
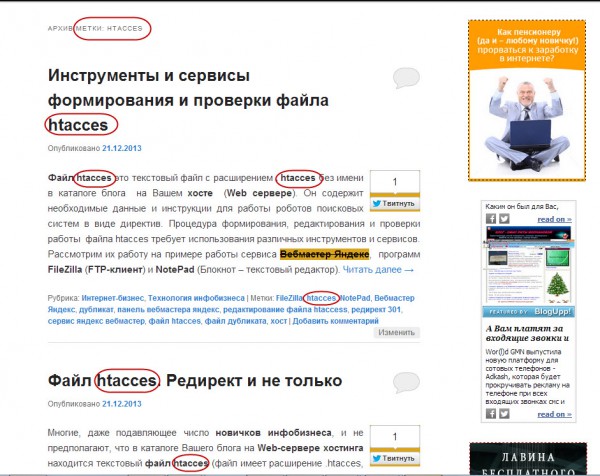
Как скрыть ссылки и текст от индексации на странице сайта?
Встречаются такие ситуации, когда требуется закрыть контент от индексации. Это может быть:
- неуникальный контент;
- шаблонный текст, встречающийся на всех страницах сайта;
- ссылки на сторонние ресурсы.
Ссылки
(внешние и внутренние)
Закрывать от поисковых систем внешние ссылки необходимо, если вы не хотите, чтобы страница, имеющая ссылку, теряла свой вес.
Это может происходить следующим образом:
- Удалением внешних ссылок. Рекомендуется убирать внешние ссылки на сторонние ресурсы.
- Если удалить ссылку нет возможности, то необходимо скрыть ссылку от индексации посредством скрипта так, чтобы в исходном коде страницы не было <a href=»» …></a>, а блок выводился в виде: <div></div>. Далее при формировании страницы скриптом выводилось содержимое данного блока в виде ссылок и прочего.
Сам скрипт требуется закрыть от индексации в файле robots. txt.
txt. - Добавлением атрибута rel=»nofollow». Необходимо прописать атрибут rel=»nofollow» для внешней ссылки (<a href=»» rel=»nofollow» target=»_blank»>текст ссылки</a>).
 txt.
txt.
Помимо внешних ссылок, аналогичное рекомендуют проводить с внутренними ссылками вида добавить в корзину, вход, авторизация, фильтр, сбросить фильтр и т.д. (для всех элементов, которые сверстаны ссылками <a href>, но при этом не ведут на реальные страницы).
Текст
Если у вас на сайте используется большое количество неуникального или дублирующегося контента, то его необходимо скрыть от индексации.
Это можно сделать двумя способами:
- выделить кусок необходимого текста с помощью тега <!—noindex—>…<!—/noindex—>
- прописать мета-тег <meta name=»robots» content=»noindex»/> странице.
Важно
Если Вы прописали мета-тег <meta name=»robots» content=»noindex»/>, то ссылки на странице все будут доступны для поисковых систем и роботы будут переходить по ним. Поэтому необходимо добавить атрибут, nofollow, если необходимо полностью запретить индексацию страницы. Выглядеть это может следующим образом: <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/>.
Поэтому необходимо добавить атрибут, nofollow, если необходимо полностью запретить индексацию страницы. Выглядеть это может следующим образом: <meta name=»robots» content=»noindex, nofollow»/> или <meta name=»robots» content=»none»/>.
#104
Февраль’19
1277
21
#94
Декабрь’18
3337
28
#60
Февраль’18
3922
19
Как скрыть от поисковых систем часть контента на странице (текст, часть страницы, ссылки)? И зачем?
На некоторых сайтах имеет смысл скрыть часть контента от поисковых систем.
Как скрыть часть контента на страницах сайта от роботов поисковых систем?
Для каких целей следует скрывать содержание?
Разберемся с вопросами далее.
Зачем скрывать контент сайта от индексации?
Контент на сайте скрывается от поисковых систем для достижения различных целей.
Если скрыть часть контента от поискового краулера, то алгоритмы ранжирования обработают не всю страницу, а лишь ее часть. В результате поисковый оптимизатор может извлечь выгоду.
Если от поисковых систем часть сайта скрывается, то для пользователей весь контент остается полностью видимым.
Итак, какой контент имеет смысл скрывать и зачем? Например:
- Ссылки для улучшения внутренней перелинковки на сайте. Улучшение достигается за счет оптимизации распределения статического ссылочного веса на сайте;
- Часть текста для повышения релевантности страницы;
- Часть страницы для улучшения ранжирования. Например, скрытие рекламных блоков со страницы, которые находятся в верхней части страницы. Если такие рекламные блоки не скрывать, то поисковая система после рендеринга на так называемом первом экране распознает нерелевантный контент, что не позволит сайту ранжироваться лучше;
- Часть страницы для защиты от санкций поисковых систем. Например, часто требуется скрывать исходящие ссылки на различные сайты.
 Например, скрытие рекламных блоков со страницы, которые находятся в верхней части страницы. Если такие рекламные блоки не скрывать, то поисковая система после рендеринга на так называемом первом экране распознает нерелевантный контент, что не позволит сайту ранжироваться лучше;
Например, скрытие рекламных блоков со страницы, которые находятся в верхней части страницы. Если такие рекламные блоки не скрывать, то поисковая система после рендеринга на так называемом первом экране распознает нерелевантный контент, что не позволит сайту ранжироваться лучше;Есть еще множество различных ситуаций при которых требуется скрывать от поисковых систем часть страницы.
Например, поисковые системы пессимизируют сайты с реферальными ссылками. Такие сайты зарабатывают на партнерских отчислениях. С точки поисковых систем таких как Google подобные сайты не несут никакой дополнительной ценности для пользователя, а значит и не должны находиться среди лидеров поиска.
Если реферальные ссылки скрыть, проблем не будет.
Как скрыть от поисковых систем часть страницы?
На практике скрыть контент сайта от индексации можно используя разные способы.
Наиболее распространенным способом по скрытию текста от поисковых систем является использование подгрузки текста по параметру в хеш-ссылке. Исходя из заявлений Google, протокол HTTP/HTTPS не был разработан для такого использования, поэтому при использовании данного метода индексация не происходит.
Наиболее распространенным способом по скрытию ссылки от поисковых систем является использование контейнера div при создании ссылки.
Но что делать, если речь идет о создании системы для скрытия контента?
Какую технологию использовать? Основные требования следующие:
- У пользователя на экране должен отображаться весь контент страницы сайта;
- Для поисковой системы должен отдаваться не весь контент страницы сайта;
- Способ должен быть условно белым, чтобы сложнее было найти повод для санкций.
В результате оптимальной технологией является та технология, которая официально:
- Не поддерживается движком поисковой системы;
- Поддерживается популярными браузерами.
Ситуация ухудшается тем, что Google обновил поисковый краулер. Теперь Google выполняет скрипты, написанные на современном JavaScript.
Рекомендованный материал в блоге MegaIndex по теме обновления краулера по ссылке далее — Google обновил поисковый краулер. Что изменилось? Как это повлияет на ранжирование?
Все приведенные способы основаны на принципах работы поискового краулера.
Но лазейка все еще есть. В результате обновления стала известна информация о принципах работы поискового краулера, используя которую можно сделать выводы о том, какие именно технологии поисковый робот не поддерживает, а значит не передает в систему ранжирования.
До начала этапа ранжирования происходит ряд процессов.
Весь процесс обработки информации до этапа ранжирования выглядит так:
После рендеринга происходит передача данных в систему ранжирования.
Если после рендеринга часть документа отсутствует, значит данная часть документа не будет участвовать и в ранжировании.
Теперь требуется разобраться с тем, какую технологию пока еще не поддерживает движок рендеринга. Применяя такую технологию на практике можно скрывать часть содержания страниц сайта от поисковой системы.
Итак, скрыть любую часть страницы от поисковой системы можно используя так называемые service workers.
Что такое сервис-воркеры? Сервис-воркеры — это событийный управляемый веб-воркер, регистрируемый на уровне источника и пути. Сервис-воркер может контролировать сайт, с которым ассоциируется, перехватывать и модифицировать запросы навигации и ресурсов.
Да, я вижу ваши лица. Подождите пугаться.
Если упростить, то сервис-воркером является программируемый сетевой проксификатор.
Иными словами, применяя сервис-воркер можно контролировать контент, который передаются пользователю.
В результате применения сервис-воркеров контент может изменяться. Поисковая система же обрабатывает такие корректировки, так как не поддерживает выполнения таких скриптов.
Почему метод эффективен в применении на практике? Сервис-воркеры поддерживаются всеми популярными браузерами и не поддерживаются движком рендеринга поисковой системы Google, через который данные передаются в систему ранжирования.
Следующие браузеры поддерживают сервис-воркеры:
- Chrome;
- Android Chrome;
- Opera;
- Safari;
- iOS Safari;
- Edge;
- Firefox.
Задача поискового оптимизатора заключается в следующем:
- Найти элементы, которые требуется скрыть от поисковой системы;
- Если такие элементы есть, то передать задачу в отдел разработки и оповестить про способы реализации на практике;
- Протестировать работу на примере одного документа путем использования программного решения Chrome Dev Tools или путем анализа кеша страницы в Google после индексации.
Вопросы и ответы
Есть ли официальные заявления о том, что Google действительно не поддерживает сервис-воркеры
Да, такие заявление являются публичными и есть на видео.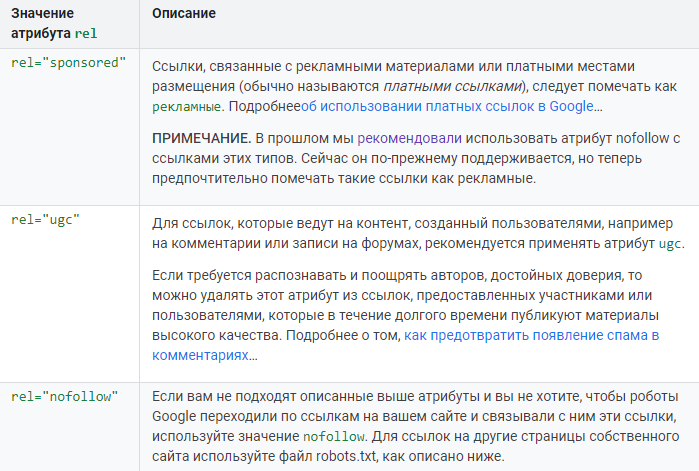
Зачем нужны сервис-воркеры?
На сайтах серивс-воркеры используют для разных целей. Например, для адаптации сайта под ситуацию с прерванным доступом к интернету.
Если интернет пропал, то при использовании сервис-воркеров сайты могут вести себя как приложения на мобильных устройствах, то есть отдавать уже скачанный контент и сигнализировать о необходимости подключения.
На практике сервис-воркеры используются еще и для кеширования изображений.
Еще используя сервис-воркеры можно сохранять данные заполненных форм и отправлять их в интернет при появлении подключения. Для реализации используется Background Sync API. Цепь следующая:
Сайт - Index DB - Service Worker - Интернет
Еще сервис-воркеры вместе с Content-Length и Range можно использовать для загрузки больших файлов частями. Например, так можно защищать видео от копирования.
Еще сервис-воркеры используются для отправки push уведомлений.
Кстати, сервис-воркеры продолжают работать даже когда окно браузера закрыто.
Кто использует сервис-воркеры?
Например сервис-воркеры используются на таких сайтах как:
- Google;
- YouTube;
- Twitter;
- Booking;
- Facebook;
- Washington Post;
Как скрыть весь сайт от поисковых систем?
В редких случаях сайты полностью могут быть закрыты от поисковых роботов. Например так защищают площадки от Роскомнадзора при продвижении сайтов различных спортивных тематик. Если стоит задача скрыть всю страницу или весь сайт от конкретных роботов, то наиболее эффективный способ заключается в запрете индексации на уровне сервера. Рекомендованный материал в блоге MegaIndex по теме защиты сайта от парсинга различными роботами по ссылке далее — Эффективные способы защиты от парсинга сайта.
Кстати, краулер MegaIndex индексирует больше ссылок за счет того, что для робота MegaIndex доступ к сайтам не закрыт.
Почему так происходит? Поисковые оптимизаторы используют различные плагины для того, чтобы закрыть ссылки от таких сервисов как SEMrush, Majestic, Ahrefs. В таких плагинах используются черные списки. Если вести речь про глобальный рынок, то MegaIndex является менее расхожим сервисом, и поэтому часто краулер MegaIndex не входит в черный список. Как результат, применяя сервис MegaIndex у поисковых оптимизаторов есть возможность найти те ссылки, которые не находят другие сервисы.
Ссылка на сервис — Внешние ссылки.
Еще выгрузку ссылок можно провести посредством API. Полный список методов доступен по ссылке — MegaIndex API. Метод для выгрузки внешних ссылок называется backlinks. Ссылка на описание метода — метод backlinks.
Пример запроса для сайта indexoid.com:
http://api.megaindex.com/backlinks?key={ключ}&domain=indexoid. com&link_per_domain=1&offset=0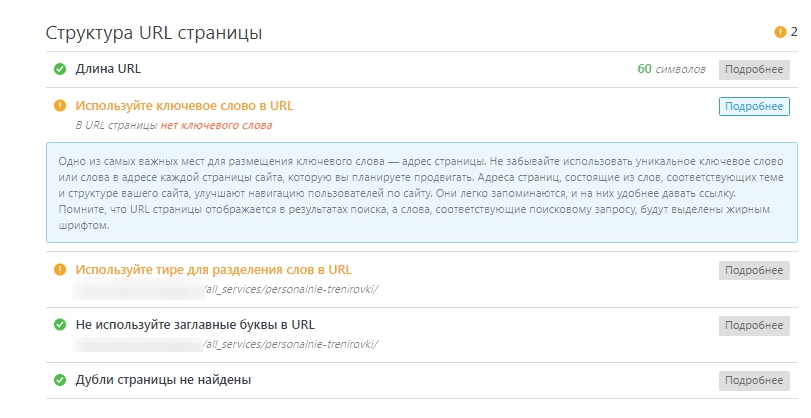 com&link_per_domain=1&offset=0
com&link_per_domain=1&offset=0Пример запроса для сайта smmnews.com:
http://api.megaindex.com/backlinks?key={ключ}&domain=smmnews.com&link_per_domain=1&offset=0Выводы
С обновлением Googlebot скрыть ссылки, текст и другие части страниц сайта от поисковой системы стало сложнее, но лазейки есть. Поисковый движок рендеринга по прежнему не поддерживает сервис-воркеры.
Используя service workers с запросами можно проводить следующие манипуляции:
- Отправлять;
- Принимать.
- Модифицировать.
Применяя сервис-воркеры можно скрыть от поисковых систем ссылки, текст, и даже блок страницы.
Итак, в результате при необходимости поисковый оптимизатор может:
- Закрыть от индексации внешние ссылки с целью улучшения распределения статического ссылочного веса;
- Закрыть от индексации страницы тегов с низкой частотностью;
- Закрыть от индексации страницы пагинации;
- Скрытый текст или часть текста от индексации;
- Закрыть от индексации файлы;
- Закрыть от индексации блок и часть страницы;
- Скрыть от индексации реферальные ссылки.

Сервис-воркеры можно использовать и в целях улучшения производительности сайта. Например, намедни Google стал использовать сервис-воркеры в поисковой выдаче.
Схема одного из интересных трюков выглядит так:
- Вы искали ресторан, например утром;
- Спустя время, вы снова искали ресторан, например по той причине, что забыли о том, где находится заведение. На данном шаге Google выдаст результаты из кеша, который управляется сервис-воркером. Как результат, данные выдаются без отправки запроса в интернет.
Преимущества следующие:
- Снижается нагрузка на сервер Google, что приводит к снижению затрат;
- Увеличивается скорость загрузки страницы с ответом. Повышается лояльность пользователя;
- Страницы откроется даже без интернета. Повышается лояльность пользователя.
Остались ли у вас вопросы, замечания или комментарии по теме скрытия части содержания страниц от поисковых систем?
Как закрыть контент от индексации — пошаговое руководство
Иногда возникают такие ситуации, когда нужно Закрыть от индексации часть контента. Пример такой ситуации мы рассматривали здесь.
Пример такой ситуации мы рассматривали здесь.
Также, иногда нужно:
- Скрыть от поиска техническую информацию
- Закрыть от индекса не уникальный контент
- Скрыть сквозной,повторяющийся внутри сайта, контент
- Закрыть мусорные страницы, которые нужны пользователям, но для робота выглядят как дубль
Постараемся в данной статье максимально подробно расписать инструменты при помощи которых можно закрывать контент от индексации.
Закрываем от индексации домен/поддомен:
Для того, чтобы закрыть от индексации домен, можно использовать:
1. Robots.txt
В котором прописываем такие строки.
User-agent: *
Disallow: /
При помощи данной манипуляции мы закрываем сайт от индексации всеми поисковыми системами.
При необходимости Закрыть от индексации конкретной поисковой системой, можно добавить аналогичный код, но с указанием Юзерагента.
User-agent: yandex
Disallow: /
Иногда, же бывает нужно наоборот открыть для индексации только какой-то конкретной ПС. В таком случае нужно составить файл Robots.txt в таком виде:
В таком случае нужно составить файл Robots.txt в таком виде:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Таким образом мы позволяем индексировать сайт только однайо ПС. Однако минусом есть то, что при использовании такого метода, все-таки 100% гарантии не индексации нет. Однако, попадание закрытого таким образом сайта в индекс, носит скорее характер исключения.
Для того, чтобы проверить корректность вашего файла Robots.txt можно воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
Статья в тему: Robots.txt — инструкция для SEO
2. Добавление Мета-тега Robots
Также можно закрыть домен от индексации при помощи Добавления к Код каждой страницы Тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Куда писать META-тег “Robots”
Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
Данный метод работает лучше чем Предыдущий, темболее его легче использовать точечно нежели Вариант с Роботсом. Хотя применение его ко всему сайту также не составит особого труда.
Хотя применение его ко всему сайту также не составит особого труда.
3. Закрытие сайта при помощи .htaccess
Для Того, чтобы открыть доступ к сайту только по паролю, нужно добавить в файл .htaccess, добавляем такой код:
После этого доступ к сайту будет возможен только после ввода пароля.
Защита от Индексации при таком методе является стопроцентной, однако есть нюанс, со сложностью просканить сайт на наличие ошибок. Не все парсеры могут проходить через процедуру Логина.
Закрываем от индексации часть текста
Очень часто случается такая ситуация, что необходимо закрыть от индексации Определенные части контента:
- меню
- текст
- часть кода.
- ссылку
Скажу сразу, что распространенный в свое время метод при помощи тега <noindex> не работает.
<noindex>Тут мог находится любой контент, который нужно было закрыть</noindex>
Однако существует альтернативный метод закрытия от индексации, который очень похож по своему принципу, а именно метод закрытия от индексации при помощи Javascript.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.
Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Подробнее об этом можно почитать тут.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Как закрыть от индексации конкретную страницу:
Для того, чтобы закрыть от индекса конкретную страницу чаще всего используются такие методы:
- Роботс txt
- Мета robots noindex
В случае первого варианта закрытия страницы в данный файл нужно добавить такой текст:
User-agent: ag
Disallow: http://site.com/page
Таким образом данная страница не будет индексироваться с большой долей вероятности. Однако использование данного метода для точечной борьбы со страницами, которые мы не хотим отдавать на индексацию не есть оптимальным.
Так, для закрытия одной страницы от индекса лучше воспользоваться тегом
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Для этого просто нужно добавить в область HEAD HTML страницы. Данный метод позволяет не перегружать файл robots. txt лишними строчками.
txt лишними строчками.
Ведь если Вам нужно будет закрыть от индекса не 1 страницу, а к примеру 100 или 200 , то нужно будет добавить 200 строк в этот файл. Но это в том случае, если все эти страницы не имеют общего параметра по которому их можно идентифицировать. Если же такой параметр есть, то их можно закрыть следующим образом.
Закрытие от индексации Раздела по параметру в URL
Для этого можно использовать 2 метода:
Рассмотрим 1 вариант
К примеру, у нас на сайте есть раздел, в котором находится неуникальная информация или Та информация, которую мы не хотим отдавать на индексацию и вся эта информация находится в 1 папке или 1 разделе сайта.
Тогда для закрытия данной ветки достаточно добавить в Robots.txt такие строки:
Если закрываем папку, то:
Disallow: /папка/
Если закрываем раздел, то:
Disallow: /Раздел/*
Также можно закрыть определенное расшерение файла:
User-agent: *
Disallow: /*.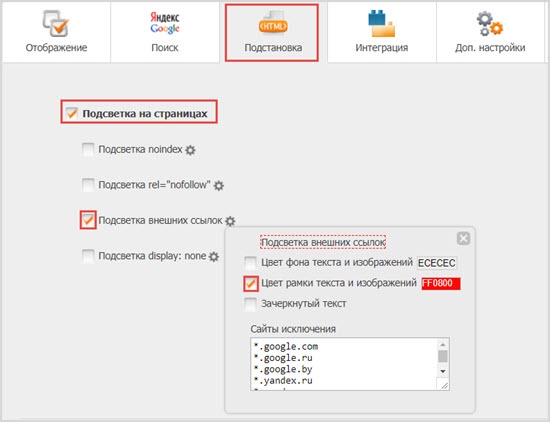 js
js
Данный метод достаточно прост в использовании, однако как всегда не гарантирует 100% неиндексации.
Потому лучше в добавок делать еще закрытие при помощи
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Который должен быть добавлен в секцию Хед на каждой странице, которую нужно закрыть от индекса.
Точно также можно закрывать от индекса любые параметры Ваших УРЛ, например:
?sort
?price
?”любой повторяющийся параметр”
Однозначно самым простым вариантом является закрытие от индексации при помощи Роботс.тхт, однако, как показывает практика — это не всегда действенный метод.
Методы, с которыми нужно работать осторожно:
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем:
В заключение
Ситуации, когда необходимо закрыть контент от индексации случаются довольно часто, иногда нужно почистить индекс, иногда нужно скрыть какой-то нежелательный материал, иногда нужно взломать чужой сайт и в роботсе указать disalow all, чтобы выбросить сайт зеркало из индекса.
Основные и самые действенные методы мы рассмотрели, как же их применять — дело вашей фантазии и целей, которые вы преследуете.
Хорошие статьи в продолжение:
— Стоит ли открывать рубрики для индексации, если в разных рубриках выводятся одни и те же посты?
— Как открывать страницы поиска в интернет магазине — руководство
А что вы думаете по этому поводу? Давайте обсудим в комментариях!)
Оцените статью
Загрузка…
Как закрыть от индексации страницу, сайт, ссылки, текст. Что нужно запрещать индексировать в robots.txt
Наш аналитик Александр Явтушенко недавно поделился со мной наблюдением, что у многих сайтов, которые приходят к нам на аудит, часто встречаются одни и те же ошибки. Причем эти ошибки не всегда можно назвать тривиальными – их допускают даже продвинутые веб-мастера. Так возникла идея написать серию статей с инструкциями по отслеживанию и исправлению подобных ошибок. Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Для хорошей индексации сайта и лучшего ранжирования страниц нужно, чтобы поисковик обходил ключевые продвигаемые страницы сайта, а на самих страницах мог точно выделить основной контент, не запутавшись в обилие служебной и вспомогательной информации.
У сайтов, приходящих к нам на анализ, встречаются ошибки двух типов:
1. При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
2. Наоборот, владельцы чересчур рьяно взялись за чистку сайта. Вместе с ненужной информацией могут прятаться и важные для продвижения и оценки страниц данные.
Сегодня мы хотим рассмотреть, что же действительно стоит прятать от поисковых роботов и как это лучше делать. Начнём с контента страниц.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
– скрываются от индексации фильтры, форма поиска, сортировка. Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
– прячется информация об оплате и доставке. Это делают, чтобы повысить уникальность на товарных карточках. А ведь это тоже информация, которая должна быть на качественной товарной карточке.
– со страниц «вырезается» меню, ухудшая оценку удобства навигации по сайту.
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!
У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен. Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Это видно из самого описания тега в справке Яндекса.
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
«Не до конца понятна механика действия и влияние на ранжирование тега <noindex>текст</noindex>. Далее поясню, почему так озадачены. А сейчас — есть 2 гипотезы, хотелось бы найти истину.
№1 Noindex не влияет на ранжирование / релевантность страницы вообще
При этом предположении: единственное, что он делает — закрывает часть контента от появления в поисковой выдаче. При этом вся страница рассматривается целиком, включая закрытые блоки, релевантность и сопряженные параметры (уникальность; соответствие и т. п.) для нее вычисляется согласно всему имеющему в коде контенту, даже закрытому.
№2 Noindex влияет на ранжирование и релевантность, так как закрытый в тег контент не оценивается вообще. Соответственно, все наоборот. Страница будет ранжироваться в соответствии с открытым для роботов контентом.»

Ответ:
В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение.
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:
Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:
Рекомендации Google.
Рекомендации Яндекса.
Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.
Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.
Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.
Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно в блоге Siteclinic.
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Рекомендации Яндекса.
Рекомендации Google.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:
В Google Search Console «Удалить URL-адрес»:
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Тег noindex
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.
Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:
Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Заключение
Удаление со страницы объёмных сквозных блоков действительно может давать положительный эффект для ранжирования. Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Убирая со страницы часть контента, не забывайте, что для ранжирования важны не только текстовые критерии, но и полнота информации, коммерческие факторы.
Примерно аналогичная ситуация и с внутренними ссылками. Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Со страницами сайта всё более однозначно. Важно следить за тем, чтобы мусорные, малополезные страницы не попадали в индекс. Для этого есть много методов, которые мы собрали и описали в этой статье.
Вы всегда можете взять у нас консультацию по техническим аспектам оптимизации, или заказать продвижение под ключ, куда входит ежемесячный seo-аудит.
ОТПРАВИТЬ ЗАЯВКУ
Автор: Александр, SEO аналитик SiteClinic.ru
Как закрыть сайт от индексации в robots.txt
Время прочтения: 4 минуты
О чем статья?
- Каким страницам и сайтам не нужно индексирование
- Когда нужно скрыть весь сайт, а когда — только часть его
- Как выбирать теги, закрывающие индексацию
Кому полезна эта статья?
- Контент-редакторам
- Администраторам сайтов
- Владельцам сайтов
Итак, в то время как все ресурсы мира гонятся за вниманием поисковых роботов ради вхождения в ТОП, вы решили скрыться от индексирования. На самом деле для этого может быть масса объективных причин. Например, сайт в разработке или проводится редизайн интерфейса.
Когда закрывать сайт целиком, а когда — его отдельные части?
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Если ресурс имеет большое количество служебной информации, делайте закрытый портал или закрывайте страницы и целые разделы.
Желательно запрещать индексацию так называемых мусорных страниц. Это старые новости, события и мероприятия в календаре. Если у вас интернет-магазин, проверьте, чтобы в поиске не оказались устаревшие акции, скидки и информация о товарах, снятых с продажи. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Лучше скрыть также всплывающие окна и баннеры, скрипты, размещенные на сайте файлы, особенно если последние много весят. Это уменьшит время индексации в целом, что положительно воспринимается поиском, и снизит нагрузку на сервер.
Как узнать, закрыт ресурс или нет?
Чтобы точно знать, идет ли индексация robots txt, сначала проверьте: возможно, закрытие сайта или отдельных страниц уже осуществлено? В этом помогут сервисы поисковиков Яндекс.Вебмастер и Google Search Console. Они покажут, какие url вашего сайта индексируются. Если сайт не добавлен в сервисы поисковиков, можно использовать бесплатный инструмент «Определение возраста документа в Яндексе» от Пиксел Тулс.
Закрываем сайт и его части: пошаговая инструкция.
- Для начала найдите в корневой папке сайта файл robots.txt. Для этого используйте поиск.
- Если ничего не нашли — создайте в Блокноте или другом текстовом редакторе документ с названием robots расширением .txt. Позже его надо будет загрузить в корневую папку сайта.
- Теперь в этом файле HTML-тегами детально распишите, куда заходить роботу, а куда не стоит.
Как полностью закрыть сайт в роботс?
Приведем пример закрытия сайта для основных роботов. Все вместе они обозначаются значком *.
Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. При этом также указывайте запрет для индексации всем роботам или тем из них, кто ищет картинки, видео и т.п. Например, указание Яндексу не засылать к вам поиск картинок будет выглядеть как
Здесь YandexImages — название робота Яндекса, который ищет изображения. Полные списки роботов можно посмотреть в справке поисковых систем.
Как закрыть отдельные разделы/страницы или типы контента?
Выше мы показали, как запрещать основным или вспомогательным роботам заходить на сайт. Можно сделать немного по-другому: не искать имена роботов, отвечающих за поиск картинок, а запретить всем роботам искать на сайте определенный тип контента. В этом случае в директиве Disallow: / указываете либо тип файлов по модели *.расширениефайлов, либо относительный адрес страницы или раздела.
Прячем ненужные ссылки
Иногда скрыть от индексирования нужно ссылку на странице. Для этого у вас есть два варианта.
- В HTML-коде самой этой страницы укажите метатег robots с директивой nofollow. Тогда поисковые роботы не будут переходить по ссылкам на странице, но на них может вести другой материал вашего или сторонних сайтов.
- В саму ссылку добавьте атрибут rel=»nofollow».
Данный атрибут рекомендует роботу не принимать ссылку во внимание. В этом случае запрет индексации работает и тогда, когда поисковая система находит ссылку не через страницу, где переход закрыт в HTML-коде.
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt являются теги, закрывающие индексации сайта или видов контента. Это мета-тег robots. Прописывайте его в исходный код сайта в файле index.html и размещайте в контейнере <head>.
Существуют два варианта записи мета-тега.
Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название: Googlebot, Яндекс.
Поле “content” из 1 варианта может иметь следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
Таким образом, можно запретить индексацию содержимого сайта независимо от файла robots.txt при помощи content=”noindex, follow”. Или разрешить ее частично: например, вы хотите не индексировать текст, а ссылки — пожалуйста. Используйте для разных случаев сочетания значений.
Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические ошибки означают, что правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в панелях инструментах Яндекс.Вебмастер и Google, прежде чем загрузить его на сайт..
Синтаксические — неправильно записаны правила в файле.
Выводы
- Запрет на индексирование — весьма полезная возможность. Убирая служебные, повторяющиеся и устаревшие блоки на страницах, вы повысите уникальность контента и экспертность сайта.
- Для проверки того, какие страницы индексируются, проще всего использовать службы поисковиков, но можно воспользоваться сторонними сервисами.
- Вы можете использовать 2 варианта: закрытие страницы через файл robots.txt или же мета-тег robots в файле index.html. Оба файла находятся в корневом каталоге.
- Закрывая служебную информацию, устаревающие данные, скрипты, сессии и utm-метки, для каждого запрета создавайте отдельное правило в файле robots.txt или отдельный мета-тег.
- Разнообразие настроек позволяет точно отобрать и закрыть те части контента, которые, будучи в поиске, не ведут к конверсии, и при этом не могут быть удалены с сайта.
Материал подготовила Светлана Сирвида-Льорентэ.
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots.txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Тег noindex и атрибут nofollow: что это такое
Тег noindex введен поисковой системой Яндекс. Он предназначен для закрытия от индексации роботами ссылки или части html кода на странице. Имеет следующую структуру:
<noindex> ссылка или часть кода, которые необходимо скрыть, </noindex>
Данный тег не чувствителен к вложенности и может быть размещен в любой части кода. Поисковые машины, кроме Яндекса, воспринимают команду в качестве невалидной. Если валидность кода важна, тег оформляется следующим образом:
<!—noindex—> текст <!—/noindex—>
Функции:
Тег noindex позволяет:
- повысить релевантность страницы поисковым запросам за счет уменьшения доли второстепенной информации и увеличения плотности ключевых слов,
- скрыть дублирующийся контент, за использование которого может последовать пессимизация сайта в выдаче Яндекса,
- сохранять статический вес страниц и управлять его передачей, так как закрытие одних ссылок пропорционально увеличивает вИЦ оставшихся,
- улучшить сниппет. Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,
- скрыть от роботов лишние данные (коды счетчиков, ссылки на сайты с постоянно изменяющейся информацией и т.д.).
Nofollow
Атрибут nofollow не оказывает влияния на индексацию ссылок, но сообщает поисковым роботам, что вес данного линка равен нулю. При продвижении сайта это позволяет сохранить его PR и тИЦ, которые на указанную страницу не передаются. Поисковые боты (кроме googlebot) по ссылке переходят. Атрибут поддерживают Google, Yahoo и Яндекс (с 30 апреля 2010 года). Структура написания параметра следующая:
анкор ссылки
Атрибут nofollow используют для ссылок на все сайты, которым не требуется передавать TrustRank ресурса-донора. Для внутренней перелинковки прием не применяется.
Noindex и nofollow позволяют закрыть от индексацию не только отдельную ссылку, но и всю страницу (прописываются внутри нее или в файле robots.txt):
<Meta name=”robot” content=”noindex, nofollow”>
или
<html>
<head>
<meta content=”nofollow”/>
<title>Заголовок данной страницы</title>
</head>
Nofollow и noindex могут использоваться совместно:
<noindex><a rel=»nofollow» href=»http://example.ru»> анкор ссылки</a></noindex>.
В таком случае поисковый робот Google ссылку проигнорирует, а Яндекса не увидит.
Другие термины на букву «N»
Совпадений не найдено
Все термины SEO-Википедии
Теги термина
Как заблокировать часть страницы от индексации Google или другими поисковыми системами
Google и другие поисковые системы следуют протоколу исключения роботов, более известному как robots.txt. Этот протокол позволяет веб-мастеру предотвращать доступ пауков поисковых систем (и других типов роботов) к определенным веб-страницам.
Но что, если вы хотите запретить поисковым системам индексировать часть страницы? Вы можете сделать это, если на вашей странице есть реклама или другой текст, не имеющий отношения к теме страницы.В качестве примера приведем фрагмент поиска Google с частью ежегодного сообщения Википедии о сборе средств.
Это не очень хорошо для пользователей и не очень хорошо для веб-мастеров. К счастью, есть простой способ предотвратить подобную ситуацию.
Как заблокировать часть страницы
Во-первых, вам нужно понять, как заблокировать индексирование всей страницы. Есть два метода:
1. Используйте файл robots.txt. Добавьте такой код, заменив somepage на настоящее имя вашей страницы:
2.Используйте метатег robots. Добавьте этот тег в раздел страницы, которую вы хотите заблокировать:
Теперь, чтобы Google исключил часть страницы, вам нужно будет поместить это содержимое в отдельный файл, например excluded.html, и использовать iframe для отображения этого содержимого на главной странице.
Тег iframe захватывает содержимое из другого файла и вставляет его на главную страницу. Наконец, используйте любой из описанных выше методов, чтобы заблокировать поисковыми системами индексировать файл excluded.html.
Методы, которые не работают надежно
В прошлом веб-мастера использовали JavaScript или Flash, чтобы скрыть контент от поисковых систем.С 2014 года это больше не работает для Google, потому что у них есть возможность сканировать и индексировать контент, созданный с помощью JavaScript или Flash. Если ваш JavaScript или Flash-контент не имеет отношения к теме вашей страницы, вы захотите использовать более надежный метод, чтобы предотвратить его индексирование.
Есть вопросы или вам нужна дополнительная информация? Свяжитесь с нами сегодня.
Индексирование поиска блоков
с помощью noindex
Вы можете запретить отображение страницы в поиске Google, указав noindex
метатег в HTML-коде страницы или путем возврата заголовка noindex в HTTP
отклик.Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он сбросит
эта страница полностью из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
Важно : Чтобы директива noindex вступила в силу, страница
не должен блокироваться файлом robots.txt, иначе это должно быть
доступный для краулера. Если страница заблокирована
robots.txt или сканер не может получить доступ к странице, он никогда не увидит
noindex , и страница по-прежнему может отображаться в результатах поиска, например
если на него ссылаются другие страницы.
Использование noindex полезно, если у вас нет root-доступа к вашему серверу, поскольку он
позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex
Есть два способа реализовать noindex : как метатег и как HTTP-ответ.
заголовок. У них такой же эффект; выберите способ, который удобнее для вашего сайта.
тег
Чтобы большинство поисковых роботов поисковых систем не проиндексировали страницу вашего сайта, поместите
следующий метатег в раздел вашей страницы:
Чтобы запретить только поисковым роботам Google индексировать страницу:
Имейте в виду, что некоторые веб-сканеры поисковых систем могут интерпретировать
noindex иначе.В результате возможно, что ваша страница
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о метатеге noindex .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением
либо noindex , либо none в вашем ответе. Вот пример
HTTP-ответ с X-Robots-Tag , инструктирующий сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Тег: noindex (…)
Узнайте больше о заголовке ответа noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть метатеги и заголовки HTTP. Если страница все еще
появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили
ярлык. Вы можете запросить у Google повторное сканирование страницы с помощью
Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из Интернета.
сканеры, поэтому они не видят тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой
файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя
robots.txt Тестер
орудие труда.
Создать и обновить индекс
В указателе перечислены термины и темы, обсуждаемые в документе, а также страницы, на которых они появляются.Чтобы создать указатель, вы помечаете записи указателя, предоставляя имя основной записи и перекрестную ссылку в вашем документе, а затем вы создаете указатель.
Вы можете создать запись указателя для отдельного слова, фразы или символа, для темы, которая охватывает диапазон страниц или ссылается на другую запись, например «Транспорт. См. Велосипеды». Когда вы выделяете текст и помечаете его как запись указателя, Word добавляет специальное поле XE (запись указателя), которое включает отмеченную основную запись и любую информацию о перекрестных ссылках, которую вы хотите включить.
После того, как вы отметите все записи указателя, вы выбираете дизайн указателя и строите готовый указатель. Word собирает записи указателя, сортирует их в алфавитном порядке, ссылается на их номера страниц, находит и удаляет повторяющиеся записи с одной и той же страницы и отображает указатель в документе.
Отметить записи
Эти шаги показывают вам, как пометить слова или фразы для вашего указателя, но вы также можете пометить записи указателя для текста, который охватывает диапазон страниц.
Выберите текст, который вы хотите использовать в качестве записи указателя, или просто щелкните то место, куда вы хотите вставить запись.
На вкладке Ссылки в группе Индекс щелкните Отметить запись .
Вы можете редактировать текст в диалоговом окне Mark Index Entry .
Вы можете добавить второй уровень в поле Subentry .Если вам нужен третий уровень, поставьте после текста подстатьи двоеточие.
Чтобы создать перекрестную ссылку на другую запись, щелкните Перекрестная ссылка в разделе Параметры , а затем введите текст для другой записи в поле.
Чтобы отформатировать номера страниц, которые будут отображаться в указателе, установите флажок Полужирный или Курсив под Формат номера страницы .
Щелкните Отметьте , чтобы отметить запись указателя. Чтобы отметить этот текст везде, где он отображается в документе, нажмите Отметить все .
Чтобы отметить дополнительные записи указателя, выделите текст, щелкните в диалоговом окне Отметить запись указателя и затем повторите шаги 3 и 4.
Создать индекс
После того, как вы отметите записи, вы готовы вставить указатель в свой документ.
Щелкните в том месте, где вы хотите добавить индекс.
На вкладке Ссылки в группе Индекс щелкните Вставить индекс .
В диалоговом окне Индекс вы можете выбрать формат для текстовых записей, номеров страниц, табуляции и начальных символов.
Вы можете изменить общий вид индекса, выбрав из раскрывающегося меню Форматы .Предварительный просмотр отображается в окне вверху слева.
Щелкните ОК .
Отредактируйте или отформатируйте запись указателя и обновите указатель
Если вы отметите больше записей после создания указателя, вам необходимо обновить указатель, чтобы они были видны.
Если вы не видите поля XE, нажмите Показать / скрыть
в группе Параграф на вкладке Домашняя страница .
Найдите поле XE для записи, которую вы хотите изменить, например, { XE «Callisto» \ t « См. Moons» } .
Чтобы отредактировать или отформатировать запись указателя, измените текст внутри кавычек.
Чтобы обновить указатель, щелкните указатель и нажмите F9. Или щелкните Обновить индекс в группе Индекс на вкладке Ссылки .
Если вы обнаружите ошибку в указателе, найдите запись указателя, которую вы хотите изменить, внесите изменения, а затем обновите указатель.
Удалить запись индекса и обновить индекс
Выделите все поле ввода указателя, включая фигурные скобки ( {} ), а затем нажмите DELETE.
Если вы не видите поля XE, нажмите Показать / скрыть
в группе Параграф на вкладке Домашняя страница .
Чтобы обновить указатель, щелкните указатель и нажмите F9. Или щелкните Обновить индекс в группе Индекс на вкладке Ссылки .
Блокировать страницы или сообщения блога от индексации поисковыми системами
Есть несколько способов запретить поисковым системам индексировать определенные страницы вашего сайта. Рекомендуется тщательно изучить каждый из этих методов, прежде чем вносить какие-либо изменения, чтобы гарантировать, что только нужные страницы заблокированы для поисковых систем.
Обратите внимание: : эти инструкции блокируют индексирование URL страницы для поиска. Узнайте, как настроить URL-адрес файла в инструменте файлов, чтобы заблокировать его от поисковых систем.
Файл Robots.txt
Ваш файл robots.txt — это файл на вашем веб-сайте, который сканеры поисковых систем читают, чтобы узнать, какие страницы они должны и не должны индексировать. Узнайте, как настроить файл robots.txt в HubSpot.
Google и другие поисковые системы не могут задним числом удалять страницы из результатов после того, как вы внедрили robots.txt метод файла. Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент (например, если на вашу страницу есть входящие ссылки с других веб-сайтов). Если ваша страница уже проиндексирована и вы хотите удалить ее из поисковых систем задним числом, рекомендуется вместо этого использовать метод метатега «Без индекса».
Мета-тег «Без индекса»
Обратите внимание: : , если вы решите использовать метод метатега «Без индекса», имейте в виду, что его не следует комбинировать с роботами.txt метод файла. Поисковым системам необходимо начать сканирование страницы, чтобы увидеть метатег «Без индекса», а файл robots.txt полностью предотвращает сканирование.
Мета-тег «без индекса» — это строка кода, введенная в раздел заголовка HTML-кода страницы, который сообщает поисковым системам не индексировать страницу.
- Щелкните имя определенной страницы или сообщения в блоге.
- В редакторе содержимого щелкните вкладку Настройки .
- Щелкните Дополнительные параметры .
- В разделе Head HTML скопируйте и вставьте следующий код:
Консоль поиска Google
Если у вас есть учетная запись Google Search Console , вы можете отправить URL-адрес для удаления из результатов поиска Google. Обратите внимание, что это будет применяться только к результатам поиска Google.
Если вы хотите заблокировать файлы в файловом менеджере HubSpot (например, PDF-документ) от индексации поисковыми системами, вы должны выбрать подключенный субдомен для файла (ов) и использовать URL-адрес файла для блокировки веб-сканеров.
Как HubSpot обрабатывает запросы от пользовательского агента
Если вы устанавливаете строку пользовательского агента для проверки сканирования вашего веб-сайта и видите сообщение об отказе в доступе, это ожидаемое поведение. Google все еще сканирует и индексирует ваш сайт.
Причина, по которой вы видите это сообщение, заключается в том, что HubSpot разрешает запросы от пользовательского агента googlebot только с IP-адресов, принадлежащих Google. Чтобы защитить сайты, размещенные на HubSpot, от злоумышленников или спуферов, запросы с других IP-адресов будут отклонены.HubSpot делает это и для других сканеров поисковых систем, таких как BingBot, MSNBot и Baiduspider.
SEO
Целевые страницы
Блог
Настройки аккаунта
Страницы веб-сайта
Правильный способ предотвращения индексации вашего сайта • Yoast
Йост де Валк
Йост де Валк — основатель и директор по продуктам Yoast.Он интернет-предприниматель, который незадолго до основания Yoast инвестировал и консультировал несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Мы уже говорили это когда-то, но мы повторим: нас удивляет, что до сих пор есть люди, использующие только файла robots.txt , чтобы предотвратить индексацию своего сайта в Google или Bing. В результате их сайт все равно появляется в поисковых системах. Вы знаете, почему это нас удивляет? Потому что robots.txt на самом деле не выполняет последнего, хотя и предотвращает индексацию вашего сайта. Позвольте мне объяснить, как это работает, в этом посте.
Чтобы узнать больше о robots.txt, прочтите robots.txt: полное руководство. Или найдите лучшие методы работы с robots.txt в WordPress.
Есть разница между индексированием и включением в Google
Прежде чем мы продолжим объяснять вещи, нам нужно сначала остановиться на некоторых терминах:
- Индексирование / индексирование
Процесс загрузки сайта или содержимого страницы на сервер поисковой системы с добавлением его в свой «индекс».” - Рейтинг / Листинг / Отображение
Отображение сайта на страницах результатов поиска (также известных как SERP).
Таким образом, хотя наиболее распространенный процесс идет от индексирования к листингу, сайт не обязательно должен быть проиндексирован как , чтобы попасть в список. Если ссылка указывает на страницу, домен или другое место, Google перейдет по этой ссылке. Если файл robots.txt в этом домене препятствует индексации этой страницы поисковой системой, он все равно будет показывать URL в результатах, если он может быть получен из других переменных, на которые, возможно, стоит обратить внимание.
Раньше это мог быть DMOZ или каталог Yahoo, но я могу представить, что Google использует, например, данные о вашем бизнесе в наши дни или старые данные из этих проектов. Больше сайтов резюмируют ваш сайт, верно.
Теперь, если приведенное выше объяснение не имеет смысла, взгляните на это видеообъяснение бывшего сотрудника Google Мэтта Каттса из 2009 г .:
Если у вас есть причины для предотвращения индексации вашего веб-сайта, добавление этого запроса на конкретную страницу, которую вы хотите заблокировать, как говорит Мэтт, по-прежнему является правильным способом.
Но вам нужно сообщить Google об этом метатеге robots. Итак, если вы хотите эффективно скрыть страницы от поисковых систем, вам нужно , чтобы проиндексировали этих страниц. Хотя это может показаться противоречивым. Это можно сделать двумя способами.
Предотвратить листинг вашей страницы, добавив метатег роботов
Первый способ предотвратить размещение вашей страницы в списке — использовать метатеги robots. У нас есть подробное руководство по метатегам роботов, которое более обширно, но в основном оно сводится к добавлению этого тега на вашу страницу:
Если вы используете Yoast SEO, это очень просто! Самостоятельно добавлять код не нужно.Узнайте, как добавить тег noindex с помощью Yoast SEO здесь.
Проблема с таким тегом в том, что его нужно добавлять на каждую страницу.
Управление метатегами роботов упрощено в Yoast SEO
Чтобы упростить процесс добавления метатега robots на каждую страницу вашего сайта, поисковые системы разработали HTTP-заголовок X-Robots-Tag. Это позволяет вам указать HTTP-заголовок с именем X-Robots-Tag и установить значение так же, как и значение мета-тегов robots.Самое замечательное в этом то, что вы можете сделать это для всего сайта. Если ваш сайт работает на Apache и включен mod_headers (обычно это так), вы можете добавить следующую единственную строку в свой файл .htaccess :
Заголовочный набор X-Robots-Tag "noindex, nofollow"
И это приведет к тому, что весь сайт может быть проиндексирован . Но никогда не будет отображаться в результатах поиска.
Итак, избавьтесь от этого файла robots.txt с помощью Disallow: / в it.Используйте вместо этого X-Robots-Tag или этот метатег robots!
Подробнее: Полное руководство по метатегу роботов »
Как проиндексировать книгу
Подготовка индекса
Стандартное требование Wiley — это единый комбинированный указатель предметов и имен. Имена авторов индексируются только в том случае, если обнаруживается предметное обсуждение автора или его работы в тексте. Если вы хотите, чтобы в указатель записывался каждый случай, когда в вашей книге обсуждается работа отдельного человека, обратитесь за одобрением к редактору проекта, так как там может не хватить места.
Специализированные указатели других тем, таких как роды и виды, географические названия (географический справочник), названия лекарств, органические соединения, формулы, случаи и уставы, или первые строки стихов могут быть предоставлены после обсуждения и утверждения редактором вашего проекта.
Если вам нужна помощь в подготовке индекса, обсудите любые проблемы с редактором проекта, чтобы избежать задержки публикации.
Когда и как индексировать
Индексирование может быть выполнено во время подачи рукописи с помощью функции индексации Word:
- Получите разрешение от вашего контактного лица Wiley на использование этой функции для составления индекса.
- Вы будете нести ответственность за добавление фактических номеров страниц в пробные оттиски, поскольку индекс, созданный с использованием страниц рукописи Word, не соответствует договорному соглашению об окончательном индексе.
Или, после изготовления оттисков:
- Из PDF-файлов. Если из-за исправлений потребуется значительная перегруппировка оттисков страниц, индекс может быть составлен из отредактированных оттисков. Пожалуйста, получите предварительное одобрение вашего контактного лица по управлению контентом Wiley, если вы хотите проиндексировать отредактированные копии страниц.
Длина индекса и сроки
Идеальная длина страницы должна составлять 4-6% от общего числа страниц наборной книги. Например, 300-страничная книга будет иметь законченный наборный указатель из 12-18 страниц, каждая из которых содержит примерно 100 статей и подстатьей.
Для особенно насыщенного содержания может быть уместным более длинный указатель, но, пожалуйста, обсудите со своим контактным лицом в Wiley, если это ваше намерение, поскольку могут быть ограничения на интервалы.
Обычно крайний срок подачи указателя составляет три недели с момента получения оттисков.Серьезная задержка публикации может быть вызвана опозданием с указателем.
Для надлежащей подготовки указателя требуется 10–15 часов на 100 страниц набора. Например, книга объемом 300 страниц потребует 30–45 часов подготовки. Пожалуйста, выделите достаточно времени для индексации.
Индексирование полезных подсказок
- Прочтите корректуру или рукопись.
- Составьте список терминов, которые будут появляться.
- Разделите эти термины на основные статьи и подстатьи.
- Добавьте номера страниц для каждой значимой ссылки на выбранный термин.
- Расположите в алфавитном порядке все основные статьи и главные слова подстатьей. Предлоги и артикли не относятся к алфавиту.
- Удалите повторяющиеся записи, объедините похожие записи (например, формы единственного и множественного числа одного и того же термина) и предоставьте перекрестные ссылки.
- Определите шаблоны, которые можно развивать дальше (в структуре статей, в виде перекрестных ссылок).
- Исправьте все остаточные опечатки или стилистические несоответствия между указателем и окончательным текстом вашей книги.
- Убедитесь, что все перекрестные ссылки «see» и «see also» указывают на действительную запись, и используют точную формулировку и написание этой записи.
- Перечислите номера страниц записей в порядке номеров.
- Поставьте себя на роль читателя. Вы лучше всех знаете текст и аргументы книги; тем не менее, немного отступите от текста и спросите: что ваши читатели будут искать в указателе?
- Определите наиболее вероятные поисковые запросы. Изучите указатели книг на похожие темы, чтобы определить, что полезно, а что не так полезно для вас как читателя.
- Обеспечьте постоянный уровень индексации повсюду. Не «переоценивайте» одни части, исключая другие.
- Индексируйте все важные темы и концепции, включая те, которые прямо не упомянуты в содержании или структуре заголовка.
- Избегайте перечисления всех упоминаний имен собственных (людей, мест) только потому, что они были обнаружены при поиске по слову.
- Различайте мимолетное иллюстративное использование и предметное обсуждение.
Что не индексировать
- Содержание записей.
- Предисловие, если оно не содержит существенной информации, которой нет в других местах книги.
- Имена авторов, если их другая работа подробно не обсуждается в тексте.
- Примечания, если они не содержат существенной информации.
- Ссылки, дополнительная литература, библиография или глоссарий.
Стиль
- Следуйте тем же стилям использования заглавных букв, орфографии и расстановки переносов, которые использовались в тексте после редактирования.
- Все элементы указателя, кроме имен собственных, должны начинаться с букв нижнего регистра.
- Когда разные термины или варианты написания одной и той же статьи используются в главах, написанных несколькими авторами, следует выбрать только один вариант и последовательно использовать его во всем указателе.
- Если хотите, укажите номера страниц, относящиеся к рисункам, выделив их курсивом, а те, которые относятся к таблицам, — жирным шрифтом. Добавьте объяснение этого использования в примечание в начале указателя.
- В учебнике для учащихся может быть полезно выделить номер индексной страницы, который соответствует введению или определению ключевого понятия в основном тексте, но это не должно использоваться в сочетании с вышеуказанным соглашением re.таблицы. Объясните использование в примечании в начале указателя.
В алфавитном порядке
Упорядочивайте по алфавиту последовательно по буквам. Или, если вы привыкли составлять указатели с пословной алфавитной системой, вы можете составить указатель в этом стиле.
Буквенная система игнорирует пробелы, дефисы и другие знаки препинания вплоть до запятой, обозначающей инверсию заголовка. Таким образом, записи располагаются в алфавитном порядке в виде одной строки символов (например, «публикации» предшествуют «общественным работам»).
Предлоги и союзы игнорировать, кроме случаев, когда они встречаются в названии или составном существительном (например, в «сигнал-шум»).
Когда статья указателя состоит из прилагательного и существительного, расположение по алфавиту определяется в соответствии с существительным (например, реформа, конституция).
Mc и Mac упорядочиваются по буквам по мере их появления; de и De, van и Van упорядочены как D и V соответственно.
Alphabetize St. как Святой и США как Соединенные Штаты.
Заказывайте записи, начиная с статей на иностранном языке (например, Le или Il) по буквам.
Записи, состоящие только из цифр (например, 80386), перечислены перед буквой A.
Расположите отдельные числа так, как если бы они были написаны по алфавиту. Например, «Даунинг-стрит, 10» следует за словом «буря».
Записи, состоящие из символов, перечислены после букв (но см. Специальные правила для химических терминов).
Индексные записи
Записи указателя не должны начинаться со статьи (например,грамм. ‘A’ или ‘the’) или предлог (например, ‘in’, ’on,’ ‘below’).
Основные статьи должны быть как можно более конкретными существительными. Например, «характеристики водорослей» является приемлемым тематическим заголовком в тексте, но читатели вряд ли будут искать информацию о водорослях под абстрактным существительным «характеристики». Правильная запись в указателе — «водоросли, характеристики».
Никогда не используйте прилагательное в качестве записи. Например, прилагательное «абсолютный» само по себе не подходит, но «абсолютная влажность» может быть правильным.
Если в качестве основной записи используется незнакомая аббревиатура или аббревиатура, ее следует указать в следующих скобках, например TCS (Total Conservation Solutions).
Если вы индексируете человека, включайте имя (или хотя бы инициал), даже если в тексте упоминается только фамилия (фамилия). Постарайтесь, насколько это возможно, последовательно использовать имена или инициалы в указателе.
Если несколько записей содержат один и тот же ключевой термин, сделайте этот термин основной записью и настройте отдельные записи как подстатьи.
Двойные записи
Двойные записи возникают, когда запись может быть представлена в двух (или более) формах. Общие типы включают:
- Аббревиатура и полная форма
- Синонимы или имя и псевдоним
- Не менее важные части заглавного слова: «разведение, рыба» и «рыбоводство»
Вам НЕ требуются двойные записи, если у вас есть два термина для одного и того же понятия (например: атомно-абсорбционная спектрометрия или AAS). В этом случае просто укажите термин, который, по вашему мнению, читатель, скорее всего, будет искать.
Если вы считаете, что двойная запись была бы полезной, рассмотрите следующий вопрос:
Нужно ли читателю понимать, что между двумя терминами существует связь?
- Если читателю будет полезно такое понимание, используйте перекрестную ссылку «см.».
- Если в этом нет необходимости, и если имеется пять или меньше ссылок на страницы и нет подстатьей, то для читателя более полезно перечислить все ссылки на страницы в обоих местах.
- Перечислите экземпляры любого термина в обоих местах, если различие между ними не имеет смысла.В этом случае вы можете указать альтернативный термин под перекрестной ссылкой «см. Также».
Когда запись встречается как в единственном, так и во множественном числе, объедините их, добавьте букву «s» в скобках и расположите по алфавиту в форме единственного числа.
Если у слова есть два или более синонима, используйте тот, который читатель, скорее всего, найдет; не включайте оба, если ссылки на страницы разделены между ними.
Подразделы и подподразделы
Размещайте подстатьи, используя отступ (одна табуляция), а не запускайте их.Это понятнее для читателя, если индекс достаточно сложен или основные записи имеют множество подстатьей.
Подстатьи, как правило, также следует перечислять в алфавитном порядке, игнорируя начальные «маленькие» слова, такие как «и», «at», «by», «in», «of» и «with». Подстатьи — это хронологическое расположение в учебниках истории и биографиях, если это делает развитие темы более понятным для читателя.
Необязательно использовать предлоги с каждой подстатьей, чтобы показать связь с основной записью (‘at,’ ‘in,’ ‘on и т. Д.). Такие предлоги наиболее полезны, когда в противном случае отношения могли бы быть неоднозначными. Если вы используете предлоги, будьте последовательны в похожих записях.
Мы не рекомендуем использовать подстатьи. Но если вы это сделаете, укажите, пожалуйста, с дополнительным отступом (две табуляции).
Если возможно, сопоставьте структуру подстатьи, например если вы предоставляете индексные записи для нескольких политиков, проиндексируйте все как:
- Имя политика
- законопроектов принято
- позиция шкафа
- колледж
- первое сообщение
- школьные дни
Индексирование перекрестных ссылок
Перекрестные ссылки в указателе используются либо для того, чтобы указать читателю на дополнительную информацию («см. Также») или на другое заглавное слово («см.»).
Перекрестная ссылка, обозначенная словом «увидеть», также не содержит ссылок на страницы: здесь «увидеть» означает, что читатель найдет то, что он ожидал найти здесь, где-то еще в указателе.
Слово «см.» Используется для указания от важной подстатьи под одним заголовком к отдельному главному заголовку. Тип перекрестной ссылки «см.» Полезен для связи между синонимами или акронимами / аббревиатурами и полными формами (но см. «Двойные записи» выше).
Перекрестная ссылка, обозначенная «см. Также», следует за набором ссылок на страницы или же присоединяется к основному заголовку, имеющему подзаголовки.Это говорит читателю, что больше информации можно получить в другом месте.
Для ссылки на подстатью можно использовать форму «см. X под Y», где X — подстать, а Y — основная запись. В качестве альтернативы, чтобы избежать строки перекрестных ссылок, вы можете использовать общий термин (выделенный курсивом), например, см. Под именами отдельных элементов.
Индексные заметки
Примечания обычно представляют собой материал, который является скорее второстепенным, чем центральным по отношению к основному тексту. Их следует индексировать только в том случае, если они содержат существенную информацию.
Указатель ссылок на примечания должен быть в форме «96n», где 96 — номер страницы.
Если вы хотите проиндексировать контент в заметке, используйте «n.» Плюс номер заметки (например, 96n.3) для одной ссылки или «nn.», Если вы делаете ссылку на несколько заметок, появляющихся на одной странице. (например, 96nn.3, 5, 7).
Нумерация
Номера страниц перечислены в порядке номеров и отделены от их записей и друг от друга запятыми.
Основные записи, за которыми следует длинная строка номеров страниц, заставят читателя выполнить поиск по многим страницам, прежде чем найти необходимую информацию.Хорошее практическое правило — генерировать подстатьи , когда имеется более пяти ссылок на страницы.
Различать непрерывные обсуждения темы на двух или более страницах (когда ссылка на страницу дана в виде одного диапазона: «30–36») и дискретные упоминания темы в отрывке текста (’30, 31, 36 ‘).
Диапазоны страниц всегда следует записывать полностью следующим образом: 16–17, 23–24, 113–114, 129–130, 200–211 и т. Д. Не используйте «ff».’(‘ И следующие страницы ’) дают номера заключительных страниц.
Обратите внимание, что при наборе текста мы будем использовать правило между диапазонами страниц, а не дефис.
Если вы не используете запятую между каждым заглавным словом и его указателем первой страницы, поместите там два символьных пробела.
Если вы обнаружите, что у вас возникает соблазн указать длинный диапазон страниц (‘750–805’), совпадающий со всей главой, или использовать такую форму, как ‘Chapter 7 passim’, это хорошее указание на то, что вам нужно ввести подстатьи. вместо этого, чтобы прервать обсуждение.
Химические термины
Химические термины сначала располагаются в алфавитном порядке по названиям соединений, без учета всех символов префикса, цифр и букв. Не обращайте внимания на круглые и квадратные скобки, окружающие части слов в составных словах. Например, 1,2-диол указан в разделе D., а S-гидрокситриптамин — в разделе H.
.
Если одно и то же соединение встречается несколько раз, но с разными префиксами, эти записи следует отсортировать, расположив префиксы в следующем порядке: курсивные буквы, буквы греческого алфавита, строчные буквы, цифры.
Если одно и то же соединение представлено как с префиксом, так и без него, сначала идет соединение без префикса. Например:
- Аминоантрахинон, 512
- 1-Аминоантрахинон, 514
- 7-аминоантрахинон, 517
В подсорте подобных соединений префикс имеет приоритет, а числа в теле записи — следующий приоритет. Например:
- 2-метил-1–1,3-бутадиен, 998
- 3-Метил-1,2-бутадиен, 997
- 1-Нафтол-3-сульфоновая кислота, 1153
- 1-Нафтол-4-сульфоновая кислота, 1128
- 2-Нафтол-1-сульфоновая кислота, 1154
Подача индекса
- Одинарный интервал — индекс, оставляя лишнюю строчку между каждой буквой алфавита.
- Отправьте индексный файл рукописи своему контактному лицу в Wiley в соответствии с предоставленным графиком.
- PDF-файл вашего индекса не нужен, если он не содержит каких-либо специальных символов, которые могут быть потеряны при передаче документа Word или другого типа файла.
- Укажите список всех специальных символов, которые не будут отображаться в файле.
Дополнительная информация и советы
Вы можете найти полезную дополнительную информацию об индексировании в следующих сетевых и печатных источниках контента (перечисленных в порядке дат)
- Американское общество индексирования: http: // www.asindexing.org [бесплатно].
- Общество индексаторов: http://www.indexers.org.uk/ [бесплатно].
- Чикагское руководство по стилю: Основное руководство для писателей, редакторов и издателей. 16-е изд. Издательство Чикагского университета. http://www.chicagomanualofstyle.org/home.html [за платным доступом].
- Батчер, Дж., 2006. Копирование-редактирование. 4-е изд. Издательство Кембриджского университета.
- Риттер, Р. М., 2002. Оксфордское руководство по стилю. Издательство Оксфордского университета.
- Бут, П., 2001. Индексирование: Руководство по передовой практике.Мюнхен: K.G. Саур.
- BS ISO 999: 1996. Информация и документация: Руководство по содержанию, организации и представлению указателей. http://www.iso.org/iso/iso_catalogue [за платным доступом].
- Wellisch, H., 1995. Индексирование от А до Я 2-е изд. Нью-Йорк: H.W. Уилсон.
- Малвани, Северная Каролина, 1994. Индексирование книг. Издательство Чикагского университета.
- Андерсон, доктор медицины, 1985. Индексирование книг. Издательство Кембриджского университета
Отключить индексацию поисковой системой | Webflow University
В этом видео используется старый интерфейс.Скоро выйдет обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, а какие нет на вашем сайте, написав файл robots.txt. Вы можете запретить сканирование страниц, папок, всего вашего сайта. Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
В этом уроке
Отключение индексации поддоменов Webflow
Вы можете запретить Google и другим поисковым системам индексировать веб-поток.io, просто отключив индексацию в настройках вашего проекта.
- Перейдите в Настройки проекта → SEO → Индексирование
- Установите Отключить индексирование поддоменов на «Да»
- Сохраните изменения и опубликуйте свой сайт
Будет опубликован уникальный файл robots.txt только на поддомене говорит поисковым системам игнорировать домен.
Создание файла robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, которые вы не хотите, чтобы поисковые системы сканировали.Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать .
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена. Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках своего проекта.
- Перейдите в Настройки проекта → SEO → Индексирование
- Добавьте нужные правила robots.txt (см. Ниже)
- Сохраните изменения и опубликуйте свой сайт
Создайте роботов .txt для своего сайта, добавив правила для роботов, сохранив изменения и опубликовав свой сайт.
Правила Robots.txt
Вы можете использовать любое из этих правил для заполнения файла robots.txt.
- User-agent: * означает, что этот раздел применим ко всем роботам.
- Disallow: запрещает роботу посещать сайт, страницу или папку.
Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: / page-name
Чтобы скрыть всю папку страниц
User-agent: *
Disallow: / folder-name /
Чтобы включить карту сайта
Sitemap: https: // your-site.com / sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt
Необходимо знать
- Содержимое вашего сайта может быть проиндексировано, даже если оно не было просканировано. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент в другом онлайн-контенте. Чтобы страница не проиндексировалась, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex.
- Кто угодно может получить доступ к robots вашего сайта.txt, чтобы они могли идентифицировать ваш личный контент и получить к нему доступ.
Добавить комментарий