
Robots txt — работа с файлом. Как закрыть сайт в robots txt от индексации. Проверка файла robots txt
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Для начала хочется ввести в курс и в общих чертах рассказать о понятиях «внутренней оптимизации».
Внутренняя оптимизация— это совокупность действий с целью улучшения индексирования поисковыми системами вашего сайта.
Под действиями для внутренней оптимизации сайта подразумеваются следующие мероприятия, выделим основные:
- сбор и группировка семантического ядра;
- работа с мета-тегами;
- оптимизация контента целевых и нецелевых страниц;
- формирование файла robots.
 txt;
txt; - реализация структурной и анкорной перелинковки.
 txt;
txt;В нашем блоге вы можете подробнее познакомиться с некоторыми действиями, связанными с внутренней оптимизацией вашего сайта:
В данной статье я хочу рассказать про Robots.txt.
Для разных поисковых систем, роботы, которых изучают интернет-ресурсы (включая ваш сайт), файл robots.txt несет в себе очень существенную информацию. Прежде чем приступить к прохождению по страницам конкретного сайта, любой робот просматривает именно этот файл.
Благодаря существованию файла robots.txt, сканирование сайта проводится более эффективно и качественно. Файл позволяет роботам незамедлительно приступать к конкретной, действительно существенной информации, которая расположена на просторах сайта.
Однако, как и инструкции в текстовом файле robotos.txt, так же и конкретные инструкции noindex в метатеге robots представляют собой только рекомендацию для роботов. Это означает, что они не могут предоставить полную гарантию того, что закрытые странички не будут индексироваться, а также добавляться в индекс.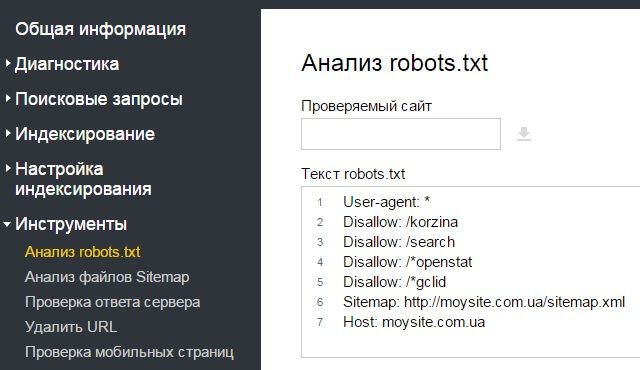
Рассмотрим ключевые синтаксические единицы на следующем примере:
User-agent: * Disallow: /wp-admin/ Host: semantica.in
- User-Agent: это робот по отношению к которому будут использованы конкретные правила (к примеру, Yandex). Зная значения User-Agent, можно наложить запрет, либо дать доступ одному из существующих роботов.
- Disallow: так будут помечены страницы, к которым будет закрыт доступ. Если таких страниц много, можно указать длинный список директив, но каждый начинать с новой строчки.
- Хэш: символ, который изображается (#) нужен для добавления заметок в файл robots.txt. Любые отметки, указанные после хэша, будут полностью игнорироваться. Любые комментарии могут быть введены как для целой строчки, так и для строчки после всех директив.
- Host: необходим для помощи определения Яндексом зеркала сайта. Если владелец 2 сайтов хочет их склеить и выполнить постраничный 301 редирект, для robot txt не нужно делать редирект дублирующего сайта. Это необходимо для того, чтобы поисковик Яндекса смог увидеть конкретную директиву непосредственно на сайте, который следует склеивать.
 Это необходимо для того, чтобы поисковик Яндекса смог увидеть конкретную директиву непосредственно на сайте, который следует склеивать.
Это необходимо для того, чтобы поисковик Яндекса смог увидеть конкретную директиву непосредственно на сайте, который следует склеивать.Все группы User-Agent / Disallow следует поделить пустыми строчками. Важно, чтобы пустые строчки не находились в пределах группы (между User-Agent и завершающей директивой Disallow).
По стандарту robots.txt и нечувствителен к регистру, но имена файлов и директорий реагируют на регистр.
Crawl-delay позволяет ограничивать скорости обходов сайтов. Это существенно важно в тех случаях, если на ресурсе очень высокая посещаемость, оказываемая нагрузка на сервер состороны всевозможных поисковых роботов может стать веской причиной появления существенных проблем.
Для осуществления гибких настроек директив могут также быть использованы следующие символы:
* (звездочка) — представлено любое последовательное использование символов
$ (значок доллара) — используется для отметки конца строки.
Применения файла robots.txt
Данная инструкция в robots. txt позволяет закрыть индексацию вашего ресурса:
txt позволяет закрыть индексацию вашего ресурса:
User-agent: * Disallow: /
Многие разработчики забывают закрывать сайт от индексации, и в итоге получается полная проиндексированная копия сайта в поисковиках. Если такая ситуация случилась с вашим сайтом, сделайте 301 постраничный редирект на основной домен сайта.
Конструкция, представленная ниже, позволяет индексировать сайт полностью:
User-agent: * Disallow:
Запрет будет введен на индексацию конкретной папки или группы папок.
User-agent: * Disallow: /category/
Запрет будет действовать для посещения страниц.
User-agent: * Disallow: /category/private.html
Запрет будет введен на индексацию файлов конкретного типа.
User-agent: * Disallow: /*.gif$
Указание Sitemap
User-agent: * Disallow: Sitemap: //semantica.
 in/sitemap.xml
in/sitemap.xml
Robots.txt VS noindex?
Если цель ваша в том, чтобы выбранная страничка не попадала в индекс, то выбрать следует noindex в метатеге robots. Для того, чтобы выполнить данный выбор, на страничке в секции следует включить следующий метатег:
<meta name="robots" content="noindex"/>
Проверка работы файла robots.txt
После того как вами был правильно создан файл robots.txt, следует проверить его на отсутствие ошибок. Для осуществления этой задачи необходимо использовать инструменты проверок от поисковиков: Google Вебмастерс. Войдите в свой аккаунт, предварительно подтвердив на нем текущий сайт, перейдите на сканирование, а далее в Инструмент, проверяющий файл robots.txt.
Для использования Яндекс Вебмастера нужно пройти по ссылке: http://webmaster.yandex.ru/robots.xml.
Здесь не обязательно авторизовываться, а также подтверждать свои персональные права на обладание сайтом. Можно сразу перейти к процессу проверок файла robots.txt.
Можно сразу перейти к процессу проверок файла robots.txt.
Правильное содержание файла robots.txt — это один из главных пунктов в вопросах внутренней оптимизации вашего сайта, а также при старте поисковых продвижений.
Как правильно настроить robots.txt — Академия SEO (СЕО)
Правильный robots.txt и его важность
Хотите узнать как закрыть сайт от индексации поисковиками, когда Вы в этом не нуждаетесь?
Оказывается, это не так уж сложно. Потребуется лишь правильный robots.txt, размещенный в корневой папке Вашего веб-ресурса.
Ну а теперь по порядку.
robots.txt – текстовый файл, в котором предписываются рекомендации для действий роботов поисковиков. Именно его они первым делом ищут, едва «переступив порог» Вашего веб-ресурса. Если его нет или он присутствует, но не содержит в себе никакой информации, поисковые боты воспринимают это как разрешение «прогуляться» по всему сайту без каких-либо ограничений.
Если его нет или он присутствует, но не содержит в себе никакой информации, поисковые боты воспринимают это как разрешение «прогуляться» по всему сайту без каких-либо ограничений.
И наоборот, если в нем прописаны определенные инструкции по запрещению индексации, поисковые роботы будут стараться их придерживаться.
Принцип действия и настройка robots.txt
Правильный robots.txt содержит в своем теле записи, каждая из которых начинается со строки, в которой указывается клиентское приложение User-agent. В нем прописывается название робота, к которому относятся инструкции в следующей строке/строках.
Если же инструкция относится ко всем паукам-индексаторам, вместо имени используется символ «звездочка»:
Далее прописывается строка с директивой Disallow и несколько спец. символов, которые выбираются в зависимости от цели инструкции.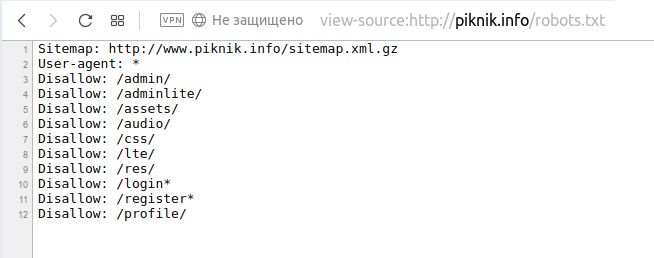
Закрыть сайт от индексации? Нет ничего проще!
Собственно говоря, основная функция robots – запретить индексацию. Чего именно? Тут уж Вам выбирать. Вариантов существует предостаточно:
- Полностью запретить индексацию сайта. Подразумевается возможность отказать пришедшему «в гости» роботу заходить на Ваш веб-ресурс и выполнять свою работу. Может быть полезно на ранних стадиях разработки сайта, когда публикация контента уже началась, но еще не доведена до нужного уровня. В этом случае индексация неоптимизированных страниц нежелательна, дабы «не подпортить» заранее репутацию сайта.
- Закрыть от индексации раздел/категорию. Используется в случае вполне действующего веб-ресурса, имеющем определенный рейтинг в глазах поисковиков, когда готовится новый раздел или категория, индексация которых пока что нежелательна.
- Запретить индексацию страницы. Удобно использовать в случае, если на сайте размещены документы, которые нужны, но не должны индексироваться и влиять на общий рейтинг веб-ресурса. Например, это может быть «Политика конфиденциальности», состоящая из неуникального текста.
Настройка robots.txt. 10 важных фишек
- Если в robots запретить индексацию, то она будет действовать по принципу старшинства. То есть запрет распространяется на все файлы, страницы и директории, которые подчинены указанному элементу.
- Правильный robots.txt всегда содержит минимум одну строку User-agent, чтобы его принимали к сведению.
- Возможна настройка robots.txt, при которой для одного бота может быть прописана запись, состоящая сразу из нескольких инструкций.
- Символ «*» перед названием поможет запретить индексацию всех объектов с указанным словом.
- Символ «/» используется как в начале, так и в конце названия директории. В противном случае robots может запретить индексацию всех страниц, в имени которых встречается «slovo».
- Пустая директива Disallow дает роботу разрешение индексировать все странички веб-ресурса.
- Желательно, чтобы правильный robots.txt указывал, где находится карта сайта. Это значительно ускорит индексацию страниц и исключит вероятность случайного пропуска роботом некоторых из них.
- Правильный robots.txt может содержать инструкции, прописанные только при использовании нижнего регистра.
- Любая Disallow может указывать только на один файл/раздел/страницу и должна прописываться с новой строки.
- Нельзя прописывать сначала Disallow, а потом User-agent. Подобная настройка robots.txt будет пустой тратой времени, поскольку боты не смогут понять таких инструкций.
 Подобная настройка robots.txt будет пустой тратой времени, поскольку боты не смогут понять таких инструкций.
Подобная настройка robots.txt будет пустой тратой времени, поскольку боты не смогут понять таких инструкций.
И самое главное правило – перед тем, как залить правильный robots.txt в корень веб-сайта, нужно убедить в его правильности. Рекомендуется проверять его на ошибки несколько раз. А еще лучше – дать проверить кому-нибудь другому. Свежему взгляду проще будет увидеть опечатки и прочие неприятности в теле файла.
Только верная настройка robots.txt поможет запретить индексацию именно тех элементов Вашего сайта, которые Вы пока что решили скрыть от «зоркого взгляда» поисковиков.
Остались вопросы? Задавайте! Ждем Вас в комментариях!
Все о файле «robots.txt» по-русски — как составить robots.txt
Файл robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Если вы – вебмастер, вы должны знать назначение и синтаксис robots. txt.
txt.
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
Создание robots.txt
Файл с указанным расширением – простой текстовый документ. Он создается с помощью обычного блокнота, программ Notepad или Sublime, а также любого другого редактора текстов. Важно, что в его названии должен быть нижний регистр букв – robots.txt.
Также существует ограничение по количеству символов и, соответственно, размеру. Например, в Google максимальный вес установлен как 500 кб, а у Yandex – 32 кб. В случае их превышения корректность работы может быть нарушена.
Создается документ в кодировке UTF-8, и его действие распространяется на протоколы HTTP, HTTPS, FTP.
При написании содержимого файла запрещается использование кириллицы. Если есть необходимость применения кириллических доменов, необходимо прибегать к помощи Punycode. Кодировка адресов отдельных страниц должна происходить в соответствии с кодировкой структуры сайта, которая была применена.
После того как файл создан, его следует запустить в корневой каталог. При этом используется FTP-клиент, проверяется возможность доступа по ссылке https://site.com./robots.txt и полнота отображения данных.
Важно помнить, что для каждого поддомена сайта оформляется свой файл с ограничениями.
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots. txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
 txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.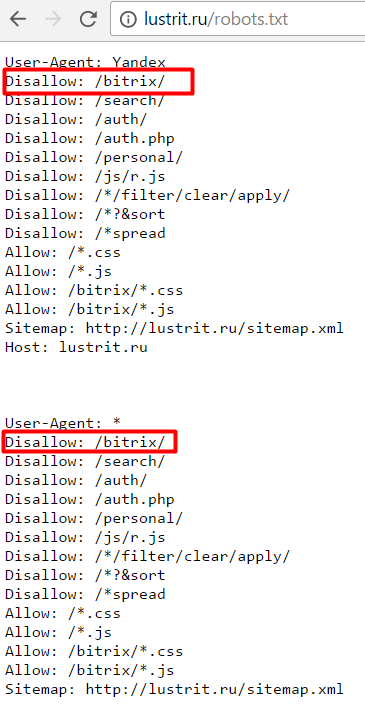 txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *. gif» или «User-agent: Ya*» не поддерживаются.
gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить весь сайт для индексации всеми роботами
User-agent: *
Disallow: /
Разрешить всем роботам индексировать весь сайт
User-agent: *
Disallow:
Или можете просто создать пустой файл «/robots.txt».
Закрыть от индексации только несколько каталогов
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Запретить индексацию сайта только для одного робота
User-agent: BadBot
Disallow: /
Разрешить индексацию сайта одному роботу и запретить всем остальным
User-agent: Yandex
Disallow:
User-agent: *
Disallow: /
Запретить к индексации все файлы кроме одного
Это довольно непросто, т. к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
User-agent: *
Disallow: /docs/
Либо вы можете запретить все запрещенные к индексации файлы:
User-agent: *
Disallow: /private.html
Disallow: /foo.html
Disallow: /bar.html
Инфографика
Проверка
Оценить правильность созданного документа robots.txt можно с помощью специальных проверочных ресурсов:
- Анализ robots.txt. – при работе с Yandex.
- robots.txt Tester – для Google.
Важно помнить, что неправильно созданный или прописанный документ может являться угрозой для посещаемости и ранжирования сайта.
О сайте
Этот сайт — некоммерческий проект. Значительная часть материалов — это переводы www.robotstxt.org, другая часть — оригинальные статьи.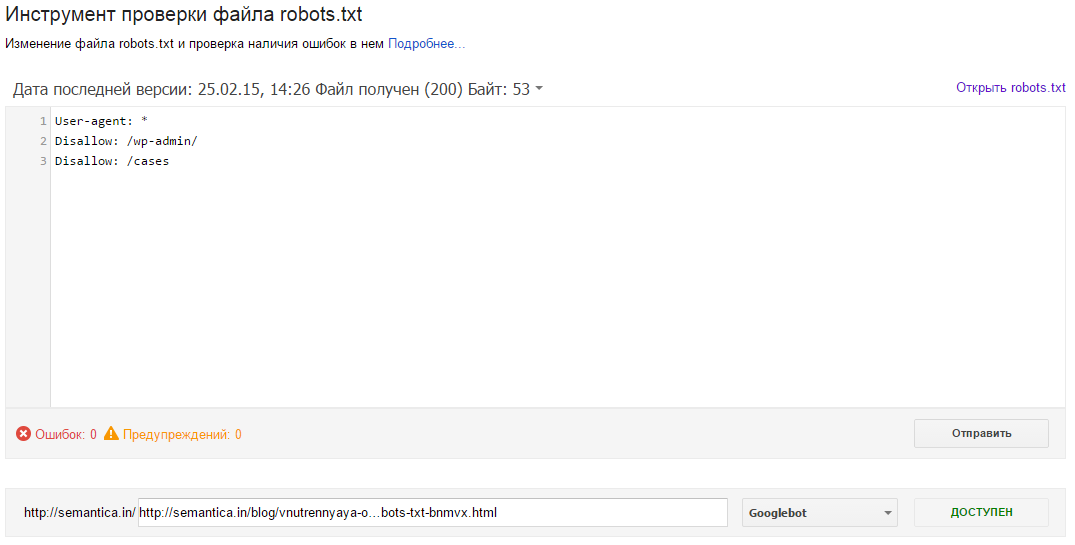 Мы не хотим ограничиваться только robots.txt, поэтому в некоторых статьях описаны альтернативные методы «ограничения» роботов.
Мы не хотим ограничиваться только robots.txt, поэтому в некоторых статьях описаны альтернативные методы «ограничения» роботов.
Тестер и валидатор Robots.txt [Примеры кода включены]
Что такое файл robots.txt
Файл
Robots.txt служит для предоставления ценной информации поисковым системам, сканирующим Интернет. Прежде чем исследовать страницы вашего сайта, поисковые роботы проверяют этот файл. Благодаря такой процедуре они могут повысить эффективность сканирования. Таким образом, вы поможете поисковым системам в первую очередь выполнить индексацию наиболее важных данных на вашем сайте. Но это возможно только в том случае, если вы правильно настроили robots.текст.
Как и директивы файла robots.txt, инструкция noindex в метатегах robots — не более чем просто рекомендация для роботов. По этой причине они не могут гарантировать, что закрытые страницы не будут проиндексированы и не будут включены в индекс. Гарантии в этом отношении неуместны. Если вам нужно закрыть для индексации какую-то часть вашего сайта, вы можете использовать пароль для закрытия каталогов.
Если вам нужно закрыть для индексации какую-то часть вашего сайта, вы можете использовать пароль для закрытия каталогов.
Важно! Чтобы директива noindex вступила в силу, страница не должна блокироваться файлом robots.txt файл. Если страница заблокирована файлом robots.txt, поисковый робот никогда не увидит директиву noindex, и страница все равно может отображаться в результатах поиска, например, если на нее ссылаются другие страницы.
Справка Google Search Console
Если на вашем веб-сайте нет txt-файла робота, ваш веб-сайт будет просканирован полностью. Это означает, что все страницы сайта попадут в поисковый индекс, что может создать серьезные проблемы для SEO.
Синтаксис Robots.txt
User-Agent: робот, к которому будут применяться следующие правила (например, «Googlebot»).Строка пользовательского агента — это параметр, который веб-браузеры используют в качестве своего имени. Но он содержит не только название браузера, но также версию операционной системы и другие параметры.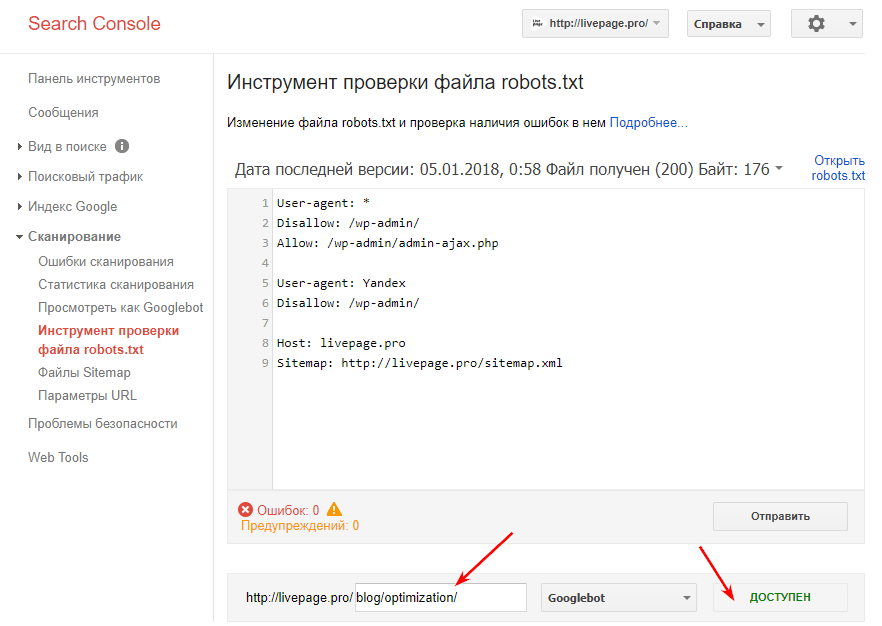 С помощью пользовательского агента вы можете определить множество параметров: название операционной системы, ее версию; проверьте устройство, на котором установлен браузер; определить функции браузера.
С помощью пользовательского агента вы можете определить множество параметров: название операционной системы, ее версию; проверьте устройство, на котором установлен браузер; определить функции браузера.
Disallow: страниц, которые вы хотите закрыть для доступа (в начале каждой новой строки вы можете включать большой список подобных директив).Каждая группа User-Agent / Disallow должна быть разделена пустой строкой. Но непустые строки не должны встречаться внутри группы (между User-Agent и последней директивой Disallow).
Знак решетки (#) можно использовать, когда необходимо оставить комментарии в файле robots.txt для текущей строки. Все, что упомянуто после решетки, будет проигнорировано. Этот комментарий применим как ко всей строке, так и в ее конце после директив. Каталоги и имена файлов чувствительны к регистру: поисковая система принимает «Каталог», «Каталог» и «КАТАЛОГ» как разные директивы.
Хост: используется Яндексом для указания главного зеркала сайта. Вот почему, если вы выполняете 301 редирект на страницу, чтобы склеить два сайта, нет необходимости повторять процедуру для файла robots.txt (на дублированном сайте). Таким образом, Яндекс обнаружит указанную директиву на сайте, которую необходимо закрепить.
Вот почему, если вы выполняете 301 редирект на страницу, чтобы склеить два сайта, нет необходимости повторять процедуру для файла robots.txt (на дублированном сайте). Таким образом, Яндекс обнаружит указанную директиву на сайте, которую необходимо закрепить.
Crawl-delay: вы можете ограничить скорость обхода вашего сайта, что очень полезно в случае высокой частоты посещаемости вашего сайта.Такая опция включена, чтобы избежать проблем с дополнительной нагрузкой на ваш сервер из-за того, что различные поисковые системы обрабатывают информацию на сайте.
Регулярные выражения: , чтобы обеспечить более гибкую настройку директив, вы можете использовать два символа, указанные ниже:
* (звездочка) — обозначает любую последовательность символов,
$ (знак доллара) — обозначает конец линия.
Как настроить robots.txt: правила и примеры
Запрет сканирования всего сайта
Пользовательский агент: *
Disallow: /
Эту инструкцию необходимо применять, когда вы создаете новый сайт и используете поддомены для предоставления доступа к нему.
Очень часто при работе над новым сайтом веб-разработчики забывают закрыть какую-то часть сайта для индексации, и в результате индексные системы обрабатывают ее полную копию. Если такая ошибка произошла, ваш главный домен должен пройти 301 редирект на страницу.
Разрешение на сканирование всего сайта
User-agent: *
Disallow:
Запрет на сканирование определенной папки
User-agent: Googlebot
Disallow: / no-index /
Бан на краулинг-страницу для определенного бота
User-agent: Googlebot
Disallow: / no-index / this-page.HTML
Запрет на сканирование определенного типа файлов
User-agent: *
Disallow: /*.pdf$
Разрешение на сканирование страницы для определенного бота
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page. html
html
User-agent: Yandex
Разрешить: / no-bots / block-all-bots-except- Яндекс-page.html
Ссылка на карту сайта
User-agent: *
Disallow:
Карта сайта: http: // www.example.com/none-standard-location/sitemap.xml
Особенности, которые необходимо учитывать
Отключить индексацию поисковой системой | Webflow University
Запретить поисковым системам индексировать страницы, папки, весь ваш сайт или только ваш субдомен webflow.io.
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, а какие нет на вашем сайте, написав файл robots.txt файл. Вы можете запретить сканирование страниц, папок, всего вашего сайта. Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
В этом уроке
Отключение индексации субдомена Webflow
Вы можете запретить Google и другим поисковым системам индексировать субдомен webflow.io, просто отключив индексирование в настройках вашего проекта.
- Перейдите в Project Settings → SEO → Indexing
- Установите Disable Subdomain Indexing на «Да»
- Сохраните изменения и опубликуйте свой сайт
A unique robots.txt будет опубликовано только на поддомене, указав поисковым системам игнорировать домен.
Создание файла robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, которые вы не хотите, чтобы поисковые системы сканировали. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать .
Как и карта сайта, файл robots. txt находится в каталоге верхнего уровня вашего домена.Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках проекта.
txt находится в каталоге верхнего уровня вашего домена.Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках проекта.
- Перейдите в Project Settings → SEO → Indexing
- Добавьте robots.txt правила, которые вы хотите (см. Ниже)
- Сохраните изменения и опубликуйте свой сайт
Создайте роботов .txt для вашего сайта, добавив правила для роботов, сохранив изменения и опубликовав свой сайт.
Robots.txt rules
Вы можете использовать любое из этих правил для заполнения роботов.txt файл.
- User-agent: * означает, что этот раздел применим ко всем роботам.
- Disallow: указывает роботу не посещать сайт, страницу или папку.
Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: / page-name
Чтобы скрыть всю папку страниц
User-agent: *
Disallow: / folder-name /
Чтобы включить карту сайта
Sitemap: https: // your-site. com / sitemap.xml
com / sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt
Необходимо знать
- Содержимое вашего сайта может быть проиндексировано, даже если оно не сканировалось. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент в другом онлайн-контенте. Чтобы страница не проиндексировалась, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex.
- Кто угодно может получить доступ к robots вашего сайта.txt, чтобы они могли идентифицировать ваш личный контент и получить к нему доступ.
Лучшие практики
Если вы не хотите, чтобы кто-либо мог найти определенную страницу или URL-адрес на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL-адреса. Вместо этого используйте любой из следующих вариантов:
Попробуйте Webflow — это бесплатно
Joomla SEO | Конфигурация метатега robots. txt и robots
 txt и robots
txt и robots Метатег robots и robots.txt — это 2 разных независимых механизма для передачи информации роботам поисковых систем. Они, в частности, позволяют вам указать, какие части вашего сайта должны индексироваться поисковыми системами, а какие нет. Оба они очень эффективны, но их следует использовать осторожно, так как небольшие ошибки могут иметь серьезные последствия!
Robots.txt используется для блокировки системных папок, таких как папка / plugins , которая по умолчанию поставляется с установкой Joomla. Метатег robots обычно используется более конкретно для блокировки определенных страниц.Например, Google не любит ваши внутренние поисковые страницы в индексе Google (см. Www.seroundtable.com/google-block-search-results-pages-24279.html), и вы должны использовать метатег robots, чтобы заблокировать их. Итак, вкратце: robots.txt сообщает Google: не заходите сюда, а метатег Robots сообщает Google: не индексируйте меня. Это 2 действительно разные вещи!
Это 2 действительно разные вещи!
Оба решения не заменяют друг друга, оба имеют свое конкретное назначение. Не используйте их одновременно! Я подробно рассмотрю оба решения.
Robots.txt
Конфигурация файла robots.txt происходит вне администратора Joomla, вы просто открываете и редактируете фактический файл. Файл robots.txt — это файл, который в основном содержит информацию о том, какую часть сайта следует сделать общедоступной. Он предназначен специально для ботов поисковых систем, которые сканируют веб-сайты, чтобы определить, какую страницу следует включить в индекс. По умолчанию движкам разрешено сканировать все, поэтому, если необходимо заблокировать части сайта, вам нужно указать их специально.
Обратите внимание, что блокировка URL в robots.txt не мешает Google проиндексировать страницу. Он просто перестанет проверять страницу. Просто проверьте этот результат для программы SEO Raven tools, которая на самом деле занимает высокие позиции в рейтинге:
Итак, если вы хотите быть абсолютно уверены в том, что не будете проиндексированы, вам следует использовать метатег robots, см. Ниже на этой странице.
Ниже на этой странице.
Вернуться к файлу robots.txt: Joomla поставляется со стандартным файлом robots.txt, который должен нормально работать для большинства сайтов, за исключением старых сайтов: в старых версиях Joomla он блокировал папку / images . Это предотвращает индексацию изображений для вашего сайта, чего, конечно же, не должно быть. Поэтому закомментируйте эту строку или удалите ее полностью:
User-agent: *
Disallow: / administrator /
Disallow: / cache /
Disallow: / cli /
Disallow: / components /
# Disallow: / images / < -------- Закомментировано с помощью # или удалите их
Disallow: / includes /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow : / logs /
# Disallow: / media / <-------- Закомментировано с помощью # или удалите их
Disallow: / modules /
Disallow: / plugins /
# Disallow : / templates / <-------- Закомментировано с помощью # или удалите их
Disallow: / tmp /
Примечание: Начиная с Joomla 3. 3 эта проблема исправлена, и эти строки больше не блокируются. Но если ваш сайт был запущен в более старой версии, старая версия robots.txt все еще может быть там!
3 эта проблема исправлена, и эти строки больше не блокируются. Но если ваш сайт был запущен в более старой версии, старая версия robots.txt все еще может быть там!
Как видите, файл в основном используется для блокировки системных папок. Кроме того, вы также можете использовать файл для предотвращения индексации определенных страниц, например страниц входа или 404, но это лучше сделать с помощью метатега robots.
Вы также можете проверить, работает ли ваш файл robots.txt, используя раздел заблокированного URL-адреса в Инструментах Google для веб-мастеров.
Расширенная настройка с помощью robots.txt
Опытные пользователи могут использовать файл robots.txt, чтобы блокировать индексацию страниц с помощью сопоставления с образцом. Вы можете, например, заблокировать любую страницу, содержащую ‘?’ для предотвращения дублирования контента с URL-адресов, отличных от SEF:
User-agent: *
Disallow: / *? *
Нет необходимости говорить, что с этим нужно быть осторожным. Другой пример можно найти на сайте searchchengineland.com.
Другой пример можно найти на сайте searchchengineland.com.
Разрешить CSS и Javascript?
Замечание, которое Google недавно сделал в отношении мобильных сайтов (см. Это видео с выступлением Мэтта Каттса из Google):
По умолчанию не блокировать CSS, Javascript и другие файлы ресурсов.Это мешает роботу Google правильно отображать страницу и понимать, что она оптимизирована для мобильных устройств.
Вот почему папки / templates и / media больше не блокируются для установки Joomla с июля 2014 года. Убедитесь, что все ваши файлы ресурсов не заблокированы. Если вы используете такой плагин, как JCH-Optimize, который объединяет несколько файлов CSS и Javascript в отдельные файлы, вам может потребоваться указать для этого правило Allow , например:
Разрешить: / plugins / system / jch_optimize / assets2 /
Разрешить: / plugins / system / jch_optimize / assets /
Тестовые роботы. txt в Инструментах Google для веб-мастеров
 txt в Инструментах Google для веб-мастеров
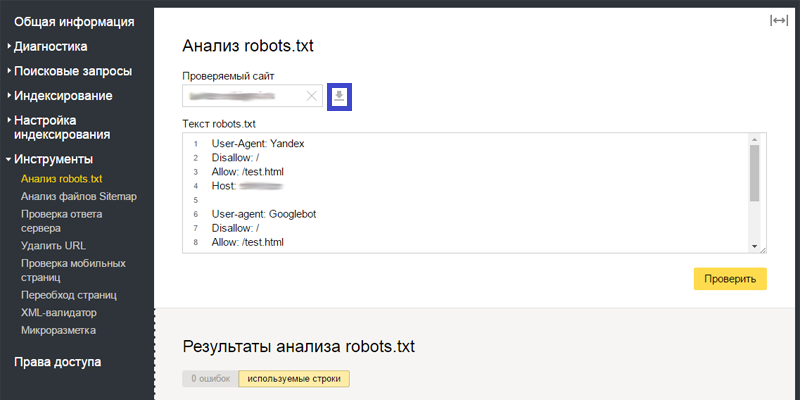
txt в Инструментах Google для веб-мастеров В 2014 году Google стал более строгим в отношении файла robots.txt. Он более требователен к заблокированным ресурсам (CSS и JS), но он также представил некоторые инструменты в вашей учетной записи веб-мастера, которые помогут вам устранять неполадки. Прежде всего, это касается robots.txt Tester , который можно найти в параметрах Crawl :
В этом случае ошибок и предупреждений нет, но если они есть, вы получите уведомление.Имейте в виду, что это всего лишь базовая проверка правильности введенных вами строк, она не проверяет, являются ли заблокированные ресурсы важными для отображения сайта.
Здесь пригодится инструмент Fetch as Google . Я действительно советую вам проверить свой сайт с помощью этого инструмента, вы можете найти потрясающие результаты! Этот инструмент пытается проверить ваш сайт глазами роботов Google, сканирующих ваш сайт. Теперь посмотрим, как наш сайт выглядит с помощью этого инструмента.
Результатом может быть зеленая галочка, но если результат частичный , вы еще не закончили !!!! Установите флажок, и откроется новая страница.Теперь ваш сайт может выглядеть так:
Это может быть дисплей, который вы получаете, когда Google обнаруживает блок для вашей папки / шаблона , где находятся все ваши CSS и JS. Какие ресурсы заблокированы, легко найти, сообщает Google прямо здесь. Подробная статья в блоге по этой теме находится прямо здесь. Убедитесь, что вы проверили это, так как это может действительно повлиять на поисковый рейтинг из-за того, что Google не сможет правильно отобразить ваш сайт. Конкретно. он не может сказать, отзывчивый ваш сайт или нет!
Укажите на карту вашего сайта
Другое: роботы.txt можно использовать для указания на ваши файлы xml-sitemap, особенно если они не расположены в корне вашего веб-сайта, что часто бывает, если ваша карта сайта создается расширениями Joomla, такими как PWT Sitemap, OSmap, Jsitemap и т. д. Что вам нужно сделать, так это найти местоположение карты сайта в конфигурации расширения, а затем просто указать на него в нижней части файла robots.txt, например:
д. Что вам нужно сделать, так это найти местоположение карты сайта в конфигурации расширения, а затем просто указать на него в нижней части файла robots.txt, например:
Карта сайта: index.php? Option = com_osmap & view = xml & tmpl = component & id = 1
Обновления Joomla и изменения в robots.txt
Время от времени проект Joomla выпускает обновления для файла robots.txt, например, больше не блокирует определенные папки. Если они это сделают, они не будут просто распространять новый файл robots.txt, потому что он перезапишет любые настройки, которые вы сделали для себя. Вместо этого они распространяют файл с названием robots.txt.dist . Если вы никогда не вносили никаких изменений, вы можете просто удалить существующий файл robots.txt и переименовать robots.txt.dist в robots.txt.
Если вы все же настраивали его, просто проверьте, что изменилось, и скопируйте это изменение в свой настроенный файл.Обычно вы будете получать уведомления о подобных изменениях в сообщениях после установки на панели инструментов Joomla. Кстати, такая же процедура применима и для изменения .htaccess.
Кстати, такая же процедура применима и для изменения .htaccess.
Мета-тег роботов
Метатег robots — лучший способ заблокировать индексирование контента, но вы можете использовать его только для URL-адресов, а не для системных папок. Это очень эффективный метод, чтобы убрать информацию из индекса Google. В Joomla вы можете указать тег в нескольких местах, в основном параллельно с другими настройками SEO, такими как мета-описания.На глобальном уровне большинство сайтов должны оставить значение по умолчанию, установленное на экране Global Configuration , в Metadata Settings . Как видите, можно установить 4 комбинации настроек:
Если вы не хотите скрыть свой сайт от поисковых систем (полезно для разработки), оставьте значение по умолчанию Index, Follow . Для определенных страниц вы можете переопределить это либо из статьи, либо из пункта меню. Например: результаты страницы поиска не должны индексироваться, но вы хотите, чтобы по ссылкам следовали: установите для тега значение Без индекса, перейдите по ссылке .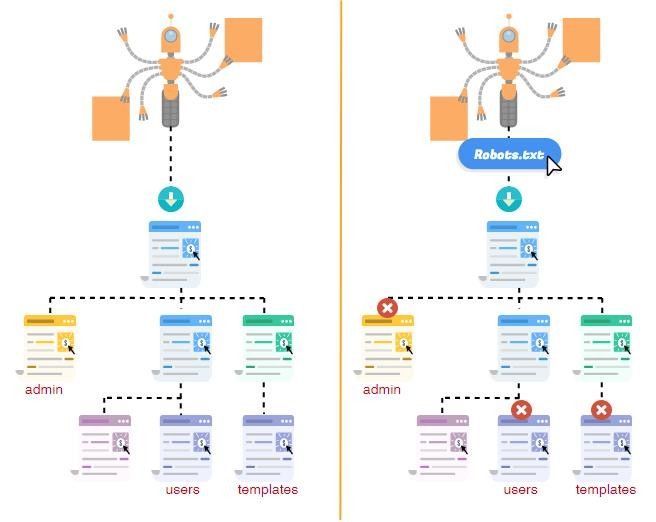 Вы можете найти больше информации об этом в электронной книге.
Вы можете найти больше информации об этом в электронной книге.
Когда вы используете тег, вы фактически создаете следующий код в своем HTML, поэтому вы можете легко проверить правильность вашей конфигурации:
Одно предупреждение: , если вы используете Noindex, Nofollow , чтобы скрыть свои сайты разработки, не забудьте изменить это, когда сайт будет запущен (это случилось со мной …), иначе ваши результаты SEO будут очень плохими …. Для дальнейшего чтения по этой теме, посмотрите этот пост на Moz.com.
robots.txt недействителен
• Обновлено
Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта они могут
ползать. Недопустимая конфигурация robots.txt может вызвать проблемы двух типов:
- Это может помешать поисковым системам сканировать общедоступные страницы, что приведет к
контент, который будет реже появляться в результатах поиска. - Это может привести к тому, что поисковые системы будут сканировать страницы, которые вы не хотите показывать в поиске.
полученные результаты.

Как не удалось выполнить аудит Lighthouse robots.txt #
Флаги маяка недействительны
robots.txt файлов:
Большинство проверок Lighthouse применяется только к той странице, на которой вы сейчас находитесь.
Однако, поскольку robots.txt определен на уровне имени хоста,
этот аудит применяется ко всему вашему домену (или субдомену).
Расширьте роботов.txt недействителен audit в вашем отчете
чтобы узнать, что не так с вашим robots.txt .
Общие ошибки включают:
-
Пользовательский агент не указан -
Шаблон должен быть пустым, начинаться с "/" или "*" -
Неизвестная директива -
Неверный URL карты сайта -
$ следует использовать только в конце шаблона
Lighthouse не проверяет, что ваш robots.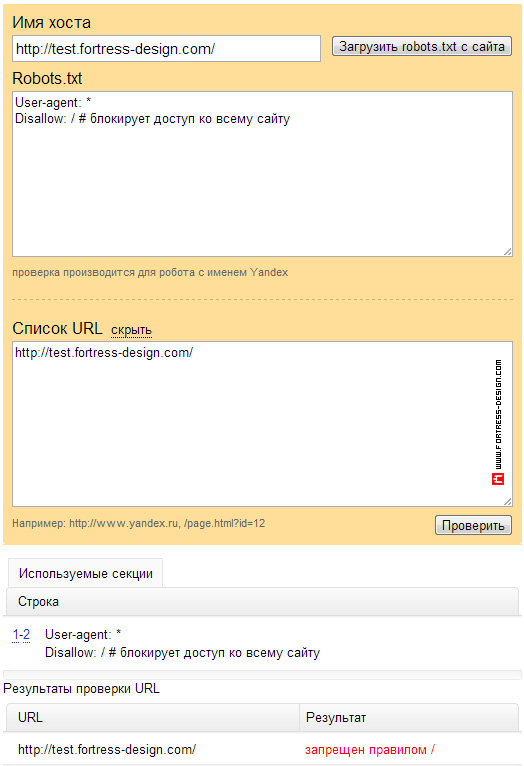 txt файл
txt файл
в правильном месте. Для правильной работы файл должен находиться в корне
ваш домен или субдомен.
Как исправить проблемы с файлом robots.txt #
Убедитесь, что robots.txt не возвращает код состояния HTTP 5XX #
Если ваш сервер возвращает ошибку сервера (код состояния HTTP
в 500) для robots.txt поисковые системы не будут знать, какие страницы следует
поползли. Они могут перестать сканировать весь ваш сайт, что предотвратит появление новых
контент из индексации.
Чтобы проверить код состояния HTTP, откройте robots.txt в Chrome и
проверьте запрос в Chrome DevTools.
Оставить robots.txt меньше 500 КиБ #
Поисковые системы могут прекратить обработку robots.txt на полпути, если файл
больше 500 КБ. Это может сбить с толку поисковую систему и привести к неверным
сканирование вашего сайта.
Чтобы файл robots.txt оставался маленьким, уделяйте меньше внимания отдельным исключенным страницам и т.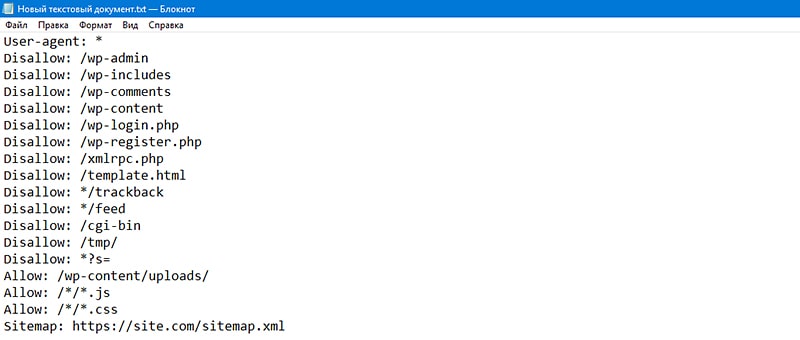 Д.
Д.
на более широкие модели.Например, если вам нужно заблокировать сканирование файлов PDF,
не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие
.pdf , используя disallow: /*.pdf .
Исправить любые ошибки формата #
- Только пустые строки, комментарии и директивы, соответствующие формату «имя: значение»
разрешено вrobots.txt. - Убедитесь, что
разрешаютизапрещают Значениялибо пусты, либо начинаются с/или*. - Не используйте
$в середине значения (например,allow: / file $ html).
Убедитесь, что есть значение для user-agent #
Имена пользовательских агентов, которые сообщают сканерам поисковых систем, каким директивам следует следовать. Вы
должен предоставлять значение для каждого экземпляра пользовательского агента , чтобы поисковые системы знали
следует ли следовать соответствующему набору директив.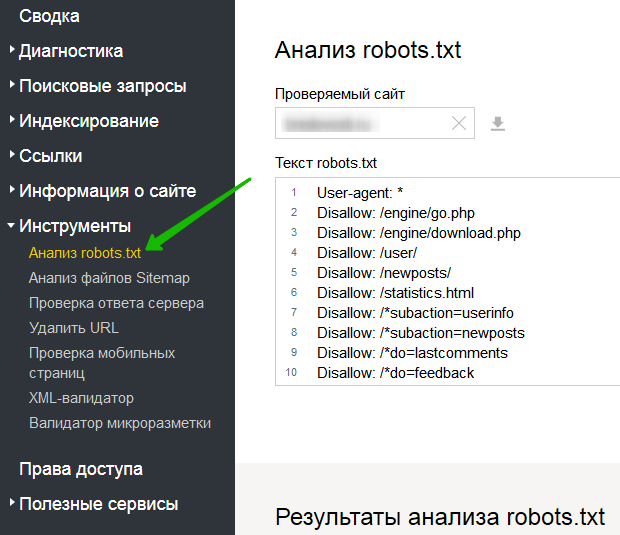
Чтобы указать конкретный сканер поисковой системы, используйте имя пользовательского агента из его
опубликованный список.(Например, вот
Список пользовательских агентов Google, используемых для сканирования.)
Используйте * для сопоставления со всеми поисковыми роботами, не имеющими аналогов.
Не надо
пользовательский агент:
запретить: / downloads / Пользовательский агент не определен.
Делать
user-agent: *
disallow: / downloads / user-agent: magicsearchbot
disallow: / uploads /
Определены общий пользовательский агент и пользовательский агент magicsearchbot .
Убедитесь, что нет директив allow или disallow до user-agent #
Имена пользовательских агентов определяют разделы файла robots.txt . Поисковый движок
сканеры используют эти разделы, чтобы определить, каким директивам следовать.
Добавить комментарий