
Как перевести, извлечь и распознать текст по фото
Optical Character Recognition (OCR) — Оптическое распознавание символов существует уже много лет и предназначено для чтения текста по фотографии. Это очень полезно, ведь мы не сможем скопировать текст из печатной книги, сканированного документа, JPG картинки или файла PDF. Есть очень много ситуаций, когда нужно быстро распознать текст с картинки и перевести его к примеру, с английского на русский по фото. Это могут быть мемы на английском языке, которые нужно перевести на русский и создать свой мемас. Это могут быть и документы договора оферты на иностранном языке в PDF формате, которые нужно перевести на русский, чтобы понять о чем речь в документе. Существует много программ на основе OCR и онлайн переводчиков по фото, которые предлагают сразу конвертировать формат файлов PDF в DOC или переводить иностранный текст по фото. Я собрал самые удобные способы, чтобы распознать текст с картинки jpg, pdf, png форматов и перевести его на другой язык.
Распознать текст с картинки и перевести онлайн
Безусловно OneNote один из лучших продуктов от Microsoft по работе многофункциональных записок, который есть на всех компьютерах и ноутбуках с Windows 10, и даже на телефонах IOS и Android. Огромный плюс OneNote в том, что можно вставить все известные форматы изображений, в том числе и PDF, распознать текст с картинки и сразу перевести на другой язык.
Запустите UWP OneNote и вставьте картинку в формате PDF, JPG или PNG, после чего нажмите по ней правой кнопкой мыши и выберите «Копировать текст из рисунка«. Далее текст будет скопирован в буфер, после чего вы можете вставить его ниже в OneNote, Word или другое любое место.
Важно: Когда вы вставите картинку, нужно подождать 1 минуту или более, чтобы алгоритм OCR распознал текст с картинки в облаке, после этого появится строка в меню «Копировать текст из рисунка». Вы можете использовать веб-версию OneNote, чтобы распознать текст с картинки через телефон.
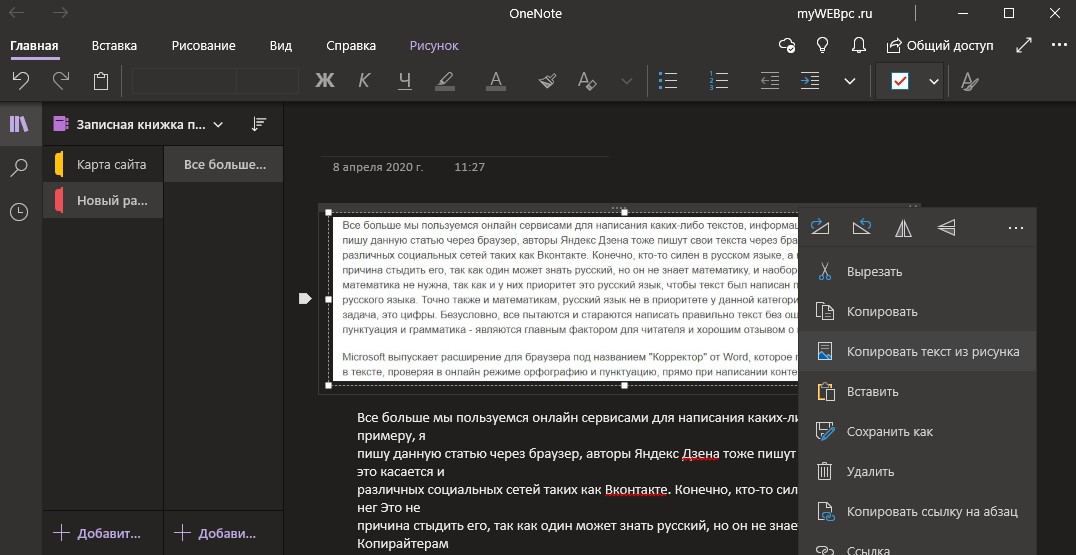
Перевести извлеченный текст из фото, можно выделив его, нажав по нему правой кнопкой мыши и выбрать «Перевод«. С правой стороны появится колонка, где вам нужно будет промотать вниз до графы «Язык перевода», и выбрать там нужный вам язык. Текст переведется при помощи онлайн переводчика microsoft.
Распознавание и перевод текста по фото в Google Docs
Google Docs может распознать текст из любой картинки формата PDF, JPG, WebP или PNG на компьютере или телефоне в онлайн режиме. Извлеченный текст мы можем сразу перевести на нужный нам язык. Загружаем файл на Google диск (Мой диск), если его нет. Далее нажимаем по файлу правой кнопкой мыши и «Открыть с помощью» > «Google Документы«.

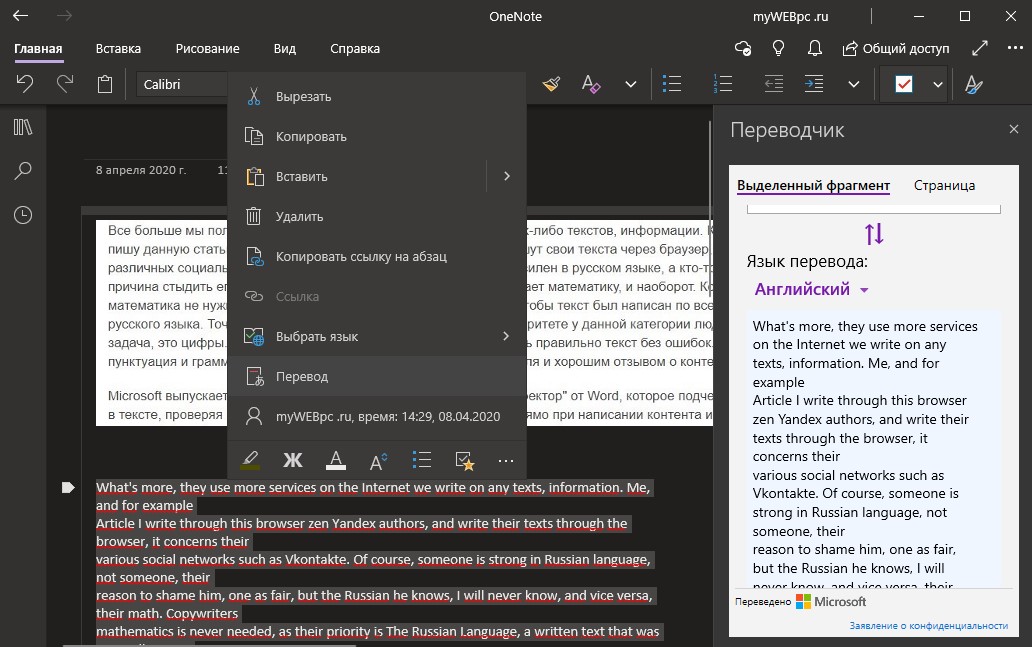
Откроется редактор документов, где мы можем поправить извлеченный текст. Чтобы перевести документ, нажмите сверху на вкладку «Инструменты» > «Перевести документ«.
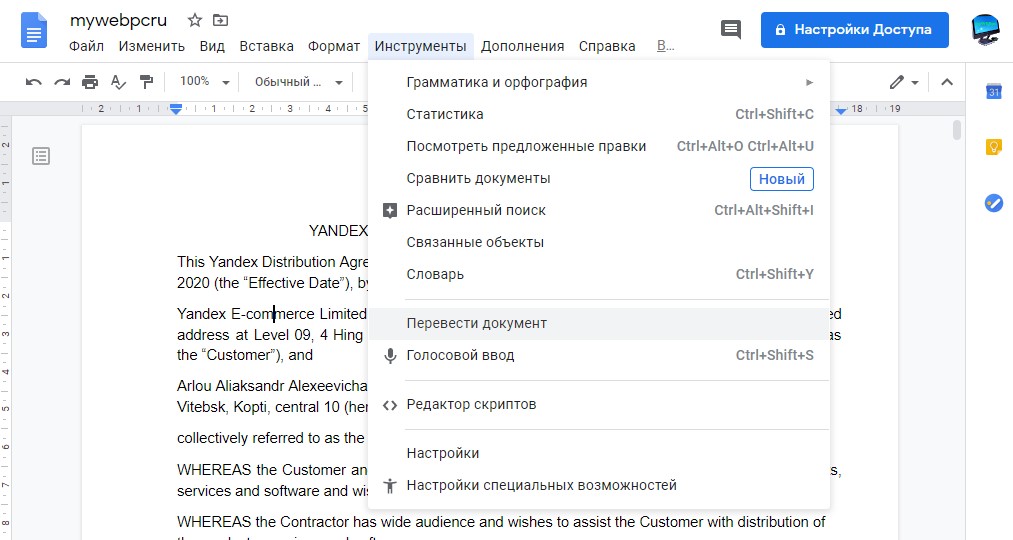
Распознать и перевести текст PDF в Word онлайн
Если мы сразу закинем PDF формат в Word онлайн (через браузер), то не получится распознать текст с картинки PDF и перевести его. Нужно для начала добавить файл в OneDrive, а потом открыть его через Word. Переходим в облачное хранилище OneDrive и открываем файл PDF, если его нет, то загрузите его туда, нажав сверху «Добавить».
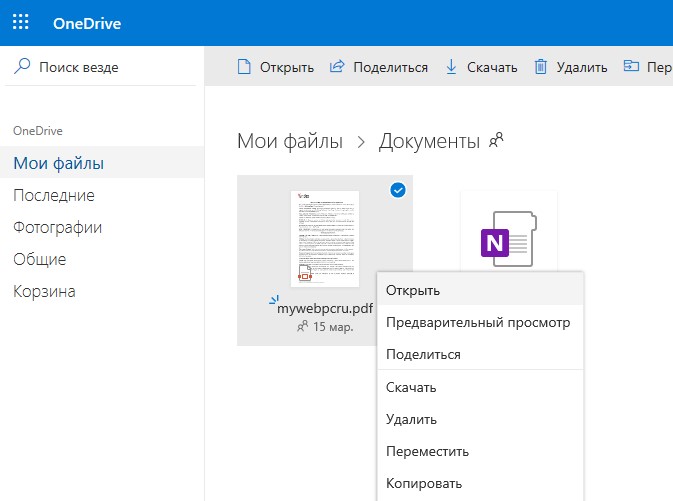
После открытия в предварительном просмотре, нажмите сверху на «Изменить в классическом приложении«, и в сообщении «Преобразовать«.
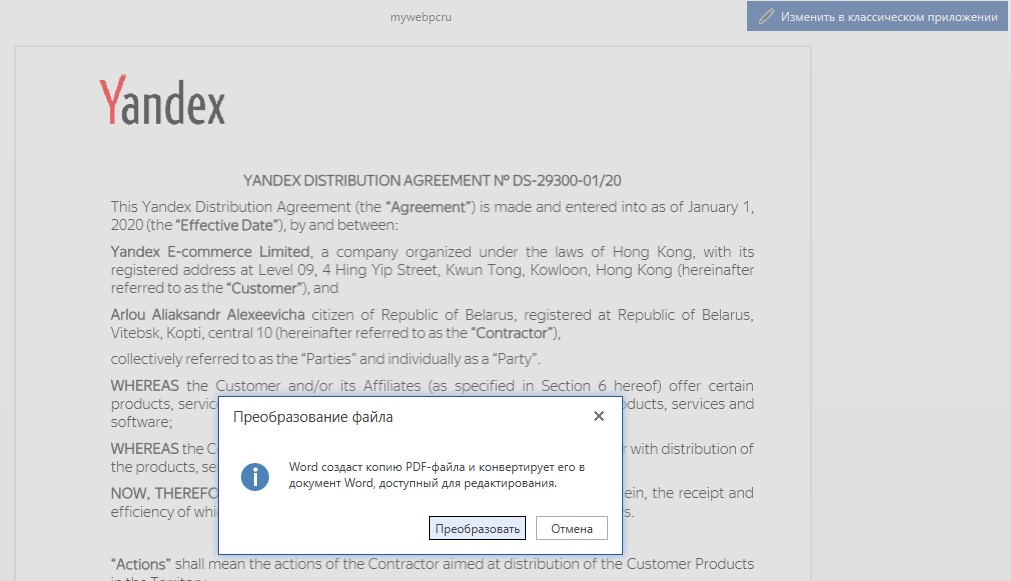
Далее PDF файл преобразуется в текстовый документ Word, где можно его редактировать. Если нажать на иконку транслита, то можно перевести документ на другой язык полностью или нужную часть.
К сожалению в бесплатной онлайн версии Word я не нашел функции, как распознать текст с картинки JPG формата. Более чем уверен, что эта функция доступна в платных подписках.
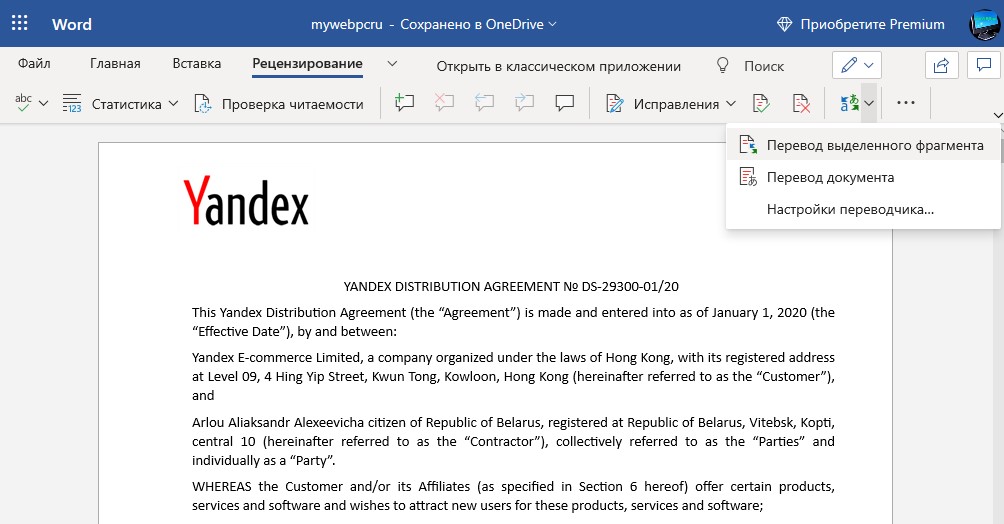
Переводчик по фото онлайн с английского на русский
Фото переводчик онлайн Яндекса, распознает текст по фото при помощи алгоритмов OCR и сразу переведет его на нужный вам язык. Перейдите ниже по ссылке и вставьте туда фото, нажав «Выбрать файл». После загрузки фото, вы можете сверху выбрать нужный вам язык для перевода, после чего нажмите «Открыть в переводчике«. Далее текст будет переведет по вашему фото.

Распознать текст с картинки при помощи программы
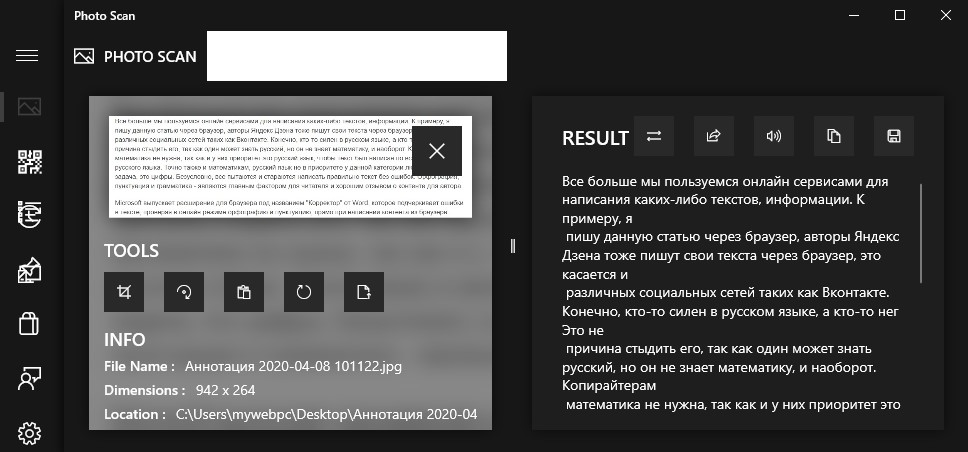
Photo Scan — приложение UWP, которое можно скачать из Microsoft Store (магазина Windows). При запуске программы вы можете вставить картинку jpg из буфера, сфоткать сразу картинку с веб-камеры, или загрузить с компьютера изображение. Далее программа при помощи алгоритма OCR распознает текст по картинке и извлечет его в правый столбик. Данный текст вы можете скопировать и вставить в Google или Яндекс онлайн переводчики.
comments powered by HyperComments
Оптическое распознавание текста (OCR) | Yandex.Cloud
В этом разделе описано, как работает возможность распознавание текста (Optical Character Recognition, OCR).
Подготовка запроса на распознавание
В запросе вы указываете список возможностей для анализа, которые необходимо применить к изображению. Чтобы распознать текст, используйте тип TEXT_DETECTION и задайте список языков в конфигурации.
Конфигурация запроса
В конфигурации указывается:
список языков, на основе которого будет определена языковая модель для распознавания.
Если вы не знаете язык текста, укажите
"*", чтобы сервис выбрал наиболее подходящую модель автоматически.модель, которая будет использована для поиска текста на изображении. Доступные модели:
page(по умолчанию) — подходит для изображений с любым количеством строк текста.line— подходит для распознавания одной строки текста. Например, если вы не хотите передавать изображение целиком, вы можете вырезать строку и отправить на распознавание только ее.На изображении должна быть только одна строка текста, а высота текста должна быть не меньше 80% от высоты изображения, иначе результаты распознавания с моделью
lineбудут непредсказуемы. Пример правильного изображения:
Определение языковой модели
Для распознавания текста в сервисе используется языковая модель, обученная на определенном наборе языков. Модель выбирается автоматически на основе списка языков, который вы указываете в конфигурации.
При каждом распознавании текста используется только одна модель. Например, если на изображении текст на китайском и японском, то распознан будет только один из этих языков. Чтобы распознать оба этих языка, укажите в запросе несколько возможностей для анализа с разными списками языков.
Совет
Для текста на русском и английском лучше всего работает англо-русская модель. Чтобы использовать ее, укажите один из этих языков или оба в text_detection_config, но не указывайте другие языки.
Требования к изображению
Изображение в запросе должно соответствовать следующим требованиям:
Поддерживаемые форматы файлов: JPEG, PNG, PDF.
MIME-тип файла вы указываете в свойстве
mime_type. По умолчаниюimage.Максимальный размер файла: 1 МБ.
Размер изображения не должен превышать 20 мегапикселей (длина x ширина).
Ответ с результатами распознавания
Сервис выделяет найденный текст на изображении и группирует его по уровням: слова группируются в строки, строки в блоки, блоки в страницы.
В результате сервис возвращает объект, где для каждого из уровней дополнительно указывается:
- страницы (
pages[]) — размер страницы; - блоки текста (
blocks[]) — расположение текста на странице; - строки (
lines[]) — расположение и достоверность распознавания; - слова (
words[]) — расположение, достоверность, текст и язык, использованный при распознавании.
Чтобы показать расположение текста, сервис возвращает координаты прямоугольника, обрамляющего текст. Координаты — количество пикселей от левого верхнего угла на изображении.
Координаты прямоугольника считаются от левого верхнего угла и указываются против часовой стрелки:
Пример распознанного слова с координатами:
{
"boundingBox": {
"vertices": [{
"x": "410",
"y": "404"
},
{
"x": "410",
"y": "467"
},
{
"x": "559",
"y": "467"
},
{
"x": "559",
"y": "404"
}
]
},
"languages": [{
"languageCode": "en",
"confidence": 0.9412244558
}],
"text": "you",
"confidence": 0.9412244558
}
Достоверность распознавания
Достоверность распознавания показывает уверенность сервиса в результате. Например, значение "confidence": 0.9412244558 для строки we like you
означает, что с вероятностью в 94% текст распознан корректно.
Сейчас достоверность считается только для строк. В значение confidence для слов и языка подставляется значение для confidence строки.
Что дальше
Как распознать текст с картинки онлайн

Распознать текст бесплатно с картинки онлайн можно с помощью Документов Google. Для этого нужно завести аккаунт или почту в Гугл. Делать все это мы будет через сервис Google Диск. После создания аккаунта вам будет доступно пространство в размере 15 ГБ — его мы и будем использовать.
- Заходим в Google Диск по ссылке
https://www.google.com/intl/ru_ru/drive/
- Загружаем фото/картинку или PDF документ нажав на кнопку «Создать» и выбрав «Загрузить файлы». Выбираем файл и загружаем.
- Жмем правой кнопкой мышки по загруженному файлу и выбираем «Открыть с помощью > Документы Google».
- Ждем пока наша картинка откроется в документе Гугл. Под картинкой будет распознанный текст. Его можно скопировать и вставить в WORD или в любой другой документ.
Ограничения
- Максимальный размер файла — 2 МБ.
- Поддерживаемые форматы — JPG, GIF, PNG и PDF.
- В файлах PDF распознаются только первые 10 страниц. (Как разделить файл PDF на части или страницы).
- Текст на картинке должен быть расположен ровно. Если он под углом, необходимо в любом графическом редакторе повернуть изображение на требуемый угол.
Если вы хотите качественного распознавания нужно сделать четкую фотографию или картинку с равномерным освещением и без размытостей.
Официально заявлена поддержка китайского языка.
Подробно про оптическое распознавание символов на Google Диске можно прочитать здесь.
Еще интересное:
Распознавайте текст с картинок бесплатно с удовольствием еще и онлайн).
Как распознать текст с картинки в Word
Представьте себе функцию, позволяющую извлечь текст из изображения и быстро вставить его в другой документ. На самом деле это возможно. Вам больше не нужно терять время, набирая все, потому что есть программы, которые используют оптическое распознавание символов (OCR) для анализа букв и слов в изображении, а затем конвертируют их в текст.
В наши дни существует так много бесплатных и эффективных опций, позволяющих извлечь текст из изображения, а не печатать его вручную. Ниже представлены самые удобные и эффективные программы и их сравнение.

Как распознать текст с картинки в Word
Видео — распознавание текста с картинки в WORD
Извлечение текста с помощью OneNote
OneNote OCR уже на протяжении нескольких лет остается одной из самых лучших программ для распознавания текста. Однако, распознавание это одна из тех менее известных функций, которые пользователи редко используют, но как только вы начнете ее использовать, вы будете удивлены тем, насколько быстрой и точной она может быть. Действительно, способность извлекать текст — одна из особенностей, которая делает OneNote лучше Evernote.
Это стандартная программа, скорее всего вам не придется устанавливать ее самостоятельно. Найдите ее на компьютере в папке Microsoft Office или же с помощью поиска на панели «Пуск». Запустите программу.
Инструкции по извлечению текста:
- Шаг 1. Откройте любую страницу в OneNote, желательно пустую.

Открываем любую страницу в OneNote
- Шаг 2. Перейдите в меню «Вставка»> «Изображения» и выберите файл изображения и настройте язык распознавания.
Выберите файл изображения
- Шаг 3. Щелкните правой кнопкой мыши по вставленному изображению и выберите «Копировать текст с изображения». Он сохранится в буфере обмена.



Копируем текст с изображения
Теперь вы можете вставить его куда угодно. Удалите вставленное изображение, если оно вам больше не нужно.

Вставляем текст куда угодно
На заметку! Это быстрый и удобный способ извлечения текста из картинки, но есть одно «но» — One Note работает подобным образом лишь с латиницей. Он не распознает русский текст.
Использование онлайн-сервисов
Онлайн-сервисы по распознаванию текста с изображения работают примерно по одному и тому же принципу. В примере ниже использовался Free Online OCR. На этом сайте стоит ограничение. Регистрация даст вам доступ к дополнительным функциям, недоступным для гостей: конвертировать многостраничный PDF (более 15 страниц) в текст, большие изображения и ZIP-архивы, выбирать языки распознавания, конвертировать в редактируемые форматы и многое другое. Распознать короткий тест можно и без регистрации.
- Шаг 1. Откройте сайт бесплатного OCR. Выберите изображение посредством кнопки «Select File». Это может быть и PDF файл.
Открываем сайт бесплатного OCR
- Шаг 2. Выберите язык и нажмите на кнопку «CONVERT».
Выбираем язык и нажимаем на кнопку «CONVERT»


Текст появится в поле ниже. Вы также можете скачать в формате Microsoft Word.
Этот способ имеет ряд преимуществ:
- Вам не придется скачивать и устанавливать стороннее программное обеспечение.
- Итог можно скачать в виде текстового документа.
- Это быстро.
- Более того на сайте можно распознавать текст на одном из множества предложенных языков.
Видео — Как распознавать текст с картинки, фотографии или PDF файла
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
- Шаг 1. Перейдите на сайт FineReader.
Открываем сайт FineReader
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.


Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Извлекаем текст

Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.

Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат |  |  |  |
Хотя рынок заполнен программным обеспечением OCR, которое может извлекать текст из изображений, хорошая программа OCR должна делать больше, чем просто распознавание текста. Она должна поддерживать макет содержимого, текстовые шрифты и графику как в исходном документе.
Понравилась статья?
Сохраните, чтобы не потерять!
| ||||||||||||||||||||||||||
.
конвертировать JPG в TXT (OCR) онлайн
Используйте эту форму для загрузки локального файла JPG и преобразования файла JPG в текстовый файл (* .txt).
1. Нажмите кнопку «Выбрать файл» (в разных браузерах может быть другое название кнопки, например «Обзор …»), откроется окно просмотра, выберите локальный файл JPG (* .JPG; * .JPEG; * .JPE ; * .JIF; * .JFIF; * .JFI) и нажмите кнопку «Открыть». Вы также можете добавить другой формат изображения, такой как BMP, PNG или TIFF и т. Д.
2. Нажмите «Конвертировать сейчас!» кнопку для преобразования. Подождите несколько секунд, пока не завершится преобразование файла.
3. Вы можете загрузить или просмотреть текстовый файл в браузере после преобразования. Для получения файлов не требуется адрес электронной почты.
Уведомление : Это онлайн-преобразование осуществляется с помощью программы с открытым исходным кодом Tesseract-OCR. Поддерживаемые языки: африкаанс, амхарский, арабский, ассамский, азербайджанский, азербайджанский, белорусский, бенгальский, тибетский, боснийский, болгарский, каталонский, кебуанский, чешский, китайский (упрощенный), китайский (традиционный), чероки, валлийский, датский, немецкий, дзонгха, Английский, эсперанто, модуль обнаружения математики / формул, эстонский, баскский, персидский, финский, французский, франкский, ирландский, галисийский, греческий, гуджарати, гаитянский, иврит, хинди, хорватский, венгерский, инуктитут, индонезийский, исландский, итальянский, яванский, Японский, каннада, грузинский, казахский, центрально-кхмерский, киргизский, корейский, курдский, лаосский, латинский, латышский, литовский, малаялам, маратхи, македонский, мальтийский, малайский, бирманский, непальский, голландский, норвежский, ория, панджаби — пенджаби, польский , Португальский, пушту, румынский, русский, санскрит, сингальский, словацкий, словенский, испанский, албанский, сербский, сербский (латинский), суахили, шведский, сирийский, тамильский, телугу, таджикский, тагальский, тайский, тигринья, турецкий, уйгурский, украинский , Урду, узбекский, вьетнамский, идиш.
Оптическое распознавание символов (OCR) : Оптическое распознавание символов (OCR) — это преобразование изображений в текст. Он широко используется в качестве формы ввода данных из печатных бумажных записей данных, будь то паспортные документы, счета-фактуры, банковские выписки, компьютеризированные квитанции, визитные карточки, почта, распечатки статических данных или любая подходящая документация. Это распространенный метод оцифровки печатных текстов, чтобы их можно было редактировать в электронном виде, искать, хранить более компактно, отображать в Интернете и использовать в машинных процессах, таких как машинный перевод, преобразование текста в речь, ключевые данные и интеллектуальный анализ текста.OCR — это область исследований в области распознавания образов, искусственного интеллекта и компьютерного зрения.
.
Добавить комментарий