
Как закрыть сайт или страницу от индексации в Google и Яндекс
Существует множество причин, по которым возникает необходимость скрыть от поисковых роботов ту или иную часть сайта, а может и полностью весь ресурс. Если на сайте размещен неуникальный контент, его нужно спрятать от поисковиков, в обязательном порядке скрывают технические страницы, админки и прочее. Если на сайте имеется повторяющийся элемент контента, то такие страницы также лучше скрыть.
В арсенале имеется несколько способов скрытия контента, отдельных страниц или сайта полностью.
Скрываем от поисковых роботов домен
Мы представляем вам несколько способов закрыть домен от индексации:
- Использовать файл robots.txt.
В файле прописываем строки:
User-agent: *
Disallow: /
— Такой синтаксис позволяет скрыть ресурс полностью от всех поисковых систем. Существует вариант для каждой поисковой системы отдельно. Для этого необходимо прописать отдельную строку к каждому поисковику:
Для этого необходимо прописать отдельную строку к каждому поисковику:
User-agent: yandex
Disallow: /
— Следующая комбинация позволяет скрыть сайт от всех поисковых машин,кроме одной определенной:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Чтобы ваш сайт действительно не попал в индекс, файл роботс должен быть написан строго по синтаксису, иначе вы рискуете продемонстрировать поисковым роботам нежелательные страницы ресурса.
- Использование мета-тега
Также домен закрывается от индексации путем добавление в код страницы мета-тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Мета-тег размещается в HEAD кода HTML той страницы, которую необходимо скрыть. Такой метод удобнее применять, когда необходимо скрыть отдельные страницы.
- Использование .htaccess
Такой способ позволяет закрывать отдельные страницы, защищенные паролем, от поисковых роботов. Особенность данного метода заключается в том, что процедура ввода пароля доступна не всем парсерам, следовательно, полностью проверить ресурс на наличие ошибок будет невозможно.
Особенность данного метода заключается в том, что процедура ввода пароля доступна не всем парсерам, следовательно, полностью проверить ресурс на наличие ошибок будет невозможно.
Процесс закрытия текста от поисковых машин
На сегодняшний день имеется возможность скрыть от индекса любую часть текстового контента, будь то меню, ссылки, текст и прочее. В этом случае метод с использованием <noindex> не эффективен. На данном этапе активно используется закрытие от индексации посредством Javaskript. Производится кодирование элементов с помощью JS в виде отдельных скриптов, которые скрываются от индекса с помощью Robots.txt.
Данный метод хорошо применять, к примеру, для большого количества ссылок, чтобы было удобней распределять их вес по страницам. Это поможет избежать путаницы. Остальные элементы также можно скрывать от индексации, будь то обычный текст, пункты меню, ссылки и даже изображения.
Хотя этот метод и считается одним из самых удобных, но Google рекомендует избегать его, так как пользователи должны видеть на сайте файлы формата JS и CSS.
Как скрыть отдельную страницу?
Для закрытия отдельной страницы от роботов лучше всего использовать Robots.txt и мета-тег <noindex>.
Первый вариант подразумевает под собой использование следующей комбинации, которая включает в себя элемент для скрытия (в данном случае это ссылка на страницу):
User-agent: ag
Disallow: http://site.com/page
После добавления такого текста в файл роботс, скорее всего желаемая страница будет скрыта от поисковых роботов, но стопроцентной гарантии нет.
Лучший вариант – это использование мета-тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Благодаря мета-тегу файл роботс не будет нагружен лишними элементами, так как он добавляется HEAD HTML страницы. Robots.txt может перегружаться, когда нужно скрыть не одну страницу, а, к примеру, 100-200 и более.
Как скрыть раздел по параметру URL?
Если страницы имеют общий параметр, по которому их можно объединить, то можно поступить следующим образом:
Рассмотрим пример, когда в определенном разделе сайта расположена информация, которую необходимо скрыть от индексации. Она объединяется единой папкой или разделом.
Она объединяется единой папкой или разделом.
Чтобы скрыть весь раздел или папку необходимо прописать такие строки в роботс:
Disallow: /папка/ или Disallow: /Раздел/*
Для полной гарантии скрытия файлов от индексации, лучше воспользоваться еще одним методом с мета-тегом:
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Такую строку добавляют в HTML-код каждой страницы, которую нужно скрыть.
Дополнительные способы скрыть страницы сайта от поисковых роботов
Существует еще несколько способов закрытия информации от индекса, но они относятся к более рискованным, нежели упомянутые выше. Можно заблокировать запросы от User-agents, которых нежелательно пропускать на сайт, к примеру, они несут какую-то опасность ресурсу или же перегружают систему лишними запросами.
Для скрытия информации на сайте используйте только те методы, которые не вызывают у вас сомнения, чтобы ненужный контент не попал в поле зрения поисковых ботов.
Любой поисковик, парсер и т.п. можно назвать вредоносным и не подпустить его к сайту. Только если вы уверены в своих действиях и имеете опыт в этом деле, тогда можно использовать данный метод. В ином случае вы рискуете еще больше навредить сайту, нежели защитить его от роботов наподобие Ахревса и прочих.
Применение HTTP-заголовка
X-robots-Tag – это часть HTTP-заголовка, которая соответствует определенному URL. Все директивы, которые содержит в себе мета-тег роботс, применяются и к данному заголовку. В X-robots-Tag прописывается агент пользователя, для которого страница не будет высвечиваться в выдаче.
Выводы
Существует множество причин, по которым весь сайт или определенную его страницу необходимо скрыть от поисковых систем. Для улучшения позиций сайта в выдаче такие действия бывают обязательны, так как может быть риск попадания неуникальных элементов сайта на общее обозрение. Это может привести к ухудшению позиций ресурса. Бывает, что просто какой-то элемент нужно скрыть с глаз пользователей, так как он является частью технического содержания сайта.
Бывает, что просто какой-то элемент нужно скрыть с глаз пользователей, так как он является частью технического содержания сайта.
Способы, которые мы рассмотрели, являются основными и универсальными для всех случаев. Некоторые из них более просты и актуальны для постоянного применения (к примеру, использование дополнительных директив в файле robots.txt или же использование мета-тега).
Стоит отметить, что использование роботс не всегда удобно в применении и не может гарантировать стопроцентное скрытие ресурса от поисковых ботов. Поэтому в качестве страховочного варианта используют мета-тег <noindex>, который дает больше гарантий, что к роботам не попадет ненужная информация.
Если дело касается скрытия всего сайта или нескольких страниц, тогда отличным вариантом будет использование роботс. Если же вам необходимо скрыть много страниц, объединенных единым параметром, тогда лучше использовать noindex и не перегружать файл роботс множеством директив.
Остальные способы стоит применять с большой осторожностью, чтобы не навредить ресурсу, к примеру, блокировка запросов от различных юзер-агентов. Такая манипуляция оградит вас от вероятных вредоносных систем, но также подвергнет другим рискам, если вы недостаточно компетентны в этом деле.
Кроме целых сайтов и страниц данные методы помогают скрыть отдельные папки и разделы сайта.
Закрыть от индексации ссылки WordPress – удаляем внешние адреса
При сео продвижении важна каждая мелочь, а ссылки являются главнейшим фактором ранжирования в сети, именно на них держится весь интернет. Но если нужно закрыть от индексации ссылки в WordPress, то есть немного хороших методов.
Такой подход практикуют администраторы ресурсов с обзорами и предложениями партнерских (Affiliate) программ, чтобы не сделать переспам внешними линками на источники.
Виды исходящих ссылок
Администратор WordPress должен знать откуда на сайте появляются исходящие ссылки, разберем четыре направления.
- В статье – автор проставляет адреса
- В имени комментария
- В теле сообщения коммента
- Пингбэки и трэкбеки WordPress
Советую все линки скрывать от индексации, хуже не сделаете, а только прибавите веса блогу.
Не работают атрибуты noindex и noffolow
Расставленные атрибуты noindex и noffolow не дадут 100% гарантии что исходящие и внешние ссылки не будут индексироваться. Данных инструкций придерживается Яндекс, Google внимание уделяет командам в robots txt.
Но нет гарантии что после очередного апдейта в алгоритмах поведения ПС появятся изменения. Поэтому решаем проблему кардинально – маскируем url скриптами js.
Скрыть ссылки в тексте статьи WordPress
Больший приоритет у ссылок находящихся в тексте, поэтому первыми закрыть от индексации нужно их. Для данной операции два пути:
- Использовать шаблоны WordPress с такой функцией
- Применять плагины
Спрятать ссылки с помощью возможностей темы
В рунете есть онлайн магазин WordPress под названием WPShop, у всех тем есть встроенная функция спрятать ссылки от индексации. Так выглядит в панели.
Так выглядит в панели.
Функции в редакторе
- Обводим фразу в который будем встраивать url
- Нажимаем на кнопку закрыть синей цепочки
- Во всплывающем окне вводим адрес и нажимаем ok
- Видим что элемент помещен в шорт код mask_link
JS скрипт заменил url на span
При наведении адрес в браузере не отображается. В исходном коде нет тега <a> он заменен на <span>, а урл закодирован в атрибуте data-href.
Видим что разработчики максимально позаботились о клиентах, например, данная ссылка ведет на другой ресурс, с описанием шаблона ROOT, она закодирована. Для всех читателей выдаю купон на скидку 15 процентов на все продукты WPShop.
переход на Reboot
Удалить скриптом No External LInks
Из всех решений нашел плагин устранения индексации WP no external links. Скрипт WP не удаляет тег <a>, он переписывает саму ссылку и создает редирект через страницу-прокладку, как происходит процесс:
- Плагин изменяет внешний url на внутреннюю (то есть с адресом вашего домена)
- Пользователь на нее кликает
- Происходит быстрый редирект, либо сначала переходит на документ внутреннего назначения, а потом переход на необходимый сайт
Второй подход похож на первый, только во втором шаге идет перенаправление сначала на стационарную запись, на которой написано “через 3 секунды вы перейдете на другой сайт”, после уже автоматом на источник.
Этот путь лучше – не происходит редиректа в его буквальном смысле, а переход на внутреннюю страницу. Устанавливаем стандартным методом поиском из админки.
WP No External LInks в админке
Переходим в настройки – no external links. В первом разделе устанавливаем такой порядок, отмечаем первые три галочки маскировки.
Глобальная настройка маскировки
Остальные параметры оставляем как есть и спускаемся вниз. Выставляем кодирование по base64 и используем java script. Время выставим 5 секунд.
Кодировка base64
Нажимаете сохранить, перейдя на сайт и направив курсор на любую ссылку увидите такой результат. Нажав откроется новая страница вашего ресурса и через 5 секунд переход на указанный урл.
Результат работы
Закрыть индексацию данным способом не нахожу правильным, много происходит манипуляций. Перенаправления ПС не любят, особенно когда обманывают, роботы умеют и определяют такие схемы, точно не знаю, но предполагаю, что пессимизация и понижение в выдаче будут.
Не забывайте настраивать и управлять внутренней перелинковкой страниц в WordPress.
 Не забывайте настраивать и управлять внутренней перелинковкой страниц в WordPress.
Не забывайте настраивать и управлять внутренней перелинковкой страниц в WordPress.В имени автора и теле комментария
Еще одной дырой внешних ссылок в WordPress являются комментарии, особенно если автоматически публикуются без проверки. Со вторым проблему можно закрыть проверкой вручную комментов.
Но как быть с первым, когда ссылка в имени комментатора, ее удаляют также вручную, но такой подход считается плохим тоном. Зачастую сообщения оставляют с одной целью получения обратного урл на блог и получить посетителей.
Старый и проверенный ARK HideCommentLinks всегда обновляется и поддерживает современные стандарты WordPress. Устанавливается вручную либо поиском из админки.
ARK HideCommentLinks
Начинает закрывать от индексации автоматически, изменений параметров не требует. Также отключает вывод индексации дублей replytocom. После активации имена авторов с внешними ссылками становятся в теге <span> и за линк не воспринимаются.
Смотрим как отображается коммент
Настройка в ClearfyPRO
Но что делать если хотим на автомате публиковать комментарии, но модерировать отдельно не удобно, прошлый инструмент не сможет так скрыть.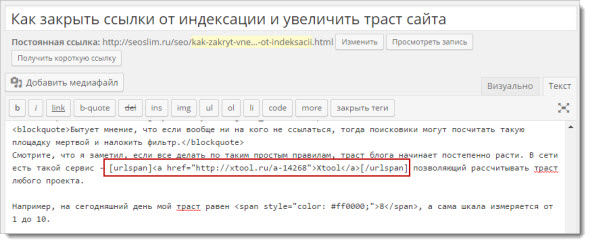 На помощь приходит наш ClearfyPRO, он при включении соответствующего раздела закрывает от поисковых систем адреса сайтов в обсуждениях. Включаем обе опции: имя автора и ссылки в тексте сообщения.
На помощь приходит наш ClearfyPRO, он при включении соответствующего раздела закрывает от поисковых систем адреса сайтов в обсуждениях. Включаем обе опции: имя автора и ссылки в тексте сообщения.
Clearfy PRO
Перейдя в любой комментарий видим, что автор и ссылки внутри сообщения смогли закрыть. Одновременно клеарфай чистит и ускоряет по множеству пунктов, например, отключает стили recentcomments. Предоставляю промо на плагин в 15%, переходите по кнопке скидка вычисляется автоматически.
Скидка на Clearfy
Убрать Pingback и trackback
Не очень частые внешние ссылки в WordPress, но появляются в зависимости от темы. Этот момент разбирал на другом блоге WPtemlate, переходите и смотрите как убрать такой функционал как удалить pingback и trackback в вордпресс.
Что же делать в итоге
Не советую использовать скрипты в которых нужно править файлы function php, footer и ядро вордпресс, в 50% случаев метод не сработает, а блог перестанет отвечать.
Советую применять связку любой шаблон от команды WPShop (закрыть ссылки в записях) + плагин ClearfyPRO (замаскирует и делает безопаснее комментарии) и не нужно устанавливать множество модулей и думать правильно ли сделано.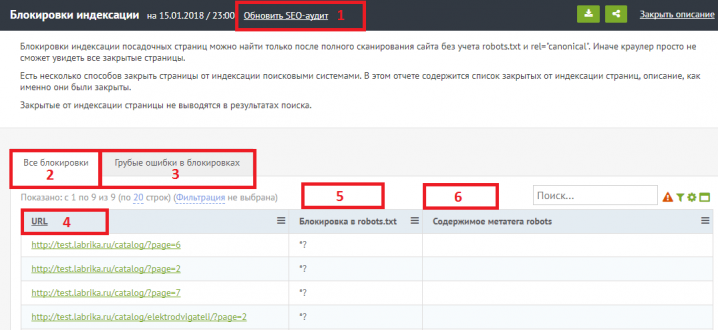 Потратится один раз и привести ресурс в порядок, а об остальном позаботятся эти крутые продукты.
Потратится один раз и привести ресурс в порядок, а об остальном позаботятся эти крутые продукты.
Пожалуйста, оцените материал: Мне нравится4Не нравится
как ее проверить, ускорить и запретить
Если интернет – огромная библиотека, то поисковые системы – ее сверхбыстрые сотрудники, способные быстро сориентировать читателя (интернет-пользователя) в бескрайнем океане информации. В этом им помогает систематизированная картотека – собственная база данных.
Когда пользователь вводит ключевую фразу, поисковая система показывает результаты из этой базы данных. То есть ПС хранят на своих серверах копии документов и обращаются к ним, когда пользователь отправляет запрос. Чтобы представить в выдаче определенную страницу, ее нужно сперва добавить в базу (индекс). Поэтому только что созданные сайты, о которых поисковики не знают, в выдаче не участвуют.
Поисковая система отправляет своего робота (он же паук, он же краулер) на поиски новых страниц, которые появляются в сети ежесекундно. Паучья стая собирает данные, передвигаясь по ссылкам с одной страницы на другую, и передает их в базу. Обработку информации производят уже другие механизмы.
Паучья стая собирает данные, передвигаясь по ссылкам с одной страницы на другую, и передает их в базу. Обработку информации производят уже другие механизмы.
У каждой поисковой системы – свой набор ботов, выполняющих разные функции. Вот пример некоторых роботов «Яндекса»:
- Основной робот.
- Индексатор картинок.
- Зеркальщик (обнаруживает зеркала сайта).
- Быстробот. Эта особь обитает на часто обновляемых сайтах. Как правило – новостных. Контент появляется в выдаче практически сразу после размещения. При ранжировании в таких случаях учитывается лишь часть факторов, поэтому позиции страницы могут измениться после прихода основного робота.
У «Гугла» тоже есть свой робот для сканирования новостей и картинок, а еще – индексатор видео, мобильных сайтов и т. д.
Скорость индексирования новых сайтов у разных ПС отличается. Каких-то конкретных сроков здесь нет, есть лишь примерные временные рамки: для «Яндекса» – от одной недели до месяца, для Google – от нескольких минут до недели. Чтобы не ждать индексации неделями, нужно серьезно поработать. Об этом и пойдет речь в статье.
Чтобы не ждать индексации неделями, нужно серьезно поработать. Об этом и пойдет речь в статье.
Сперва давайте узнаем, как проверить, проиндексирован ли сайт.
Как проверить индексацию сайта
Проверить индексацию можно тремя основными способами:
- Сделать запрос в поисковик, используя специальные операторы.
- Воспользоваться инструментами вебмастеров (Google Search Console, «Яндекс.Вебмастер»).
- Воспользоваться специализированными сервисами или скачать расширение в браузер.
Поисковые операторы
Быстро и просто примерное количество проиндексированных страниц можно узнать с помощью оператора site. Он действует одинаково в «Яндекс» и «Гугл».
Сервисы для проверки индексации
Бесплатные сервисы позволяют быстро узнать количество проиндексированных «Яндексом» и Google страниц. Есть, к примеру, очень удобный инструмент от XSEO. in и SEOGadget (можно проверять до 30 сайтов одновременно).
in и SEOGadget (можно проверять до 30 сайтов одновременно).
У RDS целая линейка полезных инструментов для проверки показателей сайтов, в том числе проиндексированных страниц. Можно скачать удобный плагин для браузера (поддерживаются Chrome, Mozilla и Opera) или десктопное приложение.
Вообще плагин больше подходит профессиональным SEOшникам. Если вы обычный пользователь, будьте готовы, что эта утилита будет постоянно атаковать вас лишней информацией, вклиниваясь в код страниц, и в итоге придется либо ее настраивать, либо удалять.
Панели вебмастера
«Яндекс.Вебмастер» и Google Search Console предоставляют подробную информацию об индексировании. Так сказать, из первых уст.
В старой версии GSC можно также посмотреть статистику сканирования и ошибки, с которыми сталкиваются роботы при обращении к страницам.
Подробнее о данных об индексировании, представленных в панелях вебмастеров, можно почитать в соответствующих разделах наших руководств по «Яндекс. Вебмастеру» и Google Search Console.
Вебмастеру» и Google Search Console.
58 самых распространенных ошибок SEO
Как контролировать индексацию
Поисковые системы воспринимают сайты совсем не так, как мы с вами. В отличие от рядового пользователя, поисковый робот видит всю подноготную сайта. Если его вовремя не остановить, он будет сканировать все страницы, без разбора, включая и те, которые не следует выставлять на всеобщее обозрение.
При этом нужно учитывать, что ресурсы робота ограничены: существует определенная квота – количество страниц, которое может обойти паук за определенное время. Если на вашем сайте огромное количество страниц, есть большая вероятность, что робот потратит большую часть ресурсов на «мусорные» страницы, а важные оставит на будущее.
Поэтому индексированием можно и нужно управлять. Для этого существуют определенные инструменты-помощники, которые мы далее и рассмотрим.
Robots.txt
Robots.txt – простой текстовый файл (как можно догадаться по расширению), в котором с помощью специальных слов и символов прописываются правила, которые понимают поисковые системы.
Директивы, используемые в robots.txt:
|
Директива
|
Описание
|
|
User-agent
|
Обращение к роботу.
|
|
Allow
|
Разрешить индексирование.
|
|
Disallow
|
Запретить индексирование.
|
|
Host
|
Адрес главного зеркала.
|
|
Sitemap
|
Адрес карты сайта.
|
|
Crawl-delay
|
Время задержки между скачиванием страниц сайта.
|
|
Clean-param
|
Страницы с какими параметрами нужно исключить из индекса.
|
User-agent показывает, к какому поисковику относятся указанные ниже правила. Если адресатом является любой поисковик, пишем звездочку:
User-agent: Yandex
User-agent: GoogleBot
User-agent: Bingbot
User-agent: Slurp (поисковый робот Yahoo!)
User-agent: *
Самая часто используемая директива – disallow. Как раз она используется для запрета индексирования страниц, файлов или каталогов.
К страницам, которые нужно запрещать, относятся:
- Служебные файлы и папки. Админ-панель, файлы CMS, личный кабинет пользователя, корзина и т. д.
- Малоинформативные вспомогательные страницы, не нуждающиеся в продвижении. Например, биографии авторов блога.
- Различного вида дубли основных страниц.
На дублях остановимся подробнее. Представьте, что у вас есть страница блога со статьей. Вы прорекламировали эту статью на другом ресурсе, добавив к существующему URL UTM-метку для отслеживания переходов. Адрес немного изменился, но он все еще ведет на ту же страницу – контент полностью совпадает. Это дубль, который нужно закрывать от индексации.
Адрес немного изменился, но он все еще ведет на ту же страницу – контент полностью совпадает. Это дубль, который нужно закрывать от индексации.
Не только системы статистики виноваты в дублировании страниц. Дубли могут появляться при поиске товаров, сортировке, из-за наличия одного и того же товара в нескольких категориях и т. д. Даже сами движки сайта часто создают большое количество разных дублей (особенно WordPress и Joomla).
Мы делаем сайты, которые оптимизированы под поисковики и приносят продажи.
Подробнее
Помимо полных дублей существуют и частичные. Самый лучший пример – главная страница блога с анонсами записей. Как правило, анонсы берутся из статей, поэтому на таких страницах отсутствует уникальный контент. В этом случае анонсы можно уникализировать или вовсе убрать (как в блоге Texterra).
У подобных страниц (списки статей, каталоги товаров и т. д.) также присутствует постраничная навигация (пагинация), которая разбивает список на несколько страниц. О том, что делать с такими страницами, Google подробно расписал в своей справке.
О том, что делать с такими страницами, Google подробно расписал в своей справке.
Дубли могут сильно навредить ранжированию. Например, из-за большого их количества поисковик может показывать по определенным запросам совершенно не те страницы, которые вы планировали продвигать и на которые был сделан упор в плане оптимизации (например, есть усиленная ссылками страница товара, а поисковик показывает совершенно другую). Поэтому важно правильно настроить индексацию сайта, чтобы этой проблемы не было. Как раз один из способов борьбы с дублями – файл robots.txt.
Пример robots.txt для одного известного блога:
При составлении robots.txt можно ориентироваться на другие сайты. Для этого просто добавьте в конце адреса главной страницы интересующего сайта после слеша «robots.txt».Не забывайте только, что функционал у сайтов разный, поэтому полностью скопировать директивы топовых конкурентов и жить спокойно не получится. Даже если вы решите скачать готовый robots. txt для своей CMS, в него все равно придется вносить изменения под свои нужды.
txt для своей CMS, в него все равно придется вносить изменения под свои нужды.
Давайте разберемся с символами, которые используются при составлении правил.
Путь к определенному файлу или папке мы указываем через слеш (/). Если указана папка (например, /wp-admin/), все файлы из этой папки будут закрыты для индексации. Чтобы указать конкретный файл, нужно полностью указать его имя и расширение (вместе с директорией).
Если, к примеру, нужно запретить индексацию файлов определенного типа или страницу, содержащую какой-либо параметр, можно использовать звездочки (*):
Disallow: /*openstat=
Disallow: /*?utm_source=
Disallow: /*price=
Disallow: /*gclid=*
На месте звездочки может быть любое количество символов (а может и не быть вовсе). Значок $ используется, когда нужно отменить правило, созданное значком *. Например, у вас есть страница eda.html и каталог /eda. Директива «/*eda» запретит индексацию и каталога, и страницы. Чтобы оставить страницу открытой для роботов, используйте директиву «/eda$».
Запретить индексацию страниц с определенными параметрами также можно с помощью директивы clean-param. Подробнее об этом можно прочитать в справке «Яндекса».
Директива allow разрешает индексирование отдельных каталогов, страниц или файлов. Например, нужно закрыть от ПС все содержимое папки uploads за исключением одного pdf-файла. Вот как это можно сделать:
Disallow: /wp-content/uploads/
Allow: /wp-content/uploads/book.pdf
Следующая важная (для «Яндекса») директива – host. Она позволяет указать главное зеркало сайта.
У сайта может быть несколько версий (доменов) с абсолютно идентичным контентом. Даже если у вас домен единственный, не стоит игнорировать директиву host, это разные сайты, и нужно определить, какую версию следует показывать в выдаче. Об этом мы уже подробно писали в статье «Как узнать главное зеркало сайта и настроить его с помощью редиректа».
Еще одна важная директива – sitemap. Здесь (при наличии) указывается адрес, по которому можно найти карту вашего сайта. О том, как ее создать и для чего она нужна, поговорим позже.
Наконец, директива, которая применяется не так часто – crawl-delay. Она нужна в случае, когда нагрузка на сервер превышает лимит хостинга. Такое редко встречается у хороших хостеров, и без видимых причин устанавливать временные ограничения на скачивание страниц роботам не стоит. К тому же скорость обхода можно регулировать в «Яндекс.Вебмастере».
Нужно отметить, что поисковые системы по-разному относятся к robots.txt. Если для «Яндекса» это набор правил, которые нельзя нарушать, то «Гугл» воспринимает его, скорее, как рекомендацию и может проигнорировать некоторые директивы.
В robots.txt нельзя использовать кириллические символы. Поэтому если у вас кириллический домен, используйте онлайн-конвертеры.
После создания файла его нужно поместить в корневой каталог сайта, т. е.: site.ru/robots.txt.
Проверить robots.txt на наличие ошибок можно в разделе «Инструменты» панели «Яндекс.Вебмастер»:
В старой версии Google Search Console тоже есть такой инструмент.
Как закрыть сайт от индексации
Если вам по какой-то причине нужно, чтобы сайт исчез из выдачи всех поисковых систем, сделать это очень просто:
User-agent: *
Disallow: /
Крайне желательно делать это, пока сайт находится в разработке. Чтобы снова открыть сайт для поисковых роботов, достаточно убрать слеш (главное – не забыть это сделать при запуске сайта).
Nofollow и noindex
Для настройки индексации используются также специальные атрибуты и html-теги.
У «Яндекса» есть собственный тег <noindex>, с помощью которого можно указать роботу, какую часть текста он не должен индексировать. Чаще всего это служебные части текста, которые не должны отображаться в сниппете, или фрагменты, которые не должны учитываться при оценке качества страницы (неуникальный контент).
Проблема в том, что этот тег практически никто кроме «Яндекса» не понимает, поэтому при проверке кода большинство валидаторов выдают ошибки. Это можно исправить, если слегка изменить внешний вид тегов:
<!—noindex—>текст<!—/noindex—>
Атрибут rel=”nofollow” позволяет закрыть от индексации отдельные ссылки на странице. В отличие от <noindex> его понимают все поисковые системы. Чтобы запретить роботу переходить по всем ссылкам на странице сразу, проще использовать вот такой мета-тег: <meta name=»robots» content=»nofollow» />.
Кстати, на мега-теге robots стоит остановиться подробнее. Как и файл robots.txt, он позволяет управлять индексацией, но более гибко. Чтобы понять принцип работы, рассмотрим варианты инструкций:
|
<meta name=»robots» content=»index,follow» />
|
индексировать контент и ссылки
|
|
<meta name=»robots» content=»noindex,nofollow» />
|
не индексировать контент и ссылки
|
|
<meta name=»robots» content=»noindex,follow» />
|
не индексировать контент, но переходить по ссылкам
|
|
<meta name=»robots» content=»index,nofollow» />
|
индексировать контент, но не переходить по ссылкам
|
Это далеко не все примеры использования мета-тега robots, так как помимо nofollow и noindex существуют и другие директивы. Например, noimageindex, запрещающая сканировать изображения на странице. Подробнее почитать об этом мета-теге и его применении можно в справке от Google.
Rel=”canonical”
Еще один способ борьбы с дублями – использование атрибута rel=”canonical”. Для каждой страницы можно задать канонический (предпочитаемый) адрес, который и будет отображаться в поисковой выдаче. Прописывая атрибут в коде дубля, вы «прикрепляете» его к основной странице, и путаницы c ee версиями не возникнет. При наличии у дубля ссылочного веса он будет передаваться основной странице.
Вернемся к примеру с пагинацией в WordPress. С помощью плагина All in One SEO можно в один клик решить проблему с дублями этого типа. Посмотрим, как это работает.
Зайдем главную страницу блога и откроем, к примеру, вторую страницу пагинации.
Теперь посмотрим исходный код, а именно – тег <link> с атрибутом rel=»canonical» в разделе <head>. Изначально он выглядит так:
<link rel=»canonical» target=»_blank» href=»http://site.ru/page/2/»>
Каноническая ссылка установлена неправильно – она просто повторяет физический адрес страницы. Это нужно исправить. Переходим в общие настройки плагина All in One SEO и отмечаем галочкой пункт «No Pagination for Canonical URLs» (Запретить пагинацию для канонических URL).
После обновления настроек снова смотрим код, теперь должно быть вот так:
<link rel=»canonical» target=»_blank» href=»http://site.ru/»>
И так – на любой странице, будь то вторая или двадцатая. Быстро и просто.
Но есть одна проблема. Для Google такой способ не подходит (он сам об этом писал), и использование атрибута canonical может негативно отразиться на индексировании страниц пагинации. Если для блога это, в принципе, не страшно, то со страницами товаров лучше не экспериментировать, а использовать атрибуты rel=”prev” и rel=”next”. Только вот «Яндекс» их, по словам Платона Щукина, игнорирует. В общем, все неоднозначно и ничего не понятно, но это нормально – это SEO.
Чек-лист по оптимизации сайта, или 100+ причин не хоронить SEO
Sitemap (карта сайта)
Если файл robots.txt указывает роботу, какие страницы ему трогать не надо, то карта сайта, напротив, содержит в себе все ссылки, которые нужно индексировать.
Главный плюс карты сайта в том, что помимо перечня страниц она содержит полезные для робота данные – дату и частоту обновлений каждой страницы и ее приоритет для сканирования.
Файл sitemap.xml можно сгенерировать автоматически с помощью специализированных онлайн-сервисов. Например, Gensitemap (рус) и XML-Sitemaps (англ). У них есть ограничения на количество страниц, поэтому если у вас большой сайт (больше 1000 страниц), за создание карты придется заплатить символическую сумму. Также получить готовый файл можно с помощью плагина. Самый простой и удобный плагин для WordPress – Google XML Sitemaps. У него довольно много разных настроек, но в них несложно разобраться.
В результате получается простенькая и удобная карта сайта в виде таблички. Причем она с
Какие страницы закрывать от индексации и как
Любая страница на сайте может быть открыта или закрыта для индексации поисковыми системами. Если страница открыта, поисковая система добавляет ее в свой индекс, если закрыта, то робот не заходит на нее и не учитывает в поисковой выдаче.
При создании сайта важно на программном уровне закрыть от индексации все страницы, которые по каким-либо причинам не должны видеть пользователи и поисковики.
К таким страницам можно отнести административную часть сайта (админку), страницы с различной служебной информацией (например, с личными данными зарегистрированных пользователей), страницы с многоуровневыми формами (например, сложные формы регистрации), формы обратной связи и т.д.
Пример:
Профиль пользователя на форуме о поисковых системах Searchengines.
Обязательным также является закрытие от индексации страниц, содержимое которых уже используется на других страницах.Такие страницы называются дублирующими. Полные или частичные дубли сильно пессимизируют сайт, поскольку увеличивают количество неуникального контента на сайте.
Пример:
Типичный блог на CMSWordPress, который содержит дубли.http://reaktivist.ru/ — главная страница.
http://reaktivist.ru/category/liniya-zhizni — страница категории.
Как видим, контент на обеих страницах частично совпадает. Поэтому страницы категорий на WordPress-сайтах закрывают от индексации, либо выводят на них только название записей.
То же самое касается и страниц тэгов– такие страницы часто присутствуют в структуре блогов на WordPress. Облако тэгов облегчает навигацию по сайту и позволяет пользователям быстро находить интересующую информацию. Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
Еще один пример – магазин на CMS OpenCart.
Страница категории товаров http://www.masternet-instrument.ru/Lampy-energosberegajuschie-c-906_910_947.html.
Страница товаров, на которые распространяется скидка http://www.masternet-instrument.ru/specials.php.
Данные страницы имеют схожее содержание, так как на них размещено много одинаковых товаров.
Особенно критично к дублированию контента на различных страницах сайта относится Google. За большое количество дублей в Google можно заработать определенные санкции вплоть до временного исключения сайта из поисковой выдачи.
Мы рекомендуем закрывать страницу от индексации, если она содержит более 40 % контента с другой страницы. В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
Примечание:
Для авторитетных сайтов с большим количеством страниц и хорошей посещаемостью (от 3000 человек в сутки) дублирование не столь существенно, как для новых сайтов.
Еще один случай, когда содержимое страниц не стоит «показывать» поисковику – страницы с неуникальным контентом. Типичный пример — инструкции к медицинским препаратам в интернет-аптеке. Контент на странице с описанием препарата http://www.piluli.ru/product271593/product_info.html неуникален и опубликован на сотнях других сайтов.
Сделать его уникальным практически невозможно, поскольку переписывание столь специфических текстов – дело неблагодарное и запрещенное. Наилучшим решением в этом случае будет закрытие страницы от индексации, либо написание письма в поисковые системы с просьбой лояльно отнестись к неуникальности контента, который сделать уникальным невозможно по тем или иным причинам.
Как закрывать страницы от индексации
Классическим инструментом для закрытия страниц от индексации является файл robots.txt. Он находится в корневом каталоге вашего сайта и создается специально для того, чтобы показать поисковым роботам, какие страницы им посещать нельзя. Это обычный текстовый файл, который вы в любой момент можете отредактировать. Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Структура файла robots.txt довольно проста. Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
User-agent: *
Если вы хотите запретить индексацию страницы только для одной ПС, например, для Яндекса, первая строка выглядит так:
User-agent: Yandex
Вторая строчка инструкции называется Disallow (запретить). Для запрета всех страниц сайта напишите в этой строке следующее:
Disallow: /
Чтобы разрешить индексацию всех страниц вторая строка должна иметь вид:
Disallow:
В строке Disallow вы можете указывать конкретные папки и файлы, которые нужно закрыть от индексации.
Например, для запрета индексации папки images и всего ее содержимого пишем:
User-agent: *
Disallow: /images/
Чтобы «спрятать» от поисковиков конкретные файлы, перечисляем их:
User-agent: *
Disallow: /myfile1.htm
Disallow: /myfile2.htm
Disallow: /myfile3.htm
Это – основные принципы структуры файла robots.txt. Они помогут вам закрыть от индексации отдельные страницы и папки на вашем сайте.
Еще один, менее распространенный способ запрета индексации – мета-тэг Robots. Если вы хотите закрыть от индексации страницу или запретить поисковикам индексировать ссылки, размещенные на ней, в ее HTML-коде необходимо прописать этот тэг. Его надо размещать в области HEAD, перед тэгом <title>.
Мета-тег Robots состоит из двух параметров. INDEX – параметр, отвечающий за индексацию самой страницы, а FOLLOW – параметр, разрешающий или запрещающий индексацию ссылок, расположенных на этой странице.
Для запрета индексации вместо INDEX и FOLLOW следует писать NOINDEX и NOFOLLOW соответственно.
Таким образом, если вы хотите закрыть страницу от индексации и запретить поисковикам учитывать ссылки на ней, вам надо добавить в код такую строку:
<meta name=“robots” content=“noindex,nofollow”>
Если вы не хотите скрывать страницу от индексации, но вам необходимо «спрятать» ссылки на ней, мета-тег Robots будет выглядеть так:
<metaname=“robots” content=“index,nofollow”>
Если же вам наоборот, надо скрыть страницу от ПС, но при этом учитывать ссылки, данный тэг будет иметь такой вид:
<meta name=“robots” content=“noindex,follow”>
Большинство современных CMS дают возможность закрывать некоторые страницы от индексации прямо из админ.панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
Как закрыть внешние, исходящие ссылки от индексации
На просторах веб дизайна и создания кода
скрытие внешних ссылок – необходимая процедура. Процесс индексации сайта
включает сбор, обработку и добавление сведений о конкретном сайте в общую базу
данных. Сегодня мы разберем, какие методики существуют для быстрого и
безопасного сокрытия внешних ссылок от поисковых систем при индексации.
Как закрыть внешние, исходящие ссылки от индексации на WordPress
Сделать закрытыми внешние ссылки от поисковых ботов можно, используя несколько тегов и плагинов, которые легко установить на платформе Word Press. На сегодняшний день существуют следующие способы:
- использование конструкции rel=”nofollow”;
- использование ряда плагинов;
- применение тега “noindex”;
- подключение AJAX – наиболее современный метод, и он же самый оптимальный вариант.
Каждый из методов обладает достаточными
преимуществами практического применения, но выделяют более современные способы,
вытесняющие устаревшие теги. К сожалению, скрипты Java более не приносят ожидаемого эффекта, так как содержимое скрипта на сегодняшний
день также читается поисковым ботом.
Как закрыть ссылки от индексации с помощью rel=”nofollow” или nofollow
Rel=”nofollow“
Несмотря на богатое прошлое элемента rel=”nofollow”, на сегодняшний день он больше не
имеет статуса тега, а является атрибутом. Какие интересные функции выполняет
данный элемент:
- позволяет скрыть подозрительную для поисковых ботов информацию, включающую комментарии к блогу, ссылки на сомнительные ресурсы, тексты с большим количеством спама;
- закрытие от индексации платных ссылок, что поможет защитить сайт от блокировки;
- поднятие в рейтинге сканирования поисковыми системами. Как известно, внешние ссылки значительно увеличивают «вес» html-страницы, а их скрытие делит «вес» на меньшие составляющие.
Большим преимуществом является тот факт, что
сервис Яндекс пока не умеет «читать» данный элемент.
Nofollow
Главное отличие данного элемента от
предыдущего лишь в историческом аспекте: ранее элемент использовался только в
качестве атрибута для тега rel. Но в некоторые моменты
истории верстки html-страниц элемент
приобрел иной статус – положение самостоятельного тега. Надо сказать, что
функции он выполняет те же, что и его собрат атрибут.
Как скрыть контент с помощью Ajax
Иногда приходится скрывать от поисковых ботов
не только внешние ссылки, но и некоторую информацию на странице. Рассмотрим,
какие виды контента можно скрыть от поисковых ботов:
- ссылки на сайты партнеров;
- рекламный контент;
- часто повторяющийся текст.
Данная информация может послужить причиной
временной блокировки сайта пользователя.
В чем заключается сущность работы сервиса Ajax? Главная особенность заключается в том, что контент не просто скрывается от ботов, но переводится на ресурс AJAX в виде внешнего файла, а в нужный момент подключается к сайту по запросу пользователя. Кроме того, помните, что не следует обрабатывать при помощи Ajax:
- скрипты с внешних ресурсов;
- приложения счетчики.
Опасность заключается в том, что эти
программы могут перестать работать.
Блокировка индексации сайта robots.txt
К данному ресурсу обращаются чаще всего на
стадии разработки сайта, когда вмешательство поисковых систем крайне
нежелательно. Далее представлена подробная инструкция, как блокировать
индексацию сайта при помощи robots.txt:
- в корне сайта необходимо создать текстовый файл robots.txt и прописать в нем строки, позволяющие скрыть все ссылки от любого поискового бота (защита предназначена для всех видов
Почему плохо ссылаться на страницы, закрытые от индексации — Devaka SEO Блог
6116
просмотров
Одна из популярных ошибок вебмастеров — ссылаться на неиндексируемые поисковой системой страницы. Это могут быть страницы, закрытые в robots.txt, имеющие мета-тег robots=noindex или просто несуществующие документы (отдают 404 код статуса). Например, на сайте может находиться система фильтрации или тегов, большинство или все из которых специально закрыты от индексации, чтобы не создавать дублей. В панели для вебмастеров вы заметите множество сообщений об ошибках, но это лишь половина проблемы.
Почему же плохо ссылаться на несуществующие страницы, или закрытые от индексации?
Закрывая документы/разделы от индексации, с одной стороны, мы избавляемся от малоинформативных страниц в индексе (хотя не всегда это происходит так, как бы мы хотели), но с другой, теряем часть статического веса, который мог бы концентрироваться лишь на полезных для поиска документах (образуется упущенная выгода).
Один из важных факторов в поисковой системе является PageRank (или статический вес). На основе него оптимизаторы планируют целые схемы перелинковки документов между собой, чтобы наиболее приоритетные получили больше статического веса. Получается, при наличии в перелинковке неиндексируемых документов нарушается один из принципов самого подхода линковки документов.
Какие можно найти решения?
В зависимости от ситуации и функционала можно применить следующие решения:
— Разрешить индексировать закрытые документы (если каждая из страниц проработаны и имеют уникальный контент).
— Убрать сами страницы и ссылки на них (если они невосстребованны даже пользователями).
— Использовать ajax-решения, например /search/#tag=статистика вместо /tag/статистика.
Возможно, у вас есть какие-то другие решения этой проблемы? И закрываете ли вы вообще какие-то разделы своего сайта от поиска?
API открытого индекса | Ссылка на Elasticsearch [7.10]
Открывает закрытый индекс. Для потоков данных API
открывает любые закрытые резервные индексы.
Вы можете использовать API открытых индексов для повторного открытия закрытых индексов. Если запрос нацелен
поток данных, запрос повторно открывает любой из закрытых индексов поддержки потока.
Закрытый индекс заблокирован для операций чтения / записи и не позволяет
все операции, которые позволяют открывать индексы. Невозможно проиндексировать
документы или для поиска документов в закрытом индексе.Это позволяет
закрытые индексы, чтобы не поддерживать внутренние структуры данных для
индексирование или поиск документов, что снижает накладные расходы на
кластер.
При открытии или закрытии индекса мастер отвечает за
перезапуск осколков индекса для отражения нового состояния индекса.
Затем осколки пройдут обычный процесс восстановления. В
данные открытых / закрытых индексов автоматически реплицируются
кластер, чтобы обеспечить надежное хранение достаточного количества копий осколков
всегда.
Вы можете открывать и закрывать несколько индексов. Выдается ошибка
если запрос явно ссылается на отсутствующий индекс. Такое поведение может быть
отключено с помощью параметра ignore_unavailable = true .
Все индексы могут быть открыты или закрыты одновременно с использованием _all в качестве имени индекса.
или указав шаблоны, которые их все идентифицируют (например, * ).
Определение индексов с помощью подстановочных знаков или _all можно отключить, установив
действие.destructive_requires_name в файле конфигурации значение true .
Этот параметр также можно изменить через api настроек обновления кластера.
Закрытые индексы занимают значительный объем дискового пространства, что может вызвать
проблемы в управляемых средах. Индексы закрытия можно отключить в настройках кластера
API, установив cluster.indices.close.enable на false . По умолчанию это , правда .
Текущий индекс записи в потоке данных не может быть закрыт.Чтобы закрыть
текущий индекс записи, поток данных сначала должен быть
перевернут, чтобы был создан новый индекс записи
и тогда предыдущий индекс записи может быть закрыт.
Ждать активных шардовправить
Поскольку при открытии или закрытии индекса выделяются его сегменты,
wait_for_active_shards настройка включена
создание индекса применяется также к действиям индекса _open и _close .
100 лучших сайтов для поиска научных журналов, статей и книг
Интернет — это предоставление информации.Помимо общения с друзьями на Facebook, просмотра видео на YouTube или покупок в Интернете на Amazon, вы также можете использовать Интернет в академических целях. Есть много отличных веб-сайтов, которые позволяют студентам, исследователям и библиотекарям искать ценные академические журналы и научные статьи .
Здесь мы собрали 100 онлайн-баз данных и поисковых систем, где вы можете найти в Интернете отличные журналы, статьи и книги для вашего успеха в учебе и публикации.Если вам известны какие-либо другие сайты, которыми стоит поделиться, сообщите нам об этом в разделе комментариев ниже.
1. Google Scholar
Google Scholar позволяет выполнять поиск по полному тексту научной литературы по множеству форматов публикации и дисциплин. Индекс веб-поисковой системы включает большинство рецензируемых онлайн-журналов крупнейших научных издательств Европы и Америки, а также научные книги и другие журналы, не рецензируемые рецензентами.
2. ScienceDirect
ScienceDirect — ведущий мировой источник научных, технических и медицинских исследований.На нем размещено более 12 миллионов материалов из 3 500 академических журналов и 34 000 электронных книг.
3. ReaserchGate
ResearchGate — это профессиональная социальная сеть, в которой ученые и исследователи могут делиться, открывать и обсуждать исследования. Сеть насчитывает более 118 миллионов страниц публикаций, 15 миллионов исследователей и более 700 тысяч проектов. Пользователи могут использовать его функцию ведения блога, чтобы писать короткие обзоры на рецензируемые статьи.
4. Springerlink
Springerlink предоставляет исследователям доступ к миллионам научных документов из журналов, книг, серий, протоколов и справочников.Он охватывает множество тем в естественных, социальных и гуманитарных науках.
5. VET-Bib
VET-Bib — это библиографическая база данных, охватывающая европейскую литературу по профессиональному образованию и обучению (ПОО).
6. Academia.edu
Academia.edu — это платформа, где ученые могут следить за научными работами и делиться ими. В настоящее время на сайте зарегистрировано более 1 миллиона пользователей, которые активно делятся статьями в любой области, следят за результатами своих исследований и следят за исследованиями ученых, за которыми они следят.
7. Архив электронной печати ArXiv.org
ArXiv — это хранилище электронных отпечатков, одобренных для публикации после модерации, которое состоит из научных статей в области математики, физики, астрономии, электротехники, информатики, статистики и количественного анализа. финансы, доступ к которым можно получить в Интернете.
8. Astrophysics Data System
Astrophysics Data System — это онлайн-база данных, содержащая более 8 миллионов статей по астрономии и физике из рецензируемых и нерецензируемых источников.
9. Google Книги
Google Книги позволяют пользователям выполнять поиск по
Use The Index, Luke охватывает Oracle, MySQL, PostgreSQL, SQL Server, …
Сайт, объясняющий разработчикам индексацию SQL — никакой чуши об администрировании.
SQL-индексирование — наиболее эффективный метод настройки, но при разработке им часто пренебрегают. Use The Index, Люк объясняет индексацию SQL с нуля и не останавливается на инструментах ORM, таких как Hibernate.
Use The Index, Luke — это бесплатная веб-версия SQL Performance Explained.Если вам нравится этот сайт, подумайте о приобретении книги. Также посмотрите в магазине другие интересные вещи, поддерживающие этот сайт.
Индексирование SQL в MySQL, Oracle, SQL Server и т. Д.
Использование индекса, Люк представляет индексирование вне зависимости от поставщика. Примечания по продукту представлены здесь:
- DB2
Use The Index, Luke охватывает индексацию SQL для IBM DB2. Тесты проводились с DB2 для Linux, UNIX и Windows (LUW) V10.С 5 по 11.5.
- MySQL
Использование индекса, Люк охватывает индексацию SQL для MySQL. Тесты проводились с MySQL 5.5 — 8.0.20.
- Oracle
Use The Index, Luke охватывает индексирование SQL для базы данных Oracle. Тесты проводились с Oracle 11g — 19c.
- PostgreSQL
Use The Index, Luke охватывает индексацию SQL для PostgreSQL. Тесты проводились с PostgreSQL 9.От 0 до 12.
- SQL Server
Использование индекса, Люк охватывает индексирование SQL для Microsoft SQL Server. Тесты проводились с SQL Server 2008R2 до 2019 года.
Есть еще вопросы об индексировании или настройке SQL? Нет проблем — ознакомьтесь с моими услугами по обучению и настройке на winand.at.
Содержание
Предисловие — Почему индексация является задачей разработки?
Анатомия индекса — Как выглядит индекс?
Листовые узлы — двусвязный список
B-Tree — сбалансированное дерево
Медленные индексы, часть I — Два компонента замедляют индекс
Предложение Where — Индексирование для повышения производительности поиска
Оператор Equals — Поиск точного ключа
Первичные ключи — Проверка использования индекса
Concatenated Keys индексы столбцов
Медленные индексы, часть II — Первый ингредиент, повторный визит
Функции — Использование функций в предложении
whereПоиск без учета регистра —
UPиНИЖНИЙПользовательские функции — Li уменьшение функциональных индексов
Избыточное индексирование — Избегайте избыточности
Переменные привязки — Для безопасности и производительности
Поиск диапазонов
Поиск диапазонов — Превышение равенства
Больше, меньше и
МЕЖДУ— пересмотрен порядок столбцовИндексирование SQL
LIKEFilters —LIKEне для полнотекстового поискаIndex Combine — Почему не использовать один индекс для каждого столбца?
Частичные индексы — Индексирование выбранных строк
NULLв базе данных Oracle — Важное любопытствоNULLв индексах — Каждый индексявляется частичным индексом
NOT NULLОграничения — влияют на использование индексаЭмуляция частичных индексов — с использованием индексации на основе функций
Условия обфускации — Общие антишаблоны 9160008 9152
- — Обратите особое внимание на
DATEтипыЧисловые строки — Не смешивайте типы
Объединение столбцов — используйте избыточный
, где предложенияSmart Logic — Самый умный способ замедлить работу SQL
90 096 Math — Базы данных не решают уравнения
Тестирование и масштабируемость — Об аппаратном обеспечении
Объем данных — Некачественное индексирование укусов назад
Загрузка системы — Производственная нагрузка влияет на время отклика
Время отклика и пропускная способность — Горизонтальная масштабируемость
Операция соединения — Не медленная, если все сделано правильно
Вложенные циклы — О проблеме выбора N + 1 в ORM
Хэш-соединение — Требуется совершенно другой подход к индексации
Соединение сортировкой-слиянием — Как застежка-молния на двух отсортированных наборах
Кластеризация данных — Для сокращения операций ввода-вывода
Предикаты индексного фильтра, преднамеренно используемые — для настройки 9 0011 LIKE
Сканирование только для индекса — Предотвращение доступа к таблицам
Организованная по индексу таблица — Кластерные индексы без таблиц
Сортировка и группировка — конвейерный порядок третья степень
Indexed Order By -
, где взаимодействия предложенийASC/DESCиNULL FIRST/LAST- изменение порядка индекса9001 Index Группировать по - Конвейерная обработка
Группировать по
Частичные результаты - Эффективное разбиение на страницы
Выбор верхних строк - если вам нужны только первые несколько строк
Получение следующего Страница - Сравнение методов смещения и поиска
Ветер ow-Functions - Пагинация с использованием аналитических запросов
Вставка, удаление и обновление - Влияние индексации на операторы DML
Insert - не может напрямую использовать индексы
Удалить - использует индексы для
, где пунктОбновление - не влияет на все индексы таблицы
Об авторе
Маркус Винанд является послом SQL Renaissance.
Добавить комментарий