень сложная. На самом деле это не так, ей сможет пользоваться даже новичок в сфере программирования.
Стоит отметить, что данная утилита имеет два отдельно обособленных буфера – это основной и вспомогательный буфер (активного и пассивного плана). Первоначально они абсолютно пусты. Специальная программа передает предварительно определенные условия для всех строк передаваемого файла.
Первоначально программа «sed» изучает одну строку. Из нее удаляются все завершающие данные, а также символы, присутствующие в новой строке. Обрабатываемая стока помещается в главный буфер.
Далее выполняются команды, которые были переданы пользователем в параметрах. За каждой определенной командой закрепляется адрес. Он используется в качестве своеобразного условия. Команда пройдет лишь в том случае, если данное условие будет соблюдено.
После выполнения всех предписанных команд, содержимое буфера шаблона попадает в классический поток вывода. Это происходит в том случае, если предварительно не была указана функция «-n», которая ограничивает вывод содержимого.
Когда символ перевода изначально был удален, он добавляется обратно. Только после этого запускается следующая интерпретация, подразумевающая обработку новой строки.
Когда пользователь не планирует использование специальных команд, после завершения первой интерпретации все содержимое основного буфера будет удалено. Стоит отметить, что содержимое, которое относится к первоначально обработанной строке, сохраняется во вспомогательном буфере. Его применяют в дальнейшем при осуществлении задач.
Особенности адресов, предающихся утилите «sed»
Все команды получают свой адрес. Именно он указывает на строки, для которых выполняется команда:
- «номер». В данном случае прописывается номер определенной строки, где в последующем будет выполняться команда.
- «первая~шаг». Здесь команда выполняется для изначальной части строки, а далее – для всех остальных. В обязательном порядке указывается шаг.
- «$». Обрабатывается последняя строка, которая относится к выбранному вами файлу.
- «/часто используемое_выражение/». Здесь используется любая строка, подходящая по регулярному выражению. Оно не должно зависеть от особенностей регистра.
- «номер, номер». Обработка начинается с начала первой строки, а заканчивается концом второй строки.
- «номер,/регулярное_выражение/». Обработка начинается с первоначальной строки, заканчивается в той, которая соответствует информации в часто используемых фразах.
- «номер+количество». Обработка начинается с верхней строки, длится до той поры, пока не будет исчерпано предварительно указанное число строк.
- «номер~число». Обработка начинается со строки с определенным номеров. Она заканчивается той строкой, которая кратна определенному числовому обозначению.
Когда пользователь не желает задавать определенный адрес для программы «sed», она распространяется на все строки в файле. Если передается один адрес, команда выполняется до той строки, которая расположена по указанному адресу.
Есть возможность передавать диапазон адресов. Информация разделяется запятыми, а команда осуществляется для тех адресов, которые находятся в требуемом диапазоне.
Регулярные выражения
У пользователя есть возможность применить такие же часто используемые выражения, как и в иных наиболее распространенных языках программирования. Стоит рассмотреть ключевой список операторов, поддерживаемых программой «sed»:
- Различные символы и их количество (*).
- Более одного символа (\+).
- Один символ или его отсутствие (\?).
- Любые символы, их количество должно быть равно i (\{i\}).
- Любые символы, их количество должно находиться в пределах от I до j (\{i, j\}).
- Любые символы, их количество должно быть больше i (\{i, \}).
Команды
Если пользователь планирует часто эксплуатировать «sed», он должен знать основной перечень команд, применяемых при редактировании. Стоит рассмотреть основные, которые применяются чаще всего:
- «q». Завершается действие сценария.
- «d». Удаляется первоначальный основной буфер шаблона, запускается следующая интерпретация цикла.
- «p». Выводится содержимое основного буфера.
- «n». Выводится состав основного буфера шаблона. Есть возможность переместить в него последующую строку.
- «s/что_прописать/на_что_поменять/опция». Заменяются символы, имеется возможность ограничить вывод с учетом часто используемых фраз.
- «y/символ/символ». Заменяются символы, присутствующие спереди строки, на те данные, которые имеются во 2 части.
- «w». Записывается содержимое основного буфера шаблона непосредственно в обрабатываемый файл.
- «N». Добавляется перевод строк в основной буфер.
- «D». Удаление основного буфера шаблона, начало интерации следующего цикла, когда в шаблоне не содержится новая строка.
- «g». Замена содержимого основного буфера на состав вспомогательного .
- «G». Добавление новых строчек в состав основного буфера. Сюда же добавляется состав вспомогательного буфера.
Стоит отметить, что утилите «sed» можно придать одновременно определенное количество команд. Для осуществления такой задачи потребуется разделить их точкой с запятой.
Примеры
Для первого примера, заменим каждое вхождение «пример» на «тест» в файле «dokument».
sed 's/пример/тест/g' dokument
ВАЖНО! В операционной системе Линукс очень важен регистр имен. Как видно из скриншота «Пример» и «пример» — это разные слова.
Дополним команду таким образом, чтобы менялось не только слово «пример», но и это же слово написанное с большой буквы. Для этого будем использовать специальные символы «\|». $/d’ file
Утилита «sed» является весьма гибким и максимально удобным инструментом, позволяющим сделать с текстом многие вещи. Такая команда отличается сложностью в усвоении, но дает решить множество задач.
Синтаксис регулярного выражения
Функция Java Perl Обратная косая черта заменяет один метасимвол ДА ДА \ Q … \ E экранирует строку метасимволов Java 6 ДА \ x00 — \ xFF (символ ASCII) ДА ДА \ n (LF) ДА ДА \ f (подача страницы) и \ v (vtab) ДА ДА \ а (звонок) ДА ДА \ e (escape) ДА ДА \ b (пробел) и \ B (обратная косая черта) № № \ cA до \ cZ (управляющий символ) ДА ДА \ ca до \ cz (управляющий символ) № ДА [abc] класс символов ДА ДА [^ abc] класс отрицательных символов ДА ДА [a-z] диапазон классов символов ДА ДА Дефис в [\ d-z] является буквальным ДА ДА Дефис в [a- \ d] является буквальным № № Обратная косая черта экранирует метасимвол класса одного символа ДА ДА \ Q. .. \ E экранирует строку метасимволов класса символов Java 6 ДА \ d сокращение для цифр ascii ДА \ w сокращение для словесных символов ascii ДА \ s сокращение для пробелов ascii ДА \ D ДА ДА [\ b] backspace ДА ДА .(начало строки / строки) ДА ДА $ (конец строки / строки) ДА ДА \ A (начало строки) ДА ДА \ Z (конец строки ДА ДА \ z (конец строки) ДА ДА \ `(начало строки) № № \ ‘(конец строки) № № \ b (в начале или в конце слова) ДА ДА \ B (НЕ в начале и не в конце слова) ДА ДА \ y (в начале или в конце слова) № № \ Y (НЕ в начале и не в конце слова) № № \ м (в начале слова) № № \ M (в конце слова) № № \ <(в начале слова) № № \> (в конце слова) № № | (чередование) ДА ДА Характеристика Java Perl ? (0 или 1) ДА ДА * (0 или больше) ДА ДА + (1 или более) ДА ДА {n} (ровно n) ДА ДА {n ДА ДА {n ДА ДА ? после любого из вышеперечисленных квантификаторов, чтобы сделать его «ленивым» ДА ДА (регулярное выражение) (пронумерованная группа захвата) ДА ДА (?: Regex) (группа без захвата) ДА ДА \ 1 до \ 9 (обратные ссылки) ДА ДА \ 10 до \ 99 (обратные ссылки) ДА ДА Прямые ссылки с \ 1 по \ 9 ДА ДА Вложенные ссылки с \ 1 по \ 9 ДА ДА Несуществующие группы обратных ссылок являются ошибкой ДА ДА Обратные ссылки на неудачные группы также не работают ДА ДА (? I) (без учета регистра) ДА ДА (? S) (точка соответствует символам новой строки) ДА ДА (? M) (^ и $ соответствуют разрывам строки) ДА ДА (? X) (режим свободного интервала) ДА ДА (? N) (явный захват) № № (? -Ismxn) (выключить модификаторы режима) ДА ДА (? Ismxn: group) (модификаторы режима, локальные для группы) ДА ДА Характеристика Java Perl (?> Регулярное выражение) (атомная группа) ДА ДА ? + n} + (притяжательные кванторы) ДА (? = Регулярное выражение) (положительный просмотр вперед) ДА ДА (?! Regex) (отрицательный просмотр вперед) ДА ДА (? <= Текст) (положительный просмотр назад) конечной длины фиксированной длины (? конечной длины фиксированной длины \ G (попытка начала матча) ДА ДА (? (? = Regex) then | else) (с использованием любого поиска) № ДА (? (Регулярное выражение) затем | иначе) № № (? (1) затем | иначе) № ДА (? (Группа) затем | иначе) № № (? # Комментарий) № ДА Поддерживается синтаксис свободного пробела ДА ДА Класс символов — одиночный маркер № ДА # начинает комментарий ДА ДА \ X (графема Unicode) № ДА \ u0000 до \ uFFFF (символ Unicode) ДА № \ x {0} — \ x {FFFF} (символ Unicode) № ДА \ pL через \ pC (свойства Unicode) ДА ДА \ p {L} — \ p {C} (свойства Unicode) ДА ДА \ p {Lu} — \ p {Cn} (свойство Unicode) ДА ДА \ p {L &} и \ p {Letter &} (эквивалент свойств Юникода [\ p {Lu} \ p {Ll} \ p {Lt}]) № ДА \ p {IsL} через \ p {IsC} (свойства Unicode) ДА ДА \ p {IsLu} через \ p {IsCn} (свойство Unicode) ДА ДА \ p {Letter} — \ p {Other} (свойства Unicode) № ДА \ p {нижний регистр} до \ p {Not_Assigned} (свойство Unicode) № ДА \ p {IsLetter} через \ p {IsOther} (свойства Unicode) № ДА \ p {IsLowercase_Letter} через \ p {IsNot_Assigned} (свойство Unicode) № ДА \ p {арабский} через \ p {Yi} (сценарий Unicode) № ДА \ p {IsArabic} через \ p {IsYi} (сценарий Unicode) № ДА \ p {BasicLatin} до \ p {Specials} (блок Unicode) № ДА \ p {InBasicLatin} через \ p {InSpecials} (блок Unicode) ДА ДА \ p {IsBasicLatin} через \ p {IsSpecials} (блок Unicode) № ДА Часть между {} во всем вышеперечисленном не чувствительна к регистру № ДА \ P (отрицательные варианты всех \ p, как указано выше) ДА ДА \ p {^. ..} (инвертированные варианты всех \ p {…}, как указано выше) № ДА (? regex) (именованная группа захвата в стиле .NET) № № (? ‘Name’regex) (именованная группа захвата в стиле .NET) № № \ k <имя> (именованная обратная ссылка в стиле .NET) № № \ k’name ‘(.Именованная обратная ссылка в стиле .NET) № № (? P regex) (именованная группа захвата в стиле Python № № (? P = name) (именованная обратная ссылка в стиле Python) № № несколько групп захвата могут иметь одно и то же имя н / д н / д \ i № № [abc- [abc]] вычитание класса символов № № [: alpha:] Символьный класс POSIX № ДА \ p {Alpha} Символьный класс POSIX ascii № \ p {IsAlpha} Символьный класс POSIX № ДА [. span-ll.] Последовательность сортировки POSIX № № [= x =] Эквивалент символов POSIX № №
Справочник по регулярным выражениям
Справочник по регулярным выражениям на этом веб-сайте работает как ссылка на весь доступный синтаксис регулярных выражений, так и как сравнение функций, поддерживаемых разновидностями регулярных выражений, обсуждаемыми в руководстве. Справочные таблицы содержат невероятное количество информации.Чтобы извлечь из них максимальную пользу, следуйте этой легенде, чтобы научиться их читать.
В таблицах есть шесть столбцов для каждой функции регулярного выражения. Первые четыре объясняют эту функцию.
Feature Имя функции, которая также служит ссылкой на соответствующий раздел в руководстве. Синтаксис Фактический синтаксис регулярного выражения для этой функции. Если синтаксис исправлен, он просто отображается как таковой. Если синтаксис имеет переменные элементы, синтаксис описывается. Описание Краткое описание того, что делает функция. Пример Функциональное регулярное выражение, демонстрирующее функцию.
Последние два столбца показывают, поддерживают ли выбранные вами два варианта регулярного выражения именно эту функцию. Вы можете изменить вкусы, используя раскрывающиеся списки над таблицей. Есть много возможных индикаторов.
ДА Все версии этого варианта поддерживают эту функцию. 3.0 Версия 3.0 и все более поздние версии этого варианта поддерживают эту функцию. Более ранние версии не поддерживают это. только 2.0 Только версия 2.0 поддерживает эту функцию. Более ранние и более поздние версии не поддерживают его. 2.0–2.9 Только версии от 2.0 до 2.9 поддерживают эту функцию. Более ранние и более поздние версии не поддерживают его. Unicode Эта функция работает с символами Unicode во всех версиях этого варианта. кодовая страница Эта функция работает с символами на активной кодовой странице во всех версиях этого варианта. ASCII Эта функция работает с символами ASCII только во всех версиях этого варианта. 3.0 Unicode Эта функция работает с символами Unicode в версиях 3.0 и выше этого варианта. Более ранние версии его вообще не поддерживают. 3.0 Unicode
2.0 ASCII Эта функция работает с символами Unicode в версиях 3.0 и позже этот аромат. Он работает с символами ASCII в версиях от 2.0 до 2.9. Более ранние версии его вообще не поддерживают. 3.0 Кодовая страница Unicode
2.0 Эта функция работает с символами Unicode в версиях 3.0 и более поздних версиях. Он работает с символами активной кодовой страницы в версиях от 2. 0 до 2.9. Более ранние версии его вообще не поддерживают. строка Тип регулярного выражения не поддерживает этот синтаксис. Но строковые литералы на языке программирования, с которыми обычно используется этот вариант регулярного выражения, действительно поддерживают этот синтаксис. 3.0
1.0 строка Версия 3.0 и более поздние версии этого варианта регулярного выражения поддерживают этот синтаксис. Более ранние версии разновидности регулярных выражений не поддерживают этот синтаксис. Но строковые литералы в языке программирования, с которым обычно используется этот вид регулярных выражений, поддерживают этот синтаксис, начиная с версии 1.0. option Все версии этого варианта регулярного выражения поддерживают эту функцию, если вы устанавливаете конкретную опцию или предшествуете ей модификатором определенного режима. option
3.0 Версия 3.0 и все более поздние версии этого варианта регулярного выражения поддерживают эту функцию, если вы устанавливаете конкретную опцию или предшествуете ей модификатором определенного режима. Более ранние версии либо вообще не поддерживают синтаксис, либо не поддерживают модификатор режима для изменения поведения синтаксиса на то, что описывает функция. 3.0
2.0 сбой Версия 3.0 и все более поздние версии этого варианта регулярного выражения поддерживают эту функцию.Версия 2.0 все более поздние выпуски до 3.0 распознают синтаксис, но всегда не соответствуют этому токену регулярного выражения. Версии до 2.0 не поддерживают синтаксис. нет Ни одна из версий этого варианта не поддерживает эту функцию. Нет никаких указаний на то, что на самом деле делает этот синтаксис. Тот же синтаксис может использоваться для другой функции, указанной в другом месте справочной таблицы. Или синтаксис может вызвать ошибку, или он может быть интерпретирован как простой текст. н / д Эта функция не применима к этому варианту регулярных выражений.Функции, описывающие поведение определенного синтаксиса, представленного ранее в справочной таблице, не имеют значения для разновидностей, которые вообще не поддерживают этот синтаксис. сбой Синтаксис распознается вкусом, и регулярные выражения, использующие его, работают, но этот конкретный токен регулярного выражения всегда не соответствует. Регулярное выражение может находить совпадения только в том случае, если этот токен сделан необязательным путем чередования или квантификатора. 2.0–2.9 сбой Версии от 2.0 до 2.9 распознают синтаксис, но всегда не соответствуют этому токену регулярного выражения. Более ранние и более поздние версии либо не распознают синтаксис, либо рассматривают его как синтаксическую ошибку. игнорируется Синтаксис распознается разновидностью, но не делает ничего полезного. Этот конкретный токен регулярного выражения всегда находит совпадение нулевой длины. ошибка Синтаксис распознается разновидностью, но обрабатывается как синтаксическая ошибка.
Когда в этой легенде написано «все версии» или «без версии», это означает все или ни одну из версий каждой разновидности, которые охвачены справочными таблицами:
Для. NET, некоторые функции обозначены как «ECMA» или «non-ECMA». Это означает, что функция поддерживается, только когда RegexOptions.ECMAScript установлен или не установлен. Функции, указанные с помощью «Unicode, отличного от ECMA», соответствуют символам ASCII, если установлен RegexOptions.ECMAScript, и символам Unicode, если RegexOptions.ECMAScript не установлен. Все, что применимо к .NET 2.0 или более поздней версии, также применимо к любой версии .NET Core. В среде IDE Visual Studio используется вариант .NET, отличный от ECMA, начиная с VS 2012.
Для вариантов std :: regex и boost :: regex есть дополнительные индикаторы ECMA, базовый, расширенный, grep, egrep и awk.Когда появляется один или несколько из них, это означает, что функция поддерживается только в том случае, если вы укажете одну из этих грамматик при компиляции регулярного выражения. Функции с индикаторами Unicode соответствуют символам Unicode при использовании std :: wregex или boost :: wregex в строках широких символов. В ссылке на заменяющую строку дополнительными индикаторами являются sed и default. Когда появляется один из них, функция поддерживается только в том случае, если вы передаете или не передаете match_flag_type :: format_sed в regex_replace ().Для ускорения есть еще один индикатор замены «все», который указывает, что функция поддерживается только тогда, когда вы передаете match_flag_type :: format_all в regex_replace ().
Для варианта PCRE2 некоторые функции замещающей строки обозначены как «расширенный». Это означает, что функция поддерживается только при передаче PCRE2_SUBSTITUTE_EXTENDED в pcre2_substitute.
Сделайте пожертвование
Этот веб-сайт только что сэкономил вам поездку в книжный магазин? Сделайте пожертвование на поддержку этого сайта, и вы получите пожизненного доступа без рекламы к этому сайту!
Справка по синтаксису регулярных выражений — Справка
\ Помечает следующий символ как специальный символ или литерал.
Соответствует началу ввода. $ Соответствует концу ввода. * Соответствует предыдущему символу ноль или более раз. Например, «zo *» соответствует либо z , либо zoo . + Соответствует предыдущему символу один или несколько раз. Например, «zo +» соответствует zoo , но не z . ? Соответствует предыдущему символу ноль или один раз. Например, a? Ve? соответствует ve в никогда не . . Соответствует любому одиночному символу, кроме символа новой строки. ( подвыражение ) Соответствует подвыражению и запоминает совпадение.Если часть регулярного выражения заключена в круглые скобки, эта часть регулярного выражения сгруппирована вместе. Таким образом, оператор регулярного выражения может применяться ко всей группе.
Если вам нужно использовать совпадающую подстроку в одном регулярном выражении, вы можете получить ее, используя обратную ссылку \ num , где num = 1..n .
Если вам нужно сослаться на совпавшую подстроку где-то за пределами текущего регулярного выражения (например, в другом регулярном выражении как заменяющую строку), вы можете получить ее, используя знак доллара $ num , где num = 1 ..n .
Если вам нужно включить символы круглых скобок в подвыражение , используйте \ ( или \) .
x | y Соответствует x или y . Например, z | wood соответствует z или wood . (z | w) oo соответствует zoo или wood . { n } n — неотрицательное целое число. Совпадает ровно n раз. Например, o {2} не соответствует o в Bob , но соответствует первым двум o в foooood . { n ,} n — неотрицательное целое число. Соответствует как минимум n раз.
Например, o {2,} не соответствует o в Bob и соответствует всем o в «foooood».
o {1,} эквивалентно o + . o {0,} эквивалентно o * .
{ n , m } m и n — неотрицательные целые числа.Совпадает минимум n и максимум m раз. Например, o {1,3} соответствует первым трем o в «fooooood». o {0,1} эквивалентно o? . [ xyz ] Набор символов. Соответствует любому из заключенных символов. Например, [abc] соответствует a в обычном .m-z] соответствует любому символу вне диапазона от m до z . \ b Соответствует границе слова, то есть позиции между словом и пробелом. Например, er \ b соответствует er в , никогда , но не er в глаголе . \ B Соответствует границе, отличной от слова.0-9] . \ f Соответствует символу подачи страницы. \ n Соответствует символу новой строки. \ r Соответствует символу возврата каретки. \ s Соответствует любому пустому пространству, включая пробел, табуляцию, подачу страницы и т. Д. Эквивалент [\ f \ n \ r \ t \ v] . \ S Соответствует любому символу, отличному от пробела. \ f \ n \ r \ t \ v] . \ t Соответствует символу табуляции. \ v Соответствует символу вертикальной табуляции. \ w Соответствует любому символу слова, включая подчеркивание. Эквивалент [A-Za-z0 -9_] . Используйте его в поле поиска . \ W Соответствует любому символу, не являющемуся словом.А-За-z0-9_] . \ num Соответствует num , где num — положительное целое число, обозначающее обратную ссылку на запомненные совпадения.
Например, (.) \ 1 соответствует двум идущим подряд идентичным символам.
\ n Соответствует n , где n — восьмеричное escape-значение. Восьмеричные escape-значения должны состоять из 1, 2 или 3 цифр. Например, \ 11 и \ 011 соответствуют символу табуляции.
\ 0011 является эквивалентом \ 001 и 1 .
Восьмеричные escape-значения не должны превышать 256. Если это так, только первые две цифры составляют выражение. Позволяет использовать коды ASCII в регулярных выражениях.
\ x n Соответствует n , где n — шестнадцатеричное escape-значение. Шестнадцатеричные escape-значения должны состоять ровно из двух цифр.
Например, \ x41 соответствует A . \ x041 эквивалентно \ x04 и 1 .
Позволяет использовать коды ASCII в регулярных выражениях.
\ $ Находит символ $ . \\ $ Это регулярное выражение, введенное в поле поиска , означает, что вы пытаетесь найти символ \ в конце строки. \ l Меняет регистр следующего символа на нижний. Используйте этот тип регулярного выражения в поле replace . \ u Изменяет регистр следующего символа на верхний регистр.Используйте этот тип регулярного выражения в поле replace . \ L Изменяет регистр всех последующих символов до \ E на нижний регистр. Используйте этот тип регулярного выражения в поле replace . \ U Изменяет регистр всех последующих символов до \ E на верхний регистр. Используйте этот тип регулярного выражения в поле replace . (?!) Это шаблон для «отрицательного просмотра вперед».Например, A (?! B) означает, что CLion будет искать A , но только если за ним не будет B . (? =) Это шаблон для «положительного просмотра вперед». Например, A (? = B) означает, что CLion будет искать A , но совпадать, если только за ним следует B . (? <=) Это шаблон для «положительного просмотра назад».Например, (? <= B) A означает, что CLion будет искать A , но только если перед ним стоит B . (? Это шаблон для «отрицательного просмотра назад». Например, (? означает, что CLion будет искать A , но только если перед ним нет B .
Справочник по синтаксису регулярных выражений
Синтаксис регулярного выражения
[Все права защищены: http: // www.regexlab.com/en/regref.htm]
Введение
Регулярное выражение предназначено для выражения характеристики в строке, а затем для сопоставления другой строки с этой характеристикой. Например, шаблон «ab +» означает «один 'a' и хотя бы один 'b», поэтому «ab», «abb», «abbbbbbb» соответствуют образцу.
Регулярное выражение используется для: (1) проверки строки на соответствие шаблону, например, адресу электронной почты. (2) найти подстроку, соответствующую определенному шаблону, из всего текста.(3) делать сложные замены в тексте.
Изучить синтаксис регулярных выражений очень просто, и несколько абстрактных концепций тоже можно легко понять. Многие статьи не вводят его концепции от простых к абстрактным шаг за шагом, поэтому некоторым людям это может показаться трудным.
учиться. С другой стороны, каждый документ обработчика регулярных выражений будет описывать его специальную функцию, но эту часть специальной функции мы не должны изучать в первую очередь.
В каждом примере в этой статье есть ссылка на тестовую страницу.А теперь приступим!
1. Базовый синтаксис регулярного выражения
1. 1 Общие символы
Буквы, цифры, подчеркивание и знаки препинания без специального определения являются «общими символами». Когда регулярное выражение соответствует строке, общий символ может соответствовать одному и тому же символу.
Пример 1: Когда шаблон «c» соответствует строке «abcde», результат сопоставления: успех; совпадение подстроки: "c"; позиция: начинается с 2, заканчивается на 3.
Пример 2: Когда шаблон «bcd» соответствует строке «abcde» , результат сопоставления: успех; совпадение подстроки: "bcd"; позиция: начинается с 1, заканчивается на 4.
1,2 Простые экранированные символы
известных нам непечатаемых символов:
Выражение
совпадений
\ r, \ n
Возврат каретки, символ новой строки
\ т
Вкладки
\
Соответствует самому "\"
Некоторые знаки препинания специально определены в регулярных выражениях. "сам
\ $
Соответствует самому "$"
\.
Соответствует самой точке (.)
Эти экранированные символы имеют тот же эффект, что и «обычные символы»: соответствуют определенному символу.
Пример 1: Когда шаблон «\ $ d» соответствует строке «abc $ de», результат сопоставления: успех; совпадение подстроки: "$ d"; позиция: начинается с 3, заканчивается на 5.
1.3 Выражение соответствует любому из многих символов
Некоторым выражениям может соответствовать любой из многих символов. Например: «\ d» может соответствовать любому цифровому символу. Каждое из этих выражений может одновременно соответствовать только одному символу, хотя они могут соответствовать любому символу определенной группы символов.
Выражение
совпадений
\ d
Любая цифра, любая из 0 ~ 9
\ w
Любые буквы, цифры, подчеркивание, любое из A ~ Z, a ~ z, 0 ~ 9, _
\ с
Любой один из символов пробела, табуляции, новой строки, возврата или новой страницы
.
'.' соответствует любому символу, кроме символа новой строки (\ n)
Пример 1: Когда шаблон «\ d \ d» соответствует «abc123», результат сопоставления: успех; совпадение подстроки: "12"; позиция: начинается с 3, заканчивается на 5.
Пример 2: Когда шаблон «a. \ d» соответствует «aaa100», результат сопоставления: успех; совпадение подстроки: "aa1"; позиция: начинается с 1, заканчивается на 4.
1.4 Пользовательское выражение соответствует любому из множества символов
В выражении
квадратные скобки [] используются для обозначения ряда символов, оно может соответствовать любому из них.abc] "соответствует" abc123 ", результат соответствия: успех; подстрока сопоставлена:" 1 "; позиция: начинается с 3, заканчивается на 4.
1,5 Специальное выражение для количественной оценки соответствия
Все введенные ранее выражения могут соответствовать символу только один раз. Если за выражением следует квантификатор, оно может совпадать более одного раза.
Например: мы можем использовать шаблон «[bcd] {2}» вместо «[bcd] [bcd]».
Выражение
Функция
{n}
Совпадение ровно n раз, например: «\ w {2}» равно «\ w \ w»; «а {5}» равно «ааааа»
{m, n}
Не менее m, но не более n раз:
«ba {1,3}» соответствует «ba», «baa», «baaa»
{м,}
Совпадение не менее n раз:
«\ w \ d {2,}» соответствует «a12», «_ 456», «M12344»...
?
Совпадение 1 или 0 раз, что эквивалентно {0,1}:
"а [cd]?" соответствует "a", "ac", "ad".
Соответствует началу строки
$
Соответствует концу строки
\ b
Соответствует границе слова
Дополнительные примеры, которые помогут вам понять."должен соответствовать началу строки. Он может быть успешным при условии, что" aaa "находится в
начало строки, например «aaa xxx xxx».
Пример 2: Когда шаблон «aaa $» соответствует «xxx aaa xxx», результат сопоставления: не удалось. Bacause «$» должен соответствовать концу строки. Он может успешно соответствовать при условии, что "ааа" находится в конце
строка, например «xxx xxx aaa».
Пример 3: Когда шаблон ". \ B." соответствует "@@@ abc", результат совпадения: успех; подстрока найдена: "@a"; позиция: начинается с 2, заканчивается на 4."и" $ "не соответствует ни одному символу, но для него требуется символ '\ w' на одной стороне, а другой - не символ '\ w' на другой стороне.
Пример 4: Когда соответствует шаблон" \ bend \ b " "выходные, конец, конец", результат совпадения: успех; подстрока сопоставлена: "конец"; позиция: начинается с 15, заканчивается в 18.
Некоторые особые знаки препинания могут повлиять на другие подшаблоны:
Выражение
Функция
|
Чередование, соответствует либо левой, либо правой стороне
()
(1).При количественной оценке позвольте подшаблонам в нем составлять целую часть.
(2). Результат совпадения подшаблонов в нем можно получить индивидуально
Пример 5: Когда шаблон «Том | Джек» соответствует строке «Я Том, он Джек», результат сопоставления: успех; подстрока найдена: "Tom"; позиция: начинается с 4, заканчивается на 7. Когда матч следующий,
результат матча: успех; совпадение подстроки: "Джек"; позиция: начинается с 15, заканчивается в 19.
Пример 6: Когда шаблон «(go \ s *) +» совпадает с «Поехали, вперед!», результат совпадения: успех; подстрока совпала: "вперед, вперед, вперед"; позиция: начинается с 6, заканчивается в 14.
Пример7: Когда шаблон «¥ (\ d + \.? \ D *)» соответствует «$ 10,9, ¥ 20,5», результат сопоставления: успех; подстрока найдена: "¥ 20,5"; позиция: начинается в 6, заканчивается в 10. Матч
Результат подшаблонов в "()": "20,5".
2. Расширенный синтаксис регулярных выражений
2.1 Неохотные или жадные кванторы
Существуют сервальные методы для количественной оценки подшаблонов, например: «{m, n}», «{m,}», «?», «*», «+».По умолчанию квантифицированный подшаблон является «жадным», то есть он будет соответствовать столько раз, сколько возможно (с учетом конкретного начального местоположения), при этом разрешая
остальная часть шаблона, чтобы соответствовать. Например, для соответствия «dxxxdxxxd»:
Выражение
Результат матча
(г) (\ ш +)
«\ w +» соответствует всем символам «xxxdxxxd» после «d»
(г) (\ w +) (г)
«\ w +» соответствует всем символам «xxxdxxx» между первым «d» и последним «d».Чтобы обеспечить успешное совпадение всего шаблона, "\ w" должен отказаться от последнего "d", хотя он может соответствовать и последнему "d".
Таким образом, можно увидеть, что: когда "\ w +" совпадает, он будет соответствовать как можно большему количеству символов. Во втором примере он не соответствует последнему «d», но это необходимо для того, чтобы весь шаблон совпадал успешно. Шаблон с "*" или "{m, n}" будет
также совпадать как можно больше раз, шаблон с "?" будет соответствовать, если возможно. Этот тип сопоставления называется «жадным сопоставлением». 9
Сопоставление с противодействием:
Чтобы после квантификатора ставился знак «?», Он может позволить шаблону соответствовать минимально возможное количество раз. Этот тип сопоставления называется сопоставлением с неохотой. Чтобы обеспечить успешное совпадение всего шаблона, неохотный шаблон может соответствовать
еще несколько раз, если потребуется. Например, для соответствия «dxxxdxxxd»:
Выражение
Результат матча
(г) (\ ш +?)
"\ w +?" совпадать как можно меньше раз, поэтому "\ w +?" соответствует только одному "x"
(г) (\ w +?) (Г)
Чтобы разрешить совпадение всего шаблона, "\ w +?" должно соответствовать "xxx". Итак, результат совпадения: "\ w +?" соответствует "xxx"
Дополнительные примеры:
Пример 1: Когда шаблон «
(. *) » соответствует «
aa
bb < / p>
", результат совпадения:
успех; подстрока соответствует: весь "
aa
bb
", "
" в шаблоне соответствует последнему «
» в строке.
Example2: Для сравнения, когда шаблон «
(. *?) » соответствует строке в example1, он соответствует
"
aa
". При следующем совпадении может быть сопоставлен следующий "
bb
".
2.2 Обращение к совпавшей подстроке \ 1, \ 2 ...
В процессе сопоставления результаты сопоставления подшаблона в круглых скобках «()» записываются для дальнейшего использования.При получении результатов совпадения эти результаты соответствия подшаблона могут быть получены индивидуально, и это было продемонстрировано
много раз в предыдущих примерах. На практике круглые скобки «()» должны использоваться, чтобы получить то, что мы действительно хотим после совпадения, например «
(. *?) ».
Фактически, результат совпадения подшаблона в круглых скобках может использоваться не только после сопоставления, но и во время сопоставления. Последняя часть подшаблона может ссылаться на результат совпадения с предыдущим подшаблоном.Использование: "\" плюс число для обозначения
соответствующая подстрока. «\ 1» относится к результату сопоставления 1-й пары круглых скобок, «\ 2» относится к результату сопоставления 2-й пары скобок.
Примеры:
Пример1: Когда шаблон "('|") (. *?) (\ 1) "соответствует"' Hello ', "World" ", результат соответствия: успех; совпадение подстроки:"' Hello '"; при совпадении next подстрока сопоставлено: "" World "".
Пример 2: когда шаблон "(\ w) \ 1 {4,}" соответствует "aa bbbb abcdefg ccccc 111121111 999999999", результат сопоставления: успех; совпадение подстроки:
"ccccc"; при следующем совпадении подстрока соответствует «999999999». " , "$" , "\ b".Все они не соответствуют никаким символам, но все они требуют определенных условий для их положения. Теперь в этой главе будут представлены дополнительные методы добавления
условия на разрыв между персонажами.
Утверждение
Lookahead: "(? = Xxxxx)", "(?! Xxxxx)"
Формат
: "(? = Xxxxx)", условие, которое оно добавляет в пробел, следующее: строка с правой стороны пробела должно быть abe, чтобы соответствовать подшаблону «xxxxx» в круглых скобках. Это просто условие, а не операция сопоставления, поэтому результата сопоставления нет.
Пример 1: Когда шаблон «Windows (? = NT | XP)» соответствует «Windows 98, Windows NT, Windows 2000», он может соответствовать только «Windows» в «Windows NT»,
другие "винды" сопоставить не удалось.
Пример 2: Когда шаблон "(\ w) ((? = \ 1 \ 1 \ 1) (\ 1)) +" соответствует "aaa ffffff 999999999", он может соответствовать первым 4 "f" из 6 "f "s, это может соответствовать
первые 7 "9" из 9 "9".
Формат: «(?! Xxxxx)», строка с правой стороны пробела не должна соответствовать подшаблону «xxxxx».
Пример 3: Когда шаблон «((?! \ Bstop \ b).) +» Соответствует «fdjka ljfdl stop fjdsla fdj», он будет соответствовать от начала строки до позиции «stop». Если в строке нет «стопа», шаблон будет соответствовать всей строке.
Пример 4: Когда шаблон «do (?! \ W)» соответствует «done, do, dog», он может соответствовать только «do». Здесь «(?! \ W)» имеет тот же эффект, что и «\ b».
Утверждение просмотра назад: "(? <= Xxxxx)", "(?
Концепции «утверждения просмотра назад» и «утверждения просмотра вперед» аналогичны.«(? <= xxxxx)» и «(?
Пример 5: Когда шаблон "(? <= \ D {4}) \ d + (? = \ D {4})" соответствует "12345678
456", он будет соответствовать 8 числам в середине, кроме первых 4 чисел и последних 4 числа. Поскольку утверждение просмотра назад не поддерживается JScript.RegExp, этот пример не может быть
продемонстрировал.Есть много механизмов, поддерживающих утверждение lookbehind, например пакет java.util.regex в Java 1.4 или новее, пространство имен System.Text.RegularExpressions на платформе .NET, механизм DEELX Regexp и т. Д.
3. Другие обычно поддерживаемые правила
Есть несколько обычно поддерживаемых правил, о которых не упоминалось.
3.1 В шаблоне символ может быть выражен как «\ xXX» или «\ uXXXX» («X» - шестнадцатеричное число)
Формат
Диапазон символов
\ xXX
0 ~ 255, например, пробел может быть "\ x20"
\ uXXXX
Любой символ может быть выражен как "\ u" плюс 4 шестнадцатеричных числа, например "\ u4E2D"
3. "сам
$
Соответствует концу строки. Используйте "\ $" для соответствия самому "$"
()
Группировка. Используйте "\ (" и "\)" для соответствия "(" и ")"
[]
Класс символов. Используйте «\ [» и «\]» для соответствия «[» и «]»
{}
Определите кванторы.Используйте "\ {" и "\}" для соответствия "{" и "}"
.
Соответствует любому символу, кроме новой строки (\ n). Используйте "\." чтобы соответствовать "." сам
?
Пусть подшаблон соответствует 0 или 1 раз. Используйте "\?" чтобы соответствовать "?" сам
+
Пусть подшаблон соответствует как минимум 1 раз. Используйте "\ +" для соответствия самому "+"
*
Разрешить совпадение подмаски в любое время. Используйте "\ *" для соответствия самому "*"
|
Чередование. Используйте "\ |" соответствовать "|" сам
3.4 Если подшаблон находится в «(?: Xxxxx)», результат соответствия не записывается для дальнейшего использования.
Пример1: Когда шаблон «(?: (\ W) \ 1) +» соответствует «a bbccdd efg», подстрока соответствует: «bbccdd».Результат соответствия подшаблона в "(? :)" не записывается, поэтому используется "\ 1"
для ссылки на результат совпадения "(\ w)".
3.5 Атрибут шаблона: Игнорировать регистр , Однострочный , Многострочный , Глобальный
Атрибут
Описание
Игнорировать регистр
Сопоставление с образцом без учета регистра. По умолчанию учитывается регистр."и" $ "соответствуют только самому началу very строки и концу④ строки. Если они многострочные, они соответствуют началу③ любой строки и концу② любой строки в строке:
①xxxxxxxxx② \ n
③xxxxxxxxx④
Весь мир
Заменить все совпадения, если шаблон используется в операции замены.
4. Встроенная подсказка
4.1. Если вы хотите узнать, что еще реализовано в продвинутых движках, вы можете обратиться к синтаксису DEELX на этом сайте.\ d + $ "требует, чтобы вся строка состояла из цифр.
4.3 Если требуется, чтобы шаблон соответствовал всему слову, а не его части, мы можем использовать "\ b" в начале и в конце шаблона, например:
используйте "\ b (if | while | else | void | int ……) \ b" для сопоставления ключевых слов в программе.
4. 4 Не позволять шаблону соответствовать пустой строке "". Или вы получите сопоставленную пустую подстроку, в то время как операция сопоставления возвращает успех. Например: если нам нужен шаблон для соответствия "123" 、 "123."、" 123,5 "、". 5 ", мы не должны использовать этот шаблон" \ d * \.? \ D * ". Хотя есть
ничего, мы все еще можем добиться успеха.
Правильный шаблон: "\ d + \.? \ D * | \. \ D +".
4.5 Не позволяйте подшаблону повторяться бесконечно долго, если подшаблон может соответствовать пустой строке.
4.6 Правильно выберите неохотный или жадный квантификатор.
4,7 Только одна сторона "|" чтобы соответствовать определенному персонажу.
5. Относительные рекламные ссылки
[DEELX Regexp Engine] - Самый удобный механизм регулярных выражений для использования. шаблон поиска
позволяет найти все строки, начинающиеся с символа.
$ 9 1095 Конец строки. Например, шаблон поиска $ позволяет найти все строки, заканчивающиеся на. . Соответствует любому одиночному символу, кроме символа новой строки. Для поиска любого символа, включая символ новой строки, вы можете использовать шаблон [\ s \ S] или включить однострочный режим с помощью модификатора (? S). * Звездочка означает «повторитель».* означает 0 или более вхождений предыдущего символа или подвыражения. Например, шаблон abc * d соответствует abd, abcd, abccd, но не a или abcx. Шаблон. * Соответствует строке любой длины (включая пустую строку), не содержащей символа новой строки. Токен * эквивалентен {0,}. + Плюс - это символ- «повторитель». + обозначает одно или несколько вхождений предыдущего символа или подвыражения. Например, шаблон ab + d
соответствует abbd или abbbd, но не соответствует abcd или abbcd. Токен + эквивалентен {1,}. ? Знак вопроса означает 0 или одно вхождение предыдущего символа или подвыражения. Например, abc? D найдет abd и abcd,
но не abccd. ? токен эквивалентен {0,1}. a { n } n случаев a . Например, fo {2} t будет
найди ногу, но не ногу или ногу. a { n ,} n или более случаев a .Например, ab {2,} c будет
найдите abbc, abbbc, abbbbc, но не abc. a { n , m } n или больше, но меньше или равно m экземпляров a .
Например, ab {2,3} c найдет abbc, но не abc или abbbbc. Примечание:
? Токен можно использовать после * , + , {n,} и {n, m} .При этом он делает шаблон поиска не жадным, то есть шаблон соответствует как можно меньшему количеству символов или подвыражений. Например, при поиске в строке abbbbbcd шаблон b {3,} вернет bbbbb, а b {3,}? вернет bbb (то есть без вопросительного знака вы получите строку из пяти символов «b», а с вопросительным знаком - строку из трех символов «b»). Аналогично, при поиске той же строки с использованием шаблона b {2,4} вы получите bbbb; при использовании b {2,4}? вы получите bb.k-x] z соответствует abz, aiz и ayz,
но не акз. ( ааа ) Обозначает подвыражение. Например, шаблон (абра) (кадабра) содержит два подвыражения: абра и кадабра. Чтобы указать круглую скобку, которую следует рассматривать буквально, поставьте после нее обратную косую черту: \ (или \). и | б Либо a , либо b . Например, ab | cde соответствует ab и cde, но не abde.e, dbe или dce. \ x NN Символ с шестнадцатеричным кодом ASCII NN . Например, A \ x31B будет
найти строку A1B. (Шестнадцатеричный 31 - это ASCII
код 1 ). Вы также можете использовать \ x { NNNN } для поиска символов, код которых занимает более одного байта (Unicode).
\ т Символ табуляции. \ п Символ новой строки.\ t \ n \ r \ f]. \ b Обозначает границу слова, то есть позицию между символом слова и пробельным символом. Например, oo \ b соответствует oo в foo, но не в foot. Аналогично, \ bfo соответствует fo in foot, но не in afoot. \ B Обозначает любую позицию в слове, кроме границы. Например, oo \ B соответствует oo в foot, но не в foo. Примечание:
Вы можете использовать выражения \ t , \ w , \ W , \ d , \ D , \ s , \ S , \ b и \ B в скобках.Например, b [\ d-e] b будет
найдите b1b, b2b или beb.
Синтаксис регулярного выражения: Справочное руководство GLib
Синтаксис регулярного выражения
Синтаксис регулярного выражения -
синтаксис и семантика регулярных выражений, поддерживаемых GRegex
Подробности регулярного выражения GRegex
Регулярное выражение - это шаблон, который сопоставляется с
строка слева направо.Большинство персонажей в
шаблон и сопоставьте соответствующие символы в строке. Как
тривиальный пример, шаблон
Быстрая коричневая лисица
соответствует части строки, которая идентична самой себе. когда
указано соответствие без регистра (флаг G_REGEX_CASELESS ), буквы
совпадают независимо от случая.
Сила регулярных выражений заключается в возможности включать
альтернативы и повторы в выкройке. Они закодированы в
паттерн за счет использования метасимволов, которые не обозначают сами себя
но вместо этого интерпретируются особым образом.
подтвердить начало строки (или строки в многострочном режиме) $ подтвердить конец строки (или строки в многострочном режиме) . соответствует любому символу, кроме новой строки (по умолчанию) [ определение класса начального символа | запуск альтернативной ветки ( стартовый подшаблон ) конечный подшаблон ? расширяет значение (, или квантификатор 0/1, или минимизатор квантора * 0 или более квантор + 1 или несколько кванторов, также «притяжательный квантор» { начальный мин. / Макс. Квантор
 The/’
The/’ CT]all/’
CT]all/’ Например, следующий пример соответствует ca, cat, catt и так далее.
Например, следующий пример соответствует ca, cat, catt и так далее. regular expressions, жарг. регэ́кспы или ре́гексы) — современная система поиска текстовых фрагментов в электронных документах, основанная на специальной системе записи образцов для поиска. Образец (англ. pattern), задающий правило поиска, по-русски также иногда называют «шаблоном», «маской», или на английский манер «па́ттерном». Регулярные выражения произвели прорыв в электронной обработке текста в конце XX века.
regular expressions, жарг. регэ́кспы или ре́гексы) — современная система поиска текстовых фрагментов в электронных документах, основанная на специальной системе записи образцов для поиска. Образец (англ. pattern), задающий правило поиска, по-русски также иногда называют «шаблоном», «маской», или на английский манер «па́ттерном». Регулярные выражения произвели прорыв в электронной обработке текста в конце XX века. При составлении шаблонов используется специальный синтаксис, поддерживающий, обычно, следующие операции:
При составлении шаблонов используется специальный синтаксис, поддерживающий, обычно, следующие операции:- {m,n}
- общее выражение, повторений может быть от m до n включительно.
- {m,}
- общее выражение, m и более повторений.
- {,n}
- общее выражение, не более n повторений.
- ?
- Знак вопроса означает 0 или 1 раз, то же самое, что и {0,1}. Например, «colou?r» соответствует и color, и colour.
- *
- Звёздочка означает 0, 1 или любое число раз ({0,}). Например, «go*gle» соответствует ggle, gogle, google и др.
- +
- Плюс означает хотя бы 1 раз ({1,}). Например, «go+gle» соответствует gogle, google и т. д. (но не ggle).



- Звёздочка после выражения, соответствующего единичному символу, соответствует нулю или более копий этого выражения. Например, «[xyz]*» соответствует пустой строке, «x», «y», «zx», «zyx», и т. д.
- \n*, где n — это цифра от 1 до 9, соответствует нулю или более вхождений для соответствия n-го отмеченного подвыражения. Например, «\(a.\)c\1*» соответствует «abcab» и «abcaba», но не «abcac».
- Выражение, заключённое в «\(» и «\)» и сопровождаемое «*», следует считать неправильным. В некоторых случаях, оно соответствует нулю или более вхождений строки, которая была заключена в скобки. В других, оно соответствует выражению, заключённому в скобки, учитывая символ «*».
 Например, «\(a.\)c\1*» соответствует «abcab» и «abcaba», но не «abcac».
Например, «\(a.\)c\1*» соответствует «abcab» и «abcaba», но не «abcac». >]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного — большинство реализаций позволяют это сделать, добавив после него знак вопроса. Второе решение, правда, может повлечь за собой обратную проблему, когда выражению соответствует слишком короткая строка.
>]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного — большинство реализаций позволяют это сделать, добавив после него знак вопроса. Второе решение, правда, может повлечь за собой обратную проблему, когда выражению соответствует слишком короткая строка.Современные (расширенные) регулярные выражения в POSIX[править]
Регулярные выражения в POSIX аналогичны традиционному Unix-синтаксису, но с добавлением некоторых метасимволов:
| + | Указывает на то, что предыдущий символ или группа может повторяться один или несколько раз. В отличие от звёздочки, хотя бы одно повторение обязательно. |
| ? | Делает предыдущий символ или группу необязательной. Другими словами, в соответствующей строке она может отсутствовать, либо присутствовать ровно один раз. |
| | | Разделяет альтернативные варианты регулярных выражений.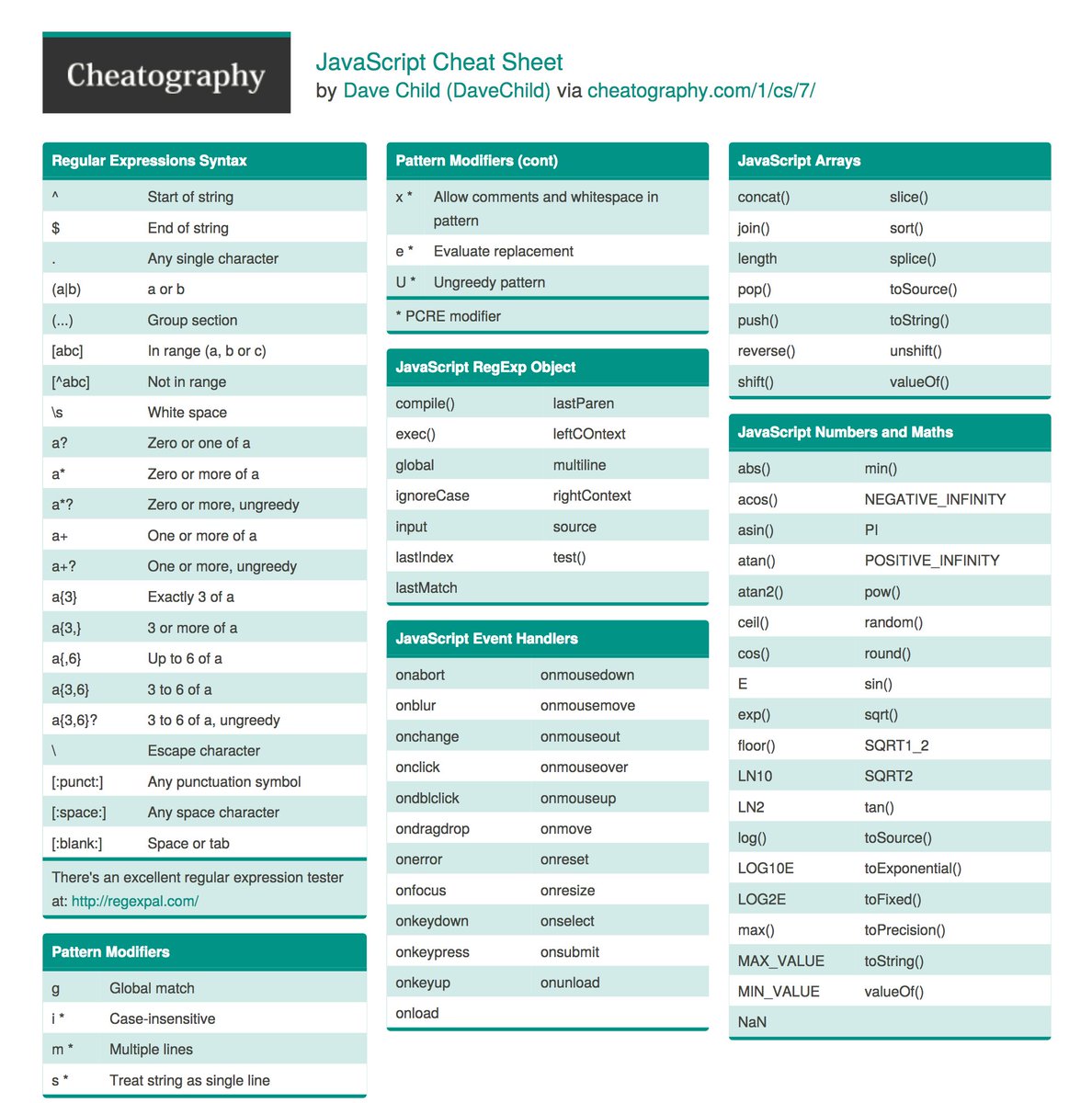 Один символ задаёт две альтернативы, но их может быть и больше, достаточно использовать больше вертикальных чёрточек. Необходимо помнить, что этот оператор использует максимально возможную часть выражения. По этой причине, оператор альтернативы чаще всего используется внутри скобок. Один символ задаёт две альтернативы, но их может быть и больше, достаточно использовать больше вертикальных чёрточек. Необходимо помнить, что этот оператор использует максимально возможную часть выражения. По этой причине, оператор альтернативы чаще всего используется внутри скобок. |
Также было отменено использование обратной косой черты: \{…\} становится {…} и \(…\) становится (…).
Perl-совместимые регулярные выражения (PCRE)[править]
Регулярные выражения в Perl имеют более богатый и в то же время предсказуемый синтаксис, чем даже в POSIX. По этой причине очень многие приложения используют именно Perl-совместимый синтаксис регулярных выражений.
- NFA (Nondeterministic Finite State Machine; Недетерминированные Конечные Автоматы) используют «жадный» алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (Deterministic Finite-state Automaton; Детерминированные Конечные Автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
 Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.- Билл Смит Методы и алгоритмы вычислений на строках (regexp) = Computing Patterns in Strings . — М.: «Вильямс», 2006. — С. 496. — ISBN 0-201-39839-7о книге
- Фридл Дж. Регулярные выражения. Библиотека программиста. — СПб.: Питер, 2001. 352 с. ISBN 5-318-00056-8.
- Бен Форта Освой самостоятельно регулярные выражения (regexp). PHP, Perl, JavaScript, Java, C#(си шарп), Visual Basic, ASP.NET,JSP, MySQL, Unix, Linux = Sams Teach Yourself Regular Expressions in 10 Minutes . — М.: «Вильямс», 2004. — С. 192. — ISBN 0-672-32566-7о книге
 — М.: «Вильямс», 2006. — С. 496. — ISBN 0-201-39839-7о книге
— М.: «Вильямс», 2006. — С. 496. — ISBN 0-201-39839-7о книгеeo:Regula esprimo
hu:Szabályos kifejezés
Примеры sed в Linux — синтаксис и регулярные выражения
Операционная система Linux для упрощения ее эксплуатации поддерживает множество специализированных команд. Утилита «sed» — это специфический редактор, позволяющий работать с текстом путем его замены. С помощью данной команды можно редактировать различные файлы без их открытия.
Специальный редактор дает возможность найти, вставить, заменить или удалить определенные фрагменты в файле. Чтобы команда «sed» работала значительно быстрее, потребуется предварительно прописать данные и опции.
Чтобы команда «sed» работала значительно быстрее, потребуется предварительно прописать данные и опции.
Синтаксис
Синтаксис данной утилиты не отличается сложностью. Он представлен в виде:
sed [параметры] [команды] (файл)
Первоначально необходимо изучить основные параметры, которые поддерживает команда:
- «-n» — дает возможность не выводить содержимое, присутствующее в буфере шаблона после каждой итерации.
- «-e» — позволяет выполнить команды, которые необходимы для редактирования текста.
- «-f» — дает возможность прочесть команды, которые были использованы при изменении файла.
- «-l». Опция позволяет указать требуемую длину строки.
- «-r». Опция применяется для включения поддержки синтаксиса расширенного типа, распространяющегося на активно используемые выражения.
- «-i». Функция предназначена для создания копии файла (в резерве) перед тем, как он будет отредактирован.
- «-s». Опция позволяет изучить несколько файлов единовременно. Они будут просмотрены не как длинные потоки, а как отдельные.
 Они будут просмотрены не как длинные потоки, а как отдельные.
Они будут просмотрены не как длинные потоки, а как отдельные.Чтобы выполнить несколько действий, используется аргумент «-e».
sed -e [команды] (файл)
Первоначально кажется, что данная утилита очень сложная. На самом деле это не так, ей сможет пользоваться даже новичок в сфере программирования.
Стоит отметить, что данная утилита имеет два отдельно обособленных буфера – это основной и вспомогательный буфер (активного и пассивного плана). Первоначально они абсолютно пусты. Специальная программа передает предварительно определенные условия для всех строк передаваемого файла.
Первоначально программа «sed» изучает одну строку. Из нее удаляются все завершающие данные, а также символы, присутствующие в новой строке. Обрабатываемая стока помещается в главный буфер.
Далее выполняются команды, которые были переданы пользователем в параметрах. За каждой определенной командой закрепляется адрес. Он используется в качестве своеобразного условия. Команда пройдет лишь в том случае, если данное условие будет соблюдено.
Он используется в качестве своеобразного условия. Команда пройдет лишь в том случае, если данное условие будет соблюдено.
После выполнения всех предписанных команд, содержимое буфера шаблона попадает в классический поток вывода. Это происходит в том случае, если предварительно не была указана функция «-n», которая ограничивает вывод содержимого.
Когда символ перевода изначально был удален, он добавляется обратно. Только после этого запускается следующая интерпретация, подразумевающая обработку новой строки.
Когда пользователь не планирует использование специальных команд, после завершения первой интерпретации все содержимое основного буфера будет удалено. Стоит отметить, что содержимое, которое относится к первоначально обработанной строке, сохраняется во вспомогательном буфере. Его применяют в дальнейшем при осуществлении задач.
Особенности адресов, предающихся утилите «sed»
Все команды получают свой адрес. Именно он указывает на строки, для которых выполняется команда:
- «номер». В данном случае прописывается номер определенной строки, где в последующем будет выполняться команда.
- «первая~шаг». Здесь команда выполняется для изначальной части строки, а далее – для всех остальных. В обязательном порядке указывается шаг.
- «$». Обрабатывается последняя строка, которая относится к выбранному вами файлу.
- «/часто используемое_выражение/». Здесь используется любая строка, подходящая по регулярному выражению. Оно не должно зависеть от особенностей регистра.
- «номер, номер». Обработка начинается с начала первой строки, а заканчивается концом второй строки.
- «номер,/регулярное_выражение/». Обработка начинается с первоначальной строки, заканчивается в той, которая соответствует информации в часто используемых фразах.
- «номер+количество». Обработка начинается с верхней строки, длится до той поры, пока не будет исчерпано предварительно указанное число строк.
- «номер~число». Обработка начинается со строки с определенным номеров. Она заканчивается той строкой, которая кратна определенному числовому обозначению.
 В данном случае прописывается номер определенной строки, где в последующем будет выполняться команда.
В данном случае прописывается номер определенной строки, где в последующем будет выполняться команда. Она заканчивается той строкой, которая кратна определенному числовому обозначению.
Она заканчивается той строкой, которая кратна определенному числовому обозначению.Когда пользователь не желает задавать определенный адрес для программы «sed», она распространяется на все строки в файле. Если передается один адрес, команда выполняется до той строки, которая расположена по указанному адресу.
Есть возможность передавать диапазон адресов. Информация разделяется запятыми, а команда осуществляется для тех адресов, которые находятся в требуемом диапазоне.
Регулярные выражения
У пользователя есть возможность применить такие же часто используемые выражения, как и в иных наиболее распространенных языках программирования. Стоит рассмотреть ключевой список операторов, поддерживаемых программой «sed»:
- Различные символы и их количество (*).
- Более одного символа (\+).
- Один символ или его отсутствие (\?).
- Любые символы, их количество должно быть равно i (\{i\}).
- Любые символы, их количество должно находиться в пределах от I до j (\{i, j\}).
- Любые символы, их количество должно быть больше i (\{i, \}).

Команды
Если пользователь планирует часто эксплуатировать «sed», он должен знать основной перечень команд, применяемых при редактировании. Стоит рассмотреть основные, которые применяются чаще всего:
- «q». Завершается действие сценария.
- «d». Удаляется первоначальный основной буфер шаблона, запускается следующая интерпретация цикла.
- «p». Выводится содержимое основного буфера.
- «n». Выводится состав основного буфера шаблона. Есть возможность переместить в него последующую строку.
- «s/что_прописать/на_что_поменять/опция». Заменяются символы, имеется возможность ограничить вывод с учетом часто используемых фраз.
- «y/символ/символ». Заменяются символы, присутствующие спереди строки, на те данные, которые имеются во 2 части.
- «w». Записывается содержимое основного буфера шаблона непосредственно в обрабатываемый файл.
- «N». Добавляется перевод строк в основной буфер.
- «D». Удаление основного буфера шаблона, начало интерации следующего цикла, когда в шаблоне не содержится новая строка.
- «g». Замена содержимого основного буфера на состав вспомогательного .
- «G». Добавление новых строчек в состав основного буфера. Сюда же добавляется состав вспомогательного буфера.

Стоит отметить, что утилите «sed» можно придать одновременно определенное количество команд. Для осуществления такой задачи потребуется разделить их точкой с запятой.
Примеры
Для первого примера, заменим каждое вхождение «пример» на «тест» в файле «dokument».sed 's/пример/тест/g' dokument
ВАЖНО! В операционной системе Линукс очень важен регистр имен. Как видно из скриншота «Пример» и «пример» — это разные слова.
Дополним команду таким образом, чтобы менялось не только слово «пример», но и это же слово написанное с большой буквы. Для этого будем использовать специальные символы «\|». $/d’ file
$/d’ file
Утилита «sed» является весьма гибким и максимально удобным инструментом, позволяющим сделать с текстом многие вещи. Такая команда отличается сложностью в усвоении, но дает решить множество задач.
| Функция | Java | Perl |
| Обратная косая черта заменяет один метасимвол | ДА | ДА |
| \ Q … \ E экранирует строку метасимволов | Java 6 | ДА |
| \ x00 — \ xFF (символ ASCII) | ДА | ДА |
| \ n (LF) | ДА | ДА |
| \ f (подача страницы) и \ v (vtab) | ДА | ДА |
| \ а (звонок) | ДА | ДА |
| \ e (escape) | ДА | ДА |
| \ b (пробел) и \ B (обратная косая черта) | № | № |
| \ cA до \ cZ (управляющий символ) | ДА | ДА |
| \ ca до \ cz (управляющий символ) | № | ДА |
| [abc] класс символов | ДА | ДА |
| [^ abc] класс отрицательных символов | ДА | ДА |
| [a-z] диапазон классов символов | ДА | ДА |
| Дефис в [\ d-z] является буквальным | ДА | ДА |
| Дефис в [a- \ d] является буквальным | № | № |
| Обратная косая черта экранирует метасимвол класса одного символа | ДА | ДА |
\ Q. .. \ E экранирует строку метасимволов класса символов .. \ E экранирует строку метасимволов класса символов | Java 6 | ДА |
| \ d сокращение для цифр | ascii | ДА |
| \ w сокращение для словесных символов | ascii | ДА |
| \ s сокращение для пробелов | ascii | ДА |
| \ D | ДА | ДА |
| [\ b] backspace | ДА | ДА |
| .(начало строки / строки) | ДА | ДА |
| $ (конец строки / строки) | ДА | ДА |
| \ A (начало строки) | ДА | ДА |
| \ Z (конец строки | ДА | ДА |
| \ z (конец строки) | ДА | ДА |
| \ `(начало строки) | № | № |
| \ ‘(конец строки) | № | № |
| \ b (в начале или в конце слова) | ДА | ДА |
| \ B (НЕ в начале и не в конце слова) | ДА | ДА |
| \ y (в начале или в конце слова) | № | № |
| \ Y (НЕ в начале и не в конце слова) | № | № |
| \ м (в начале слова) | № | № |
| \ M (в конце слова) | № | № |
| \ <(в начале слова) | № | № |
| \> (в конце слова) | № | № |
| | (чередование) | ДА | ДА |
| Характеристика | Java | Perl |
| ? (0 или 1) | ДА | ДА |
| * (0 или больше) | ДА | ДА |
| + (1 или более) | ДА | ДА |
| {n} (ровно n) | ДА | ДА |
| {n | ДА | ДА |
| {n | ДА | ДА |
| ? после любого из вышеперечисленных квантификаторов, чтобы сделать его «ленивым» | ДА | ДА |
| (регулярное выражение) (пронумерованная группа захвата) | ДА | ДА |
| (?: Regex) (группа без захвата) | ДА | ДА |
| \ 1 до \ 9 (обратные ссылки) | ДА | ДА |
| \ 10 до \ 99 (обратные ссылки) | ДА | ДА |
| Прямые ссылки с \ 1 по \ 9 | ДА | ДА |
| Вложенные ссылки с \ 1 по \ 9 | ДА | ДА |
| Несуществующие группы обратных ссылок являются ошибкой | ДА | ДА |
| Обратные ссылки на неудачные группы также не работают | ДА | ДА |
| (? I) (без учета регистра) | ДА | ДА |
| (? S) (точка соответствует символам новой строки) | ДА | ДА |
| (? M) (^ и $ соответствуют разрывам строки) | ДА | ДА |
| (? X) (режим свободного интервала) | ДА | ДА |
| (? N) (явный захват) | № | № |
| (? -Ismxn) (выключить модификаторы режима) | ДА | ДА |
| (? Ismxn: group) (модификаторы режима, локальные для группы) | ДА | ДА |
| Характеристика | Java | Perl |
| (?> Регулярное выражение) (атомная группа) | ДА | ДА |
| ? + | n} + (притяжательные кванторы) | ДА |
| (? = Регулярное выражение) (положительный просмотр вперед) | ДА | ДА |
| (?! Regex) (отрицательный просмотр вперед) | ДА | ДА |
| (? <= Текст) (положительный просмотр назад) | конечной длины | фиксированной длины |
| (? | конечной длины | фиксированной длины |
| \ G (попытка начала матча) | ДА | ДА |
| (? (? = Regex) then | else) (с использованием любого поиска) | № | ДА |
| (? (Регулярное выражение) затем | иначе) | № | № |
| (? (1) затем | иначе) | № | ДА |
| (? (Группа) затем | иначе) | № | № |
| (? # Комментарий) | № | ДА |
| Поддерживается синтаксис свободного пробела | ДА | ДА |
| Класс символов — одиночный маркер | № | ДА |
| # начинает комментарий | ДА | ДА |
| \ X (графема Unicode) | № | ДА |
| \ u0000 до \ uFFFF (символ Unicode) | ДА | № |
| \ x {0} — \ x {FFFF} (символ Unicode) | № | ДА |
| \ pL через \ pC (свойства Unicode) | ДА | ДА |
| \ p {L} — \ p {C} (свойства Unicode) | ДА | ДА |
| \ p {Lu} — \ p {Cn} (свойство Unicode) | ДА | ДА |
| \ p {L &} и \ p {Letter &} (эквивалент свойств Юникода [\ p {Lu} \ p {Ll} \ p {Lt}]) | № | ДА |
| \ p {IsL} через \ p {IsC} (свойства Unicode) | ДА | ДА |
| \ p {IsLu} через \ p {IsCn} (свойство Unicode) | ДА | ДА |
| \ p {Letter} — \ p {Other} (свойства Unicode) | № | ДА |
| \ p {нижний регистр} до \ p {Not_Assigned} (свойство Unicode) | № | ДА |
| \ p {IsLetter} через \ p {IsOther} (свойства Unicode) | № | ДА |
| \ p {IsLowercase_Letter} через \ p {IsNot_Assigned} (свойство Unicode) | № | ДА |
| \ p {арабский} через \ p {Yi} (сценарий Unicode) | № | ДА |
| \ p {IsArabic} через \ p {IsYi} (сценарий Unicode) | № | ДА |
| \ p {BasicLatin} до \ p {Specials} (блок Unicode) | № | ДА |
| \ p {InBasicLatin} через \ p {InSpecials} (блок Unicode) | ДА | ДА |
| \ p {IsBasicLatin} через \ p {IsSpecials} (блок Unicode) | № | ДА |
| Часть между {} во всем вышеперечисленном не чувствительна к регистру | № | ДА |
| \ P (отрицательные варианты всех \ p, как указано выше) | ДА | ДА |
\ p {^. ..} (инвертированные варианты всех \ p {…}, как указано выше) ..} (инвертированные варианты всех \ p {…}, как указано выше) | № | ДА |
| (? | № | № |
| (? ‘Name’regex) (именованная группа захвата в стиле .NET) | № | № |
| \ k <имя> (именованная обратная ссылка в стиле .NET) | № | № |
| \ k’name ‘(.Именованная обратная ссылка в стиле .NET) | № | № |
| (? P | № | № |
| (? P = name) (именованная обратная ссылка в стиле Python) | № | № |
| несколько групп захвата могут иметь одно и то же имя | н / д | н / д |
| \ i | № | № |
| [abc- [abc]] вычитание класса символов | № | № |
| [: alpha:] Символьный класс POSIX | № | ДА |
| \ p {Alpha} Символьный класс POSIX | ascii | № |
| \ p {IsAlpha} Символьный класс POSIX | № | ДА |
[.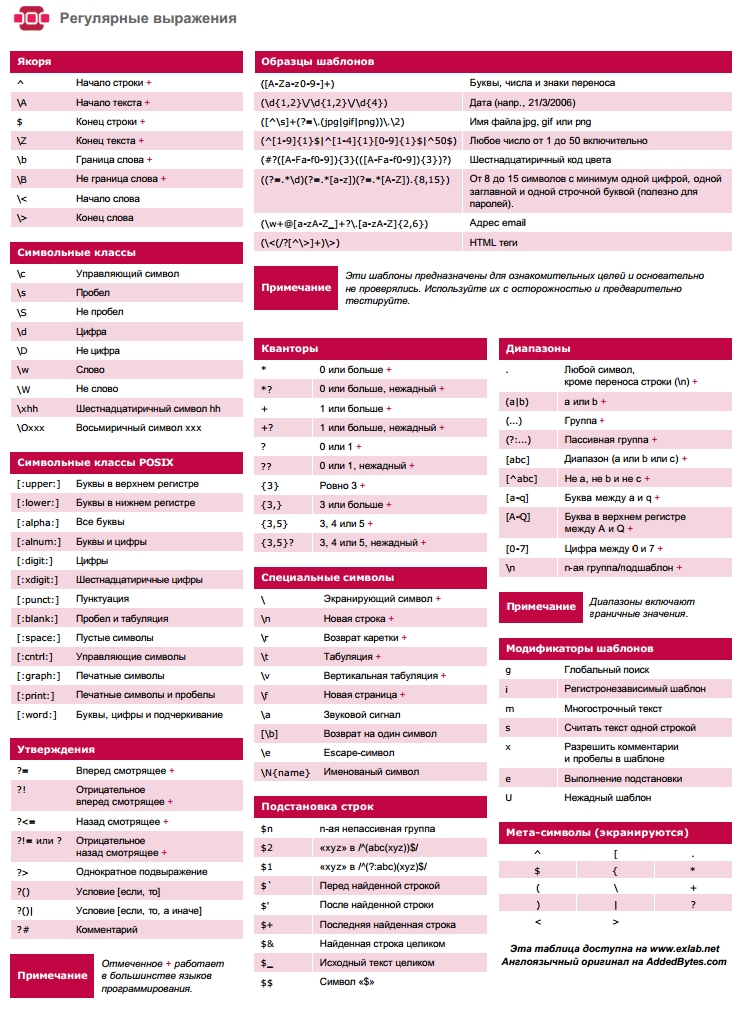 span-ll.] Последовательность сортировки POSIX span-ll.] Последовательность сортировки POSIX | № | № |
| [= x =] Эквивалент символов POSIX | № | № |
Справочник по регулярным выражениям
Справочник по регулярным выражениям на этом веб-сайте работает как ссылка на весь доступный синтаксис регулярных выражений, так и как сравнение функций, поддерживаемых разновидностями регулярных выражений, обсуждаемыми в руководстве. Справочные таблицы содержат невероятное количество информации.Чтобы извлечь из них максимальную пользу, следуйте этой легенде, чтобы научиться их читать.
В таблицах есть шесть столбцов для каждой функции регулярного выражения. Первые четыре объясняют эту функцию.
| Feature | Имя функции, которая также служит ссылкой на соответствующий раздел в руководстве. |
|---|---|
| Синтаксис | Фактический синтаксис регулярного выражения для этой функции. Если синтаксис исправлен, он просто отображается как таковой. Если синтаксис имеет переменные элементы, синтаксис описывается. Если синтаксис имеет переменные элементы, синтаксис описывается. |
| Описание | Краткое описание того, что делает функция. |
| Пример | Функциональное регулярное выражение, демонстрирующее функцию. |
Последние два столбца показывают, поддерживают ли выбранные вами два варианта регулярного выражения именно эту функцию. Вы можете изменить вкусы, используя раскрывающиеся списки над таблицей. Есть много возможных индикаторов.
| ДА | Все версии этого варианта поддерживают эту функцию. |
| 3.0 | Версия 3.0 и все более поздние версии этого варианта поддерживают эту функцию. Более ранние версии не поддерживают это. |
| только 2.0 | Только версия 2.0 поддерживает эту функцию. Более ранние и более поздние версии не поддерживают его. |
| 2.0–2.9 | Только версии от 2.0 до 2.9 поддерживают эту функцию. Более ранние и более поздние версии не поддерживают его.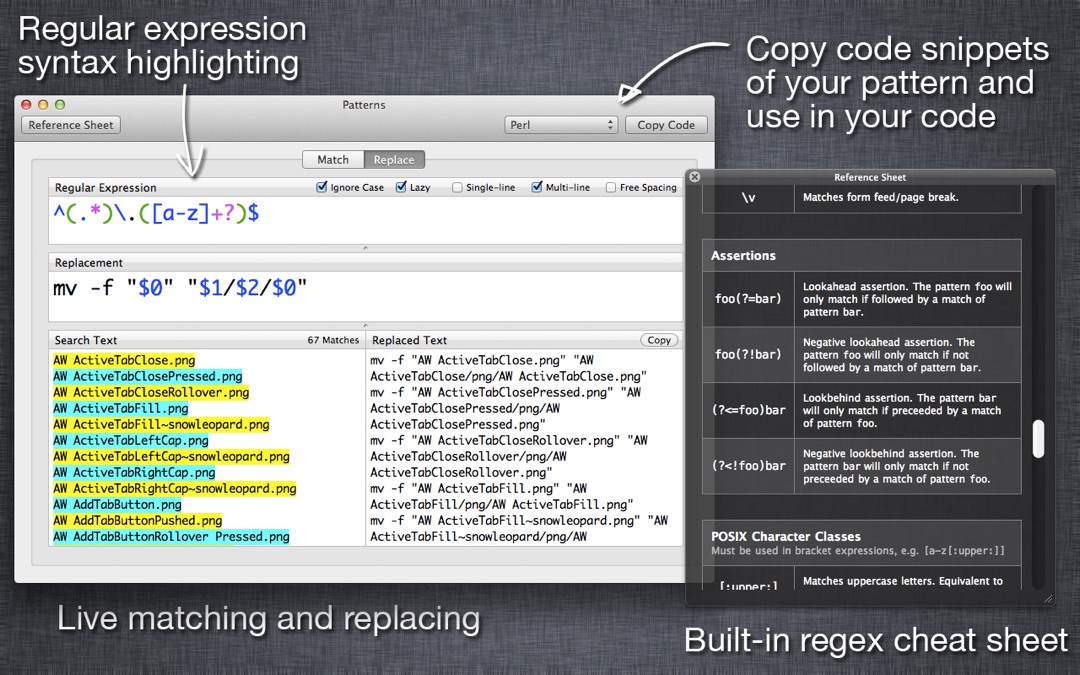 |
| Unicode | Эта функция работает с символами Unicode во всех версиях этого варианта. |
| кодовая страница | Эта функция работает с символами на активной кодовой странице во всех версиях этого варианта. |
| ASCII | Эта функция работает с символами ASCII только во всех версиях этого варианта. |
| 3.0 Unicode | Эта функция работает с символами Unicode в версиях 3.0 и выше этого варианта. Более ранние версии его вообще не поддерживают. |
| 3.0 Unicode 2.0 ASCII | Эта функция работает с символами Unicode в версиях 3.0 и позже этот аромат. Он работает с символами ASCII в версиях от 2.0 до 2.9. Более ранние версии его вообще не поддерживают. |
| 3.0 Кодовая страница Unicode 2.0 | Эта функция работает с символами Unicode в версиях 3.0 и более поздних версиях. Он работает с символами активной кодовой страницы в версиях от 2. 0 до 2.9. Более ранние версии его вообще не поддерживают. 0 до 2.9. Более ранние версии его вообще не поддерживают. |
| строка | Тип регулярного выражения не поддерживает этот синтаксис. Но строковые литералы на языке программирования, с которыми обычно используется этот вариант регулярного выражения, действительно поддерживают этот синтаксис. |
| 3.0 1.0 строка | Версия 3.0 и более поздние версии этого варианта регулярного выражения поддерживают этот синтаксис. Более ранние версии разновидности регулярных выражений не поддерживают этот синтаксис. Но строковые литералы в языке программирования, с которым обычно используется этот вид регулярных выражений, поддерживают этот синтаксис, начиная с версии 1.0. |
| option | Все версии этого варианта регулярного выражения поддерживают эту функцию, если вы устанавливаете конкретную опцию или предшествуете ей модификатором определенного режима. |
| option 3.0 | Версия 3.0 и все более поздние версии этого варианта регулярного выражения поддерживают эту функцию, если вы устанавливаете конкретную опцию или предшествуете ей модификатором определенного режима. Более ранние версии либо вообще не поддерживают синтаксис, либо не поддерживают модификатор режима для изменения поведения синтаксиса на то, что описывает функция. Более ранние версии либо вообще не поддерживают синтаксис, либо не поддерживают модификатор режима для изменения поведения синтаксиса на то, что описывает функция. |
| 3.0 2.0 сбой | Версия 3.0 и все более поздние версии этого варианта регулярного выражения поддерживают эту функцию.Версия 2.0 все более поздние выпуски до 3.0 распознают синтаксис, но всегда не соответствуют этому токену регулярного выражения. Версии до 2.0 не поддерживают синтаксис. |
| нет | Ни одна из версий этого варианта не поддерживает эту функцию. Нет никаких указаний на то, что на самом деле делает этот синтаксис. Тот же синтаксис может использоваться для другой функции, указанной в другом месте справочной таблицы. Или синтаксис может вызвать ошибку, или он может быть интерпретирован как простой текст. |
| н / д | Эта функция не применима к этому варианту регулярных выражений.Функции, описывающие поведение определенного синтаксиса, представленного ранее в справочной таблице, не имеют значения для разновидностей, которые вообще не поддерживают этот синтаксис. |
| сбой | Синтаксис распознается вкусом, и регулярные выражения, использующие его, работают, но этот конкретный токен регулярного выражения всегда не соответствует. Регулярное выражение может находить совпадения только в том случае, если этот токен сделан необязательным путем чередования или квантификатора. |
| 2.0–2.9 сбой | Версии от 2.0 до 2.9 распознают синтаксис, но всегда не соответствуют этому токену регулярного выражения. Более ранние и более поздние версии либо не распознают синтаксис, либо рассматривают его как синтаксическую ошибку. |
| игнорируется | Синтаксис распознается разновидностью, но не делает ничего полезного. Этот конкретный токен регулярного выражения всегда находит совпадение нулевой длины. |
| ошибка | Синтаксис распознается разновидностью, но обрабатывается как синтаксическая ошибка. |
Когда в этой легенде написано «все версии» или «без версии», это означает все или ни одну из версий каждой разновидности, которые охвачены справочными таблицами:
Для. NET, некоторые функции обозначены как «ECMA» или «non-ECMA». Это означает, что функция поддерживается, только когда RegexOptions.ECMAScript установлен или не установлен. Функции, указанные с помощью «Unicode, отличного от ECMA», соответствуют символам ASCII, если установлен RegexOptions.ECMAScript, и символам Unicode, если RegexOptions.ECMAScript не установлен. Все, что применимо к .NET 2.0 или более поздней версии, также применимо к любой версии .NET Core. В среде IDE Visual Studio используется вариант .NET, отличный от ECMA, начиная с VS 2012.
NET, некоторые функции обозначены как «ECMA» или «non-ECMA». Это означает, что функция поддерживается, только когда RegexOptions.ECMAScript установлен или не установлен. Функции, указанные с помощью «Unicode, отличного от ECMA», соответствуют символам ASCII, если установлен RegexOptions.ECMAScript, и символам Unicode, если RegexOptions.ECMAScript не установлен. Все, что применимо к .NET 2.0 или более поздней версии, также применимо к любой версии .NET Core. В среде IDE Visual Studio используется вариант .NET, отличный от ECMA, начиная с VS 2012.
Для вариантов std :: regex и boost :: regex есть дополнительные индикаторы ECMA, базовый, расширенный, grep, egrep и awk.Когда появляется один или несколько из них, это означает, что функция поддерживается только в том случае, если вы укажете одну из этих грамматик при компиляции регулярного выражения. Функции с индикаторами Unicode соответствуют символам Unicode при использовании std :: wregex или boost :: wregex в строках широких символов. В ссылке на заменяющую строку дополнительными индикаторами являются sed и default. Когда появляется один из них, функция поддерживается только в том случае, если вы передаете или не передаете match_flag_type :: format_sed в regex_replace ().Для ускорения есть еще один индикатор замены «все», который указывает, что функция поддерживается только тогда, когда вы передаете match_flag_type :: format_all в regex_replace ().
В ссылке на заменяющую строку дополнительными индикаторами являются sed и default. Когда появляется один из них, функция поддерживается только в том случае, если вы передаете или не передаете match_flag_type :: format_sed в regex_replace ().Для ускорения есть еще один индикатор замены «все», который указывает, что функция поддерживается только тогда, когда вы передаете match_flag_type :: format_all в regex_replace ().
Для варианта PCRE2 некоторые функции замещающей строки обозначены как «расширенный». Это означает, что функция поддерживается только при передаче PCRE2_SUBSTITUTE_EXTENDED в pcre2_substitute.
Сделайте пожертвование
Этот веб-сайт только что сэкономил вам поездку в книжный магазин? Сделайте пожертвование на поддержку этого сайта, и вы получите пожизненного доступа без рекламы к этому сайту!
\ | Помечает следующий символ как специальный символ или литерал. | Соответствует началу ввода. |
$ | Соответствует концу ввода. | |
* | Соответствует предыдущему символу ноль или более раз. Например, «zo *» соответствует либо z , либо zoo . | |
+ | Соответствует предыдущему символу один или несколько раз. Например, «zo +» соответствует zoo , но не z . | |
? | Соответствует предыдущему символу ноль или один раз. Например, a? Ve? соответствует ve в никогда не . | |
. | Соответствует любому одиночному символу, кроме символа новой строки. | |
( подвыражение ) | Соответствует подвыражению и запоминает совпадение.Если часть регулярного выражения заключена в круглые скобки, эта часть регулярного выражения сгруппирована вместе.
| |
x | y | Соответствует x или y . Например, z | wood соответствует z или wood . (z | w) oo соответствует zoo или wood . | |
{ n } | n — неотрицательное целое число. Совпадает ровно n раз. Например, Совпадает ровно n раз. Например, o {2} не соответствует o в Bob , но соответствует первым двум o в foooood . | |
{ n ,} | n — неотрицательное целое число. Соответствует как минимум n раз. Например, | |
{ n , m } | m и n — неотрицательные целые числа.Совпадает минимум n и максимум m раз. Например, o {1,3} соответствует первым трем o в «fooooood». o {0,1} эквивалентно o? . | |
[ xyz ] | Набор символов. Соответствует любому из заключенных символов.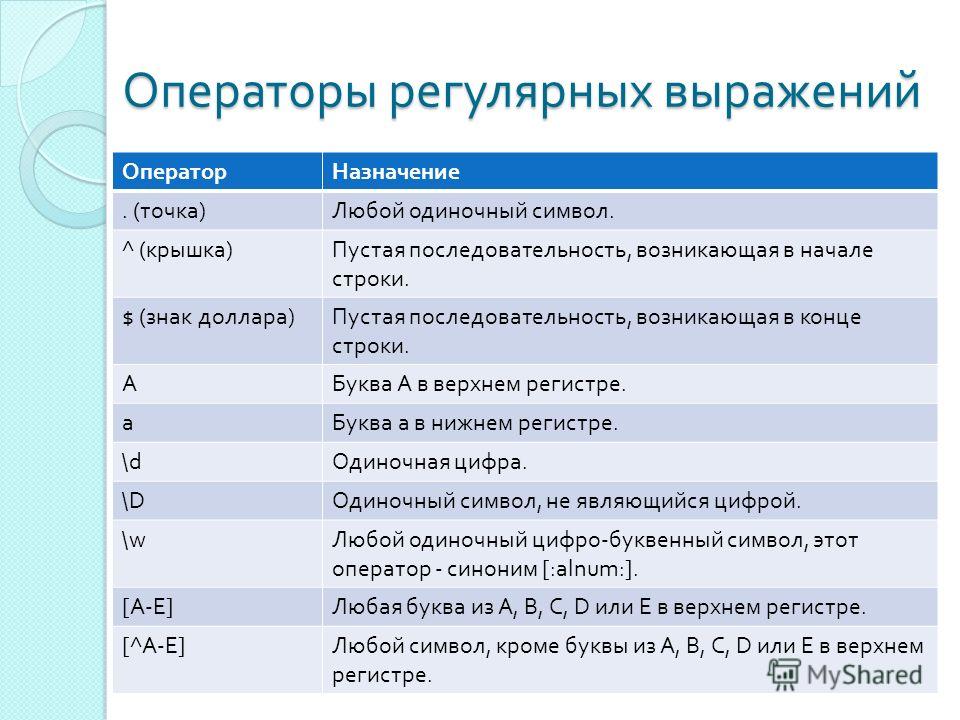 Например, Например, [abc] соответствует a в обычном .m-z] соответствует любому символу вне диапазона от m до z . | |
\ b | Соответствует границе слова, то есть позиции между словом и пробелом. Например, er \ b соответствует er в , никогда , но не er в глаголе . | |
\ B | Соответствует границе, отличной от слова.0-9] . | |
\ f | Соответствует символу подачи страницы. | |
\ n | Соответствует символу новой строки. | |
\ r | Соответствует символу возврата каретки. | |
\ s | Соответствует любому пустому пространству, включая пробел, табуляцию, подачу страницы и т. Д. Эквивалент [\ f \ n \ r \ t \ v] . | |
\ S | Соответствует любому символу, отличному от пробела. \ f \ n \ r \ t \ v] . \ f \ n \ r \ t \ v] . | |
\ t | Соответствует символу табуляции. | |
\ v | Соответствует символу вертикальной табуляции. | |
\ w | Соответствует любому символу слова, включая подчеркивание. Эквивалент [A-Za-z0 -9_] . Используйте его в поле поиска . | |
\ W | Соответствует любому символу, не являющемуся словом.А-За-z0-9_] . | |
\ num | Соответствует num , где num — положительное целое число, обозначающее обратную ссылку на запомненные совпадения. Например, | |
\ n | Соответствует n , где n — восьмеричное escape-значение. Восьмеричные escape-значения должны состоять из 1, 2 или 3 цифр. Например, Восьмеричные escape-значения не должны превышать 256. Если это так, только первые две цифры составляют выражение. Позволяет использовать коды ASCII в регулярных выражениях. | |
\ x n | Соответствует n , где n — шестнадцатеричное escape-значение. Шестнадцатеричные escape-значения должны состоять ровно из двух цифр. Например, Позволяет использовать коды ASCII в регулярных выражениях. | |
\ $ | Находит символ $ . | |
\\ $ | Это регулярное выражение, введенное в поле поиска , означает, что вы пытаетесь найти символ \ в конце строки. | |
\ l | Меняет регистр следующего символа на нижний. Используйте этот тип регулярного выражения в поле replace . | |
\ u | Изменяет регистр следующего символа на верхний регистр.Используйте этот тип регулярного выражения в поле replace . | |
\ L | Изменяет регистр всех последующих символов до \ E на нижний регистр. Используйте этот тип регулярного выражения в поле replace . | |
\ U | Изменяет регистр всех последующих символов до \ E на верхний регистр. Используйте этот тип регулярного выражения в поле replace . | |
(?!) | Это шаблон для «отрицательного просмотра вперед».Например, A (?! B) означает, что CLion будет искать A , но только если за ним не будет B . | |
(? =) | Это шаблон для «положительного просмотра вперед». Например, Например, A (? = B) означает, что CLion будет искать A , но совпадать, если только за ним следует B . | |
(? <=) | Это шаблон для «положительного просмотра назад».Например, (? <= B) A означает, что CLion будет искать A , но только если перед ним стоит B . | |
(? | Это шаблон для «отрицательного просмотра назад». Например, (? означает, что CLion будет искать |

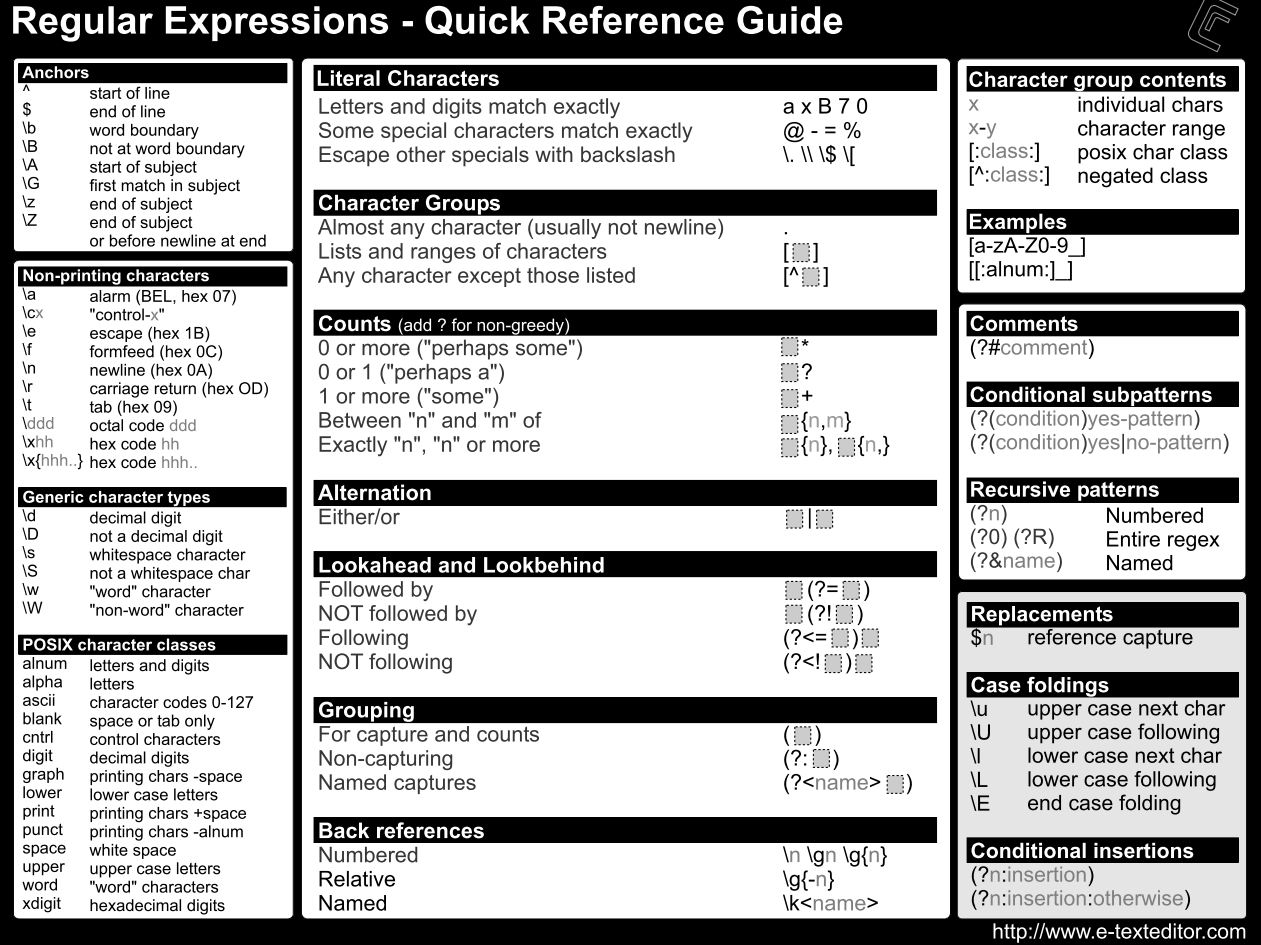 Таким образом, оператор регулярного выражения может применяться ко всей группе.
Таким образом, оператор регулярного выражения может применяться ко всей группе.Синтаксис регулярного выражения[Все права защищены: http: // www.regexlab.com/en/regref.htm] Введение Регулярное выражение предназначено для выражения характеристики в строке, а затем для сопоставления другой строки с этой характеристикой. Регулярное выражение используется для: (1) проверки строки на соответствие шаблону, например, адресу электронной почты. (2) найти подстроку, соответствующую определенному шаблону, из всего текста.(3) делать сложные замены в тексте. Изучить синтаксис регулярных выражений очень просто, и несколько абстрактных концепций тоже можно легко понять. Многие статьи не вводят его концепции от простых к абстрактным шаг за шагом, поэтому некоторым людям это может показаться трудным. В каждом примере в этой статье есть ссылка на тестовую страницу.А теперь приступим! 1. Базовый синтаксис регулярного выражения 1. Буквы, цифры, подчеркивание и знаки препинания без специального определения являются «общими символами». Когда регулярное выражение соответствует строке, общий символ может соответствовать одному и тому же символу. Пример 1: Когда шаблон «c» соответствует строке «abcde», результат сопоставления: успех; совпадение подстроки: "c"; позиция: начинается с 2, заканчивается на 3. Пример 2: Когда шаблон «bcd» соответствует строке «abcde» , результат сопоставления: успех; совпадение подстроки: "bcd"; позиция: начинается с 1, заканчивается на 4. 1,2 Простые экранированные символы известных нам непечатаемых символов:
Некоторые знаки препинания специально определены в регулярных выражениях. | |
\ $ | Соответствует самому "$" |
\. | Соответствует самой точке (.) |
 Например, шаблон «ab +» означает «один 'a' и хотя бы один 'b», поэтому «ab», «abb», «abbbbbbb» соответствуют образцу.
Например, шаблон «ab +» означает «один 'a' и хотя бы один 'b», поэтому «ab», «abb», «abbbbbbb» соответствуют образцу. 1 Общие символы
1 Общие символы  "сам
"самЭти экранированные символы имеют тот же эффект, что и «обычные символы»: соответствуют определенному символу.
Пример 1: Когда шаблон «\ $ d» соответствует строке «abc $ de», результат сопоставления: успех; совпадение подстроки: "$ d"; позиция: начинается с 3, заканчивается на 5.
1.3 Выражение соответствует любому из многих символов
Некоторым выражениям может соответствовать любой из многих символов. Например: «\ d» может соответствовать любому цифровому символу. Каждое из этих выражений может одновременно соответствовать только одному символу, хотя они могут соответствовать любому символу определенной группы символов.
Выражение | совпадений |
\ d | Любая цифра, любая из 0 ~ 9 |
\ w | Любые буквы, цифры, подчеркивание, любое из A ~ Z, a ~ z, 0 ~ 9, _ |
\ с | Любой один из символов пробела, табуляции, новой строки, возврата или новой страницы |
. | '.' соответствует любому символу, кроме символа новой строки (\ n) |

Пример 1: Когда шаблон «\ d \ d» соответствует «abc123», результат сопоставления: успех; совпадение подстроки: "12"; позиция: начинается с 3, заканчивается на 5.
Пример 2: Когда шаблон «a. \ d» соответствует «aaa100», результат сопоставления: успех; совпадение подстроки: "aa1"; позиция: начинается с 1, заканчивается на 4.
1.4 Пользовательское выражение соответствует любому из множества символов
В выражении
квадратные скобки [] используются для обозначения ряда символов, оно может соответствовать любому из них.abc] "соответствует" abc123 ", результат соответствия: успех; подстрока сопоставлена:" 1 "; позиция: начинается с 3, заканчивается на 4.
1,5 Специальное выражение для количественной оценки соответствия
Все введенные ранее выражения могут соответствовать символу только один раз. Если за выражением следует квантификатор, оно может совпадать более одного раза.
Если за выражением следует квантификатор, оно может совпадать более одного раза.
Например: мы можем использовать шаблон «[bcd] {2}» вместо «[bcd] [bcd]».
Выражение | Функция | |
{n} | Совпадение ровно n раз, например: «\ w {2}» равно «\ w \ w»; «а {5}» равно «ааааа» | |
{m, n} | Не менее m, но не более n раз: | |
{м,} | Совпадение не менее n раз: | |
? | Совпадение 1 или 0 раз, что эквивалентно {0,1}: | Соответствует началу строки |
$ | Соответствует концу строки | |
\ b | Соответствует границе слова |

Дополнительные примеры, которые помогут вам понять."должен соответствовать началу строки. Он может быть успешным при условии, что" aaa "находится в
начало строки, например «aaa xxx xxx».
Пример 2: Когда шаблон «aaa $» соответствует «xxx aaa xxx», результат сопоставления: не удалось. Bacause «$» должен соответствовать концу строки. Он может успешно соответствовать при условии, что "ааа" находится в конце
строка, например «xxx xxx aaa».
Пример 3: Когда шаблон ". \ B." соответствует "@@@ abc", результат совпадения: успех; подстрока найдена: "@a"; позиция: начинается с 2, заканчивается на 4."и" $ "не соответствует ни одному символу, но для него требуется символ '\ w' на одной стороне, а другой - не символ '\ w' на другой стороне.
Пример 4: Когда соответствует шаблон" \ bend \ b " "выходные, конец, конец", результат совпадения: успех; подстрока сопоставлена: "конец"; позиция: начинается с 15, заканчивается в 18.
Некоторые особые знаки препинания могут повлиять на другие подшаблоны:
Выражение | Функция |
| | Чередование, соответствует либо левой, либо правой стороне |
() | (1).При количественной оценке позвольте подшаблонам в нем составлять целую часть. |
Пример 5: Когда шаблон «Том | Джек» соответствует строке «Я Том, он Джек», результат сопоставления: успех; подстрока найдена: "Tom"; позиция: начинается с 4, заканчивается на 7. Когда матч следующий,
Когда матч следующий,
результат матча: успех; совпадение подстроки: "Джек"; позиция: начинается с 15, заканчивается в 19.
Пример 6: Когда шаблон «(go \ s *) +» совпадает с «Поехали, вперед!», результат совпадения: успех; подстрока совпала: "вперед, вперед, вперед"; позиция: начинается с 6, заканчивается в 14.
Пример7: Когда шаблон «¥ (\ d + \.? \ D *)» соответствует «$ 10,9, ¥ 20,5», результат сопоставления: успех; подстрока найдена: "¥ 20,5"; позиция: начинается в 6, заканчивается в 10. Матч
Результат подшаблонов в "()": "20,5".
2. Расширенный синтаксис регулярных выражений
2.1 Неохотные или жадные кванторы
Существуют сервальные методы для количественной оценки подшаблонов, например: «{m, n}», «{m,}», «?», «*», «+».По умолчанию квантифицированный подшаблон является «жадным», то есть он будет соответствовать столько раз, сколько возможно (с учетом конкретного начального местоположения), при этом разрешая
остальная часть шаблона, чтобы соответствовать. Например, для соответствия «dxxxdxxxd»:
Например, для соответствия «dxxxdxxxd»:
Выражение | Результат матча |
(г) (\ ш +) | «\ w +» соответствует всем символам «xxxdxxxd» после «d» |
(г) (\ w +) (г) | «\ w +» соответствует всем символам «xxxdxxx» между первым «d» и последним «d».Чтобы обеспечить успешное совпадение всего шаблона, "\ w" должен отказаться от последнего "d", хотя он может соответствовать и последнему "d". |
Таким образом, можно увидеть, что: когда "\ w +" совпадает, он будет соответствовать как можно большему количеству символов. Во втором примере он не соответствует последнему «d», но это необходимо для того, чтобы весь шаблон совпадал успешно. Шаблон с "*" или "{m, n}" будет
также совпадать как можно больше раз, шаблон с "?" будет соответствовать, если возможно. Этот тип сопоставления называется «жадным сопоставлением». 9
Этот тип сопоставления называется «жадным сопоставлением». 9
Сопоставление с противодействием:
Чтобы после квантификатора ставился знак «?», Он может позволить шаблону соответствовать минимально возможное количество раз. Этот тип сопоставления называется сопоставлением с неохотой. Чтобы обеспечить успешное совпадение всего шаблона, неохотный шаблон может соответствовать
еще несколько раз, если потребуется. Например, для соответствия «dxxxdxxxd»:
Выражение | Результат матча |
(г) (\ ш +?) | "\ w +?" совпадать как можно меньше раз, поэтому "\ w +?" соответствует только одному "x" |
(г) (\ w +?) (Г) | Чтобы разрешить совпадение всего шаблона, "\ w +?" должно соответствовать "xxx". |
 Итак, результат совпадения: "\ w +?" соответствует "xxx"
Итак, результат совпадения: "\ w +?" соответствует "xxx"Дополнительные примеры:
Пример 1: Когда шаблон «
» соответствует «
aa
bb < / p>
", результат совпадения:
успех; подстрока соответствует: весь "
aa
bb
", "
" в шаблоне соответствует последнему «
» в строке.
Example2: Для сравнения, когда шаблон «
» соответствует строке в example1, он соответствует
"
aa
". При следующем совпадении может быть сопоставлен следующий "
bb
".
2.2 Обращение к совпавшей подстроке \ 1, \ 2 ...
В процессе сопоставления результаты сопоставления подшаблона в круглых скобках «()» записываются для дальнейшего использования.При получении результатов совпадения эти результаты соответствия подшаблона могут быть получены индивидуально, и это было продемонстрировано
много раз в предыдущих примерах.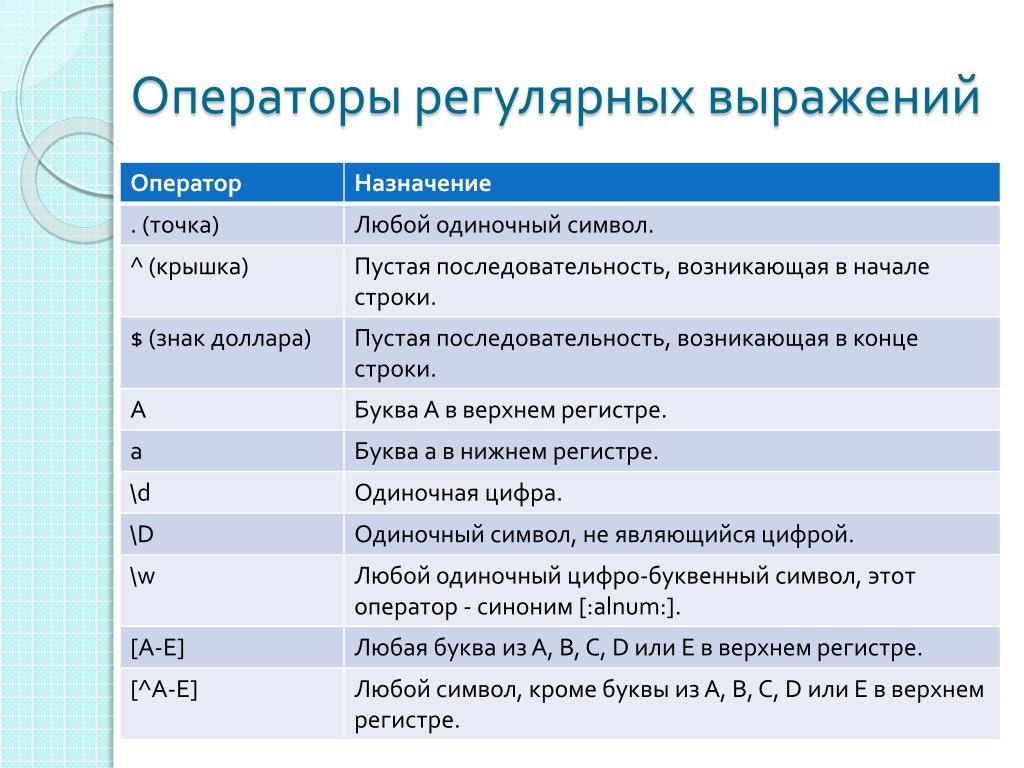 На практике круглые скобки «()» должны использоваться, чтобы получить то, что мы действительно хотим после совпадения, например «
На практике круглые скобки «()» должны использоваться, чтобы получить то, что мы действительно хотим после совпадения, например «
».
Фактически, результат совпадения подшаблона в круглых скобках может использоваться не только после сопоставления, но и во время сопоставления. Последняя часть подшаблона может ссылаться на результат совпадения с предыдущим подшаблоном.Использование: "\" плюс число для обозначения
соответствующая подстрока. «\ 1» относится к результату сопоставления 1-й пары круглых скобок, «\ 2» относится к результату сопоставления 2-й пары скобок.
Примеры:
Пример1: Когда шаблон "('|") (. *?) (\ 1) "соответствует"' Hello ', "World" ", результат соответствия: успех; совпадение подстроки:"' Hello '"; при совпадении next подстрока сопоставлено: "" World "".
Пример 2: когда шаблон "(\ w) \ 1 {4,}" соответствует "aa bbbb abcdefg ccccc 111121111 999999999", результат сопоставления: успех; совпадение подстроки:
"ccccc"; при следующем совпадении подстрока соответствует «999999999». " , "$" , "\ b".Все они не соответствуют никаким символам, но все они требуют определенных условий для их положения. Теперь в этой главе будут представлены дополнительные методы добавления
" , "$" , "\ b".Все они не соответствуют никаким символам, но все они требуют определенных условий для их положения. Теперь в этой главе будут представлены дополнительные методы добавления
условия на разрыв между персонажами.
Утверждение
Lookahead: "(? = Xxxxx)", "(?! Xxxxx)"
Формат
: "(? = Xxxxx)", условие, которое оно добавляет в пробел, следующее: строка с правой стороны пробела должно быть abe, чтобы соответствовать подшаблону «xxxxx» в круглых скобках. Это просто условие, а не операция сопоставления, поэтому результата сопоставления нет.
Пример 1: Когда шаблон «Windows (? = NT | XP)» соответствует «Windows 98, Windows NT, Windows 2000», он может соответствовать только «Windows» в «Windows NT»,
другие "винды" сопоставить не удалось.
Пример 2: Когда шаблон "(\ w) ((? = \ 1 \ 1 \ 1) (\ 1)) +" соответствует "aaa ffffff 999999999", он может соответствовать первым 4 "f" из 6 "f "s, это может соответствовать
первые 7 "9" из 9 "9".
Формат: «(?! Xxxxx)», строка с правой стороны пробела не должна соответствовать подшаблону «xxxxx».
Пример 3: Когда шаблон «((?! \ Bstop \ b).) +» Соответствует «fdjka ljfdl stop fjdsla fdj», он будет соответствовать от начала строки до позиции «stop». Если в строке нет «стопа», шаблон будет соответствовать всей строке.
Пример 4: Когда шаблон «do (?! \ W)» соответствует «done, do, dog», он может соответствовать только «do». Здесь «(?! \ W)» имеет тот же эффект, что и «\ b».
Утверждение просмотра назад: "(? <= Xxxxx)", "(?
Концепции «утверждения просмотра назад» и «утверждения просмотра вперед» аналогичны.«(? <= xxxxx)» и «(?
Пример 5: Когда шаблон "(? <= \ D {4}) \ d + (? = \ D {4})" соответствует "12345678
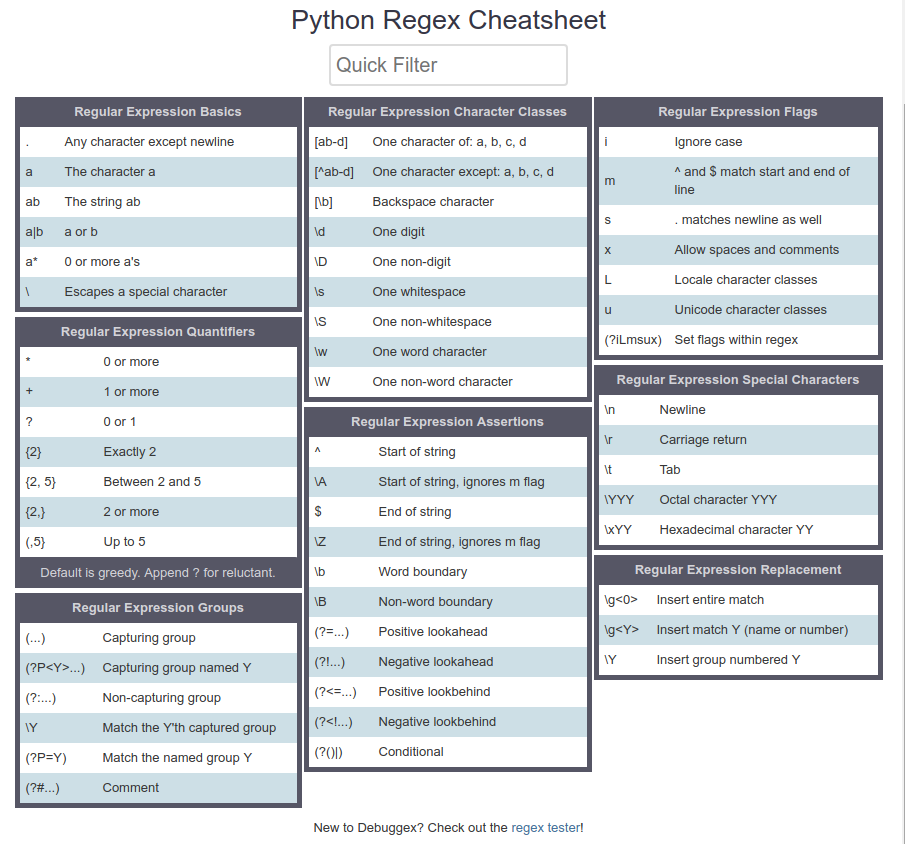 Поскольку утверждение просмотра назад не поддерживается JScript.RegExp, этот пример не может быть
Поскольку утверждение просмотра назад не поддерживается JScript.RegExp, этот пример не может бытьпродемонстрировал.Есть много механизмов, поддерживающих утверждение lookbehind, например пакет java.util.regex в Java 1.4 или новее, пространство имен System.Text.RegularExpressions на платформе .NET, механизм DEELX Regexp и т. Д.
3. Другие обычно поддерживаемые правила
Есть несколько обычно поддерживаемых правил, о которых не упоминалось.
3.1 В шаблоне символ может быть выражен как «\ xXX» или «\ uXXXX» («X» - шестнадцатеричное число)
Формат | Диапазон символов |
\ xXX | 0 ~ 255, например, пробел может быть "\ x20" |
\ uXXXX | Любой символ может быть выражен как "\ u" плюс 4 шестнадцатеричных числа, например "\ u4E2D" |
3. "сам
"сам
$
Соответствует концу строки. Используйте "\ $" для соответствия самому "$"
()
Группировка. Используйте "\ (" и "\)" для соответствия "(" и ")"
[]
Класс символов. Используйте «\ [» и «\]» для соответствия «[» и «]»
{}
Определите кванторы.Используйте "\ {" и "\}" для соответствия "{" и "}"
.
Соответствует любому символу, кроме новой строки (\ n). Используйте "\." чтобы соответствовать "." сам
?
Пусть подшаблон соответствует 0 или 1 раз. Используйте "\?" чтобы соответствовать "?" сам
+
Пусть подшаблон соответствует как минимум 1 раз. Используйте "\ +" для соответствия самому "+"
Используйте "\ +" для соответствия самому "+"
*
Разрешить совпадение подмаски в любое время. Используйте "\ *" для соответствия самому "*"
|
Чередование. Используйте "\ |" соответствовать "|" сам
для ссылки на результат совпадения "(\ w)".
Атрибут
Описание
Игнорировать регистр
Сопоставление с образцом без учета регистра. По умолчанию учитывается регистр."и" $ "соответствуют только самому началу very строки и концу④ строки. Если они многострочные, они соответствуют началу③ любой строки и концу② любой строки в строке:
По умолчанию учитывается регистр."и" $ "соответствуют только самому началу very строки и концу④ строки. Если они многострочные, они соответствуют началу③ любой строки и концу② любой строки в строке:
①xxxxxxxxx② \ n
③xxxxxxxxx④
Весь мир
Заменить все совпадения, если шаблон используется в операции замены.
 4 Не позволять шаблону соответствовать пустой строке "". Или вы получите сопоставленную пустую подстроку, в то время как операция сопоставления возвращает успех. Например: если нам нужен шаблон для соответствия "123" 、 "123."、" 123,5 "、". 5 ", мы не должны использовать этот шаблон" \ d * \.? \ D * ". Хотя есть
4 Не позволять шаблону соответствовать пустой строке "". Или вы получите сопоставленную пустую подстроку, в то время как операция сопоставления возвращает успех. Например: если нам нужен шаблон для соответствия "123" 、 "123."、" 123,5 "、". 5 ", мы не должны использовать этот шаблон" \ d * \.? \ D * ". Хотя естьничего, мы все еще можем добиться успеха.
Правильный шаблон: "\ d + \.? \ D * | \. \ D +".
 шаблон поиска
шаблон поискапозволяет найти все строки, начинающиеся с символа.
соответствует abbd или abbbd, но не соответствует abcd или abbcd.
 Токен + эквивалентен {1,}.
Токен + эквивалентен {1,}.но не abccd. ? токен эквивалентен {0,1}.
найди ногу, но не ногу или ногу.
найдите abbc, abbbc, abbbbc, но не abc.
Например, ab {2,3} c найдет abbc, но не abc или abbbbc.
Примечание:
 Например, при поиске в строке abbbbbcd шаблон b {3,} вернет bbbbb, а b {3,}? вернет bbb (то есть без вопросительного знака вы получите строку из пяти символов «b», а с вопросительным знаком - строку из трех символов «b»). Аналогично, при поиске той же строки с использованием шаблона b {2,4} вы получите bbbb; при использовании b {2,4}? вы получите bb.k-x] z соответствует abz, aiz и ayz,
Например, при поиске в строке abbbbbcd шаблон b {3,} вернет bbbbb, а b {3,}? вернет bbb (то есть без вопросительного знака вы получите строку из пяти символов «b», а с вопросительным знаком - строку из трех символов «b»). Аналогично, при поиске той же строки с использованием шаблона b {2,4} вы получите bbbb; при использовании b {2,4}? вы получите bb.k-x] z соответствует abz, aiz и ayz,но не акз.
найти строку A1B.
 (Шестнадцатеричный 31 - это ASCII
(Шестнадцатеричный 31 - это ASCIIкод 1 ).
Вы также можете использовать \ x { NNNN } для поиска символов, код которых занимает более одного байта (Unicode).
Примечание:
Вы можете использовать выражения \ t , \ w , \ W , \ d , \ D , \ s , \ S , \ b и \ B в скобках.Например, b [\ d-e] b будет
найдите b1b, b2b или beb.
Синтаксис регулярного выражения
Синтаксис регулярного выражения -
синтаксис и семантика регулярных выражений, поддерживаемых GRegex
строка слева направо.Большинство персонажей в
шаблон и сопоставьте соответствующие символы в строке. Как
тривиальный пример, шаблон
указано соответствие без регистра (флаг
G_REGEX_CASELESS ), буквысовпадают независимо от случая.
альтернативы и повторы в выкройке. Они закодированы в
паттерн за счет использования метасимволов, которые не обозначают сами себя
но вместо этого интерпретируются особым образом.
Часть узора, заключенная в квадратные скобки, называется "символом".
класс".
обратная косая черта
Символ обратной косой черты имеет несколько применений. Во-первых, если за ним следует
не буквенно-цифровой символ, он удаляет любое особое значение, которое
характер может иметь.Использование обратной косой черты как escape-символа
применяется как внутри, так и за пределами классов символов.
Например, если вы хотите сопоставить символ *, вы пишете \ * в
шаблон. Это экранирующее действие применяется независимо от того, действуют ли следующие
в противном случае был бы интерпретирован как метасимвол, поэтому он
всегда безопасно ставить перед не буквенно-цифровым символом обратную косую черту, чтобы указать
что он стоит сам за себя. В частности, если вы хотите сопоставить
обратная косая черта, вы пишете \\.
Если шаблон скомпилирован с использованием G_REGEX_EXTENDED
вариант, пробел в шаблоне (кроме класса символов) и
символы между # вне класса символов и следующей новой строкой
игнорируются.Для включения пробела или символа # можно использовать экранирующую обратную косую черту.
как часть выкройки.
Обратите внимание, что компилятор C сам интерпретирует обратную косую черту в строках, поэтому
вам нужно продублировать все символы \, когда вы помещаете регулярное выражение
в строке C, например "\\ d {3}".
Если вы хотите убрать особое значение из последовательности символов,
вы можете сделать это, поместив их между \ Q и \ E.
Последовательность \ Q ... \ E распознается как внутри, так и снаружи символа
классы.
Непечатаемые символы
Второе использование обратной косой черты обеспечивает способ кодирования непечатаемых
символы в узорах видимым образом. Нет никаких ограничений на
появление непечатаемых символов, кроме двоичного нуля, который
завершает шаблон, но когда шаблон готовится с помощью текста
редактирования, обычно проще использовать один из следующих escape-символов
последовательности, чем двоичный символ, который он представляет:
Таблица 3. Непечатаемые символы
| Побег | Значение |
|---|---|
| \ a | аварийный сигнал, то есть символ BEL (шестнадцатеричный 07) |
| \ сх | "control-x", где x - любой символ |
| \ e | escape (шестнадцатеричный 1B) |
| \ f | подача формы (шестнадцатеричный 0C) |
| \ п | перевод строки (шестнадцатеричный 0A) |
| \ r | возврат каретки (шестнадцатеричный 0D) |
| \ т | табуляция (шестнадцатеричная 09) |
| \ ddd | символа с восьмеричным кодом ddd или обратная ссылка |
| \ xhh | символа с шестнадцатеричным кодом hh |
| \ x {ххх..} | символа с шестнадцатеричным кодом ччч .. |
Точный эффект \ cx заключается в следующем: если x - строчная буква,
он переводится в верхний регистр. Тогда бит 6 символа (шестнадцатеричный 40) равен
перевернутый. Таким образом, \ cz становится шестнадцатеричным 1A, а \ c {становится шестнадцатеричным 3B, а \ c;
становится шестнадцатеричным 7B.
После \ x читаются от нуля до двух шестнадцатеричных цифр (буквы могут быть
в верхнем или нижнем регистре). Может отображаться любое количество шестнадцатеричных цифр.
между \ x {и}, но значение кода символа
должно быть меньше 2 ** 31 (то есть максимальное шестнадцатеричное значение
7FFFFFFF).Если символы, отличные от шестнадцатеричных цифр, появляются между
\ x {and}, или если нет завершения}, эта форма выхода не является
признал. Вместо этого начальный \ x будет интерпретироваться как основной шестнадцатеричный
escape, без следующих цифр, что дает символ, чей
значение равно нулю.
Символы, значение которых меньше 256, могут быть определены любым из
два синтаксиса для \ x. Нет никакой разницы
в способе обращения с ними. Например, \ xdc - это то же самое, что
\ x {dc}.
После \ 0 читаются еще до двух восьмеричных цифр.Если будет меньше
чем две цифры, используются только те, которые присутствуют.
Таким образом, последовательность \ 0 \ x \ 07 определяет два двоичных нуля, за которыми следует BEL
символ (кодовое значение 7). Убедитесь, что вы указали две цифры после
начальный ноль, если следующий за ним символ шаблона является восьмеричным
цифра.
Обработка обратной косой черты, за которой следует цифра, отличная от 0, сложна.
Вне класса символов GRegex читает его и любые последующие цифры как
десятичное число. Если число меньше 10, или если есть
было по крайней мере, что многие предыдущие захватывающие левые круглые скобки в
выражение, вся последовательность используется как обратная ссылка.А
описание того, как это работает, будет дано позже, после обсуждения
заключенных в скобки подшаблонов.
Внутри класса символов или если десятичное число больше 9
и было не так много подшаблонов захвата, GRegex перечитывает
до трех восьмеричных цифр после обратной косой черты и использует их для генерации
символ данных. Любые последующие цифры означают сами себя. Например:
Таблица 4. Непечатаемые символы
| Побег | Значение |
|---|---|
| \ 040 | - это еще один способ записи пробела |
| \ 40 | то же самое, при условии, что имеется менее 40 предыдущих подшаблонов захвата. |
| \ 7 | - всегда обратная ссылка |
| \ 11 | может быть обратной ссылкой или другим способом написания табуляции |
| \ 011 | всегда вкладка |
| \ 0113 | - это табуляция, за которой следует символ "3" |
| \ 113 | может быть обратной ссылкой, иначе символ с восьмеричным кодом 113 |
| \ 377 | может быть обратной ссылкой, в противном случае байт, состоящий полностью из 1 бит |
| \ 81 | - это либо обратная ссылка, либо двоичный ноль, за которым следуют два символа «8» и «1» |
Обратите внимание, что восьмеричные значения 100 или больше не должны вводиться
ведущий ноль, потому что когда-либо читается не более трех восьмеричных цифр.
Все последовательности, определяющие один символ, могут использоваться как внутри
и вне классов персонажей. Кроме того, внутри класса символов
последовательность \ b интерпретируется как символ возврата (шестнадцатеричное 08), а
последовательности \ R и \ X интерпретируются как символы «R» и «X» соответственно.
Вне класса символов эти последовательности имеют разные значения (см. Ниже).
Абсолютные и относительные обратные ссылки
Последовательность \ g, за которой следует положительное или отрицательное число, необязательно заключенное
в фигурных скобках - абсолютная или относительная обратная ссылка.Обратные ссылки
обсуждается позже, после обсуждения заключенных в скобки подшаблонов.
Общие типы символов
Другой вариант использования обратной косой черты - для указания универсальных типов символов.
Всегда признаются:
Таблица 5. Общие символы
| Побег | Значение |
|---|---|
| \ d | любая десятичная цифра |
| \ D | любой символ, кроме десятичной цифры |
| \ с | любой пробельный символ |
| \ S | любой символ, не являющийся пробельным |
| \ w | любой символ "слова" |
| \ Вт | любой символ, не являющийся словом |
Каждая пара управляющих последовательностей разделяет полный набор символов.
на два непересекающихся множества.Любой данный символ соответствует одному и только одному,
каждой пары.
Эти последовательности типов символов могут появляться как внутри, так и снаружи символа.
классы. Каждый из них соответствует одному символу соответствующего типа.
Если текущая точка совпадения находится в конце переданной строки, все
из них не удается, так как нет символа для сопоставления.
Для совместимости с Perl \ s не соответствует символу VT (код
11). Это отличает его от «космического» класса POSIX. \ S
символы - HT (9), LF (10), FF (12), CR (13) и пробел (32).
Символ «слово» - это подчеркивание или любой символ меньше 256,
это буква или цифра.
Символы со значениями больше 128 никогда не соответствуют \ d,
\ s или \ w и всегда соответствует \ D, \ S и \ W.
Последовательности новой строки
За пределами класса символов escape-последовательность \ R соответствует любому Unicode
последовательность новой строки.
Эта конкретная группа соответствует либо двухсимвольной последовательности CR, за которой следует
LF или один из одиночных символов LF (перевод строки, U + 000A), VT (вертикальная табуляция,
U + 000B), FF (перевод страницы, U + 000C), CR (возврат каретки, U + 000D), NEL (следующий
строка, U + 0085), LS (разделитель строк, U + 2028) или PS (разделитель абзацев, U + 2029).Последовательность из двух символов рассматривается как единый блок, который
нельзя разделить. Внутри класса символов \ R соответствует букве «R».
Свойства символов Юникода
Для поддержки универсальных типов символов есть три дополнительных выхода
последовательности, это:
Таблица 6. Общие типы символов
| Побег | Значение |
|---|---|
| \ p {xx} | персонаж со свойством xx |
| \ P {xx} | символ без свойства xx |
| \ X | расширенная последовательность Unicode |
Имена свойств, представленные xx выше, ограничены Unicode
имена скриптов, общие свойства категории и "Любой", соответствующий
любой символ (включая новую строку).Другие свойства, например "InMusicalSymbols"
в настоящее время не поддерживаются. Обратите внимание, что \ P {Any} не соответствует никаким символам,
поэтому всегда вызывает сбой матча.
Наборы символов Юникода определяются как принадлежащие определенным сценариям. А
символ из одного из этих наборов может быть сопоставлен с помощью имени скрипта. За
например, \ p {Greek} или \ P {Han}.
Те, которые не являются частью идентифицированного сценария, объединяются как
«Обычный». Текущий список скриптов можно найти в документации для
перечисление #GUnicodeScript.Lu} совпадает с \ P {Lu}.
Если с \ p или \ P указана только одна буква, она включает в себя все общие
свойства категории, начинающиеся с этой буквы. В этом случае при отсутствии
при отрицании фигурные скобки в escape-последовательности необязательны; эти двое
примеры имеют тот же эффект:
\ p {L}
\ pL
Помимо двухбуквенных кодов категорий, перечисленных в
документация для перечисления #GUnicodeType, следующие
Поддерживаются коды свойств общей категории:
Таблица 7.Коды недвижимости
| Код | Значение |
|---|---|
| К | Другое |
| л | Письмо |
| М | Марка |
| N | Номер |
| п | Пунктуация |
| S | Символ |
| Z | Сепаратор |
Также поддерживается специальное свойство L &: оно соответствует символу, имеющему
свойство Lu, Ll или Lt, другими словами, буква, которая не классифицируется как
модификатор или «другое».
Длинные синонимы этих свойств, которые поддерживает Perl (например, \ ep {Letter})
не поддерживаются GRegex, и нельзя добавлять префиксы к любому из этих
недвижимость с "Есть".
Ни один из символов в таблице Unicode не имеет свойства Cn (неназначенный).
Вместо этого это свойство предполагается для любой кодовой точки, не входящей в
Таблица Юникода.
Указание сопоставления без регистра не влияет на эти escape-последовательности.
Например, \ p {Lu} всегда соответствует только прописным буквам.
\ X escape соответствует любому количеству символов Unicode, которые образуют
расширенная последовательность Unicode. \ X эквивалентно
(?> \ PM \ pM *)
То есть он соответствует символу без свойства «метка», за которым следует
на ноль или более символов со свойством "mark" и обрабатывает
последовательность как атомная группа (см. ниже). Персонажи со знаком "отметка"
свойство обычно являются акцентами, влияющими на предыдущий символ.
Сопоставление символов по свойству Unicode происходит не быстро, потому что GRegex имеет
для поиска структуры, содержащей данные более пятнадцати тысяч
символы.Вот почему традиционные escape-последовательности, такие как \ d и
\ w не используют свойства Unicode.
Простые утверждения
Последний вариант использования обратной косой черты - для некоторых простых утверждений. An
утверждение определяет условие, которое должно быть выполнено в определенной точке в
совпадение без использования каких-либо символов из строки. В
использование подшаблонов для более сложных утверждений описано ниже.
Утверждения с обратной косой чертой:
Таблица 8. Простые утверждения
| Побег | Значение |
|---|---|
| \ b | совпадений на границе слова |
| \ B | совпадает, если не на границе слова |
| \ A | соответствует началу строки |
| \ Z | соответствует в конце строки или перед новой строкой в конце строки |
| \ z | соответствует только в конце строки |
| \ G | соответствует первой соответствующей позиции в строке |
Эти утверждения могут не появляться в классах символов (но обратите внимание, что \ b
имеет другое значение, а именно символ backspace внутри
класс персонажа).
Граница слова - это позиция в строке, где текущий
символ и предыдущий символ не соответствуют \ w или \ W (т. е.
один соответствует \ w, а другой соответствует \ W), либо началу или концу
строка, если первый или последний символ соответствует \ w соответственно.
Утверждения \ A, \ Z и \ z отличаются от традиционного циркумфлекса.
и доллар (описанный в следующем разделе) в том смысле, что они всегда соответствуют
в самом начале и в конце строки, любые параметры
задавать.Таким образом, они не зависят от многострочного режима. Эти три утверждения
на них не влияют параметры G_REGEX_MATCH_NOTBOL или G_REGEX_MATCH_NOTEOL ,
которые влияют только на поведение метасимволов с циркумфлексом и доллара.
Однако, если аргумент start_position функции сопоставления отличен от нуля,
указывает, что сопоставление должно начинаться с точки, отличной от начала
строка \ A никогда не может совпадать. Разница между \ Z и \ z заключается в
что \ Z соответствует перед новой строкой в конце строки, а также в
самый конец, тогда как \ z соответствует только в конце.
Утверждение \ G истинно только тогда, когда текущая совпадающая позиция находится в
начальная точка совпадения, как указано аргументом start_position
к функциям сопоставления. Он отличается от \ A, когда значение startoffset равно
ненулевой.
Обратите внимание, однако, что интерпретация \ G как начала
текущее совпадение немного отличается от Perl, который определяет его как
конец предыдущего матча. В Perl они могут быть разными, если
ранее совпавшая строка была пустой.
Если все альтернативы шаблона начинаются с \ G, выражение будет
привязан к начальной позиции матча, и установлен флаг "привязка"
в скомпилированном регулярном выражении.
Circumflex и доллар
Вне класса символов в режиме сопоставления по умолчанию циркумфлекс
символ - это утверждение, которое истинно, только если текущее соответствие
точка находится в начале строки. Если аргумент start_position для
функции сопоставления не равны нулю, циркумфлекс никогда не может соответствовать, если
Параметр G_REGEX_MULTILINE не установлен.Внутри класса символов циркумфлекс
имеет совершенно другое значение (см. ниже).
Циркумфлекс не обязательно должен быть первым символом рисунка, если число
альтернатив, но это должно быть первым делом в каждом
альтернатива, в которой он появляется, если шаблон когда-либо будет соответствовать этому
филиал. Если все возможные варианты начинаются с циркумфлекса, то есть
если шаблон ограничен совпадением только в начале строки,
это называется "закрепленным" шаблоном. (Есть и другие
конструкции, которые могут вызвать привязку шаблона.)
Символ доллара - это утверждение, которое истинно только в том случае, если текущий
точка совпадения находится в конце строки или сразу
перед новой строкой в конце строки (по умолчанию). Доллар не нужен
быть последним символом шаблона, если есть несколько альтернатив
вовлечены, но это должен быть последний элемент в любой ветке, в которой он
появляется. Доллар не имеет особого значения в классе символов.
Значение доллара можно изменить так, чтобы оно совпадало только с
самый конец строки, установив параметр G_REGEX_DOLLAR_ENDONLY в
время компиляции.Это не влияет на утверждение \ Z.
Значения символов с циркумфлексом и доллара изменяются, если
G_REGEX_MULTILINE опция установлена. В этом случае
циркумфлекс соответствует сразу после внутренних символов новой строки, а также
начало строки. Он не соответствует символу новой строки, заканчивающей строку.
Доллар соответствует перед любыми символами новой строки в строке, а также в самом начале
конец, когда установлен G_REGEX_MULTILINE . Когда новая строка
заданная как двухсимвольная последовательность CRLF, изолированные символы CR и LF
не указывайте новые строки.не закреплены в многострочном режиме, и возможно соответствие для циркумфлекса
когда аргумент start_position функции сопоставления
не равно нулю. Параметр G_REGEX_DOLLAR_ENDONLY игнорируется
если установлен G_REGEX_MULTILINE .
Обратите внимание, что последовательности \ A, \ Z и \ z могут использоваться для сопоставления начала и
конец строки в обоих режимах, и если все ветви шаблона начинаются с
\ A он всегда привязан, независимо от того, G_REGEX_MULTILINE
установлен.
Точка (точка, точка)
Вне класса символов точка в шаблоне соответствует любому одному символу
в строке, включая непечатаемый символ, но не (по
по умолчанию) новая строка. В UTF-8 длина символа может превышать один байт.
Когда конец строки определяется как один символ, точка никогда не соответствует этому
персонаж; при использовании двухсимвольной последовательности CRLF точка не соответствует CR
если сразу за ним следует LF, но в противном случае он соответствует всем символам
(в том числе изолированные CR и LF).Когда какие-либо окончания строк Unicode
распознано, точка не соответствует CR, LF или любому другому окончанию строки
символы.
Если установлен флаг G_REGEX_DOTALL , точки соответствуют символам новой строки
также. Обработка точки полностью не зависит от обработки циркумфлекса.
и доллар, единственная связь заключается в том, что они оба включают новую строку
символы. Точка не имеет особого значения в классе символов.
Поведение точки по отношению к новым строкам можно изменить.Если
G_REGEX_DOTALL опция установлена, точка соответствует любому
персонаж без исключения. Если новая строка определена как двухсимвольная
последовательность CRLF, для соответствия ей нужны две точки.
Обработка точки полностью не зависит от обработки циркумфлекса и
доллар, единственная связь заключается в том, что они оба включают символы новой строки. Точка не имеет
особое значение в классе символов.
Соответствие одному байту
За пределами класса символов escape-последовательность \ C соответствует любому байту,
как в режиме UTF-8, так и вне его.В отличие от точки, он всегда соответствует любой строке
конечные символы.
Эта функция предоставляется в Perl для сопоставления отдельных байтов в
Режим UTF-8. Потому что он разбивает символы UTF-8 на отдельные
байтов, то, что остается в строке, может быть искаженной строкой UTF-8. За
по этой причине лучше избегать escape-последовательности \ C.
GRegex не позволяет \ C появляться в утверждениях просмотра назад (описано
ниже), потому что в режиме UTF-8 это сделало бы невозможным вычисление
длина просмотра назад.
Квадратные скобки и классы символов
Открывающая квадратная скобка вводит класс символов, заканчивающийся символом
закрывающая квадратная скобка. Закрывающая квадратная скобка сама по себе не является чем-то особенным. Если закрывающая квадратная скобка требуется как член класса,
это должен быть первый символ данных в классе (после начального
циркумфлекс, если есть) или экранированный обратной косой чертой.
Класс символов соответствует одному символу в строке. Соответствующий персонаж
должен быть в наборе символов, определенных классом, если только первый
символ в определении класса является циркумфлексом, и в этом случае
строковый символ не должен входить в набор, определенный классом.aeiou] соответствует любому символу, кроме гласной строчной буквы.
Обратите внимание, что циркумфлекс - это просто удобное обозначение для указания
символы, которые находятся в классе, путем перечисления тех, которых нет. А
класс, который начинается с циркумфлекса, не является утверждением: он по-прежнему потребляет
символ из строки, и поэтому он не работает, если текущий указатель
находится в конце строки.
В режиме UTF-8 можно включать символы со значениями больше 255
в классе как буквальная строка байтов или используя экранирование \ x {
механизм.а]
всегда соответствует одному из этих символов.
Знак минус (дефис) может использоваться для указания диапазона символов в
класс персонажа. Например, [d-m] соответствует любой букве
от d до m включительно. Если знак минус требуется в
class, он должен быть экранирован обратной косой чертой или находиться в позиции
где его нельзя интерпретировать как указание диапазона, обычно как
первый или последний символ в классе.
Использование буквального символа "]" в качестве конечного символа невозможно.
диапазона.Такой узор, как [W-] 46] интерпретируется как класс
два символа («W» и «-»), за которыми следует буквальная строка «46]», поэтому
соответствует "W46]" или "-46]". Однако, если "]" экранирован
обратная косая черта интерпретируется как конец диапазона, поэтому [W - \] 46] интерпретируется
как класс, содержащий диапазон, за которым следуют два других символа. \ W_] соответствует любой букве или цифре,
но не подчеркивание.
В классах символов распознаются только метасимволы:
обратная косая черта, дефис (только там, где это можно интерпретировать как указание
диапазон), циркумфлекс (только в начале), открывающая квадратная скобка (только
когда это можно интерпретировать как введение имени класса POSIX - см.
следующий раздел) и закрывающая квадратная скобка. Однако,
экранирование других не буквенно-цифровых символов не вредит.
Классы символов Posix
GRegex поддерживает нотацию POSIX для классов символов.Это использует имена
заключены в [: и:] в квадратных скобках. Например,
[01 [: alpha:]%]
соответствует «0», «1», любому буквенному символу или «%». Поддерживаемый класс
имена
Таблица 9. Классы Posix
| Имя | Значение |
|---|---|
| alnum | букв и цифр |
| альфа | буквы |
| ascii | кодов символов 0-127 |
| пустой | только пробел или табуляция |
| cntrl | управляющих символа |
| цифра | десятичных цифры (то же, что \ d) |
| график | печатных знака, без пробела |
| нижний | строчные буквы |
| печать | печатных символа, включая пробел |
| пункт | печатных знака, кроме букв и цифр |
| место | пробел (не совсем то же самое, что \ s) |
| верх | заглавные буквы |
| слово | символа "слово" (то же, что и \ w) |
| xdigit | шестнадцатеричные цифры |
Символы "пробел": HT (9), LF (10), VT (11), FF (12), CR (13),
и пробел (32).цифра:]]
соответствует «1», «2» или любому нецифровому значению. GRegex также признает
Синтаксис POSIX [.ch.] И [= ch =], где «ch» - это «элемент сортировки», но
они не поддерживаются, и при их обнаружении выдается ошибка.
В режиме UTF-8 символы со значениями больше 128 не соответствуют никаким
классов символов POSIX.
Вертикальная полоса
Символы вертикальной черты используются для разделения альтернативных шаблонов. За
например, узор
гилберт | салливан
соответствует либо "gilbert", либо "sullivan".Любое количество альтернатив может
появляются, и допускается пустая альтернатива (соответствует пустому
строка). Процесс сопоставления пробует каждую альтернативу по очереди, начиная с
слева направо, и используется первый успешный. Если альтернативы находятся внутри подшаблона (определенного ниже), «успешно» означает соответствие остальной части основного шаблона, а также альтернативы в подшаблоне.
Внутренняя настройка опции
Настройки G_REGEX_CASELESS , G_REGEX_MULTILINE , G_REGEX_MULTILINE ,
и G_REGEX_EXTENDED Параметры могут быть изменены изнутри шаблона с помощью
последовательность букв параметров в стиле Perl, заключенных между "(?" и ")".В
варианты букв
Таблица 10. Настройки опций
| Опция | Флаг |
|---|---|
| i | G_REGEX_CASELESS |
| м | G_REGEX_MULTILINE |
| с | G_REGEX_DOTALL |
| x | G_REGEX_EXTENDED |
Например, (? Im) устанавливает многострочное сопоставление без регистра.Это также
эти параметры можно отключить, поставив перед буквой дефис, а
комбинированная установка и снятие установки, например (? im-sx), которая устанавливает G_REGEX_CASELESS
и G_REGEX_MULTILINE при отключении G_REGEX_DOTALL и G_REGEX_EXTENDED ,
также разрешено. Если буква появляется как до, так и после
дефис, параметр не установлен.
Когда изменение параметра происходит на верхнем уровне (то есть не внутри подшаблона
круглые скобки), изменение применяется к остальной части узора
что следует.
Изменение параметра внутри подшаблонов (см. Ниже описание подшаблонов)
влияет только на ту часть текущего паттерна, которая следует за ним, поэтому
(а (? Я) б) в
соответствует abc и aBc и никаким другим строкам (при условии, что G_REGEX_CASELESS не
используемый). Таким образом, параметры могут иметь разные настройки.
в разных частях узора. Любые изменения, внесенные в одну альтернативу
переходят в последующие ветки в рамках того же подшаблона. За
пример,
(a (? I) b | c)
соответствует "ab", "aB", "c" и "C", хотя при сопоставлении "C"
первая ветвь заброшена до установки опции.Это потому что
эффекты настроек параметров происходят во время компиляции. Было бы
в противном случае какое-то очень странное поведение.
Опции G_REGEX_UNGREEDY и
G_REGEX_EXTRA и G_REGEX_DUPNAMES
можно изменить так же, как и Perl-совместимые параметры, используя
символы U, X и J соответственно.
Подшаблоны
Подшаблоны разделяются круглыми скобками (круглые скобки), которые могут быть
вложенные. Превращение части шаблона в подшаблон делает две вещи:
Он локализует набор альтернатив.Например, узор
cat (aract | erpillar |) соответствует одному из слов «кошка», «катаракта» или
"гусеница". Без круглых скобок это будет соответствовать слову "катаракта",
«эрпиллар» или пустая строка.Он устанавливает подшаблон как захватывающий подшаблон. Это означает
что при совпадении всего шаблона эта часть
Строка, соответствующая подшаблону, может быть получена с помощьюg_match_info_fetch ().
Открывающие скобки считаются слева направо (начиная с 1, как
подшаблон 0 - это вся совпадающая строка), чтобы получить числа для
захват подшаблонов.
Например, если строка «красный король» сопоставлена с шаблоном
((красный | белый) (король | королева))
захваченные подстроки "красный король", "красный" и "король" пронумерованы 1, 2 и 3 соответственно.
Тот факт, что простые круглые скобки выполняют две функции, не всегда
полезно. Часто бывает, что требуется подшаблон группировки
без требования захвата. Если следует открывающая скобка
знак вопроса и двоеточие, подшаблон не выполняет никакого захвата,
и не учитывается при подсчете количества последующих
захват подшаблонов.Например, если строка «белый ферзь»
сопоставлен с образцом
((?: Красный | белый) (король | королева))
захваченные подстроки "белая королева" и "королева" пронумерованы
1 и 2. Максимальное количество подшаблонов захвата - 65535.
В качестве удобного сокращения, если требуются какие-либо настройки параметров на
начало субшаблона без захвата, могут появиться буквы выбора
между "?" и ":". Таким образом, два шаблона
(? I: суббота | воскресенье) (? :(? i) суббота | воскресенье)
соответствуют точно такому же набору строк.Потому что альтернативные ветки
пробовал слева направо, и параметры не сбрасываются до конца
подшаблон достигнут, настройка параметра в одной ветке влияет
последующие ветви, поэтому указанные выше шаблоны соответствуют "SUNDAY", а также
"Суббота".
Именованные подшаблоны
Определить захватывающие скобки по номеру просто, но это может быть
очень сложно отслеживать числа в сложных регулярных выражениях.
Кроме того, если выражение изменяется, числа могут
изменение.Чтобы решить эту проблему, GRegex поддерживает присвоение имен
подшаблоны. Подшаблон можно назвать одним из трех способов: (? <Имя> ...) или
(? 'name' ...) как в Perl или (? P
Ссылки на захват скобок из других
части шаблона, такие как обратные ссылки, рекурсия и условия,
могут быть сделаны как по имени, так и по номеру.
Имена состоят из 32 буквенно-цифровых символов и знаков подчеркивания. Названный
захватывающие круглые скобки по-прежнему выделяют числа, а также имена, точно так же, как
если имена не присутствовали.По умолчанию имя должно быть уникальным в пределах шаблона, но можно расслабиться.
это ограничение, установив параметр G_REGEX_DUPNAMES в
время компиляции. Это может быть полезно для шаблонов, в которых только один экземпляр
именованные круглые скобки могут совпадать. Предположим, вы хотите сопоставить название дня недели,
либо в виде трехбуквенного сокращения, либо в виде полного имени, и в обоих случаях вы
хотите извлечь аббревиатуру. Этот шаблон (без учета разрывов строк) делает
работа:
(?Пн | Пт | Вс) (?: день)? | (? Вт) (?: день)? | (? ср) (?: nesday)? | (? чт) (?: rsday)? | (? Сб) (?: urday)?
Имеется пять захватывающих подстрок, но после совпадения устанавливается только одна.Функция извлечения данных по имени возвращает подстроку
для первого (и в этом примере единственного) подшаблона этого имени, который
совпадает. Это избавляет от необходимости искать подшаблон с номером. если ты
сделать ссылку на неуникальный именованный подшаблон из другого места в
шаблон используется тот, который соответствует наименьшему номеру.
повторение
Повторение определяется квантификаторами, которые могут следовать за любым из
Следующие пункты:
буквальный символ данных
метасимвол точка
escape-последовательность \ C
escape-последовательность \ X (в режиме UTF-8)
escape-последовательность \ R
escape-последовательность, например \ d, которая соответствует одному символу
класс символов
обратная ссылка (см. Следующий раздел)
заключенный в скобки подшаблон (если это не утверждение)
Общий квантификатор повторения определяет минимальное и максимальное количество
разрешенных совпадений, указав два числа в фигурных скобках
(фигурные скобки), разделенные запятой.Цифры должны быть меньше 65536,
и первое должно быть меньше или равно второму. Например:
z {2,4}
соответствует «zz», «zzz» или «zzzz». Закрывающая скобка сама по себе не является
особый персонаж. Если второе число опущено, но стоит запятая
в настоящее время нет верхнего предела; если второе число и запятая
оба опущены, квантификатор указывает точное количество необходимых
совпадения. Таким образом
[aeiou] {3,}
соответствует не менее 3 последовательных гласных, но может соответствовать гораздо большему количеству, а
\ d {8}
соответствует ровно 8 цифрам.Открывающая фигурная скобка, которая появляется в
позиция, в которой квантификатор недопустим, или тот, который не соответствует
синтаксис квантификатора считается буквальным символом. Например,
{, 6} - это не квантификатор, а буквальная строка из четырех символов.
В режиме UTF-8 квантификаторы применяются к символам UTF-8, а не к
отдельные байты. Так, например, \ x {100} {2} соответствует двум UTF-8
символы, каждый из которых представлен двухбайтовой последовательностью. По аналогии,
\ X {3} соответствует трем расширенным последовательностям Unicode, каждая из которых может быть
длиной в несколько байтов (причем они могут быть разной длины).
Квантификатор {0} разрешен, заставляя выражение вести себя так, как если бы
предыдущий элемент и квантификатор отсутствовали.
Для удобства три наиболее распространенных квантора имеют односимвольный
сокращения:
Таблица 11. Сокращения для кванторов
| Сокращение | Значение |
|---|---|
| * | эквивалентно {0,} |
| + | эквивалентно {1,} |
| ? | эквивалентно {0,1} |
Можно создавать бесконечные циклы, следуя подшаблону
который не может соответствовать никаким символам с квантификатором, не имеющим верхнего предела,
например:
(а?) *
Поскольку есть случаи, когда это может быть полезно, такие шаблоны
принято, но если какое-либо повторение подшаблона действительно соответствует
символов нет, цикл разорван принудительно.
По умолчанию квантификаторы являются «жадными», то есть соответствуют как можно большему количеству
по возможности (до максимально допустимого количества раз), без
приводя к сбою остальной части шаблона. Классический пример того, где
это создает проблемы при попытке сопоставления комментариев в программах на языке C. Эти
появляются между / * и * /, а внутри комментария отдельные * и /
могут появиться символы. Попытка сопоставить комментарии C с помощью
шаблон
/\*.*\*/
к строке
/ * первый комментарий * / без комментария / * второй комментарий * /
терпит неудачу, потому что он соответствует всей строке из-за жадности
файл.* пункт.
Однако, если после квантификатора стоит вопросительный знак, он перестает
быть жадным и вместо этого соответствует минимально возможное количество раз, поэтому
шаблон
/\*.*?\*/
правильно поступает с комментариями C. Значение различных
квантификаторы не меняются иначе, просто предпочтительное количество
совпадения. Не путайте вопросительный знак с его использованием в качестве
квантификатор сам по себе. Поскольку он имеет два применения, иногда он может
кажутся удвоенными, как в
\ d ?? \ d
который соответствует одной цифре по предпочтению, но может соответствовать двум, если это
только так, чтобы остальная часть шаблона соответствовала.
Если установлен флаг G_REGEX_UNGREEDY , квантификаторы не являются жадными
по умолчанию, но отдельные можно сделать жадными, следуя за ними с
знак вопроса. Другими словами, он меняет поведение по умолчанию.
Когда заключенный в скобки подшаблон определяется количественно с минимальным повторением
количество больше 1 или с ограниченным максимумом, больше памяти
требуется для скомпилированного выкройки, пропорционально размеру
минимум или максимум.
Если шаблон начинается с.* или. {0,} и флаг G_REGEX_DOTALL
установлен, таким образом позволяя точке совпадать с новой строкой,
шаблон неявно привязан, потому что все, что будет дальше, будет проверено
против каждой позиции символа в строке, поэтому нет
точка в повторной попытке общего совпадения в любой позиции после первой. для явного указания привязки.
Однако есть одна ситуация, когда оптимизацию использовать нельзя.
Когда. * Находится внутри круглых скобок, которые являются предметом
обратная ссылка в другом месте шаблона, совпадение в начале может завершиться ошибкой
где более поздний преуспевает. Рассмотрим, например:
(. *) Abc \ 1
Если строка - «xyz123abc123», точкой совпадения является четвертый символ.
По этой причине такой шаблон не закреплен неявно.
Когда подшаблон захвата повторяется, захваченное значение является
подстрока, соответствующая последней итерации.Например, после
(твид [думе] {3} \ s *) +
сопоставил "tweedledum tweedledee" значение захваченной подстроки
это «твидлди». Однако, если есть вложенные подшаблоны захвата,
соответствующие захваченные значения могли быть установлены на предыдущих итерациях.
Например, после
/ (а | (б)) + /
соответствует «aba», значение второй захваченной подстроки - «b».
Атомная группировка и притяжательные кванторы
И с максимизацией («жадный»), и с минимизацией («нелюбопытный» или «ленивый»)
повторение, отказ того, что следует, обычно вызывает повторное
предмет для переоценки, чтобы увидеть, есть ли другой номер
of Repeats позволяет остальной части шаблона соответствовать.Иногда это
полезно для предотвращения этого либо для изменения характера
совпадать, или вызвать его сбой раньше, чем в противном случае, когда
автор выкройки знает, что продолжать нет смысла.
Рассмотрим, например, шаблон \ d + foo, примененный к строке
123456бар
После сопоставления всех 6 цифр и неудачного совпадения "foo" нормальный
действие сопоставителя состоит в том, чтобы повторить попытку, указав только 5 цифр, соответствующих
\ d + item, а затем с 4 и так далее, прежде чем окончательно потерпеть неудачу.«Атомная группировка» (термин, взятый из книги Джеффри Фридла) обеспечивает
средство для указания того, что если подшаблон совпал, он не
подлежат переоценке таким образом.
Если мы используем атомарную группировку для предыдущего примера, сопоставитель
немедленно откажитесь от совпадения с "foo" в первый раз. Обозначение
это своего рода специальная скобка, начинающаяся с (?> как в этом
пример:
(?> \ D +) foo
Такая скобка "блокирует" часть шаблона, которую она содержит.
после совпадения, и отказ в дальнейшем в шаблоне
не позволил вернуться в нее.Возврат к предыдущему
items, однако, работает как обычно.
Альтернативное описание заключается в том, что подшаблон этого типа соответствует
строка символов, которую будет использовать идентичный автономный шаблон
совпадение, если оно привязано к текущей точке строки.
Подшаблоны атомарной группировки не захватывают подшаблоны. Простые случаи
такой, как приведенный выше пример, можно рассматривать как максимальное повторение, которое
должен проглотить все, что может. Итак, а одновременно \ d + и \ d +? готовы
чтобы настроить количество совпадающих цифр, чтобы
остальная часть совпадения с шаблоном (?> \ d +) может соответствовать только всей последовательности
цифры.
Атомные группы вообще, конечно, могут содержать сколь угодно сложные
подшаблоны и могут быть вложенными. Однако когда подшаблон для
атомная группа - это всего лишь один повторяющийся элемент, как в приведенном выше примере
могут использоваться более простые обозначения, называемые «притяжательным квантификатором». Этот
состоит из дополнительного символа +, следующего за квантификатором. С помощью
В этих обозначениях предыдущий пример можно переписать как
\ d ++ foo
Притяжательные кванторы всегда жадны; установка
G_REGEX_UNGREEDY опция игнорируется.Они удобны для обозначения
более простые формы атомной группы. Однако нет никакой разницы в
значение притяжательного квантора и эквивалента
атомная группа, хотя может быть разница в производительности;
притяжательные кванторы должны быть немного быстрее.
Синтаксис притяжательного квантификатора является расширением синтаксиса Perl.
Он был изобретен Джеффри Фридлом в первом издании его книги и
затем реализован Майком Макклоски в пакете Sun Java.
В конечном итоге он нашел свое отражение в Perl в версии 5.10.
В GRegex есть оптимизация, которая автоматически "овладевает" некоторыми простыми
конструкции паттернов. Например, последовательность A + B рассматривается как A ++ B, потому что
нет смысла возвращаться к последовательности A, когда B должен следовать.
Когда шаблон содержит неограниченное количество повторов внутри подшаблона, который
может повторяться неограниченное количество раз, использование
атомная группа - единственный способ избежать некоторых неудачных совпадений,
действительно очень долгое время. Шаблон
(\ D + | <\ d +>) * [!?]
соответствует неограниченному количеству подстрок, которые либо состоят из не-
цифры или цифры, заключенные в <>, за которыми следует либо! или ?.Когда это
спички, бегает быстро. Однако, если он применяется к
аааааааааааааааааааааааааааааааааааааааааааааааааа
требуется много времени, чтобы сообщить об ошибке. Это потому, что
строку можно разделить на внутреннюю \ D + repeat и внешнюю
* повторять большое количество способов, и все нужно попробовать. (The
пример использует [!?] вместо одного символа в конце, потому что
В GRegex есть оптимизация, позволяющая быстро выходить из строя
когда используется один символ.Он помнит последний одиночный символ
что требуется для совпадения, и преждевременно выйти из строя, если его нет
в строке.) Если шаблон изменен так, что он использует атомарный
группа, например:
((?> \ D +) | <\ d +>) * [!?]
последовательности нецифровых символов не могут быть нарушены, и отказ происходит быстро.
Обратные ссылки
Вне класса символов обратная косая черта, за которой следует цифра больше
0 (и, возможно, другие цифры) - это обратная ссылка на подшаблон захвата.
ранее (то есть слева) в шаблоне при условии, что
многие предыдущие захватывающие левые круглые скобки.
Однако, если десятичное число после обратной косой черты меньше 10,
он всегда воспринимается как обратная ссылка и вызывает ошибку, только если
не так много захватывающих левых скобок во всем шаблоне.
Другими словами, скобки, на которые есть ссылка, не обязательно
слева от ссылки для чисел меньше 10. A "вперед назад
ссылка "этого типа может иметь смысл, когда речь идет о повторении и
подшаблон справа участвовал в более ранней итерации.
Невозможно иметь числовую "прямую обратную ссылку" на подшаблон.
чье число равно 10 или больше, используя этот синтаксис, потому что последовательность, такая как \ e50,
интерпретируется как восьмеричный символ. См. Подраздел под названием
«Непечатаемые символы» выше для получения дополнительных сведений об обработке цифр.
после обратной косой черты. При использовании именных скобок такой проблемы не возникает.
Обратная ссылка на любой подшаблон возможна с использованием именованных круглых скобок (см. Ниже).
Другой способ избежать неоднозначности, присущей использованию цифр после
обратная косая черта используется для использования escape-последовательности \ g (введенной в Perl 5.10.)
За этим escape-символом должно следовать положительное или отрицательное число,
опционально заключены в фигурные скобки.
Добавить комментарий