
Поиск информации с использованием компьютера. Программные поисковые сервисы. Использование ключевых слов, фраз для поиска информации. Комбинации условия поиска. (СПО)
Тема: Поиск информации с использованием компьютера. Программные поисковые сервисы. Использование ключевых слов, фраз для поиска информации. Комбинации условия поиска.
Интернет –это глобальная компьютерная сеть, объединяющая многие локальные, региональные и корпоративные сети и включающая в себя десятки миллионов компьютеров.
Работая в сети, необходимо быстро ориентироваться в имеющемся объеме информации.
Для поиска информации используются в основном три основных типа:
-Указание адреса страницы — это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
— Перемещение по гипертекстовым ссылкам — это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу.
— Обращение к поисковой системе .
В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru), Rambler (rambler.ru), @mail.ru .
Поисковая система предоставляет возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины.
Яндекс — российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов.
Google — Лидер поисковых систем в Интернете.
Rambler — создан в 1996 году. Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова.
Использование ключевых слов, фраз для поиска информации. Комбинации условий поиска
Комбинации условий поиска
Поиск информации по ключевому слову (фразе) в Интернете аналогичен поиску информации о каком-то слове или фразе в книге, когда для этого используется так называемый Предметный указатель, где против слова или фразы указана страница текста, на которой можно найти его разъяснение. Запрос к поисковой машине может быть двух видов: простой и сложный. Простой запрос характеризуется вводом слова или словосочетания, при этом дополнительные знаки не используются. Сложный запрос строится с использованием так называемых операторов (ключевых слов), которые в каждой поисковой машине могут иметь различия.
Операторы поисковых запросов помогают получить полезную информацию об индексации сайта, выявить проблемы и даже разобраться в нюансах работы поисковых алгоритмов. В данной статье все операторы поиска без примеров, но зато они здесь ВСЕ и будут дополняться (или удаляться), чтобы информация была актуальна.
Общие для Яндекс и Google операторы.

Стоит добавить, что если Яндекс точно следует операторам, то Google может их проигнорировать, если посчитает, что есть результаты лучше.
Оператор “+” и “-“ — Поиск документов, которые обязательно содержат (или обязательно не содержат) указанное слово. Можно использовать несколько операторов в одном запросе, причем как «минус», так и «плюс»
Поиск по цитате, оператор кавычки «» — Поисковая система будет искать точное совпадение фразы. Можно использовать несколько раз в одном запросе. Даже можно добавить «минус» перед одним из запросов.
Оператор “*” звездочка — Яндекс: Используется для указания пропущенного слова в цитате. Одна звездочка – одно слово. Применяется только с оператором «кавычки». Google: Используется для указания пропущенных слов в запросе.
Оператор «|» — Поиск страниц содержащих любое из слов связанных этим оператором.
Оператор “~” — Яндекс: ищет документы, в которых слово указанное после оператора не содержится в одном предложении со словом до оператора. Google: ищет документы с указанным словом и его синонимами.

Операторы поиска для Яндекса
«!» — Поиск документов, где слово содержится только в заданной форме. Можно искать даже слова с заглавными буквами.
«!!» — Поиск документов, где слово содержится в любой форме, в любом падеже.
«&» — Поиск документов, где слова связанные оператором находятся в одном предложении.
«&&» — Тоже самое, только слова в пределах одного документа.
«<<» — Поиск слов в пределах документа, но релевантность (она влияет на положение в результатах поиска) рассчитывает только по первому слов (которое до оператора)
Оператор /n , где n максимальное расстояние между заданными словами
Поиск документов, в которых заданные слова располагаются в пределах n слов друг относительно друга и в обратном порядке следования.
Дополнительно можно задать прямой (+) или обратный (—) порядок следования слов в найденных документах.
Оператор /(m n), где
m — минимальное расстояние между заданными словами, n — максимальное расстояние между заданными словами
Поиск документов, в которых заданные слова располагаются на расстоянии не менее m и не болееn слов друг относительно друга.
Дополнительно можно задать прямой (+) или обратный (—) порядок следования слов в найденных документах.
Оператор && /n,
Где n — максимальное расстояние между предложениями, содержащими слова запроса
Поиск документов, в которых слова запроса (разделенные оператором) располагаются в пределах n предложений друг относительно друга.
Порядок, в котором идут слова запроса, не учитывается.
Оператор скобки ()
Группировка слов при сложных запросах.
Внутри заключенной в скобки группы также могут быть использованы любые операторы.
Документные операторы Яндекса
title: — поиск по заголовкам страниц
url: — поиск по страницам на заданном URL, например url:aiwastudio.ru/blog/*
site: — Поиск по всем поддоменам и страницам указанного сайта.
inurl: — Поиск по страницам, размещенным на данном хосте. Идентичен оператору url: с заданным именем хоста.
domain: — Поиск по страницам, расположенным на заданном домене.
mime: -Поиск по документам в заданном типе файла.
lang: — Поиск по страницам на заданном языке
date: — Поиск по страницам с ограничением по дате их последнего изменения. Год изменения указывается обязательно. Месяц и день можно заменить символом *.
cat: Поиск по страницам сайтов, зарегистрированных в Яндекс.Каталоге, тематическая рубрика или регион которых совпадают с заданным.

Перечисленные выше операторы не обязательно запоминать, т.к. расширенные поиск Яндекса по сути является интерфейсом к этим операторам. Т.е. вы сможете выбирать настройки поисковой формы и получать результат, как будто вводили операторы вручную.
Теперь недокументированные операторы:
Intext – ищет только те документы, текст которых содержит слова запроса, т.е. не в метатегах или еще где-то, а именно в тексте.
image – ищет все документы, в которых содержится изображение с заданным именем.
Anchormus – ищет ссылки на музыкальные файлы, содержащие указанный запрос в анкоре
Linkmus – ищет все страницы, с которые есть ссылка на указанный музыкальный файл
Inlink – для поиска в тексте ссылок
Linkint – поиск внутренних ссылок на определенный документ
Anchorint – поиск документов, содержащих указанный запрос в текстах своих ссылок на свои внутренние документы
idate — ищет документы с заданной датой последней индексации.
style – поиск по значению атрибута stylesheet тега link
applet – поиск по значению атрибута code тега applet:
script — поиск по значению атрибута src тега script
object – поиск по содержимому атрибутов тега object
action – поиск по значению атрибута action тега form
profile – поиск по значению атрибута profile тега head
inpos — поиск текста в пределах заданных позиций элементов на странице(inpos:0..100)

Операторы поиска для Google
Оператор «..» две точки — Используется для поиска диапазонов между числами.
Оператор «@» — Для поиска по тегам в соц. Сетях
Оператор «#» — Поиск по хештегам
Документные операторы Google
site: аналогично Яндексу ищет по указанному сайту или домену
link: поиск страниц, ссылающихся на указанный сайт
related: поиск страниц со схожим содержимым
info: С помощью этого оператора можно получить сведения о веб-адресе, в том числе ссылки на кешированную версию страницы, похожие сайты, а также страницы, ссылающиеся на указанную вами.
cache: просмотр кешированной версии страницы
filetype: поиск в указанных типах файлов, можно указать расширение
movie: поиск информации о фильмах
daterange: поиск страниц проиндексированных за указанный промежуток времени
allintitle: поиск страниц, у которых слова из запроса находятся в title
intitle: тоже самое, но часть запроса может содержаться и в другой части страниц
allinurl: поиск страниц, содержащих все слова запроса в url
inurl: тоже самое, но для одного слова
allintext: только в тексте
intext: для одного слова
allinanchor: поиск по словам в анкорах
inanchor:
define: поиск страниц с определением указанного слова

Если есть чем дополнить, или какие-то операторы уже не работают – пишите в комментариях.
Операторы поисковой системы Bing
contains: Оставляет результаты с сайтов, которые содержат ссылки на типы файлов, которые вы указываете
ext: Возвращает только веб-страницы с расширением, которое вы указываете
filetype: Возвращает только веб-страницы, созданные с типом файла, который вы указываете
inanchor: или inbody: или intitle: эти ключевые слова возвращают веб-страницы с заданным термином в метаданных, например якоре, тексте и названии сайта
ip: Находит сайты, которые размещены по определенному IP-адресу
language: Возвращает веб-страницы на определенном языке
loc: или location: Возвращает веб-страницы из определенной страны илирегиона
prefer: Дает приоритет условию поиска или другому оператору, чтобы cосредоточить результаты поиска.
site: Возвращает веб-страницы, которые принадлежат указанному сайту.
feed: Находит каналы RSS или Atom на веб-сайте по терминам, которые вы ищете.
hasfeed: Находит веб-страницы с каналами RSS или Atom на веб-сайте по терминам, которые вы ищете.
url: Проверяет, есть ли указанный домен или веб-адрес в индексе Bing.

Контрольные вопросы и задания
Что такое поисковая система?
Перечислите самые популярные поисковые системы.
Перечислите способы поиска информации в сети «Интернет»
Назовите назначение оператора поисковых запросов?
Составьте таблицу «Операторы поиска для Яндекса». Таблица должна содержать два столбца (название оператора, назначение оператора).
Составьте таблицу «Операторы поиска для Google». Таблица должна содержать два столбца (название оператора, назначение оператора).

Как правильно искать информацию в Интернете
Если поиск не приносит нужных результатов, то скорее всего вы неправильно ищете.
Чтобы найти то, что вы хотите, вам потребуется немного знаний о системе поиска. Достаточно будет 1 раз разобраться как правильно искать информацию в интернете и проблем с поисками у вас больше не возникнет. Весь процесс состоит из:
- Браузера — поисковая машина (Google Chrome, Mozila Firefox…).
- Поисковой системы — сайт, который выдаёт информацию на основе запроса (Google поиск, Yandex поиск).
- Вида запроса — например, какая погода завтра.
- Критерия запроса — например, за последний час или искать только в изображениях.
- Поисковой выдачи — обычно выводится 10 различных сайтов на страницу.
Перед тем как приступить к поиску нужно выбрать браузер.
Выбор браузера для поиска
От браузера зависит удобство и комфорт при поиске информации, а так же вид её отображения. Изначально на операционных системах Windows по умолчанию стоит браузер Internet Explorer. Не очень удобный и отображение сайтов в нём недостаточно хорошее. К тому же, по результатам тестирования, Internet Explorer показал наихудший результат.
Изначально на операционных системах Windows по умолчанию стоит браузер Internet Explorer. Не очень удобный и отображение сайтов в нём недостаточно хорошее. К тому же, по результатам тестирования, Internet Explorer показал наихудший результат.
Из всего множества браузеров международным лидером считается Google Chrome. За ним идут Opera, Mozilla Firefox и другие. В нём есть всё, что нужно пользователю для комфортного поиска.
Вот так он выглядит:
Необязательно использовать этот браузер, но я советую именно его.
Преимущества очевидны:
- Перевод страницы на родной язык в 1 клик.
- Быстрая скорость работы.
- Множество дополнительных приложений.
- Возможность открыть закрытую вкладку (CTR + SHIFT + T).
- Простое изменение масштаба просмотра (CTR + колесо мыши).
- Добавление в закладки в 1 клик.
- Режим инкогнито (не сохраняет историю посещений)
- Голосовой поиск.

Скачайте здесь.
Чтобы назначить его по умолчанию запустите Google Chrome >> Нажмите на значок настройки >> В разделе «Браузер по умолчанию» выберите Google Chrome:
Так же здесь можно выбрать поиск по умолчанию (об этом ниже).
Выбор поисковой системы
В России наиболее популярны 2 вида поиска — это Yandex и Google. Оба довольно неплохо справляются со своей задачей. Основное отличие их в том, что Google мировой лидер и создан универсально для всех стран, а Yandex навёрстывает упущенное от Google и создан специально для России и стран СНГ.
Нет смысла описывать другие системы. Их алгоритмы не так эффективны как у этих двух. Поставьте Google или Yandex по умолчанию как на изображении выше.
Правильное составление запроса и критерий.
Новички часто вводят неправильные запросы и получают в выдаче некачественные сайты с кучей рекламой и вирусов. Запрос должен быть точный, без лишних символов и с уточнением чего-либо если требуется. Ещё можно использовать точные названия или ключевые слова.
Запрос должен быть точный, без лишних символов и с уточнением чего-либо если требуется. Ещё можно использовать точные названия или ключевые слова.
Например, при поиске песни, вы не знаете её названия, но знаете некоторый текст, напишите его в запрос и песня найдётся.
Пример плохих запросов:
- Поиск изображения кота в интернете — поиск и так проходит в интернете, поисковая система это знает без вас.
- Скачать программу «Ccleaner» бесплатно — Не нужно ставить лишних знаков, в интернете и так 90% всего бесплатно.
- Интернет кот обои скачать — поисковая система не глупая и хорошо понимает человеческий язык.
- Форум про котов смотреть бесплатно без смс — много лишних условий, запрос должен быть коротким и понятным.
Пример хороших запросов:
- Изображение кота на диване
- Скачать книгу про рыжего кота
- Обои для рабочего стола с котом
- Форум про уход за котами
Я покажу примеры с использованием браузера Google Chrome. Возможно они будут работать и в вашем браузере. Если необходимо выбирайте критерий например, если вы ищете только изображение:
Возможно они будут работать и в вашем браузере. Если необходимо выбирайте критерий например, если вы ищете только изображение:
Возможности позволяют искать даже по картинке. Нажмите на специальный значок рядом с поисковой строкой.
Теперь остаётся ввести ссылку на изображение либо выбрать файл на компьютере. Найдутся все совпадающие изображения с разными размерами. Можно будет отфильтровать. Так же найдутся похожие изображения.
Иногда следует учитывать географию запроса например, если вы ищете, что-то в определенном городе, то впишите его названия в конце запроса. Какие запросы актуальны вы можете бесплатно проверить тут. Чем больше показов в месяц, тем лучше.
Несколько примеров грамотного использования поиска
Определение значения слова. Поставьте перед любым словом define: и вы узнаете, что оно означает.
Встроенный калькулятор. Вы можете вписывать математические операции и получите результат их решения вот в таком виде:
Просмотр погоды. Введя слово погода: (ваш город) вы получите всю информацию о погоде на данный момент в вашем городе. Пример ниже.
Введя слово погода: (ваш город) вы получите всю информацию о погоде на данный момент в вашем городе. Пример ниже.
Если вам нужно найти, что-нибудь специфическое и необычное, то можно воспользоваться расширенным поиском. Для этого справа от поисковой строки зайдите в настройки и выберите расширенный тип поиска в выпадающем меню. Пример ниже.
Затем появится окно, в котором вы сможете тонко настроить все фильтры для нахождения нужной вам информации. Вот как оно выглядит:
Выбор информации в поисковой выдаче
Для правильного поиска информации важно уметь фильтровать поисковую выдачу. Определять сайты с нужной вам информацией до того как вы перейдёте на них. Рассмотрим пример по запросу Ccleaner:
Если вы знаете официальный сайт программы, то лучше выбрать именно его. В данном случае его адрес подчёркнут красным. Неофициальные сайты подчёркнуты желтым. Официальный сайт на английском, но его можно легко в 1 клик перевести на русский.
Скачивая с сайта производителя программы, вы не получите вирусов или неактуальную версию программы (конечно если производитель следит за своей репутацией).
В случаях если по запросу выводится совсем не та информация, то воспользуйтесь подсказкой внизу страницы (в Google Chrome):
В основном вся нужная информация содержится на первых 10 сайтах. Не рекомендуется смотреть следующие страницы так, как чем дальше сайт от первой позиции, тем хуже его качество (не всегда, но в основном — это так).
Сейчас поисковые системы хорошо понимают людей и достаточно будет правильно составить запрос для получения нужной информации. Даже если вы составите некорректный запрос, то система исправит вас.
Дополнительные возможности
Существуют различные фильтры, которые вы можете использовать. Посмотрите на них в таблице ниже.
| Пример | Результат |
|---|---|
site:sitemozg. ru ru | Все страницы указанного сайта |
| define:домен | Определение слова домен |
| related:sitemozg.ru | Похожие сайты |
| собака OR кот | Страницы с одним из двух слов |
| ноутбук $100 | Страницы с указанной ценой |
| купить замок -здание | Исключает страницы со словом после символа — |
| «кажется дождь начинается» | Страницы где запрос имеет точно такой вид |
| висит * нельзя * | Подставляет вместо * слова больше всего подходящие по смыслу |
Таким образом можно отфильтровать информацию так, как вам нужно. Здесь далеко не все хитрости. Посмотрите видео, там есть ещё несколько других.
Вы хорошо владеете поиском в браузере?Poll Options are limited because JavaScript is disabled in your browser.
 «>
«>Отлично! Всё могу найти. 50%, 1 голос
1 голос 50%
1 голос — 50% из всех голосов
Нахожу почти всё. 50%, 1 голос
1 голос 50%
1 голос — 50% из всех голосов
Иногда сталкиваюсь с затрудниями. 0%, 0 голосов
0 голосов
0 голосов — 0% из всех голосов
Часто не получается найти, то что нужно.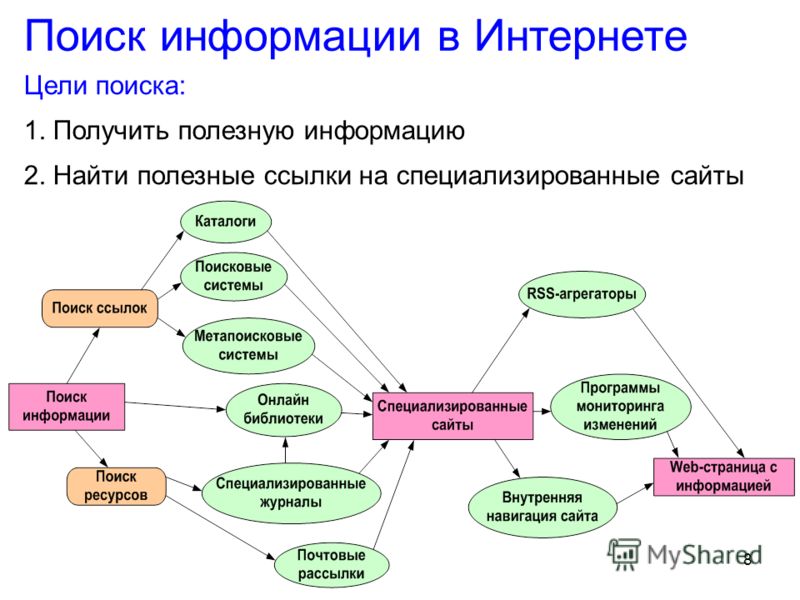 0%, 0 голосов
0%, 0 голосов
0 голосов
0 голосов — 0% из всех голосов
Всего голосов: 2
8 июля, 2016
×
Вы или с вашего IP уже голосовали. Голосовать
Правила эффективного поиска информации в интернете
Поиск информации – одна из задач, которую приходится решать каждому пользователю интернета.
Приступая к поиску данных в интернете, стоит определить цель поиска. Полезно ответить для себя на следующие вопросы:
- известны ли вам адреса ресурсов сети, с которых можно начать поиск?
- что вы уже знаете о проблеме, информацию о которой ищете?
- с каких ключевых слов стоит начать поиск?
- сколько времени вы готовы потратить на поиск нужных данных?
От того, как именно поставлена задача, во многом зависит и стратегия поисковой деятельности, и выбор соответствующих поисковых средств.
Существуют три основных способа поиска информации в интернете:
Способ 1: Указание адреса страницы
Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
Способ 2: Передвижение по гиперссылкам
Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу. Но этот способ очень простой и подходит для начинающего пользователя.
Способ 3: Обращение к поисковой системе
На помощь приходят специальные поисковые системы (их еще называют поисковыми машинами).
Результатом выполнения запроса является перечень ссылок на Web-страницы, рядом с которыми присутствуют заданные текстовые фрагменты. Наиболее популярные поисковые серверы: Яндекс (yandex.ru), Гугл (google.ru) и Рамблер (rambler.ru). Языки запросов различных поисковиков несколько отличаются друг от друга.
Поисковая система Яндекс
- Чтобы найти информацию с помощью поисковой системы Яндекс, откроем главную страницу. Строка для ввода поискового запроса расположена в верхней части страницы, в области, выделенной желтым фоном.

Укажем в ней необходимые ключевые слова и нажмем на клавиатуре клавишу или щелкнем мышью на кнопке «Найти», размещенной возле строки поиска.
Получив такую команду, Яндекс просмотрит всю свою базу данных и попытается найти в ней веб-страницы, где встречается введенное нами слово или словосочетание. При этом нужно заранее учитывать, что чем обширнее наш запрос, тем меньшее количество веб-страниц будет ему соответствовать.
- По умолчанию на одной странице Яндекс отображает только 10 таких ссылок, поэтому для ознакомления с полными результатами поиска необходимо будет листать страницы с помощью цифр-ссылок.
- Каждый обнаруженный ресурс в результатах поиска представлен названием веб-страницы и текстом ссылки. Кроме того, в большинстве случаев поисковая система демонстрирует небольшой фрагмент текста, содержащегося на той или иной найденной веб-странице, в котором обнаружено совпадение с текстом вашего запроса. При этом слова, которые мы ввели для поиска, в этих фрагментах будут выделены полужирным начертанием.

- Внизу страницы с результатами поиска, есть строка «в других поисковых системах». Рядом с этими словами имеются ссылки на несколько других популярных поисковых систем. Поэтому, если мы не нашли с помощью Яндекса нужной нам информации, можно воспользоваться другими поисковыми системами, перейдя по ссылке.
Поиск информации в Яндексе можно осуществлять
в простом и расширенном поисковом режиме.
- Простой поиск
Поиск по одному или нескольким ключевым словам, введенным в строку запроса.
Перед тем как начинать вводить в строку поиска поисковой системы запрос, тщательно его сформулируйте.
Чем более четкой будет выбранная формулировка, тем меньше ненужных вам сайтов предложит в результатах поиска поисковая система.
- Расширенный поиск
Все популярные поисковые системы располагают специальными возможностями для расширенного поиска ресурсов.
Чтобы попасть на веб-страницу, предоставляющую такие возможности, необходимо воспользоваться ссылкой с названием типа «Расширенный поиск».
Перейдя по этой ссылке, мы увидим большую поисковую форму, в которой можно указать множество параметров.
Поисковая система Яндекс позволяет, например, настраивать параметры поиска слов в зависимости от их расположения (рядом, в одном предложении, на одной странице) и формы.
Кроме того, она может искать веб-страницы по их языку (русский, украинский, белорусский и т.д.), по дате последнего изменения и даже по формату файла веб-страницы.
Наконец, с помощью Яндекса информацию можно искать на каком-то конкретном сайте. Это бывает полезно в том случае, если на нужном вам сайте нет встроенной поисковой системы.
Для каждой поисковой системы существуют свои языки запросов. Мы познакомимся с логическим языком запросов для Яндекса, который позволяет в режиме обычного поиска вводить в строку поиска дополнительные служебные команды, уточняющие ваши требования.
 Рассмотрим некоторые такие команды.
Рассмотрим некоторые такие команды.- Используйте знаки «+» и «-«.
Чтобы исключить документы, где встречается определенное слово, поставьте перед ним знак минуса (-). И наоборот, чтобы определенное слово обязательно присутствовало в документе, поставьте перед ним плюс (+). Обратите внимание, что слово и знак плюс-минус должны быть написаны слитно.
Например, если вы хотите узнать про аквариумных рыбок, но без продажи и разведения, то набираем в поисковой строке:
«аквариумные рыбки -разведение -продажа».
- Поиск точного соответствия — знак «!».
Искать по точной словоформе. Вы можете дать команду Яндексу не учитывать формы слов из запроса при поиске.
Например, запрос !иванов найдет только страницы с упоминанием этой фамилии, а не города «Иваново».
- Поиск точной фразы – кавычки.
Помещать поисковый запрос в кавычки (например, «кто виноват и что делать») нужно только в том случае, если мы хотим найти фразу, на 100% совпадающую с текстом нашего запроса.
Кавычки заставляют поисковый механизм отбирать лишь документы, в которых слова из запроса стоят в точно таком же порядке, в котором мы указали их в поисковом запросе. Если же кавычек нет, то по запросу «кто виноват и что делать» поисковая система может предложить нам страницу, содержащую фразу «кто виноват — тому и делать, что скажут» или же «ну и кто виноват, что Петр Петрович не умеет делать пельмени». Формально при этом поисковая система справится со своей работой, ведь в указанных отрывках есть все слова из введенной фразы. А то, что они стоят совсем не в том порядке, в котором нам нужно, — это уже другой вопрос, который и уточняется использованием кавычек.
При работе с поисковыми системами рано или поздно мы встретим слово «релевантность».
Релевантность — это степень соответствия найденных документов нашему запросу. Например, в Яндексе его можно обнаружить внизу каждой веб-страницы, содержащей результаты поиска, сразу под набором цифр-ссылок. Здесь оно используется в качестве параметра для функции «Отсортировано». Помимо параметра по релевантности, доступен также вариант по дате.
Здесь оно используется в качестве параметра для функции «Отсортировано». Помимо параметра по релевантности, доступен также вариант по дате.
Если страницы в результатах поиска сортируются по релевантности, то это значит, что в самом начале указываются сайты с наибольшим уровнем соответствия вашему запросу, после них располагаются ресурсы с меньшим уровнем релевантности и т.д.
Детские поисковые системы
- Чтобы обезопасить детей от ненужной информации, созданы специальные детские поисковые системы, которые индексируют не все сайты, а только сайты с детской или околодетской тематикой.
Для самых юных пользователей Интернета создана специальная поисковая система АгА, которая предназначена для поиска информации детских ресурсов. Она содержит много ресурсов по воспитанию и здоровью детей, поэтому ее можно рекомендовать не только детям, но и родителям. Очень удобно искать в этой поисковой системе, используя карту сайта.
АгА не только поисковый сервис.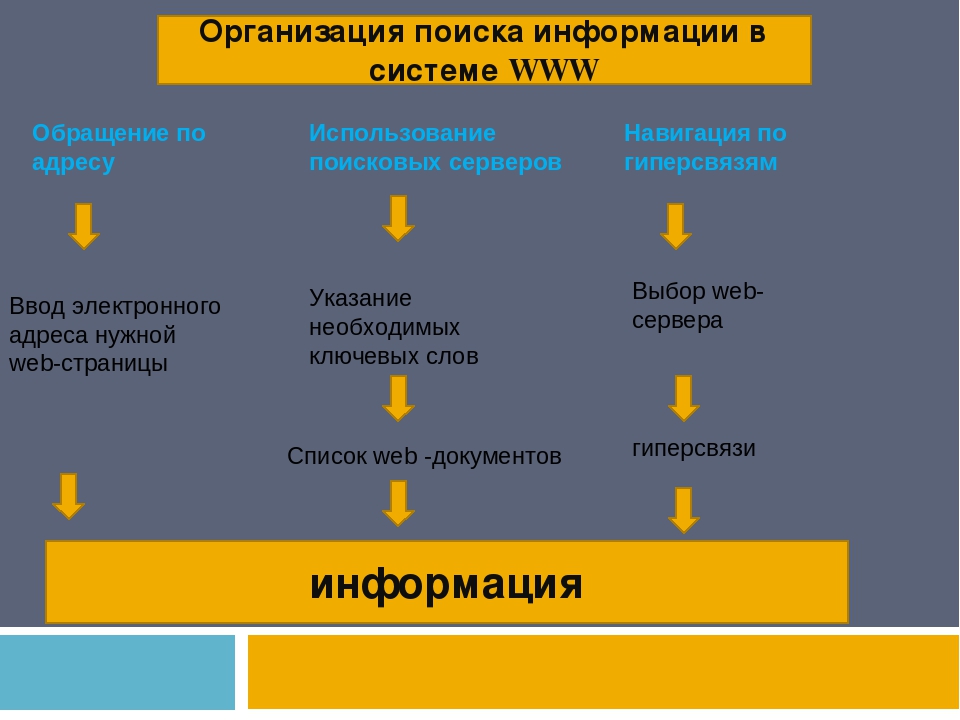 Здесь есть всеми любимые мультики, раскраски, просмотр диафильмов, помощь по разным школьным предметам и т.д.
Здесь есть всеми любимые мультики, раскраски, просмотр диафильмов, помощь по разным школьным предметам и т.д.
Quintura для Детей – визуальный поиск по детским ресурсам, разработанный специально для детей и ориентирован на школьников младших и средних классов.
Для поиска используется интерактивное облако Quintura. Красочный и привлекательный интерфейс сервиса содержит несколько интерактивных картинок, кликая на которые, дети сразу могут выбрать интересную для себя тему, например: наука, музыка, динозавры или игры.
Интернет Служба World Wide Web. Способы поиска информации в Интернете
Содержание урока
Интернет Служба World Wide Web. Интернет — мировое содружество сетей
Интернет Служба World Wide Web. Гиперструктура WWW
Способы поиска информации в Интернете. Три способа поиска в Интернете
Способы поиска информации в Интернете. Язык запросов поисковой системы
Коллекция цифровых образовательных ресурсов
Способы поиска информации в Интернете
Три способа поиска в Интернете
Три способа поиска в Интернете
Интернет в целом и Всемирная паутина в частности предоставляют пользователю доступ к тысячам серверов и миллионам web-страниц, на которых хранится невообразимый объем информации.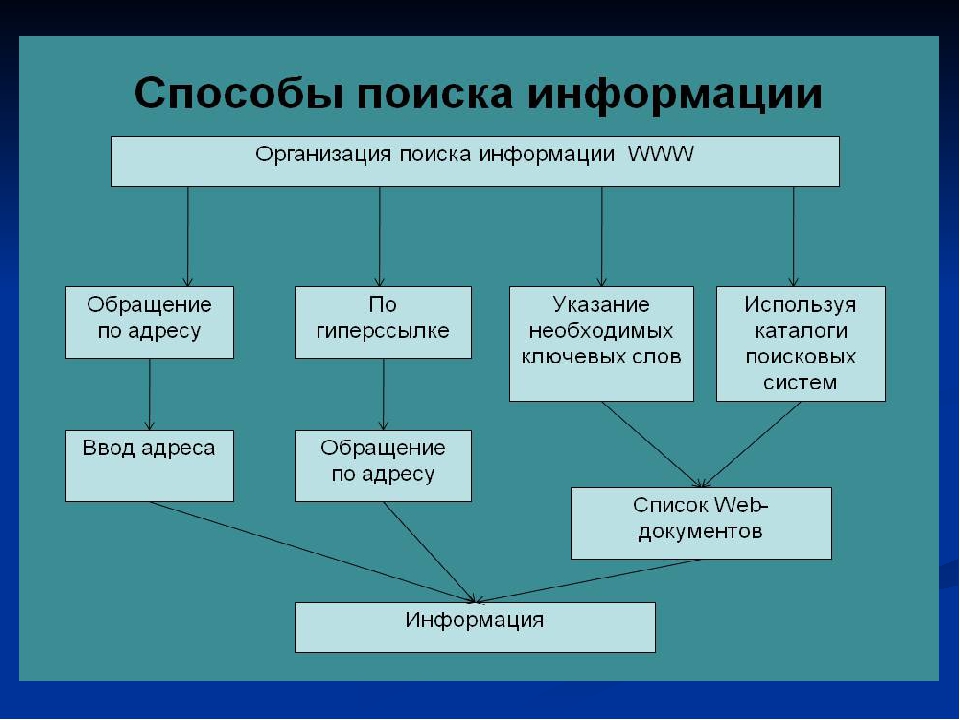 Как не потеряться в этом «информационном океане»? Для этого необходимо научиться искать и находить нужную информацию в сети.
Как не потеряться в этом «информационном океане»? Для этого необходимо научиться искать и находить нужную информацию в сети.
Как уже было сказано, существуют три основных способа поиска информации в Интернете.
1. Указание адреса страницы. Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа.
2. Передвижение по гиперссылкам. Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу. Если текущий документ посвящен, например, музыке, то, используя гиперссылки этого документа, вряд ли можно будет попасть на сайт, посвященный спорту.
3. Обращение к поисковому серверу (поисковой системе). Использование поисковых серверов — наиболее удобный способ поиска информации. В настоящее время в русскоязычной части Интернета популярны следующие поисковые серверы:
• Yandex;
• Rambler;
• Google.
Существуют и другие поисковые системы.
Поисковые серверы
Наиболее доступным и удобным способом поиска информации во Всемирной паутине является использование поисковых систем. При этом поиск информации можно осуществлять по каталогам, а также по набору ключевых слов, характеризующих отыскиваемый текстовый документ.
Рассмотрим использование поисковых серверов более подробно. Поисковый сервер содержит большое количество ссылок на самые различные документы, и все эти ссылки систематизированы в тематические каталоги.
Например: спорт, кино, автомобили, игры, наука и др. Причем эти ссылки устанавливаются сервером самостоятельно в автоматическом режиме путем регулярного просмотра всех появляющихся во Всемирной паутине web-страниц. Кроме того, поисковые серверы предоставляют пользователю возможность поиска информации по ключевым словам. После ввода ключевых слов поисковый сервер начинает просматривать документы на других web-серверах и выводить на экран ссылки на те документы, в которых встретились указанные слова. Обычно результаты поиска сортируются по убыванию специального рейтинга документов, который показывает, насколько полно заданный документ отвечает условиям поиска или насколько часто он запрашивается в сети.
Обычно результаты поиска сортируются по убыванию специального рейтинга документов, который показывает, насколько полно заданный документ отвечает условиям поиска или насколько часто он запрашивается в сети.
Поиск информации в Интернете/Советы по поиску — Викиучебник
- Определитесь с инструментами поиска.
Для обнаружения в текстах фрагментов, аналогичных заданному, используются инструменты линейного поиска информации. К таким инструментам относятся прежде всего общедоступные поисковые машины. Для нахождения данных о связях между объектами используйте системы, позволяющие запрос по связям.
- Проверяйте орфографию.
Если поиск не нашел ни одного документа, то вы, возможно, допустили орфографическую ошибку в написании слова. Проверьте правильность написания. Если вы использовали при поиске несколько слов, то посмотрите на количество каждого из слов в найденных документах (перед их списком после фразы «Результат поиска»). Какое-то из слов не встречается ни разу? Скорее всего, его вы и написали неверно.
Какое-то из слов не встречается ни разу? Скорее всего, его вы и написали неверно.
- Используйте синонимы.
Если список найденных страниц слишком мал или не содержит полезных страниц, попробуйте изменить слово. Например, вместо «рефераты» возможно больше подойдет «курсовые работы» или «сочинения». Попробуйте задать для поиска три-четыре слова-синонима сразу. Для этого перечислите их через вертикальную черту (|). Тогда будут найдены страницы, где встречается хотя бы одно из них. Например, вместо «фотографии» попробуйте «фотографии | фото | фотоснимки».
- Ищите больше, чем по одному слову.
Слово «психология» или «продукты» дадут при поиске поодиночке большое число бессмысленных ссылок. Добавьте одно или два ключевых слова, связанных с искомой темой. Например, «психология Юнга» или «продажа и покупка продовольствия». Рекомендуем также сужать область вашего вопроса. Если вы интересуетесь автомобилями ВАЗа, то запросы «автомобиль Волга» или «автомобиль ВАЗ» выдадут более подходящие документы, чем «легковые автомобили».
- Не пишите большими буквами
Начиная слово с большой буквы, вы не найдете слов, написанных с маленькой буквы, если это слово не первое в предложении. Поэтому не набирайте обычные слова с Большой Буквы, даже если с них начинается ваш вопрос Яндексу. Заглавные буквы в запросе рекомендуется использовать только в именах собственных. Например, «группа Черный кофе», «телепередача Здоровье».
- Найти похожие документы
Если один из найденных документов ближе к искомой теме, чем остальные, нажмите на ссылку «найти похожие документы». Ссылка расположена под краткими описаниями найденных документов. Яndex проанализирует страницу и найдёт документы, похожие на тот, что вы указали. Но если эта страница была стерта с сервера, а Яндекс еще не успел удалить ее из базы, то вы получите сообщение «Запрошенный документ не найден».
- Используйте знаки «+» и «-«
Чтобы исключить документы, где встречается определенное слово, поставьте перед ним знак минуса. И наоборот, чтобы определенное слово обязательно присутствовало в документе, поставьте перед ним плюс. Обратите внимание, что между словом и знаком плюс-минус не должно быть пробела. Например, если вам нужно описание Парижа, а не предложения многочисленных турагентств, имеет смысл задать такой запрос «путеводитель по парижу -агентство -тур». Плюс стоит использовать в том случае, когда нужно найти так называемые стоп-слова (наиболее частотные слова русского языка, в основном это местоимения, предлоги, частицы). Чтобы найти цитату из Гамлета, надо задать запрос «+быть или +не быть».
И наоборот, чтобы определенное слово обязательно присутствовало в документе, поставьте перед ним плюс. Обратите внимание, что между словом и знаком плюс-минус не должно быть пробела. Например, если вам нужно описание Парижа, а не предложения многочисленных турагентств, имеет смысл задать такой запрос «путеводитель по парижу -агентство -тур». Плюс стоит использовать в том случае, когда нужно найти так называемые стоп-слова (наиболее частотные слова русского языка, в основном это местоимения, предлоги, частицы). Чтобы найти цитату из Гамлета, надо задать запрос «+быть или +не быть».
- использовать язык запросов
С помощью специальных знаков вы сможете сделать запрос более точным. Например, укажите, каких слов не должно быть в документе, или что два слова должны идти подряд, а не просто оба встречаться в документе. (Описание синтаксиса языка запросов)
- Искать без морфологии
Вы можете указать Яндексу не перебирать все словоформы слов из запроса при поиске. Например, !лукоморья найдет только страницы, цитирующие строчку из стихотворения Пушкина («У лукоморья дуб зеленый»).
- Поиск картинок и фотографий
Яндекс умеет искать не только в тексте документа, но и отыскивать картинки по названию файла или подписи. Для этого перейдите в «расширенный поиск». Для поиска картинки предусмотрены два поля. В поле «Название картинки» вписываются слова для поиска по названиям картинок, обычно появляющихся, когда к картинке подводится курсор. Например, название картинки «Венера» выдаст все страницы с картинками Венеры (всего, что можно понимать под этим словом).
В поле «Подпись к картинке» вписывается название файла, содержащего картинку. Например, запрос dog найдет в Интернете все картинки, в имени файла которых встречается слово «dog». С большой вероятностью эти картинки связаны с собаками.
Поиск информации в интернете. Пошаговая инструкция ⋆ Детский мир
Информацию можно искать разными способами – в словарях, справочниках, энциклопедиях и других книгах. Можно по телефону обратиться в справочную службу. А еще очень удобно искать информацию с помощью интернета. Для этого надо открыть специальную программу просмотра ресурсов интернета – Microsoft Internet Explorer и ввести краткий вопрос в строку поиска поисковой системы Яндекс, Рамблер или какой-то другой.
Правила набора текста
1. Чтобы ввести текст в строку поиска, установи курсор в начало строки поиска и щелкни левой кнопкой мыши.
2. Прописные буквы набирай, нажимая на клавишу нужной буквы на клавиатуре и одновременно на клавишу Shift.
3. Если вместо одной буквы случайно наберешь другую, выдели ее курсором, а затем нажми клавишу Delete.
4. Чтобы выделить букву или слово, нажми левую кнопку мыши и, удерживая ее, вдели курсором нужную букву или слово.
5. Выше букв на клавиатуре расположены цифры. Если нажать на клавишу цифры и одновременно на клавишу Shift, то можно набрать символ (кавычки, двоеточие и др.), изображенный на соответствующей клавише.
Ищем информацию в интернете
1. Включи компьютер с помощью кнопки «пуск» на системном блоке.
2. После того как компьютер полностью загрузится, на мониторе появится изображение рабочего стола.
3. Щелкни мышкой по значку программы Microsoft Internet Explorer на рабочем столе. В открывшемся окне поисковой системы установи курсор в строке поиска и набери какой-нибудь запрос. Щелкни мышкой по кнопке найти.
4. В новом окне откроется список ресурсов, которые содержат твой запрос. Щелкни мышкой по любой строчке из этого списка. Тебе откроется окно сайта, на котором ты увидишь всю интересующую тебя информацию. По ссылкам переходи с раздела на раздел.
5. Как только ты найдешь и прочитаешь ту информацию, которую искал, закрой все окна по очереди, щелкая мышкой по кнопке «закрыть» в правом верхнем углу каждого окна.
6. Выключи компьютер. Для этого в левом нижнем углу рабочего стола щелкни по кнопке «пуск». В открывшемся окне выбери строку «завершение работы». Щелкни по «ок».
правил запланированных запросов — список по группе ресурсов (Azure Monitor)
Список правил поиска по журналам в группе ресурсов.
В этой статье
GET https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/microsoft.insights/scheduledQueryRules?api-version=2018-04-16 С дополнительными параметрами:
GET https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/microsoft.insights /duledQueryRules? api-version = 2018-04-16 & $ filter = {$ filter} Параметры URI
| Имя | В | Требуется | Тип | Описание |
|---|---|---|---|---|
ресурс | путь | Правда | Имя группы ресурсов. | |
подписка | путь | Правда | Идентификатор подписки Azure. | |
api-версия | запрос | Правда | Версия клиентского API. | |
$ фильтр | запрос | Фильтр, применяемый к операции. Для получения дополнительной информации см. Https://msdn.microsoft.com/en-us/library/azure/dn931934.aspx |
Ответы
Безопасность
azure_auth
Поток OAuth3 для Azure Active Directory
Тип:
oauth3
Поток:
неявный
URL-адрес авторизации:
https://login.microsoftonline.com/common/oauth3/authorize
Прицелы
| Имя | Описание |
|---|---|
| user_impersonation | выдавать себя за свою учетную запись пользователя |
Примеры
Правила списка
Образец запроса
GET https: // management.azure.com/subscriptions/14ddf0c5-77c5-4b53-84f6-e1fa43ad68f7/resourcegroups/gigtest/providers/microsoft.insights/scheduledQueryRules?api-version=2018-04-16 Пример ответа
{
"значение": [
{
«id»: «/subscriptions/b67f7fec-69fc-4974-9099-a26bd6ffeda3/resourceGroups/Rac46PostSwapRG/providers/microsoft.insights/scheduledQueryRules/logalertfoo»,
"name": "logalertfoo",
"type": "Microsoft.Insights / scheduleQueryRules",
"location": "Запад США",
"теги": {},
"properties": {
"description": "описание оповещения журнала",
"enabled": "false",
"lastUpdatedTime": "2017-06-23T21: 23: 52.0221265Z ",
"provisioningState": "Успешно",
"источник": {
"запрос": "запросы",
"queryType": "ResultCount",
"dataSourceId": "/subscriptions/b67f7fec-69fc-4974-9099-a26bd6ffeda3/resourceGroups/Rac46PostSwapRG/providers/microsoft.insights/components/sampleAI"
},
"график": {
"frequencyInMinutes": 15,
"timeWindowInMinutes": 15
},
"действие": {
"odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction ",
«серьезность»: «1»,
"триггер": {
"thresholdOperator": "GreaterThan",
«порог»: 2,
"metricTrigger": {
"thresholdOperator": "LessThan",
«порог»: 2,
"metricTriggerType": "Всего",
"metricColumn": "user_Id"
}
},
"aznsAction": {
"actionGroup": [],
"emailSubject": "Заголовок сообщения электронной почты",
"customWebhookPayload": "{}"
}
}
}
},
{
«идентификатор»: «/ подписки / b67f7fec-69fc-4974-9099-a26bd6ffeda3 / resourceGroups / Rac46PostSwapRG / Provider / microsoft.insights / scheduleQueryRules / logalertfoo ",
"name": "logalertfoo",
"type": "Microsoft.Insights / scheduleQueryRules",
"location": "Запад США",
"теги": {},
"properties": {
"description": "описание оповещения журнала",
"enabled": "true",
"lastUpdatedTime": "2017-06-23T21: 23: 52.0221265Z",
"provisioningState": "Успешно",
"источник": {
"запрос": "запросы",
"queryType": "ResultCount",
«dataSourceId»: «/ subscriptions / b67f7fec-69fc-4974-9099-a26bd6ffeda3 / resourceGroups / Rac46PostSwapRG / Provider / microsoft.идеи / компоненты / sampleAI "
},
"график": {
"frequencyInMinutes": 10,
"timeWindowInMinutes": 30
},
"действие": {
"odata.type": "Microsoft.WindowsAzure.Management.Monitoring.Alerts.Models.Microsoft.AppInsights.Nexus.DataContracts.Resources.ScheduledQueryRules.AlertingAction",
«серьезность»: «1»,
"триггер": {
"thresholdOperator": "GreaterThan",
«порог»: 3
},
"aznsAction": {
"actionGroup": [],
"emailSubject": "Заголовок сообщения электронной почты",
"customWebhookPayload": "{}"
}
}
}
}
]
} Определения
AlertingAction
Укажите действие, которое необходимо предпринять, если тип правила — Предупреждение
| Имя | Тип | Описание |
|---|---|---|
| aznsAction | Справочник по группе действий Azure. | |
| odata.type | строка:
| Задает действие.Поддерживаемые значения — AlertingAction, LogToMetricAction |
| строгость | Уровень опасности | |
| дросселированиеInMin | время (в минутах), в течение которого предупреждения должны быть ограничены или подавлены. | |
| триггер | Условие срабатывания, которое приводит к срабатыванию правила предупреждения. |
AlertSeverity
Уровень серьезности предупреждения
| Имя | Тип | Описание |
|---|---|---|
| 0 | ||
| 1 | ||
| 2 | ||
| 3 | ||
| 4 |
AzNsActionGroup
Группа действий Azure
| Имя | Тип | Описание |
|---|---|---|
| actionGroup | Справочник по группе действий Azure. | |
| customWebhookPayload | Пользовательские полезные данные для отправки для всех URI веб-перехватчиков в группе действий Azure | |
| Тема письма | Переопределение настраиваемой темы для всех идентификаторов электронной почты в группе действий Azure |
Условный оператор
Условие результата Критерии оценки. Поддерживаемые значения — «Больше, чем», «Меньше, чем» или «Равно».
| Имя | Тип | Описание |
|---|---|---|
| Равно | ||
| Больше чем | ||
| Меньше, чем |
Критерии
Задает критерии преобразования журнала в метрику.
| Имя | Тип | Описание |
|---|---|---|
| Габаритные размеры | Список измерений для создания показателя | |
| metricName | Название метрики |
Размер
Задает критерии преобразования журнала в метрику.
| Имя | Тип | Описание |
|---|---|---|
| название | Название измерения | |
| оператор | Оператор для значений размеров | |
| ценности | Список значений измерений |
включено
Флаг, указывающий, включено ли правило поиска по журналу.Значение должно быть истинным или ложным
| Имя | Тип | Описание |
|---|---|---|
| ложный | ||
| правда |
Ответ на ошибку
Описывает формат ответа об ошибке.
| Имя | Тип | Описание |
|---|---|---|
| код | Код ошибки | |
| сообщение | Сообщение об ошибке, указывающее, почему операция не удалась. |
LogMetricTrigger
Дескриптор триггера показателей журнала.
| Имя | Тип | Описание |
|---|---|---|
| metricColumn | Оценка метрики по определенному столбцу | |
| metricTriggerType | Метрический тип триггера — «Последовательный» или «Итого» | |
| порог | Порог срабатывания метрики. | |
| thresholdOperator | Операция оценки для метрики — «Больше, чем», «Меньше, чем» или «Равно». |
LogSearchRuleResource
Ресурс правила поиска журнала.
| Имя | Тип | Описание |
|---|---|---|
| мне бы | Идентификатор ресурса Azure | |
| место расположения | Расположение ресурса | |
| название | Имя ресурса Azure | |
| свойства.действие | Действие: | Необходимо выполнить действие при выполнении правила. |
| properties.description | Описание правила поиска по журналу. | |
| properties.enabled | Флаг, указывающий, включено ли правило поиска по журналу. Значение должно быть истинным или ложным | |
| свойства.lastUpdatedTime | Последний раз правило обновлялось в формате IS08601. | |
| properties.provisioningState | Состояние инициализации правила запланированного запроса | |
| properties.schedule | Расписание (частота, временное окно) для правила. Обязательно для типа действия — AlertingAction | |
| свойства.источник | Источник данных, по которому правило будет запрашивать данные | |
| теги | Теги ресурсов | |
| тип | Тип ресурса Azure |
LogSearchRuleResourceCollection
Представляет коллекцию ресурсов правила поиска по журналу.
LogToMetricAction
Укажите действие, которое необходимо предпринять, когда тип правила преобразует журнал в метрику
| Имя | Тип | Описание |
|---|---|---|
| критерии | Критерии метрики | |
| одата.тип | строка:
| Задает действие.Поддерживаемые значения — AlertingAction, LogToMetricAction |
metricTriggerType
Метрический тип триггера — «Последовательный» или «Итого»
| Имя | Тип | Описание |
|---|---|---|
| Последовательный | ||
| Общее |
оператор
Оператор для значений размеров
| Имя | Тип | Описание |
|---|---|---|
| Включают |
ProvisioningState
Состояние инициализации правила запланированного запроса
| Имя | Тип | Описание |
|---|---|---|
| Отменено | ||
| Развертывание | ||
| Не удалось | ||
| Удалось |
QueryType
Установить значение ResultAccount
| Имя | Тип | Описание |
|---|---|---|
| ResultCount |
График
Определяет, как часто запускать поиск и временной интервал.
| Имя | Тип | Описание |
|---|---|---|
| frequencyInMinutes | частота (в минутах), с которой должно оцениваться условие правила. | |
| timeWindowInMinutes | Временное окно, для которого необходимо получить данные для запроса (должно быть больше или равно frequencyInMinutes). |
Источник
Задает поисковый запрос журнала.
| Имя | Тип | Описание |
|---|---|---|
| авторизованные ресурсы | Список ресурсов, указанных в запросе | |
| dataSourceId | URI ресурса, по которому должен выполняться поисковый запрос журнала. | |
| запрос | Журнал поискового запроса.Обязательно для типа действия — AlertingAction | |
| queryType | Установите значение ResultCount. |
Условие триггера
Условие, которое приводит к правилу поиска по журналу.
| Имя | Тип | Описание |
|---|---|---|
| metricTrigger | Условие запуска для правила запроса метрики | |
| порог | Результат или порог подсчета, на основе которого должно срабатывать правило. | |
| thresholdOperator | Операция оценки для правила — «GreaterThan» или «LessThan». |
Информационные правила: стратегическое руководство по сетевой экономике: Шапиро, Карл: Бесплатная загрузка, заимствование и потоковая передача: Интернет-архив
Включает библиографические ссылки и указатель
В информационных правилах авторы Шапиро и Вариан показывают, что многие классические экономические концепции могут обеспечить понимание и понимание, необходимые для успеха в век информации.Они утверждают, что если менеджеры серьезно хотят разработать эффективные стратегии конкуренции в новой экономике, они должны понимать фундаментальную экономику информационных технологий. Независимо от того, принимает ли информация форму программного кода или записанной музыки, публикуется в книге или журнале или даже размещается на веб-сайте, менеджеры должны знать, как оценить последствия ценообразования, защиты и планирования новых версий информационных продуктов и услуг, и системы. Информационные правила — первая книга, в которой экономика информации и сетей превращается в практические бизнес-стратегии. Это руководство по успешным действиям, которые могут помочь бизнес-лидерам успешно справляться с трудными решениями информационной экономики.Охватываемые предметы включают в себя: конкурентное преимущество, экономический анализ, теория игр, информационный век, информационная экономика, информационные технологии, интеллектуальная собственность, маркетинговая стратегия, новая экономика, ценообразование, ценовая стратегия, ценность информации
Также включает информацию об Adobe, Apple Computer, AT&T, Bell Atlantic, Cisco Systems, Computer Associates, клиенты, закрепление клиентов, экономия на масштабе, Electric Library, Encyclopedia Britannica, Федеральная комиссия по связи (FCC), Федеральная торговая комиссия (FTC), групповые цены, телевидение высокой четкости (HDTV ), IBM, информационная экономика, установленная база, Intel, Интернет, Java, библиотеки, Macintosh, Microsoft Corp., Netscape Communications Corporation, сетевые рынки, Nintendo, Philips, положительные отзывы, Quicken, QWERTY-клавиатура, Rockwell, Sony, стандарты, войны стандартов, Sun Microsystems, затраты на переключение, Министерство юстиции США, Робототехника США, Windows, World Wide Web (WWW ), так далее
Ваши права согласно HIPAA | HHS.gov
Это руководство остается в силе только в той степени, в которой оно соответствует постановлению суда по делу Ciox Health, LLC против Азара, № 18-cv-0040 (DDC 23 января 2020 г.), которое может быть Найдено по адресу https: // ecf.dcd.uscourts.gov/cgi-bin/show_public_doc?2018cv0040-51 . Дополнительную информацию о заказе можно получить по телефону https://www.hhs.gov/hipaa/court-order-right-of-access/index.html . Любое положение в данном руководстве, отмененное решением Ciox Health, отменяется.
Большинство из нас считает, что наша медицинская и другая медицинская информация является частной и должна быть защищена, и мы хотим знать, у кого эта информация есть.Правило конфиденциальности, федеральный закон, дает вам права на вашу медицинскую информацию и устанавливает правила и ограничения в отношении того, кто может просматривать и получать вашу медицинскую информацию. Правило конфиденциальности применяется ко всем формам защищенной информации о здоровье людей, будь то электронная, письменная или устная. Правило безопасности — это федеральный закон, требующий защиты медицинской информации в электронной форме.
Видео о праве доступа HIPAA
OCR объединилась с Управлением HHS Национального координатора по ИТ в области здравоохранения, чтобы создать Ваша медицинская информация, ваши права! , серия из трех коротких обучающих видеороликов (на английском языке с возможностью использования субтитров на испанском), которые помогут вам понять ваше право в соответствии с HIPAA на доступ и получение копии вашей медицинской информации.
Инфографика о праве доступа HIPAA
OCR объединилась с офисом HHS Национального координатора по ИТ в области здравоохранения, чтобы создать этот одностраничный информационный бюллетень с иллюстрациями, который дает общее резюме ваших прав в соответствии с HIPAA:
Информационные бюллетени HIPAA
Кто должен соблюдать эти законы
Мы называем организации, которые должны соблюдать правила HIPAA, «защищенными организациями».
Охватываемые организации включают:
- Планы медицинского страхования , включая медицинские страховые компании, HMO, планы медицинского страхования компаний и определенные государственные программы, которые оплачивают медицинское обслуживание, такие как Medicare и Medicaid.
- Большинство поставщиков медицинских услуг — те, которые ведут определенный бизнес в электронном виде, например, выставляют счета вашей медицинской страховке электронным способом, — включая большинство врачей, клиник, больниц, психологов, мануальных терапевтов, домов престарелых, аптек и стоматологов.
- Информационные центры здравоохранения — объекты, которые обрабатывают нестандартную медицинскую информацию, которую они получают от другой организации, в стандарт (т. Е. В стандартный электронный формат или содержание данных) или наоборот.
Кроме того, деловые партнеры субъектов, на которые распространяется действие страховки, должны соблюдать некоторые положения правил HIPAA.
Часто подрядчикам, субподрядчикам и другим сторонним лицам и компаниям, которые не являются сотрудниками застрахованной организации, потребуется доступ к вашей медицинской информации при предоставлении услуг застрахованной организации. Мы называем эти организации «деловыми партнерами». Примеры деловых партнеров:
- Компании, которые помогают вашим врачам получать оплату за медицинское обслуживание, в том числе компании, выставляющие счета, и компании, обрабатывающие ваши заявки на медицинское обслуживание
- Компании, которые помогают управлять планами медицинского страхования
- Людям нравятся сторонние юристы, бухгалтеры и ИТ-специалисты
- Компании, хранящие или уничтожающие медицинские записи
Субъекты, на которые распространяется действие страховой защиты, должны иметь контракты со своими деловыми партнерами, гарантирующие, что они будут использовать и раскрывать вашу медицинскую информацию надлежащим образом и надлежащим образом защищать ее.Деловые партнеры также должны иметь аналогичные контракты с субподрядчиками. Деловые партнеры (включая субподрядчиков) должны соблюдать условия использования и раскрытия информации своих контрактов и Правил конфиденциальности, а также требования безопасности Правил безопасности.
Кто не обязан соблюдать эти законы
Многие организации, располагающие медицинской информацией о вас, не обязаны соблюдать эти законы. .
Примеры организаций, которые не обязаны соблюдать Правила конфиденциальности и безопасности:
- Страховщики жизни
- Работодатели
- Носители компенсаций рабочим
- Большинство школ и школьных округов
- Многие государственные учреждения, например, службы защиты детей
- Большинство правоохранительных органов
- Множество муниципальных образований
Какая информация защищается
- Информация, которую ваши врачи, медсестры и другие поставщики медицинских услуг помещают в вашу медицинскую карту
- Разговоры вашего врача о вашем уходе или лечении с медсестрами и другими лицами
- Информация о вас в компьютерной системе вашей медицинской страховой компании
- Платежная информация о вас в вашей клинике
- Большая часть другой медицинской информации о вас принадлежит тем, кто должен соблюдать эти законы
Как защищается эта информация
- Субъекты, на которые распространяется действие Соглашения, должны принять меры для защиты вашей медицинской информации и гарантировать, что они не будут использовать или раскрывать вашу медицинскую информацию ненадлежащим образом.
- Субъекты, на которые распространяется защита, должны разумно ограничивать использование и раскрытие информации до минимума, необходимого для достижения их предполагаемой цели.
- Субъекты, на которые распространяется действие страховки, должны иметь процедуры, ограничивающие круг лиц, которые могут просматривать и получать доступ к вашей медицинской информации, а также внедрять программы обучения сотрудников по вопросам защиты вашей медицинской информации.
- Деловые партнеры также должны принять меры для защиты вашей медицинской информации и гарантировать, что они не будут использовать или раскрывать вашу медицинскую информацию ненадлежащим образом.
Какие права дает мне правило конфиденциальности в отношении информации о моем здоровье?
Медицинские страховые компании и поставщики медицинских услуг, являющиеся покрываемыми организациями, должны соблюдать ваше право на:
- Попросите показать и получить копию вашей медицинской карты
- Внесите исправления в вашу медицинскую информацию
- Получите уведомление о том, как ваша медицинская информация может быть использована и предоставлена
- Решите, хотите ли вы дать свое разрешение, прежде чем информация о вашем здоровье может быть использована или передана для определенных целей, например для маркетинга
- Получите отчет о том, когда и почему информация о вашем здоровье была предоставлена для определенных целей
- Если вы считаете, что ваши права нарушаются или ваша медицинская информация не защищается, вы можете
Вам следует ознакомиться с этими важными правами, которые помогут вам защитить вашу медицинскую информацию.
Вы можете задать своему врачу или страховщику вопросы о своих правах.
Узнайте больше о своих правах на конфиденциальность медицинской информации.
Кто может просматривать и получать информацию о вашем здоровье
Правило конфиденциальности устанавливает правила и ограничения на то, кто может просматривать и получать вашу медицинскую информацию.
Чтобы убедиться, что ваша медицинская информация защищена таким образом, чтобы не мешать вашему медицинскому обслуживанию, ваша информация может использоваться и передаваться:
- Для вашего лечения и координации ухода
- Платить врачам и больницам за ваше медицинское обслуживание и помогать вести их бизнес
- Вместе со своей семьей, родственниками, друзьями или другими лицами вы определяете, кто участвует в вашем медицинском обслуживании или счетах за медицинское обслуживание, если вы не возражаете.
- Чтобы врачи обеспечивали хороший уход, а дома престарелых были чистыми и безопасными
- Для защиты здоровья населения, например, сообщая о случаях гриппа в вашем районе
- Для подачи необходимых сообщений в полицию, например для сообщения о огнестрельных ранениях
Информация о вашем здоровье не может быть использована или передана без вашего письменного разрешения, если это не разрешено законом.Например, без вашего разрешения ваш провайдер обычно не может:
- Предоставьте информацию своему работодателю
- Используйте или делитесь вашей информацией в маркетинговых или рекламных целях или продавайте вашу информацию
ARDC привержен культуре разнообразия и инклюзивности.Для получения дополнительной информации нажмите здесь. Щелкните здесь, чтобы связаться с ARDC. Заходя на этот сайт, вы подтверждаете и соглашаетесь со всеми условиями и |
Домашняя страница — Файлы общественной инспекции FCC
Файлы общественной проверки
На этом сайте представлена сводная информация и доступ к «общедоступному файлу» (или «общедоступному файлу») для следующих типов организаций: лицензированные радио- и телестанции с полным спектром услуг, телевизионные станции класса A, системы кабельного телевидения , провайдеры спутникового прямого вещания («DBS») и лицензиаты спутникового радио (также именуемые «Службы спутникового цифрового аудио-радио» или «SDARS»).
Комиссия впервые приняла правила, требующие от радиостанций хранить общедоступный файл более 40 лет назад, а некоторые файлы политических программ были общедоступными уже почти 75 лет. Публичный файл для радиостанций содержит разнообразную информацию о деятельности каждой радиостанции и услугах ее лицензированному сообществу, включая информацию о политическом времени, проданном или отданном каждой радиостанцией, ежеквартальные списки наиболее значимых программ, транслируемых каждой радиостанцией по важным вопросам. сообществу, данные о собственности каждой станции и активные заявки, которые каждая станция подала в Комиссию.Комиссия утвердила требование к файлам общественной проверки, чтобы «сделать информацию, на которую общественность уже имеет право, более доступной, с тем чтобы общественность была поощрена к более активному участию в диалоге с лицензиатами вещания».
Cable, DBS и SDARS также имеют требования к публичным и политическим файлам. Требования к политическим файлам этих организаций в основном аналогичны требованиям теле- и радиовещательных компаний. Однако, помимо политического файла, другие требования к общедоступным файлам кабельных, DBS и SDARS организаций несколько отличаются от требований к общедоступным файлам, применимых к вещательным компаниям.
Просмотрите полный список элементов , которые должны быть помещены в файл.
Поиск объектов и имен файлов
Объекты можно искать по позывному, номеру канала, идентификатору объекта, принадлежности к сети, PSID, почтовому индексу для кабельных систем, юридическим названиям для DBS, SDARS и кабельных систем. Ключевые слова также сопоставляются с именами файлов и путями к папкам.
Использование предварительно созданных определений правил с IBM InfoSphere Information Analyzer
Импорт и использование предварительно определенных проверок качества данных
Харальд Смит
Опубликовано 15 декабря 2011 г.
Узнайте, как использовать готовые пакеты IBM®
Правила качества данных InfoSphere® Information Analyzer.Мы покажем тебе как
чтобы понять доступный контент, как использовать эту информацию для решения общих
условия качества данных, и как затем импортировать их в вашу информацию
Среда анализатора для ускорения разработки и оценки правил.
Обзор
С помощью IBM InfoSphere Information Analyzer вы можете создавать правила качества данных
для автоматического отслеживания потенциальных проблем с качеством данных
определенные бизнес-требования или на основе выявленных проблем
во время профилирования данных.Для разработки этих правил может потребоваться время.
проверить широкий диапазон данных в данной таблице, системе или
Окружающая среда.
Цель этой статьи — показать вам способы ускорить это
разработка за счет импорта и использования предварительно созданной информации
Определения правил анализатора, которые прилагаются к этой статье. Используя эти
предварительно созданные определения правил качества данных, вы сможете ускорить
разработка проверки качества данных на вашем предприятии.
Эта статья посвящена следующим задачам:
- Понимание определений правил, доступных в предварительно созданных пакетах
- Использование предварительно созданных определений правил для обеспечения качества общих данных
условия - Проверка структуры и содержания правила Information Analyzer
XML-файл определения - Импорт предварительно созданных определений правил данных с помощью HTTP / CLI API
— функция, представленная в InfoSphere Information Analyzer
V8.5 и улучшенный в V8.7
Предварительно созданные правила качества данных, сопровождающие эту статью, предназначены
к:
- Сократите усилия по выявлению проблем с качеством данных во многих общих
информационные домены (ключи, национальные идентификаторы, даты, коды стран,
адреса электронной почты и т. д.) и условия (проверка полноты, действительный
значений, проверок диапазона, агрегированных итогов, уравнений и т. д.) - Служить моделями, шаблонами и примерами для вашего собственного дополнительного правила
design - Может использоваться в заданиях анализатора информации (либо V8.5 или V8.7),
или через стадию правил, доступную в информационном сервере V8.7.
Адреса доменов общих данных и
условия качества
Практически любой фрагмент данных, хранящийся в базе данных или файле или обрабатываемый
через задание или веб-службу имеет некоторое связанное условие, указывающее
соответствуют ли данные установленным правилам проверки. Эти условия могут
быть таким же простым, как указание на то, что в поле должны быть данные (т.е., что
он является полным) или когда есть данные, которые соответствуют некоторым указанным
формат или набор значений (т.е. значения действительны). Или условия могут
указывают, что данные должны соответствовать записям в указанном справочном источнике,
например, почтовые индексы, или что определенное уравнение правильно
рассчитано.
Возможный диапазон данных, которые могут быть оценены, и потенциальное число
условий качества, которые могут быть определены, является существенным, и это
статья (и сопутствующие заранее составленные определения правил) не могут адресовать
все возможные обстоятельства.Вместо этого основное внимание уделяется обеспечению быстрого старта.
для набора областей данных и условий, обычно встречающихся во многих
источники данных.
Information Analyzer позволяет определять логику правил для
такие домены данных и условия отдельно от любого физического источника данных
поэтому одна и та же логика последовательно применяется от источника данных к данным
источник (т. е. одно определение правила данных может применяться и использоваться со многими
источники данных).В сочетании с возможностью импорта набора правил
определения в заданном формате XML, вы можете взять заранее созданное правило
определения и загрузите их в Information Analyzer и запустите
применяя их к вашим собственным источникам данных.
Правило
определения
Определения правил следуют базовому синтаксису, где переменная, которая может просто
быть словом или термином, оценивается на основе определенного условия или типа
проверять.Указанное условие или проверка могут потребовать, а могут и не потребовать
дополнительное ссылочное значение, такое как другая переменная, список значений,
указанный формат и т.д .. Далее могут быть связаны несколько условий
вместе с пунктами IF , THEN , AND или OR . Например, очень простое определение правила может быть таким:
следует: DateOfBirth IS_DATE .
Это условие означает, что переменная DateOfBirth должна иметь
распознанный формат даты.
В более сложном случае у вас может быть определение правила, например
как в листинге 1.
Листинг 1. Пример определения правила
IF DateOfBirth СУЩЕСТВУЕТ
И DateOfBirth> datevalue ('1900-01-01')
И DateOfBirth Здесь есть условный оператор, который проверяет,
DateOfBirth существует и находится в пределах установленного диапазона, и только если эти условия
встречаются, другая переменная с именем CustomerType проверяется на равенство
к указанному значению.
Дополнительная информация о создании и использовании определений правил доступна в
руководство пользователя Information Analyzer (см. определения правил данных).
Основные примеры доменов данных
Самые основные определения правил проверяют полноту поля или
стандартный буквенный или числовой формат. Предварительно созданные правила включают
примеры этих условий.
Рисунок 1. Общая полнота и
правила типа данных
Например, определение правила AlphanumFieldExists
оценивает следующее условие: Поле1 СУЩЕСТВУЕТ И
len (обрезать (Поле1)) <> 0 .
Этот пример включает несколько основных
возможности:
- Использование общего имени переменной - в данном случае просто вызываемого
Поле1- ПРИМЕЧАНИЕ: Переменная может быть связана с
( привязано ) к любому столбцу
или поле данных. Это гибкость, которая позволяет
определение правила, чтобы обеспечить основу для многих актуальных
исполняемые правила данных.
- Тесты для нескольких условий - наличие данных и не равно
( <> ) состояние- ПРИМЕЧАНИЕ: Нет конкретного ограничения на количество условий
которые можно включить в одно определение правила, хотя
практически полезно сохранять определения правил
понятно. При создании определений правил ищите
основные строительные блоки и воспользоваться информацией
Возможность набора правил анализатора вместо этого комбинировать условия
объединить все в одно правило (см. методы анализа правил данных в документе IBM Information
Центр].
- Включение функций - В данном случае len и trim
- ПРИМЕЧАНИЕ: Обратитесь к пользователю Information Analyzer.
Руководство по набору доступных функций. Функции часто могут быть
используется для облегчения решения условий. В этом случае
функции используются для проверки наличия пробелов в поле. Отделка
функция сначала удаляет любое количество пустых (пробелов) значений из
слева или справа от любого фактического текста.Функция len
определяет длину всех оставшихся буквенно-цифровых символов
с ожиданием, что в поле будет хотя бы один
символьное значение (то есть длина не равна 0).
Домены данных по классификации данных
На базовом уровне, помимо общих примеров, приведенных выше, вы можете примерно
классифицировать данные в набор общих доменов данных, как показано в столбце
Детали анализа Information Analyzer:
- Идентификатор - поле, как правило, уникальное и может идентифицировать связанные
данные (например,g., идентификатор клиента, национальный идентификатор) - Индикатор - поле, часто называемое флагом, которое имеет двоичное состояние
(например, Верно или Ложь, Да или Нет, Женский или Мужской) - Код - поле, которое имеет отдельный и определенный набор значений, часто
сокращенно (например, код штата, статус клиента) - Дата - поле, которое содержит некоторое значение даты
- Количество - поле, которое содержит числовое значение и не классифицируется как
Идентификатор или код (например,g., Цена, Сумма, Стоимость актива) - Текст - поле, которое содержит буквенно-цифровые значения, возможно, длинный текст,
и не классифицируется как идентификатор или код (например, имя, адрес,
Описание)
Кроме того, существует базовая классификация правил: Действительное значение
Комбинация, в которой одно поле имеет определенное значение,
во втором поле должно быть определенное значение.
Подмножество предварительно созданных определений правил следует за этими общими группами
и типовые требования к валидации.На рисунке 2, например, выделены
предварительно созданные определения правил для полей кода.
Рис. 2. Общие
определения правил на основе классификации для кодов
Эти определения правил, обычно основанные на классификациях общих данных
оценить структурные форматы или основные требования к валидации (например,
Идентификатор должен находиться в диапазоне, ограниченном низким и высоким значением, но
он не указывает точных значений).
Если, например, у вас есть поле кода, которое позволяет вводить буквенно-цифровые значения
0-9, вы можете применить определение правила
Code1DigitNumeric (см. Рисунок 2) на
убедитесь, что поле содержит одно однозначное числовое значение. Это правило
определение выглядит следующим образом: Код MATCHES_FORMAT
«9» .
В этом примере показано простое условие:
- Использование общей переменной с именем Code
- Тест для одного условия формата:
MATCHES_FORMAT - ПРИМЕЧАНИЕ: Information Analyzer имеет две отдельные проверки данных.
форматирование: MATCHES_FORMAT ,
показано здесь, и MATCHES_REGEX ,
который оценивается по широкому диапазону регулярных выражений
условий (множество примеров можно найти через простой Google
поиск по термину "регулярное выражение").
- Условие
MATCHES_FORMAT требует
исходная величина; в этом случае,
он ожидает одно и только одно числовое значение (все числовые цифры
представлены цифрой 9).
Общий
домены данных
Как уже отмечалось, существует множество потенциальных доменов данных, которые могут быть
включены в пакет предварительно созданных определений правил данных. Примеры
общих доменов, включенных в доступные пакеты, включают:
- Демографические данные
- Возраст
- Дата рождения
- Дата смерти
- Национальный идентификатор (e.g., номер социального страхования США, канадский
Номер SIN, номер паспорта, налоговый код Италии и т. Д.)
- Информация об адресе в Интернете
- Адрес электронной почты
- IP-адрес
- URL
- Информация о заказе / продажах / политике
- Сумма и количество заказа
- Сумма продаж (например, с налогом с продаж или без него, с или без
скидка) - Срок погашения
- Код продукта (например,g., код ISBN, код UPC)
- Информация о трудоустройстве
- Телефонная информация (только для Северной Америки)
Эти общие домены охватывают диапазон классов данных, обеспечивая больше
конкретные случаи для вашего использования, а также условия правил, которые могут быть более
сложный. Рассмотрим следующее заранее созданное определение правила
SalesamtWDiscountPlusTaxValid , который оценивает
поле суммы продаж на основе нескольких переменных, включая скидку и
налог:
(qtyValue1 * цена) - (qtyValue1 * скидка) + (((qtyValue1 * цена) -
(qtyValue1 * Discount)) * salesTax) = totalAmount
В этом примере показано, что исходная информация (в данном случае)
или справочная информация, используемая при валидации, может включать
количество критериев:
- В этой логике используются пять переменных:
- qtyValue1 - количество товара в заказе или продаже
- price - цена товара в заказе или продаже
- скидка - скидка, примененная к номеру в заказе или
sale - salesTax - Налог с продаж, применяемый к заказу или продаже
- totalAmount - Общая сумма заказа или продажи
- ПРИМЕЧАНИЕ: В самом определении правила нет спецификации
относительно того, где фактически хранятся данные; эти переменные
все могут содержаться в одной базе данных или файле или могут приходить
из нескольких источников.Эта информация требуется только тогда, когда
переменные связаны , когда правило исполняемых данных
генерируется.
- Тест для одного условия
= (равно)- ПРИМЕЧАНИЕ: Это правило можно также записать на
реверс, где totalAmount - это
исходная переменная (слева), которая равна
к справочным данным (уравнение, поставленное справа).
- Уравнение, использующее ряд функций (стандартные числовые
операторы + , - ,
* и /) и соответствующие скобки.
Стандартизированные домены данных
(США)
Сопровождающий готовый пакет правил предназначен для
проверка результатов процессов стандартизации для названий США, улиц
адреса и почтовые области из IBM InfoSphere QualityStage®.В
Этап стандартизации QualityStage принимает входящие данные, такие как
Имена и адреса в США, которые не определены четко, анализирует эти данные и
создает стандартизированную форму. Например, рассмотрим два
адреса:
100 West Main Street apt 10
100 W Main St # 10
Вполне возможно, что эти два адреса представляют одно и то же место. Но
различия в форматировании и описании не позволят получить такую информацию
от связи.Результат этапа стандартизации с использованием
набор правил для адресов в США для обоих даст:
Street # Pre-direction Street St. Type Unit #
100 W Main St, кв. 10
100 W Main St Apt 10
Как правило, эти наборы правил стандартизации обеспечивают
вывод, но могут быть исключения, такие как новые данные, неожиданные условия,
данные по умолчанию или тестовые данные, а также необычные форматы.Готовое правило
определения нацелены на эти результаты, хотя они могут применяться к любым
хорошо проанализированная информация об имени, адресе или почтовом отделении. Например,
определение правила RuralRouteTypeIfExistsThenValidValues тестов
допустим ли тип маршрута в сельской местности.
ЕСЛИ RuralRouteType СУЩЕСТВУЕТ
И len (обрезать (RuralRouteType)) <> 0
ТО rtrim (RuralRouteType) IN_REFERENCE_LIST {'RR', 'RTE', 'HC', 'CONTRACT'} В этом примере выделены несколько критериев, помещенных в
IF… THEN условие:
-
IF… AND… то же самое, что и полнота
пример AlphanumFieldExists , показанный выше.При выражении в условии IF записываются только те области, в которых поле
имеет значение, будет оценено с последующим условием THEN . Записи, в которых нет ценности, не будут оцениваться и будут
не генерировать никаких исключений. - Условие
THEN является основанием для выполнения
или не соответствует определению правила. В пределах условия
rtrim функция удаляет все пробелы на
справа от RuralRouteType , и в результате
значение оценивается по набору из четырех допустимых значений, указанных в
список. - ПРИМЕЧАНИЕ: Это тип правила
ЕСЛИ… ТО
определения хорошо работают вместе как часть более широкого набора правил. В
По сути, они описывают серию случаев, каждый из которых имеет свои критерии.
Определив определения правил отдельно и сгруппировав их в
набор правил, он позволяет лучше понять, в каких записях есть проблемы, поскольку
а также сколько записей нарушают определенные правила.
Использование предварительно созданного правила
Определения
Сопутствующие заранее созданные определения правил могут быть рассмотрены из
перспектива дизайна и перспектива развертывания.
Ускорители времени разработки,
шаблоны и модели
С точки зрения дизайна вы можете использовать предварительно созданные определения правил
как есть, копируйте / изменяйте в соответствии с вашими потребностями или используйте их в качестве моделей дизайна. В
в следующем разделе «Импорт предварительно созданных определений правил» описывается
основные шаги по добавлению готовых пакетов в ваш проект (ы).
Файл IARuleDefs-BaseSet1-General-v8x.xml включает более
130 определений общих правил и общих доменов, описанных выше.В
файл IARuleDefs-BaseSet1-USStan-v8x.xml включает
около 60 определений для проверки названия, адреса и почтового отправления в США
стандартизированная информация по области, описанная выше.
Во-первых, после импорта в проект вы можете сразу использовать это правило.
определения для тестирования или оценки ваших источников данных, создавая правила данных как
описано в Руководстве пользователя Information Analyzer (см. Создание правила данных из определения правила).В этом качестве
определения правил ускоряют вашу способность запускать подробные данные
оценка качества.
Во-вторых, вы можете использовать эти определения правил в качестве шаблонов для настройки
ваши собственные конкретные условия данных. Рассмотрим пример, когда вы
есть поле с именем "Регион", которое представляет определенный сегмент мира.
Регион определяется как текстовое поле длиной пять символов, и первое
два символа - это буквенные символы, которые должны быть в следующих
список: AM (Африка и Ближний Восток), AP (Азиатско-Тихоокеанский регион), ЕС (Европа),
NA (Северная Америка) и SA (Южная Америка).
Предварительно созданные определения правил не включают такое точное правило
определение. Однако определение правила
TextSubstrInRefList описывается как «Текст подстроки
значение, начинающееся с позиции 3 для длины 3, находится в списке ссылок. "Это
похоже на определение правила, которое вам нужно: оцените подстроку для
включение в список литературы.
В этом случае вы можете сделать следующее:
- Войдите в Information Analyzer.
- Откройте свой проект и перейдите в меню «Разработка» и «Данные».
Пункт меню "Качество". - Выберите нужное определение правила в своем проекте
( TextSubstrInRefList , в данном случае). - Выберите задачу Create a Copy , как показано на рисунке 3.
Рисунок 3. Создание копии
задача
- В диалоговом окне для создания копии выберите ОК .
- Это создаст копию исходного правила с именем
(Copy_of_TextSubstrInRefList в этом случае). - Откройте это новое определение правила, чтобы при необходимости отредактировать его:
- Измените имя определения правила:
Region_SubstrInRefList . - Измените функцию подстроки с:
- До: подстрока (TextField, 3, 3)
- После: подстрока (Регион, 1, 2)
- ПРИМЕЧАНИЕ: В этом случае вы хотите запустить
функция подстроки в первом символе для
длиной 2.
- Измените данные справочного списка с:
- До: {'AAA', 'AAB', 'BAA', 'CCC'}
- После: {'AM', 'AP', 'EU', 'NA', 'SA'}
- Сохраните обновленное определение правила.
В-третьих, вы можете использовать определения правил как эталонные модели - примеры
конкретные функции или используемые условия, которые могут направлять вас при разработке
и разработайте уникальные правила для вашей среды.
Подходы к качеству развертывания
проверка и мониторинг
Как и все определения правил, предварительно созданные пакеты могут быть:
- Используются для создания исполняемых правил данных для проверки качества.
- Включено в определения наборов правил и исполняемые наборы правил для проверки
несколько условий вместе.- Более подробно обсуждается в анализаторе информации
Руководство по передовой практике и методологии (см. Раздел Ресурсы), наборы правил имеют несколько различных
Преимущества развертывания:- Они обеспечивают поддержку для оценки данных на основе многих
условия правила данных. С заранее созданным правилом
определений, вы можете объединить как можно больше из этих
по мере необходимости для оценки всех полей в данном
запись, включая несколько экземпляров одного и того же правила
определение, например FieldExists . - Они оценивают все проверенные правила для каждой записи в наборе
так что результаты можно просматривать в нескольких измерениях.
(Например, вы можете увидеть все записи, которые не проходят каждый
конкретное правило, просмотреть все правила, которые относятся к данной записи
не удалось, или посмотрите на пересечения определенных наборов
правила). - Они оптимизируют оценку правил для выполнения и
обработка.
- ПРИМЕЧАНИЕ: Любое определение набора правил, которое вы создаете, может содержать эти
предварительно созданные определения правил и / или ваши собственные определения правил в
любая комбинация.
- Опубликовано для пользователей в других проектах, чтобы воспользоваться
- Когда вы импортируете предварительно созданные определения правил, они импортируются
к вашему проекту. Для других пользователей, не входящих в ваш
проекта для использования, определения правил должны быть опубликованы или
импортированы в свои проекты. - Экспортировано для развертывания в другом анализаторе информации
среды - Например, если вы работаете в разработке
среда с тестовыми данными, чтобы убедиться, что ваши правила данных работают
правильно, вам может потребоваться экспортировать эти правила данных в
производственная среда для постоянного контроля качества.
С появлением Information Analyzer V8.7 определения правил
встроенный анализатор информации может быть добавлен в новую стадию правил в IBM
Задание InfoSphere DataStage или QualityStage.Эта возможность позволяет использовать
любое опубликованное определение правила для проверки данных, которые
часть процессов интеграции или очистки данных, в том числе добавленные
через прилагаемые предварительно созданные пакеты определения правил.
Например, вы ежедневно получаете файл от стороннего
источник. Качество источника данных часто низкое, что приводит к проблемам
в других информационных системах, включая вашу бизнес-отчетность.Это ежедневно
файл в настоящее время выполняет задание QualityStage для стандартизации файла и
загрузить в существующие источники данных. Вы хотите протестировать входящие данные для
полнота с использованием набора определений правил и проверки результатов
вывод стандартизации QualityStage.
На рисунке 4 показано добавление новой стадии правила, CustomerValidityCheck,
в этом примере работы. На стадии правила может быть одно определение правила или несколько, в зависимости от
количество полей данных, которые необходимо проверить.Выходы из этого
Этап включает действительные данные, недопустимые данные и подробные сведения о конкретных нарушениях.
Рис. 4. Проверка данных в процессе
в DataStage или QualityStage
Дополнительные сведения об этом см. в разделе Использование этапа правила данных.
возможности.
Воспользовавшись преимуществами заранее созданных определений правил, вы можете:
- Сократить усилия по обращению ко многим общим информационным областям и
условия. - Предоставление моделей и публикация определений правил для работы других пользователей
из. - Ускорьте процесс оценки, тестирования и развертывания правил данных
в анализаторе информации. - Разверните определения правил для постоянного контроля качества и
проверка данных в полете.
Понимание предварительно созданного правила
пакеты определений
Предварительно созданные определения правил Information Analyzer, которые сопровождают это
статьи импортируются через Information Analyzer API.
Содержание
структура
Предварительно созданные определения структурированы с использованием определенной схемы XML.Для получения полной информации о структуре см.
в элементы файла схемы для определений правил.
Вкратце файлы определений выглядят как листинг 2.
Листинг 2. XML-схема определения правил
" "
<описание> Поле существует; только нулевой контроль
Поле1 СУЩЕСТВУЕТ
<описание> существует буквенно-цифровое поле; значение NULL & \
проверка пустого значения
<выражение> Поле1 СУЩЕСТВУЕТ И len (обрезать (Поле1)) <> 0
<описание> Пример буквенного формата; исключает нулевые значения
ЕСЛИ Поле1 СУЩЕСТВУЕТ, ТО Поле1 MATCHES_FORMAT 'AAAA'
Пример буквенно-цифрового формата 1; как с \
Табличка № транспортного средства; исключает нулевые значения
ЕСЛИ Поле1 СУЩЕСТВУЕТ, ТО Поле1 MATCHES_FORMAT '999AAA'
Содержимое включает:
- Общий заголовок XML:
, который не следует изменять. - Определенный заголовок XML для анализатора информации:
. Вам нужно будет изменить your-project на
любое имя проекта Information Analyzer, которое вы используете. - XML-комментарии, заключенные между
- Начало раздела определений правил:
- Блок содержимого для каждого определения правила, включая:
- Имя определения правила
- Для V8.Только 7 файлов, папка
- Описание определения правила
- Выражение (логика правила)
Пример:
<описание> Поле существует; только нулевой контроль
Поле1 СУЩЕСТВУЕТ
- После всех блоков определения правил конец определений правил
раздел и конец содержимого XML:
Готовые пакеты определения правил
доступно
Доступны два пакета определения правил
(см. Загружаемые ресурсы).Один предназначен для использования с информацией
Анализатор V8.5, второй для использования с V8.7. Содержимое определения правил одинаково для обоих пакетов. Единственный
разница в том, что V8.7 включает ссылку на папку, которая будет
добавить определение правила в определенную папку во время импорта. Этот вариант
недоступно во время импорта в V8.5.
Для IBM InfoSphere Information Analyzer V8.5:
- IARuleDefs-BaseSet1-v85.zip
- Общие определения правил домена и условий:
IARuleDefs-BaseSet1-General-v85.xml - Определения правил условий проверки стандартизации в США:
IARuleDefs-BaseSet1-USStan-v85.xml
- ПРИМЕЧАНИЕ: Этот пакет можно использовать в Information Analyzer V8.5 или
V8.7.
Для IBM InfoSphere Information Analyzer V8.7:
- IARuleDefs-BaseSet1-v87.zip
- Общие определения правил домена и условий:
IARuleDefs-BaseSet1-General-v87.xml - Определения правил условий проверки стандартизации в США:
IARuleDefs-BaseSet1-USStan-v87.xml
- ПРИМЕЧАНИЕ: Этот пакет можно использовать только в Информационной
Analyzer V8.7, поскольку он включает параметры папки, ранее не доступные в API, и
CLI.
Вам потребуется:
- Выберите пакет, подходящий для вашей версии Information Analyzer
и скачайте из приложений к статье. - Сохраните файл на своем компьютере.
- Распакуйте пакет и извлеките два файла XML в место на вашем
компьютер.
Импорт предварительно созданного правила
определений
Есть два варианта импорта или загрузки предварительно созданных определений:
Интерфейс командной строки (CLI) и REST (HTTP) API, доступ к которому осуществляется через
браузер.
Интерфейс командной строки (CLI)
- Команда:
IAAdmin . - Доступен в клиенте Information Analyzer и
сервер. - Преимущества:
- Нет
Надстройки POST необходимы для вашего
браузер. - Многим техническим специалистам нравятся утилиты командной строки.
- Недостатки
- Хотя и относительно короткий, некоторые люди находят синтаксис командной строки
сбивает с толку. - В некоторых средах утилиты командной строки отключены.
Интерфейс REST API (браузер)
- Он использует утилиту
HTTP POST . - Преимущества:
- Недостатки:
- Требуется надстройка
POST (некоторые среды не позволяют
надстройки браузера).
В этой статье описаны оба метода импорта. Последующие шаги импорта предполагают, что вы:
- Загрузите, разархивируйте (распакуйте) и сохраните правило
Определение XML-файлов в любом месте анализатора информации
Клиент или сервер постоянно находятся (это может быть удаленный сервер, удаленный
Образ клиента или ваш собственный компьютер).- ПРИМЕЧАНИЕ: В этих инструкциях предполагается, что вы загрузили на свой
собственная машина и будет импортирована с вашего местного
Окружающая среда.
- Откройте каждый XML-файл, который вы хотите использовать с помощью Блокнота (или
любой другой базовый редактор файлов). - Измените имя проекта (отображается как
"your-project", как указано выше) одному из ваших
выбор, который уже существует в вашей среде Information Analyzer
у вас есть доступ к.- Примечание: если еще нет проекта Information Analyzer, вы
(или вашему администратору проекта IA) потребуется создать
один - ПРИМЕЧАНИЕ: Если вы не измените имя проекта в XML-файле,
проект с именем your-project будет создан
и все определения правил будут там.
- Сохраните файл (ы) XML.
Импорт из командной строки (CLI)
Для импорта определений правил Information Analyzer через
CLI:
- Откройте командную строку (DOS) на клиенте.Например, на
Windows® XP, вы можете использовать Пуск> Все
Программы> Стандартные> Командная строка . - Перейдите в папку C: \ IBM \ InformationServer \ ASBNode \ bin.
- Выполните следующую команду:
IAAdmin -user xxxxx -password xxxxx -host your-server
-port 9080 -create -projectContent C: \ Temp \ IARuleDefs-BaseSet1-General
-v87.xml
- Используйте информацию о конфигурации анализатора информации, указанную выше
команда, актуальная для вашей среды:-
–пользователь (ваш анализатор информации
идентификатор пользователя) -
–пароль (ваш пароль Information Analyzer) -
–host (ваш Information Analyzer
сервер - соответствует вашему логину
информации) -
–port (обычно 9080 - соответствует вашей регистрационной информации) - После
–projectContent укажите местоположение
где вы сохранили XML-файл.В примере показан сохраненный файл
в C: \ Temp \, но расположение и имя вашего файла могут быть
отличается от показанного здесь. Используйте v85 или v87 в имени файла в зависимости от
ваша установленная версия.
ПРИМЕЧАНИЯ:
- Если вы импортируете BaseSet1-General и
Пакеты определения правил BaseSet1-USStan, вам необходимо
измените имя файла и запустите команду второй раз для
второй импорт. - Вы получите сообщение об ошибке, если дважды выполните указанную выше команду.
с тем же именем файла. Ошибка сообщит вам, что
правила уже существуют. Если это произойдет, то повторно выдайте вышеуказанный
команда с -update вместо
- создать . - Если вы попытаетесь импортировать файлы v87 в
версия Information Analyzer 8.5, вы получите сообщение об ошибке
сообщение следующего вида:
> XML-запрос, переданный как параметр, не может быть проанализирован по следующей причине: Функция «папка» не найдена. - Вышеупомянутая команда будет выполняться примерно 4-5 минут.
Если импорт прошел успешно, вы можете войти в Information Analyzer,
откройте свой проект (как указано в XML-файле при импорте) и
просмотрите импортированные определения правил. Вы должны увидеть список правил
определения аналогичны рисунку 5.
Рисунок 5. Импортированное правило
определения
Импорт веб-браузера (REST
API)
В следующем примере импорта браузера используется Firefox и
связанное дополнение Poster.Если у вас другой браузер, вы
нужно найти утилиту, которая позволяет выполнять POST
функция для импорта предварительно созданного правила Information Analyzer
определения с помощью этого метода.
Перед выполнением импорта этим методом вам понадобится утилита Firefox.
чтобы разрешить функцию POST. Выполните следующие действия (они могут отличаться в зависимости от версии вашего
browser):
- Откройте Firefox и перейдите к https: // addons.mozilla.org/en-US/firefox/addon/poster/.
- Выберите Добавить в Firefox .
- При появлении запроса выберите Установить сейчас .
- Закройте и перезапустите Firefox.
- После перезапуска Firefox включите панель надстроек с помощью следующих
(опять же в зависимости от версии)- Firefox> Параметры> Панель надстроек или
- Firefox> Инструменты> Надстройки
- В зависимости от версии надстройка может отображаться как:
- Золотистый P в правом нижнем углу
браузер - Пункт меню в Firefox> Инструменты>
Плакат
Чтобы выполнить импорт определений правил Information Analyzer через
браузер:
- Откройте Firefox и перейдите к надстройке.
- Выберите надстройку Poster. Вы должны увидеть форму браузера, как показано на рисунке.
6. Рисунок 6. Плакат Firefox
форма
- Заполните форму:
URL: http: // \
: 9080 / InformationAnalyzer / create? ProjectContent
Пользователь: Ваш идентификатор пользователя Information Analyzer
Пароль: ваш пароль Information Analyzer
Тайм-аут: Изменить на 300
Файл: введите имя файла или выберите Обзор кнопка для выбора
XML-файл из соответствующего каталога.Обратите внимание, что имя
ваш файл будет отличаться от показанного здесь. Использовать
v85 или v87 как
подходит для вашей установки.
POST: Выберите это, чтобы запустить процесс загрузки. - POST займет немного времени (3-5 минут), и вы
должен увидеть сообщение о статусе
ОК .
ПРИМЕЧАНИЕ: Возможно, вы
получить ответ о тайм-ауте, если тайм-аут не изменился.Этот
просто влияет на ответ клиенту о статусе, но должен
не влияет на функцию публикации на сервере.
Если импорт прошел успешно, вы можете войти в Информацию
Анализатор, откройте свой проект (такой же, как указано в XML-файле в
import) и просмотрите импортированные определения правил. Вы должны увидеть список
определений правил, аналогичных рисунку 5 выше.
Теперь вы готовы начать использовать готовое правило анализатора информации.
определения.
Заключение
Теперь вы можете использовать предварительно созданный набор определений правил.
сопровождение этой статьи в вашем IBM InfoSphere Information Analyzer
проекты.
В этой статье специально рассмотрено, как выполнять следующие задачи:
- Общие сведения об определениях правил, доступных в готовых пакетах
сопровождающий эту статью. - Используйте готовые определения правил для решения общих вопросов качества данных
условия. - Просмотрите структуру и содержимое XML-файла определения правил.
- Импортируйте заранее созданные определения правил данных с помощью API HTTP / CLI для
либо Information Analyzer V8.5, либо V8.7.
После импорта вы можете использовать предварительно созданные определения правил для создания данных.
правила качества, затем проверяйте и отслеживайте потенциальное качество данных
проблемы. И, используя заранее созданные определения правил, вы можете сократить
время, необходимое для проверки качества данных для широкого круга
данные в любой данной таблице, системе или среде.
Приложение: Предварительно построенное определение правил
имена и описания
Предварительно созданные определения правил предоставляются для использования с IBM InfoSphere
Информационный сервер.
Следующие определения правил включены в
IARuleDefs-BaseSet1-General-v8 x .xml-файл.
Таблица 1. Определения правил в
IARuleDefs-BaseSet1-General-v8x.xml
Название правила Краткое описание правила FieldExists Field Exists AlphanumFieldExists Буквенно-цифровое поле существует AlphaFormatValid Пример алфавитного формата AlphanumpormatFormatValid 900 VALID 9003 AlphanumpormatValid 900V Буквенно-цифровой формат 2 FieldIsNumeric Поле является числовым FieldExistsAndNumeric Поле существует и является числовым FieldExistsAndNumeric_2 Поле существует и является числовым FieldIsDate date FieldIsDate date
FieldExistsAndDate Поле существует и является значением даты FieldExistsAndDate_2 Поле существует и является значением даты IndicatorY_ NValid Поле индикатора - «Y» или «N» IndicatorUpperCaseY_NValid Поле индикатора - любой вариант «Y» или «N» IndicatorT_FValid Поле индикатора - «T» или «F» IndicatorUpperCaseT_FValid Поле индикатора - любой вариант «T» или «F» IndicatorString0_1Valid Поле индикатора - «1» или «0» IndicatorNum0_1Valid ric
1 или Поле индикатора - числовое значение 0 Code1DigitUpperCase Код - однозначный прописной алфавит Code1DigitLowerCase Код - однозначный строчный алфавит Code1DigitNumeric Code1DigitNumeric A - однозначный числовой 9
9D
Код является однозначным буквенно-цифровым, в любом регистре
Code1DigitAlph abetic Код однозначный буквенно-цифровой -Code1DigitNumeric_2 -Code1DigitNumeric_2 -Code1DigitNumeric_2 -Code1DigitNumeric_2 -Code is однозначный цифровой Code1DigitAlphanum_2 Код однозначный буквенно-цифровой CodeInRefMaster код CodeNotInDefaultValueList Код не полностью 9s TextSubstrIsValueX Substring Текстовое значение, начинающееся с позиции 3 для длины 1, равно 'X' TextSubstrInRefList Substring Текстовое значение, начинающееся с позиции 3 для длины 3, находится в
список ссылок Date1NumLessThanDate2 Дата <= 2-я дата Date1StringLessThanDate2 String Date <= 2-я строка даты Date1NumLessThanSysdate Date <= System Date; не будущая дата Date1StringLessThanSysdate String Date <= System Date; не будущая дата DateNumWithinLastYear Дата в течение одного года от текущей даты DateStringWithinLastYear Дата в течение одного года от текущей даты Date1NumWithin60DaysDate2 Дата в течение 60 дней от 2-й даты Date1StringWithin60DaysDate2
Дата в течение 60 дней после 2-го числа YearNumNotFuture Year <= System Year; не будущий год YearStringNotFuture Year <= System Year; не будущий год YearNumIsCurrentYear Year = System Year; совпадает с годом системной даты YearStringIsCurrentYear Year = System Year; совпадает с годом системной даты IdentifierUnique Идентификатор уникален CompoundIdentifierUnique Идентификатор соединения уникален Id1StXCharactersAlphabetic 900dCI 1-й символ x 900haractersAlphabetic
900dC
dC 1-й символ 900hast439 900dC 9001 4-5 символов одного идентификатора соответствуют второму идентификатору
IdOccursLtXTimes Идентификатор встречается IdInValidRange Идентификатор в допустимом диапазоне (одиночный) IdInValidMulti_Range Идентификатор в допустимом диапазоне 900InValidMulti_Range Идентификатор в допустимом диапазоне (множественный / сегментированный) 900In в справочном столбце QtyInValidRange Количество в допустимом диапазоне QtyAdditionValid Расчет количества действителен (добавление) QtyArithmeticValid Вычисление количества допустимо (арифметическое) QtyMultimetity
900V32 Количество 900V32 вычисление допустимо (умножение) QtyDivisionValid Вычисление количества допустимо (деление) QtyStringInValidRange Количество в допустимом диапазоне - строковое значение 900 30
QtyStringAdditionValid Вычисление количества допустимо (сложение) - строковые значения QtyStringArithmeticValid Вычисление количества допустимо (арифметическое) - строковые значения QtyStringMultiplyValid Вычисление количества допустимо (вычисление количества) QtyStringDivisionValid Вычисление количества допустимо (деление) - строковые значения IfFieldaIsXThenFieldbIsY Если fieldA = 'X', то fieldB = 'Y' IfFieldExThenFieldbDoes XThenField fieldB не должно существовать
IfFieldaIsXThenFieldbInValidValueSet Если fieldA = 'X', тогда fieldB находится в допустимом наборе значений IfFieldaInValidValueSetThenFieldbExists Если fieldA находится в допустимом наборе значений 'X IfFieldaGtXThenFieldbIsY Если fieldA> qtyValue, то fieldB = 'Y' IfFieldaIsXThenFieldbGtQty Если fieldA = 'X', тогда fieldB> qtyValue field literals aKeyConcatenated поле 900A и field literalusConcatenated
ссылочный столбец AlphanumValidNoNonprintCharacters Буквенно-цифровые символы без непечатаемых символов FieldFreqLessThanPercentLimitForAllRecords Частота поля меньше, чем Pct Limit для всех записей Ageric 0 900In
Ageric Ageric> AdultInRangeNumeric Adult: Age> = 18 и <125 ChildInRangeNumeric Child: Age> = 0 и <18 AgeInRangeString Строковые данные Age: Age> = 0 и <125 AdultinrangeString Строковые данные Adult: Age> = 18 и <125 ChildinrangeString Строковые данные Child: Age> = 0 и <18 AgeinrangeCalc Производные Age: Age> = 0 и < 125 AdultinrangeCalc Получено Возраст Взрослый: Возраст> = 18 и <125 ChildinrangeCalc Производный возраст Ребенок: Возраст> = 0 и <18 Ребенок, не состоящий в браке Числовой Если Ребенок (числовой), то Семейное положение = 'N' ChildnotmarriedString Если Child (строка), то семейное положение = 'N' ChildnotmarriedCalc Если дочернее (производное), то семейное положение = 'N' DobReasonableRangeNumeric Дата рождения> = 1900-01 -01 и <= системная дата; не
будущая дата DobReasonableRangeString Дата рождения> = 1900-01-01 и <= системная дата; не
будущая дата IfDodExistsThenGtDobNumeric Дата смерти может быть пустой, но если она существует, она должна быть> =
Дата рождения, а не дата в будущем IfDodExistsThenGtDobString Дата смерти может быть пустым, но если она существует, она должна быть> =
Дата рождения, а не дата в будущем StartDtWeekday_Numeric Дата начала - будний день StartDtWeekday_String Дата начала - будний день MaturityDtExistsValidCondition Дата погашения существует, где условие 39 Ssn9DigitNumeric SSN является 9-значным числовым SsnMatchesNumericFormat SSN соответствует только числовому формату SsnMatchesHyphenFormat SSN соответствует числовому формату с дефисами Matchesatches
TYPHINS Matches
SsnMatchesRegex SSN соответствует формату регулярного выражения Cana
.
Добавить комментарий