
Файл robots.txt — способы анализа и проверки robots.txt
Поисковые роботы — краулеры начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцам сайтов следует создать и периодически проводить анализ robots.txt. От корректности его работы зависит скорость индексации страниц и место в поисковой выдачи.
Создание файла
Описание. Файл robots.txt — это документ со служебной информацией. Он предназначен для поисковых роботов. В нем записывают, какие страницы можно индексировать, какие — нет и каким именно краулерам. Например, англоязычный Facebook разрешает доступ только боту Google. Файл robots.txt любого сайта можно посмотреть в браузере по ссылке
www.site.ru/robots.txt.
Он не является обязательным элементом сайта, но его наличие желательно, потому что с его помощью владельцы сайта управляют поисковыми роботами. Задавайте разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничивайте время индексации и запрещайте доступ роботам, которые не относятся к основным поисковым системам. Это уменьшит нагрузку на сервер.
Создание. Создают файл в текстовом редакторе Notepad или подобных. Следите за тем, чтобы размер файла не превышал 32 КБ. Выбирайте для файла кодировку ASCII или UTF-8. Учтите, что файл должен быть единственным. Если сайт создан на CMS, то он будет генерироваться автоматически.
Разместите созданный файл в корневой директории сайта рядом с основным файлом index.html. Для этого используют FTP доступ. Если сайт сделан на CMS, то с файлом работают через административную панель. Когда файл создан и работает корректно, он доступен в браузере.
При отсутствии robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, когда увидите в выдаче незаполненные страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, остальные — закройте от индексации.
Проверка. Периодически проверяйте, все ли работает корректно. Если краулер не получает ответ 200 ОК, то он автоматически считает, что файла нет, и сайт открыт для индексации полностью. Коды ошибок бывают такими:
-
3хх — ответы переадресации. Робота направляют на другую страницу или на главную. Создавайте до пяти переадресаций на одной странице. Если их будет больше, робот пометит такую страницу как ошибку 404. То же самое относится и к переадресации по принципу бесконечного цикла; -
4хх — ответы ошибок сайта. Если краулер получает от файла robots.txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403; -
5хх — ответы ошибок сервера. Краулер будет «стучаться», пока не получит ответ, отличный от 500-го.
Правила создания
Начинаем с приветствия. Каждый файл должен начинаться с приветствия User-agent. С его помощью поисковики определят уровень открытости.
|
Код |
Значение |
|
User-agent: * |
Доступно всем |
|
User-agent: Yandex |
Доступно роботу Яндекс |
|
User-agent: Googlebot |
Доступно роботу Google |
|
User-agent: Mail.ru |
Доступно роботу Mail.ru |
Добавляем отдельные директивы под роботов. При необходимости добавляйте директивы для специализированных поисковых ботов Яндекса.
Однако в этом случае директивы * и Yandex не будут учитываться.
|
YandexBot |
Основной робот |
|
YandexImages |
Яндекс.Картинки |
|
YandexNews |
Яндекс.Новости |
|
YandexMedia |
Индексация мультимедиа |
|
YandexBlogs |
Индексация постов и комментариев |
|
YandexMarket |
Яндекс.Маркет |
|
YandexMetrika |
Яндекс.Метрика |
|
YandexDirect |
Рекламная сеть Яндекса |
|
YandexDirectDyn |
Индексация динамических баннеров |
|
YaDirectFetcher |
Яндекс.Директ |
|
YandexPagechecker |
Валидатор микроразметки |
|
YandexCalendar |
Яндекс.Календарь |
У Google собственные боты:
|
Googlebot |
Основной краулер |
|
Google-Images |
Google.Картинки |
|
Mediapartners-Google |
AdSense |
|
AdsBot-Google |
Проверка качества рекламы |
|
AdsBot-Google-Mobile |
Проверка качества рекламы на мобильных устройствах |
|
Googlebot-News |
Новости Google |
Сначала запрещаем, потом разрешаем. Оперируйте двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Работайте с разными уровнями. В файле можно задать настройки на четырех уровнях: сайта, страницы, папки и типа контента. Допустим, вы хотите закрыть изображения от индексации. Это можно сделать на уровне:
- папки — disallow: /images/
- типа контента — disallow: /*.jpg
Директивы группируйте блоками и отделяйте пустой строкой. Не пишите все правила в одну строку. Для каждой страницы, краулера, папки и пр. используйте отдельное правило. Также не путайте инструкции: бота пишите в user-agent, а не в директиве allow/disallow.
|
Нет |
Да |
|
Disallow: Yandex |
User-agent: Yandex Disallow: / |
|
Disallow: /css/ /images/ |
Disallow: /css/ Disallow: /images/ |
Пишите с учетом регистра. Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Укажите 301 редирект на главное зеркало сайта. Раньше для этого использовалась директива Host, но с марта 2018 г. она больше не нужна. Если она уже прописана в файле robots.txt, удалите или оставьте ее на свое усмотрение; роботы игнорируют эту директиву.
Для указания главного зеркала проставьте 301 редирект на каждую страницу сайта. Если редиректа стоят не будет, поисковик самостоятельно определит, какое зеркало считать главным. Чтобы исправить зеркало сайта, просто укажите постраничный 301 редирект и подождите несколько дней.
Пропишите директиву Sitemap (карту сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы:
- файлы не противоречили друг другу;
- страницы были исключены из обоих файлов;
- страницы были разрешены в обоих файлах.
Проводя анализ содержимого robots.txt, обратите внимание, включен ли sitemap в одноименную директиву. Записывается так: Sitemap: www.yoursite.ru/sitemap.xml
Указывайте комментарии через символ #. Все, что написано после него, краулер игнорирует.
Проверка файла
Проводите анализ robots.txt с помощью инструментов для разработчиков: через Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла собственным требованиям. Если для Яндекса файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в обеих системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверка в Яндекс.Вебмастере
Сначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Внизу станет доступен результат проверки.
Дополнительно проверяйте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Проверка в Google Robots Testing Tool
Позволяет проверять и редактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправляйте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл через блокнот или другой текстовый редактор. Затем загрузите его на сервер в корневой каталог.
Запомните
-
Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200. -
Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта. -
Заполняйте файл по правилам. Начинайте с кода “User-agent:”. Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис. -
Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех». -
Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов. -
Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap. -
Для анализа robots.txt используйте инструменты для разработчиков. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
Материал подготовила Светлана Сирвида-Льорентэ.
Инструменты проверки файла robots.txt | www.wordpress-abc.ru
Вступление
Если у вас есть желание закрыть некоторые материалы своего сайта от поисковых и других ботов, используется три метода:
Во-первых, создаётся файл robots.txt в котором специальными записями закрываются/открываются части контента. Важно, что файл robots.txt запрещает роботам сканировать URL сайта;
Во-вторых, на HTML(XHTML) страницах или в HTTP заголовке прописывается мета–тег robots с атрибутами noindex (не показывает страницу в поиске) и/или nofollow (не разрешает боту обходить ссылки страницы). Синтаксис мета тега robots:
<meta name="robots" content="noindex, nofollow" />Важно, что мета–тег robots работает, если есть доступ ботов к сканированию страниц, где мета тег прописан. То есть они не закрыты файлом
robots.txt.
В-третьих, можно создавать закрытые разделы сайта.
При составлении файла robots.txt полезно проверять правильность его составления. Для этого предлагаю посмотреть следующие инструменты проверки файла robots.txt.
Инструменты проверки файла robots.txt
Напомню, что в классическом варианте в файле robots.txt создаются отдельные директивы для агента пользователя Yandex (user-agent: yandex) и других поисковых ботов сети, включая Googleboot (user-agent: *).
Инструмент проверки №1
Google в возможностях Searh Console оставил инструмент проверки файла robots.txt. Вот ссылка на него: https://www.google.com/webmasters/tools/robots-testing-tool
Вот скрин:
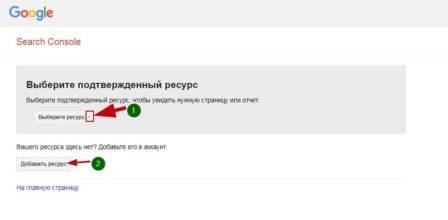
Для использования инструмента вам нужно зарегистрироваться инструментах веб–мастеров Google и добавить в них свой ресурс (сайт). Если вы всё это сделали, просто выберете сайт для проверки.
После выбора сайту откроется инструмент проверки файла robots.txt. Внизу читаем ошибки и предупреждения. Если их нет, то смотрим ещё ниже и видим сам инструмент проверки.
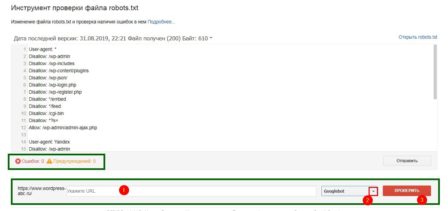
В форме проверки указываете проверяемый URL, выбираете бота Google (по умолчанию Googleboot) и жмёте кнопку «Проверить».
Результат проверки будет показан на этой же станице в виде зелёной надписи «Доступен» или красной надписи «Не доступен». Всё просто и понятно.

Инструмент проверки №2
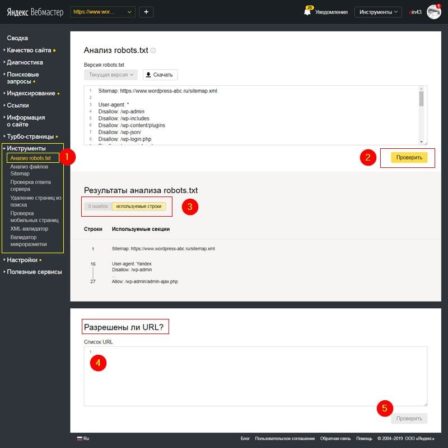
По логике составления файла robots.txt о которой я напомнил выше, такой же инструмент проверки должен быть в веб–инструментах Яндекс для ботов Yandex. Смотрим. Действительно, в вашем аккаунте Яндекс Веб–мастер выбираете заранее добавленный ресурс (свой сайт).
В меню «Инструменты» есть вкладка «Анализ robots.txt», где проверяется весь файл robots на ошибки и проверяются отдельные URL сайта на закрытие в файле robots.
Независимые инструменты проверки файла robots.txt
Встаёт логичный вопрос, можно ли проверить файл robots.txt и его работу независимо от инструментов веб мастеров? Наверняка можно.
Во-первых, чтобы просмотреть доступность своего файла robots впишите в браузер его адрес. Он должен открыться и нормально читаться. Проверку можно сделать в нескольких браузерах.
Адрес файла должен быть:
http(s)://ваш_домен/robots.txt
Во-вторых, используйте для проверки файла следующие инструменты:
Websiteplanet.com
https://www.websiteplanet.com/ru/webtools/robots-txt/
Дотошный инструмент, выявляет ошибки и предупреждения, которые не показывают сами боты.
Seositecheckup.com
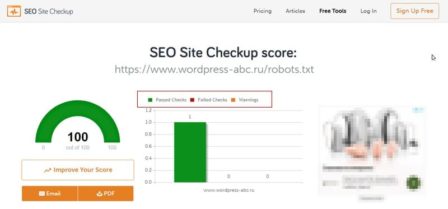
https://seositecheckup.com/tools/robotstxt-test
Англоязычный инструмент проверки файла robots.txt на ошибки. Регистрация не требуется. Хотя навязывается сервисом. Результаты в виде диаграммы.
Стоит отметить, что с июня сего года (2019) правила для составления файла robots.txt стали стандартом и распространяются на всех ботов. Так что выявленные ошибки для бота Google, будут ошибками и для бота Yandex.
Technicalseo.com
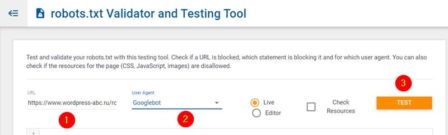
https://technicalseo.com/tools/robots-txt/
Протестируйте и подтвердите ваш robots.txt с помощью этого инструмента тестирования. Проверьте, заблокирован ли URL-адрес, какой оператор его блокирует и для какого агента пользователя. Вы также можете проверить, запрещены ли ресурсы для страницы (CSS, JavaScript, IMG).
en.ryte.com
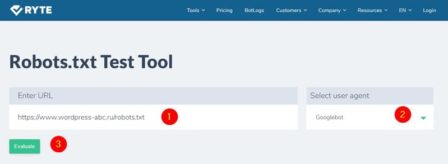
https://en.ryte.com/free-tools/robots-txt/
Просто вписывает адрес своего файла и делаете проверку. Показывает предупреждения по синтаксису файла.
Вывод про инструменты проверки файла robots.txt
По-моему, лучшие инструменты проверки файла robots.txt находятся в инструментах веб–мастеров. Они ближе к источнику и более чувствительны к изменениям правил.
Кстати, есть проверка файла robots.txt в инструментах веб–мастеров Mail поисковика (https://webmaster.mail.ru/) и была у поисковика Bing.
Еще статьи
Похожие посты:
Похожее
Проверка robots.txt на ошибки | Impuls-Web.ru
В одной из прошлых статей мы с вами подробно рассмотрели, как создать файл robots.txt на примере сайта созданного на WordPress.
В этой статье я хотела бы рассмотреть, как осуществить для robots.txt проверку в поисковых системах Яндекс и Google.
Навигация по статье:
Проверка в Яндекс
В яндексе для robots.txt проверка происходит следующим образом:
- 1.Заходим на сервис Яндекс.Вебмастер (https://webmaster.yandex.ru), проходим авторизацию и в верхней панели слева, в раскрывающемся списке, выбираем сайт для которого нужно провести проверку.
- 2.В левом боковом меню выбираем «Инструменты» = > «Анализ robots.txt»
- 3.Попадаем на страницу проверки robots.txt. Если вы не меняли стандартный файл, то увидите следующую картину:
- 4.Если вы еще не добавляли для своего сайта robots.txt, то вам нужно создать этот файл, следуя указаниям, приведенным в моей прошлой статье. После чего, при помощи FTP-клиента загрузить этот файл в корень вашего сайта:
- 5.После этого, в адресной строке «Проверяемый сайт», вводим адрес нашего сайта и нажимаем на кнопку загрузки.
- 6.Произойдет загрузка файла, расположенного по указанному нами адресу и автоматически будет проведена проверка файла на содержание ошибок. Содержимое файла будет показано в поле «Текст robots.txt»
Внизу, в табличке «Результаты анализа robots.txt», вы можете просмотреть количество ошибок в файле.
Проверка в Google
В Google Search Console для robots.txt проверка делается похожим образом:
- 1.Заходим на главную страницу сервиса Search Console (//www.google.com/webmasters/tools/dashboard), проходим авторизацию и переходим в раздел «Сканирование» => «Инструмент проверки файла robots.txt»
- 2.На следующей странице нам первым делом необходимо удостовериться в доступности файла для гуглбота. В нижней части страницы, в адресной строке вводим путь к нашему файлу robots.txt и нажимаем «Проверить».
- 3.Если все нормально, то красная кнопка замениться на надпись «Доступен».
- 4.Далее, нажимаем на кнопку «Отправить».
В открывшемся окне нужно нажить на нижнюю кнопку «Отправить»:
- 5.Закрываем окошко и через несколько минут обновляем страницу проверки:
Количество ошибок и предупреждений можно увидеть в нижней части окна.
Как видите, для robots.txt проверка проводится достаточно быстро. Если после проверки у вас найдут какие-то несоответствия, то нужно будет их исправить и повторить процедуру загрузки и проверки файла в той же последовательности.
А на этом у меня сегодня все. Надеюсь, моя статья будет для вас полезна. Думаю, у вас не должно возникнут каких-то сложностей в процессе создания и загрузки файла robots.txt, но если что – пишите мне через форму комментариев. Желаю вам успешной проверки! До встречи в следующих статьях!
С уважением Юлия Гусарь
Что такое robots.txt и какие инструменты для его проверки существуют?
Впервые о файле robots.txt (его еще называют индексным) услышали в 1994 году. За 26 лет его существования изменилось многое, кроме одного – большинство владельцев сайтов до сих пор ничего о нем не знают. Почему стоит познакомиться с robots.txt вашего сайта и как понять, что в него пора вносить правки. Давайте разбираться.
Файлы разные нужны, файлы разные важны
Robots.txt по праву можно назвать помощником поисковых роботов. Этот файл подсказываем им, какие разделы есть на сайте, какие страницы стоит посмотреть, а на какие заглядывать нет никакой необходимости. Именно в этом файле прописывается запрет индексации на технические страницы, дубли и страницы, которые вы по каким-то причинам не хотите показывать великим и ужасным Яндексу и Google. Содержимое индексного файла прописывается при помощи кодировки UTF-8. Использование другой кодировки может стать причиной неправильной обработки информации поисковыми роботами.
В рамках SEO файл robots.txt тщательно анализируют с помощью инструментов для его проверки. Почему это так важно? Потому что всего одна ошибка в содержимом этого помощника поисковых роботов может стоить вам бюджета продвижения. Заглянем внутрь этого файла и изучим его подробнее.
Из чего же, из чего же сделан robots.txt?
Чтобы изучить индексный файл своего сайта, откройте его. Для этого зайдите на главную страницу своего ресурса, в адресной строке после адреса сайта поставьте слэш, а затем введите название файла, который вам нужен (robots.txt). Загрузите страницу. Перед вами тот самый индексный файл. Первая часть нашего robots.txt выглядит вот так:
Ваш robots.txt сильно отличается? Не спешите расстраиваться.
Если напротив User-agent в вашем индексном файле прописан Googlebot или Yandex, значит правила задаются только для указанного робота. Звездочка, использованная в примере ниже, показывает, что правила действуют для всех поисковых роботов без исключения. Ошибки в этом правиле можно найти и без инструмента для проверки файла robots.txt.
Если на сайте нет страниц, закрытых от сканирования, robots.txt может выглядеть вот так:
Если сайт полностью закрыт от индексации, то запись будет отличаться всего на один символ:
Вроде мелочь, а для поисковых роботов совершенно другая картина. Если разработчик закрыл от индексации только часть контента (например, папку, отдельный URL или файл), это отображается напротив правила Disallow.
Тогда как предыдущее правило запрещает индексирование определенного контента, то это, наоборот, разрешает. Когда его использовать? Например, вы хотите показывать только те страницы, которые располагаются в разделе «Каталог». Все остальные страницы в таком случае закрываются от индексации с помощью правила Disallow.
Это правило используется для показа роботу главного зеркала сайта, которое нужно индексировать. Если сайт работает на HTTPS, протокол обязательно прописывается в индексном файле. Если на HTTP, название протокола можно опустить. Выяснить, верно ли прописано это правило на вашем сайте можно и не используя инструмент для проверки файла robots.txt. Достаточно найти строку со словом host и сравнить ее с образцом.
С помощью этого правила вы показываете поисковому роботу, где можно посмотреть все урлы вашего сайта, которые он должен проиндексировать. Чтобы их найти роботу придется прогуляться по адресу типа https://site.ua/sitemap.xml. Все это вписывается в индексный файл. У нас это сделано вот так:
Правило стоит использовать, если у вашего ресурса слабый сервер. Оно позволяет увеличивать длину промежутка загрузки страниц. Параметр по умолчанию измеряется в секундах.
Это правило призвано бороться с дублированием контента, связанным с динамическими параметрами. Из-за сортировок, разных
id сессий и других причин на сайте одна и та же страница может быть доступна по нескольким адресам. Чтобы поисковый робот не расценил такое явление как дублирование, его прописывают в robots.txt. Если страница отвечает по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1,
то правило выглядит следующим образом:
Прежде чем познакомиться с инструментами для проверки файла robots.txt рассмотрим символы, применяемыми в нем.
Не правилами едиными…
Чаще всего в robots.txt используются следующие символы:
Необходима для обозначения любой последовательности. Например, с ее помощью можно спрятать от робота все файлы с расширением gif, хранящиеся в папке catalog.
Ставится для обозначения местонахождения файла в корневом каталоге, а также при закрытии от индексации всего сайта.
Этот символ показывает, где перестает действовать звездочка. В примере на скриншоте мы закрываем от индексации содержимое папки каталог, но при этом урлы, в которых содержится элемент catalog, индексировать разрешено.
Используется значительно реже, чем все остальные символы, потому как нужна только для комментариев. После решетки можно написать любую подсказку, которая поможет в работе вам или веб-мастеру, работающему с сайтом.
Осваиваем инструменты для проверки файла robots.txt
В интернете можно найти добрую сотню сервисов, разбирающих по косточкам индексные файлы сайтов. Мы доверяем только тем, которые учитывают все изменения в алгоритмах поисковых роботов. А таких сервисов всего 2: Google Webmaster Tools и «Анализ robots.txt» от Яндекса. Покажем, как работать с каждым из них.
Чтобы начать пользоваться этим инструментом, нужно войти в свой Google-аккаунт, а потом открыть эту ссылку.
Если это ваше первое знакомство с Google Webmaster, придется добавить сайт и подтвердить свои права на него. Сделать это можно несколькими способами. Самый простой из них – закачка файлов.
После подтверждения прав на сайт вы получите полный доступ к инструменту для проверки файла robots.txt. Выберите этот сервис в панели меню, затем укажите, что хотите проанализировать индексный файл своего сайта. И получите результаты проверки. Выглядеть это будет примерно так:
Красным прямоугольником мы выделили строку, на которую вам нужно обратить свое внимание в первую очередь. Здесь показывается, есть ли ошибки в robots.txt. Если инструмент нашел ошибки, пролистайте содержимое файла с помощью бегунка и найдите значок белый крест в красном круге на полях. В тех строках, где есть такие значки, что-то написано неправильно. К сожалению, Google еще не научился сразу же говорить, что именно не так и предлагать исправления. Поэтому с ошибками придется разбираться самостоятельно. Или обращаться за советом к профессионалам.
Новая версия этого инструмента для проверки файла robots.txt дает возможность смотреть открыты ли для индексации новые страницы. Она также позволяет вносить изменения в индексный файл сразу же после нахождения ошибок. Для этого больше не нужно открывать robots.txt в отдельной вкладке. Еще одна фишка обновления – просмотр старых версий индексного файла. Вы можете посмотреть не только, что вы меняли, но и как на это реагировали роботы.
В связке с этим инструментом стоит использовать просмотр сайта глазами Googlebot. Используя эту функцию вы сможете проанализировать, понравится ли поисковому роботу ваш сайт или нет.
- «Анализ robots.txt»
С этим сервисом все проще, хотя бы потому что он приспособлен для русскоязычного пользователя. Прежде чем приступить к непосредственной работе с инструментом для проверки robots.txt, придется пройти те же этапы, что и с Google Webmaster Tools. Когда получите доступ к сервису, загляните в боковое меню и найдите в нем интересующий нас сервис.
На этой странице вы увидите результаты анализа индексного файла. Если в нем есть ошибки, их количество отобразится в нижней части страницы. В верхней части, где помещается robots.txt, можно будет подробно просмотреть ошибки и тут же исправить их.
В разделе «Анализ robots.txt» также можно узнать индексируются ли определенные страницы сайта или нет. Для этого урлы вносят в нижнее окно и отправляют на проверку.
Все не так просто, как кажется
Думали, что разберетесь с robots.txt за 5 минут и тут же внесете в него правки, но что-то пошло не так? Не расстраивайтесь. Специалисты Студии ЯЛ решат вашу проблему. Позвоните нам и мы дадим профессиональный совет. Ну а если вы не хотите разбираться с индексным файлом, поручите это нам. В рамках оптимизации и SEO-продвижения сотрудники Студии ЯЛ приведут в порядок ваш robots.txt и не только.
Алексей Радкевич
Директор Студии ЯЛ
Другие материалы:
Файл robots.txt | SEO-портал
Стандарт robots.txt отличается оригинальным синтаксисом. Существуют общие для всех роботов директивы (правила), а также директивы, понятные только роботам определенных поисковых систем.
Стандартные директивы
Директивами для robots.txt называются правила, состоящие из названия и значения (параметра), идущего после знака двоеточия. Например:
# Директива User-agent со значением Yandex: User-agent: Yandex
Регистр символов в названиях директив не учитывается.
Для большинства директив стандарта в качестве значения применяется URL-префикс (часть URL-адреса). Например:
User-agent: Yandex # URL-префикс в качестве значения: Disallow: /admin/
Регистр символов учитывается роботами при обработке URL-префиксов.
Директива User-agent
Правило User-agent указывает, для каких роботов составлены следующие под ним инструкции.
Значения User-agent
В качестве значения директивы User-agent указывается конкретный тип робота или символ *. Например:
# Последовательность инструкций для робота YandexBot: User-agent: YandexBot Disallow: /
Основные типы роботов, указываемые в User-agent:
- Yandex
- Подразумевает всех роботов Яндекса.
- YandexBot
- Основной индексирующий робот Яндекса
- YandexImages
- Робот Яндекса, индексирующий изображения.
- YandexMedia
- Робот Яндекса, индексирующий видео и другие мультимедийные данные.
- Подразумевает всех роботов Google.
- Googlebot
- Основной индексирующий робот Google.
- Googlebot-Image
- Робот Google, индексирующий изображения.
Регистр символов в значениях директивы User-agent не учитывается.
Обработка User-agent
Чтобы указать, что нижеперечисленные инструкции составлены для всех типов роботов, в качестве значения директивы User-agent применяется символ * (звездочка). Например:
# Последовательность инструкций для всех роботов: User-agent: * Disallow: /
Перед каждым последующим набором правил для определённых роботов, которые начинаются с директивы User-agent, следует вставлять пустую строку.
User-agent: * Disallow: / User-agent: Yandex Allow: /
При этом нельзя допускать наличия пустых строк между инструкциями для конкретных роботов, идущими после User-agent:
# Нужно: User-agent: * Disallow: /administrator/ Disallow: /files/ # Нельзя: User-agent: * Disallow: /administrator/ Disallow: /files/
Обязательно следует помнить, что при указании инструкций для конкретного робота, остальные инструкции будут им игнорироваться:
# Инструкции для робота YandexImages: User-agent: YandexImages Disallow: / Allow: /images/ # Инструкции для всех роботов Яндекса, кроме YandexImages User-agent: Yandex Disallow: /images/ # Инструкции для всех роботов, кроме роботов Яндекса User-agent: * Disallow:
Директива Disallow
Правило Disallow применяется для составления исключающих инструкций (запретов) для роботов. В качестве значения директивы указывается URL-префикс. Первый символ / (косая черта) задает начало относительного URL-адреса. Например:
# Запрет сканирования всего сайта: User-agent: * Disallow: / # Запрет сканирования конкретной директории: User-agent: * Disallow: /images/ # Запрет сканирования всех URL-адресов, начинающихся с /images: User-agent: * Disallow: /images
Применение директивы Disallow без значения равносильно отсутствию правила:
# Разрешение сканирования всего сайта: User-agent: * Disallow:
Директива Allow
Правило Allow разрешает доступ и применяется для добавления исключений по отношению к правилам Disallow. Например:
# Запрет сканирования директории, кроме одной её поддиректории: User-agent: * Disallow: /images/ # запрет сканирования директории Allow: /images/icons/ # добавление исключения из правила Disallow для поддиректории
При равных значениях приоритет имеет директива Allow:
User-agent: * Disallow: /images/ # запрет доступа Allow: /images/ # отмена запрета
Директива Sitemap
Добавить ссылку на файл Sitemap в можно с помощью одноименной директивы.
В качестве значения директивы Sitemap в указывается прямой (с указанием протокола) URL-адрес карты сайта:
User-agent: * Disallow: # Директив Sitemap может быть несколько: Sitemap: https://seoportal.net/sitemap-1.xml Sitemap: https://seoportal.net/sitemap-2.xml
Директива Sitemap является межсекционной и может размещаться в любом месте файла. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
Следует учитывать, что файл robots.txt является общедоступным, и благодаря директиве Sitemap злоумышленники могут получить доступ к новым страницам раньше поисковых роботов, что может повлечь за собой воровство контента.
Использование директивы Sitemap в robots.txt может повлечь воровство контента сайта.
Регулярные выражения
В файле robots.txt могут применяться специальные регулярные выражения в URL-префиксах с помощью символов * и $.
Символ /
Символ / (косая черта) является разделителем URL-префиксов, отражая степень вложенности страниц. Важно понимать, что URL-префикс с символом / на конце и аналогичный префикс, но без косой черты, поисковые роботы могут воспринимать как разные страницы:
# разные запреты: Disallow: /catalog/ # запрет для вложенных URL (/catalog/1), но не для /catalog Disallow: /catalog # запрет для /catalog и всех URL, начинающихся с /catalog, в том числе: # /catalog1 # /catalog1 # /catalog1/2
Символ *
Символ * (звездочка) предполагает любую последовательность символов. Он неявно приписывается к концу каждого URL-префикса директив Disallow и Allow:
User-agent: Googlebot Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/* # то же самое
Символ * может применяться в любом месте URL-префикса:
User-agent: Googlebot Disallow: /*catalog/ # запрещает все URL-адреса, содержащие "/catalog/": # /1catalog/ # /necatalog/1 # images/catalog/1 # /catalog/page.htm # и др. # но не /catalog
Символ $
Символ $ (знак доллара) применяется для отмены неявного символа * в окончаниях URL-префиксов:
User-agent: Google Disallow: /*catalog/$ # запрещает все URL-адреса, заканчивающиеся символами "catalog/": # /1/catalog/ # но не: # /necatalog/1 # /necatalog # /catalog
Символ $ (доллар) не отменяет явный символ * в окончаниях URL-префиксов:
User-agent: Googlebot Disallow: /catalog/* # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/*$ # то же самое # Но: Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/$ # запрет только URL-адреса "/catalog/"
Директивы Яндекса
Роботы Яндекса способны понимать три специальных директивы:
- Host (устарела),
- Crawl-delay,
- Clean-param.
Директива Host
Директива Host является устаревшей и в настоящее время не учитывается. Вместо неё необходимо настраивать редирект на страницы главного зеркала.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Яндекс.Помощь
Правило Crawl-delay следует размещать в группу правил, которая начинается с директивы User-Agent, но после стандартных для всех роботов директив Disallow и Allow:
User-agent: * Disallow: Crawl-delay: 1 # задержка между посещениями страниц 1 секунда
В качестве значений Crawl-delay могут использоваться дробные числа:
User-agent: * Disallow: Crawl-delay: 2.5 # задержка между посещениями страниц 2.5 секунд
Директива Clean-param
Директива Clean-param помогает роботу Яндекса верно определить страницу для индексации, URL-адрес которой может содержать различные параметры, не влияющие на смысловое содержание страницы.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Яндекс.Помощь
В качестве значения правила Clean-param указывается параметр и URL-префикс адресов, для которых не следует учитывать данный параметр. Параметр и URL-префикс должны быть разделены пробелом:
User-agent: * Disallow: # Указывает на отсутствие значимости параметра id в URL-адресе с index.htm # (например, в адресе seoportal.net/index.htm?id=1 параметр id не станет учитываться, # а в индекс, вероятно, попадёт страница с URL-адресом seoportal.net/index.htm): Clean-param: id index.htm
Для указания 2-х и более незначительных параметров в одном правиле Clean-param применяется символ &:
User-agent: * Disallow: # Указывает на отсутствие значимости параметров id и num в URL-адресе с index.htm Clean-param: id&num index.htm
Директива Clean-param может быть указана в любом месте файла robots.txt. Все указанные правила Clean-param будут учтены роботом Яндекса:
User-agent: * Allow: / # Для разных страниц с одинаковыми параметрами в URL-адресах: Clean-param: id index Clean-param: id admin
Анализ файлов robots.txt крупнейших сайтов / Хабр
Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру.
По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
Найдено в yangteacher.ru/robots.txt
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php
(Предупреждение: Краулинг Facebook запрещён без письменного разрешения. См. http://www.facebook.com/apps/site_scraping_tos_terms.php)
Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
Как посмотреть robots.txt сайта, который вам интересен?

От автора: хотите составить для своего проекта файл с указаниями для робота, но не знаете как? Сегодня разберемся, как посмотреть robots.txt сайта и изменить его под свои нужды.
В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Итак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:
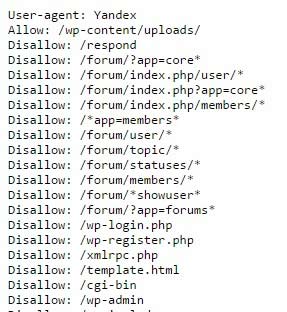
В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content
Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ |
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Все вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
Disallow: /wp-feed
Disallow: */trackback
Disallow: */feed
Disallow: /tag/
Disallow: /archive/
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/ |
Это лишь некоторые из дублей, создаваемых wordpress. Могу сказать, что так можно делать, но защиты на 100% ожидать не стоит. Я бы даже сказал, что вообще не нужно ее ожидать и проблема как раз в том, о чем я уже говорил ранее:
Поисковые системы все равно могут забрать в индекс такие вещи.
Тут уже нужно бороться по-другому. Например, с помощью редиректов или плагинов, которые будут уничтожать дубли. Впрочем, это уже тема для отдельной статьи.
Где находится robots.txt?
Этот файл всегда находится в корне сайта, поэтому мы и можем обратиться к нему, прописав адрес сайта и название файла через слэш. По-моему, тут все максимально просто.
В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. О настройке я также напишу еще 1-2 статьи в ближайшее время, потому что в этой статье мы рассмотрели не все. Кстати, также много информации по продвижению сайтов-блогов вы можете найти в нашем курсе. А я на этом пока прощаюсь с вами.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее 
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотреть
Инструмент проверки и тестирования Robots.txt
Файл robots.txt
Файл robots.txt — это простой текстовый файл, используемый для информирования робота Googlebot о тех областях домена, которые могут сканироваться сканером поисковой системы, и тех, которые не могут. Кроме того, ссылку на карту сайта XML также можно включить в файл robots.txt. Прежде чем бот поисковой системы начнет индексировать , он сначала ищет в корневом каталоге файл robots.txt и считывает указанные там спецификации.Для этого текстовый файл необходимо сохранить в корневом каталоге домена и присвоить ему имя: robots.txt .
Файл robots.txt можно просто создать с помощью текстового редактора. Каждый файл состоит из двух блоков. Сначала указывается пользовательский агент, к которому должна применяться инструкция, затем следует команда «Disallow», после которой перечисляются URL-адреса, которые необходимо исключить из сканирования. Пользователь должен всегда проверять правильность файла robots.txt перед его загрузкой в корневой каталог веб-сайта.Даже малейшая ошибка может привести к тому, что бот проигнорирует спецификации и, возможно, включит страницы, которые не должны отображаться в индексе поисковой системы.
Этот бесплатный инструмент от Ryte позволяет протестировать файл robots.txt. Вам нужно только ввести соответствующий URL-адрес и выбрать соответствующий пользовательский агент. При нажатии на «Начать тест» инструмент проверяет, разрешено ли сканирование по указанному вами URL. Вы также можете использовать Ryte FREE для проверки множества других факторов на вашем сайте! Вы можете анализировать и оптимизировать до 100 URL-адресов с помощью Ryte FREE.Просто нажмите здесь, чтобы получить БЕСПЛАТНУЮ учетную запись »
Самая простая структура файла robots.txt выглядит следующим образом:
Пользовательский агент: * Disallow:
Этот код дает роботу Googlebot разрешение сканировать все страницы. Чтобы бот не сканировал весь веб-сайт, вы должны добавить в файл robots.txt следующее:
Пользовательский агент: * Disallow: /
Пример: Если вы хотите запретить сканирование каталога / info / роботом Googlebot, вы должны ввести следующую команду в файле robots.txt файл:
Пользовательский агент: Googlebot Disallow: / info /
Более подробную информацию о файле robots.txt можно найти здесь:
.
Анализатор Robots.txt
Инструменты SEO
Инструменты, которые помогут вам создать и продвигать свой веб-сайт.
Расширения Firefox
Веб-инструменты
Если вам нужна обратная связь или у вас есть какие-либо животрепещущие вопросы, задавайте их на форуме сообщества, чтобы мы могли их решить.
Обзор
Обзор содержания сайта.Включает карту сайта, глоссарий и контрольный список для быстрого старта.
SEO
Содержит информацию о ключевых словах, SEO на странице, построении ссылок и социальном взаимодействии.
КПП
Советы по покупке трафика в поисковых системах.
Отслеживание
Узнайте, как отслеживать свой успех с помощью обычных объявлений SEO и PPC. Включает информацию о веб-аналитике.
Доверие
Создание заслуживающего доверия веб-сайта — это основа того, чтобы быть достойным ссылок и продавать клиентам.
Монетизация
Узнайте, как зарабатывать деньги на своих веб-сайтах.
Аудио и видео
Ссылки на полезную аудио и видео информацию. Мы будем создавать новые SEO-видео каждый месяц.
Интервью
Эксклюзивные интервью только для участников.
Скидки
купонов и предложений, которые помогут вам сэкономить деньги на продвижении ваших сайтов.
Карта сайта
Просмотрите все наши учебные модули, на которые есть ссылки на одной странице.
Введите URL вашего robots.txt
или вставьте его содержимое сюда
Связанная информация о файле Robots.txt
Получите конкурентное преимущество сегодня
Ваши ведущие конкуренты годами инвестируют в свою маркетинговую стратегию.
Теперь вы можете точно знать, где они ранжируются, выбирать лучшие ключевые слова и отслеживать новые возможности по мере их появления.
Изучите рейтинг своих конкурентов в Google и Bing сегодня с помощью SEMrush.
Введите конкурирующий URL-адрес ниже, чтобы быстро получить доступ к их истории эффективности обычного и платного поиска — бесплатно.
Посмотрите, где они занимают место, и побейте их!
- Исчерпывающие данные о конкурентах: исследований эффективности в обычном поиске, AdWords, объявлениях Bing, видео, медийной рекламе и многом другом.
- Сравните по каналам: используйте чью-то стратегию AdWords, чтобы стимулировать рост вашего SEO, или используйте их стратегию SEO, чтобы инвестировать в платный поиск.
- Глобальный охват: Отслеживает результаты Google по более чем 120 миллионам ключевых слов на многих языках на 28 рынках.
- Исторические данные о производительности: восходит к прошлому десятилетию, до того, как существовали Panda и Penguin, поэтому вы можете искать исторические штрафы и другие потенциальные проблемы с рейтингом.
- Без риска: Бесплатная пробная версия и низкая ежемесячная плата.
Ваши конкуренты, исследуют ваш сайт
Найдите новые возможности сегодня
.
Добавить комментарий