
Наш аналитик Александр Явтушенко недавно поделился со мной наблюдением, что у многих сайтов, которые приходят к нам на аудит, часто встречаются одни и те же ошибки. Причем эти ошибки не всегда можно назвать тривиальными – их допускают даже продвинутые веб-мастера. Так возникла идея написать серию статей с инструкциями по отслеживанию и исправлению подобных ошибок. Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Для хорошей индексации сайта и лучшего ранжирования страниц нужно, чтобы поисковик обходил ключевые продвигаемые страницы сайта, а на самих страницах мог точно выделить основной контент, не запутавшись в обилие служебной и вспомогательной информации.
У сайтов, приходящих к нам на анализ, встречаются ошибки двух типов:
1. При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
2. Наоборот, владельцы чересчур рьяно взялись за чистку сайта. Вместе с ненужной информацией могут прятаться и важные для продвижения и оценки страниц данные.
Сегодня мы хотим рассмотреть, что же действительно стоит прятать от поисковых роботов и как это лучше делать. Начнём с контента страниц.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
– скрываются от индексации фильтры, форма поиска, сортировка. Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
– прячется информация об оплате и доставке. Это делают, чтобы повысить уникальность на товарных карточках. А ведь это тоже информация, которая должна быть на качественной товарной карточке.
– со страниц «вырезается» меню, ухудшая оценку удобства навигации по сайту.
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!
У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен. Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Это видно из самого описания тега в справке Яндекса.
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
«Не до конца понятна механика действия и влияние на ранжирование тега <noindex>текст</noindex>. Далее поясню, почему так озадачены. А сейчас — есть 2 гипотезы, хотелось бы найти истину.
№1 Noindex не влияет на ранжирование / релевантность страницы вообще
При этом предположении: единственное, что он делает — закрывает часть контента от появления в поисковой выдаче. При этом вся страница рассматривается целиком, включая закрытые блоки, релевантность и сопряженные параметры (уникальность; соответствие и т. п.) для нее вычисляется согласно всему имеющему в коде контенту, даже закрытому.
№2 Noindex влияет на ранжирование и релевантность, так как закрытый в тег контент не оценивается вообще. Соответственно, все наоборот. Страница будет ранжироваться в соответствии с открытым для роботов контентом.»
Ответ:

В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение.
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:

Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:

Рекомендации Google.
Рекомендации Яндекса.
Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.

Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.

Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.

Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно в блоге Siteclinic.
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Рекомендации Яндекса.
Рекомендации Google.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:

В Google Search Console «Удалить URL-адрес»:

Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Тег noindex
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.

Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:

Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Заключение
Удаление со страницы объёмных сквозных блоков действительно может давать положительный эффект для ранжирования. Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Убирая со страницы часть контента, не забывайте, что для ранжирования важны не только текстовые критерии, но и полнота информации, коммерческие факторы.
Примерно аналогичная ситуация и с внутренними ссылками. Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Со страницами сайта всё более однозначно. Важно следить за тем, чтобы мусорные, малополезные страницы не попадали в индекс. Для этого есть много методов, которые мы собрали и описали в этой статье.
Вы всегда можете взять у нас консультацию по техническим аспектам оптимизации, или заказать продвижение под ключ, куда входит ежемесячный seo-аудит.
ОТПРАВИТЬ ЗАЯВКУ
Автор: Александр, SEO аналитик SiteClinic.ru
Закрыть текст статьи от индексации
У любого блогера возникает потребность закрыть текст статьи от индексации. Зачем? Одна из самых распространённых причин — это скопированные выдержки с другого сайта. Если данный текст уже давно существует на другом сайте, и поисковые системы его давно проиндексировали, они определяют тот сайт как хозяина контента. Да, существует ещё помощник от Яши, который как бы сохраняет за вами авторские права на текст, который вы туда внесёте. Но в паутине есть разные мнения на этот счёт: и положительные, и отрицательные. Я считаю, добавлять туда написанные вами статьи надо обязательно, а вот скрывать от индексации чужие тексты или выдержки не помешает.

Итак, закрыть можно как текст, так и ссылку. И как я говорил ранее, внешняя ссылка на сторонний ресурс — это вселенское зло вашего блога, будем практиковаться )
Мы определились с нашими флагманами в статье Настройка Title и Description для блога — это Яша и Гена.
1. Закрыть ссылки от индексации.
Чтобы наша ссылка на сторонний сайт была закрыта от индексации, так как индексируемая ссылка передаёт как ТИЦ сайта, так и траст, что немаловажно, передавать их всем подряд чревато потерей доверия, что повлечёт потерю и ТИЦа, и траста вашего сайта. Используем тэг «nofollow». Оба поисковика с 2010 года, если почитать описание изменений ядер поисковых систем, понимают этот тэг одинаково и рекомендуют к использованию при закрытии ссылок от индексации. Нам остаётся только добавлять тэг при создании ссылок. Вот пример ссылки в моей статье на скачивание дистрибутива самого WordPress:
Достаточно <a target=»_blank» href=»https://ru.wordpress.org/releases/» rel=»nofollow»> скачать дистрибутив </a> самого WordPress
Текст до и текст после. Анкор ссылки. Тэг закрывающий от индексации. Сама ссылка
<a target=»_blank» rel=»nofollow»> href=»https://ru.wordpress.org/releases/» скачать дистрибутив </a>
Тем самым мы ставим ссылку для удобства пользования, но закрываем её от передачи веса ТИЦ и траста. Да и просто закрываем ссылки на буржуйские сайты.
2. Закрыть текст статьи от индексации.
В данном случае у поисковиков есть различия понимания данного действия.
У Яши, проще простого, необходимо поместить текст в тэг noindex.
Вот текст, который я скопировал с support Яши и поместил его в noindex.
Тег noindex не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<span><code><span><!—noindex—></span>текст, индексирование которого нужно запретить<span><!—/noindex—></span></code></span>
|
| <span><code><span><!—noindex—></span>текст, индексирование которого нужно запретить<span><!—/noindex—></span></code></span> |
И сам код до скрываемого текста и после скрываемого текста.
<!—noindex—>
Тег <span class=»tag codeph»>noindex</span> не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<div class=»codeblock»>
<pre><code class=»xml»><span class=»comment»><!—noindex—></span>текст, индексирование которого нужно запретить<span class=»comment»><!—/noindex—></span></code></pre>
</div><!—/noindex—>
Как быть с Геной? У него есть свой тэг и работает он аналогично тэгу от Яши. Отсюда вывод: если мы хотим закрыть от Яши и Гены одновременно, надо ставить два тэга.
Сам тэг Гены несёт аналогичную функцию, но выглядит по-другому.
<!—googleoff: index—> закрываемый текст <!—googleon: index—>
Текст, закрытый от индексации Яши и Гены, будет выглядеть вот так:
<!—noindex—><!—googleoff: index—> закрываемый текст <!—googleon: index—><!—/ noindex—>
Одно очень важное добавление: Гена закрывает тэгом даже ссылки. Для Яши все ссылки внутри тега <!—noindex—> необходимо закрывать обязательно ещё и «nofollow».
Удачи в передаче и приобретении ТИЦ и траста.
Надеюсь, что после данной статьи вопроса, как закрыть текст статьи от индексации, у вас больше не возникнет.
Как закрыть контент от индексации: руководство
Иногда возникают такие ситуации, когда нужно Закрыть от индексации часть контента. Далее рассмотрим все на примерах.
Часто необходимые вещи, которые необходимо скрыть от индексации Яндексом и Google:
- Скрыть от поиска техническую информацию
- Закрыть от индекса не уникальный контент
- Скрыть сквозной,повторяющийся внутри сайта, контент
- Закрыть мусорные страницы, которые нужны пользователям, но для робота выглядят как дубль
Как закрыть от индексации домен и поддомен
Для того, чтобы закрыть от индексации домен, можно использовать
1. Robots.txt
Для этого прописываем в нем следующие строки:
User-agent: * Disallow: /
При помощи данной манипуляции мы закрываем сайт от индексации всеми поисковыми системами.
При необходимости Закрыть от индексации конкретной поисковой системой, можно добавить аналогичный код, но с указанием Юзерагента.
User-agent: yandex Disallow: /
Иногда, же бывает нужно наоборот открыть для индексации только какой-то конкретной ПС. В таком случае нужно составить файл Robots.txt в таком виде:
User-agent: * Disallow: / User-agent: Yandex Allow: /
Таким образом мы позволяем индексировать сайт только однайо ПС. Однако минусом есть то, что при использовании такого метода, все-таки 100% гарантии не индексации нет. Однако, попадание закрытого таким образом сайта в индекс, носит скорее характер исключения.
Для того, чтобы проверить корректность вашего файла Robots.txt можно воспользоваться данным инструментом просто перейдите по этой ссылкеhttp://webmaster.yandex.ru/robots.xml.
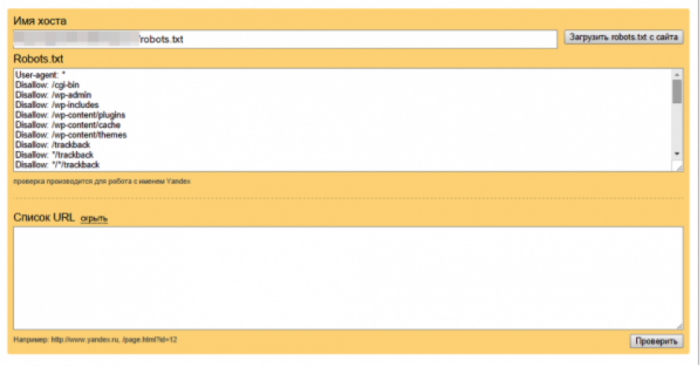
2. Добавление Мета-тега Robots
Также можно закрыть домен от индексации при помощи Добавления к Код каждой страницы Тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Куда писать META-тег “Robots”. Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
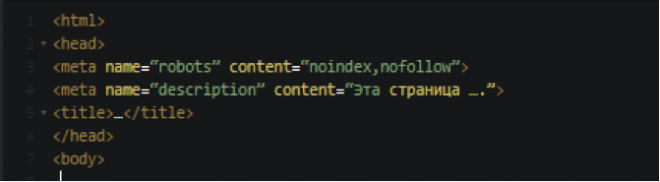
Данный метод работает лучше чем Предыдущий, темболее его легче использовать точечно нежели Вариант с Роботсом. Хотя применение его ко всему сайту также не составит особого труда.
3. Закрытие сайта при помощи .htaccess
Для Того, чтобы открыть доступ к сайту только по паролю, нужно добавить в файл .htaccess, добавляем такой код:
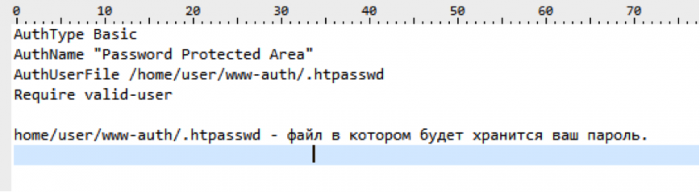
После этого доступ к сайту будет возможен только после ввода пароля.
Защита от Индексации при таком методе является стопроцентной, однако есть нюанс, со сложностью просканить сайт на наличие ошибок. Не все парсеры могут проходить через процедуру Логина.
Закрываем от индексации часть текста
Очень часто случается такая ситуация, что необходимо закрыть от индексации Определенные части контента:
- меню
- текст
- часть кода.
- ссылку
Скажу сразу, что распространенный в свое время метод при помощи тега <noindex> не работает.
<noindex>Тут мог находится любой контент, который нужно было закрыть</noindex>
Однако существует альтернативный метод закрытия от индексации, который очень похож по своему принципу, а именно метод закрытия от индексации при помощи Javascript.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.
Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Как закрыть от индексации конкретную страницу
Для того, чтобы закрыть от индекса конкретную страницу чаще всего используются такие методы:
- Роботс txt
- Мета robots noindex
В случае первого варианта закрытия страницы в данный файл нужно добавить такой текст:
User-agent: ag Disallow: http://site.com/page
?Таким образом данная страница не будет индексироваться с большой долей вероятности. Однако использование данного метода для точечной борьбы со страницами, которые мы не хотим отдавать на индексацию не есть оптимальным.
Так, для закрытия одной страницы от индекса лучше воспользоваться тегом
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
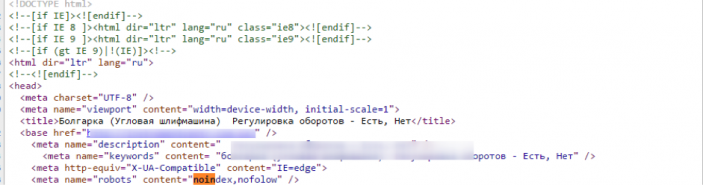
Для этого просто нужно добавить в область HEAD HTML страницы. Данный метод позволяет не перегружать файл robots.txt лишними строчками.
Ведь если Вам нужно будет закрыть от индекса не 1 страницу, а к примеру 100 или 200 , то нужно будет добавить 200 строк в этот файл. Но это в том случае, если все эти страницы не имеют общего параметра по которому их можно идентифицировать. Если же такой параметр есть, то их можно закрыть следующим образом.
Закрытие от индексации Раздела по параметру в URL
Для этого можно использовать 2 метода:
К примеру, у нас на сайте есть раздел, в котором находится неуникальная информация или Та информация, которую мы не хотим отдавать на индексацию и вся эта информация находится в 1 папке или 1 разделе сайта.
Тогда для закрытия данной ветки достаточно добавить в Robots.txt такие строки:
Disallow: /папка/
или
Disallow: /Раздел/*
Также можно закрыть определенное расшерение файла:
User-agent: * Disallow: /*.js
Данный метод достаточно прост в использовании, однако как всегда не гарантирует 100% неиндексации.
Потому лучше в добавок делать еще закрытие при помощи
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Который должен быть добавлен в секцию Хед на каждой странице, которую нужно закрыть от индекса.
Точно также можно закрывать от индекса любые параметры Ваших УРЛ, например:
?sort ?price ?”любой повторяющийся параметр”
Однозначно самым простым вариантом является закрытие от индексации при помощи Роботс.тхт, однако, как показывает практика — это не всегда действенный метод.
Опасные методы закрытия индексации в robots.txt
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
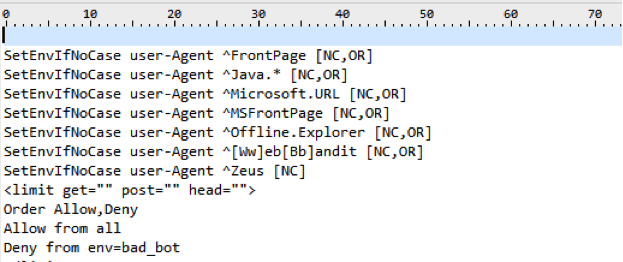
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
 ?
?
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
2. Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем.
Заключение
Ситуации, когда необходимо закрыть контент от индексации случаются довольно часто, иногда нужно почистить индекс, иногда нужно скрыть какой-то нежелательный материал, иногда нужно взломать чужой сайт и в роботсе указать disalow all, чтобы выбросить сайт зеркало из индекса.
Основные и самые действенные методы мы рассмотрели, как же их применять — дело вашей фантазии и целей, которые вы преследуете.
Дата публикации: 07 апреля, 2016
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
|
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow»)
|
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор). Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом:
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
nofollow и noindex | Закрываемся от индексации на tehnopost.info
- nofollow (Яндекс & Google)
- rel=»nofollow» – не переходить по ссылке
- content=»nofollow» – не переходить по всем ссылкам
- Действие rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
- noindex – не индексировать текст
(тег и значение только для Яндекса)- Тег <noindex> – не признанное изобретение Яндекса
- Тег <noindex> – не индексировать кусок текста
- Метатег noindex – не индексировать текст всей страницы
- Разница в действии тега и метатега noindex
- Особенности метатега noindex
- Тег и метатег noindex для Google
- Универсальный метатег (Яндекс & Google)
 Тег noindex служит для обозначения фрагментов текста, запрещенных для индексирования поисковой системой Яндекс.
Тег noindex служит для обозначения фрагментов текста, запрещенных для индексирования поисковой системой Яндекс.
Тег введен в оборот системой яндекс и используется только ей и, возможно, Рамблер.
Google его не понимает и никак не учитывает.
Первоначально, чтобы закрыть часть текста от индексации, нужно было обернуть его, как указано ниже:
<noindex>текст, закрытый от индексации</noindex>
|
| <noindex>текст, закрытый от индексации</noindex> |
Поскольку тег не является частью утвержденных стандартов, возникают проблемы валидации страницы при ее проверке в любом сервисе проверки валидностью кода html.
Из-за этого яндекс ввел другую версию тега вида <!–noindex–>неиндексируемый текст<!–/noindex–>. При таком использовании страница нормально проходит проверку. Первый вариант также до сих пор работает, но более правильно использовать второй вариант.
Применять данный тег можно, например, чтобы закрыть счетчики, комментарии. Но нет смысла закрывать, например, меню в целях перераспределения ссылочного веса на сайте.
Передача веса закрытой ссылке
Тег закрывает от индексации только текст, заключенный в него, но не влияет на индексирование ссылок внутри этого текста и передачу веса по ним. Для закрытия ссылки нужно использовать атрибут rel=”nofollow”, как писал здесь.
Метатег noindex
Метатег в коде страницы вида:
<meta name=»robots» content=»noindex,nofollow»/>
|
| <meta name=»robots» content=»noindex,nofollow»/> |
запрещает от индексации содержимое всей страницы (за это отвечает noindex), а также индексацию ссылок на этой страницы (за это отвечает nofollow).
Для массового проставления данного метатега, например, для архивов и других таксономий в wordpress можно использовать плагин Yoast SEO. В нем можно прописать метатеги в том числе и для отдельных страниц.
В robots.txt тег noindex не работает и не используется.
Сообщение – url запрещен к индексированию тегом noindex
В некоторых случаев вебмастер яндекс выдает сообщение, что адрес страницы, например, главной запрещен от индексации. Это значит, что на странице появился обнаружен этот метатег. Чаще всего такое бывает в двух случаях. Когда создавали сайт, то указали настройку “Попросить поисковые системы не индексировать сайт” на время разработки. Теперь нужно просто убрать эту пометку и отправить сайт в вебмастере на перепроверку. Или второй вариант – у вас стоит SEO плагин вроде Yoast Seo, в настройках которого вы указали запрет индексации, соответственно теперь его нужно убрать.
текстовых индексов — MongoDB Manual
Закрыть ×
MongoDB Руководство
Версия 4.2 (текущая)
Версия 4.4 (ожидается)
Версия 4.2 (текущая)
Версия 40
Версия 3.6
Версия 3.4
Версия 3.2
Версия 30
Версия 2.6
Версия 2.4
Версия 2.2
- Введение
- Начало работы
- Создание кластера свободных уровней Atlas
- Базы данных и коллекции
- Представления
- Материализованные представления по запросу
- Ограниченные коллекции
- Документы
- Типы BSON
- MongoDB Extended JSON (v2)
- MongoDB Extended JSON (v1)
Sort Order
- 9000
- Установка MongoDB Community Edition
- Установка в Linux
- Установка в Red Hat
- Установка с использованием.tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Устранить неполадки при установке Ubuntu
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить с помощью Sball
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить с помощью SUSE
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить с помощью SUSE
- Установить на macOS
- Установить с помощью .tgz Tarball
- Установить на Windows
- Установить с помощью msiexec.exe
- Установить с помощью SUSE
- Установить MongoDB Enterprise
- Установить в Linux
- Установить в Red Hat
- Установить с помощью .tgz Tarball
- Установить на Ubuntu
- Установить с помощью .tgz Tarball
- Установить на Debian
- Установить с помощью .tgz Tarball
- Установить в Red Hat
- Установить на SUSE
- Установить с помощью .tgz Tarball
- Установить на Amazon
- Установить с помощью .tgz Tarball
- Установить в Linux
- Установить на macOS
- Установить на MacOS
- Установить на ОС Windows Установите с помощью msiexec.exe
- Установить с помощью SUSE
- Установка с Docker
- Установка в Red Hat
- Обновление сообщества MongoDB до MongoDB Enterprise
- Обновление до MongoDB Enterprise (автономно)
- Обновление до MongoDB Enterprise (набор реплик)
- Обновление до MongoDB
Enterprise версии
- Установка в Linux
(Shadow)
(Shadow)
Enterprise
(Shadow)
(Sharp)
mongo Shell- Настройка
mongoShell - Доступ к
mongoShell Help - Запись сценариев для
mongo - Shell Shell
-
mongoКраткое руководство по Shell
0 9015
- Вставка документов
- Методы вставки
- Документы-запросы
- Запрос на встраиваемые / вложенные документы
- Запрос на массив
- Запрос на массив
- Встроенные документы
- Поля, возвращаемые из запроса
- Запрос на пустые или отсутствующие поля
- Выполните итерацию курсора в оболочке
mongo
Проект
- Обновление документов
- Обновления с помощью конвейера агрегации
- Методы обновления
.
полнотекстового индексирования в SQL Server 2012
В этой статье мы увидим, как создать полнотекстовый индекс поиска для базы данных SQL Server. Когда мы разрабатываем приложение, во многих случаях нам необходимо предоставить средство поиска в нашем приложении. Вы можете искать записи, используя ключевые слова, такие как «где» и «как», и могут быть другие способы. В этой статье мы рассмотрим метод индекса полнотекстового поиска для поиска в записях и его влияние. Итак, давайте рассмотрим практический пример создания индекса полнотекстового поиска в SQL Server.Пример разработан в SQL Server 2012 с использованием SQL Server Management Studio.
Создание таблицы в SQL Server
Сначала я создал таблицу с именем News. Таблица «Новости» имеет столбец «Заголовок», как показано ниже:

Использование предикатов «Где и как»
После создания таблицы «Новости» со столбцом «Заголовок» можно создать эти запросы для записей поиска:
- ВЫБРАТЬ * ИЗ новостей ГДЕ Название = ‘Заявление’
- ВЫБРАТЬ * ИЗ Новости ГДЕ Название НРАВИТСЯ ‘% Заявление%’
Вывод

На изображении выше не отображаются никакие записи, другими словами «» , где ключевое слово «» используется для полного текста столбца, а ключевое слово « подобно » используется для частей столбца.
Теперь выполните следующую инструкцию, которая содержит текст поиска рядом с инструкцией. Например:
- SELECT * FROM News WHERE Заголовок LIKE ‘% Statements%’
Вывод

На приведенном выше изображении не отображается какая-либо запись, другими словами, ключевое слово «like» используется для полный текст или часть столбца. Он не поддерживает:
- Два слова рядом друг с другом
- Несколько слов с разными весами
- Слово или словосочетание, близкое к поисковому слову или фразе
Полнотекстовый поисковый индекс для SQL Server
First of все запустите SQL Server 2012, выберите базу данных, щелкните правой кнопкой мыши таблицу новостей и выберите полнотекстовый индекс, чтобы определить полнотекстовый индекс.

Откроется окно мастера полнотекстового индекса.
Теперь нажмите кнопку «Далее». Уникальный индекс, по умолчанию, является правильным.

Теперь нажмите кнопку «Далее» и выберите столбцы из таблицы «Новости», чтобы создать индекс полнотекстового поиска.

Теперь нажмите кнопку «Далее», и автоматически по умолчанию выбрано правильное значение.

Теперь нажмите кнопку «Далее» и укажите название каталога.

Теперь нажмите кнопку «Далее».

Теперь нажмите кнопку «Далее». Это откроет окно мастера полнотекстового индекса с проделанной работой.
Теперь нажмите кнопку Готово.
Теперь нажмите кнопку «Закрыть», и вы увидите каталог, созданный после расширения полнотекстовых каталогов.

Теперь щелкните правой кнопкой мыши таблицу новостей и выберите Полнотекстовый индекс, чтобы начать заполнение.

Теперь нажмите на Начать полное заполнение.

Поиск с использованием полнотекстового индекса
Теперь вы действительно готовы выполнить некоторые поиски. Четыре предиката T-SQL участвуют в полнотекстовом поиске:
- FREETEXT: Это находит слово или слова, которые вы даете ему в любом месте столбца поиска.
- FREETEXTTABLE: Это работает как свободный текст, за исключением того, что возвращает результаты в виде объекта Table.
- СОДЕРЖИТ: Вы можете искать одно слово «рядом» с другим таким образом.
- CONTAINSTABLE: Это работает как содержит, за исключением того, что возвращает свои результаты в объекте таблицы.
Пример
Я добавил полнотекстовый индекс в столбец Заголовок таблицы новостей и использовал предикат FreeText :
- ВЫБРАТЬ * ИЗ Новости ГДЕ Название LIKE ‘% Statements%’
- ВЫБРАТЬ * ИЗ Новостей ГДЕ FREETEXT (Заголовок, «Заявление»)
Выход

Пример
Я добавил полнотекстовый индекс в столбец Заголовок в таблице новостей и с помощью содержит Предикат:
- ВЫБРАТЬ * ИЗ Новостей ГДЕ Содержит (Название, «Заявления»)
- ВЫБРАТЬ * ИЗ Новостей ГДЕ FreeText (Заголовок, «Заявления»)
Выход
 ,
,
Это относится как к SharePoint 2007, так и к 2010. В MOSS Enterprise и в версии 2010 Enterprise.
ОБНОВЛЕНИЕ
(14.03.16): если вы используете SharePoint 2013 или SharePoint Online с Office 365 для предприятий, вам не нужно это решение. Эта функциональность теперь встроена в каждый отдельный список и библиотеку, с милой маленькой рамкой «Найти» вверху.
Существует готовая веб-часть, называемая веб-частью текстового фильтра .По сути, когда вы помещаете эту веб-часть на страницу и размещаете веб-часть списка или библиотеки на той же странице, вы затем создаете соединение веб-части, которое отправляет текст, введенный в поле, в качестве фильтра, в один из столбцов в. веб-часть, как это:
Имя Молли Кларк должно было быть введено точно. Итак, если вы наберете «Молли», эта запись не появится.
Люди используют веб-часть текстового фильтра, когда хотят просто найти один столбец в списке или библиотеке. В противном случае вы просто используете поле «Поиск» в верхней части экрана, выбираете «Этот список» или «Этот сайт» и выполняете поиск SharePoint таким образом.
Еще одна заметка, прежде чем я перейду к сегодняшнему решению:
Если вы используете столбцы сайта в своих списках, есть настройка, в которой вы можете указать, какие столбцы НЕ нужно для поиска на сайте. В Параметры сайта щелкните Доступные для поиска столбцы . Поставьте флажки в столбце NoCrawl для тех, которые не должны быть доступны для поиска.
Вот как настроить текстовый фильтр, чтобы любой частичный поиск слов работал
Одна проблема: с этим решением я не думаю, что есть способ заставить список автоматически отображать все элементы по умолчанию перед выполнением фильтра.
Итак, еще раз, это касается веб-части представления данных… и концепции «параметров», о которой я постоянно говорю.
- Перейдите на страницу веб-части, откройте ее в SharePoint Designer и вставьте веб-часть текстового фильтра и веб-часть представления данных в любой список или библиотеку.
- Нажмите, чтобы выбрать веб-часть списка, щелкните меню Просмотр данных и выберите Параметры .
- Создайте новый параметр . В столбце имени не имеет значения, как он называется, давайте просто назовем его FilterParam.В раскрывающемся списке Источник параметров выберите Строка запроса .
Query String Variable должно быть точным именем столбца, который вы хотите отфильтровать. - Щелкните меню Просмотр данных и выберите Фильтр .
Имя поля должно быть именем столбца, который вы хотите отфильтровать, а — ЗДЕСЬ : из Сравнение выберите СОДЕРЖИТ .Для значения выберите имя параметра, созданного на шаге 3. Нажмите ОК .
- Щелкните правой кнопкой мыши веб-часть «Текстовый фильтр » и выберите «Свойства веб-части ».
- Имя фильтра Поле обязательно. Придумай что-нибудь. Если оно будет использоваться для поиска в поле заголовка, вы можете назвать его интуитивно понятным, например «Поиск заголовка». В Advanced Filter Options также есть поле для управления шириной в пикселях.Введите ширину, если вы не хотите, чтобы веб-часть растягивалась по всей странице. Нажмите ОК .
- Щелкните правой кнопкой мыши веб-часть текстового фильтра и выберите Соединения веб-частей.
- Выберите Отправить значения фильтра на . Нажмите Далее .
- Подключитесь к веб-части на этой странице . Нажмите Далее .
- Целевая веб-часть: выберите название вашего списка. Эта часть важна: целевое действие должно быть Получить параметры от .Нажмите Далее .
- Щелкните по названию текстового фильтра слева и по имени вашего нового параметра справа. Нажмите Далее .
- Нажмите Готово и сохраните страницу веб-части.
Попробуйте. В текстовом фильтре вы можете ввести любую часть любого слова и нажать клавишу ввода. Он не требует булевых выражений или чего-то подобного, но гораздо полезнее, чем просто набирать текст.Опять же, это решение, которое я только что разработал сегодня, и не может сказать, есть ли способ заставить веб-часть отображать все элементы, пока вы не захотите отфильтровать ее. Ничего очевидного. Я предполагаю, что если вам нужно отобразить весь список, вы можете просто вставить третью веб-часть на страницу в качестве полного просмотра списка.
,
Существует несколько способов проинструктировать Google избегать различных страниц вашего сайта:
.. и так далее. Все эти директивы функционируют по-разному, но все они служат одной и той же основной цели: контролировать, как Google сканирует различные страницы на вашем сайте. Например, вы можете использовать meta noindex для указания Google не индексировать карту сайта, RSS-канал или любую другую страницу, которую вы пожелаете. Этот уровень контроля над тем, какие страницы сканируются и индексируются, полезен, но что, если вам нужно контролировать, как Google сканирует содержимое определенной страницы? Легко.Google позволяет нам делать это с помощью набора googleon / googleoff тегов.
О тэгах googleon и googleoff
Проще говоря, теги googleon / googleoff сообщают GoogleBot Google Search Appliance, когда начинать и останавливать индексацию различных частей веб-документа. Рассмотрим следующий пример:
Это обычный (X) контент HTML, который будет проиндексирован Google.
Этот (X) контент HTML НЕ будет проиндексирован Google.
В этом примере мы видим, как теги googleon / googleoff не позволят Google проиндексировать второй абзац. Обратите внимание на параметр « index », который может быть установлен на любой из следующих параметров:
- index — контент, окруженный «
googleoff:index» не будет проиндексирован Google - anchor — текст привязки для любых ссылок в области «
googleoff:anchor» не будет связан с целевой страницей - фрагмент — содержание, окруженное «
googleoff:фрагмент» не будет использоваться для создания фрагментов для результатов поиска - все — содержимое, окруженное «
googleoff:все», обрабатывается со всеми атрибутами: индекс, якорь и фрагмент
Круто, а? Давайте посмотрим на конкретный пример использования.,
Использование тегов googleon и googleoff
Пример 1: Комментарии в блоге
Допустим, ваши ветки комментариев имеют тенденцию отклоняться от обсуждения вне темы. Держать ваши страницы как можно более сфокусированными на предмете под рукой — отличный способ повысить релевантность целевых ключевых слов на странице при одновременном повышении точности соответствия поисковых запросов. Таким образом, чтобы исключить излишнее подшучивание из индекса Google, можно добавить googleon / googleoff тегов следующим образом:
Ник Мейсон - 2 августа 2009 г.
От Ее Величества Королевы.Его ботинки были очень чистыми.
Рик Райт - 3 августа 2009 г.
Каждый год становится короче, никогда не находишь время.
Дэвид Гилмор - 4 августа 2009 г.
У реки, держась за руки, сверните меня и положите.
Роджер Уотерс - 5 августа 2009 г.
И через некоторое время вы можете работать над очками для стиля.
Мы определенно не хотим видеть такую бессмысленную нить в Google, и будет интересно посмотреть, не будет ли пример
исключен из индекса ..
Да пребудет с тобой Сила
. При использовании этого метода для управления тем, как Google индексирует ваш контент на странице, необходимо помнить о нескольких моментах. Во-первых, существует разница между индексированием , индексированием и , сканированием .Google может сканировать части вашей страницы, которые разграничены тегами googleon / googleoff . Поэтому, если вы подумали, что этот метод может быть способом борьбы с новой политикой Google nofollow, забудьте об этом - PageRank будет продолжать проходить через любые ссылки, содержащиеся в зоне googleoff .
Кроме того, имейте в виду, что это запатентованный метод, поддерживаемый исключительно Google Search Appliance. Если у вас есть контент, который вы хотите исключить из индекса для всех поисковых систем, то вам нужно будет найти другой способ сделать это.В конце концов, Yahoo! и MSN / Live / Bing / независимо от того, что может создавать собственные «включенные / выключенные теги», но шансы на то, что они будут подчиняться фирменной технологии могучего Google, невелики.
Для получения дополнительной информации о тегах googleon / googleoff ознакомьтесь с официальной документацией Google.
Об авторе
Джефф Старр = Креативный мыслитель. Увлечен свободным и открытым вебом.

GA Pro: добавьте Google Analytics в WordPress как профессионал.,

2025 © Все права защищены.
Добавить комментарий