
Как запретить индексацию страницы с помощью robots.txt?

От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
User-agent: *
Disallow: /kontakty/
Disallow: /about/
Disallow: /uslugi/
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/ |

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Естественно, указываем настоящие url-адреса. Если же вам необходимо не индексировать страничку http://blog.ru/about-me, то в robots.txt нужно прописать так:
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
<meta name = «robots» content = «noindex,nofollow»>
<meta name = «robots» content = «noindex,nofollow»> |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.
Запрещается использовать более двух значений. Например:
<meta name = «robots» content = «noindex,nofollow, follow»>
<meta name = «robots» content = «noindex,nofollow, follow»> |
И любые другие. В этом случае мы видим противоречие.
Итог
Наиболее удобным способом закрытия страницы для поискового робота я вижу использование мета-тега. В таком случае вам не нужно будет постоянно, сотни раз редактировать файл robots.txt, чтобы открыть или закрыть очередной url, а это решение принимается непосредственно при создании новых страниц.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее 
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотреть
Как закрыть сайт от индексации разными способами: инструкция
Доброго дня, дорогие читатели блога iklife.ru.
В этой статье я расскажу о том, как закрыть сайт от индексации с помощью самых разных способов. Индексация – это процесс занесения информации вашего ресурса в базы поисковых систем. При этом поисковые роботы могут заносить абсолютно любую информацию вашего проекта. Даже ту, что не нужно. Подобное особенно часто встречается в случаях, когда сам сайт только создан, и какой-то полезной информации там еще нет.
Естественно, ПС все равно могут начать индексацию, что в дальнейшем может создать некоторые проблемы с SEO-продвижением. Сегодня мы разберем наиболее популярные способы сокрытия проекта от взора поисковых роботов. Давайте начинать!
Что такое индексация
Индексация – это процесс, который подразумевает считывание всей информации вашего ресурса для дальнейшего занесения ее в базы ПС. Иными словами, это когда поисковики анализируют ваш сайт, чтобы потом выдавать его пользователям в поисковой выдаче. В процессе индексации учитывается абсолютно все: начиная от дизайна и заканчивая количеством текста в статьях.
В процессе индексации сайта ПС могут делать для себя определенные пометки. Например, если вы начнете размещать на своем веб-ресурсе копипаст, то ваш сайт может попасть под фильтр. В таком случае он больше не будет участвовать в поисковом ранжировании на равных условиях с другими проектами. Поисковик будет просто занижать ресурс в позициях либо вовсе уберет его из результатов.
То же касается и каких-то других аспектов SEO-продвижения. Во время индексации поисковые роботы анализируют все показатели, чтобы определить качество сайта и возможность размещения страниц по каким-то определенным запросам. Если на проекте отсутствует информация (статьи и страницы), то разместить его где-то либо не представляется возможным.
Такой веб-ресурс будет доступен только по прямому обращению с использованием специальных регулярных выражений. В общих результатах его не встретить.
Роботы ПС начинают индексацию всех открытых сайтов сразу же после их создания. Вы даже можете не добавлять свой проект в Яндекс.Вебмастер и Google Search Console, но роботы все равно придут на ваш ресурс и начнут аудит всей доступной информации. Если вы только что создали свой проект, естественно, вам подобная индексация не нужна. Например, очень часто при создании проектов люди пользуются шаблонами.
Чтобы лучше настроить внешний вид ресурса, они загружают специальные демо-конфигурации, которые в автоматическом режиме создают тестовые варианты статей. Это, как правило, копипастные материалы, которые нужны только для того, чтобы тема оформления выглядела должным образом. Согласитесь, настраивать шаблон намного проще, если ты сразу видишь, как это все будет выглядеть в конечном итоге. Когда ресурс пустой, настроить шаблон должным образом бывает очень сложно.
Это особенно актуально для проектов на WordPress, потому как тема на заполненном проекте и тема на пустом выглядят совершенно по-разному. Пользователи выгружают демо-контент, чтобы настроить внешний вид, и в случае, если проект не был закрыт от ПС, эти самые страницы с демо-контентом могут попасть в поисковую выдачу.
Естественно, они будут на самых последних страницах, но тем не менее это будет создавать негативный эффект для SEO-продвижения. По сути, это можно рассматривать как попадание мусорных страниц и документов в ПС. Потом вам придется удалять их все, на что может потребоваться определенное время.
Видимого негативного эффекта от этого, конечно, быть не должно. Однако некоторые трудности возникнут. Ваш веб-ресурс не будет классифицироваться как полностью уникальный, и в некоторых случаях поисковые роботы будут занижать позиции уже настоящих статей в выдаче. Даже после удаления всех этих демо-материалов эффект может держаться еще какое-то время.
Именно поэтому при начальной разработке проекта лучше закрыть его от индексации и открывать уже только после того, как он будет полностью готов. Причем это касается не только демо-контента, но и, вообще, любой разработки – дизайна, скорости загрузки и т. д. Если что-то на ресурсе не работает должным образом, лучше это на время скрыть от глаз пользователей и ПС.
Помимо закрытия на этапе разработки, есть и другие причины для того, чтобы исключить свой проект из поисковой выдачи. К примеру, это может понадобиться специализированным ресурсам, материалы которых не должны быть в общем доступе. Обычно это какие-то специальные закрытые проекты, информация на которых предназначена для ограниченного количества людей.
Естественно, если поисковые системы начнут считывать информацию с таких проектов, то ни о какой приватности речь идти не будет. Все данные будут доступны для изучения с помощью различных сервисов. Сами ПС сохраняют слепки сайтов, поэтому, даже если владельцы проекта решат удалить информацию, которая по ошибке попала в поисковик, где-то может остаться сохраненная копия.
Также закрытие проекта от индексации актуально для внутренних ресурсов различных компаний, которые создают такие сайты для своих сотрудников. Это могут быть специальные панели управления, страницы с расписанием и т. д.
В общем, причин для закрытия проекта от поисковых систем очень много. Да и способов реализации этого тоже.
Закрываем сайт от поисковиков разными способами
Способов скрыть свой сайт от взгляда поисковиков очень много. Например, в WordPress для этого есть специальная галочка, которая автоматически проставляет специальный тег на всех страницах проекта. Подобный функционал есть и в некоторых других платформах. Достаточно просто перейти в панель управления, найти нужный параметр и активировать его. Также есть и более универсальные способы, которые будут работать на большинстве известных CMS. Даже на самописных или HTML-сайтах подобные способы будут работать. О них я и расскажу далее.
В WordPress
Для скрытия ресурса от ПС вам достаточно активировать настройку, которая отвечает за видимость для роботов ПС. Перейдите в панель управления, наведите курсор на пункт “Настройки” и выберите там подпункт “Чтение”. Откроется страница, где самой последней опцией будет нужная нам галочка.
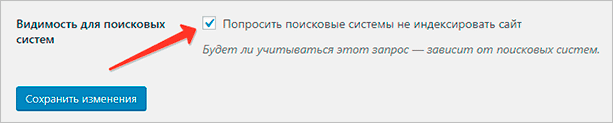
Активируйте чекбокс с галочкой, после чего кликните на кнопку “Сохранить изменения”. Отныне ваш ресурс не будет индексироваться поисковыми системами. WordPress проставит на всех страницах ресурса специальные теги, которые сообщают, что данный материал не должен участвовать в поисковом ранжировании.

При этом даже в самих настройках сообщается, что далеко не всегда поисковые системы следуют этому запросу. Яндекс и Google, скорее всего, последуют, а вот менее популярные ПС могут проиндексировать ваш ресурс несмотря на все усилия.
В любой момент вы можете вернуться в настройки и отключить эту галочку. Тогда метатег автоматически уберется со всех страниц, и вы сможете отправить их на переобход с помощью Яндекс.Вебмастера или Google Search Console.
Помимо полного закрытия ресурса, вы можете делать то же самое, но только с нужными статьями или страницами. Для этого вам необходимо будет установить плагин для поисковой оптимизации Yoast SEO или любое аналогичное расширение. В рамках этой статьи я рассмотрю именно Yoast SEO.
Чтобы закрыть нужную страницу или статью, вы должны открыть редактор в панели управления, после чего прокрутить страницу вниз. Вплоть до сниппета с Yoast SEO, где расположено окно с title, описанием и ключевым словом для вашего материала.
Перейдите во вкладку “Дополнительно” (значок шестеренки), после чего выберите пункт “Нет” в раскрывающемся меню “Разрешить поисковым системам показывать Запись в результатах поиска?”
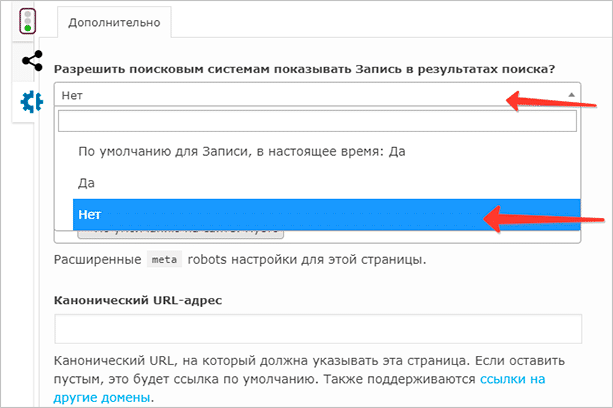
Здесь же вы можете указать и другие настройки. Например, расширить метатег robots для этой конкретной страницы. Однако новичкам вряд ли потребуются эти функции. Достаточно будет выбрать соответствующий пункт в настройках записи, после чего сохранить изменения с помощью нужной кнопки.
Это можно сделать с любой записью и страницей. Также это можно сделать с метками (тегами) и другими кастомными таксономиями.
Чтобы закрыть полностью все страницы или полностью все записи, вы также можете воспользоваться параметрами плагина Yoast SEO. Просто перейдите в меню “SEO” – “Отображение в поисковой выдаче”. Откроется страница, где в верхнем меню необходимо выбрать пункт “Типы содержимого”. Там будут указаны все таксономии вашего ресурса.
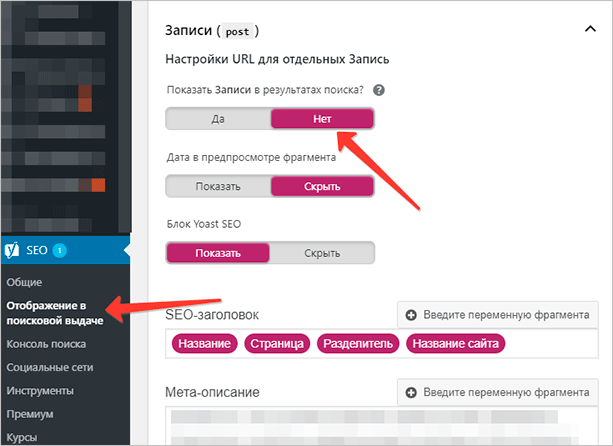
К каждой таксономии будет свой набор настроек, который, как правило, имеет один шаблон. Вам необходимо перейти к нужной таксономии (например, к записям), развернуть содержимое вкладки и выбрать “Нет” в пункте “Показать Записи в результатах поиска?” После этого вам нужно просто сохранить настройки.
На всех записях автоматически проставится метатег robots, который будет сообщать поисковикам, что именно эти документы индексировать не нужно. В то же время другие таксономии и страницы будут доступны для индексации.
То же самое вы можете сделать и со страницами, и с архивами, и с метками. Нужно просто перейти к нужному пункту, изменить эту настройку, после чего сохранить изменения.
Запрет через robots.txt
Закрыть ресурс от взгляда ПС можно с помощью самого стандартного способа – через robots.txt, который есть практически на каждом проекте. Данный файл имеет очень большое значение для поисковиков, потому что именно в нем описываются все правила для роботов. Если этого файла нет, ПС классифицируют подобное как ошибку.
Для закрытия всего проекта вам необходимо стереть все нынешнее содержимое файла, после чего добавить туда следующие строки.
User-agent: *
Disallow: /
Эти правила будут закрывать ваш сайт от всех ПС. При желании вы можете закрыть ресурс только от одного поисковика. Для этого вместо звездочки необходимо указать название робота.
Например, чтобы скрыть проект конкретно от Google, вам нужно использовать такой код.
User-agent: Googlebot
Disallow: /
Также вместо Googlebot можно прописать “Yandex”, тогда ваш ресурс будет скрыт только от Яндекса.
Чтобы скрыть конкретную папку или страницу, вы должны указать ее в файле, используя директиву “Disallow”.
К примеру, вы хотите закрыть страницу /blog/ от всех ПС. Остальные материалы по вашему замыслу должны индексироваться. Для этого вы должны использовать следующие строчки в robots.txt.
User-agent: *
Disallow: /blog/
Проверить правильность использования robots.txt вы можете в панелях управления для вебмастеров. Подобные инструменты есть и в Яндексе, и в Google.
Кстати говоря, использование правильного файла robots.txt – залог успешного SEO-продвижения. О том, как создать правильный robots.txt для WordPress и Joomla я рассказывал в отдельном материале. Рекомендую ознакомиться.
Через метатег robots
Этот способ очень похож на самый первый, где я рассказывал, как закрыть ресурс от индексации в WordPress через настройки и плагин. Только в этом случае вам придется добавлять нужный метатег в код самостоятельно без всяких интерфейсов и т. д.
Во все страницы, которые вы хотите закрыть от ПС, нужно добавить следующий тег.
<meta name=”robots” content=”noindex, nofollow”/>
В WordPress это можно сделать при помощи редактора тем, который расположен в меню “Внешний вид”. Просто перейдите в панель управления, найдите там нужный пункт, наведите на него курсор и выберите “Редактор тем”.
Далее, вам нужно будет выбрать файл заголовка (header.php), который используется почти на всех страницах проекта. Туда-то и нужно вставить данный метатег.
Сразу скажу, что ручное размещение тега именно на WordPress неоправданно. Зачем это делать, если есть настройки, которые могут помочь реализовать все в более упрощенном варианте.
Такой способ больше подойдет для самописных сайтов или ресурсов, которые используют какие-то сторонние платформы, где нет возможности так просто активировать данный метатег в настройках.
Через htaccess
С помощью этого файла можно закрыть ресурс от индексации. Сделать это можно при помощи таких строчек.
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
SetEnvIfNoCase User-Agent «^Mail» search_bot
SetEnvIfNoCase User-Agent «^BlogPulseLive» search_bot
SetEnvIfNoCase User-Agent «^php» search_bot
SetEnvIfNoCase User-Agent «^Parser» search_bot
SetEnvIfNoCase User-Agent «^spider» search_bot
SetEnvIfNoCase User-Agent «^igdeSpyder» search_bot
SetEnvIfNoCase User-Agent «^Snapbot» search_bot
SetEnvIfNoCase User-Agent «^Yahoo» search_bot
SetEnvIfNoCase User-Agent «^Aport» search_bot
SetEnvIfNoCase User-Agent «^Robot» search_bot
SetEnvIfNoCase User-Agent «^msnbot» search_bot
SetEnvIfNoCase User-Agent «^WordPress» search_bot
SetEnvIfNoCase User-Agent «^bot» search_bot
Нужно добавить их в файл. Эти правила закроют ваш проект от всех известных ПС.
Заключение
Как видите, способов закрытия проекта от ПС очень много. Я рассмотрел наиболее популярные и действенные варианты. Надеюсь, что этот материал поможет вам в решении ваших проблем. Все на самом деле очень просто, особенно если вы используете WordPress или аналогичную платформу. Достаточно просто активировать настройку, и проект будет закрыт.
Также можно воспользоваться универсальным способом и закрыть ресурс через robots.txt. Таким вариантом пользуется абсолютное большинство вебмастеров, и никаких нареканий у них не возникает. В любой удобный момент можно просто изменить содержимое файла и отправить сайт на переиндексацию.
Если вы новичок в мире вебмастеринга и хотите начать зарабатывать на собственном блоге или информационном сайте, я советую вам ознакомиться с курсом Василия Блинова – автора и создателя iklife.ru. В этом курсе собрана вся необходимая и полезная информация по разработке сайтов, монетизации, SEO-продвижению и другим полезным сферам. На лендинге по ссылке выше вы сможете найти все необходимые подробности.
Как закрыть сайт от индексации?
Приветствую вас, посетители сайта Impuls-Web!
Когда вы только приступили к созданию сайта и не хотите, что бы поисковые системы индексировали его до завершения работ, вы может закрыть сайт от индексации в поисковых системах.
Навигация по статье:
Так же такая необходимость может возникнуть для тестового сайта, или для сайта, который предназначен для закрытого пользования определенной группой лиц, и вам не нужно, чтобы внутренние ссылки попали в выдачу поисковиков.
Я хочу вам сегодня показать несколько достаточно простых способов, как можно закрыть сайт от индексации.
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
- 2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:
- 3.Сохраняем изменения.
Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:
Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)
Как закрыть сайт от индексации name=»robots»?
Данный способ заключается в самостоятельном добавлении записи, показанной на предыдущем скриншоте. Данный вариант подойдет для тех сайтов, которые создаются без использования CMS.
Вам всего лишь нужно в начале каждой страницы, перед закрытием тега </head> добавить эту запись:
<meta name=’robots’ content=’noindex,follow’ />
<meta name=’robots’ content=’noindex,follow’ /> |
В поле content можно задать следующие условия:
Запрещающие условия:
- none – запрет для страниц и ссылок;
- noindex – запрет для страниц;
- nofollow – запрещает индексацию ссылок на странице;
Разрещающие условия:
- all – разрешает индексацию страниц и ссылок;
- index — разрешает индексацию страниц;
- follow – разрешает индексацию ссылок на странице;
Зная данный набор условий, мы можем составить альтернативную запись для полного запрета для сайта и ссылок на нем. Выглядеть она будет вот так:
<meta name=’robots’ content=’none’ />
<meta name=’robots’ content=’none’ /> |
Как закрыть сайт от индексации в robots.txt?
Показанные выше варианты закрытия сайта от индексации работают для всех поисковиков, а это бывает не всегда нужно. Так же, предыдущий способ достаточно неудобен в случае, если ваш ресурс состоит из большого количества страниц, и каждую из них нужно закрыть от индексации.
В этом случае лучше воспользоваться еще одним способом закрытия сайта от индексации. Данный вариант дает нам возможность более гибко закрывать от индексации не только сайт в целом, но и отдельные страницы, медиафайлы и папки.
Для полного закрытия от индексации вам нужно создать в редакторе кода NotePad++ файл с названием robots.txt и разместить в нем такую запись:
User-agent: *
Disallow: /
User-agent со значением * означает, что данное правило предназначено для всех поисковых роботов. Так же вы можете запретить индексацию для какой-то поисковой системы в отдельности. Для этого в User-agent указываем имя конкретного поискового робота. Например:
В этом случае запись будет работать только для Яндекса.
Обратите внимание. В строке User-agent может быть указан только один поисковый робот, и соответственно директивы Disallow, указанные ниже будут работать только для него. Если вам нужно запретить от индексацию в нескольких ПС, то вам нужно это сделать по отдельность для каждой. Например:
User-agent: Googlebot
Disallow: /
User-agent: Yandex
Disallow: /
User-agent: Googlebot Disallow: /
User-agent: Yandex Disallow: / |
Так же, директива Disallow позволяет закрывать отдельные элементы. Данная директива указывается отдельно для каждого закрываемого элемента. Например:
User-agent: Yandex
Disallow: *.jpg
Disallow: /about-us.php
User-agent: Yandex Disallow: *.jpg Disallow: /about-us.php |
Здесь для поискового робота Yandex закрыты для индексации все изображение с расширением .jpg и страница /about-us.php.
Каждый из показанных приемов удобен по своему в зависимости от сложившейся ситуации. Надеюсь у меня получилось достаточно подробно рассказать вам о способах закрытия сайта от индексации, и данный вопрос у вас не вызовет трудностей в будущем.
Если данная информация была для вас полезно, обязательно оставьте свой комментарий под статьей и поделитесь ею в социальных сетях.
Желаю вам успехов в создании сайтов. До встречи в следующих статьях!
С уважением Юлия Гусарь
Настройка robots.txt – как узнать, какие страницы необходимо закрывать от индексации
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
- User-agent:*
- User-agent: Yandex
- User-agent: Googlebot
- User-agent: Bingbot
- User-agent: YandexImages
- User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:
*Примечание для User agent: Yandex
-
Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.
-
Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
-
Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
- Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
- Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».
Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации. Более подробно о том, как устранить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте», вы читайте в нашем блоге.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.
В следующем окне нажимаем «Изучить просканированную страницу».
Далее нажимаем ресурсы страницы
В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.
Если же такие ресурсы будут, вы увидите сообщения следующего вида:
Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
- Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
- Админ панель ресурса.
- Страницы сортировок, страницы вида отображения информации на сайте.
- Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
- Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить. Если вы не знаете, как это сделать, обращайтесь к нам за помощью.
Как закрыть от индексации сайт, ссылку, страницу, в robots ?
Далеко не всегда нужно, чтобы поисковые системы индексировали всю информацию на сайте.
Иногда, вебмастерам даже нужно полностью закрыть сайт от индексации, но новички не знают, как это сделать. При желании, можно скрыть от поисковиков любой контент, ресурс или его отдельные страницы.
Как закрыть от индексации сайт, ссылку, страницу? Есть несколько простых функций, которые вы сможете использовать, для закрытия любой информации от Яндекса и Гугла. В этой статье мы подскажем, как закрыть сайт от индексации через robots, и покажем, какой код нужно добавить в этот файл.

Закрываем от индексации поисковиков
Перед тем как рассказать о способе с применением robots.txt, мы покажем, как на WordPress закрыть от индексации сайт через админку. В настройках (раздел чтение), есть удобная функция:

Можно убрать видимость сайта, но обратите внимание на подсказку. В ней говорится, что поисковые системы всё же могут индексировать ресурс, поэтому лучше воспользоваться проверенным способом и добавить нужный код в robots.txt.
Текстовый файл robots находится в корне сайта, а если его там нет, создайте его через блокнот.
Закрыть сайт от индексации поможет следующий код:
User-agent: *
Disallow: /
Просто добавьте его на первую строчку (замените уже имеющиеся строчки). Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Если не можете использовать этот способ, просто добавьте в код сайта строчку <meta name=»robots» content=»noindex,follow» />.
Когда проделаете эти действия, сайт больше не будет индексироваться, это самый лучший способ для закрытия ресурса от поисковых роботов.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.

К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно:
— Скорость сайта – важный фактор
— Почему Яндекс не индексирует сайт?
— Оригинальные тексты для защиты от Yandex
Правильный файл robots.txt для сайта
Директивы Разрешить и запретить из соответствующего блока User-agent сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в данном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Карта сайта
Если вы используете файлы структуры сайта с помощью карты сайта, укажите путь к файлу в качестве директивы карта сайта (если файлов несколько, укажите все). Пример:
Пользовательский агент: Яндекс. Позволять: / карта сайта: https://example.com/site_structure/my_sitemaps1.xml карта сайта: https: // example.com / site_structure / my_sitemaps2.xml
Директива является межсекционной, поэтому будет роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессии загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запрос робота, воспользуйтесь директивой Crawl-delay.Она позволяет задать поисковому роботу минимальный период времени (в секунду) между окончанием одной страницы и началом следующей.
Перед тем, как изменить скорость обхода сайта.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот использует к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота. Директива
Clean-param
Директива работает только с роботом Яндекса.
. Если адреса сайта содержат динамические параметры, которые не влияют на их содержимое (данные сессий, пользователей, рефереров и т. П.), Вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующую информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123 Параметр ref используется только для того, чтобы отследить с каким ресурсом был сделан запрос и не меняет содержимое, по всем трем адресам будет наша одна и та же страница с книгой book_id = 123.Тогда, если указать директиву следующим образом:
Пользовательский агент: Яндекс
Запретить:
Clean-param: ref /some_dir/get_book.pl робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123 Если на сайте такая страница , именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0 [& p1 & p2 & .. & pn] [path] В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать.Во втором поле указывается префикс пути страниц, для применения правила.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9 .- / * _. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc / forum / showthread.php
Clean-param: sid и сортировка /forum/*.php
Clean-param: someTrash & otherTrash Директива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, структуры и ряда других факторов. Специально для этого предназначен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой результат появляется в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: / cgi-bin # папка на хостинге Запретить: /? # все параметры запроса на главной Disallow: / wp- # все файлы WP: / wp-json /, / wp-includes, / wp-content / plugins Disallow: / wp / # если есть подкаталог / wp /, где установлена CMS (если нет, # правило можно удалить) Запретить: *? S = # поиск Запретить: * & s = # поиск Запретить: / search / # поиск Disallow: / author / # архив автора Disallow: / users / # архив авторов Disallow: * / trackback # трекбеки, комментарии в комментариях о появлении открытой # ссылки на статью Disallow: * / feed # все фиды Disallow: * / rss # rss фид Disallow: * / embed # все встраивания Запретить: * / wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используется, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: * utm * = # ссылки с utm-метками Disallow: * openstat = # ссылки с метками openstat Разрешить: * / uploads # открываем папку с файлами uploads Карта сайта: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: / cgi-bin Запретить: /? Запретить: / wp- Запретить: / wp / Запретить: *? S = Запретить: * & s = Запретить: / search / Запретить: / author / Запретить: / users / Disallow: * / trackback Disallow: * / feed Запрещение: * / rss Disallow: * / embed Запретить: * / wlwmanifest.xml Запретить: /xmlrpc.php Запретить: * utm * = Запретить: * openstat = Разрешить: * / uploads Разрешить: /*/*.js # открываем js-скрипты внутри / wp- (/ * / - для приоритета) Разрешить: /*/*.css # открываем css-файлы внутри / wp- (/ * / - для приоритета) Разрешить: /wp-*.png # картинки в плагинах, кешировать папку и т.д. Разрешить: /wp-*.jpg # картинки в плагинах, кешировать папку и т.д. Разрешить: /wp-*.jpeg # картинки в плагинах, кешировать файлы и т.д. Разрешить: /wp-*.gif # картинки в плагинах, кэшировать папку и т.д. Разрешить: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Яндекс # правила для Яндекса (комментарии не дублирую) Disallow: / cgi-bin Запретить: /? Запретить: / wp- Запретить: / wp / Запретить: *? S = Запретить: * & s = Запретить: / search / Запретить: / author / Запретить: / users / Disallow: * / trackback Disallow: * / feed Запрещение: * / rss Disallow: * / embed Запретить: * / wlwmanifest.xml Запретить: /xmlrpc.php Разрешить: * / uploads Разрешить: /*/*.js Разрешить: /*/*.css Разрешить: / wp- *.PNG Разрешить: /wp-*.jpg Разрешить: /wp-*.jpeg Разрешить: /wp-*.gif Разрешить: /wp-admin/admin-ajax.php Clean-Param: utm_source & utm_medium & utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалить параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *
Disallow: / administrator /
Disallow: / cache /
Disallow: / includes /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow: / media /
Disallow: / modules /
Disallow: / plugins /
Disallow : / templates /
Disallow: / tmp /
Disallow: / xmlrpc /
Карта сайта: http: // путь к вашей карте XML формата
Robots.txt пример для Битрикс
User-agent: *
Disallow: /*index.php$
Disallow: / bitrix /
Disallow: / auth /
Disallow: / personal /
Disallow: / upload /
Disallow: / search /
Disallow: / * / search /
Disallow: / * / slide_show /
Disallow: / * / gallery / * order = *
Disallow: / *? Print =
Disallow: / * & print =
Disallow: / * register =
Disallow: / * Forgot_password =
Disallow: / * change_password =
Disallow: / * login =
Disallow: / * logout =
Disallow: / * auth =
Disallow: / *? action =
Disallow: / * action = ADD_TO_COMPARE_LIST
Disallow: / * action = DELETCE_LIST
Запретить: / * действие = ADD2BASKET
9005 1 Disallow: / * action = BUY
Disallow: / * bitrix _ * =
Disallow: / * backurl = *
Disallow: / * BACKURL = *
Disallow: / * back_url = *
Disallow: / * BACK_URL = *
Disallow: / * back_url_admin = *
Disallow: / * print_course = Y
Disallow: / * COURSE_ID =
Disallow: / *? COURSE_ID =
Disallow: / *? PAGEN
Disallow: / * PAGEN_1 =
Disallow: / * PAGEN_2 =
Disallow: / * PAGEN_3 =
Disallow: / * PAGEN_4 =
PAGEN_5 * Disallow: / =
Disallow: / * PAGEN_6 =
Disallow: / * PAGEN_7 =
Disallow: / * PAGE_NAME = user_post
Disallow: / * PAGE_NAME = detail_slide_show _NAME
Disallow = search: / * * PAGE_NAME
Disallow = search
Disallow: / * PAGE_NAME = user_post
Disallow: / * PAGE_NAME = detail_slide_show
Disallow: / * SHOWALL
Disallow: / * show_all =
Карта сайта: http: // путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *
Disallow: / assets / cache /
Disallow: / assets / docs /
Disallow: / assets / export /
Disallow: / assets / import /
Disallow: / assets / modules /
Disallow: / assets / plugins /
Disallow: / assets / snippets /
Disallow: / install /
Disallow: / manager /
Карта сайта: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *
Disallow: / database /
Disallow: / includes /
Disallow: / misc /
Disallow: / modules /
Disallow: / sites /
Disallow: / themes /
Disallow: / scripts /
Disallow: / updates /
Disallow: / profiles /
Disallow: / profile
Запретить: / profile / *
Запретить: / xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: / admin /
Disallow: / comment / reply /
Disallow: / contact /
Disallow: / logout /
Disallow: / search /
Disallow: / user / register /
Disallow: / user / password /
Disallow: * register *
Disallow: * login *
Disallow: / top-rating-
Disallow: / messages /
Disallow: / book / export /
Disallow: / user2userpoints /
Disallow: / myuserpoints /
Disallow: / tagadelic /
Disallow: / referral /
Disallow: / aggregator /
Disallow: / files / pin /
Disallow: / your -голосов
Disallo w: / comments / latest
Disallow: / * / edit /
Disallow: / * / delete /
Disallow: / * / export / html /
Disallow: / taxonomy / term / * / 0 $
Disallow: / * / edit $
Disallow: / * / outline $
Disallow: / * / revisions $
Disallow: / * / contact $
Disallow: / * downloadpipe
Disallow: / node $
Disallow: / node / * / track $
Disallow: / * &
Disallow: / *%
Disallow: / *? Page = 0
Disallow: / * section
Disallow: / * order
Disallow: / *? Sort *
Disallow: / * & sort *
Disallow: / * voteupdown
Disallow: / * calendar
Disallow: / * index.php
Разрешить: / *? page =
Запретить: / *?
Карта сайта: http: // путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, пройти закрыть от индексации другие страницы. В зависимости от цели, запрет на индексцию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.текст.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. Например, Яндекс и Google предоставляют собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс - Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список - выберите Анализ роботов.txt или по ссылке http://webmaster.yandex.ru/robots.xml

Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt .
Слева выберите Инструменты - Анализ robots .txt

Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а лишь спустя некоторое время .
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console ваш сайт, Запрос к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество - указано под окном редактирования. - Внизу на экране укажите нужный URL-адрес в соответствующем окне.
- В раскрывающемся меню справа выберите робота .
- Нажмите кнопку ПРОВЕРИТЬ .
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН . В первом случае роботы Google могут переходить по указанному вами адресу, а во втором случае - нет.
- При необходимости внесите изменения в меню и проверка заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл роботов.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru. С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в дополнительный каталог вашего сайта.
.
правил обработки директив, какие директивы не используются в Google и зачем нужны Disallow и Crawl-delay - Пиксель Тулс
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
Мета-тег noindex, наиболее эффективный способ удалить страницу из индекса.
404 и 410 коды ответа сервера.В некоторых случаях 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно - именно страницы, полностью скрытые под логином, а не часть контента).
удаление Временное страница из индекса с помощью инструмента в Search Console.
Запретить в robots.txt.
Тем не менее, роботы.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это текстовый файл, который содержит инструкции для краулеров - какие страницы сайта не следует посещать, где лежит наш файл Sitemap.xml и для каких роботов распространяются правила.
Файл размещается в основной директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие роботов.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет - следуют общим инструкциям.
Действующие правила robots.txt
Пользовательский агент
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определенные указания конкретному ему.
брать шире, то User-Agent - клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
Примеры:
Агент пользователя: *- символ астериск используются для обозначения сразу же всех краулеров.User-agent: Яндекс- основной краулер Яндекс-поиска.User-agent: Google-Image- робот поиска Google по картинкам.Пользователь-агент: AhrefsBot- краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта / api / и / tmp / , несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
Пользовательский агент: *
Запрещение: / tmp /
Запретить: / api /
Пользовательский агент: DuckDuckBot
Disallow: / duckhunt / Запретить
Директива, которая позволяет блокировать индексации полностью сайт или определенные разделы.
Может быть полезно для закрытия временных официальных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
Пользовательский агент: *
# Закрываем раздел / cms и все файлы внутри
Disallow: / cms
# Закрываем папку / images / resized / (сами изображения разрешены к сканированию)
Запретить: / api / resized / Упростить инструкции выполняют операторы:
*- любая последовательность символов в URL.По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.$- символ в конце URL-адреса, он используется, чтобы отменить использование * на конце правил.
Пользовательский агент: *
# Закрываем URL, начинающиеся с / photo после домена. Например:
# /фото
# / фото / обзор
Запретить: / фото
# Закрываем все URL, начинающиеся с / blog / после домена и заканчивающиеся / stats /
Disallow: / blog / * / stats $
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Разрешить
С помощью этой директивы можно напротив, разрешить каталог или конкретный адрес к индексции. В некоторых случаях проще запретить сканирование всего сайта и с помощью Разрешить открыть нужные разделы.
Пользовательский агент: *
# Блокируем весь раздел / admin
Запретить: / admin
# Кроме файла / admin / css / style.css
Разрешить: /admin/css/style.css
# Открываем все файлы в папке / admin / js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Разрешить: / admin / js / Также Разрешить можно использовать для отдельных User-Agent.
# Запрещаем доступ к сайту всем роботам
Пользовательский агент: *
Запретить: /
# Кроме краулера Яндекса
Пользователь-агент: Яндекс
Разрешить: / Задержка сканирования
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Пользовательский агент: *
Задержка сканирования: 5 Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если высокое значение установлено, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Задержка сканирования: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Карта сайта
Одно из ключевых применений robots.txt в SEO - указание на расположение карты сайты.Обратите внимание, используется полный URL-адрес (их может быть несколько).
Карта сайта: https://www.example.com/sitemap.xml
Карта сайта: https://www.example.com/blog-sitemap.xml Необходимо иметь в виду:
- Директива
Карта сайта указывается с заглавной S.
Карта сайта не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поиска роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Пользовательский агент: *
Disallow: / Запрет конкретного раздела сайта
Пользовательский агент: *
Запретить: / admin / Запрет определенного файла
Пользовательский агент: *
Запретить: /admin/my-embarrassing-photo.png Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже разработали, пользователь-агент, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже - слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот задержка сканирования, напротив, установлена только для него.
# отредактированная версия robots.txt сайта IMDB
#
# Задержка интервала сканирование для ScouJet
#
Пользовательский агент: ScouJet
Задержка сканирования: 3
#
#
#
# Все остальные
#
Пользовательский агент: *
Запретить: / tvschedule
Запретить: / ActorSearch
Disallow: / ActressSearch
Запретить: / AddRecommendation
Запретить: / ads /
Запретить: / Альтернативные версии
Запретить: / AName
Disallow: / Награды
Disallow: / BAgent
Запретить: / Голосование /
#
#
Карта сайта: https: // www.imdb.com/sitemap_US_index.xml.gz Противоречия директив
Общее правило - если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов.
Пользовательский агент: *
# /admin/js/global.js разрешён к сканированию
# /admin/js/update.js по-прежнему запрещён
Запретить: / admin
Разрешить: /admin/js/global.js Может показаться, что файл /admin/js/global.js попадает под правило блокирования его раздела Отключить: / admin / .Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
Список распространенных User-Agent
| Пользовательский агент | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Бингбот | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| ЯндексБот | Основной индексирующий бот Яндекса |
| ЯндексИзображения | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple.Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| Роджербот | Краулер сервиса МОЗ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Советы по операторам
Как упоминалось выше, широко применяются два оператора: * и $ .С их помощью можно:
1. Заблокировать определенные типы файлов.
Пользовательский агент: *
# Блокируем любые файлы с расширением .json
Disallow: /*.json$ В примере выше астериск * указывает на любые символы в названии, а оператор $ гарантирует, что расширение .json находится точно в конце адреса, и правило не исследует страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром ? , после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET точно являются дублями.
Пользовательский агент: *
# Блокируем любые URL, представлен символ?
Disallow: / *? Заблокировать результаты поиска, но не саму страницу поиска.
Пользовательский агент: *
# Блокируем страницу результатов поиска
Запретить: / search.php? query = * Имеет ли значение регистр?
Определённо да. При указании правил запрещать / разрешать, URL-адреса могут быть относительными, но предписывать регистр.
Пользовательский агент: *
# / users разрешены для просмотра, поскольку регистр разный
Disallow: / Пользователи Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: - без разницы. Исключение - Карта сайта: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» - динамика сканирования страниц сайта в Яндексе и Google.
Контроль изменений в файле robots.txt.Теперь точно не упустите, если кто-то из коллег закрыл сайт от индексации (или наоборот).
Держите свои robots.txt в порядке, и пусть в индекс попадает только необходимое!
.
примеров для различных CMS, правила, рекомендации
Правильная индексция страниц сайта в системе одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года - robots.txt.
Что такое Robots.txt?
Robots.txt - текстовый файл на странице, запрещенные инструкции для роботов какие разрешены для индексции, а какие нет.Но это не является предложением для поисковых машин, инструкции не рекомендуют характер, например, как пишет Google, если на сайте есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индекс ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексции:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировки
- страницы авторизации и регистрации
- учета товаров
Как создать и добавить роботов.txt на сайте?
Robots.txt обычный текстовый файл, можно создать в блокноте, следуя синтаксису который будет описан ниже. Для одного сайта нужен только один такой файл.
Файл нужно добавить в основной каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с действующими объектами .
Директива User-agent
С помощью данной директивы можно указать робота поисковой системы будут заданы нижеследующие рекомендации.Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot - основной робот Google;
- ЯндексБот - основной индексирующий робот;
- Googlebot-Image - робот картинок;
- Яндекс. Изображения - роботции Яндекс.Картинок;
- Яндекс Метрика - робот Яндекс.Метрики;
- Яндекс Маркет— робот Яндекс.Маркета;
- Googlebot-Mobile --индексатор мобильной версии.
Директивы Запретить и Разрешить
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Запретить - директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: / site /
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru / site /
Примечание: Если директива будет указана пустым, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / - это закроет весь сайт от индексации.
Директива Карта сайта
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: / site /
Allow: /
Sitemap: http: // site.com / sitemap1.xml
Карта сайта: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указаний главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которому он доступен. Указывать Хост необходимо в секции роботов Яндекса:
Пользовательский агент: Яндекс
Disallow: / site /
Хост: site.ru
Примечание: Если главным зеркалом является домен с протоколом https, то его нужно указать в роботсе таким образом:
Хост: https://site.ru.
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить индексции страницы сайта, которые формируются с динамическими ограничениями.Такие могут быть показаны дублями страницы для поиска систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param: p1 [& p2 & p3 & p4 & .. & pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https: // site .ru / promo-odezhda / polo.html? kol_from = & price_to = & color = 7
- https: // site.ru / Promo-odezhda / polo.html? kol_from = 100 & price_to = & color = 7
Для того, чтобы исключить подобные страницы индекс следует установить директиву таким образом:
Clean-param: kol_from1 & price_to2 & pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1 & price_to2 & pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (для ресурсов с большим Содержание страниц).Чтобы нагрузку на сервер, можно запустить директивой Crawl-delay.
Параметром для задержки сканирования является время в секундах, которое указывает одного роботам, что следует скачивать с сайта не чаще в раза в период.
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: / site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указать в одной строке
- Правила в роботс указываются в следующей форме: [Имя_директивы]: [необязательный пробел] [ ] [необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать «;»
- Пустая строка трактуется как конец директивы User-agent, если нет правильной строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на следующей строке тоже следует поставить #)
- Роботы.txt нечувствителен к регистру
- В директивах «Разрешить», «Запретить» можно указывать только то, что он воспринимается как Disallow: (можно индексировать все)
- В директивах «Разрешить», «Запретить» можно указать только 1 параметр
- В директивах «Разрешить», «Запретить» в параметрах директории сайта указываются со слешем (например, Disallow: / site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.txt
При указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*.php # запрещает '/store/ex.php' и '/store/test/ex1.php'
Disallow: / * tpl # запрещает не только '/ tpl', но и '/ tpl / user'
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *.Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: / site $ # запрещено для индексации '/ site', но не запрещено '/ ex.css'
User-agent: *
Disallow: / site # индексции и '/ site', и '/site.css'
User-agent: *
Disallow: / site $ # запрещен к индексции только '/ site'
Disallow: / site * $ # так же, как 'Disallow: / site' запрещает и / site.css и / site
Особенности настройки robots.txt для Яндекса
Особенности настройки роботса для Яндекса только наличие директории Хост в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Яндекс
Disallow: / site
Disallow: / admin
Disallow: / users
Disallow: * / templates
Disallow: * / css
Host: www.site.com
В данном случае директива Host указывает роботам Яндекса.site.com (но директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность состоит лишь в том, что сама компания рекомендует не закрывать специальные файлы с css-стилями и js-скриптами. В таком случае робот примет такой вид:
User-agent: Googlebot
Disallow: / site
Disallow: / admin
Disallow: / users
Disallow: * / templates
Разрешить: * .css
Разрешить: * .js
Хост: www.site.com
С помощью директив Разрешить роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексции страницы:
Еще одним инструментом проверки правильности роботс является “ Инструмент проверки файла robots.txt ”в панели Google Search Console:
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексом сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те, которые могут повредить хорошему ранжированию ресурса в выдаче.
Пример настройки роботс для WordPress
Правильный robots.txt для WordPress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Disallow: / cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: / wp- # файлы WP: / wp-json /, / wp-includes, / wp-content / plugins
Disallow: *? s = # результаты поиска
Disallow: / search # результаты поиска
Disallow: * / page / # страницы пагинации
Disallow: / * print = # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: / cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: / wp- # файлы WP: / wp-json /, / wp-includes, / wp-content / plugins
Disallow: *? s = # результаты поиска
Disallow: / search # результаты поиска
Disallow: * / page / # страницы пагинации
Disallow: / * print = # страницы для печати
Allow: * .css # открыть все файлы стилей
Allow: * .js # открыть все с js-скриптами
User- агент: *
Disallow: / cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: / wp- # файлы WP: / wp-json /, / wp-includes, / wp-content / plugins
Disallow: *? s = # результаты поиска
Disallow: / search # результаты поиска
Disallow: * / page / # страницы пагинации
Disallow: / * print = # страницы для печати
Карта сайта: http: // site.ru / sitemap.xml
Карта сайта: http://site.ru/sitemap1.xml
Пример настройки роботс для Битрикс
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексция дублей страниц сайта.
Чтобы избежать подобных проблем, следует правильно настроить файл robots.txt. Ниже приведен пример robots.txt для CMS 1С-Битрикс:
User-Agent: Яндекс
Disallow: / personal /
Disallow: / search /
Disallow: / auth /
Disallow: / bitrix /
Disallow: / login /
Disallow : / *? action =
Disallow: /? mySort =
Disallow: * / filter /
Disallow: * / clear /
Разрешить: / personal / cart /
HOST: https: // site.ru
User-Agent: *
Disallow: / personal /
Disallow: / search /
Disallow: / auth /
Disallow: / bitrix /
Disallow: / login /
Disallow: / *? action =
Disallow: /? mySort =
Disallow: * / filter /
Disallow: * / clear /
Allow: / personal / cart /
Карта сайта: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: / personal /
Disallow: / search /
Disallow: / auth /
Disallow: / bitrix /
Disallow: / login /
Disallow: / *? Action =
Disallow: /? MySort =
Disallow: * / filter /
Disallow: * / clear /
Разрешить: / bitrix / js /
Разрешить: / bitrix / templates /
Разрешить: / bitrix / tools / conversion / ajax_counter.php
Разрешить: / bitrix / components / main /
Разрешить: / bitrix / css /
Разрешить: /bitrix/templates/comfer/img/logo.png
Разрешить: / personal / cart /
Карта сайта: https: // site .ru / sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
Пользовательский агент: Яндекс
Disallow: / * route = account /
Disallow: / * route = affiliate /
Disallow: / * route = checkout /
Disallow: / * route = product / search
Disallow: / index.php
Disallow: / admin
Disallow: / catalog
Disallow: / download
Disallow: / export
Disallow: / system
Disallow: / *? sort =
Disallow: / * & sort =
Disallow: / *? order =
Disallow: / * & order =
Disallow: / *? Limit =
Disallow: / * & limit =
Disallow: / *? Filter_name =
Disallow: / * & filter_name =
Disallow: / *? Filter_sub_category =
Disallow: / * & filter_sub_category =
Disallow: / *? Filter_description =
Disallow: / * & filter_description =
Disallow: / *? Tracking =
Disallow: / * & tracking =
Disallow: / *? Page =
Disallow: / * & page =
Disallow: / wishlist
Disallow: / login
Host: site.ru
User-agent: Googlebot
Disallow: / * route = account /
Disallow: / * route = affiliate /
Disallow: / * route = checkout /
Disallow: / * route = product / search
Disallow: / index. php
Disallow: / admin
Disallow: / catalog
Disallow: / download
Disallow: / export
Disallow: / system
Disallow: / *? sort =
Disallow: / * & sort =
Disallow: / *? order =
Disallow: / * & order =
Disallow: / *? Limit =
Disallow: / * & limit =
Disallow: / *? Filter_name =
Disallow: / * & filter_name =
Disallow: / *? Filter_sub_category =
Disallow: / * & filter_sub_category =
Disallow: / *? Filter_description =
Disallow: / * & filter_description =
Disallow: / *? Tracking =
Disallow: / * & tracking =
Disallow: / *? Page =
Disallow: / * & page =
Disallow: / wishlist
Disallow: / login
Разрешить: *.css
Разрешить: * .js
User-agent: *
Disallow: / * route = account /
Disallow: / * route = affiliate /
Disallow: / * route = checkout /
Disallow: / * route = product / search
Disallow: /index.php
Disallow: / admin
Disallow: / catalog
Disallow: / download
Disallow: / export
Disallow: / system
Disallow: / *? sort =
Disallow: / * & sort =
Disallow : / *? order =
Disallow: / * & order =
Disallow: / *? limit =
Disallow: / * & limit =
Disallow: / *? filter_name =
Disallow: / * & filter_name =
Disallow: / *? filter_sub_category =
Disallow: / * & filter_sub_category =
Disallow: / *? Filter_description =
Disallow: / * & filter_description =
Disallow: / *? Tracking =
Disallow: / * & tracking =
Disallow: / *? Page =
Disallow: / * & page =
Disallow: / wishlist
Disallow: / login
Карта сайта: http: // site.ru / sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен бытьлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: / emarket / addToCompare
Disallow: / emarket / basket
Disallow: /go_out.php
Disallow: / images
Disallow: / files
Disallow: / users
Disallow: / admin
Disallow: / search
Disallow: / install-temp
Disallow: / install-static
Disallow: / install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: / emarket / addToCompare
Disallow: / emarket / basket
Disallow: /go_out.php
Disallow: / images
Disallow: / files
Disallow: / users
Disallow: / admin
Disallow: / search
Disallow: / install-temp
Disallow: / install-static
Disallow: / install-libs
Allow: * .css
Allow: * .js
User-Agent: *
Disallow: /?
Disallow: / emarket / addToCompare
Disallow: / emarket / basket
Disallow: / go_out.php
Disallow: / images
Disallow: / files
Disallow: / users
Disallow: / admin
Disallow: / search
Disallow: / install-temp
Disallow: / install-static
Disallow: / install-libs
Карта сайта : http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots.txt для Джумлы должен быть составлен таким образом:
Пользовательский агент: Яндекс
Disallow: / administrator /
Disallow: / cache /
Disallow: / components /
Disallow: / component /
Disallow: / includes /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow: / media /
Disallow: / modules /
Запрещать: / plugins /
Запрещать: / templates /
Запрещать: / tmp /
Запрещать: / *? Start = *
Запрещать: / xmlrpc /
Хост: www.site.ru
User-agent: Googlebot
Disallow: / administrator /
Disallow: / cache /
Disallow: / components /
Disallow: / component /
Disallow: / includes /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow: / media /
Disallow: / modules /
Disallow: / plugins /
Disallow: / templates /
Disallow: / tmp /
Disallow: / *? Start = *
Disallow: / xmlrpc /
Разрешить: * .css
Разрешить: * .js
Пользовательский агент: *
Запретить: / administrator /
Запретить: / cache /
Запретить: / components /
Запретить: / component /
Запретить: / включает /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow: / media /
Disallow: / modules /
Disallow: / plugins /
Disallow: / templates /
Disallow: / tmp /
Disallow: / *? Start = *
Disallow: / xmlrpc /
Карта сайта: http: // www.site.ru/sitemap.xml
.
Добавить комментарий